
阅读量:0
文章目录
1. 文件描述符为什么从3开始使用?
修改test.c文件内容
#include<sys/types.h> #include<sys/stat.h> #include<fcntl.h> #include<stdio.h> #include<unistd.h> #include<errno.h> #include<string.h> #define LOG "log.txt" int main() { umask (0);//将权限掩码设置成0 int fd=open(LOG, O_RDONLY );//打开一个文件,若文件不存在则重新创建一个 if(fd==-1)//说明打开失败 { printf("fd:%d,errno:%d,errstring:%s\n",fd,errno,strerror(errno));//打印出错误信息 } else printf("fd :%d\n", fd); char buffer[1024]; ssize_t n= read(fd,buffer,sizeof(buffer)-1);//使用系统接口来进行IO的时候,一定要注意\0的问题 if(n>0)//成功了,实际读到了多少字节 { buffer[n]='\0'; printf("%s\n",buffer); } close(fd); //关闭文件 return 0; } 运行可执行程序,发现文件描述符返回的是3

但为啥是3,不是0 ,1,2
任何一个进程,在启动的时候,默认会打开当前进程的三个文件:
标准输入、标准输出、标准错误 ——本质都是文件
C语言:标准输入(stdin) 标准输出(stdout) 、标准错误(stderr) ——文件在系统层的表现
C++: 标准输入(cin) 标准输出(cout) 、标准错误(cerr) ——文件在系统层的表现,它是一个类
因为Linux下一切皆文件,所以向显示器打印,本质就是向文件中写入
标准输入—设备文件—>键盘文件
标准输出—设备文件—> 显示器文件
标准错误—设备文件—> 显示器文件
创建test.cc文件(cc后缀即cpp代码)
#include<iostream> #include<cstdio>//写C++时,使用C++风格的C语言代码 int main() { //C语言 printf("hello printf->stdout\n");//向stdout进行输出 fprintf(stdout,"hello printf->stdout\n ");//将数据向stdout进行输出 fprintf(stderr,"helllo printf->stderr\n");//将数据向标准错误打印 //C++ std::cout<<"hello cout->cout"<<std::endl;//表示标准输出 std::cerr<<"hello cerr->cerr"<<std::endl;//向标准错误中打印数据 return 0; } 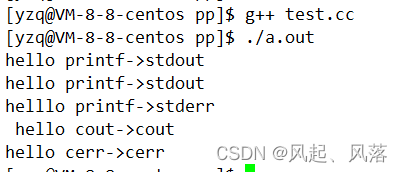
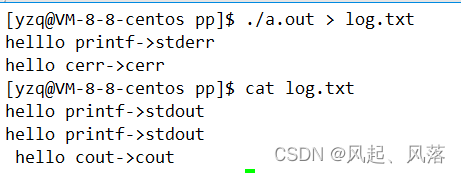
输出重定向是将标准输出重定向,此时log.txt文件中只会存在标准输出的内容
所以标准输出和标准错误都会向显示器打印,但是其实是不一样的
