
阅读量:0
目录
一、进程的创建
1.fork函数初识
它从已存在进程中创建一个新进程。新进程为子进程,而原进程为父进程。
#include <unistd.h> pid_t fork(void); 返回值:自进程中返回0,父进程返回子进程id,出错返回-1进程调用fork,当控制转移到内核中的fork代码后,内核做:
1.分配新的内存块和内核数据结构给子进程
2.将父进程部分数据结构内容拷贝至子进程
3.添加子进程到系统进程列表当中
4.fork返回,开始调度器调度
当一个进程调用fork之后,就有两个二进制代码相同的进程。而且它们都运行到相同的地方。但每个进程都将可以通过if else分流执行各自的代码
在fork之前父进程独立执行,fork之后,父子两个执行流分别执行。注意,fork之后,谁先执行完全由调度器决定。
2.fork函数返回值
成功时
子进程返回0,
父进程返回的是子进程的pid
fork函数调用失败时返回-1
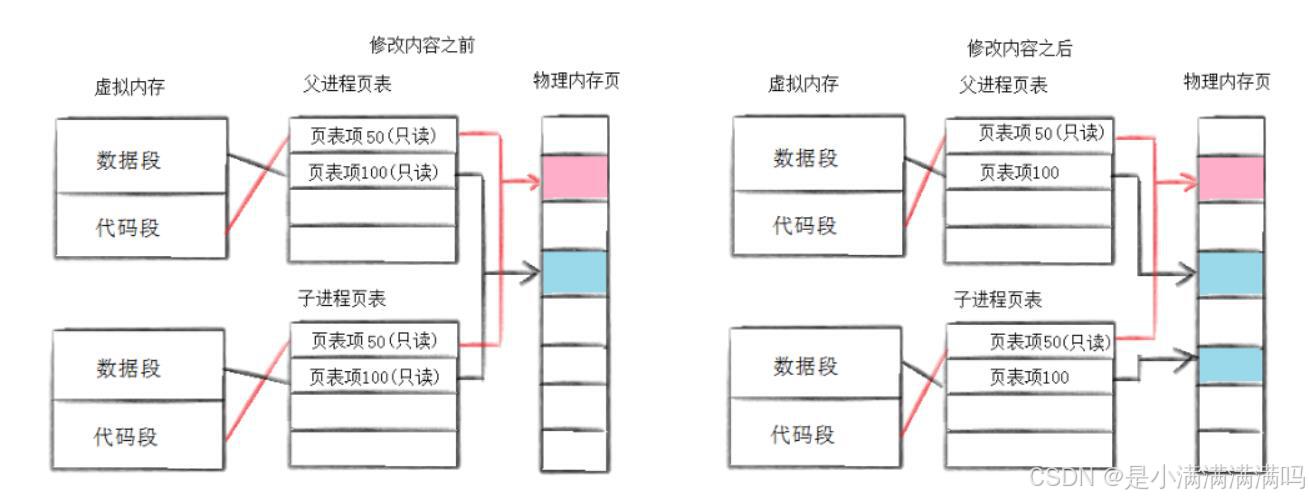
3.写时拷贝
通常,父子代码共享,父子再不写入时,数据也是共享的,当任意一方试图写入,便以写时拷贝的方式拷贝一份副本。
在fork之后,页表中所有进程地址的标志位都变成只读,看后续谁先触发只读权限的错误就给谁进行写时拷贝,并且修改权限为可读可写
4.fork的常规用法
1.一个父进程希望复制自己,使父子进程同时执行不同的代码段。
2.一个进程要执行一个不同的程序。例如子进程从fork返回后,调用exec函数。
5.fork调用失败的原因
1.系统中有太多的进程
2.实际用户的进程数超过了限制
二、进程终止
1.进程退出场景
代码运行完毕,结果正确
代码运行完毕,结果不正确
代码异常终止
对于正常运行的这两种结果
我们这个main函数return的是进程的退出码,来表征进程的运行结果是否正确
一般而言谁会关心这个进程的运行情况呢?一般是父进程关心。因此进程的退出码可以被它的父进程拿到,可以通过 echo $? 查看最近一个进程的退出码
但是父进程为什么要关心呢?本质其实是用户在关心,用户在知道失败的原因之后,会根据失败的原因进行处理,实现交互
当代码运行结果正确时我们不作太多关注,当代码运行结果不正确时,我们想要知道为什么不正确
-->可以用return的不同的返回值数字来表征不同的原因---退出码
strerror

