
阅读量:0
我们在学习C语言的时候,都学过内存区域的划分如栈、堆、代码区、数据区这些。但我们其实并不真正理解内存 — 我们之前一直说的内存是物理上的内存吗?
前言
我们先看一段测试代码:
#include <stdio.h> #include <assert.h> #include <unistd.h> int g_value = 100; //全局变量 int main() { // fork在返回的时候,父子都有了,return两次,id是不是pid_t类型定义的变量呢?返回的本质,就是写入! // 谁先返回,谁就让OS发生写时拷贝 pid_t id = fork(); assert(id >= 0); if(id == 0) { //child while(1) { printf("我是子进程, 我的id是: %d, 我的父进程是: %d, g_value: %d, &g_value : %p\n",\ getpid(), getppid(), g_value, &g_value); sleep(1); g_value=200; // 只有子进程会进行修改 } } else { //father while(1) { printf("我是父进程, 我的id是: %d, 我的父进程是: %d, g_value: %d, &g_value : %p\n",\ getpid(), getppid(), g_value, &g_value); sleep(1); } } } 运行结果:
我们可以注意到子进程的变量值内容发生了改变,而父进程的变量值内容一直没有发生改变,并且两个进程的全局变量打印出来的地址值是一样的。
那这地址到底是不是真的物理地址?
== 当然不能是,如果是同一个物理地址,不可能读取同一个变量会读取到不同的数值 。==
从上面结果我们可以得出: 子进程对全局变量数据修改,不影响父进程 - — 进程具有独立性 也就是说,我们在语言层面用的地址,不是物理地址。
所以我们之前说‘程序的地址空间’是不准确的,那准确的说这是什么地址呢?
我们一般叫:虚拟地址或者线性地址
我们在用C/C++语言所看到的地址,全部都是虚拟地址!物理地址,用户一概看不到,由OS统一管理。OS必须负责将 虚拟地址 转化成 物理地址 。
理解进程地址空间
通过故事引入
我们知道操作系统会帮助我们用于管理计算机硬件和软件资源.假设操作系统是个大富翁,手底下有10个亿的内存,大富翁同时有四个私生子,四个分别从事不同的活动,彼此不知道互相的存在(对应进程的独立性),在大富翁老去时,会将自己的财产继承给私生子,那么由于每个私生子彼此不知道存在,大富翁让每个私生子都会以为自己可以继承10个亿的财产(画的大饼),是孩子就总会有给老爹要钱的时候,那么为了管理自己的10个亿财产,大富翁很有必要将其描述组织起来,以供自己四个彼此独立的私生子使用。
那么大富翁(操作系统)将画的大饼先描述,在组织,其实就是管理进程地址空间的过程 ---- 本质就是:一个内核数据结构,struct mm_struct{ }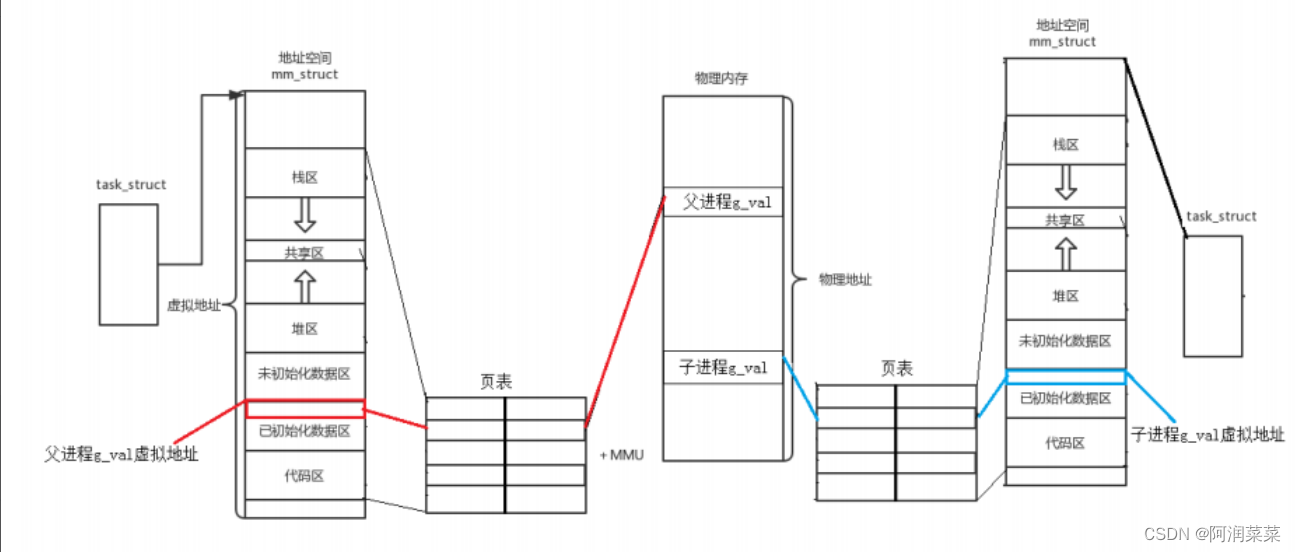
现在我们知道了地址空间就是内核数据结构 ---- 那它是怎么对应物理内存的?
