
阅读量:0
前言:最近在学习一些rk3588相关的东西,趁着这个项目,把学习的相关东西整合下,放到一个项目里面,巩固学习的知识。
项目名称:yolov5识别图像、ffmpeg发送到rtmp服务器
功能:1、opencv读取usb摄像头,使用RK3588自带的NPU推理yolov5s算法,识别图像
2、使用ffmpeg,将处理的图像进行压缩成h264格式,发送到rtmp服务器上。
2023.3.4补充:
这两天搞了一下OpenCL相关的,顺带在rk3588上运行了一下。对项目的图像转化部分做了一个调整。以前用的是OpenCV提供API,将BGR转化为RBG格式,现在用OpenCL调用GPU转化。自己写的用CPU完成这个功能的代码,运行时间大概在11.09317ms,调用GPU运行的时间平均在2.15199ms(均调用100次,取平均值),速度还是有比较大的提升,GPU在大规模数据运算效率是高不少。这里放下GPU运行的内核函数代码,写的很简单,供参考。
/* 功能:使用GPU,见BGR像素转化为RGB格式 dst_img_buffer: 转化好的图像存放缓存区,RGB格式 src_img_buffer: 原始图像,BGR格式 img_w: 图像宽 img_h: 图像高,代码未用到 无返回值 */ __kernel void bgr2rgb( __global unsigned char* dst_img_buffer, __global const unsigned char* src_img_buffer, const int img_w, const int img_h) { int w = get_global_id(0); int h = get_global_id(1); dst_img_buffer[(h * img_w + w) * 3 + 0] = src_img_buffer[(h * img_w + w) * 3 + 2]; dst_img_buffer[(h * img_w + w) * 3 + 1] = src_img_buffer[(h * img_w + w) * 3 + 1]; dst_img_buffer[(h * img_w + w) * 3 + 2] = src_img_buffer[(h * img_w + w) * 3 + 0]; }在makefile里面添加OpenCL相关的部分。
OPENCL_LDLIBS = -lmali OPENCL_LDLIBS_PATH = -L/usr/lib/aarch64-linux-gnu以后有时间再更新OpenCL部分。
一、环境搭建
本次用到的组件有opencv、ffmpeg、npu相关的库,因此,需要先安装环境。
1、rk3588固件
笔者这里用的系统固件是RK官网的ubuntu固件,名字为:ROC-RK3588S-PC_Ubuntu20.04-Gnome-r2202_v1.0.4b_221118.7z。使用官方提供的下载工具 RKDevTool_Release_v2.84下载固件到板子里面。具体方式不说了,参考一下官方的资料下栽进去即可。
2、opencv编译
opencv是图像处理用到的比较多的一个开源库。在官方的资料里面,可以通过交叉编译,编译出来opencv库,笔者电脑实在拉跨,rk的sdk编译不出来,因此,就直接在rk3588板子里面编译opencv,不得不说,rk3588性能确实强,编译opencv这种库,一会就好了,好像比我虚拟机的ubuntu系统编译的还要快。笔者这里用的是opencv-4.5.4.zip这个版本的opencv。准备好源码之后,开始编译。具体如下:
1)安装必要的库
sudo apt-get install build-essential cmake cmake-gui g++ pkg-config libgtk2.0-dev
2)解压源码、进入对应的目录
mkdir build
cd build
cmake -D CMAKE_BUILD_TYPE=RELEASE -D WITH_TBB=ON -D WITH_V4L=ON -D WITH_GTK=ON -D WITH_OPENGL=ON ..
