
随着AI模型训练成本的上升,人们越来越关注推理硬件的成本,尤其是在需要低延迟响应的应用中。Transformer模型需要强大的硬件支持,例如200毫秒以下的响应时间。Artificial Analysis最近分析了AI模型性能和定价,特别指出AMD的“Antares” Instinct MI300X GPU加速器在运行Meta Platforms最新发布的Llama 3.1 405B模型方面可能会优于Nvidia的硬件。

考虑到开源PyTorch框架和Llama模型的优势,我们认为PyTorch/Llama组合将会非常流行。AMD的技术团队显然已经针对这一技术栈对Antares GPU进行了优化。
首先我们需要针对这个来分析:需要多少GPU才能存储Llama 3.1 405B参数模型的权重,包括权重和内存开销?
这次比较仅涉及AMD MI300X与最初的Nvidia “Hopper” H100,并且提到了2023年11月宣布的未来产品Hopper H200 GPU以及3月宣布的“Blackwell” GPU,由于没有大规模出货,所以没有出现在图表中。
据Artificial Analysis称,需要810 GB来加载Llama 3.1 405B模型的权重,另外243 GB用于留出30%的FP16处理开销空间,总计1053 GB的总容量。
如果降低到FP8精度,数据量减半,需要405 GB用于权重和121.5 GB用于开销,这意味着可以减少所需的计算引擎数量。如果进一步降低到FP4精度,数据量再次减半,所需HBM内存和GPU数量也将减半。不过,这样做会牺牲一些LLM的响应精度以换取数据精度的降低。
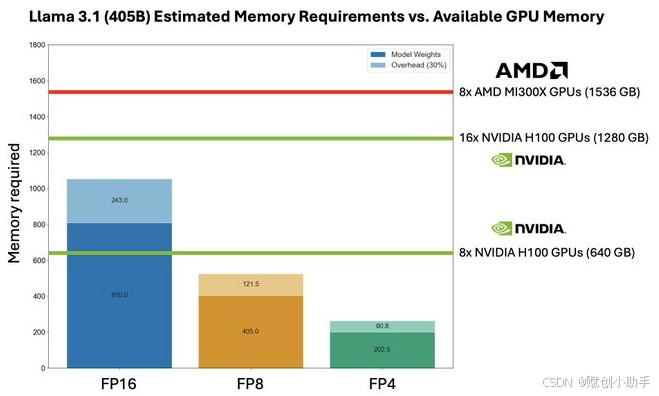
使用Nvidia的Hopper H100 GPU,每个拥有80 GB的HBM内存,需要两个八路HGX卡才能适应Llama 3.1 405B的权重和开销。如果降低到FP8精度,可以全部装在一台服务器上,使用一个带有八个Hopper GPU的HGX板。
使用AMD MI300X八路GPU板的系统可以轻松容纳Llama 3.1 405B模型的权重。实际上,如果可能的话,只需要5.5个GPU。另一个角度来看,正确的MI300X GPU可以让我们在八路系统板共享内存内运行参数约为590亿的Llama模型的未来版本。
除了性能和内存容量外,成本也是一个必须考虑的因素。上述的对比中同样没有出现B100和B200 GPU,所以,我们综合Artificial Analysis的想法整理了以下表格:
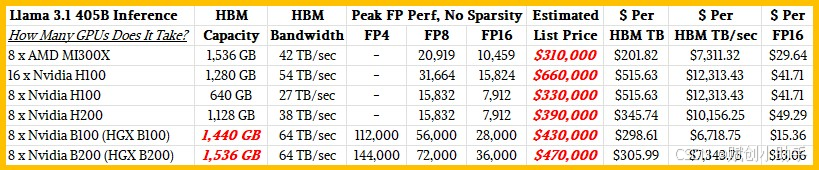
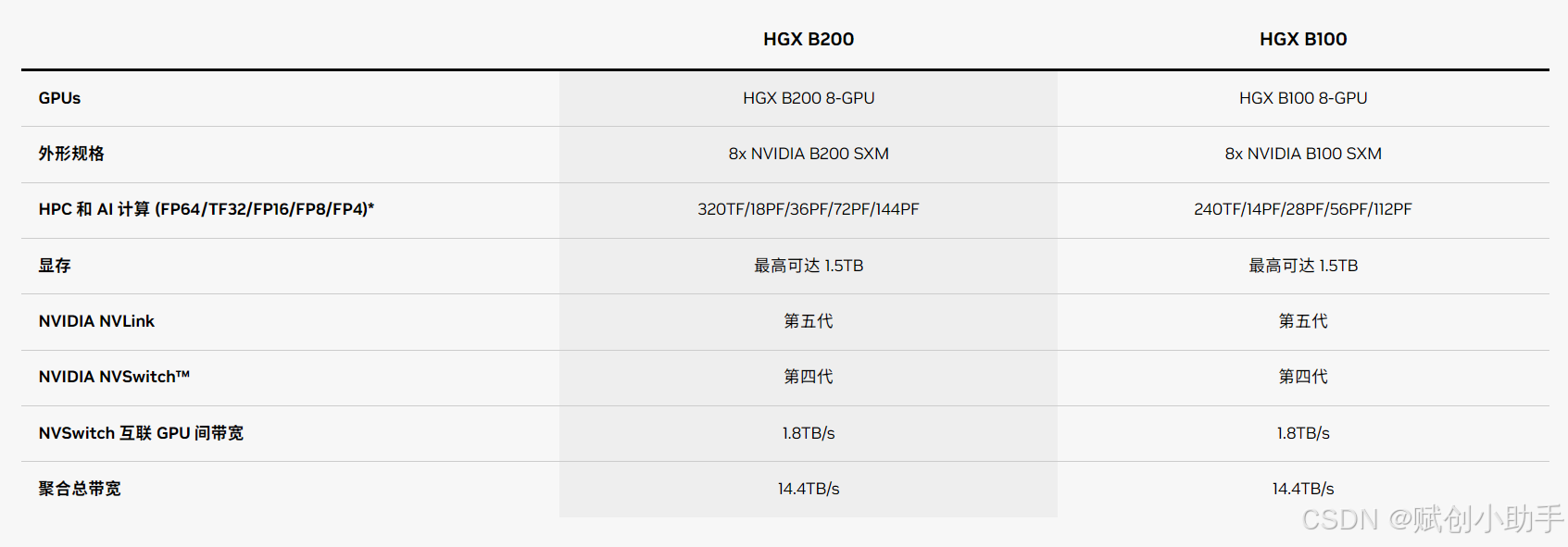
整理过程中,我们发现了Nvidia B100和B200规格中一些奇怪的地方。Nvidia架构技术简报显示,HGX B100和HGX B200系统板将拥有高达1536 GB的内存,即每个B100 GPU有192 GB。但DGX B200规格表说它将只有1440 GB的HBM内存,即每个B100 GPU有180 GB。(我们找不到DGX B100服务器的规格表。)我们认为B100和B200将具有不同的内存容量,就像Hopper一代的H100和H200一样,我们不认为B200的内存容量会低于B100。因此,我们预测B100在HGX B100系统板上将各有180 GB,B200在HGX B200系统板上将各有192 GB,并以此来配置我们的GPU系统。
