
阅读量:0
一、日志的概念
1、什么是日志?
日志是指工作日志,现在的日志主要发表在网络,详细介绍一个过程和经历的记录。日志是日记的一种,是一种记录了生活和情感的写作模式,多指个人的,一般是记载每天所做的工作,就像在笔记本上写日记一样,不同的是日志是发表在网络上的虚拟空间储存,在这个基础上进一步提高了效率和节约时间,只要申请一个个人博客即可,在日志里可以记录一些琐事,写下一些心情。
2、在项目开发中为什么需要日志呢?
在项目开发中,都不可避免的使用到日志。没有日志虽然不会影响项目的正常运行,但是没有日志的项目可以说是不完整的。日志在调试,错误或者异常定位,数据分析中的作用是不言而喻的。
2.1、调试
在项目调试时,查看栈信息可以方便的知道当前程序的运行状态,如果你大量使用printf或者std::cerr,这是一种最方便最有效的方法,但显得不够专业。在程序中的重要地方打印日志,之后对产生的日志进行分析,可以找到对应代码的问题(比如,利用日志找到具体问题所在模块以后,就可以利用gdb调试工具对程序进行调试)。因此日志系统成为了大型软件项目代码调试的主要手段。
2.2、错误定位
不要以为程序能正确跑起来就可以高枕无忧,程序在运行一段时间后,可能由于数据问题,网络问题,内存问题等出现异常。这时日志可以帮助开发人员快速定位错误位置。
2.3、数据分析
大数据的兴起,使得大量的日志分析成为可能。日志中蕴含了大量的用户数据,包括点击行为,兴趣偏好等。
3、日志分类
(1)面向问题排查的日志;
(2)面向提醒或警告的日志;
(3)面向调试和测试的日志;
(4)面向功能的日志(准确的说,这是数据文件,不是日志);
(5)面向人阅读的日志;
(6)面向机器解析的日志。
4、日志消息的级别
(1)FATAL ERRO 致命错误
发生致命错误,代表服务器整个或者核心功能,已经无法工作。
处理原则如下:
A、在服务器启动时就应该检查,如果存在致命错误,直接抛出异常,让服务器不要启动起来(启动了也无法正常工作,不如不启动)。
B、如果在服务器启动之后,发生了致命的错误,则记录error级别的错误日志,最好是同时触发相关的修复和警告工作(比如,给开发和维护人员发送警告邮件)。
(2)ERROR(错误)功能或者逻辑级别的严重异常
发生error级别的异常,代表功能或者重要逻辑遇到问题、无法正常工作。
(3)WARN(警告)
warn是警告的意思,它有两方面作用:
一是从程序角度,在某些功能或逻辑不正常时,发生了一些小故障但是没有大的影响。
二是从业务角度,遇到了一些特殊操作或者特殊数据,例如重要数据或者配置被修改,或者操作需要引起重视。
(4)INFO(信息)
info用于记录一些有用的、关键的信息,一般这些信息出现的不频繁,只是在初始化的地方或者重要操作的地方才记录。
(5)DEBUG(调试)
debug用于记录一些调试信息,为了方便查看程序的执行过程和相关数据、了解程序的动态。
(6)TRACE(跟踪)
trace用于记录一些更详细的调试信息,这些信息无需每次调试时都打印出来,只在需要更详细的调试信息时才开启,例如在排查问题时、或者测试时跟踪程序的执行。
(7)TRACE和DEBUG的区别:
debug日志相对比较正规,它记录下程序执行的关键信息,可以在生产环境下保存下来,用于排查问题,日志输出量要控制在比较小的范围,而trace级别的日志,仅用于开发或者测试时调试程序,用来查看程序详细执行信息,通常只用于开发环境,它在测试环境和生产环境一般是不开启的,只在需要时临时开启来排查问题,对于它的日志量是没有限制的,通常来说trace日志输出比较多。
(8)总结和补充
注意,是否需要日志,以及日志的级别,是根据功能的重要性来决定的,而不是根据程序是否异常来决定的。也就是说,对于程序报错,不一定都记录error级别的日志,在一些不太重要的地方,记录成warn或者debug级别就可以了。
另外,在系统出现致命错误之后,应该立即采取措施,而不仅仅是记录error日志。
二、利用C++实现日志系统