make -j16 && make install
我这里安装到默认的目录下,也可以使用-D CMAKE_INSTALL_PREFIX=../install安装到指定的目录下面。opencv参考网上的博客安装下就行了,遇到的问题,网上基本都有解决方案。
3、ffmpeg安装
本次使用的压缩格式是h264,ffmpeg里面没有带相关的源码,因此,在ffmpeg编译之前,需要先编译libx264库。准备好libx264源码,笔者用到的是x264.tar.bz2。这里直接给出configure配置,同样是直接安装到默认目录,需要的话,可以使用--prefix=../install指定对应的目录。
./configure --enable-shared --enable-static --disable-cli --enable-pic
make -j16 && make install
编译ffmpeg之前,还需要编译openssl,本次用到的版本是openssl-3.1.0-alpha1.tar.gz。rk3588上,直接
./configure
make -j16 && sudo make install
ffmpeg类似,本次用到的版本是ffmpeg-snapshot.tar.bz2。给出configure
./configure --target-os=linux --arch=arm64 --enable-shared --enable-ffmpeg --enable-pthreads --enable-libx264 --enable-libsrt --enable-gpl
make -j16 && sudo make install
编译的时候会遇到一些问题,请百度,参考其他的博主的,写这篇文章的时候,项目已经做好了,具体有哪些问题也记不太清了,百度上都有解决方法。若是遇到有些库找不到路径,可以添加链接路径,或者建立软链接都可以。环境上的问题基本上都比较容易解决。若是rk3588里面缺少了其他的库,请对照网上的教程安装。
4、rtmp服务器安装
网上很多rtmp服务器的安装,这里给一个博客链接,供小伙伴参考。
搭建好nginx(虚拟机ubuntu),编译好ffmpeg(rk3588开发板)之后,可以使用如下指令测试在rk3588板子上是否能够正常运行。
ffmpeg -re -stream_loop -1 -i 1.mp4 -vcodec libx264 -acodec aac -f flv rtmp://192.168.1.102:1935/live/test
其中,1.mp4是测试视频,使用h264编码(用到了libx264),192.168.1.100是笔者局域网的服务器ip,1935是端口号。使用ffplay等带拉流的软件,输入
ffplay rtmp://192.168.1.100:1935/live/test,正常情况下可以看到音视频流。
ffmpeg指令推流界面
 ffplay播放
ffplay播放
二、代码流程
这里,基本知识如h264编码等不谈,若是需要相关背景知识,请参考网上其他博主的文章。本篇博文主要从代码角度,谈谈怎么实现功能并给出参考代码。
代码流程如图。
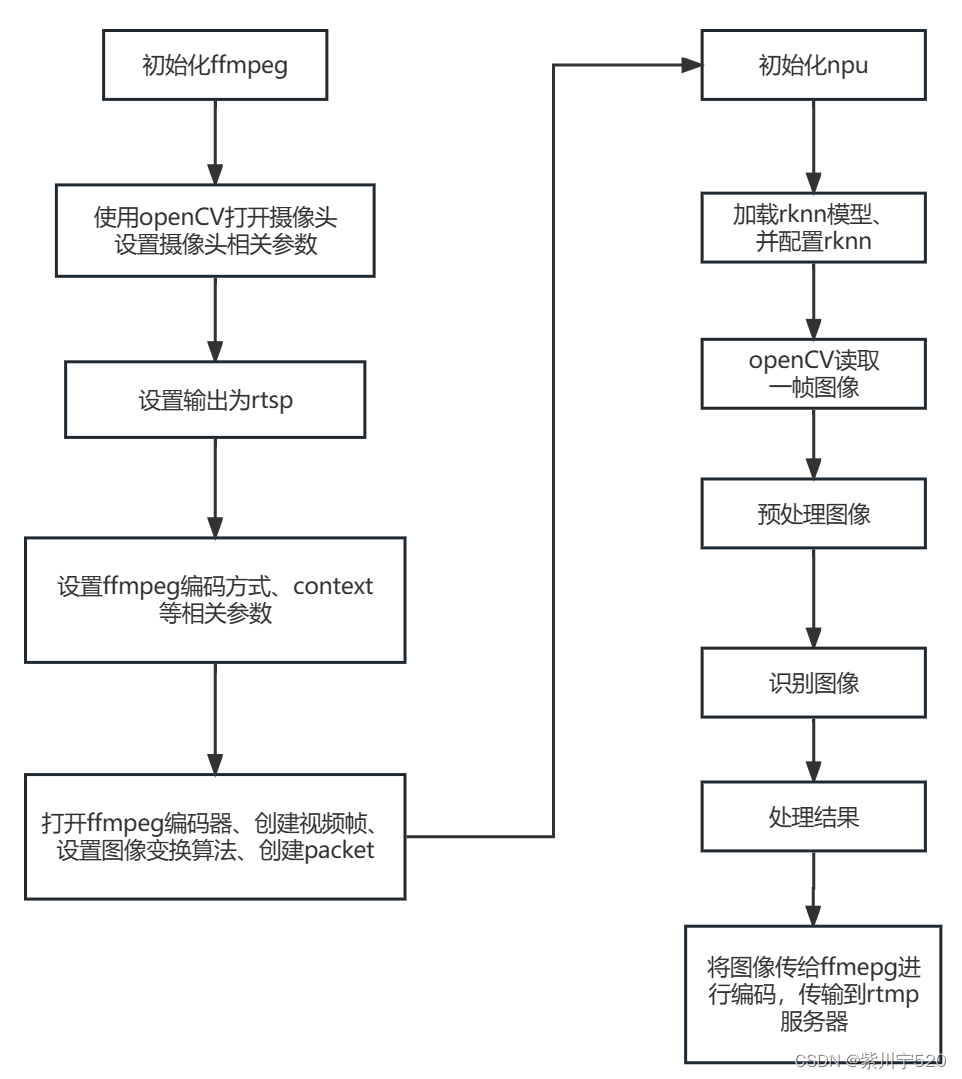
首先,需要初始化ffmpeg、opencv、npu相关部分。ffmpeg编程的时候,需要配置一些参数,输入流使用的是opencv打开的摄像头。需要初始化、打开编码器、初始化上下文。
video->codec = avcodec_find_encoder(AV_CODEC_ID_H264); if (!video->codec) { printf("Codec '%s' not found\n", "h264"); return -1; } video->codec_ctx = avcodec_alloc_context3(video->codec); if (!video->codec_ctx) { printf("codec_ctx alloc fail\n"); return -1; } video->codec_ctx->width = width; // 设置编码视频宽度 video->codec_ctx->height = height; // 设置编码视频高度 video->codec_ctx->bit_rate = 50 * 1024 * 8; //50kb video->codec_ctx->codec_id = video->codec->id; video->codec_ctx->thread_count = 8; video->codec_ctx->time_base.num = 1; video->codec_ctx->time_base.den = fps; // 设置帧率,num为分子,den为分母,如果是1/25则表示25帧/s video->codec_ctx->framerate.num = fps; video->codec_ctx->framerate.den = 1; video->codec_ctx->pix_fmt = AV_PIX_FMT_YUV420P; // 设置输出像素格式 //画面组的大小,多少帧一个关键帧 video->codec_ctx->gop_size = 50; video->codec_ctx->max_b_frames = 0; ret = avcodec_open2(video->codec_ctx, video->codec, NULL); if (ret < 0){ printf("open codec fail\n"); return -1; }摄像头输入的是YUV格式,openCV打开的摄像头,输入的则是BGR格式,用ffmpeg转码的时候需要将BGR转化为YUV420P格式。使用ffmpeg,定义一个转化算法。
