
阅读量:3
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新软件测试全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上软件测试知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注软件测试)
正文
“hello4”
127.0.0.1:6379> srandmember set
“hello3”
127.0.0.1:6379> srandmember set
“hello5”
127.0.0.1:6379> srandmember set
“hello4”
127.0.0.1:6379> srandmember set
“hello4”
127.0.0.1:6379> srandmember set
“hello1”
127.0.0.1:6379> srandmember set
“hello5”
127.0.0.1:6379>
可以指定随机抽取的元素个数
127.0.0.1:6379> srandmember set 2
- “hello2”
- “hello1”
127.0.0.1:6379> srandmember set 2 - “hello2”
- “hello4”
127.0.0.1:6379> srandmember set 2 - “hello5”
- “hello4”
127.0.0.1:6379> srandmember set 2 - “hello3”
- “hello4”
127.0.0.1:6379>
####################################################################################
随机删除集合中某个元素 spop
127.0.0.1:6379> spop set
“hello1”
127.0.0.1:6379> spop set
“hello3”
127.0.0.1:6379> spop set
“hello2”
127.0.0.1:6379> smembers set
- “hello5”
- “hello4”
127.0.0.1:6379>
####################################################################################
将集合中某个指定元素移动到另一个集合中 smove
127.0.0.1:6379> smembers set
- “hello5”
- “hello4”
127.0.0.1:6379> sadd set2 world1
(integer) 1
127.0.0.1:6379> sadd set2 world2
(integer) 1
127.0.0.1:6379> smove set set2 hello4
(integer) 1
127.0.0.1:6379> smembers set - “hello5”
127.0.0.1:6379> smembers set2 - “world2”
- “hello4”
- “world1”
127.0.0.1:6379>
####################################################################################
关于集合
- 差集 sdiff set1 set2 返回set1与set2的差集 即set1中与set2不重合的元素
- 交集 sinter set1 set2 返回set1和set2的交集 应用场景:共同好友、共同爱好、推荐好友
- 并集 sunion set1 set2 返回set1和set2的并集
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> sadd set1 aa
(integer) 1
127.0.0.1:6379> sadd set1 bb
(integer) 1
127.0.0.1:6379> sadd set1 cc
(integer) 1
127.0.0.1:6379> sadd set2 cc
(integer) 1
127.0.0.1:6379> sadd set2 dd
(integer) 1
127.0.0.1:6379> sadd set2 ee
(integer) 1
127.0.0.1:6379> sdiff set1 set2
- “aa”
- “bb”
127.0.0.1:6379> sinter set1 set2 - “cc”
127.0.0.1:6379> sunion set1 set2 - “cc”
- “ee”
- “aa”
- “bb”
- “dd”
127.0.0.1:6379>
4.Hash(哈希)
这个可以理解为 key-map ,而map本身是一个 key-value形式。
所有的hash操作均以 h 开头
####################################################################################
存值 hset | hmset
取值 hget | hmget
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> hset hash name bingbing
(integer) 1
127.0.0.1:6379> hget hash name
“bingbing”
127.0.0.1:6379>
127.0.0.1:6379> hmset hash name1 bingbing name2 fangfang
OK
127.0.0.1:6379> hmget hash name1 name2
- “bingbing”
- “fangfang”
127.0.0.1:6379>
####################################################################################
显示指定key中的所有key-value键值对
127.0.0.1:6379> hgetall hash
- “name”
- “bingbing”
- “name1”
- “bingbing”
- “name2”
- “fangfang”
127.0.0.1:6379>
####################################################################################
删除指定key中某个属性key
127.0.0.1:6379> hgetall hash
- “name”
- “bingbing”
- “name1”
- “bing”
- “name2”
- “fang”
127.0.0.1:6379> hdel hash name
(integer) 1
127.0.0.1:6379> hgetall hash - “name1”
- “bing”
- “name2”
- “fang”
127.0.0.1:6379>
####################################################################################
返回当前key中有多少组K-V键值对
127.0.0.1:6379> hgetall hash
- “name1”
- “bingbing”
- “name2”
- “fangfang”
127.0.0.1:6379> hlen hash
(integer) 2
127.0.0.1:6379>
####################################################################################
只获得所有的key hkeys
只获得所有的value hvals
127.0.0.1:6379> hkeys hash
- “name1”
- “name2”
127.0.0.1:6379> hvals hash - “bingbing”
- “fangfang”
127.0.0.1:6379>
####################################################################################
指定增量 incr
判断是否存在 ,存在则操作失败返回0,不存在则将新值添加到map中,操作成功返回1
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> hset hash age1 5
(integer) 1
127.0.0.1:6379> hincrby hash age1 5
(integer) 10
127.0.0.1:6379> hsetnx hash age2 20
(integer) 1
127.0.0.1:6379> hsetnx hash age3 20
(integer) 1
127.0.0.1:6379> hsetnx hash age2 200
(integer) 0
127.0.0.1:6379> hgetall hash
- “age1”
- “10”
- “age2”
- “20”
- “age3”
- “20”
127.0.0.1:6379>
哈希更适合于对象的存储,String更适合字符串存储
5.Zset(有序集合)
在set的基础上,增加了一个值,如 set k1 v1 -> zset k1 score1 v1
####################################################################################
添加元素 zadd
查看元素 zrange
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> zadd zset 1 one # 添加一个值
(integer) 1
127.0.0.1:6379> zadd zset 2 two 3 three # 添加多个值
(integer) 2
127.0.0.1:6379> zrange zset 0 -1
- “one”
- “two”
- “three”
127.0.0.1:6379>
####################################################################################
实现排序
127.0.0.1:6379> zadd salary 2500 xiaohong 5000 zhangsan 500 lisi
(integer) 3
127.0.0.1:6379> zrangebyscore salary -inf +inf # 显示全部用户,根据score值 递增排序
- “lisi”
- “xiaohong”
- “zhangsan”
127.0.0.1:6379> zrangebyscore salary -inf +inf withscores # 显示全部用户,根据score值 递增排序,同时显示score值 - “lisi”
- “500”
- “xiaohong”
- “2500”
- “zhangsan”
- “5000”
127.0.0.1:6379> zrevrangebyscore salary +inf -inf withscores # 显示全部用户,根据score值 递减排序,同时显示score值 - “zhangsan”
- “5000”
- “xiaohong”
- “2500”
- “lisi”
- “500”
####################################################################################
删除元素
127.0.0.1:6379> zrange salary 0 -1 # 这里可以注意到当输出全部元素时,默认是根据score升序输出的
- “lisi”
- “xiaohong”
- “zhangsan”
127.0.0.1:6379> zrem salary lisi
(integer) 1
127.0.0.1:6379> zrange salary 0 -1 - “xiaohong”
- “zhangsan”
127.0.0.1:6379>
####################################################################################
获取集合大小
127.0.0.1:6379> zcard salary
(integer) 2
127.0.0.1:6379>
####################################################################################
获取集合中指定score区间的元素个数
127.0.0.1:6379> zadd animals 1 tiger 2 monkey 3 donkey 4 mouse 5 cat 6 dog
(integer) 6
127.0.0.1:6379> zrange animals 0 -1 withscores
- “tiger”
- “1”
- “monkey”
- “2”
- “donkey”
- “3”
- “mouse”
- “4”
- “cat”
- “5”
- “dog”
- “6”
127.0.0.1:6379> zcount animals 2 5
(integer) 4
127.0.0.1:6379>
应用场景:
- 存储班级成绩表(使用唯一id与score绑定)
- 对工资表进行排序(使用唯一id与score绑定)
- 消息权重
- 普通消息
- 重要消息
- 排行榜(取TOP N)
2.三大特殊数据类型
1.geospatial(地理位置)
定位 附近的人 打车距离 …
Redis的Geo支持这些功能的实现
可以推算地理位置的信息,两地之间的距离,方圆几公里内的人…
只有6个命令
####################################################################################
geoadd 添加地理位置
规则:两极无法直接添加,我们一般会下载城市数据,直接通过java程序一次性导入!