此部分将提供日志系统部分代码。
1、开发日志系统的目的
(1)追踪程序执行的过程;
(2)追踪数据的变化;
(3)快速定位问题的根源;
(4)数据统计和性能分析;
(5)为以后开发其他项目提供支持。
2、日志系统的功能需求
2.1、日志消息分为六个级别:
依次为FATAL(致命错误)、ERROR(错误)、WARN(警告)、INFO(信息)、DEBUG(调试)、TRACE(跟踪)。
2.2、日志消息格式
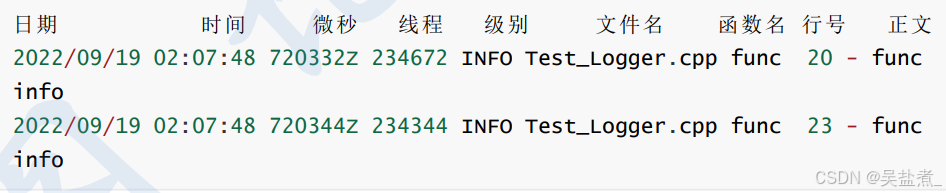
2.3、日志消息格式的要求
(1)每条日志占一行。
(2)时间戳精确到微秒。
(3)始终使用GMT时区。
(4)打印线程ID。
(5)打印日志级别。
(6)打印源文件名,函数名,行号。(修复bug时不至于搞错对象)
2.4、记录日志的方式
终端显示和写入日志文件。
2.5、滚动日志(rolling log)
日志文件必须能够滚动(rolling),可以简化日志归档的实现。滚动日志的目的是防止单个日志文件过大,以至于占满硬盘空间。滚动日志的原理是通过设定的规则(最大文件、最多保存多少天),超过设定的值就删除较早的记录。滚动的条件是:文件大小(如每写满1GB就换下一个文件)和时间(如每天零点新建一个日志文件,不论前一个文件有没有写满)。
2.6、LOG文件名格式
basename+now+hostname+pid+".log"
basename 基础名,由用户指定,通常可以设为应用程序名
now 当前时间,格式“%Y%m%d-%H%M%S”
hostname 主机名
pid 进程号,getpid()
".log" 固定后缀名,表明这是一个log文件
各部分之间,用“.”连接
举例如下:
test_log_mt.20220218-134000.ubuntu.12426.log
3、日志系统的设计
(1)公共头文件
enum class LOG_LEVEL { FATAL=0, ERROR=1, WARN=2, INFO=3, DEBUG=4, TRACE=5, NUM_LOG_LEVELS,//日志级别数 }; static const char* LLtoStr[]={ {"FATAL"}, {"ERROR"}, {"WARN"}, {"INFO"}, {"DEBUG"}, {"TRACE"}, {"NUM_LOG_LEVELS"}, };(2)时间戳类型设计
#ifndef __TIMESTAMP_H__ #define __TIMESTAMP_H__ #include<ctime> // include<time.h> #include<string> // include<cstring> #include"LogCommon.hpp" class MicroTimestamp : public copyable { private: std::int64_t microSecondsSinceEpoch_;// 1970 .....2023 public: MicroTimestamp(); explicit MicroTimestamp(int64_t microSecondsSinceEpoch); void swap(MicroTimestamp& that); //按不同的两种格式输出时间 std::string toString() const; std::string toFormattedString(bool showMicroseconds = true) const; std::string toFormattedFile() const; bool valid() const; // for internal usage. std::int64_t microSecondsSinceEpoch() const ; time_t secondsSinceEpoch() const; public: static MicroTimestamp