先来看一下地址空间是怎么划分的:
代码区、数据区、堆区等这些区域如何理解?
在我们小学的时候可能会遇到课桌上有一道“线”的情况,是什么线?三八线。那当时画三八线的本质就是:区域划分 — 地址空间就是线性区域
同样在Linux内核数据结构中也存在区域划分,类似下面的这种代码,用来管理内存空间:
struct area { int start; int end; } 同时,我们对线性区域进行指定start和end即可完成区域划分 ---- 类似于这样
struct area owner_1 (1,50}; struct area owner_2 (50,100}; 如果限定了区域,那区域之间的数据是什么?以一个4GB的内存为例,大概是这样的:
struct mm_struct //4GB { long code_start; long code_end; long init_start; long init_end; //..... long stack_start; long stack_end; } 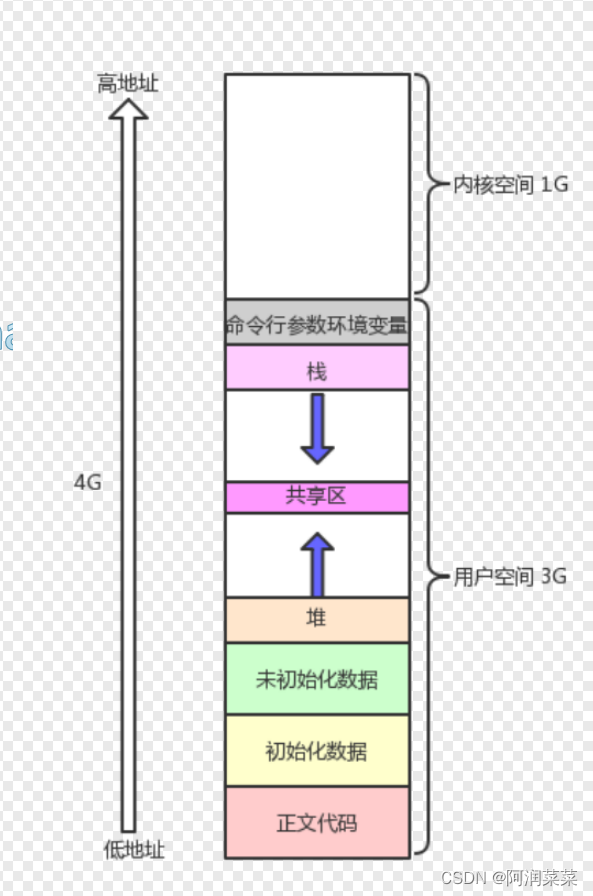
通过上述,我们可以知道地址空间区域是可以进行动态调整大小的 ---- 即更改 start或者end
理解页表
进程地址空间毕竟只是逻辑上的内存,并不是真正的物理内存,是不能存储数据的,进程的数据和代码是只能存储在物理内存上的,但是进程使用的是虚拟内存!进程只能访问虚拟地址,但是实际的数据是存储在物理内存上的,那么进程是如何通过虚拟地址拿到数据和代码的?
实际上在虚拟地址与物理地址之间是有一种映射关系的,这种映射关系被存储在页表中!每个进程都有自己的页表!