有效的经度从-180° 到 180°
有效的纬度从-85.05112878° 到 85.05112878°
geoadd key 值(经度 纬度 名称)
127.0.0.1:6379> geoadd china:city 120.2155 30.2530 hangzhou
(integer) 1
127.0.0.1:6379> geoadd china:city 116.3329 39.8926 beijing
(integer) 1
127.0.0.1:6379> geoadd china:city 106.5404 29.4026 chongqing
(integer) 1
127.0.0.1:6379> geoadd china:city 121.4894 31.4052 shanghai
(integer) 1
127.0.0.1:6379> geoadd china:city 113.8803 22.5532 shenzhen
(integer) 1
127.0.0.1:6379> geoadd china:city 108.9342 34.2305 xian 121.5255 38.9522 dalian
(integer) 2
127.0.0.1:6379>
####################################################################################
geopos 获取地理位置具体的经度和纬度 (获得当前定位,得到一个坐标值)
127.0.0.1:6379> geopos china:city beijing
- “116.33290082216262817”
- “39.89260124060681534”
127.0.0.1:6379> geopos china:city hangzhou - “120.21550029516220093”
- “30.25300090777527373”
127.0.0.1:6379>
####################################################################################
geodist 获取两个位置之间的距离,可以指定单位
- m 表示单位为米
- km 表示单位为千米
- mi 表示单位为英里
- ft 表示单位为英尺
127.0.0.1:6379> geodist china:city beijing shanghai km # 查看上海到北京的直线距离
“1052.2966”
127.0.0.1:6379> geodist china:city beijing chongqing km # 查看重庆到北京的直线距离
“1469.0513”
127.0.0.1:6379>
####################################################################################
georadius 以给定位置的经度纬度为中心,找出给定半径内的所有位置
127.0.0.1:6379> georadius china:city 110 30 1000 km
- “chongqing”
- “xian”
- “shenzhen”
- “hangzhou”
127.0.0.1:6379> georadius china:city 110 30 500 km - “chongqing”
- “xian”
127.0.0.1:6379> georadius china:city 110 30 1000 km withcoord withdist count 2 # count限制查询出的个数 - “chongqing”
- “340.7691” # 到中心位置的直线距离 withdist
- “106.54040247201919556” # 显示出经纬度 withcoord
- “29.40259942409589655”
- “xian”
- “481.1256”
- “108.93419891595840454”
- “34.23050055933691027”
127.0.0.1:6379>
####################################################################################
georadiusbymember 以给定位置为中心,找出给定半径内的所有位置(包括自己)
127.0.0.1:6379> georadiusbymember china:city shanghai 400 km
- “hangzhou”
- “shanghai”
127.0.0.1:6379>
####################################################################################
geohash 返回指定一个或多个位置的 Geohash表示
本命令将返回11个字符的Geohash字符串(将二维的经纬度转换为一维的字符串,如果两个字符串越接近,则距离越接近)
127.0.0.1:6379> geohash china:city beijing shanghai
- “wx4dznpp1p0”
- “wtw6st1us10”
127.0.0.1:6379>
GEO 底层的实现原理其实就是Zset,因此我们可以直接使用Zset命令来操作GEO
127.0.0.1:6379> zrange china:city 0 -1
- “chongqing”
- “xian”
- “shenzhen”
- “hangzhou”
- “shanghai”
- “beijing”
- “dalian”
127.0.0.1:6379> zrem china:city beijing
(integer) 1
127.0.0.1:6379> zrange china:city 0 -1- “chongqing”
- “xian”
- “shenzhen”
- “hangzhou”
- “shanghai”
- “dalian”
127.0.0.1:6379>
2.hyperloglog
- 什么是基数?
A{1,3,5,7,8, 9,7}
基数就是指集合中重复的元素个数,比如这个例子中,基数为5。基数可以接受误差!
Redis Hyperloglog 是进行基数统计的算法,提供了一种不精确的去重计数方案,错误率 0.81%。
- 优点:在输入元素的数量或者体积非常大时,计算计数所需的空间总是固定的,并且是很小的。在redis里面,每个Hyperloglog键只需要花费12kb内存,就可以计算接近2 ^ 64 个不同元素的基数。
- 实际案例
网页的UV(一个人可以访问一个网站多次,但是依然算作一个人)
传统的方式,使用set保存用户的id,然后就可以统计set中的元素数量作为标准判断!
这个方式如果保存大量的用户id,就会比较麻烦!然而我们的目的是为了计数,而不是真正保存用户id
- 如果允许容错,那么推荐使用Hyperloglog
- 如果不允许容错,那么使用set或者自己的数据类型
####################################################################################
添加元素 pfadd
统计元素基数 pfcount
合并两个键建立新键 pfmerge
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> pfadd key1 a b c d e f g h i j
(integer) 1
127.0.0.1:6379> pfadd key2 f g h i j k l m n o
(integer) 1
127.0.0.1:6379> pfcount key1
(integer) 10
127.0.0.1:6379> pfcount key2
(integer) 10
127.0.0.1:6379> pfmerge key key1 key2
OK
127.0.0.1:6379> pfcount key
(integer) 15
127.0.0.1:6379>
3.bitmaps
使用位存储 000000111111 只要是只有两个状态的,都可以使用bitmaps
可以用来:
- 统计用户 活跃 不活跃
- 登录 未登录
- 打卡 未打卡
bitmaps是一种数据结构,操作二进制位进行记录,只有 0 和 1 两个状态!
