阅读量:0
Shell编程类-网站检测



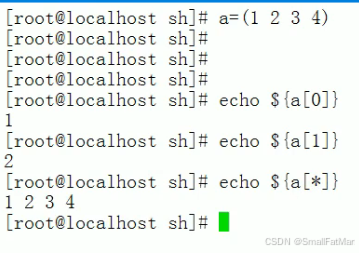
a=(1 2 3 4) echo ${a[0]} echo ${a[*]} - 这里声明一个数值,并选择逐个调用输出还是全部输出


curl -w %{http_code} urL/IPADDR - 常用-w选项去判断网站的状态,因为不加选择访问到的网站可能出现乱码无法判断是否网站down了。

面试题参考答法
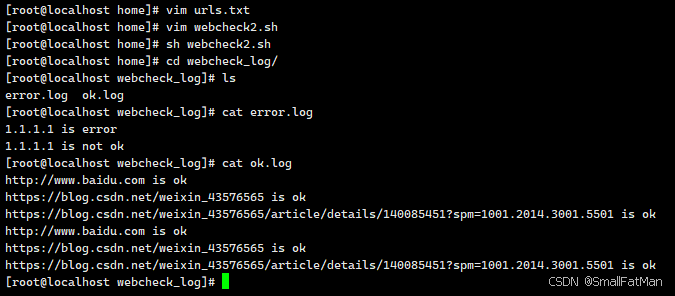
#!/bin/bash web=( http://www.baidu.com https://blog.csdn.net/weixin_43576565 https://blog.csdn.net/weixin_43576565/article/details/140085451?spm=1001.2014.3001.5501 1.1.1.1 ) #定义数组 for i in "${web[@]}"; do #按照数组中值的个数循环,每次循环吧数组中值赋予变量i code=$(curl -o /dev/null -s --connect-timeout 5 -w '%{http_code}' "$i" | grep -E "200|302") if [[ "$code" != "" ]]; then echo "$i is ok" >>/home/webcheck_log/ok.log else code=$(curl -o /dev/null -s --connect-timeout 5 -w '%{http_code}' "$i" | grep -E "200|302") if [[ "$code" != "" ]]; then echo "$i is ok" >>/home/webcheck_log/ok.log else echo "$i is error" >>/home/webcheck_log/error.log fi fi done 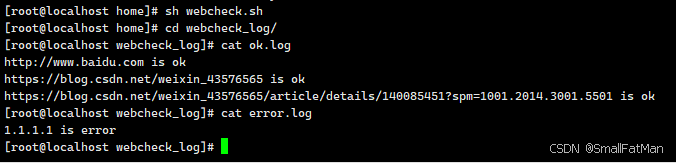
这段脚本是一个Bash脚本,用于检查一组网址的可访问性。它使用curl命令来发送HTTP请求,并根据返回的状态码判断网址是否可用。脚本的主要步骤如下:
- 定义一个名为web的数组,其中包含了要检查的网址。
- 使用for循环遍历数组中的每个网址。
- 对于每个网址,使用curl命令发送HTTP请求,并设置超时时间为5秒。
- 使用grep命令过滤出状态码为200或302的响应,这些状态码表示请求成功。
- 如果找到了匹配的状态码,将网址写入名为ok.log的文件,表示该网址可用。
- 如果没有找到匹配的状态码,再次尝试发送请求,如果仍然没有匹配的状态码,将网址写入名为error.log的文件,表示该网址不可用。
这个脚本可以用于定期检查一组网址的可访问性,并将结果记录在日志文件中。
- 正常的编程思维是这样的写,但是在Shell脚本中更注重脚本的复用,所以应该将web数组部分改为读取文本内容。
要将web数组部分改为读取文本内容以提高复用率,可以将网址列表存储在一个文本文件中,然后使用脚本读取该文件并将每个网址添加到web数组中。以下是修改后的脚本:
#!/bin/bash # 定义一个空数组 declare -a web # 从文本文件中读取网址并添加到数组中 while IFS= read -r line; do web+=("$line") done < urls.txt # 按照数组中值的个数循环,每次循环吧数组中值赋予变量i for i in "${web[@]}"; do # 使用curl命令发送HTTP请求,并设置超时时间为5秒 code=$(curl -o /dev/null -s --connect-timeout 5 -w '%{http_code}' "$i" | grep -E "200|302") # 如果找到了匹配的状态码,将网址写入名为ok.log的文件,表示该网址可用 if [[ "$code" != "" ]]; then echo "$i is ok" >>/home/webcheck_log/ok.log else # 如果没有找到匹配的状态码,再次尝试发送请求,如果仍然没有匹配的状态码,将网址写入名为error.log的文件,表示该网址不可用 code=$(curl -o /dev/null -s --connect-timeout 5 -w '%{http_code}' "$i" | grep -E "200|302") if [[ "$code" != "" ]]; then echo "$i is ok" >>/home/webcheck_log/ok.log else echo "$i is not ok" >>/home/webcheck_log/error.log fi fi done 在这个修改后的脚本中,我们首先声明了一个空数组web,然后使用while IFS= read -r line; do ... done < urls.txt循环从名为urls.txt的文本文件中逐行读取网址,并将其添加到web数组中。
这段代码是Bash脚本中的一个循环结构,用于从名为urls.txt的文件中逐行读取内容。下面是对这段代码的解释:
while IFS= read -r line; do ... done: 这是一个while循环,它会一直执行直到文件结束。在这个循环中,每次迭代都会读取一行文本并将其存储在变量line中。IFS=: 这是内部字段分隔符(Internal Field Separator)的设置。将其设置为空字符串意味着不使用任何字符作为字段分隔符,这样整行文本都会被当作一个字段处理。read -r line: 这是read命令的一个选项,用于从输入中读取一行并将其存储在变量line中。-r选项表示原始模式,这意味着反斜杠不会被视为转义字符。done < urls.txt: 这是重定向操作符,它将文件urls.txt的内容作为输入传递给while循环。这意味着while循环将从urls.txt文件中逐行读取内容。
综上所述,这段代码的作用是从名为urls.txt的文件中逐行读取内容,并将每行内容存储在变量line中,然后执行循环体中的代码。
这样,我们就可以通过修改urls.txt文件来轻松地更改要检查的网址列表,从而提高脚本的复用性。