
阅读量:1
一.引言
近日,浪潮信息联合Intel在IPF大会上发布了可运行千亿参数大模型的AI通用服务器,首次实现了单机通用服务器,即可运行千亿参数大模型。并在发布现场演示了基于NF8260G7服务器进行yuan2.0-102B模型在代码编写、逻辑推理等高难度问题上的实时推理效果,引起了业界广泛的关注。本文将详细解读yuan2.0-102B模型在NF8260G7服务器上进行高效实时推理的原理和技术路径。

二.大模型推理部署难点
提到大模型的推理,大家最先想到的还是以GPU为主的异构加速计算。随着大模型从基础研发走向落地应用,如何构建高效、稳定、易用、低成本的基础设施,是当前业界关注的焦点。相比于异构加速计算,使用AI通用服务器进行大模型推理具有落地成本更低、和已有业务的计算基础设施兼容度更高以及更稳定高效等多方位的优势。
当前,大模型的推理计算主要面临着如下几大方面的挑战,制约着大模型的服务成本和落地应用。
- 1.模型参数量大:大模型的推理过程中,需要在GPU显存中存放全部的模型权重参数,以及计算过程中的KV Cache等数据,一般需要占用模型参数量2-3倍的内存空间。因此部署一个千亿大模型(100B)往往需要200-300GB的GPU显存空间。这超过了当前业界主流的AI加速芯片的显存大小。而随着当前业界的LLM的网络架构从GPT架构走向MOE架构,主流的开源模型的尺寸越来越大,千亿及以上参数的模型成为了主流。
- 2.算力与带宽需求大:大模型的推理主要分为预填充和解码2个阶段。其中预填充阶段把prompt一次性输入给模型进行计算,计算压力更为明显,而在解码阶段,因为每次推理仅生成1个token,计算访存比较低,对内存带宽的压力更为明显。因此,千亿大模型的实时推理,不仅需要计算设备具备较高的计算能力,也需要计算设备具备较高的存储单元到计算单元的数据搬运效率。
三.NF8260G7服务器的特点和优势
相比于异构加速方案,NF8260G7作为一款采用高密度设计的2U4路服务器,支持16TB大内存容量。可以轻松满足千亿大模型推理的内存需求,甚至于万亿参数的MOE架构大模型推理的内存需求。NF8260G7服务器配置了4颗具有AMX(高级矩阵扩展)的AI加速功能的英特尔至强处理器。单机可以达到300TFlops以上的FP16算力。

NF8260G7服务器前视图
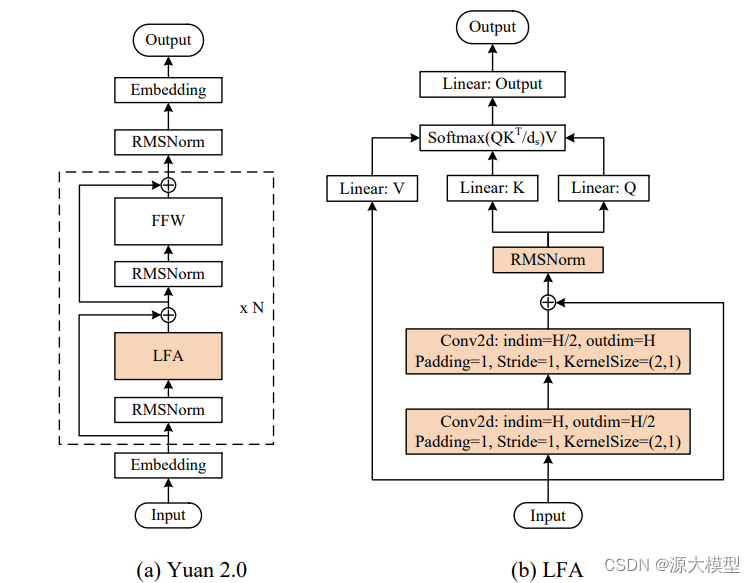