####################################################################################
记录周一到周日是否打卡
127.0.0.1:6379> setbit sign 0 1
(integer) 0
127.0.0.1:6379> setbit sign 1 0
(integer) 0
127.0.0.1:6379> setbit sign 2 1
(integer) 0
127.0.0.1:6379> setbit sign 3 1
(integer) 0
127.0.0.1:6379> setbit sign 4 0
(integer) 0
127.0.0.1:6379> setbit sign 5 1
(integer) 0
127.0.0.1:6379> setbit sign 6 1
(integer) 0
127.0.0.1:6379>
####################################################################################
查看某一天是否打卡
127.0.0.1:6379> getbit sign 3
(integer) 1
127.0.0.1:6379> getbit sign 4
(integer) 0
127.0.0.1:6379>
####################################################################################
查看总有有多少天打卡 可自定义区间,如果不写就是默认全部区间
需要注意的是这里的自定义区间是以字节(byte)为单位的,而我们bitmap中存储的数据是以位(bit)为单位的,1 byte = 8 bit
127.0.0.1:6379> bitcount sign
(integer) 5
3.redis的事务
原子性:要么同时成功,要么同时失败
redis中单条命令保证原子性,但是redis的事务是不保证原子性的。
redis事务的本质是一组命令的集合。一个事务中的所有命令都会被序列化,在事务执行过程中,会按照顺序执行。
特性:
- 一次性
- 顺序性
- 排他性
redis事务没有隔离级别的概念:所有的命令在事务中并没有直接被执行,只有在发起执行命令的时候才会执行。
redis事务的执行流程
- 开启事务 multi
- 命令入队 …
- 执行事务 exec
正常执行事务
####################################################################################
开启事务 multi
命令入队 …
执行事务 exec
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> get k2
QUEUED
127.0.0.1:6379> set k3 v3
QUEUED
127.0.0.1:6379> exec
- OK
- OK
- “v2”
- OK
中途放弃事务
####################################################################################
放弃事务 discard 一旦放弃事务,当前事务队列中的所有命令均不会被执行
127.0.0.1:6379> keys *
- “k3”
- “k1”
- “k2”
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k4 v4
QUEUED
127.0.0.1:6379> set k5 v5
QUEUED
127.0.0.1:6379> discard
OK
127.0.0.1:6379> keys * - “k3”
- “k1”
- “k2”
127.0.0.1:6379>
遇到异常
- 编译型异常(代码有问题,命令有错) – 事务中所有的命令都不会被执行
- 运行时异常(比如说遇到 1 / 0 ) – 如果事务队列中存在语法异常,那么执行命令的时候,错误命令抛出异常 其他命令正常执行
4.redis的监控
1.悲观锁
- 很悲观,认为什么时候都会出问题,无论做什么都会加锁
2.乐观锁
- 很乐观,认为什么时候都不会出问题,所以不会加锁!更新数据的时候会判断一下version,在此期间是否有人修改过这个数据。
- 获取version
- 更新的时候会比较version
上述是乐观锁和悲观锁的原理简介,下面测试redis如何实现监控
使用watch实现redis的乐观锁操作
正常执行成功
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> set money 100
OK
127.0.0.1:6379> set out 0
OK
127.0.0.1:6379> watch money # 监视money对象
OK
127.0.0.1:6379> multi # 事务正常结束,期间数据没有发生变动,这个时候就正常执行成功
OK
127.0.0.1:6379> decrby money 20
QUEUED
127.0.0.1:6379> incrby out 20
QUEUED
127.0.0.1:6379> exec
- (integer) 80
- (integer) 20
127.0.0.1:6379>
多线程下其他线程修改了队列中的值,则事务执行失败。
线程1
127.0.0.1:6379> watch money
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> decrby money 20
QUEUED
127.0.0.1:6379> incrby out 20
QUEUED
127.0.0.1:6379> exec # 执行之前另外一个线程修改了事务队列中的值,这个时候事务执行失败
(nil)
127.0.0.1:6379>
线程2
127.0.0.1:6379> set money 1000
OK
127.0.0.1:6379>
5.Jedis
使用java来操作redis
Jedis 是 Redis官方推荐的java连接开发工具 使用java 操作Redis中间件
如果使用java操作redis,那么一定要对jedis十分熟悉。
1.在IDEA中连接阿里云服务器端redis
新建maven项目,在pom中导入
redis.clients jedis 4.2.2 com.alibaba fastjson 1.2.76新建java文件,测试是否redis是否能ping成功
public class TestPing {
public static void main(String[] args) {
//1. new Jedis对象
Jedis jedis = new Jedis(“自己服务器公网ip”,7521); //这里7521是自己redis.conf配置文件中的自定义redis端口
jedis.auth(“自己服务器端redis的密码”);
//2.测试
System.out.println(jedis.ping());
}
}
连接成功
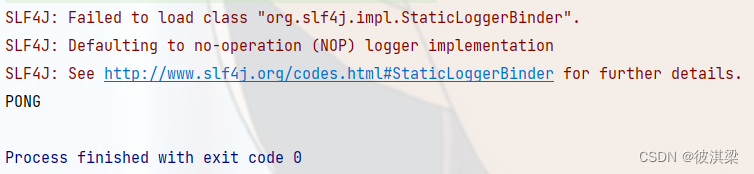
解决slf4j错误提示,在pom中导入如下日志依赖即可解决。
log4j log4j 1.2.17 org.slf4j slf4j-api 2.0.0-alpha7 org.slf4j slf4j-log4j12 2.0.0-alpha7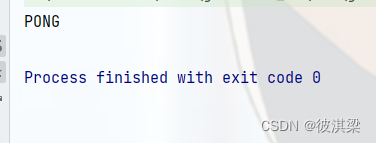
2.常用API
1.key
System.out.println(“清空数据:”+jedis.flushDB());
System.out.println(“判断某个键是否存在:”+jedis.exists(“username”));
System.out.println(“新增<‘username’,‘kuangshen’>的键值对:”+jedis.set(“username”, “kuangshen”));
System.out.println(“新增<‘password’,‘password’>的键值对:”+jedis.set(“password”, “password”));
System.out.print(“系统中所有的键如下:”);
Set keys = jedis.keys(“*”);
System.out.println(keys);
System.out.println(“删除键password:”+jedis.del(“password”));
System.out.println(“判断键password是否存在:”+jedis.exists(“password”));
System.out.println(“查看键username所存储的值的类型:”+jedis.type(“username”));
System.out.println(“随机返回key空间的一个:”+jedis.randomKey());
System.out.println(“重命名key:”+jedis.rename(“username”,“name”));
System.out.println(“取出改后的name:”+jedis.get(“name”));
System.out.println(“按索引查询:”+jedis.select(0));
System.out.println(“删除当前选择数据库中的所有key:”+jedis.flushDB());
System.out.println(“返回当前数据库中key的数目:”+jedis.dbSize());
System.out.println(“删除所有数据库中的所有key:”+jedis.flushAll());
2.String
jedis.flushDB();
System.out.println(“=增加数据=”);
System.out.println(jedis.set(“key1”,“value1”));
System.out.println(jedis.set(“key2”,“value2”));
System.out.println(jedis.set(“key3”, “value3”));
System.out.println(“删除键key2:”+jedis.del(“key2”));
System.out.println(“获取键key2:”+jedis.get(“key2”));
System.out.println(“修改key1:”+jedis.set(“key1”, “value1Changed”));
System.out.println(“获取key1的值:”+jedis.get(“key1”));
System.out.println(“在key3后面加入值:”+jedis.append(“key3”, “End”));
System.out.println(“key3的值:”+jedis.get(“key3”));
System.out.println(“增加多个键值对:”+jedis.mset(“key01”,“value01”,“key02”,“value02”,“key03”,“value03”));
System.out.println(“获取多个键值对:”+jedis.mget(“key01”,“key02”,“key03”));
System.out.println(“获取多个键值对:”+jedis.mget(“key01”,“key02”,“key03”,“key04”));
System.out.println(“删除多个键值对:”+jedis.del(“key01”,“key02”));
System.out.println(“获取多个键值对:”+jedis.mget(“key01”,“key02”,“key03”));
jedis.flushDB();
System.out.println(“=新增键值对防止覆盖原先值====”);
System.out.println(jedis.setnx(“key1”, “value1”));
System.out.println(jedis.setnx(“key2”, “value2”));
System.out.println(jedis.setnx(“key2”, “value2-new”));
System.out.println(jedis.get(“key1”));
System.out.println(jedis.get(“key2”));
System.out.println(“=新增键值对并设置有效时间===”);
System.out.println(jedis.setex(“key3”, 2, “value3”));
System.out.println(jedis.get(“key3”));
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(jedis.get(“key3”));
System.out.println(“=获取原值,更新为新值”);
System.out.println(jedis.getSet(“key2”, “key2GetSet”));
System.out.println(jedis.get(“key2”));
System.out.println(“获得key2的值的字串:”+jedis.getrange(“key2”, 2, 4));
3.List