同时虚拟地址是经过页表(+MMU(集成在cpu中))映射到物理地址 ---- 像是我们大学生会被学号编号,进行确认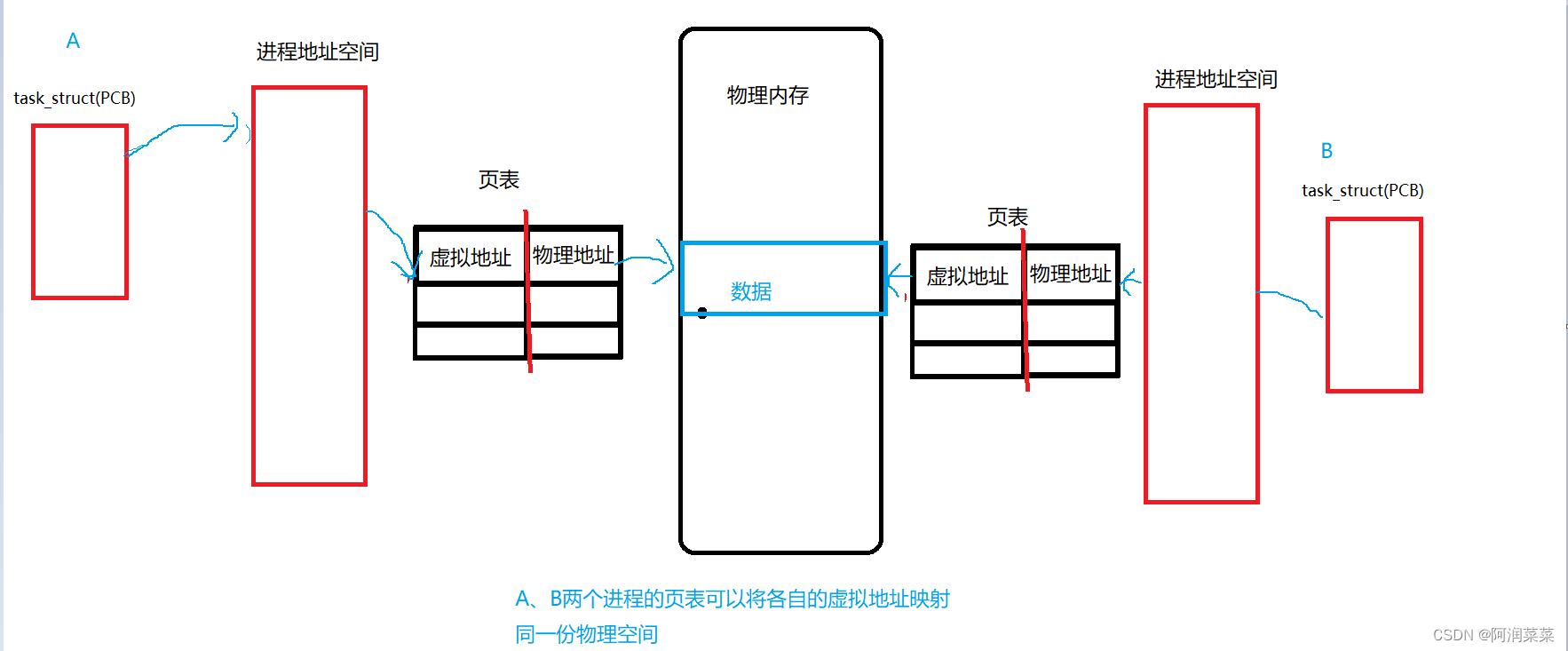
同时根据上述知识可以知道,同一个变量,地址相同,其实是虚拟地址相同,内容不同其实是被映射到了不同的物理地址
所以说内存分布实际上并不是真实(物理内存)的内存的分布,而是OS给进程画的一张“大饼”,就是让进程认为自己一个就拥有整个内存!说白了进程空间就是OS欺骗进程的一种手段!
每个进程都有属于自己的一张进程地址空间和对应的页表!
找到地址不是目的,而是一种手段(页表),目的是该地址对应的内容!
到这里还能回答原始问题:子进程的mm_struct继承父进程 ---- 即虚拟地址一样 进程独立,映射到不同的物理地址
深入扩展去理解!
地址空间为什么要存在?
