
阅读量:2
一文详解 Memcached
1.Memcached 简介
Memcached 是一个开源的,支持高性能,高并发的分布式内存缓存系统,由 C 语言编写,总共 2000 多行代码。从软件名称上看,前 3 个字符 Mem 就是内存的意思,而接下来的后面 5 个字符 cache 就是缓存的意思,最后一个字符 d,是 daemon 的意思,代表的是服务器端守护进程模式服务。
Memcached 服务分为服务器端和客户端两部分。其中,服务器端软件的名字形如 Memcached-1.4.24.tar.gz,客户端软件的名字形如 Memcache-2.25.tar.gz。
Memcached 软件诞生于 2003 年,最初由 LiveJournal 的 Brad Fitzpatrick 开发完成。Memcache 是整个项目的名称,而 Memcached 是服务器端的主程序名,因其协议简单,应用部署方便,且支持高并发,因此被互联网企业广泛使用,直到现在仍然如此。其官方网站地址:http://memcached.org/。
Memcached 的作用
传统场景中,多数 Web 应用都将数据保存到关系型数据库中(如 MySQL),Web 服务器从中读取数据并在浏览器中显示。但随着数据量增大、访问集中,关系型数据库的负担就会出现加重,响应缓慢,导致网站打开延迟等问题,影响用户体验。
这时就需要 Memcached 软件出马了。使用 Memcached 的主要目的是,通过在自身内存中缓存关系型数据库的查询结果,减少数据库被访问的次数,以提高动态 Web 应用的速度,提高网站架构的并发能力和可扩展性。
Memcached 服务的运行原理是通过在事先规划好的系统内存空间中临时缓存数据库中的各类数据,以达到减少前端业务服务对数据库的直接高并发访问,从而提升大规模网站集群中动态服务的并发访问能力。
生产场景的 Memcached 服务一般被用来保存网站中经常被读取的对象或数据,就像我们的客户端浏览器也会把经常访问的网页缓存起来一样,通过内存缓存来存取对象或数据要比磁盘存取快很多,因为磁盘是机械的。因此,在当今的 IT 企业中,Memcached 的应用范围很广泛。
互联网常见内存缓存服务软件
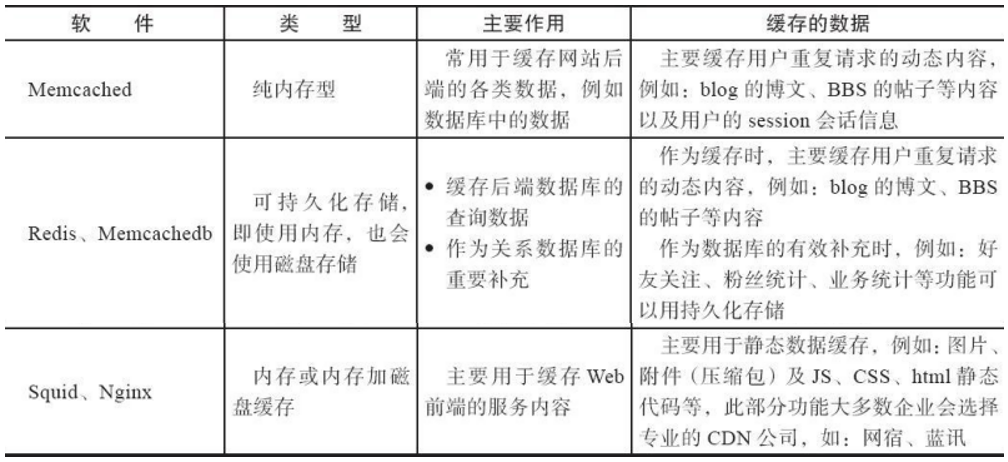
2.Memcached 的用户与应用场景
2.1 Memcached 常见用途工作流程
Memcached 是一种内存缓存软件,在工作中经常用来缓存数据库的查询数据,数据被缓存在事先与分配的 Memcached 管理的内存中,可以通过 API 或命令的方式存取内存中缓存的这些数据,Memcached 服务内存中缓存的数据就像一张巨大的 Hash 表,每条数据都是以 Key-Value 对的形式存在。
2.2 网站读取 Memcached 数据时工作流程