0默认对应标准输入,1默认对应标准输出、2默认对应标准错误
修改myfile.c文件内容
#include<sys/types.h> #include<sys/stat.h> #include<fcntl.h> #include<stdio.h> #include<unistd.h> #include<errno.h> #include<string.h> #define LOG "log.txt" int main() { int fd1=open(LOG,O_WRONLY |O_CREAT | O_TRUNC,0666); int fd2=open(LOG,O_WRONLY |O_CREAT | O_TRUNC,0666); int fd3=open(LOG,O_WRONLY |O_CREAT | O_TRUNC,0666); int fd4=open(LOG,O_WRONLY |O_CREAT | O_TRUNC,0666); int fd5=open(LOG,O_WRONLY |O_CREAT | O_TRUNC,0666); int fd6=open(LOG,O_WRONLY |O_CREAT | O_TRUNC,0666); printf("%d\n",fd1); printf("%d\n",fd2); printf("%d\n",fd3); printf("%d\n",fd4); printf("%d\n",fd5); printf("%d\n",fd6); return 0; } 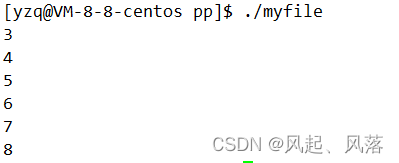
运行可执行程序,发现 打印结果为 3 4 5 6 7 8
因为 标准输入、标准输出、标准错误分别占用了0 、1、2,所以只能从3开始
文件描述符(open对应的返回值)本质就是数组的下标
2. 文件描述符本质理解
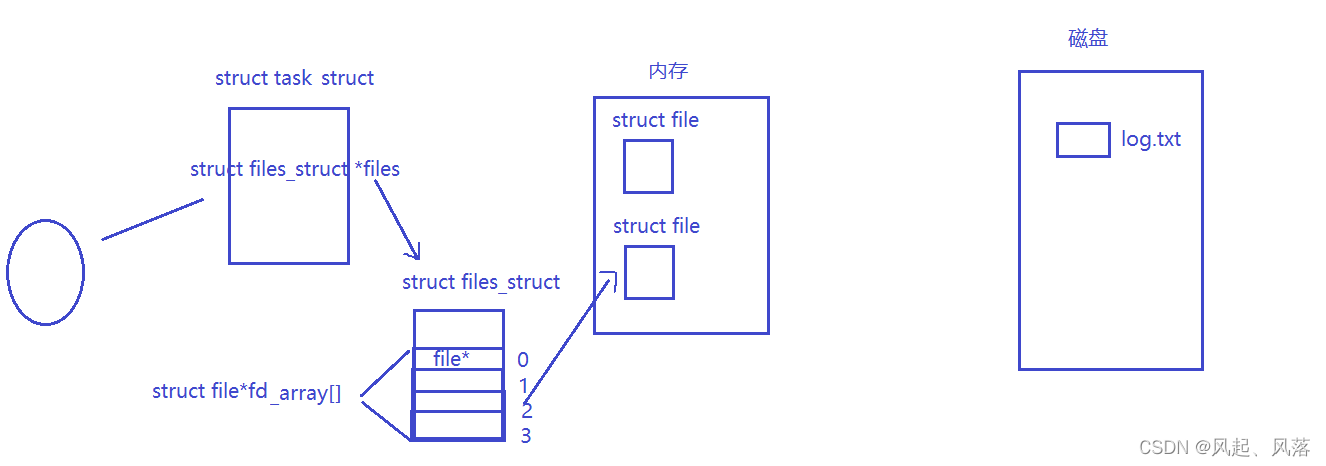
启动代码时就会变成一个进程,该进程在内核中就必须有自己的数据结构 struct task_struct,
称之为当前进程所对应的进程描述符
打开文件时,操作系统会把文件加载到内存里,以供CPU通过进程的方式来访问对应的文件
任何一个进程,在启动的时候,默认会打开进程的三个文件,系统中一定会存在大量被打开的文件,这些文件一定会被操作系统管理起来,通过先描述,在组织,创建 struct file 结构体,该结构体一定包含文件属性等,每一次创建并打开文件时,都是在内核中创建一个struct file的结构体
目前认为只要找到file,就可以找到所有文件内容
为了维护一个进程和多个文件的映射关系,在内核中定义了数据结构struct files_struct,该结构体内部有一个数组struct file* fd [ ] ,是一个内容为struct file*的数组
当进程初始化时,会创建struct files_struct 结构体,通过结构体找到数组,只要有数组一定有下标
3. 如何理解Linux下的一切皆文件?

内存把数据写到显示器上,属于写入的过程,读取是从键盘中读取的,键盘输入后,操作系统把输入的数据回显到显示器上了,所以显示器只能负责打印
不同的硬件所对应的方法是完全不一样的,打开键盘时,操作系统内部会创建struct file对象