jedis.flushDB();
System.out.println(“=添加一个list=”);
jedis.lpush(“collections”, “ArrayList”, “Vector”, “Stack”,“HashMap”, “WeakHashMap”, “LinkedHashMap”);
jedis.lpush(“collections”, “HashSet”);
jedis.lpush(“collections”, “TreeSet”);
jedis.lpush(“collections”, “TreeMap”);
jedis.lpush(“collections”, “HashMap”);
//-1代表倒数第一个元素,-2代表倒数第二个元素,end为-1表示查询全部
System.out.println(“collections的内容:”+jedis.lrange(“collections”, 0, -1));
System.out.println(“collections区间0-3的元素:”+jedis.lrange(“collections”,0,3));
System.out.println(“=“);
// 删除列表指定的值 ,第二个参数为删除的个数(有重复时),后add进去的值先被删,类似于出栈
System.out.println(“删除指定元素个数:”+jedis.lrem(“collections”, 2, “HashMap”));
System.out.println(“collections的内容:”+jedis.lrange(“collections”, 0, -1));
System.out.println(“删除下表0-3区间之外的元素:”+jedis.ltrim(“collections”, 0, 3));
System.out.println(“collections的内容:”+jedis.lrange(“collections”, 0, -1));
System.out.println(“collections列表出栈(左端):”+jedis.lpop(“collections”));
System.out.println(“collections的内容:”+jedis.lrange(“collections”, 0, -1));
System.out.println(“collections添加元素,从列表右端,与lpush相对应:”+jedis.rpush(“collections”, “EnumMap”));
System.out.println(“collections的内容:”+jedis.lrange(“collections”, 0, -1));
System.out.println(“collections列表出栈(右端):”+jedis.rpop(“collections”));
System.out.println(“collections的内容:”+jedis.lrange(“collections”, 0, -1));
System.out.println(“修改collections指定下标1的内容:”+jedis.lset(“collections”, 1, “LinkedArrayList”));
System.out.println(“collections的内容:”+jedis.lrange(“collections”, 0, -1));
System.out.println(”=”);
System.out.println(“collections的长度:”+jedis.llen(“collections”));
System.out.println(“获取collections下标为2的元素:”+jedis.lindex(“collections”, 2));
System.out.println(“===============================”);
jedis.lpush(“sortedList”, “3”,“6”,“2”,“0”,“7”,“4”);
System.out.println(“sortedList排序前:”+jedis.lrange(“sortedList”, 0, -1));
System.out.println(jedis.sort(“sortedList”));
System.out.println(“sortedList排序后:”+jedis.lrange(“sortedList”, 0, -1));
4.Set
System.out.println(“向集合中添加元素(不重复)”);
System.out.println(jedis.sadd(“eleSet”, “e1”,“e2”,“e4”,“e3”,“e0”,“e8”,“e7”,“e5”));
System.out.println(jedis.sadd(“eleSet”, “e6”));
System.out.println(jedis.sadd(“eleSet”, “e6”));
System.out.println(“eleSet的所有元素为:”+jedis.smembers(“eleSet”));
System.out.println(“删除一个元素e0:”+jedis.srem(“eleSet”, “e0”));
System.out.println(“eleSet的所有元素为:”+jedis.smembers(“eleSet”));
System.out.println(“删除两个元素e7和e6:”+jedis.srem(“eleSet”, “e7”,“e6”));
System.out.println(“eleSet的所有元素为:”+jedis.smembers(“eleSet”));
System.out.println(“随机的移除集合中的一个元素:”+jedis.spop(“eleSet”));
System.out.println(“随机的移除集合中的一个元素:”+jedis.spop(“eleSet”));
System.out.println(“eleSet的所有元素为:”+jedis.smembers(“eleSet”));
System.out.println(“eleSet中包含元素的个数:”+jedis.scard(“eleSet”));
System.out.println(“e3是否在eleSet中:”+jedis.sismember(“eleSet”, “e3”));
System.out.println(“e1是否在eleSet中:”+jedis.sismember(“eleSet”, “e1”));
System.out.println(“e1是否在eleSet中:”+jedis.sismember(“eleSet”, “e5”));
System.out.println(“=============================");
System.out.println(jedis.sadd(“eleSet1”, “e1”,“e2”,“e4”,“e3”,“e0”,“e8”,“e7”,“e5”));
System.out.println(jedis.sadd(“eleSet2”, “e1”,“e2”,“e4”,“e3”,“e0”,“e8”));
System.out.println(“将eleSet1中删除e1并存入eleSet3中:”+jedis.smove(“eleSet1”, “eleSet3”, “e1”));//移到集合元素
System.out.println(“将eleSet1中删除e2并存入eleSet3中:”+jedis.smove(“eleSet1”, “eleSet3”, “e2”));
System.out.println(“eleSet1中的元素:”+jedis.smembers(“eleSet1”));
System.out.println(“eleSet3中的元素:”+jedis.smembers(“eleSet3”));
System.out.println("集合运算=”);
System.out.println(“eleSet1中的元素:”+jedis.smembers(“eleSet1”));
System.out.println(“eleSet2中的元素:”+jedis.smembers(“eleSet2”));
System.out.println(“eleSet1和eleSet2的交集:”+jedis.sinter(“eleSet1”,“eleSet2”));
System.out.println(“eleSet1和eleSet2的并集:”+jedis.sunion(“eleSet1”,“eleSet2”));
System.out.println(“eleSet1和eleSet2的差集:”+jedis.sdiff(“eleSet1”,“eleSet2”));//eleSet1中有,eleSet2中没有
jedis.sinterstore(“eleSet4”,“eleSet1”,“eleSet2”);//求交集并将交集保存到dstkey的集合
System.out.println(“eleSet4中的元素:”+jedis.smembers(“eleSet4”));
5.Hash
jedis.flushDB();
Map<String,String> map = new HashMap<String, String>();
map.put(“key1”,“value1”);
map.put(“key2”,“value2”);
map.put(“key3”,“value3”);
map.put(“key4”,“value4”);
//添加名称为hash(key)的hash元素
jedis.hmset(“hash”,map);
//向名称为hash的hash中添加key为key5,value为value5元素
jedis.hset(“hash”, “key5”, “value5”);
System.out.println(“散列hash的所有键值对为:”+jedis.hgetAll(“hash”));//return Map<String,String>
System.out.println(“散列hash的所有键为:”+jedis.hkeys(“hash”));//return Set
System.out.println(“散列hash的所有值为:”+jedis.hvals(“hash”));//return List
System.out.println(“将key6保存的值加上一个整数,如果key6不存在则添加key6:”+jedis.hincrBy(“hash”, “key6”, 6));
System.out.println(“散列hash的所有键值对为:”+jedis.hgetAll(“hash”));
System.out.println(“将key6保存的值加上一个整数,如果key6不存在则添加key6:”+jedis.hincrBy(“hash”, “key6”, 3));
System.out.println(“散列hash的所有键值对为:”+jedis.hgetAll(“hash”));
System.out.println(“删除一个或者多个键值对:”+jedis.hdel(“hash”, “key2”));
System.out.println(“散列hash的所有键值对为:”+jedis.hgetAll(“hash”));
System.out.println(“散列hash中键值对的个数:”+jedis.hlen(“hash”));
System.out.println(“判断hash中是否存在key2:”+jedis.hexists(“hash”,“key2”));
System.out.println(“判断hash中是否存在key3:”+jedis.hexists(“hash”,“key3”));
System.out.println(“获取hash中的值:”+jedis.hmget(“hash”,“key3”));
System.out.println(“获取hash中的值:”+jedis.hmget(“hash”,“key3”,“key4”));
3.事务
jedis.flushDB();
JSONObject jsonObject = new JSONObject();
jsonObject.put(“hello”,“world”);
jsonObject.put(“name”,“bingbing”);
String result = jsonObject.toJSONString();
//开启事务
Transaction multi = jedis.multi();
//乐观锁
// multi.watch(result);
try {
multi.set(“user1”,result);
multi.set(“user2”,result);
//成功则执行事务
multi.exec();
}catch (Exception e){
//失败则放弃事务
multi.discard();
e.printStackTrace();
}finally {
System.out.println(jedis.get(“user1”));
System.out.println(jedis.get(“user2”));
jedis.close();//关闭连接
}
6.springboot整合redis
springboot通过springdata操作数据 如 jpa jdbc mongodb redis
springdata也是和springboot齐名的项目!