从逻辑上来说,当程序访问后端数据库获取数据时会优先访问 Memcached 缓存,如果缓存中有数据就直接返回给客户端用户,如果没有合适的数据(没有命中),再去后端的数据库读取数据,读取到需要的数据后,就会把数据返回给客户端,同时还会把读取到的数据缓存到 Memcached 内存中,这样客户端用户再次请求相同的数据时就会直接读取 Memcached 缓存的数据了,这就大大地减轻了后端数据库的压力,并提高了整个网站的响应速度,提升了用户体验。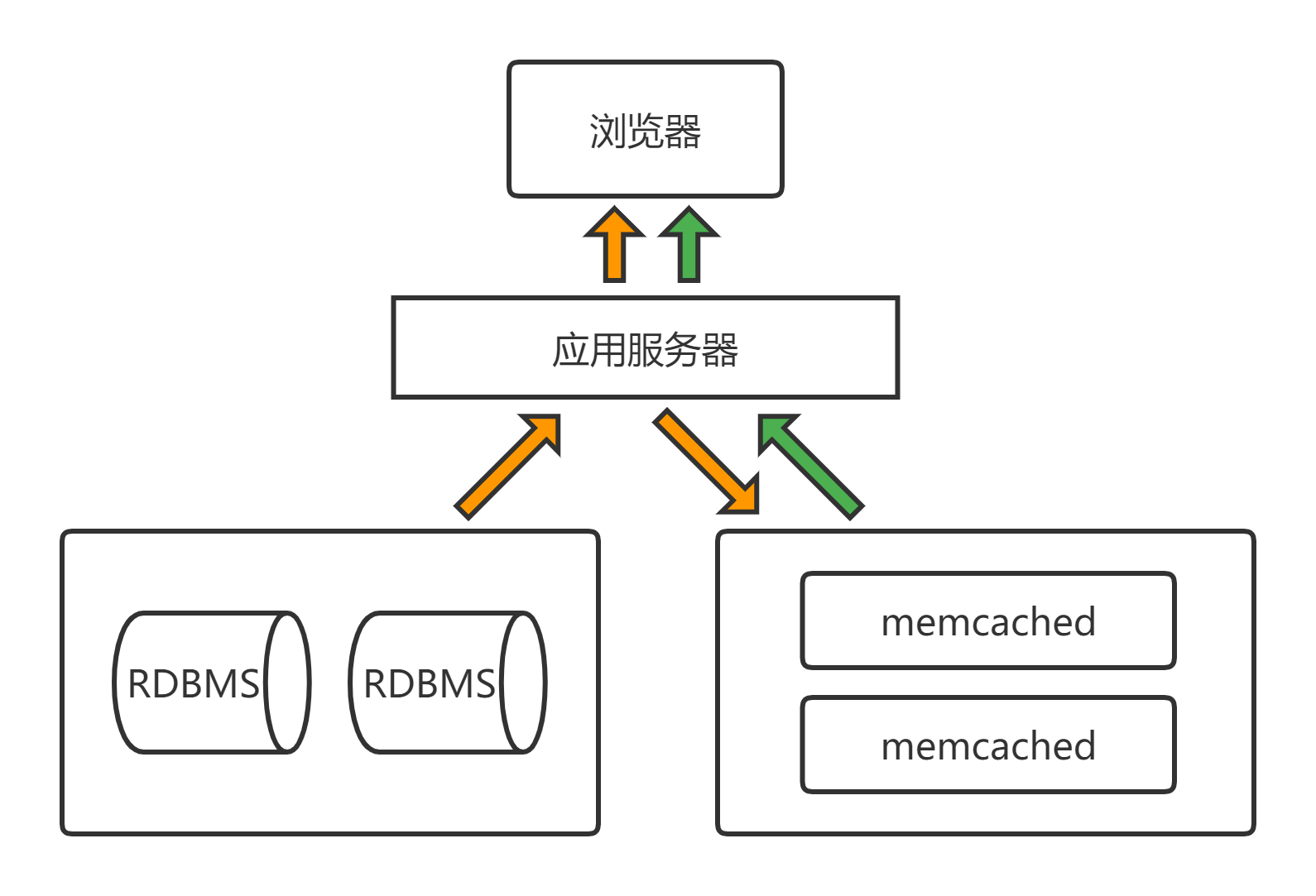
如上图所示:使用 Memcached 缓存查询的数据来减少数据库压力的具体工作流程如下:
- Web 程序首先检查客户端请求的数据是否在 Memcached 缓存中存在,如果存在,直接把请求的数据返回给客户端,此时不再请求后端数据库。
- 如果请求的数据在 Memcached 缓存中不存在,则程序会去请求数据库服务,把从数据库中取到的数据返回给客户端,同时把新取到的数据缓存一份到 Memcached 缓存中。
2.3 网站更新 Memcached 数据时的工作流程
(1)当程序更新或删除数据时,会首先处理后端数据库中的数据。
(2)在处理后端数据库中数据的同时,也会通知 Memcached,告诉它对应的旧数据失效,从而保证 Memcached 中缓存的数据始终和数据库中一致,这个 数据一致性 非常重要,也是大型网站分布式缓存集群最头疼的问题所在。
(3)如果是在高并发读写场合,除了要程序通知 Memcached 过期的缓存失效外,还可能要通过相关机制,例如在数据库上部署相关程序(如在数据库中设置触发器使用 UDFs),实现当数据库有更新时就把数据更新到 Memcached 服务中,这样一来,客户端在访问新数据时,因预先把更新过的数据库数据复制到 Memcached 中缓存起来了,所以可以减少第一次查询数据库带来的访问压力,提升 Memcached 中缓存的命中率,甚至新浪门户还会把持久化存储 Redis 做成 MySQL 数据库的从库,实现真正的主从复制。
下图为 Memcached 网站作为缓存应用更新数据的流程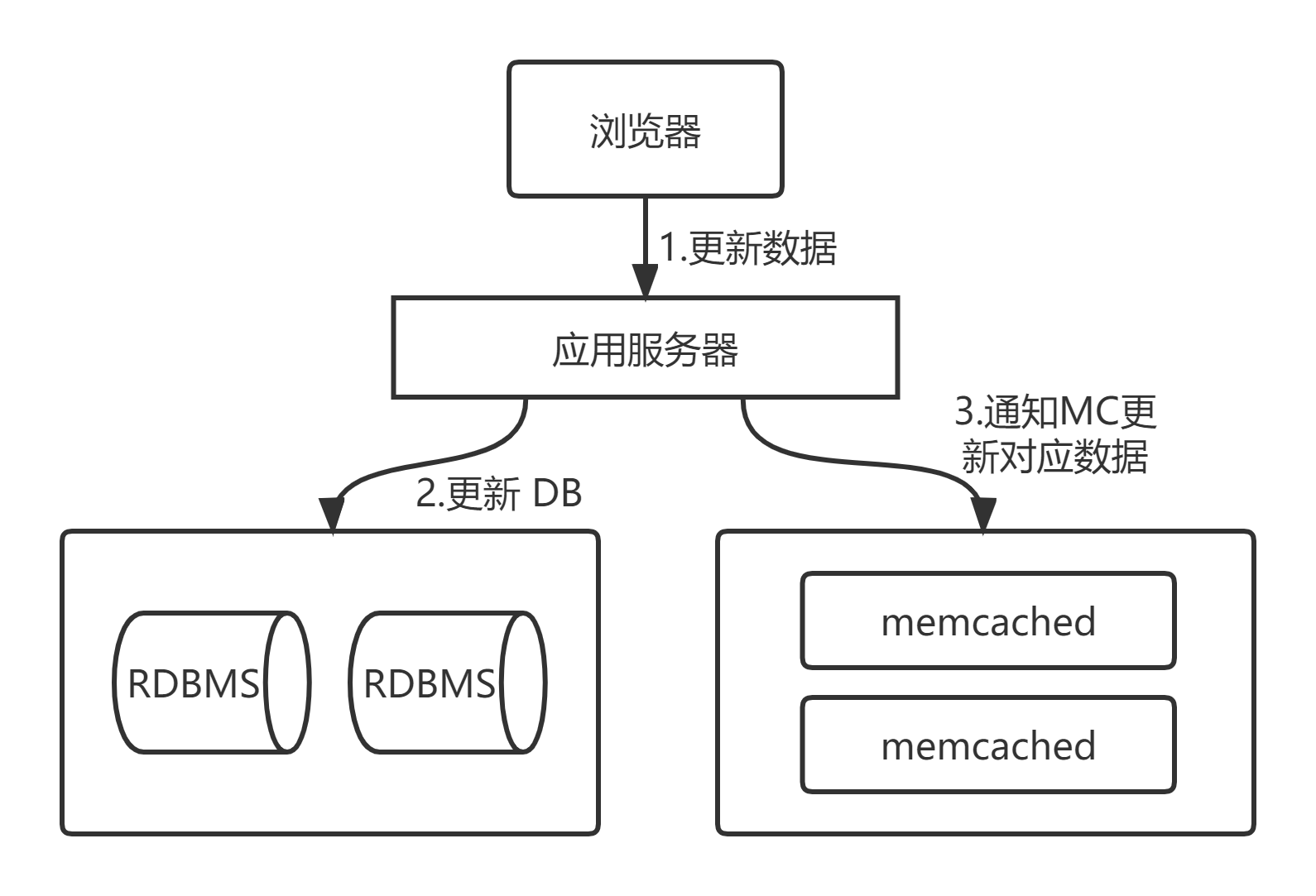
下图为 Memcached 服务作为缓存应用通过相关软件更新数据的流程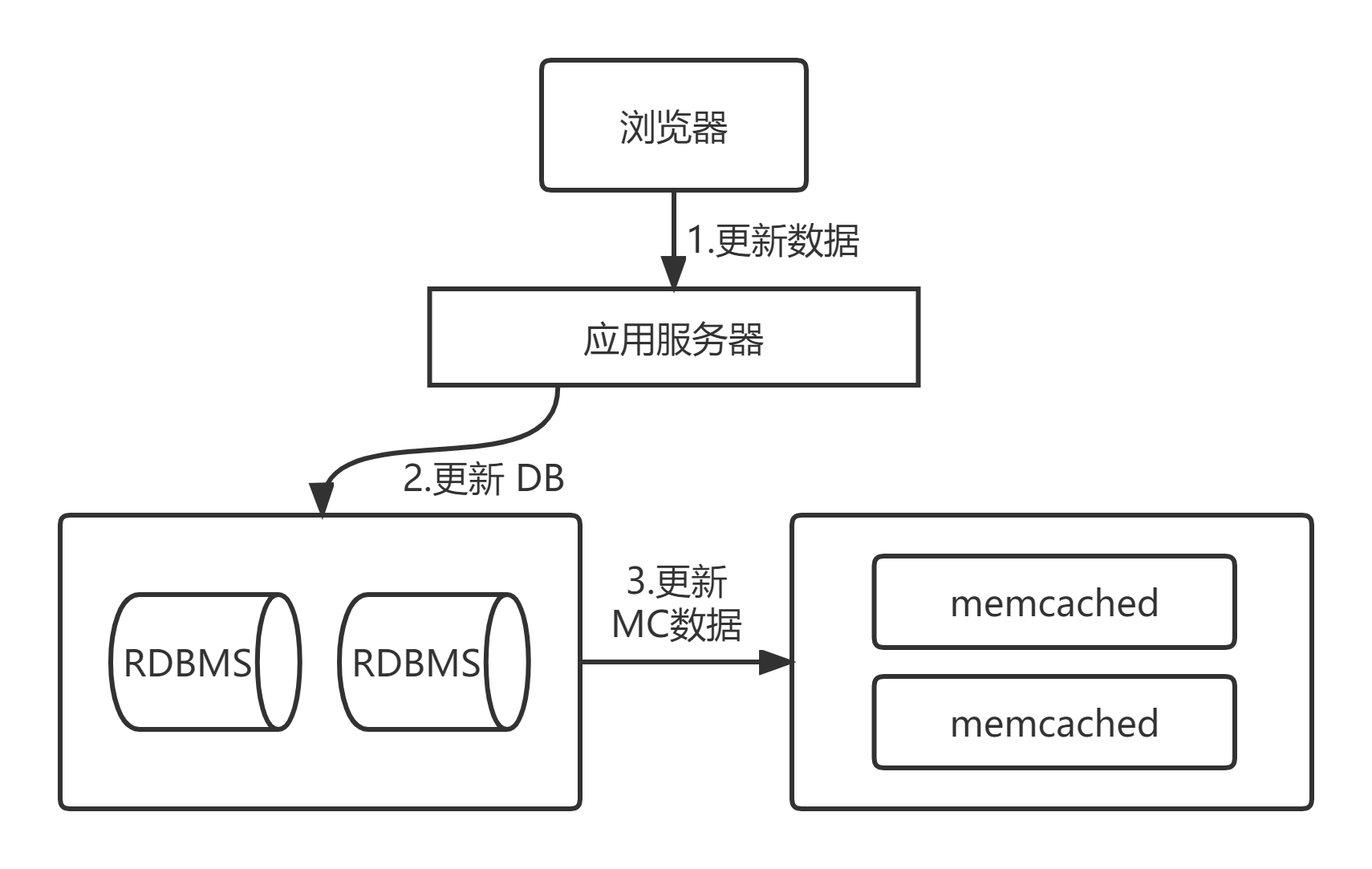
2.4 Memcached 在企业中的应用场景
2.4.1 作为数据库的查询数据缓存
(1)完整数据缓存
例如:电商的商品分类功能不是经常变动的,因此可以事先放到 Memcached 里,然后再对外提供数据访问。这个过程被称之为 数据预热。此时只需读取缓存,无需读取数据库就能得到 Memcached 缓存里的所有商品分类数据了,所以数据库的访问压力就会大大降低。
为什么商品分类数据可以事先放在缓存里呢?因为商品分类几乎都是由内部人员管理的,如果需要更新数据,更新数据库后,就可以把数据同时更新到 Memcached 里。如果把商品分类数据做成静态化文件,然后通过在前端 Web 缓存或者使用 CDN 加速效果更好。
(2)热点数据缓存
