阅读量:0
训练清华ChatGLM-6B时报错, 原因是显存不够
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 96.00 MiB (GPU 0; 23.70 GiB total capacity; 4.37 GiB already allocated; 64.81 MiB free; 4.37 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
尝试将
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()改为
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().quantize(4).cuda()仍然报错
RuntimeError: CUBLAS error: CUBLAS_STATUS_NOT_INITIALIZED
排错流程如下
查看服务器显存占用情况
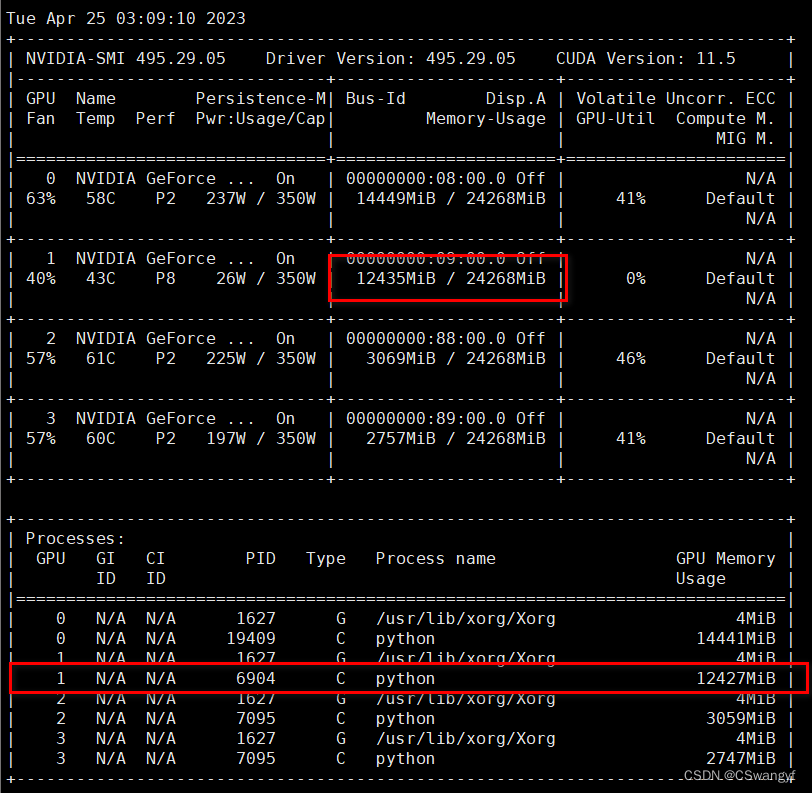
watch -n 0.1 nvidia-smi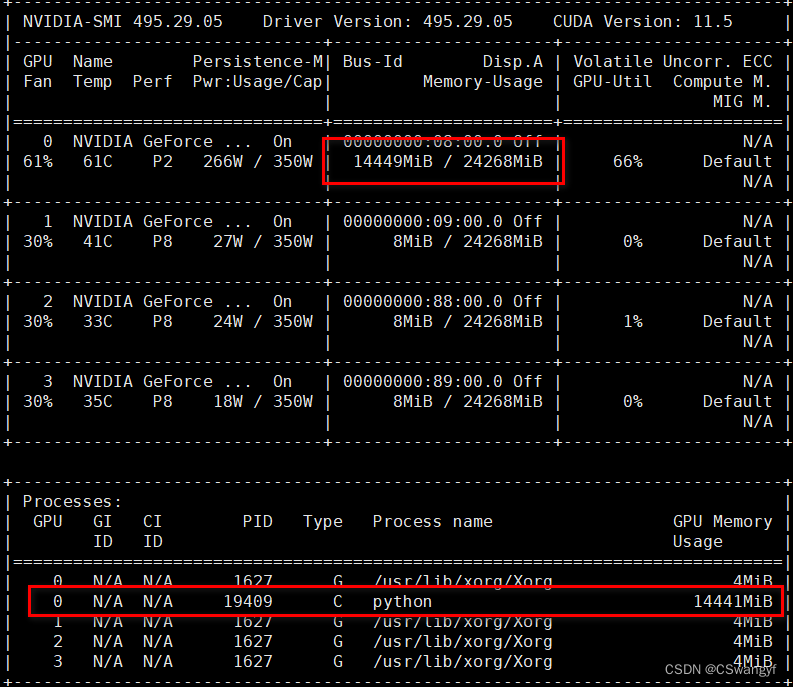
发现gpu:0显存被PID:19409程序大量占用, 报错应该是默认在gpu:0训练导致显存不足, 接着查看gpu:0上程序所属用户(如果不是师兄的我就kill了)
top
一看是root的, 惹不起还躲不起嘛, 换张卡跑, 顺嘴一提, 权限内的程序可以kill -9 {pid}掉释放显存
kill -9 19409发现gpu:1空闲, 指定gpu:1上训练模型, 有多种方法,
(1) 可以在py代码开头(一定要在开头)加
import os os.environ['CUDA_VISIBLE_DEVICES']='1'这样即可指定在gpu:1上训练, 实际上是只设置gpu:1可见, 而屏蔽其他gpu卡
(2) 可以在代码运行前shell或bash脚本中加
CUDA_VISIBLE_DEVICES=1 python xxx.py这样即可指定在gpu:1上训练, 实际上是只设置gpu:1可见, 而屏蔽其他gpu卡
(3)在程序中使用set_device()
import torch torch.cuda.set_device(id) 设置完成后查看显存占用情况可以看到, gpu:1显存占用马上上升了, 不影响其他gpu卡的显存
可以看到清华的ChatGLM-6B约占12G显存(其他卡显存增加是写文章的时候其他小伙伴在跑)