在springboot 2.x版本之后,原来使用的 jedis 被替换为了 lettuce
- jedis 采用的直连,多个线程操作的话,是不安全的,如果想要避免不安全,需要使用jedis pool连接池 --BIO模式
- lettuce 采用的netty。实例可以在多个线程中进行共享,不存在线程不安全的情况!可以减少线程数量 --NIO模式
源码分析
@Bean
@ConditionalOnMissingBean( // 这里表明我们可以自己定义一个 redisTemplate来替换这个默认的
name = {“redisTemplate”}
)
@ConditionalOnSingleCandidate(RedisConnectionFactory.class)
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
// 默认的 RedisTemplate 没有过多的设置,redis对象都是需要序列化的!
// 两个泛型都是 Object, Object , 我们后续使用需要进行强制转换 String,Object
RedisTemplate<Object, Object> template = new RedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
@Bean
@ConditionalOnMissingBean // 由于String是redis中最常使用的类型,所以单独提出来了一个bean
@ConditionalOnSingleCandidate(RedisConnectionFactory.class)
public StringRedisTemplate stringRedisTemplate(RedisConnectionFactory redisConnectionFactory) {
return new StringRedisTemplate(redisConnectionFactory);
}
整合测试
配置连接
springboot所有的配置类 都有一个自动配置类 RedisAutoConfiguration
自动配置类都会绑定一个properties 配置文件 RedisProperties
spring.redis.host=阿里云公网ip
spring.redis.port=自定义端口
spring.redis.password=redis密码
测试
// 测试类
@Autowired
private RedisTemplate redisTemplate;
@Test
void contextLoads() {
// 在企业开发中,80%的情况下,都不会使用原生的方式去编写代码,因此需要自己编写一个RedisUtil工具类
// redisTemplate 操作不同的数据类型,API和我们的指令是一样的
// opsForValue 操作字符串 类似 String
// opsForList 操作列表 类似 List
// opsForSet 操作集合 类似 Set
// opsForGeo 操作Geo 类似 Geo
// opsForHash opsForZSet opsForHyperLogLog
// redisTemplate.opsForValue();
// redisTemplate.opsForList();
// redisTemplate.opsForSet();
// redisTemplate.opsForGeo();
// redisTemplate.opsForHash();
// redisTemplate.opsForZSet();
// redisTemplate.opsForHyperLogLog();
// 除了基本的操作,我们常用的方法都可以直接通过redisTemplate操作,比如事务和基本的CRUD
// RedisConnection connection = redisTemplate.getConnectionFactory().getConnection();
// connection.flushDb();
redisTemplate.opsForValue().set(“mykey”,“bingbing”);
System.out.println(redisTemplate.opsForValue().get(“mykey”));
}
如果value中包含有中文,则在控制台输出可能会出现乱码
分析出现乱码的原因:
源码中
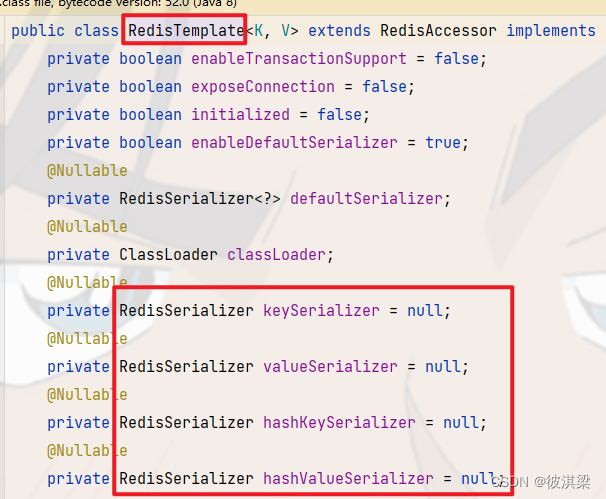
redisTemplate实现序列化配置,默认的序列化方式为jdk序列化,而我们可能会用到json来进行序列化,此时需要自己定义redis的配置类。
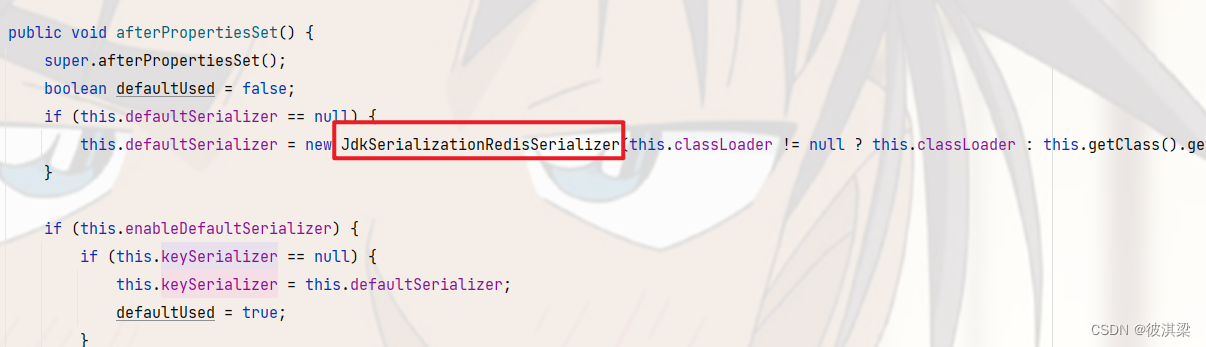
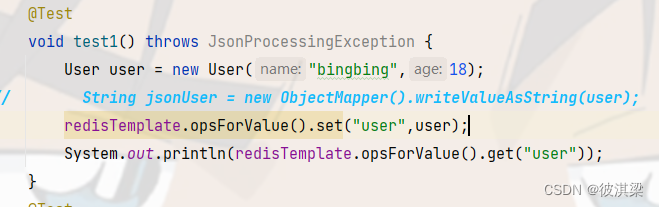
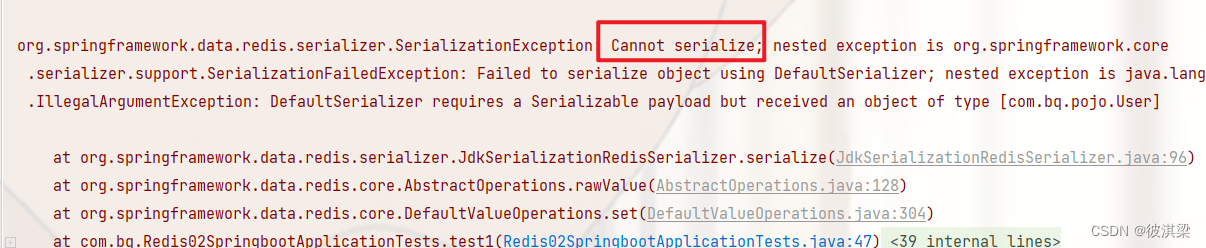
直接传入对象会报错,提示对象没有序列化
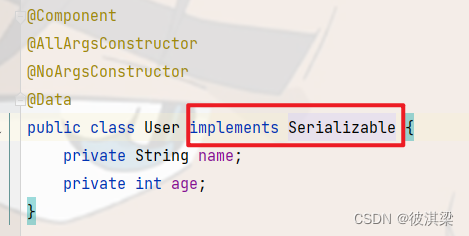
解决方案,将对象实现序列化接口
自定义redis配置类
@Configuration
public class RedisConfig {
//编写我们自己的 redisTemplate,这是一个固定的模板
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
//为了开发方便,一般直接使用 <zString, Object>
RedisTemplate<String, Object> template = new RedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
//Json序列化
Jackson2JsonRedisSerializer objectJackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer<>(Object.class);
//序列化完之后需要进行转义使用
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
objectMapper.activateDefaultTyping(LaissezFaireSubTypeValidator.instance,ObjectMapper.DefaultTyping.NON_FINAL, JsonTypeInfo.As.PROPERTY);
objectJackson2JsonRedisSerializer.setObjectMapper(objectMapper);
//String的序列化
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
//key采用String的序列化方式
template.setKeySerializer(stringRedisSerializer);
//value采用json序列化方式
template.setValueSerializer(objectJackson2JsonRedisSerializer);
//hash的key采用String的序列化方式
template.setHashKeySerializer(stringRedisSerializer);
//hash的value采用json序列化方式
template.setHashValueSerializer(objectJackson2JsonRedisSerializer);
template.afterPropertiesSet();
return template;
}
}
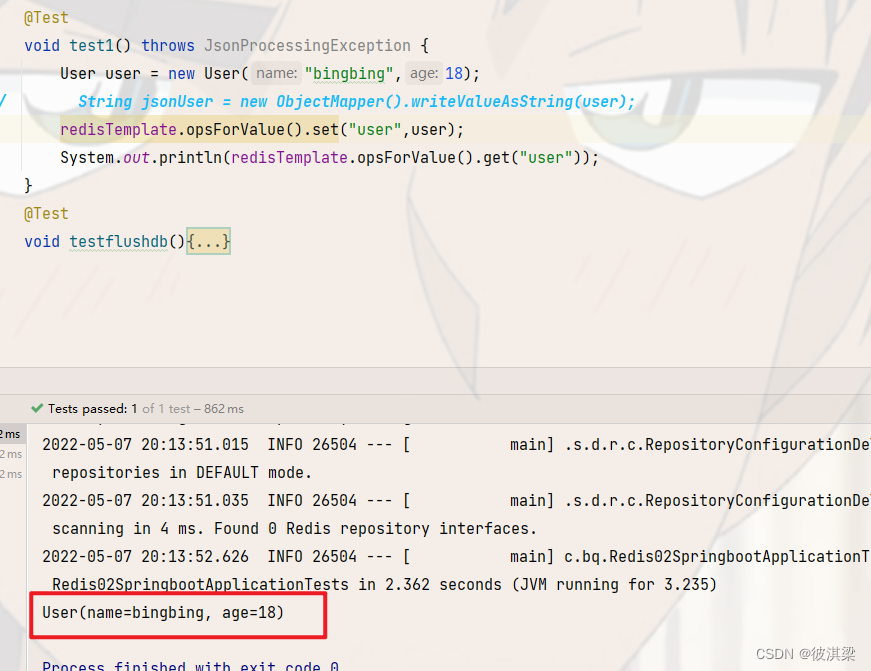
同样是执行上图代码,使用原生jdk序列化和使用自定义redis配置类之后的序列化效果对比
RedisUtils工具类
package com.bq.utils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import org.springframework.util.CollectionUtils;
import java.util.Collection;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.concurrent.TimeUnit;
/**
* @Name: RedisUtil
* @Author: 铁锅炖大鹅
* @Time: 2022/5/7 21:06
* @Version: 1.0
*/
@Component
public final class RedisUtil {
@Autowired
private RedisTemplate<String,Object> redisTemplate;
// common=======
/**
* 指定缓存失效时间
* @param key 键
* @param time 时间
* @return
*/
public boolean expire(String key,long time){
try{
if (time > 0){
redisTemplate.expire(key,time, TimeUnit.SECONDS);
}
return true;
}catch (Exception e){
e.printStackTrace();
return false;
}
}
/**
* 根据 key 获取过期时间
* @param key 键 不能为 null