// 创建视频重采样上下文:指定源和目标图像分辨率、格式 video->swsCtx = sws_getContext(width, height, AV_PIX_FMT_BGR24, width, height, AV_PIX_FMT_YUV420P, SWS_BICUBIC,NULL, NULL, NULL);代码中,video是笔者自定义的一个结构体,用于管理代码。上面width、height是输入图像的格式,输入格式为BGR,下面width、height是输出图像的格式,输入格式为YUV420P。同时,需要创建两个视频帧,用于保存视频帧数据,一个是BGR,一个YUV420P。video结构体:
//定义输入流,一般使用摄像头 struct input_video_stream{ //使用opencv打开输入流 VideoCapture cap; // capture Mat img; int width, height; //宽高 int fps; //帧率 AVFormatContext *fmt_ctx; }; //定义输出流 struct output_video_stream{ const AVOutputFormat *fmt; AVFormatContext *fmt_ctx; AVStream *stream; AVPacket *packet; const AVCodec *codec; //编码器 }; struct h_video { struct input_video_stream input_video_stream; struct output_video_stream output_video_stream; const AVCodec *codec; //编码器 AVCodecContext *codec_ctx; // 给编码器分配内存,返回对应编码器上下文 SwsContext *swsCtx; //用于转化视频格式 AVFrame *rgbFrame; //存放RGB格式的数据帧 AVFrame *yuvFrame; //存放YUV格式的数据帧 AVPacket *pkt; //packet包,存放处理过的压缩数据 };struct input_video_stream、struct output_video_stream、struct h_video笔者是定义的用于管理相关资源。
BGR、YUV420P帧均需要地方存放,需要初始化两个视频帧。
//创建BGR视频帧 video->rgbFrame = av_frame_alloc(); video->rgbFrame->format = AV_PIX_FMT_BGR24; video->rgbFrame->width = width; video->rgbFrame->height = height; ret = av_frame_get_buffer(video->rgbFrame, 32); //创建YUV视频帧并配置 video->yuvFrame = av_frame_alloc(); video->yuvFrame->format = AV_PIX_FMT_YUV420P; video->yuvFrame->width = width; video->yuvFrame->height = height; ret = av_frame_get_buffer(video->yuvFrame, 32);packet用于存放转码之后的视频数据。
video->pkt = av_packet_alloc(); if (!video->pkt){ printf("pkt alloc fail\n"); return -1; } av_init_packet(video->pkt);ffmpeg处理的代码基本上就这些。
初始化、配置npu部分,参考了rk的例程。
这里直接放我封装的调用rknn识别图像的类代码吧,
头文件
#ifndef __DETECET_H #define __DETECET_H #include <dlfcn.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/time.h> #include <iostream> #include <sstream> #define _BASETSD_H #include "RgaUtils.h" #include "im2d.h" #include <opencv2/opencv.hpp> #include <opencv2/highgui.hpp> #include <opencv2/imgproc.hpp> #include <opencv2/videoio.hpp> #include "postprocess.h" #include "rga.h" #include "rknn_api.h" #define PERF_WITH_POST 1 using