热点数据缓存一般是用于由用户更新的商品,例如淘宝的卖家,在卖家新增商品后,网站程序就会把商品写入后端数据库,同时把这部分数据,放入 Memcached 内存中,下一次访问这个商品的请求就直接从 Memcached 内存中取走了。这种方法用来缓存网站热点的数据,即利用 Memcached 缓存经常被访问的数据。
注:这个过程可以通过程序实现,也可以在数据库上安装相关软件进行设置,直接由数据库把内容更新到 Memcached 中,就相当于 Memcached 是 MySQL 的从库一样。
- 如果碰到电商双 11,秒杀高并发的业务场景,必须要事先预热各种缓存,包括前端的 Web 缓存和后端的数据库缓存。也就是先把数据放入内存预热,然后逐步动态更新。此时,会先读取缓存,如果缓存里没有对应的数据,再去读取数据库,然后把读到的数据放入缓存。如果数据库里的数据更新,需要同时触发缓存更新,防止给用户过期的数据,当然对于百万级别并发还有很多其他的工作要做。
- 绝大多数的网站动态数据都是保存在数据库当中的,每次频繁地存取数据库,会导致数据库性能急剧下降,无法同时服务更多的用户(比如 MySQL 特别频繁的锁表就存在此问题),那么,就可以让 Memcached 来分担数据库的压力。增加 Memcached 服务的好处除了可以分担数据库的压力以外,还包括无须改动整个网站架构,只须简单地修改下程序逻辑,让程序先读取 Memcached 缓存查询数据即可,当然别忘了,更新数据时也要更新 Memcached 缓存。
2.4.2 作为集群节点的 Session 会话共享存储
即把客户端用户请求多个前端应用服务集群产生的 Session 会话信息,统一存储到一个 Memcached 缓存中。由于 Session 会话数据是存储在内存中的,所以速度很快。
下图为 Memcached 服务在企业集群架构中的常见工作位置:
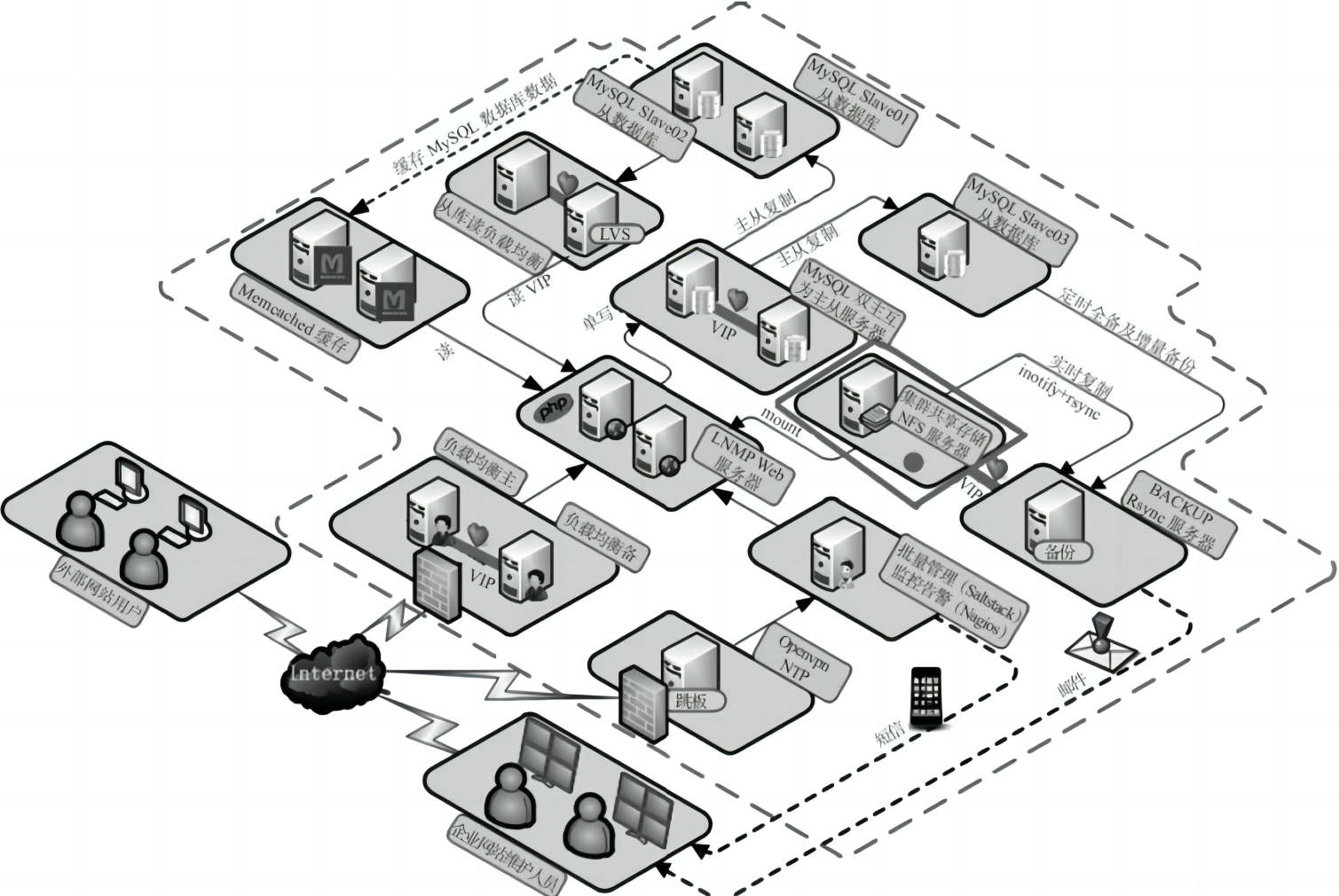
3.Memcached 的特点与工作机制
3.1 Memcached 的特点
- 协议简单。Memcached 的协议实现很简单,采用的是基于文本行的协议,能通过 telnet / nc 等命令直接操作 Memcached 服务存储数据。
- 支持 epoll / kqueue 异步 I/O 模型,使用 libevent 作为事件处理通知机制。简单的说,libevent 是一套利用 C 开发的程序库,它将 BSD 系统的 kqueue,Linux 系统的 epoll 等事件处理功能封装成一个接口,确保即使服务器端的连接数增加也能发挥很好的性能。Memcached 就是利用这个 libevent 库进行异步事件处理的。
- 采用 key / value 键值数据类型。被缓存的数据以 key / value 键值形式存在。
- 全内存缓存,效率高。Memcached 管理内存的方式非常高效,即全部的数据都存放于 Memcached 服务事先分配好的内存中,无持久化存储的设计,和系统的物理内存一样,当重启系统或 Memcached 服务时,Memcached 内存中的数据就会丢失。如果希望重启后,数据依然能保留,那么就可以采用 Redis 这样的持久性内存缓存系统。