将键盘的read方法和 write方法 保存到函数指针中
每一个设备也只需要把方法的地址放入函数指针中
在当前进程看来,所有的东西都是文件对象,要有数据放到缓冲区里,底层读写时只需要调用对应的方法,来完成对应的读写,不关心底层的差异化
操作系统也有自己的wirte和read,本质上是拷贝,将应用层的数据拷贝到缓冲区里,在调用底层不同设备的方法,所以看起来就是Linux下一切皆文件
4. FILE是什么,谁提供?和内核的struct有关系么?
操作系统层面,必须要访问fd,才能找到文件
任何语言层访问外设或者文件必须经历操作系统
FILE *fopen(const char *path, const char *mode);
FILE是一个结构体,FILE由C语言提供的
C语言动态库
C语言头文件
证明struct FILE结构体中存在文件描述符fd
#include<sys/types.h> #include<sys/stat.h> #include<fcntl.h> #include<stdio.h> #include<unistd.h> #include<errno.h> #include<string.h> #define LOG "log.txt" int main() { printf("%d\n",stdin->_fileno);//fileno代表文件描述符 printf("%d\n",stdout->_fileno); printf("%d\n",stderr->_fileno); FILE*fp=fopen(LOG,"w"); printf("%d\n",fp->_fileno); return 0; } 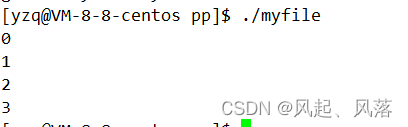