---- 比如野指针越界问题,破坏了进程独立性,进程的数据会遭到破坏,影响到进程运行
- 防止地址随意访问,保护物理内存与其他进程运行
- 同时页表具有读写权限控制属性,解释了为什么代码段只是可读的,为什么有些变量不能赋值
- 将进程管理和内存管理进行解耦合 | 通过malloc本质讲解
- 可以让进程以统一视角看待自己的代码和数据
虚拟内存是OS欺骗进程的一种手段,进程在看待进程的时候都认为自己拥有整块内存,然后开始对着“这块内存”开始布局自己的代码和数据,但是实际上这些代码和数据到底存没存储起来,还得看OS,但是站在进程的角度,他是认为我们已经布局完整个内存了!进程是看不到真实物理内存的!进程只能看到进程地址空间! - 可以充分的利用内存资源,让内存的利用率变的高效起来!
比如:两个进程可能都需要访问某个动态库;如果没有进程地址空间的话,OS就会将这个动态库加载内存两次,也就是内存中会有两份一模一样的数据!这是没必要的!但是有了进程地址空间过后,我们可以让两个进程的虚拟地址同时映射到这同一份数据!也就是说两个进程可以共享这份数据!这份数据也就只需要在内存中存在一份就行了!但是在进程看来他们都认为这份数据是自己独享的!
malloc 本质
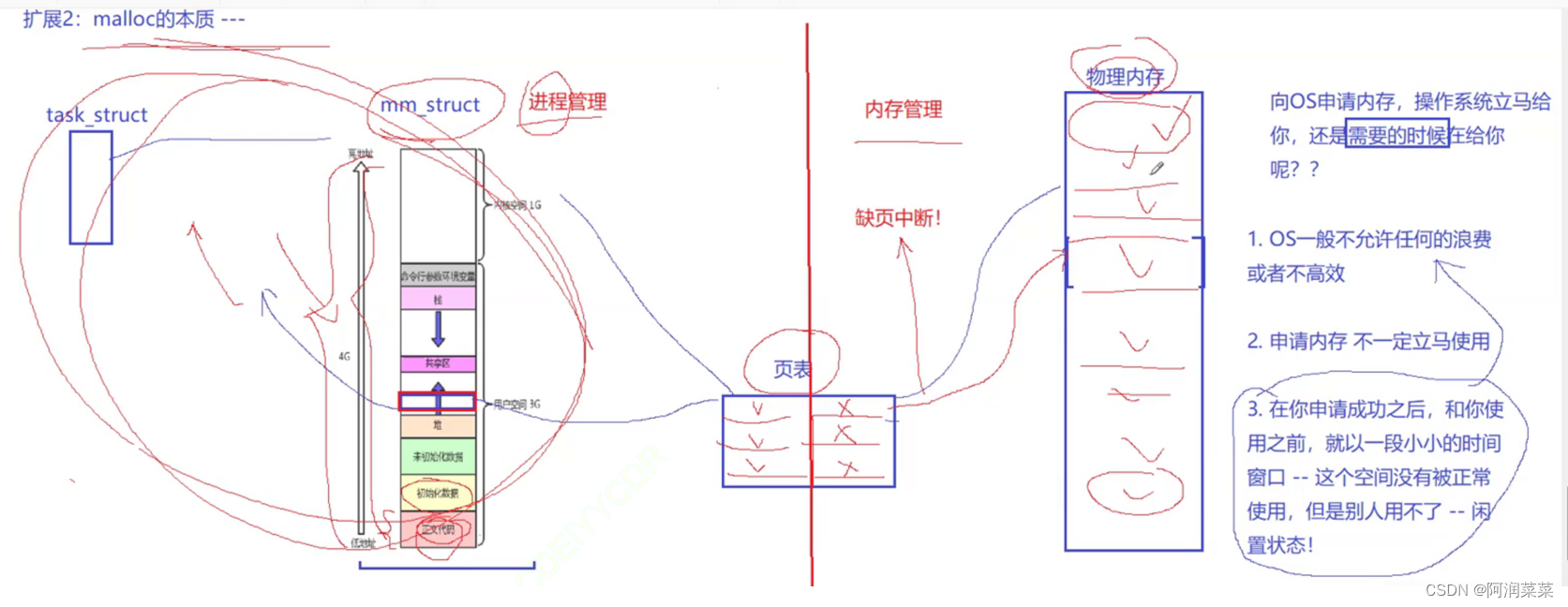
作为一款优秀的操作系统,不能允许任何的浪费或者不高效的存在。
所以操作系统使用1缺页中断方式来管理内存 ---- 即先在虚拟地址空间申请虚拟内存。
然后通过2页表映射 ,在实际物理内存上开辟空间 同时不需要关心数据放在物理内存哪个位置 因为通过页表映射都能找到
也就是说:在CPU上读取到的地址,全是进程空间上的地址,也就是虚拟地址!CPU不会直接去物理内存上读取数据!