- 当内存中缓存的数据容量达到服务启动时设定的内存值时,就会自动使用 LRU 算法(最近最少被使用的)删除过期的缓存数据。也可以在存放数据时对存储的数据设置过期时间,这样过期后数据就自动被清除,Memcached 服务本身不会监控数据过期,而是在访问的时候查看 key 的时间戳判断是否过期。
- 可支持分布式集群。Memcached 没有像 MySQL 那样的主从复制方式,分布式 Memcached 集群的不同服务器之间是互不通信的,每一个节点都独立存取数据,并且数据内容也不一样。通过对 Web 应用端的程序设计或者通过支持 Hash 算法的负载均衡软件,可以让 Memcached 支持大规模海量分布式缓存集群应用。
3.2 Memcached 工作原理与机制
3.2.1 Memcached 工作原理
Memcached 是一套类似 C/S 模式架构的软件,在服务器端启动 Memcached 服务守护进程,可以指定监听本地的IP地址,端口号,并发访问连接数,以及分配了多少内存来处理客户端请求。
3.2.2 Socket 时间处理机制
Memcached 软件是由 C 语言来实现的,全部代码仅有 2000 多行,采用的是异步 epoll / kqueue 非阻塞 I/O 网络模型,其实现方式是基于异步的 libevent 事件单进程,单线程模式。使用 libevent 作为事件通知机制,应用程序端通过指定服务器的 IP 地址及端口,就可以连接 Memcached 服务进行通信。
3.2.3 数据存储机制
需要被缓存的数据以 key / value 键值对的形式保存在服务器端预分配的内存区中,每个被缓存的数据都有唯一的标识 key,操作 Memcached 中的数据就是通过这个唯一标识的 key 进行的。缓存到 Memcached 中的数据仅放置在 Memcached 服务预分配的内存中,而非存储在 Memcached 服务器所在的磁盘上,因此存取速度非常快。
由于 Memcached 服务自身没有对缓存的数据进行持久化存储的涉及,因此,在服务器端的 Memcached 服务进程重启之后,存储在内存中的这些数据就会丢失。且当内存中缓存的数据容量达到启动时设定的内存值时,也会自动使用 LRU 算法删除过期的数据。
开发 Memcached 的初衷仅是通过内存缓存提升访问效率,并没有过多考虑数据的永久存储问题。因此,如果使用 Memcached 作为缓存数据服务,要考虑数据丢失后带来的问题,例如:是否可以重新生成数据,还有,在高并发场合下缓存宕机或重启会不会导致大量请求直接到数据库,导致数据库无法承受,最终导致网站架构雪崩等。
3.2.4 内存管理机制
- 采用 Slab 内存分配机制
- 采用 LRU 对象清除机制
- 采用 Hash 机制快速检索 Item
3.2.5 多线程处理机制
- 多线程处理时采用的是 pthread(POSIX)线程模式。
- 若要激活多线程,可在编译时指定:
./configure --enable-threads - 锁机制不够完善
- 负载过重时,可以开启多线程(-t 线程数为CPU核数)