namespace cv; //OpenCV标准库 class detect{ public: rknn_context ctx; rknn_sdk_version version; rknn_input_output_num io_num; struct timeval start_time, stop_time; size_t actual_size = 0; int img_width; int img_height; int img_channel; const float nms_threshold = NMS_THRESH; const float box_conf_threshold = BOX_THRESH; rga_buffer_t src; rga_buffer_t dst; im_rect src_rect; im_rect dst_rect; char *model_path; detect(char* model_name); ~detect(); int rknn_envs_init(const char* model_path); int rknn_envs_free(); int detect_image(Mat &orig_img, detect_result_group_t *detect_result_group); int draw_results(Mat &orig_img, detect_result_group_t *detect_result_group); private: int model_data_size; unsigned char *model_data; unsigned char* load_data(FILE* fp, size_t ofst, size_t sz); unsigned char* load_model(const char* filename, int* model_size); }; #endif cpp文件
#include "./include/detect.h" using namespace cv; //OpenCV标准库 using namespace std; //C++标准程序库中的所有标识符都被定义于一个名为std的namespace中 detect::detect(char* model_path){ int ret = 0; memset(&src_rect, 0, sizeof(src_rect)); memset(&dst_rect, 0, sizeof(dst_rect)); memset(&src, 0, sizeof(src)); memset(&dst, 0, sizeof(dst)); this->model_path = model_path; } detect::~detect(){ } /************************************************************************** 功能: 内部使用,读取rknn格式的模型文件数据 参数说明 fp:文件句柄 ofst: 偏移量 sz: 模型大小 返回值: 0表示成功 ***************************************************************************/ unsigned char* detect::load_data(FILE* fp, size_t ofst, size_t sz) { unsigned char* data; int ret; data = NULL; if (NULL == fp) { return NULL; } ret = fseek(fp, ofst, SEEK_SET); if (ret != 0) { printf("blob seek failure.\n"); return NULL; } data = (unsigned char*)malloc(sz); if (data == NULL) { printf("buffer malloc failure.\n"); return NULL; } ret = fread(data, 1, sz, fp); return data; } /************************************************************************** 功能: 内部使用,加载rknn格式的模型文件 参数说明 filename:模型路径 model_size: 模型大小 返回值: 0表示成功 ***************************************************************************/ unsigned char* detect::load_model(const char* filename, int* model_size) { FILE* fp; unsigned char* data; fp = fopen(filename, "rb"); if (NULL == fp) { printf("Open file %s failed.