
阅读量:0
服务器出现大量 TIME_WAIT 状态的原因有哪些?
首先要知道 TIME_WAIT 状态是主动关闭连接方才会出现的状态(别陷入一个误区不是只有客户端才能主动关闭连接的),所以如果服务器出现大量的 TIME_WAIT 状态的 TCP 连接,就是说明服务器主动断开了很多 TCP 连接。
问题来了,什么场景下服务端会主动断开连接呢?
第一个场景:HTTP 没有使用长连接
第二个场景:HTTP 长连接超时
第三个场景:HTTP 长连接的请求数量达到上限
HTTP 没有使用长连接
我们先来看看 HTTP 长连接(Keep-Alive)机制是怎么开启的。
在 HTTP/1.0 中默认是关闭的,如果浏览器要开启 Keep-Alive,它必须在请求的 header 中添加:
Connection: Keep-Alive然后当服务器收到请求,作出回应的时候,它也被添加到响应中 header 里:
Connection: Keep-Alive这样做,TCP 连接就不会中断,而是保持连接。当客户端发送另一个请求时,它会使用同一个 TCP 连接。这一直继续到客户端或服务器端提出断开连接。
从 HTTP/1.1 开始, 就默认是开启了 Keep-Alive,现在大多数浏览器都默认是使用 HTTP/1.1,所以 Keep-Alive 都是默认打开的。一旦客户端和服务端达成协议,那么长连接就建立好了。
如果要关闭 HTTP Keep-Alive,需要在 HTTP 请求或者响应的 header 里添加 Connection:close 信息,也就是说,只要客户端和服务端任意一方的 HTTP header 中有 Connection:close 信息,那么就无法使用 HTTP 长连接的机制。
关闭 HTTP 长连接机制后,每次请求都要经历这样的过程:建立 TCP -> 请求资源 -> 响应资源 -> 释放连接,那么此方式就是 HTTP 短连接
在 RFC 文档中,并没有明确由谁来关闭连接,请求和响应的双方都可以主动关闭 TCP 连接。不过,根据大多数 Web 服务的实现,不管哪一方禁用了 HTTP Keep-Alive,都是由服务端主动关闭连接,那么此时服务端上就会出现 TIME_WAIT 状态的连接。
因此,当服务端出现大量的 TIME_WAIT 状态连接的时候,可以排查下是否客户端和服务端都开启了 HTTP Keep-Alive,因为任意一方没有开启 HTTP Keep-Alive,都会导致服务端在处理完一个 HTTP 请求后,就主动关闭连接,此时服务端上就会出现大量的 TIME_WAIT 状态的连接。
HTTP 长连接超时
HTTP 长连接可以在同一个 TCP 连接上接收和发送多个 HTTP 请求/应答,避免了连接建立和释放的开销。
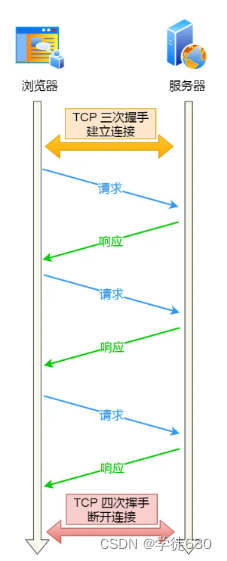
为了避免资源浪费的情况,web 服务软件一般都会提供一个参数,用来指定 HTTP 长连接的超时时间,比如 nginx 提供的 keepalive_timeout 参数。
假设设置了 HTTP 长连接的超时时间是 60 秒,nginx 就会启动一个「定时器」,如果客户端在完后一个 HTTP 请求后,在 60 秒内都没有再发起新的请求,定时器的时间一到,nginx 就会触发回调函数来关闭该连接,那么此时服务端上就会出现 TIME_WAIT 状态的连接。
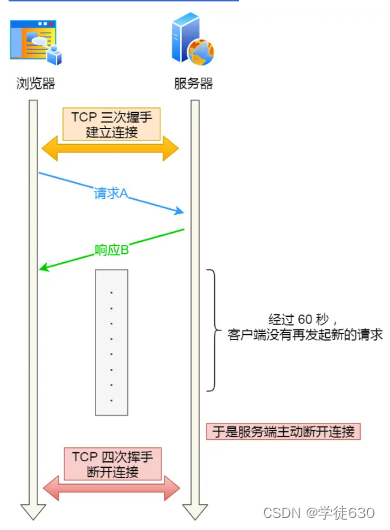
对此,可以往网络问题的方向排查,比如是否是因为网络问题,导致客户端发送的数据一直没有被服务端接收到,以至于 HTTP 长连接超时。
HTTP 长连接的请求数量达到上限
Web 服务端通常会有个参数,来定义一条 HTTP 长连接上最大能处理的请求数量,当超过最大限制时,就会主动关闭连接。
比如 nginx 的 keepalive_requests 这个参数,这个参数是指一个 HTTP 长连接建立之后,nginx 就会为这个连接设置一个计数器,记录这个 HTTP 长连接上已经接收并处理的客户端请求的数量。如果达到这个参数设置的最大值时,则 nginx 会主动关闭这个长连接,那么此时服务端上就会出现 TIME_WAIT 状态的连接。
keepalive_requests 参数的默认值是 100 ,意味着每个 HTTP 长连接最多只能跑 100 次请求,这个参数往往被大多数人忽略,因为当 QPS (每秒请求数) 不是很高时,默认值 100 凑合够用。
但是,对于一些 QPS 比较高的场景,比如超过 10000 QPS,甚至达到 30000 , 50000 甚至更高,如果 keepalive_requests 参数值是 100,这时候就 nginx 就会很频繁地关闭连接,那么此时服务端上就会出大量的 TIME_WAIT 状态。
解决的方式也很简单,调大 nginx 的 keepalive_requests 参数就行。
服务器出现大量 CLOSE_WAIT 状态的原因有哪些?