说明结构体struct FILE内部存在文件描述符
同时因为0 1 2 被占用了,所以我们自己写的文件描述符返回3
5. 重定向的本质
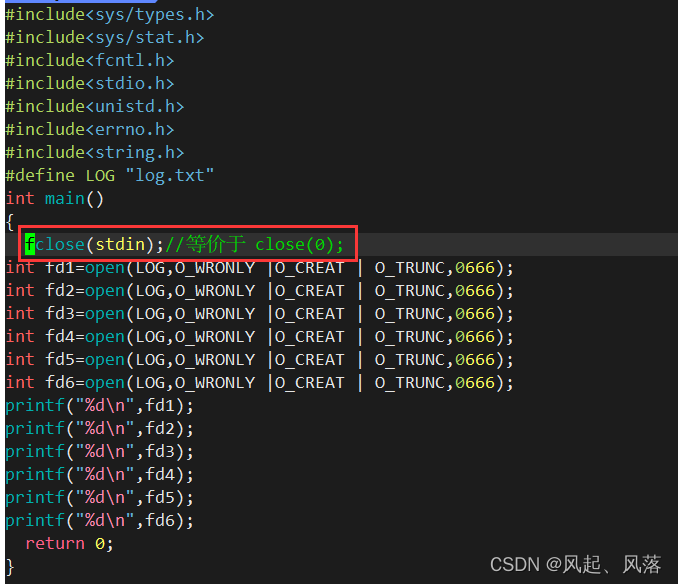
关闭文件描述符0后,发现从0开始可以被输出了

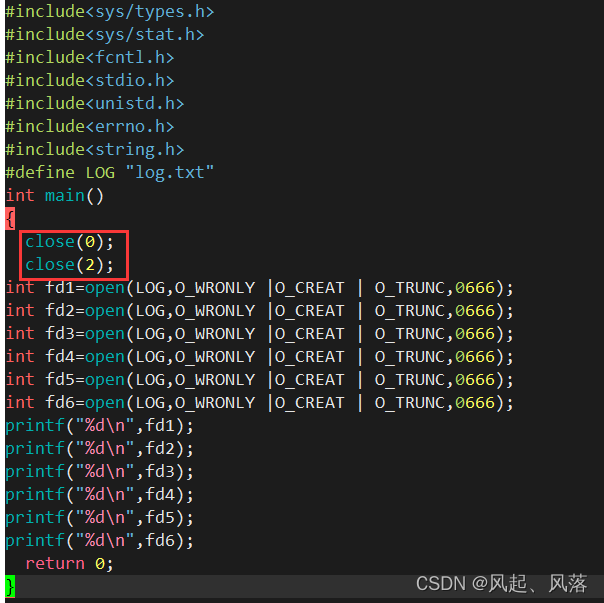
关闭文件描述符0和2后,发现0和2都可以被使用了

进程中,文件描述符的分配规则:在文件描述符表中,最小的,没有被使用的数组元素分配给新文件
输出重定向
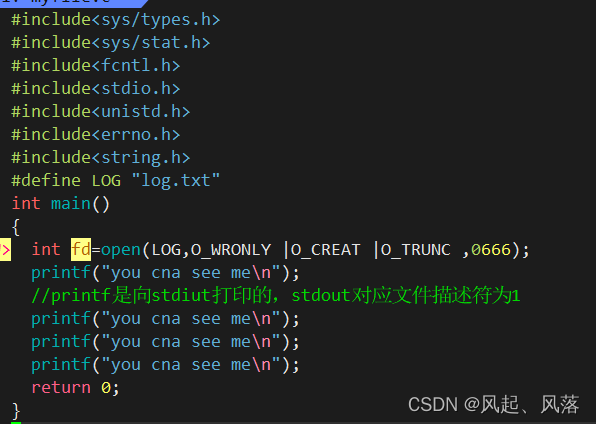
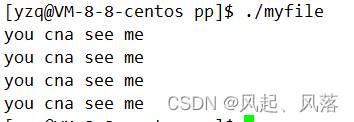
若不关闭文件描述符1,当前printf打印的结果显示到显示器上面
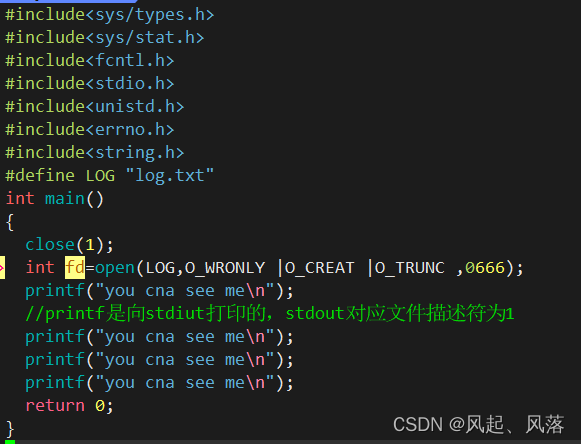
关闭文件描述符1,再打开新的文件log.txt
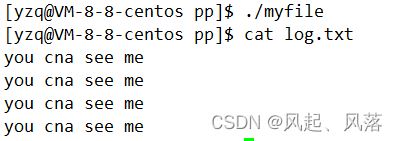
此时运行可执行程序没有显示出you can see me,打开新文件发现本来应该打印到显示器的内容,打印到log.txt中了
本来应该打印到显示器上的内容,打印到文件里 ,这种现象叫做重定向
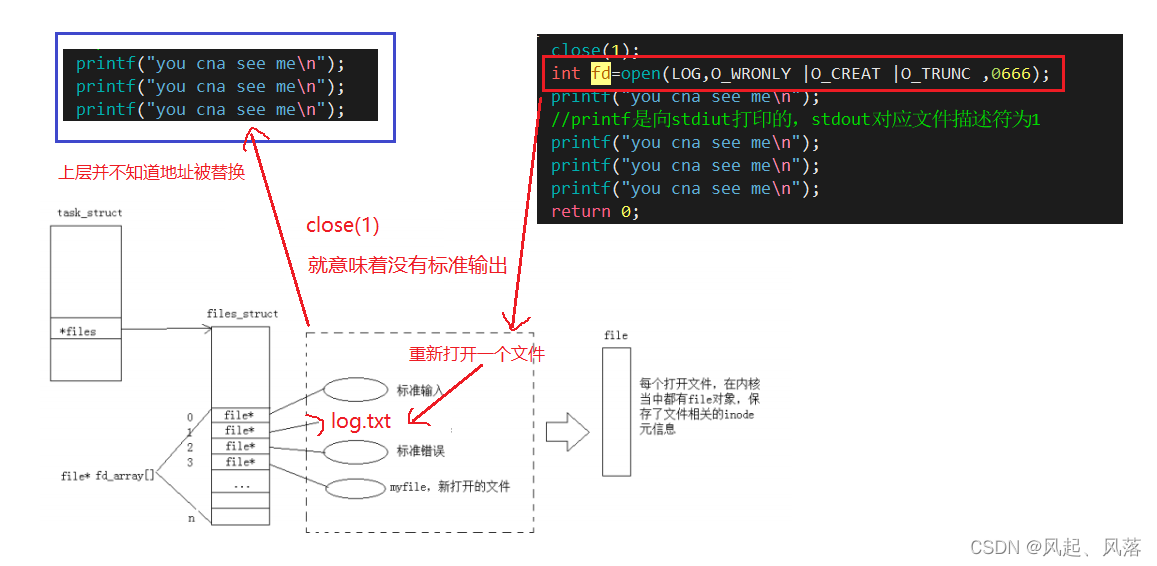
在文件描述符表中,最小的,没有被使用的数组元素分配给新文件,所以把文件描述符1分配给了log.txt
1号下标里面的地址填成了log.txt文件的地址,上层printf打印它知道吗?