\n", filename); return NULL; } fseek(fp, 0, SEEK_END); int size = ftell(fp); data = load_data(fp, 0, size); fclose(fp); *model_size = size; return data; } /************************************************************************** 功能: 初始化rknn模型的运行环境 参数说明 model_path:rknn格式的模型路径 返回值: 0表示成功 ***************************************************************************/ int detect::rknn_envs_init(const char* model_path) { int ret = 0; /* 加载rknn文件,创建网络 */ model_data_size = 0; model_data = load_model(model_path, &model_data_size); ret = rknn_init(&ctx, model_data, model_data_size, 0, NULL); if (ret < 0) { printf("rknn_init error ret=%d\n", ret); return -1; } ret = rknn_query(ctx, RKNN_QUERY_SDK_VERSION, &version, sizeof(rknn_sdk_version)); if (ret < 0) { printf("rknn_query RKNN_QUERY_SDK_VERSION error ret=%d\n", ret); return -1; } // printf("sdk version: %s driver version: %s\n", version.api_version, version.drv_version); ret = rknn_query(ctx, RKNN_QUERY_IN_OUT_NUM, &io_num, sizeof(io_num)); if (ret < 0) { printf("rknn_init RKNN_QUERY_IN_OUT_NUM error ret=%d\n", ret); return -1; } return 0; } /************************************************************************** 功能: 识别之后的图像,在原始图像上绘制结果方框 参数说明 orig_img:待绘制图像,原始图像 detect_result_group: 存放模型推理输出的结果 返回值: 0表示成功 ***************************************************************************/ int detect::draw_results(Mat &orig_img, detect_result_group_t *detect_result_group){ char text[256]; //printf("count: %d\n", detect_result_group.count); for (int i = 0; i < detect_result_group->count; i++) { //处理推理结果 detect_result_t* det_result = &(detect_result_group->results[i]); sprintf(text, "%s %.1f%%", det_result->name, det_result->prop * 100); printf("name: %s @ size:(%d %d %d %d) %f\n", det_result->name, det_result->box.left, det_result->box.top, det_result->box.right, det_result->box.bottom, det_result->prop); int x1 = det_result->box.left; int y1 = det_result->box.top; int x2 = det_result->box.right; int y2 = det_result->box.bottom; rectangle(orig_img, cv::Point(x1, y1), cv::Point(x2, y2), cv::Scalar(255, 0, 0, 255), 3); putText(orig_img, text, cv::Point(x1, y1 + 12), cv::FONT_HERSHEY_SIMPLEX, 0.5, cv::Scalar(0, 0, 0)); } imshow("窗口", orig_img); cv::waitKey(1); return 0; } /************************************************************************** 功能: 将传入的图像进行识别,结果保存到detect_result_group 参数说明 orig_img:待识别图像,分辨率任意,最好大于 [640 × 