* @return 返回时间 (以 秒 为单位) 返回0代表永久有效
*/
public long getExpire(String key){
return redisTemplate.getExpire(key,TimeUnit.SECONDS);
}
/**
* 判断 key 是否存在
* @param key 键
* @return 存在返回 true 不存在返回 false
*/
public boolean hasKey(String key){
try{
return redisTemplate.hasKey(key);
}catch (Exception e){
e.printStackTrace();
return false;
}
}
/**
* 删除缓存
* @param key 可以传 一个键 或 多个键
*/
public void del(String… key){
if (key != null && key.length > 0){
if (key.length == 1){
redisTemplate.delete(key[0]);
}else {
redisTemplate.delete((Collection) CollectionUtils.arrayToList(key));
}
}
}
// String=======
/**
* 普通缓存获取
* @param key 键
* @return 值
*/
public Object get(String key){
return key == null ? null : redisTemplate.opsForValue().get(key);
}
/**
* 普通缓存放入
* @param key 键
* @param value 值
* @return 成功返回true 失败返回false
*/
public boolean set(String key,Object value){
try {
redisTemplate.opsForValue().set(key,value);
return true;
}catch (Exception e){
e.printStackTrace();
return false;
}
}
/**
* 普通缓存放入并设置时间
* @param key 键
* @param value 值
* @param time 时间(以秒为单位) time > 0 当time <= 0时将设置无限期
* @return 成功返回 true 失败返回 false
*/
public boolean set(String key,Object value,long time){
try {
if (time > 0){
redisTemplate.opsForValue().set(key,value,time,TimeUnit.SECONDS);
}else {
set(key,value);
}
return true;
}catch (Exception e){
e.printStackTrace();
return false;
}
}
/**
* 递增
* @param key 键
* @param delta 递增步长(大于0)
* @return
*/
public long incr(String key,long delta){
if (delta < 0){
throw new RuntimeException(“递增因子必须大于0!”);
}
return redisTemplate.opsForValue().increment(key,delta);
}
/**
* 递减
* @param key 键
* @param delta 递减步长(大于0)
* @return
*/
public long decr(String key, long delta) {
if (delta < 0) {
throw new RuntimeException(“递减因子必须大于0”);
}
return redisTemplate.opsForValue().increment(key, -delta);
}
// ======Map=
/**
* HashGet
* @param key 键 不能为null
* @param item 项 不能为null
*/
public Object hget(String key, String item) {
return redisTemplate.opsForHash().get(key, item);
}
/**
* 获取hashKey对应的所有键值
* @param key 键
* @return 对应的多个键值
*/
public Map<Object, Object> hmget(String key) {
return redisTemplate.opsForHash().entries(key);
}
/**
* HashSet
* @param key 键
* @param map 对应多个键值
*/
public boolean hmset(String key, Map<String, Object> map) {
try {
redisTemplate.opsForHash().putAll(key, map);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* HashSet 并设置时间
* @param key 键
* @param map 对应多个键值
* @param time 时间(秒)
* @return true成功 false失败
*/
public boolean hmset(String key,Map<String,Object> map,long time){
try {
redisTemplate.opsForHash().putAll(key, map);
if (time > 0) {
expire(key, time);
}
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 向一张hash表中放入数据,如果不存在将创建
*
* @param key 键
* @param item 项
* @param value 值
* @return true 成功 false失败
*/
public boolean hset(String key, String item, Object value) {
try {
redisTemplate.opsForHash().put(key, item, value);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 向一张hash表中放入数据,如果不存在将创建
*
* @param key 键
* @param item 项
* @param value 值
* @param time 时间(秒) 注意:如果已存在的hash表有时间,这里将会替换原有的时间
* @return true 成功 false失败
*/
public boolean hset(String key, String item, Object value, long time) {
try {
redisTemplate.opsForHash().put(key, item, value);
if (time > 0) {
expire(key, time);
}
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 删除hash表中的值
* @param key 键 不能为 null
* @param item 项 可以传入多个 不能为 null
*/
public void hdel(String key, Object… item) {
redisTemplate.opsForHash().delete(key, item);
}
/**
* 判断hash表中是否有该项的值
*
* @param key 键 不能为null
* @param item 项 不能为null
* @return true 存在 false不存在
*/
public boolean hHasKey(String key, String item) {
return redisTemplate.opsForHash().hasKey(key, item);
}
/**
* hash递增 如果不存在,就会创建一个 并把新增后的值返回
*
* @param key 键
* @param item 项
* @param by 要增加几(大于0)
*/
public double hincr(String key, String item, double by) {
return redisTemplate.opsForHash().increment(key, item, by);
}
/**
* hash递减
*
* @param key 键
* @param item 项
* @param by 要减少记(小于0)
*/
public double hdecr(String key, String item, double by) {
return redisTemplate.opsForHash().increment(key, item, -by);
}
// Set=
/**
* 根据key获取Set中的所有值
* @param key 键
*/
public Set sGet(String key) {
try {
return redisTemplate.opsForSet().members(key);
