
阅读量:2
### 3.2 硬盘读写性能测试(filename:待测试路径 HDD硬盘随机读写测试性能一般在4M/s左右) fio -filename=/vdb_data/test_randread -direct=1 -iodepth 1 -thread -rw=randrw -ioengine=psync -bs=4k -size=10G -numjobs=10 -runtime=60 -group_reporting -name=mytest
**参数解释** -filename=/vdb_data/test_randread:指定测试文件的路径和名称为/vdb_data/test_randread。
-direct=1:使用直接I/O模式,即跳过系统缓存,直接读写磁盘。
-iodepth 1:每个作业的I/O深度为1,即每个作业在队列中只有一个I/O请求。
-thread:使用线程模式执行测试任务。
-rw=randrw:使用随机读写模式进行测试,即同时进行随机读和随机写操作。
-ioengine=psync:指定使用psync I/O引擎。
-bs=4k:设置每个I/O请求的块大小为4KB。
-size=10G:指定测试文件的大小为10GB。
-numjobs=10:指定并发作业数为10,即同时执行10个测试任务。
-runtime=60:设置测试运行时间为60秒。
-group_reporting:汇总所有作业的结果报告。
-name=mytest:指定测试任务的名称为mytest,用于标识这个测试任务。
### 3.3 硬盘透传 虚拟机磁盘透传是指将物理主机上的磁盘直接映射给虚拟机使用,而不是通过虚拟机软件(如VMware、VirtualBox)创建虚拟磁盘文件。这样做可以提高性能,减少虚拟化层的开销,适用于一些对性能要求较高的应用场景。 #### 3.3.1 以下是在一些常见虚拟化平台上实现磁盘透传的步骤: **KVM/QEMU**(测试的情况) 1、编辑虚拟机的XML配置文件,添加类似如下的配置: vim /vmimages/passthough-disk.xml
**其中/dev/nvme4n1是要透传的物理磁盘设备。** 2、使用virsh工具重新加载配置文件使更改生效: #挂载透传硬盘
virsh attach-device vm1 /vmimages/passthough-disk.xml
#取消挂载透传硬盘
virsh detach-device vm1 /vmimages/passthough-disk.xml
vm1是虚拟机名
**VMware vSphere/ESXi** 1、在ESXi主机上将物理磁盘添加到存储适配器中。 2、在虚拟机设置中选择添加硬件 - 存储控制器 - 硬盘。 3、选择“使用一个已经存在的磁盘”,然后选择要透传的物理磁盘。 4、完成虚拟机设置并启动虚拟机,系统会识别并挂载透传的物理磁盘。 **Microsoft Hyper-V** 1、在Hyper-V管理器中选择目标虚拟机,右键点击设置。 2、选择添加硬件,然后选择物理硬盘。 3、选择要透传给虚拟机的物理磁盘。 4、完成虚拟机设置并启动虚拟机,系统会识别并挂载透传的物理磁盘。 ### 3.4 挂载内存盘 mount -t tmpfs -o size=40G tmpfs /mnt/tmp/
**-t tmpfs**:指定挂载的是内存盘 **-o size=40G tmpfs**;指定挂载内存盘大小 **开机自动挂载** tmpfs /mnt/tmp/ tmpfs size=40G 0 0
内存盘读写性能测试(去除-direct参数,否则不能运行): fio -filename=/mnt/tmp/test_randread -iodepth 1 -thread -rw=randrw -ioengine=psync -bs=4k -size=2G -numjobs=1 -runtime=600 -group_reporting -name=mytest
### 3.5 隔核测试 1、隔核操作 sudo vim /etc/default/grub
**增加以下内容** 隔核2-79,iommu=pt,intel_iommu=on
GRUB_CMDLINE_LINUX_DEFAULT=“isolcpus=2-79 iommu=pt intel_iommu=on”
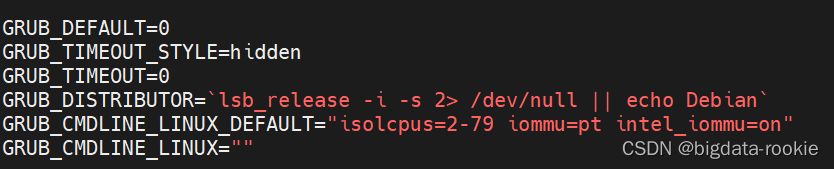 使改动生效 update-grub
reboot
2、指定内核测试磁盘性能 taskset -c 3(指定xx核) fio -filename=/ssd_test/test_randread -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=16k -size=10G -numjobs=1 -runtime=60 -group_reporting -name=mytest
3、给予线程高权限,防止因为out of memory被宿主机kill: ps aux | grep qemu(获取虚拟机得进程id)
echo -1000 > /proc/进程id/oom_score_adj
**占用指定内存空间以达到极限测试效果的程序** def allocate_memory(size_in_gb):
# 分配指定GB数的内存空间
num_bytes = size_in_gb * (1024**3) # 转换GB到字节
try:
# 使用bytearray创建一个大数组
big_array = bytearray(num_bytes)
print(f"Successfully allocated {size_in_gb} GB of memory")
return big_array
except MemoryError:
print(f"Failed to allocate {size_in_gb} GB of memory. Not enough resources.")
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
视频,并且后续会持续更新**
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)
[外链图片转存中…(img-Fxiwf2pK-1712991256350)]
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