可以通过错误码来打印错误原因
每个数字对应一种错误描述,下面是部分的举例
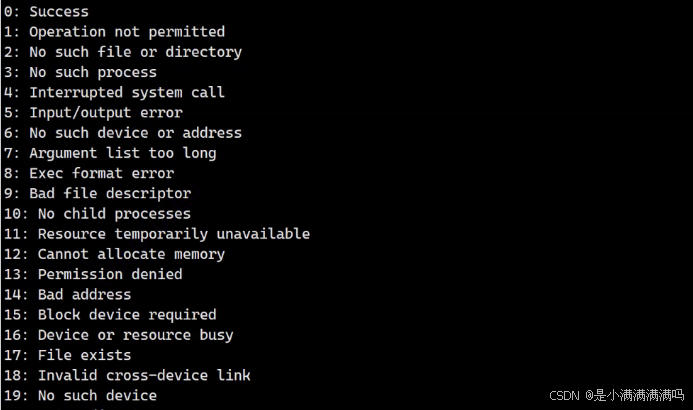
例如在下面这个ls 指令产生的进程退出后会交给bash它的退出码

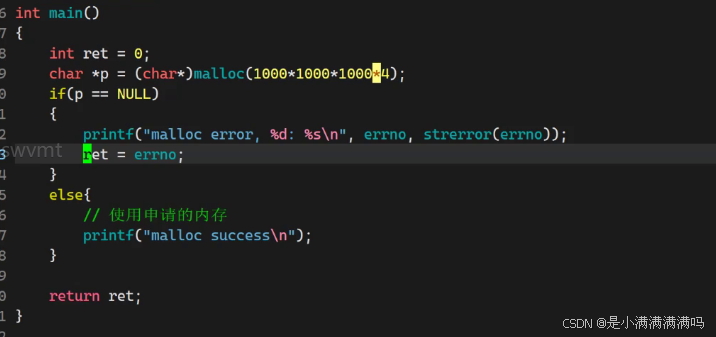
errno
这是c语言给我们提供的一个全局变量
它会储存最近一次库函数调用失败时候的错误码,它会被覆盖
由此通过errno变量我们可以知道库函数调用失败的错误码,也可以通过strerror打印错误原因,还可以将错误码转化为进程的退出码

(但是在后续应用中我们多采取c与c++混编,所有一般不会采用c标准库给我们提供的错误码)
对于异常终止的情况
本质可能是代码并没有跑完
因此进程的退出码无意义,我们不关心退出码了
所有我们先看进程是不是正常终止,然后再看代码运行结果是否正确,即关系退出码
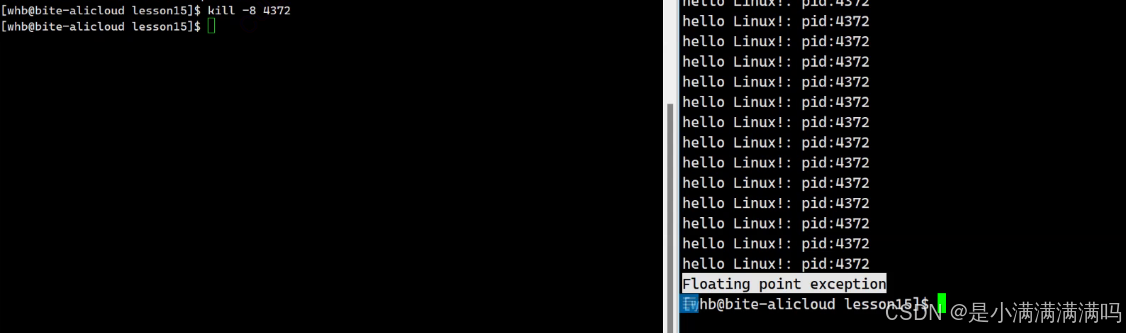
当出现异常这些异常会被转化为硬件信息,被操作系统识别从而向目标进程发信号,让我们的进程直接退出
进程出现异常本质是我们的进程收到了对应的信号
下面是一些信号
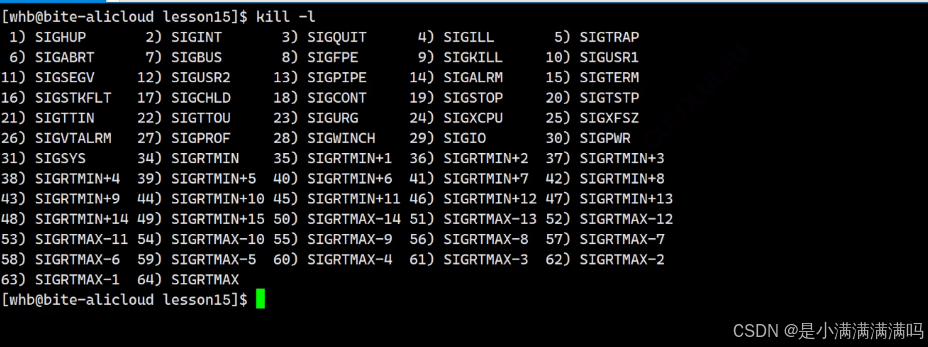
例如当我们代码中出现/0时,会出现浮点数异常,
解引用空指针会报段错误