考虑到目前GPU的价格,我们认为装满GPU的机器将同时用于LLM推理和LLM训练。因此,我们构建的任何八路GPU主板服务器的基本配置都相当强大,配备双X86 CPU、许多核心和大量主存(2 TB)、大量东西向流量的网络带宽(八个200 Gb/s卡)和大量本地闪存存储(6.9 TB)。除去GPU,这样配置的基础机器成本约为150,000美元。
关于GPU定价,我们使用了以下价格标准:
AMD MI300X 192 GB: $20,000
Nvidia H100 80 GB: $22,500
Nvidia H200 141 GB: $30,000
Nvidia H100 180 GB: $35,000
Nvidia H200 192 GB: $40,000
这里将GPU板添加到基础X86硬件的系统价格,只是想说明问题,并不能作为购物指南。实际价格受需求压力和时间问题的影响,通常会有很多溢价。相对推理,训练对网络,内存和闪存的要求会比较高,配置太低会受到限制。
考虑到成本和未来的可扩展性,选择具有更高HBM内存容量的GPU(如AMD的MI300X)可能更为明智。这样,不仅可以在当前满足推理需求,还能为未来可能的模型扩展预留足够的资源,同时避免了因轻量级配置而在训练过程中遇到的性能瓶颈。
一些AI工作负载对内存带宽的敏感度将高于对内存容量或计算能力的敏感度,这取决于给定的精度。在这方面,我们预计基于MI300X的系统在每单位内存带宽的成本方面将与使用Nvidia B200 GPU加速器的系统相当。基于Nvidia HGX B200板卡的系统将在相同的1.5TB内存下提供高出51%的带宽,但价格也高出51%。(这两个数字是我们独立得出的。我们并没有猜测价格涨幅会与内存带宽涨幅相匹配。我们将拭目以待Nvidia和市场的实际表现。)
有趣的是,如果定价如我们所预期,使用B100的系统将在内存容量和内存带宽方面提供更高的性价比,但B100预计不会提供相应水平的计算性能。B100和B200的FP4数字是真实的,B200预计将比B100有28.6%的更高性能,Nvidia尚未解释原因。B200可能比B100多出的6.7%的内存容量将有所帮助,但看起来B100在开始发货时将比B200激活较少的流多处理器。
从原始峰值浮点性能规格来看,Nvidia的B100将远超MI300X,而B200的表现将更为出色。在峰值FP16性能水平上,将B100/B200与MI300X进行比较,Nvidia大约提供了两倍的性价比优势。
然而,AMD MI300X,与Nvidia H100和H200一样,现在已经开始出货,,其每美元的性能比H200高出41%至66%。但请注意,在真实的Llama 2 70B推理测试中,根据Nvidia在H200发布期间公布的基准测试结果,H200的性能是H100的1.9倍。因此,在购买GPU时,需综合实际需求,注意分析浮点运算次数与内存容量和内存带宽之间的比例。

AMD MI300X和Nvidia H100和H200在这两个比率上大致处于同一水平,但Nvidia B100和B200每单位内存容量和每单位内存带宽拥有更多的FLOPs,并且有可能由于内存限制,在实际工作负载中,性能可能无法实现。
同样,对于AMD即将在今年晚些时候推出的MI325X(具有288GB内存和6TB/s带宽)、明年推出的MI350(具有288GB内存和未知带宽)以及2026年推出的MI400X,也建议采取同样的谨慎态度。在购买之前,请确保通过充分的测试来评估它们是否满足您的性能需求和预算要求。

**赋创(EMPOWERX)**作为高性能计算领域的先锋,一直致力于推动技术创新,我们会及时关注最前沿的科技动态,为客户提供高效、可靠的计算解决方案。

如果您有服务器相关的问题或需要进一步了解更详细的信息,请随时私信我们【4006-997-916 / 0755-86936235】。