不知道,它也不关心,它只认文件描述符1
重定向的原理:在上层无法感知的情况下,在OS内部 ,更改进程内部对应的文件描述符表中,特定下标的指向
输入重定向
先在log.txt文件中输入内容 123 456
修改myfile.txt文件内容
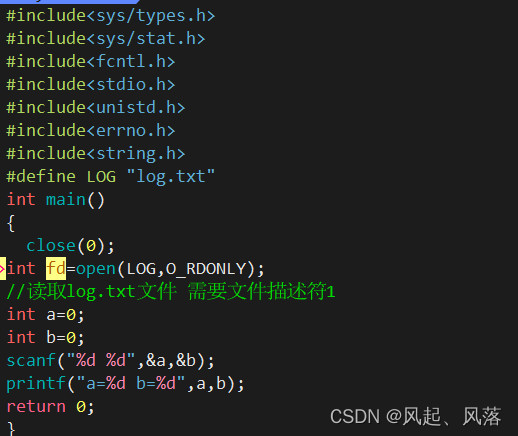
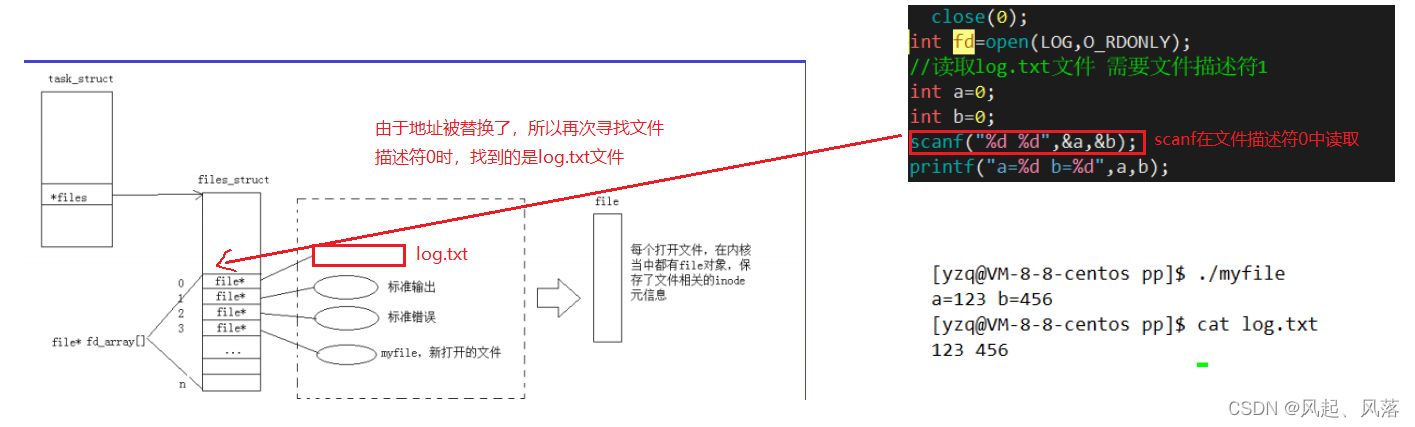
关闭文件描述符0,所以scanf读取时会读取log.txt文件中的内容
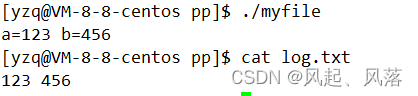
读取的内容与log.txt文件内容相同
本来要从键盘中读取,结果现在要在文件中读取,这叫做输入重定向
追加重定向
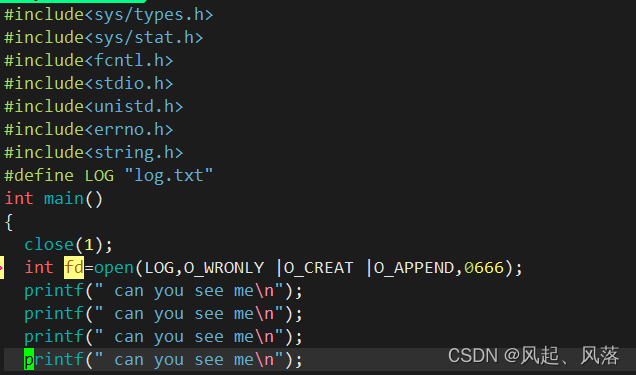
关闭文件描述符1后,导致printf不会打印在显示器上,而是追加到log.txt文件中
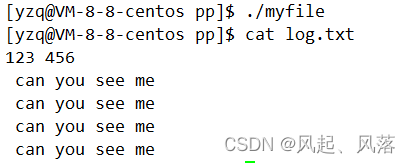