CLOSE_WAIT 状态是「被动关闭方」才会有的状态,而且如果「被动关闭方」没有调用 close 函数关闭连接,那么就无法发出 FIN 报文,从而无法使得 CLOSE_WAIT 状态的连接转变为 LAST_ACK 状态。
所以,当服务端出现大量 CLOSE_WAIT 状态的连接的时候,说明服务端的程序没有调用 close 函数关闭连接。
普通的 TCP 服务端的流程
我们先来分析一个普通的 TCP 服务端的流程:
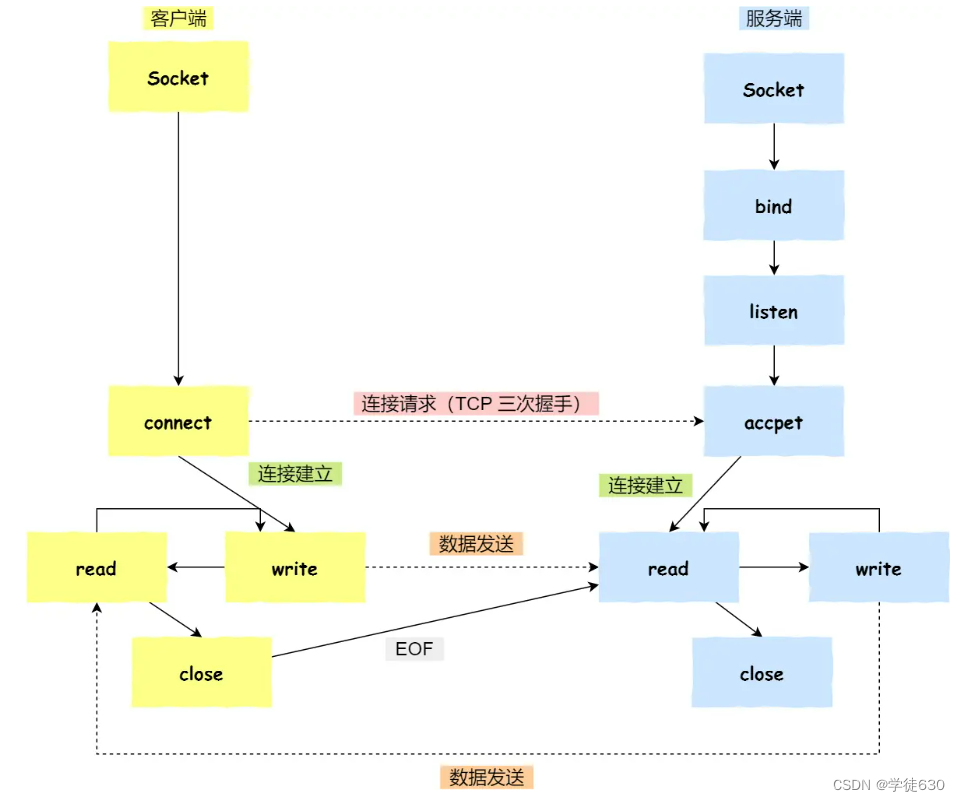
创建服务端 socket,bind 绑定端口、listen 监听端口
将服务端 socket 注册到 epoll
epoll_wait 等待连接到来,连接到来时,调用 accpet 获取已连接的 socket
将已连接的 socket 注册到 epoll
epoll_wait 等待事件发生
对方连接关闭时,我方调用 close
导致服务端没有调用 close 函数的原因
可能导致服务端没有调用 close 函数的原因,如下。
- 第一个原因:第 2 步没有做,没有将服务端 socket 注册到 epoll,这样有新连接到来时,服务端没办法感知这个事件,也就无法获取到已连接的 socket,那服务端自然就没机会对 socket 调用 close 函数了。
不过这种原因发生的概率比较小,这种属于明显的代码逻辑 bug,在前期 read view 阶段就能发现的了。
- 第二个原因: 第 3 步没有做,有新连接到来时没有调用 accpet 获取该连接的 socket,导致有大量客户端主动断开了连接,而服务端没机会对这些 socket 调用 close 函数,从而导致服务端出现大量 CLOSE_WAIT 状态的连接。
发生这种情况可能是因为服务端在执行 accpet 函数之前,代码卡在某一个逻辑或者提前抛出了异常。
- 第三个原因:第 4 步没有做,通过 accpet 获取已连接的 socket 后,没有将其注册到 epoll,导致后续收到 FIN 报文的时候,服务端没办法感知这个事件,那服务端就没机会调用 close 函数了。
发生这种情况可能是因为服务端在将已连接的 socket 注册到 epoll 之前,代码卡在某一个逻辑或者提前抛出了异常。
- 第四个原因:第 6 步没有做,当发现客户端关闭连接后,服务端没有执行 close 函数
可能是因为代码漏处理,或者是在执行 close 函数之前,代码卡在某一个逻辑,比如发生死锁等等。
可以发现,当服务端出现大量 CLOSE_WAIT 状态的连接的时候,通常都是代码的问题,这时候我们需要针对具体的代码一步一步的进行排查和定位,主要分析的方向就是服务端为什么没有调用 close。