640] detect_result_group: 存放模型推理输出的结果 返回值: 0表示成功 ***************************************************************************/ int detect::detect_image(Mat &orig_img, detect_result_group_t *detect_result_group) { int ret = 0; void* resize_buf = nullptr; rknn_tensor_attr input_attrs[io_num.n_input]; //存放输入参数 //先对传来的图像进行处理 Mat img; //用于NPU推理的图像 Mat tImg; //用于图像的转化 cvtColor(orig_img, tImg, cv::COLOR_BGR2RGB); resize(tImg, img, Size(640, 640), 0, 0, cv::INTER_NEAREST); //模型的输入图像分辨率为[640 × 640], 原始图像需要缩放一次 img_width = img.cols; img_height = img.rows; memset(input_attrs, 0, sizeof(input_attrs)); for (int i = 0; i < io_num.n_input; i++) { input_attrs[i].index = i; ret = rknn_query(ctx, RKNN_QUERY_INPUT_ATTR, &(input_attrs[i]), sizeof(rknn_tensor_attr)); if (ret < 0) { printf("rknn_init error ret=%d\n", ret); return -1; } } rknn_tensor_attr output_attrs[io_num.n_output]; //存放输出参数 memset(output_attrs, 0, sizeof(output_attrs)); for (int i = 0; i < io_num.n_output; i++) { output_attrs[i].index = i; ret = rknn_query(ctx, RKNN_QUERY_OUTPUT_ATTR, &(output_attrs[i]), sizeof(rknn_tensor_attr)); } //模型的输入通道数、宽、高 int channel = 3; int width = 0; int height = 0; if (input_attrs[0].fmt == RKNN_TENSOR_NCHW) { //输入的通道数、宽、高 channel = input_attrs[0].dims[1]; width = input_attrs[0].dims[2]; height = input_attrs[0].dims[3]; } else { width = input_attrs[0].dims[1]; height = input_attrs[0].dims[2]; channel = input_attrs[0].dims[3]; } rknn_input inputs[1]; //存放输入图像相关参数 memset(inputs, 0, sizeof(inputs)); inputs[0].index = 0; inputs[0].type = RKNN_TENSOR_UINT8; inputs[0].size = width * height * channel; inputs[0].fmt = RKNN_TENSOR_NHWC; inputs[0].pass_through = 0; if (img_width != width || img_height != height) { //长宽和模型输入不一致,resize一次 resize_buf = malloc(height * width * channel); memset(resize_buf, 0x00, height * width * channel); src = wrapbuffer_virtualaddr((void*)img.data, img_width, img_height, RK_FORMAT_RGB_888); dst = wrapbuffer_virtualaddr((void*)resize_buf, width, height, RK_FORMAT_RGB_888); ret = imcheck(src, dst, src_rect, dst_rect); if (IM_STATUS_NOERROR != ret) { printf("%d, check error! %s", __LINE__, imStrError((IM_STATUS)ret)); return -1; } inputs[0].buf = resize_buf; // } else { inputs[0].buf = (void*)img.data; //存放图像数据 } gettimeofday(&start_time, NULL); //开始时间 rknn_inputs_set(ctx, io_num.n_input, inputs); //设置NPU的输入, rknn_output