3.3 Memcached 预热理念及集群节点的正确重启方法
当需要大面积重启 Memcached 时,首先要在前端控制网站入口的访问流量,然后,重启 Memcached 集群并进行数据预热,所有数据都预热完毕之后,再逐步放开前端网站入口的流量。
为了满足 Memcached 服务数据可以持久化存储的需求,在较早时期,新浪网基于 Memcached 服务开发了一款 NoSQL 软件,名字为 MemcacheDB,实现了在缓存的基础上增加了持久存储的特性,不过目前逐步被更优秀的 Redis 软件取代了。
如果由于机房断电或者搬迁服务器集群到新机房,那么启动集群服务器时,一定要从网站集群的后端依次往前端开启,特别是开启 Memcached 缓存服务器时要提前预热。
4.Memcached 内存管理
4.1 Memcached 内存管理机制解析
4.1.1 malloc 内存管理机制
在讲解 Memcached 内存管理机制前,先来了解 malloc。malloc 的全称是 memory allocation,即动态内存分配,当无法知道内存具体位置的时候,想要绑定真正的内存空间,就需要用到动态分配内存。
早期的 Memcached 内存管理是通过 malloc 分配内存实现的,使用完后通过 free 来回收内存。这种方式容易产生内存碎片并降低操作系统对内存的管理效率。因此,也会加重操作系统内存管理器的负担,最坏的情况下,会导致操作系统比 Memcached 进程本身还慢,为了解决上述问题,Slab Allocator 内存分配机制就诞生了。
4.1.2 Slab 内存管理机制
现在的 Memcached 是利用 Slab Allocation 机制来分配和管理内存的,过程如下:
提前将大内存分配大小为 1MB 的若干个 slab,然后针对每个 slab 再进行小对象填充,这个小对象称为 chunk,避免大量重复的初始化和清理,减轻了内存管理器的负担。
Slab Allocation 内存分配的原理是按照预先规定的大小,将分配给 Memcached 服务的内存预先分割成特定长度的内存块(chunk),再把尺寸相同的内存块(chunk)分成组(chunks slab class),这些内存块不会释放,可以重复利用,如下图所示。

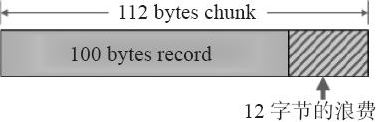
新增数据对象存储时。因 Memcached 服务器中保存着 slab 内空闲 chunk 的列表,他会根据该列表选择 chunk,然后将数据缓存于其中。当有数据存入时,Memcached 根据接收到的数据大小,选择最适合数据大小的 slab 分配一个能存下这个数据的最小内存块(chunk)。例如:有 100 字节的一个数据,就会被分配存入下面 112 字节的一个内存块中,这样会有 12 字节被浪费,这部分空间就不能被使用了,这也是 Slab Allocator 机制的一个缺点。
4.1.3 Slab Allocation 的主要术语
| Slab Allocation 主要术语 | 注解说明 |
|---|---|