重新理解地址空间
- 我们的程序在被编译的时候,没有被加载到内存,那么我们的程序内部有没有地址呢?
答案是:有的。源代码被编译的时候,就已经按照虚拟地址的方式进行了代码和数据的编址(使用ELF格式:划分数据区域)
比如我们简单写一段代码:
1 #include <stdio.h> 2 int main() 3 { 4 printf("hello world!\n"); 5 6 return 0; 7 } 我们将这段程序先编译成可执行程序,然后利用命令objdump -S对其进行反汇编: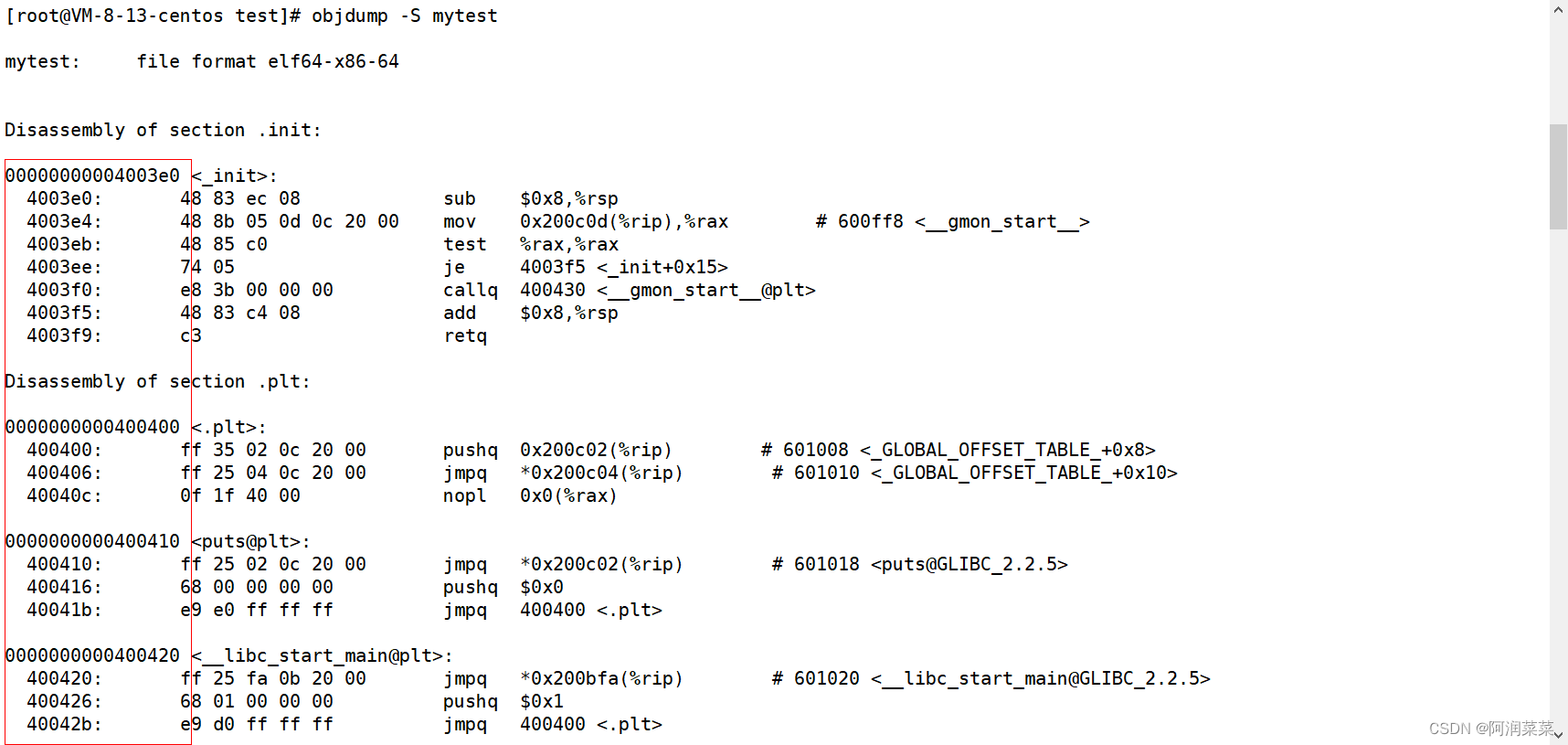
我们会发现,在我们的程序在未加载进内存的时候,编译器就已经确定好了各条指令的地址!