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
/**
* 根据value从一个set中查询,是否存在
*
* @param key 键
* @param value 值
* @return true 存在 false不存在
*/
public boolean sHasKey(String key, Object value) {
try {
return redisTemplate.opsForSet().isMember(key, value);
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 将数据放入set缓存
*
* @param key 键
* @param values 值 可以是多个
* @return 成功个数
*/
public long sSet(String key, Object… values) {
try {
return redisTemplate.opsForSet().add(key, values);
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
/**
* 将set数据放入缓存
*
* @param key 键
* @param time 时间(秒)
* @param values 值 可以是多个
* @return 成功个数
*/
public long sSetAndTime(String key, long time, Object… values) {
try {
Long count = redisTemplate.opsForSet().add(key, values);
if (time > 0)
expire(key, time);
return count;
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
/**
* 获取 set 缓存的长度
* @param key 键
* @return 长度
*/
public long sGetSetSize(String key) {
try {
return redisTemplate.opsForSet().size(key);
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
/**
* 移除值 value
*
* @param key 键
* @param values 值 可以是多个
* @return 移除的个数
*/
public long setRemove(String key, Object… values) {
try {
Long count = redisTemplate.opsForSet().remove(key, values);
return count;
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
// =list===
/**
* 获取list缓存的内容
*
* @param key 键
* @param start 开始
* @param end 结束 0 到 -1代表所有值
*/
public List lGet(String key, long start, long end) {
try {
return redisTemplate.opsForList().range(key, start, end);
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
/**
* 获取list缓存的长度
* @param key 键
* @return 长度
*/
public long lGetListSize(String key){
try {
return redisTemplate.opsForList().size(key);
}catch (Exception e){
e.printStackTrace();
return 0;
}
}
/**
* 通过索引 获取list中的值
* @param key 键
* @param index 索引 index >= 0 时, 0 表头,1 第二个元素,依次类推;index < 0 时,-1,表尾,-2倒数第二个元素,依次类推
*/
public Object lGetIndex(String key, long index) {
try {
return redisTemplate.opsForList().index(key, index);
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
/**
* 将list放入缓存
*
* @param key 键
* @param value 值
*/
public boolean lSet(String key, Object value) {
try {
redisTemplate.opsForList().rightPush(key, value);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 将list放入缓存
* @param key 键
* @param value 值
* @param time 生效时间
* @return
*/
public boolean lSet(String key,Object value,long time){
try {
redisTemplate.opsForList().rightPush(key,value);
if (time > 0){
expire(key,time);
}
return true;
}catch (Exception e){
e.printStackTrace();
return false;
}
}
/**
* 将list放入缓存
*
* @param key 键
* @param value 值
* @return
*/
public boolean lSet(String key, List value) {
try {
redisTemplate.opsForList().rightPushAll(key, value);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 将list放入缓存
*
* @param key 键
* @param value 值
* @param time 时间(秒)
* @return
*/
public boolean lSet(String key, List value, long time) {
try {
redisTemplate.opsForList().rightPushAll(key, value);
if (time > 0)
expire(key, time);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 根据索引修改list中的某条数据
* @param key 键
* @param index 索引
* @param value 值
* @return 成功返回true 失败返回false
*/
public boolean lUpdateIndex(String key,long index,Object value){
try {
redisTemplate.opsForList().set(key,index,value);
return true;
}catch (Exception e){
e.printStackTrace();
return false;
}
}
/**
* 移除N个值value
*
* @param key 键
* @param count 移除多少个
* @param value 值
* @return 移除的个数
*/
public long lRemove(String key, long count, Object value) {
try {
Long remove = redisTemplate.opsForList().remove(key, count, value);
return remove;
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
}
测试示例
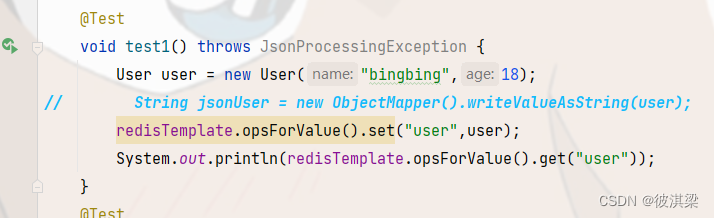
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MQPGFy0u-1652186726338)(Redis.assets/image-20220508174304583.png)]
7.redis.conf文件配置
启动的时候,就是通过这个配置文件来启动!
单位
配置文件 单位 对大小写不敏感
包含
可以导入其他配置文件
网络
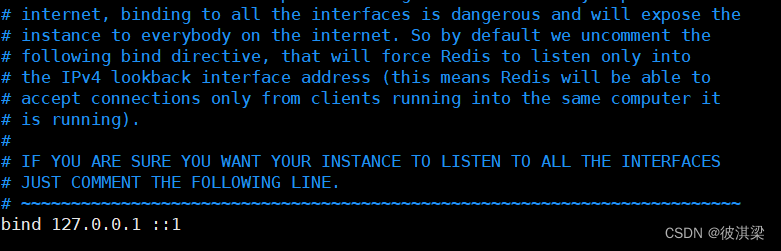
绑定ip
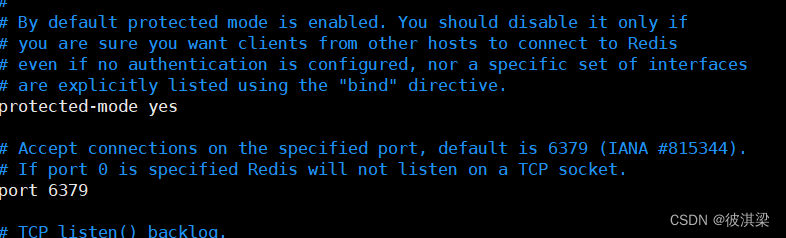
保护模式
端口设置
通用

以守护进程的方式运行,默认是 no ,我们需要自己开启为 yes

如果以后台的方式运行,我们就需要指定一个 pid 文件
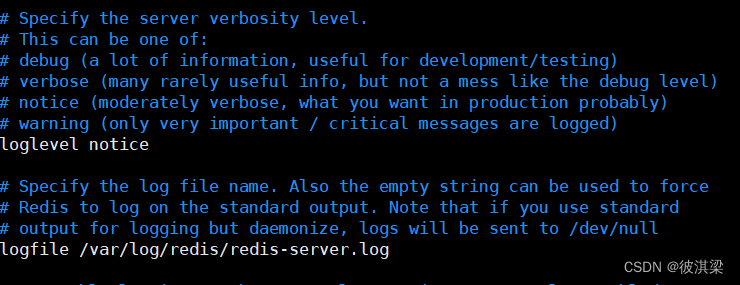
设置日志级别,以及日志的存储位置

设置数据库的数量,默认是 16 个
设置是否总是显示 LOGO
快照
用于数据持久化,即 在规定的时间内,执行了多少次操作之后,会将数据持久化到文件(.rdb .aof)
redis 是内存数据库,如果没有进行持久化,那么数据断电即失!
