
阅读量:0

引言
随着深度学习模型,尤其是大型语言模型的规模不断扩大,对于开发和本地部署这些模型所需的图形处理单元(GPU)内存的需求也在日益增加。构建或获得一台装备有多个GPU的计算机只是面临的挑战之一。默认情况下,大多数库和应用程序仅支持单个GPU的使用。因此,计算机还需要安装合适的驱动程序和能够支持多GPU配置的库。
本文[1]旨在提供一份设置多GPU(Nvidia)Linux系统的指南,以及一些重要库的安装方法。这将帮助你节省在实验过程中的时间,让你能够更快地开始你的开发工作。
文章最后还提供了一些流行的开源库的链接,这些库能够支持多GPU配置,以便于进行深度学习。
目标
配置一个多GPU Linux系统,并安装必要的库,如CUDA Toolkit和PyTorch,以便开始你的深度学习之旅🤖。这些步骤也适用于只有单个GPU的计算机。
我们将安装1) CUDA Toolkit,2) PyTorch,以及3) Miniconda,以便于使用像exllamaV2和torchtune这样的框架来开始深度学习。
环境检查

在终端里运行 nvidia-smi 命令来查看计算机中安装了多少个GPU。该命令会列出所有安装的GPU。如果输出与预期不符或者命令执行失败,首先需要为您的Linux系统安装相应的Nvidia显卡驱动。确保 nvidia-smi 命令能够正确显示计算机中所有安装的GPU列表。
1. CUDA-Toolkit
请先查看 /usr/local/cuda-xx 路径下是否有 CUDA 文件夹,这表示可能已经安装了 CUDA 的某个版本。如果您已经安装了您需要的 CUDA 工具包版本(可以通过终端中的 nvcc 命令来验证),请直接跳过。
确认您希望使用的 PyTorch 库所需的 CUDA 版本:从本地开始 | PyTorch(我们计划安装的是 CUDA 12.1)。
访问 NVIDIA 开发者网站的 CUDA Toolkit 12.1 下载页面,获取适用于 Linux 的安装命令(选择与您的操作系统版本相匹配的“deb (本地)”安装器类型)。
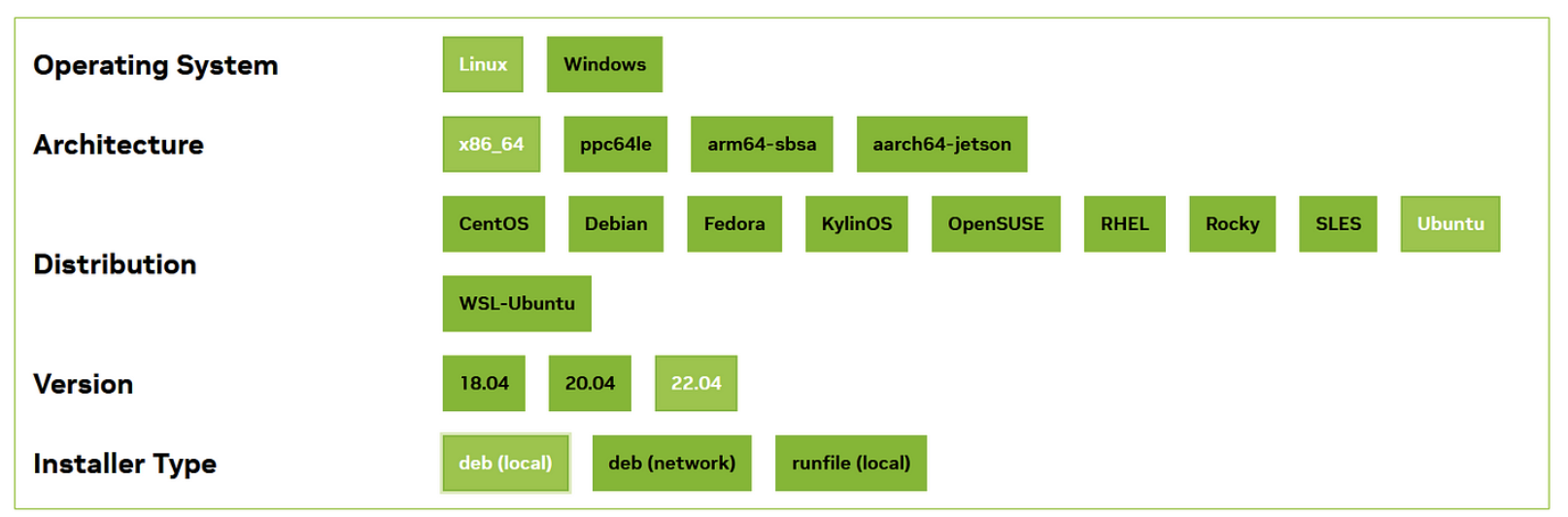
根据您的选择,终端将显示基础安装器的命令。将这些命令复制并粘贴到您的 Linux 终端中,以完成 CUDA 工具包的安装。例如,如果您使用的是 x86_64 架构的 Ubuntu 22 系统,请打开下载文件夹中的终端,并执行以下命令:
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pin
sudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/12.1.0/local_installers/cuda-repo-ubuntu2204-12-1-local_12.1.0-530.30.02-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu2204-12-1-local_12.1.0-530.30.02-1_amd64.deb
sudo cp /var/cuda-repo-ubuntu2204-12-1-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cuda