outputs[io_num.n_output]; //存放输出结果 memset(outputs, 0, sizeof(outputs)); for (int i = 0; i < io_num.n_output; i++) { outputs[i].want_float = 0; } ret = rknn_run(ctx, NULL); //使用模型推理 ret = rknn_outputs_get(ctx, io_num.n_output, outputs, NULL); //获得模型结果 gettimeofday(&stop_time, NULL); //结束时间 // 后处理 float scale_w = (float)width / img_width; float scale_h = (float)height / img_height; scale_w = (float)width / orig_img.cols; scale_h = (float)height / orig_img.rows; std::vector<float> out_scales; std::vector<int32_t> out_zps; for (int i = 0; i < io_num.n_output; ++i) { out_scales.push_back(output_attrs[i].scale); out_zps.push_back(output_attrs[i].zp); } //将模型推理的结果存放到detect_result_group post_process((int8_t*)outputs[0].buf, (int8_t*)outputs[1].buf, (int8_t*)outputs[2].buf, height, width, box_conf_threshold, nms_threshold, scale_w, scale_h, out_zps, out_scales, detect_result_group); ret = rknn_outputs_release(ctx, io_num.n_output, outputs); return 0; } /************************************************************************** 功能: 释放资源 参数说明 无 返回值: 0表示成功 ***************************************************************************/ int detect::rknn_envs_free(){ //释放资源 int ret = 0; // release ret = rknn_destroy(ctx); if (model_data) { free(model_data); } } 代码都比较简单,注释也比较详细。不懂的可以私聊博主。
detect类使用的时候,初始化一下环境,
detect.rknn_envs_init(detect.model_path);然后就可以使用NPU推理图像了,传入参数为openCV的Mat格式图像,结果保存在detect_result_group。
detect_result_group_t detect_result_group; detect.detect_image(orig_img, &detect_result_group);最后,就是将图像进行编码成h264格式、发送给rtmp服务器了,将关键代码贴出。
uint8_t *src_data[4]; int src_linesize[4]; //BGR24--->YUV420 av_image_fill_arrays(src_data, src_linesize, orig_img.data, AV_PIX_FMT_BGR24, orig_img.cols, orig_img.rows, 1); cv::Size frameSize = orig_img.size(); int cvLinesizes[1]; cvLinesizes[0] = orig_img.step1(); av_image_copy(h_video.rgbFrame->data, h_video.rgbFrame->linesize, (const uint8_t **)src_data, src_linesize, AV_PIX_FMT_BGR24, orig_img.cols, orig_img.rows); sws_scale(h_video.swsCtx, &orig_img.data, cvLinesizes, 0, height, h_video.yuvFrame->data, h_video.yuvFrame->linesize); h_video.yuvFrame->pts = i++; video_encode(&h_video.output_video_stream,h_video.codec_ctx, h_video.yuvFrame,h_video.pkt);video_encode代码在下面。
