
阅读量:0
服务器GPU挂掉
跑深度学习的代码的时候发现中断了。通过命令查看:
nvidia-smi 显示
Unable to determine the device handle for GPU 0000:01:00.0: Unknown Error。 感觉很莫名其妙。通过重启大法之后,又能用一段时间。
shutdown -r now 但是过了一个小时左右又会挂掉。不能从根本解决问题。那么到底为什么GPU会自己挂掉呢?
问题排查
通过查看日志定位错误原因:
nvidia-bug-report.sh 在当前目录下生成了nvidia-bug-report.log日志文件。查看到日志文件的内容如下:

网上查找一下这个报错码79https://forums.developer.nvidia.com/t/gpu-has-fallen-of-the-bus/122124发现要么是电源问题,要么是温度过高问题。
重现问题,查看温度日志
如果判断是否是GPU温度过高呢?需要打一个温度日志,再运行一下代码,看GPU温度是否超过了shutdown 温度(GPU温度过高会自动掉线保护GPU)。命令如下:
nvidia-smi -q -l 2 -d TEMPERATURE -f nvidiatemp.log 代码继续跑,等待问题重现后查看温度日志就可以确定是否是温度过高导致GPU自动掉线了。
果然,当GPU掉线后,查看温度日志: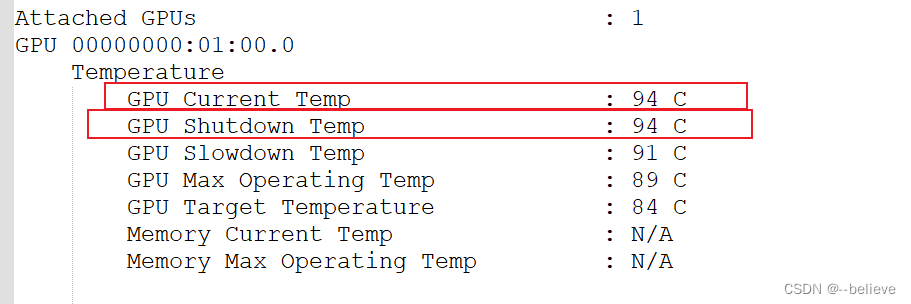
上图中CurrentTemp表示当前温度,Shutdown Temp表示超过这个温度GPU会自动掉线。Target Temp表示目标温度(GPU比较合适的温度)。
找到问题了!就是温度过热导致GPU掉线!
解决问题
温度过热?
多半是散热不行,果然,发现一个风扇明显转的较慢。猜测可能是那个风扇坏掉了。
于是将显卡风扇拆下来。通过拨动发现其中一个风扇没另一个风扇灵活。拆开发现转轴有点杂质,增大了风扇阻力,清理了一下,上了点润滑油。(当然直接换风扇最为方便!!!免得担心风扇被拆坏掉)
装上后发现能正常工作,温度再也没有超负荷过!问题完美解决!