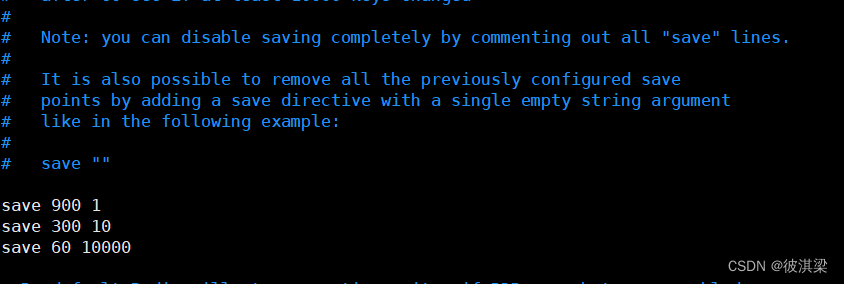
上图默认设置的意思是
如果 900 s 内 至少有 1 个 key 进行了修改,我们就进行数据持久化操作
如果 300 s 内 至少有 10 个 key 进行了修改,我们就进行数据持久化操作
如果 60 s 内 至少有 10000 个 key 进行了修改,我们就进行数据持久化操作
我们之后学习持久化时,会在这里定义自己的数据持久化规则!
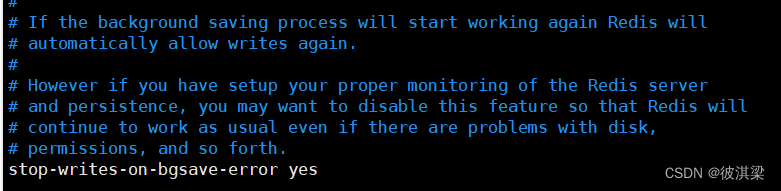
数据持久化过程中出错,是否还需要停止工作 默认为停止工作 即 yes

是否压缩.rdb文件
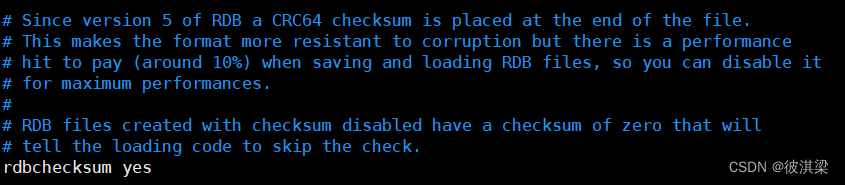
保存 .rdb文件时,进行错误的检查校验
.rdb文件的保存目录
安全
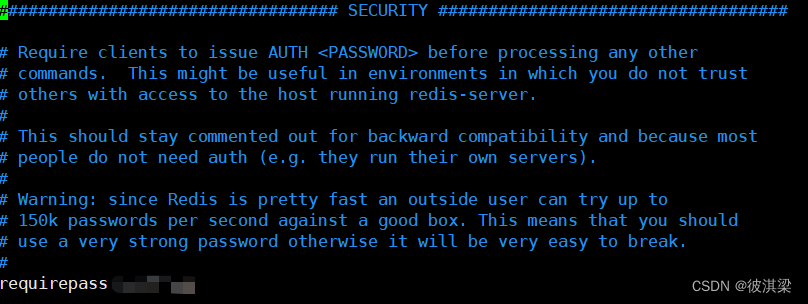
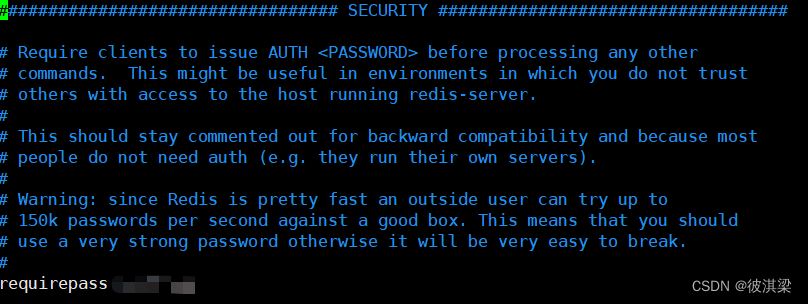
可以在这里设置 redis 的密码,默认是没有密码!
当然密码也可以用过命令来设置
config get requirepass 获取密码
config ser requirepass 设置密码
auth 密码 密码设置过之后在连接redis时需要先加一行这个命令进行登录
限制
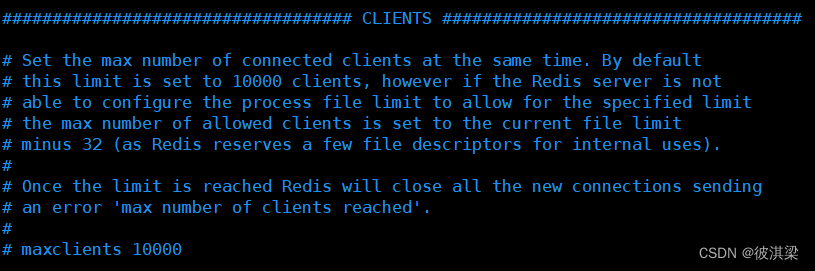
限制最大能连接的客户端数量

限制最大的内存容量
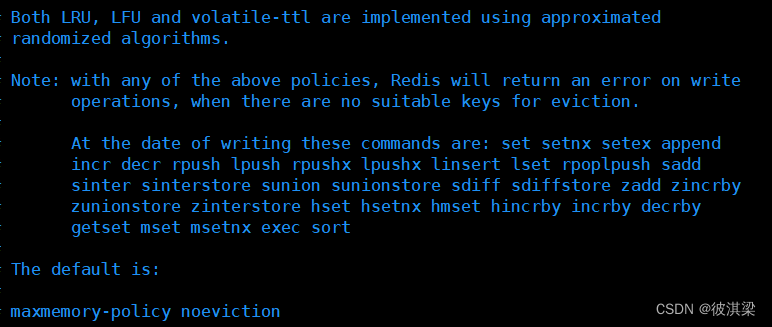
内存到达上限之后的处理策略,共有五种策略

从上到下依次为:
- 只对设置了过期时间的 key 进行 LRU 删除
- 对任意 key 进行 LRU 删除
- 只对删除了过期时间的 key 进行 LFU 删除
- 对任意 key 进行 LFU 删除
- 只对设置了过期时间的 key 进行随机删除
- 对任意 key 进行随机删除
- 永不删除,只返回一个写操作错误
AOF模式
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注软件测试)
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
aof`)
redis 是内存数据库,如果没有进行持久化,那么数据断电即失!
上图默认设置的意思是
如果 900 s 内 至少有 1 个 key 进行了修改,我们就进行数据持久化操作
如果 300 s 内 至少有 10 个 key 进行了修改,我们就进行数据持久化操作
如果 60 s 内 至少有 10000 个 key 进行了修改,我们就进行数据持久化操作
我们之后学习持久化时,会在这里定义自己的数据持久化规则!
数据持久化过程中出错,是否还需要停止工作 默认为停止工作 即 yes
是否压缩.rdb文件
保存 .rdb文件时,进行错误的检查校验
.rdb文件的保存目录
安全
可以在这里设置 redis 的密码,默认是没有密码!
当然密码也可以用过命令来设置
config get requirepass 获取密码
config ser requirepass 设置密码
auth 密码 密码设置过之后在连接redis时需要先加一行这个命令进行登录
限制
限制最大能连接的客户端数量
限制最大的内存容量
内存到达上限之后的处理策略,共有五种策略
从上到下依次为:
- 只对设置了过期时间的 key 进行 LRU 删除
- 对任意 key 进行 LRU 删除
- 只对删除了过期时间的 key 进行 LFU 删除
- 对任意 key 进行 LFU 删除
- 只对设置了过期时间的 key 进行随机删除
- 对任意 key 进行随机删除
- 永不删除,只返回一个写操作错误
AOF模式
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注软件测试)
[外链图片转存中…(img-68qQcWQ6-1713619245222)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