int video_encode(struct output_video_stream *out_stream,AVCodecContext *enc_ctx, AVFrame *frame, AVPacket *pkt) { int ret; /* send the frame to the encoder */ if (frame) printf("Send frame %lld\n", frame->pts); ret = avcodec_send_frame(enc_ctx, frame); if (ret < 0) { printf("Error sending a frame for encoding\n"); return -1; } while (ret >= 0) { ret = avcodec_receive_packet(enc_ctx, pkt); if (ret == AVERROR(EAGAIN) || ret == AVERROR_EOF){ return -1; } else if (ret < 0) { printf("Error during encoding\n"); return -1; } //推流 pkt->pts = av_rescale_q(pkt->pts,out_stream->stream->time_base,out_stream->stream->time_base); pkt->dts = av_rescale_q(pkt->dts,out_stream->stream->time_base,out_stream->stream->time_base); // 往输出流写入数据 av_interleaved_write_frame(out_stream->fmt_ctx, pkt); av_packet_unref(pkt); } } 整个项目做的都比较简陋,供大家学习参考吧,路过的大佬请轻喷,笔者只是个初学者。
代码部分参考了rk给的npu例子和网上各路大神的代码,在此一并感谢。
笔者编译用的是makefile进行编译程序,这里给出笔者的makefile部分,供小伙伴参考。
TARGET_NAME=app CPPFLAGS = -g -fpermissive -std=c++11 -Wall -static CPP = g++ CPPFILES = main.cpp video.cpp detect.cpp postprocess.cpp LDLIBS := LDLIBS_PATH:= INCS_PATH:= RKNN_LDLIBS = -ldl -lmpimmz -lrga -lrknn_api -lrknnrt RKNN_LDLIBS_PATH = -L./lib RKNN_INCS_PATH = -I./include OPENCV_LDLIBS = -lopencv_calib3d -lopencv_core -lopencv_dnn -lopencv_features2d -lopencv_flann -lopencv_gapi -lopencv_highgui -lopencv_imgcodecs -lopencv_imgproc -lopencv_ml -lopencv_objdetect -lopencv_photo -lopencv_stitching -lopencv_video -lopencv_videoio OPENCV_INCS_PATH = -I/usr/local/include/opencv4 FFMPEG_LDLIBS = -lavformat -lavdevice -lavcodec -lavutil -lswresample -lavfilter -lpostproc -lswscale -lSDL2 LDLIBS += $(FFMPEG_LDLIBS) $(OPENCV_LDLIBS) $(RKNN_LDLIBS) LDLIBS_PATH += -L/usr/local/lib $(RKNN_LDLIBS_PATH) INCS_PATH += $(OPENCV_INCS_PATH) -I/usr/local/include $(RKNN_INCS_PATH) all:$(TARGET_NAME) $(TARGET_NAME): $(CPP) -o ${TARGET_NAME} ${CPPFILES} ${INCS_PATH} ${LDLIBS_PATH} ${LDLIBS} @echo "end" clean: rm -rf *.o $(TARGET_NAME) 三、结果
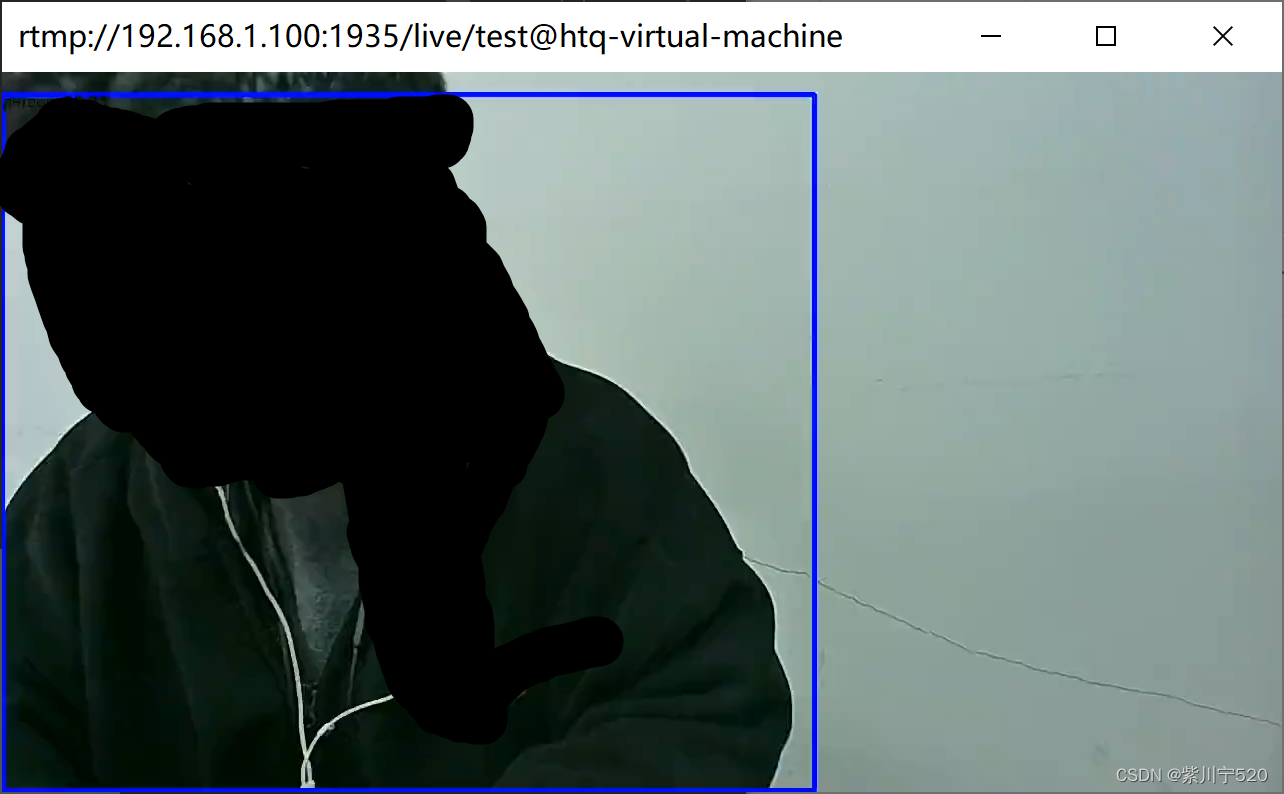
在rk3588上运行程序,输入./app "rtmp://192.168.1.100:1935/live/test" 。在Ubuntu上输入 ffplay rtmp://192.168.1.100:1935/live/test,测试效果。ffplay拉流界面
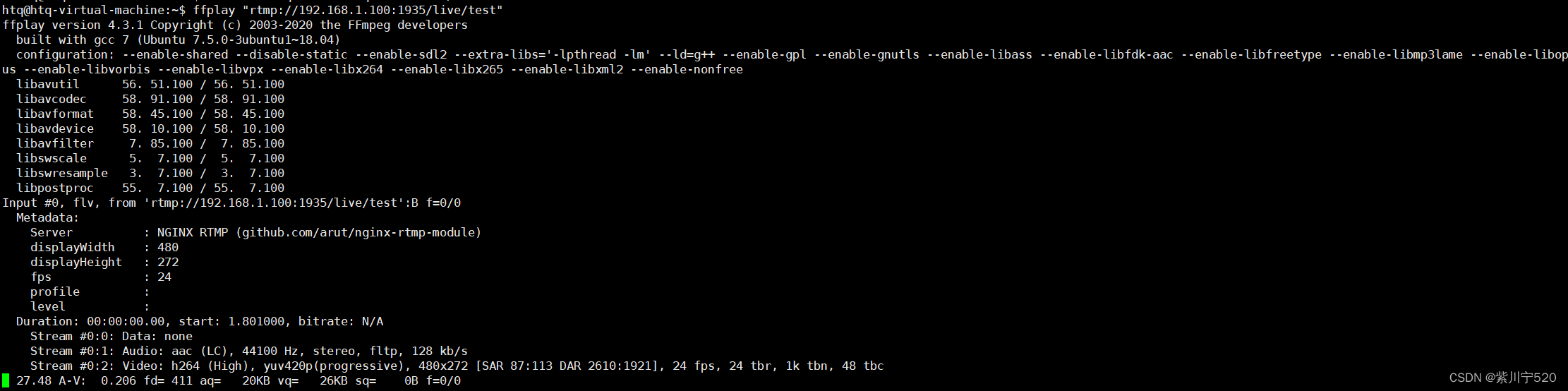
这里是远程显示的图像。蓝色的框框,是将识别到的人圈出来,用到的模型是之前训练出来的。
模型训练可以参考笔者之前的博文。
Yolo v5训练并移植到RK3588S平台_rk3588 yolov5_紫川宁520的博客-CSDN博客
总结:整个项目,从难度角度来看,其实都比较简单,没有用到特别复杂的东西,但牵扯到的东西比较多,有些很零碎,有些折腾起来很繁琐。程序运行的效果,只能说还行吧,有点卡顿,后面有时间再考虑优化的问题了。
