
阅读量:4
2024年6月17日,我们的运维团队突然收到了一连串的告警。监控大屏上,代表着不同 Sealos 可用区的绿点中,零星地闪烁起了一两个红点。
“奇怪,怎么有几台服务器突然 hang 住了?” 值班的小辉皱起了眉头。
这次故障的诡异之处在于它的随机性。并非所有节点都受到影响,而是在不同可用区中,时不时地有个别服务器突然 “失联”。更令人不解的是,这些突然 hang 住的服务器资源都很充足,CPU、内存、磁盘 IO 等各项指标都处于健康水平。
“正常情况下它们不是都会自愈么?” 小谢问道。
“不会,我们已经观察了10分钟,还是没有恢复正常。” 小杨摇摇头,“这不太正常。”
常规手段失效,真凶难寻
面对这种间歇性但严重的故障,我们立即启动了应急预案。首先,我们祭出了我们的 “传家宝”——dmesg 命令,希望能从系统日志中找到一些蛛丝马迹。
然而,这次 dmesg 没有给我们任何有价值的信息。日志中看不到任何异常,服务器看起来完全正常,太诡异了。我们对比了之前遇到的所有已知问题,发现这次的情况与以往都不同,问题主要发生在北京和广州节点,但发生的概率较低,这更增加了排查的难度。
我们继续深入排查,检查了网络连接、系统负载、进程状态等多个方面,但所有指标都显示正常。
“等等,我发现了一个共同点!” 小李突然喊道,“所有出问题的节点,内核版本都是 5.15.0-91-generic!”