Yuan2.0(源2.0)是浪潮信息在2023年11月发布的新一代基础语言大模型。它包括Yuan2.0-102B、Yuan2.0-51B和Yuan2.0-2B三个模型。在模型架构上,Yuan2.0提出了一种基于本地化过滤的注意力机制(Localized Filtering-based Attention),用于捕捉输入序列的局部依赖关系。相对于传统的全局Attention机制,LFA在前向传播之前引入了两层一维卷积层,以考虑更多的输入信息,从而具有更强的时序性和局部性。另外Yuan2.0通过更多高质量的预训练数据和微调数据集来提升模型的理解能力。
为了尽可能的加速yuan2.0-102B的推理计算效率,我们采用了张量并行(tensor parallel)策略来同时使用NF8260G7服务器中的4颗CPU。张量并行通过把yuan2.0-102B模型中的注意力层和前馈层的矩阵计算分别拆分到多个处理器,来同时使用4颗处理器来进行计算加速。但是,需要提到的是,张量并行策略因为对模型参数的切分粒度较细,会需要处理器在每次张量计算后进行数据同步。这些额外的数据同步,对处理器间的通信带宽,提出了较高的要求。传统在使用多个基于PCIe互联的AI芯片进行张量并行时,通信占比往往会高达50%,也就是AI芯片有50%的时间都在等待数据传输,处于空闲状态,极大的影响了推理效率。相比之下,NF8260G7服务器中的4颗CPU采用了全链路UPI总线互连,通过全链路UPI互连有两个优势:(1)全链路互连可以使得任意两个CPU的通信可以直接进行数据传输,(2)UPI互连的传输速率高,传输速率高达16GT/s。远高于PCIe的通信带宽,从而保障了4颗处理器间高效的数据传输。
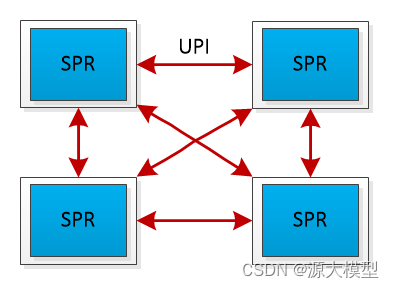
UPI总线互连示意图
四.基于张量并行和NF4量化的模型部署策略
在此基础上,为了进一步加速yuan2.0-102B的推理效率,我们使用了NF4量化技术,来进一步提升推理的解码效率,从而达到实时推理的解码需求。NF4(4位NormalFloat)数据类型属于分位数量化,是一种信息论上对于正态分布数据来说最优的量化数据类型,确保每个量化区间中有相等数量的值来自输入张量。分位数量化通过估计输入张量的分位数来实现,由于LLM模型权重为具有零中心的正态分布,因此可以通过缩放标准差来适应我们的数据类型的范围,其实际量化得到的精度结果比4位整数和4位浮点数(整形和浮点型数据的量化数据间隔呈现平均分布和指数分布,对于描述呈现正态分布的模型权重来说分位数量化描述更精确)更好。INT4数据类型(平均分布)和NF4数据类型(正态分布)对比图如下图所示:
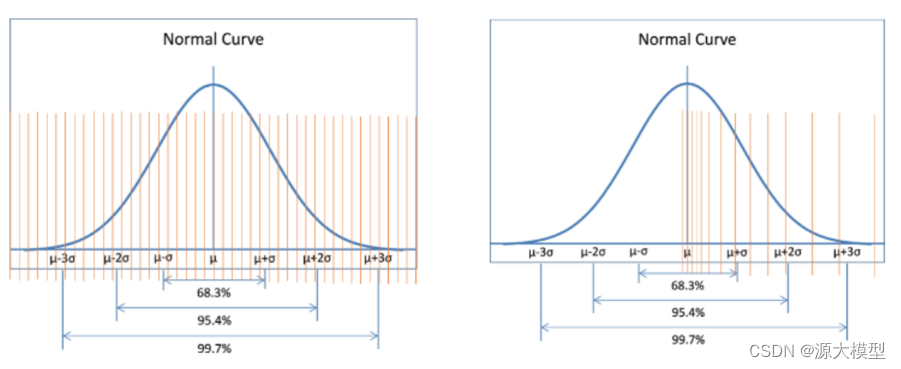
INT4数据类型与NF4数据类型对比