| slab class | 内存区类别(48 byte - 1MB) |
| slab | 动态创建的实际内存区,即分配给 Slab 的内存空间,默认是 1MB。分配给 Slab 之后根据 slab 的大小切分成 chunk。slab 默认大小为 1048576 byte (1MB)。大于 1MB 的数据会忽略 |
| slab classid | Slab class 的 ID |
| chunk | 数据区块,固定大小,chunk 初始大小,1.4 版本中是 48 bytes |
| item | 实际存储在 chunk 中的数据项 |
4.1.4 Slab 内存管理机制特点
提前分配大内存 Slab 1MB,再进行小对象填充 chunk。
避免大量重复的初始化和清理,减轻内存管理器负担。
避免频繁 malloc / free 内存分配导致的碎片。
4.1.5 MC 内存管理机制小结
MC 的早期内存管理机制为 malloc(动态内存分配)。
malloc(动态内存分配)产生内存碎片,导致操作系统性能急剧下降。
Slab 内存分配机制可以解决内存碎片的问题。
Memcached 服务的内存预先分割成特定长度的内存块,称为 chunk,用于缓存数据的内存空间或内存块,相当于磁盘的 block,只不过磁盘的每一个 block 都是相等的,而 chunk 只有在同一个 Slab Class 内才是相等的。
Slab Class 指特定大小(1MB)的包含多个 chunk 的集合或组,一个 Memcached 包含多个 Slab Class,每个 Slab Class 包含多个相同大小的 chunk。
Slab 机制也有缺点,例如,Chunk 的空间会有浪费等。
4.2 Memcached Slab Allocator 内存管理机制的缺点
(1)chunk 存储 item 浪费空间
Slab Allocator 解决了当初的内存碎片问题,但新的机制也给 Memcached 带来了新的问题。这个问题就是,由于分配的是特定长度的内存,因此无法有效利用分配的内存。例如,将 100 字节的数据缓存到 128 字节的 chunk 中,剩余的 28 字节就浪费了,如下图所示:
避免浪费内存的办法是,预先计算出应用存入的数据大小,或把同一业务类型的数据存入一个 Memcached 服务器中,确保存入的数据大小相对均匀,这样就可以减少内存的浪费。
还有一种办法是,在启动时指定 -f 参数,能在某种程度上控制内存组之间的大小差异。在应用中使用 Memcached 时,通常可以不重新设置这个参数,即使用默认值 1.25 进行部署即可。如果想优化 Memcached 对内存的使用,可以考虑重新计算数据的预期平均长度,调整这个参数来获得合适的设置值,命令如下:
-f <factor>chunk size growth factor (default:1.25)! (2)Slab 尾部剩余空间
假设在 classid=40 中,两个 chunk 占用了 1009384 byte,那么就有 1048576 - 1009384 = 39192 byte 会被浪费掉。解决办法:规划 slab 大小 = chunk 大小 * n 整数倍。