运行可执行程序,无显示,都追加到log.txt文件中
重定向函数 ——dup2
输入 man dup2 查看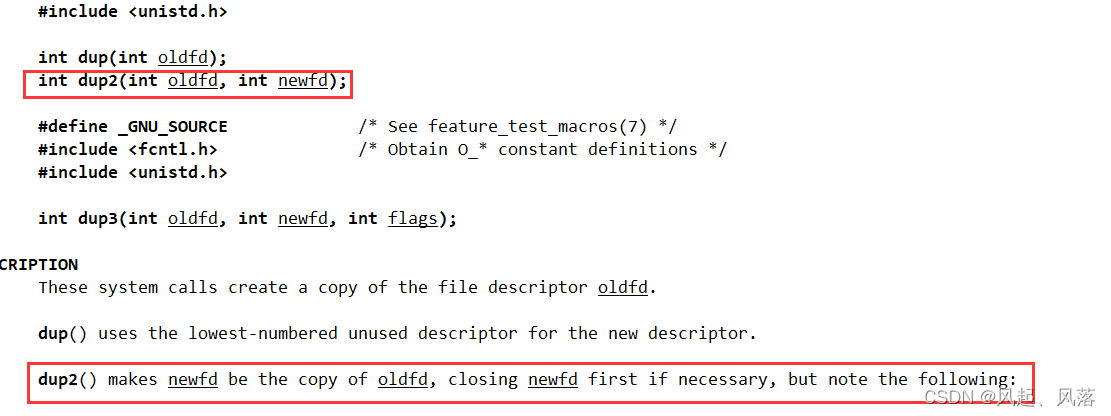
刚刚重定向时,需要先关闭文件描述符1,再打开文件
现在可以直接将文件打开,使用dup2重定向
输出重定向对应的文件描述符是1
打开myfile文件,假设其文件描述符是fd
newfd为oldfd的一份拷贝,最后只剩下oldfd
dup2(fd,1)
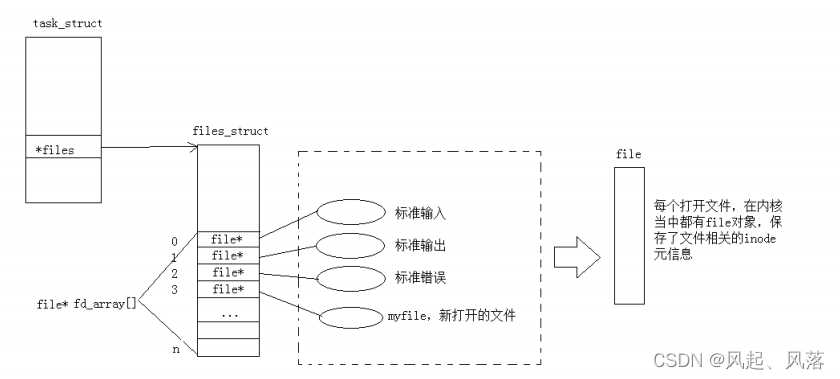
将3号描述符里面的内容拷贝到1里面,用3号内容覆盖1号内容,此时1号描述符就不再指向标准输出了,转而指向myfile文件,写入1的内容,就会写入文件中

把本来应该显示到标准输出的内容,显示到log.txt文件中
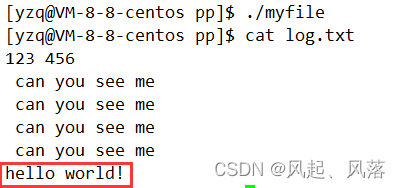
此时printf打印内容显示到log.txt文件中
6. 如何理解缓冲区?