而即使进程本身没有异常,但是当我们主动向其发信号时,该进程也会终止
2.进程常见退出方法
正常终止
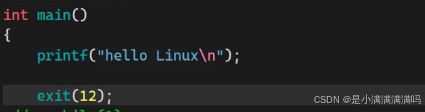
1. 调用exit()

exit括号里面跟着的,就是该进程的退出码

exit 在任意地方调用都表示调用进程直接退出,而return只表示当前函数返回
所以在main函数中exit和return是等价的
2. _exit()
它是一个系统调用接口
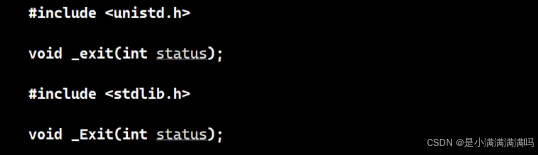
基本上和exit()是相同的,但是它是直接结束进程,而exit()会刷新缓冲区之后才退出
实际上
exit最后也会调用exit, 但在调用exit之前,还做了其他工作:
1. 执行用户通过 atexit或on_exit定义的清理函数。
2. 关闭所有打开的流,所有的缓存数据均被写入
3. 调用_exit
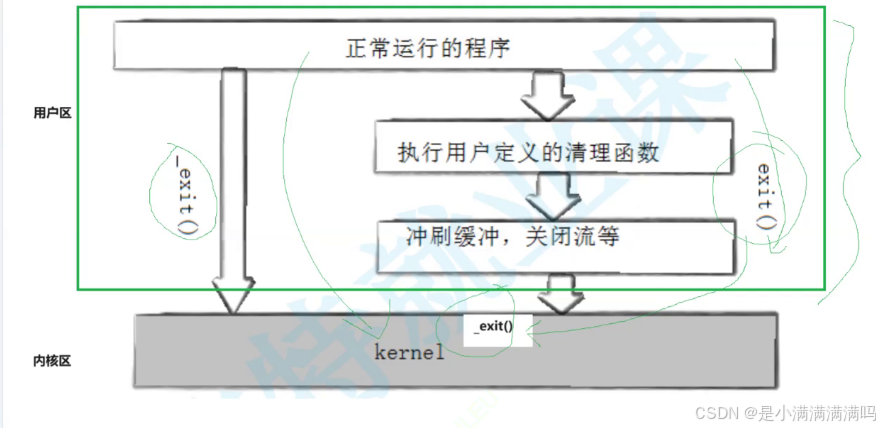
从而我们可以推得,缓冲区绝对不在内核区,因为如果在内核区,无论是exit还是_exit都是刷新缓冲区
3. 从main返回
return是一种更常见的退出进程方法。在main函数中执行return n等同于执行exit(n),因为调用main的运行时函数会将main的返回值当做 exit的参数。
异常退出:
ctrl + c,信号终止