4.3 使用 Growth Factor 对 Slab Allocator 内存管理机制调优
在启动 Memcached 时指定 Growth Factor 因子(通过 -f 选项),就可以在某种程度上控制每组 Slab 之间的差异。默认值 1.25。但是,在该选项出现之前,这个因子曾经被固定为 2。让我们用以前的设置,以 verbose 模式启动 Memcached 试试看:
memcached -f 2 w 启动后的 verbose
slab class 1:chunk size 128 perslab 8192 slab class 2:chunk size 256 perslab 4096 slab class 3:chunk size 512 perslab 2048 slab class 4:chunk size 1024 perslab 1024 slab class 5:chunk size 2048 perslab 512 slab class 6:chunk size 4096 perslab 256 slab class 7:chunk size 8192 perslab 128 slab class 8:chunk size 16384 perslab 64 slab class 9:chunk size 32768 perslab 32 slab class 10:chunk size 65536 perslab 16 slab class 11:chunk size 131072 perslab 8 slab class 12:chunk size 262144 perslab 4 slab class 13:chunk size 524288 perslab 2 可见,从 128 字节的组开始,组的大小依次增大为原来的 2 倍。这样设置的问题是,Slab 之间的差别比较大,有些情况下就相当浪费内存。因此,为尽量减少内存浪费,两年前追加了 growth factor 这个选项。
来看看现在的默认设置(f=1.25)时的输出:
slab class 1:chunk size 88 perslab 11915 <---88*11915=1048520 slab class 2:chunk size 112 perslab 9362 slab class 3:chunk size 144 perslab 7281 slab class 4:chunk size 184 perslab 5698 slab class 5:chunk size 232 perslab 4519 slab class 6:chunk size 296 perslab 3542 slab class 7:chunk size 376 perslab 2788 slab class 8:chunk size 472 perslab 2221 slab class 9:chunk size 592 perslab 1771 slab class 10:chunk size 744 perslab 1409 <---744*1409=1048520 此时每个 Slab 的大小是一样的,即 1048520,1MB。