基于NF4,yuan2.0-102B使用了嵌套量化(Double Quant)技术来压缩模型权重参数。嵌套量化为针对NF4量化后进行的二次量化,由于NF4量化后会产生大量的scale参数,由于对于千亿大模型的量化,如果量化后的scale以FP32作为存储的话会占用大量的内存空间,假设以每 64 个参数为做一个 block进行量化(block size=64),则千亿大模型的scale参数存储仍会额外用到的空间大小为:
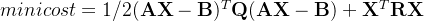
通过将scale参数进行量化到FP8可以将参数进一步减少,存储全部scale的空间仅需要额外增加:
其中二次量化block size=256,在量化后,模型的每个权重参数仅占用4byte的内存空间,从内存到CPU的数据搬运效率提升了4倍。从而大幅减轻了内存带宽对yuan2.0-102B推理的解码效率的制约。
通过张量并行和NF4量化,我们最终在NF8260G7服务器上实现了千亿大模型的实时推理,最终通过张量并行和NF4量化后profiling结果(通过profiling结果,我们可以对服务器在LLM推理中的算子和通信有一个效率占比评估)如下图所示:
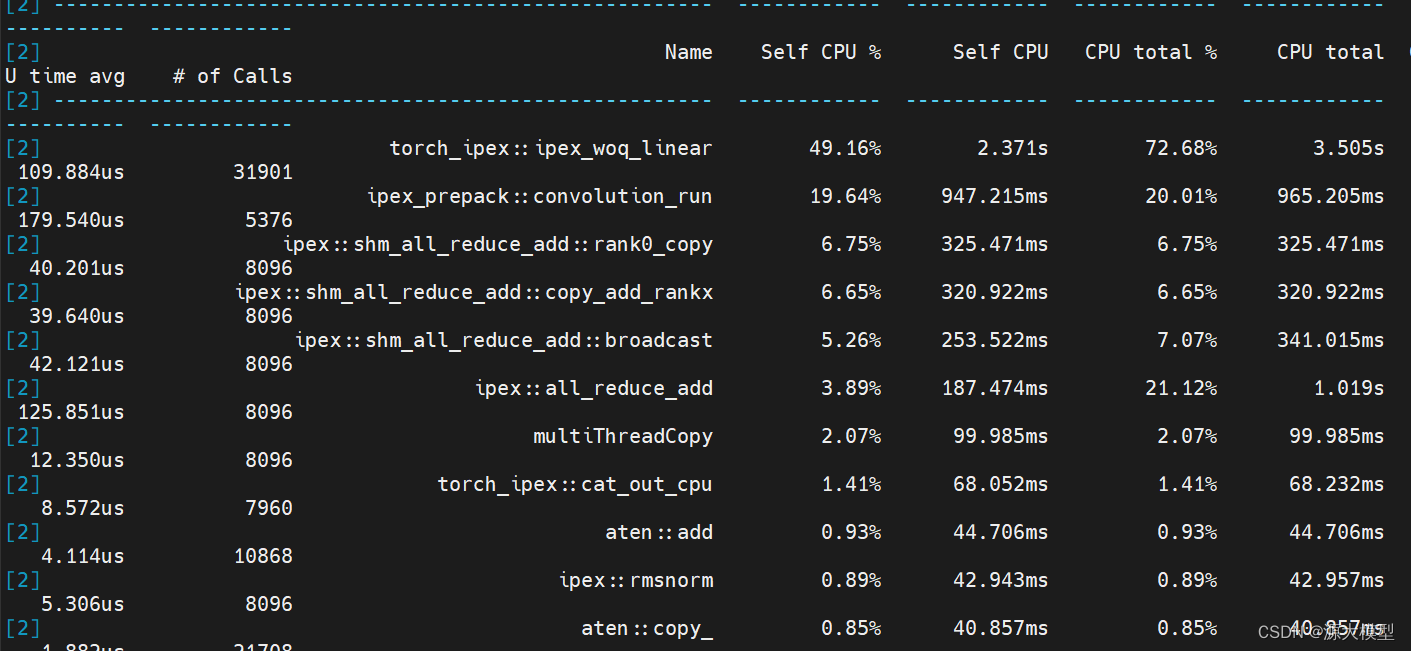
从profiling结果可以看出,其中线性层的运行时间占比50%,卷积运行时间占比20%,聚合通信时间占比20%,其它计算占比10%。
下面是yuan2.0-102B进行实时推理的几个例子。
五.结论
总的来说,如何实现千亿大模型推理是需要进行硬件、软件、模型三个方面进行综合考量的结果。NF8260G7服务器拥有16TB大内存容量和300TFlops以上的FP16算力,能满足千亿大模型推理的内存需求。此外,服务器中的4颗CPU采用了全链路UPI总线互连,传输速率高达16GT/s,保障了高效的数据传输。在此基础上,采用了张量并行策略和NF4量化技术,我们实现了yuan2.0-102B的高效实时推理。为业界构建千亿大模型的高效推理方案提供了新的选择。
更多信息,请访问以下页面
YuanChat Github 项目主页:GitHub - IEIT-Yuan/YuanChat
Yuan 2.0 Github 项目主页:GitHub - IEIT-Yuan/Yuan-2.0: Yuan 2.0 Large Language Model
Yuan 2.0 系列模型Hugging Face 主页:https://huggingface.co/IEITYuan
Yuan 2.0 系列模型Modelscope 主页:魔搭社区