在安装 CUDA 工具包的过程中,安装程序可能会提示您进行内核更新。如果终端弹出任何更新内核的提示,请立即按下 esc 键来取消操作。请不要在这个阶段更新内核!— 这可能会损坏您的 Nvidia 显卡驱动程序。
安装完成后,请重启您的 Linux 系统。即使重启后,nvcc 命令可能还是无法使用。这是因为您还需要将 CUDA 的安装路径添加到环境变量 PATH 中。您可以使用 nano 文本编辑器打开 .bashrc 配置文件来进行这一设置。
nano /home/$USER/.bashrc
滚动到 .bashrc 文件的底部并添加以下两行:
export PATH="/usr/local/cuda-12.1/bin:$PATH"
export LD_LIBRARY_PATH="/usr/local/cuda-12.1/lib64:$LD_LIBRARY_PATH"
保存更改并关闭 nano 编辑器:
2. Miniconda
在安装 PyTorch 之前,最好先安装 Miniconda,然后在 Conda 环境中安装 PyTorch。为每个项目创建一个新的 Conda 环境也很方便。
打开下载文件夹中的终端并运行以下命令:
mkdir -p ~/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
rm -rf ~/miniconda3/miniconda.sh
# initiate conda
~/miniconda3/bin/conda init bash
~/miniconda3/bin/conda init zsh
关闭并重新打开终端。现在 conda 命令应该可以工作了。
3. PyTorch
(可选步骤)— 为您的项目新建一个 conda 环境。您可以将 <环境名称> 替换为您自己选定的名称。我个人习惯用项目的名字来命名环境。
您可以在开始项目工作时使用 conda activate <环境名称> 命令来激活环境,在工作结束后使用 conda deactivate <环境名称> 命令来停用环境。
conda create -n <environment-name> python=3.11
# activate the environment
conda activate <environment-name>
安装适合您的 CUDA 版本的 PyTorch 库。以下命令适用于我们安装的 cuda-12.1:
pip3 install torch torchvision torchaudio
上述命令来自PyTorch安装指南:

PyTorch 安装完成后,在终端中检查 PyTorch 可见的 GPU 数量。
python
>> import torch
>> print(torch.cuda.device_count())
8
这应该打印系统中安装的 GPU 数量(在我的例子中为 8),并且还应该与 nvidia-smi 命令中列出的 GPU 数量相匹配。
Source: https://towardsdatascience.com/how-to-setup-a-multi-gpu-linux-machine-for-deep-learning-in-2024-df561a2d3328
本文由 mdnice 多平台发布