组间的差距比因子为 2 时小得多,可见,这个值越小,Slab 中 chunk size 的差距就越小,内存浪费也就越小。可见,默认值 1.25 更适合缓存几百字节的对象。从上面的输出结果来看,可能会觉得有些计算误差,这些误差是为了保持字节数的对齐而故意设置的。
当使用 Memcached 或是直接使用默认值进行部署时,最好是重新计算一下数据的预期平均长度,调整 growth factor,以获得最恰当的设置。内存是珍贵的资源,浪费就太可惜了。
4.4 Memcached 的检测过期与删除机制
(1)Memcached 懒惰检测对象过期机制
首先要知道,Memcached 不会主动检测 item 对象是否过期,而是在进行 get 操作时检查 item 对象是否过期以及是否应该删除!
因为不会主动检测 item 对象是否过期,自然也就不会释放已分配给对象的内存空间了,除非为添加的数据设定过期时间或内存缓存满了,在数据过期后,客户端不能通过 key 取出它的值,其存储空间将被重新利用。
Memcached 使用的这种策略为 懒惰检测对象过期策略,即自己不监控存入的 key / value 对是否过期,而是在获取 key 值时查看记录的时间戳(sed key flag exptime bytes),从而检查 key / value 对空间是否过期。这种策略不会在过期检测上浪费 CPU 资源。
(2)Memcached 懒惰删除对象机制
当删除 item 对象时,一般不会释放内存空间,而是做删除标记,将指针放入 slot 回收插槽,下次分配的时候直接使用。
Memcached 在分配空间时,会优先使用已经过期的 key / value 对空间;若分配的内存空间占满,Memcached 就会使用 LRU 算法来分配空间,删除最近最少使用的 key / value 对,从而将其空间分配给新的 key / value 对。在某些情况下(完整缓存),如果不想使用 LRU 算法,那么可以通过 -M 参数来启动 Memcached,这样,Memcached 在内存耗尽时,会返回一个报错信息,如下:
-M rerurn error on memory exhausted(rather than removing items) (3)下面针对 Memcached 删除机制进行一个小结
- 不主动检测 item 对象是否过期,而是在 get 时才会检查 item 对象是否过期以及是否应该删除。
- 当删除 item 对象时,一般不释放内存空间,而是做删除标记,将指针放入 slot 回收插槽,下次分配的时候直接使用。
- 当内存空间满的时候,将会根据 LRU 算法把最近最少使用的 item 对象删除。
- 数据存入可以设定过期时间,但是数据过期后不会被立即删除,而是在 get 时检查 item 对象是否过期以及是否应该删除。
- 如果不希望系统使用 LRU 算法清除数据,可以用使用
-M参数。