修改myfile.c文件的内容
#include<sys/types.h> #include<sys/stat.h> #include<fcntl.h> #include<stdio.h> #include<unistd.h> #include<errno.h> #include<string.h> #define LOG "log.txt" int main() { //C库 fprintf(stdout,"hello world\n"); //系统调用 const char*msg="hello write\n"; write(1,msg,strlen(msg)); fork(); return 0; } 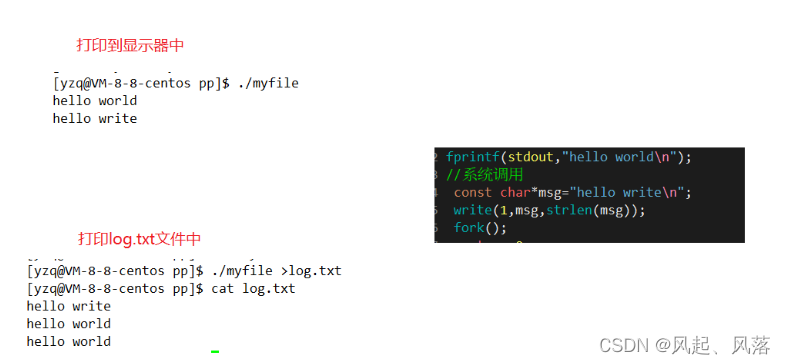
运行可执行程序只有两行信息,但是重定向到log.txt文件后,打印出三行信息,说明重复打印了
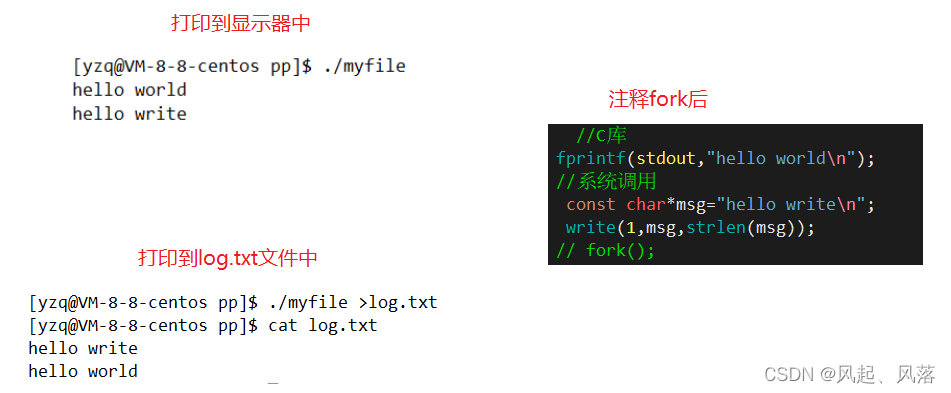
若将fork函数注释掉后,发现 两者显示结果相同\

struct FILE除了会封装fd之外,还会预留一部分输出缓冲区
当把字符串想写入stdout中时 ,struct FILE除了fd,还有一部分缓冲区
当我们想写的时候,并不是把数据拷贝到操作系统内部,而是把数据放到缓冲区当中
此时这个fprintf函数会直接返回
C库会结合一定的刷新策略,将缓冲区中的数据写入操作系统(write(FILE->fd,xxxx))
刷新策略:
1.无缓冲 (不提供缓冲)
2.行缓冲
如果碰到\n,就会把\n在内之前的内容刷新出来
3. 全缓冲
只有把缓冲区写满的时候,才会刷新缓冲区
显示器采用的刷新策略:行缓冲
普通文件采用的刷新策略:全缓冲
为什么要有缓冲区?
节省调用者的时间
系统调用也会花费时间
可能写了10次,如果每次调用fprintf传给操作系统 都要花费时间
但若都写入缓冲区中,统一传给操作系统 效率就变高了
write接口不论有没有重定向,都会正常打印,因为调用write是系统调用 没有缓冲区,直接调用就写给操作系统了
而使用fprintf ,数据会先写入缓冲区
当要打印到显示器中时 刷新策略:行缓冲
因为打印的内容都存在\n,在调用fork时,打印的内容已经在缓冲区中被刷新走了,刷新之后在fork就没有任何意义了
所以fork就什么也没干
当打印到普通文件时 刷新策略:全缓冲
使用 hello world 没办法把缓冲区写满,就无法刷新,父子两个进程都要刷新
刷新就要对缓冲区做清空,即对数据做修改,此时谁先刷新就先发生写时拷贝,所以最终就会打印两次相同数据