为什么?源代码在被编译的时候,就已经按照虚拟地址空间的方式对代码和数据进行了地址的编制,只不过只些代码和数据的地址都是虚拟地址,并不是真实的物理地址!只有当我们的程序被加载进内存了,才会真正的拥有物理地址!
那么整个程序的运行过程基本上是:
1、OS将我们的程序加载进内存(注意并不是一次性全部加载进去,而是先加载一些比较重要的代码和数据);
2、OS为该程序建立pcb,来管理该进程;
3、OS为该进程创建地址空间地址和页表;
4、cpu从特定的进程空间地址处读取数据!然后OS在根据cpu提供的虚拟地址,映射到对应物理地址,获取对应的数据给cpu,cpu开始处理!如果OS在根据cpu提供虚拟地址没有建立起对应的物理地址时,OS会暂停cpu对于该进程的处理,然后重新加载一部分数据进入内存,然后再建立映射关系,出现这种情况:叫做缺页中断!
所以虚拟地址这样的策略不只是影响OS,我们的编译器同样遵守这样的规则!
进程的代码和数据必须一直在内存中吗?
答:不是。OS会将暂时不用的进程代码、数据和部分进程控制块通过我们的页表技术交换至磁盘中存储。怎么理解写时拷贝呢?
写时拷贝(copy-on-write, COW)是一种计算机程序设计领域的优化策略。其核心思想是,如果有多个调用者(callers)同时请求相同资源(如内存或磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本(private copy)给该调用者,而其他调用者所见到的最初的资源仍然保持不变。这过程对其他的调用者都是透明的。
写时拷贝主要的优点是如果调用者没有修改该资源,就不会有副本(private copy)被创建,因此多个调用者只是读取操作时可以共享同一份资源。
写时拷贝常见的应用场景有:
- 虚拟内存管理中的写时复制:当一个进程fork一个子进程时,并不会立即复制父进程占用的所有内存页,而是与父进程共享相同的内存页,并把这些页面标记为只读。当父进程或子进程试图修改这些页面时,系统才会为修改者分配新的页面,并将原来页面上的内容复制过去。
- 字符串处理中的写时复制:当一个字符串被赋值给另一个字符串变量时,并不会立即复制字符串内容,而是让两个变量指向相同的字符串。当其中一个变量试图修改字符串内容时,系统才会为修改者分配新的字符串空间,并将原来字符串上的内容复制过去⁵。
我们知道在fork调用了子进程后,只有当子进程进行内容修改时,物理地址才会发生改变! 并且页表项中可以具有读写权限,本质就是:按需申请资源,提高效率!
CPU从特定的进程空间地址处读取数据!然后OS在根据cpu提供的虚拟地址,映射到对应物理地址,获取对应的数据给cpu,cpu开始处理!如果OS在根据cpu提供虚拟地址没有建立起对应的物理地址时,OS会暂停cpu对于该进程的处理,然后重新加载一部分数据进入内存,然后再建立映射关系,出现这种情况:叫做缺页中断!↩︎
实际上在虚拟地址与物理地址之间是有一种映射关系的,这种映射关系被存储在页表中!每个进程都有自己的页表!
当进程需要访问虚拟地址上某一处的数据时,OS就会拿着进程提供的虚拟地址,根据该进程提供的页表转换成对于的物理地址,然后去对于的物理内存上取数据在交给进程!这个过程进程是看不到的,站在进程的角度就是,我(进程)需要访问虚拟地址为0x11223344处的数据,然后就直接拿到了数据,在进程看来它就认为自己的数据是存储在虚拟内存上的,只要自己需要,随时都可以拿到,殊不知其真实数据是存储在物理内存上的,进程之所以能随时拿到数据,都是由OS完成的!↩︎