这个发现让我们眼前一亮,难道真凶就藏在这个特定的内核版本中?
意外的 “内核恐慌”
为了进一步确认猜测,我们联系了云服务提供商的技术支持团队。在他们的协助下,我们终于在串口日志中发现了关键线索。
就在系统 hang 住之前,日志中打印了一段特殊的堆栈信息:
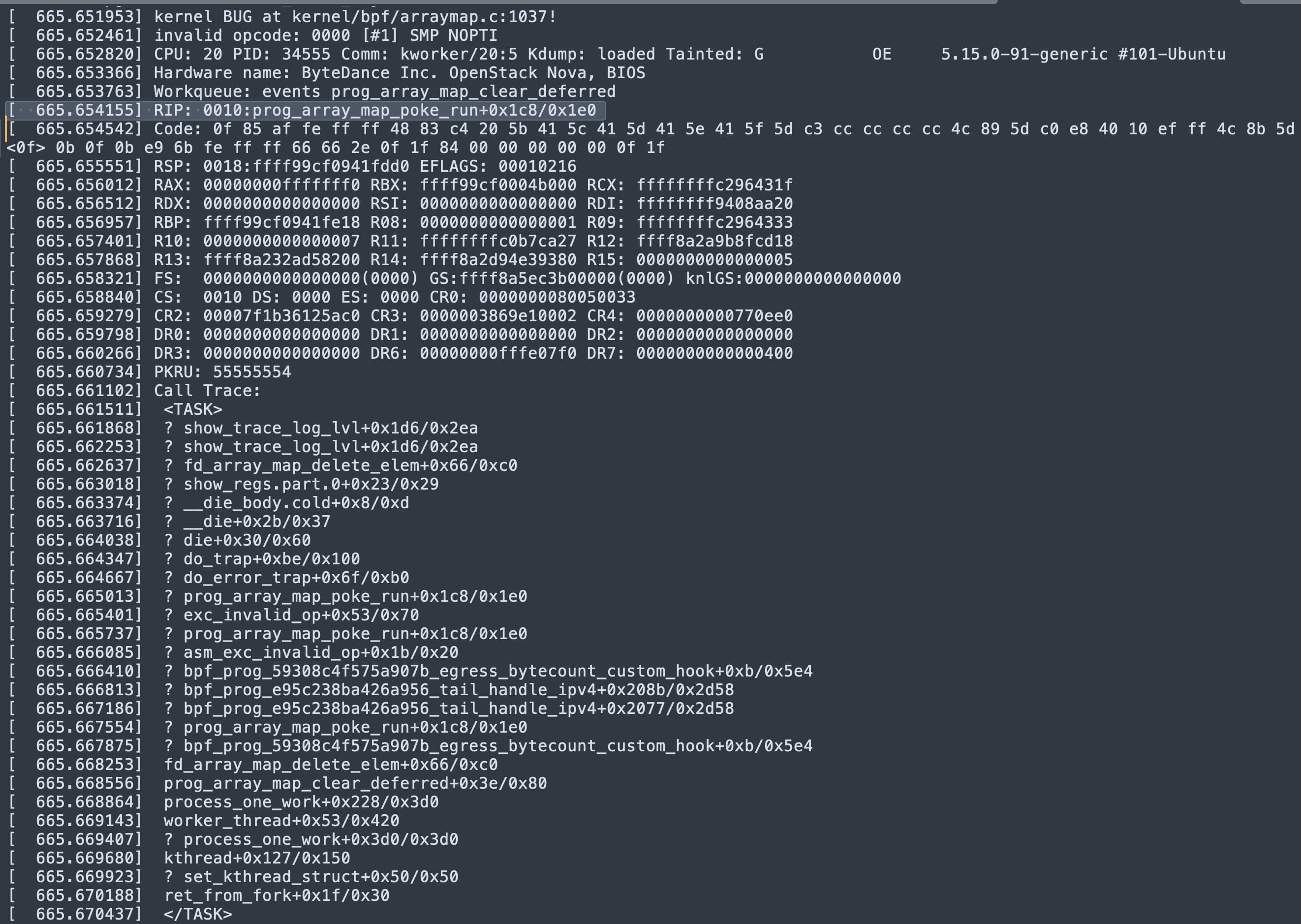
这段堆栈信息清楚地显示,系统触发了一个内核 bug,导致了严重的内核恐慌。正常情况下,当发生内核 panic 时,系统应该会崩溃并进入 kdump 流程,将 Vmcore 写入磁盘,然后重新启动。但是,我们的系统却陷入了持续的 hang 状态,这显然不太对劲。
进一步分析 kdump 的日志,我们发现了问题的真相:
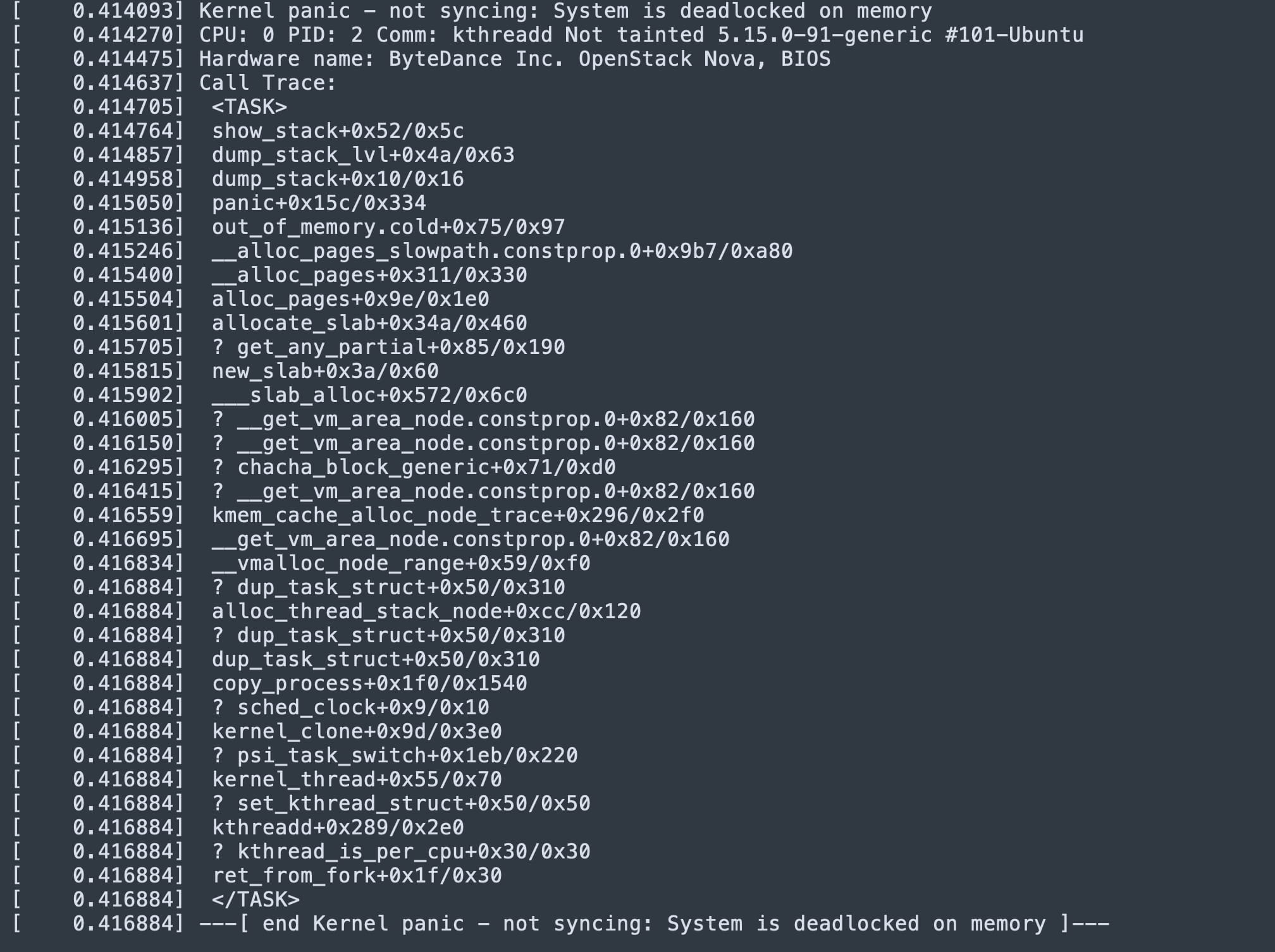
原来,kdump 在启动第二内核时出现了异常。我们怀疑,这可能是由于 crashkernel 配置的内存不足,导致第二内核启动失败,系统最终陷入了 hang 状态。
好家伙,这不就像是消防车在赶往火灾现场的路上自己也出了故障。。。
内核升级大法
既然找到了问题的根源,接下来就是对症下药的时候了。我们的解决方案很直接——升级内核到已经修复了这个 bug 的最新版本:
apt install linux-image-5.15.0-112-generic然而,事情并没有像我们预想的那样一帆风顺。在升级内核后的恢复过程中,我们又遇到了一个新的挑战——Cilium (我们使用的网络方案) 开始频繁重启,并报出了这样的错误:
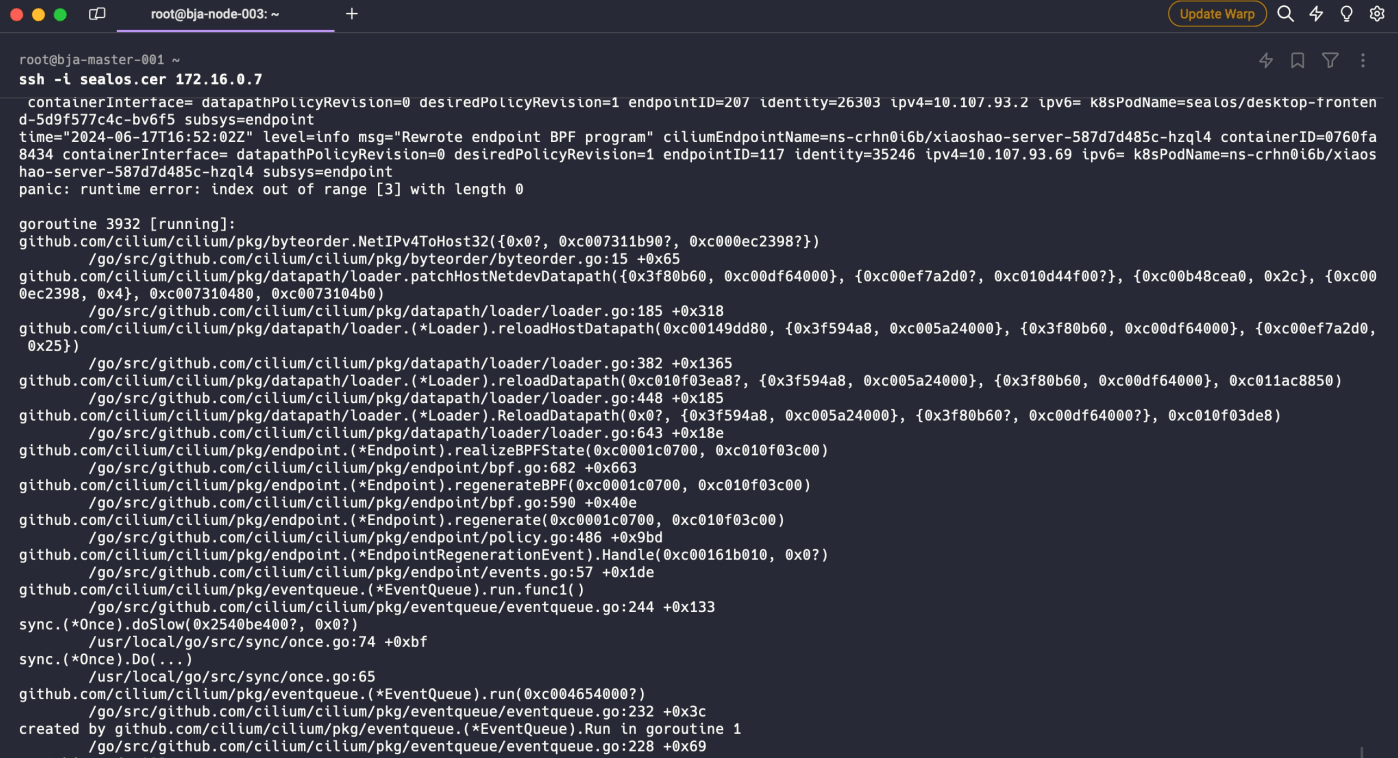
Cilium 的小插曲
仔细查看 Cilium 的错误日志,我们发现问题出在一个叫做 “kube-ipvs0” 的网络接口上。这个 “kube-ipvs0” 设备其实是 Kubernetes 的 kube-proxy 组件在使用 IPVS 模式时创建的。
等等,我们的集群不是已经不再使用 kube-proxy 了吗?
经过一番排查后发现,原来在我们迁移到 Cilium 网络方案的过程中,忘记了清理这个遗留的网络接口。就是这个小小的疏忽导致了 Cilium 无法正确获取节点上的 IPv4 地址,进而引发了我们遇到的错误。
Cilium 源码中的相关片段:
// https://github.com/cilium/cilium/blob/8c7e442ccd48b9011a10f34a128ec98751d9a80e/pkg/datapath/loader/loader.go#L183 if option.Config.EnableIPv4Masquerade && bpfMasqIPv4Addrs != nil { ipv4 := bpfMasqIPv4Addrs[ifName] // nil checking is missing here opts["IPV4_MASQUERADE"] = uint64(byteorder.NetIPv4ToHost32(ipv4)) // ipv4 is nil }这段代码中,Cilium 尝试获取网络设备的 IPv4 地址,但是由于 “kube-ipvs0” 设备并不包含有效的 IP 地址,导致了空指针异常,最终就会导致 ip 进行类型转换时溢出:
func NetIPv4ToHost32(ip net.IP) uint32 { ipv4 := ip.To4() _ = ipv4[3] // Assert length of ipv4. return Native.Uint32(ipv4) }参考 issue:https://github.com/cilium/cilium/issues/30746
解决方法很简单:删除这个多余的网络接口。
ip link delete kube-ipvs0完成这个操作后,Cilium 终于恢复了正常,我们的服务也重新上线了。
总结
这次的故障给我们上了很重要的一课:要保持警惕,不放过任何细节。
即使是一个看似无害的遗留网络设备,也可能成为系统稳定性的隐患。在进行重大架构变更时,我们需要更加细致地清理旧的组件和配置。