now(); static MicroTimestamp invalid(); static const int kMicroSecondsPerSecond = 1000 * 1000; }; //内联函数减少函数调用的时间消耗 inline bool operator<(const MicroTimestamp &lhs, const MicroTimestamp &rhs) { return lhs.microSecondsSinceEpoch() < rhs.microSecondsSinceEpoch(); } inline bool operator==(const MicroTimestamp &lhs, const MicroTimestamp &rhs) { return lhs.microSecondsSinceEpoch() == rhs.microSecondsSinceEpoch(); } inline double timeDifference(const MicroTimestamp &high, const MicroTimestamp &low) { int64_t diff = high.microSecondsSinceEpoch() - low.microSecondsSinceEpoch(); return static_cast<double>(diff) / MicroTimestamp::kMicroSecondsPerSecond; } inline MicroTimestamp addTime(const MicroTimestamp ×tamp, const double seconds) { int64_t delta = static_cast<int64_t>(seconds * MicroTimestamp::kMicroSecondsPerSecond); return MicroTimestamp(timestamp.microSecondsSinceEpoch() + delta); } #endif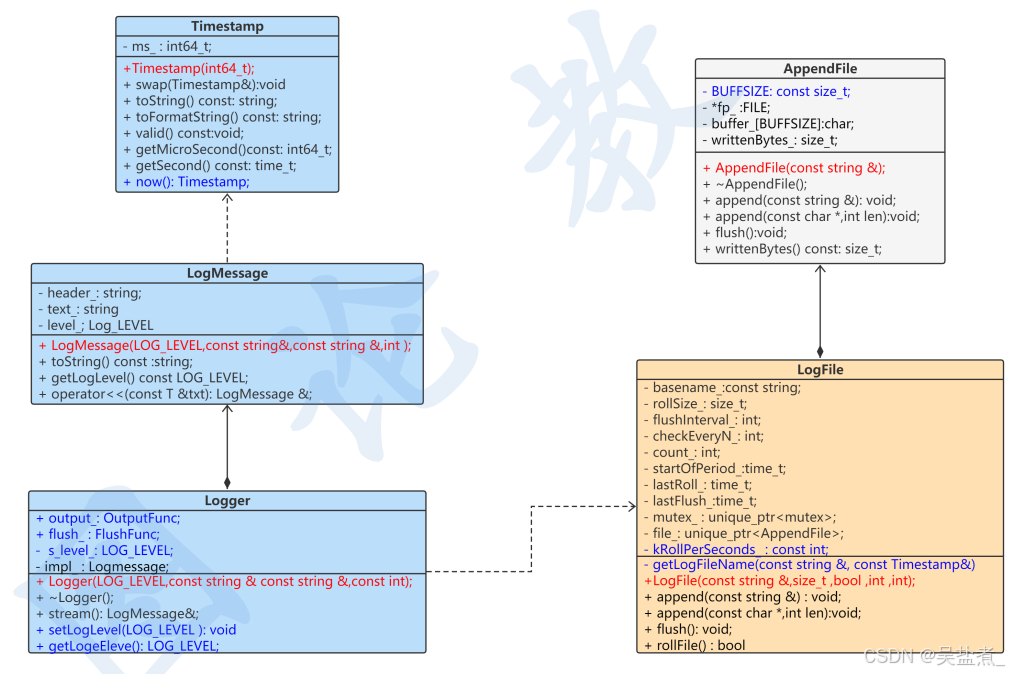
..........
4、日志系统设计注意事项
(1)回滚:
当文件大小超过设置固定大小(防止撑满内存空间)
当时间到达当天00.00,重新生成新的文件保存日志。
(2)时间戳类型:
获得UTC时间,格式化字符串。
将每次写入日志文件的一行信息,都要将当前时间戳保存,并写入文件。
(3)日志流类型:
可以定义字符串输入输出流对象(stringstream),将日志级别、文件名称、函数名称、行号进行保存。
(4)日志类型:
Logger用于将日志事件信息(时间 日志级别 文件名 行号等)输出到缓冲区,默认输出到stdout。
目的是实现这样一个日志类:
在构造函数里面把日期基本信息例如时间、日志级别信息写入到logstream中
在析构函数里面先把源文件名,行号写入到logstream中,再把logstream中数据写入到日志输出地。例如文件,stdout
从构造开始到析构结束只算一条日志,中间可以通过logger.stream()<<"new 日志"操作来写入具体日志信息。
(5)文件写类型的实现:
可以以不加锁方式写文件,不线程安全,但是效率高。
三、多线程异步日志系统
多线程程序对日志提出了新的需求:线程安全,即多个线程可以并发写日志,多个线程的日志消息不会出现交织。线程安全不难办到,简单的方法是用一个全局mutex保护IO,或者每个线程单独写一个日志文件,但这两种做法的效率并不高。前者会造成全部线程抢一个锁,后者有可能让业务线程阻塞在写磁盘操作上。
每个进程中的多线程程序最好只写一个日志文件,这样分析日志更容易,不必在多个文件中跳来跳去。再说多线程写多个文件也不一定能提速。解决办法如下:
用一个工作线程负责收集日志消息,并写入日志文件,其他业务线程只管往这个日志线程发送日志消息,这称为“异步日志”。
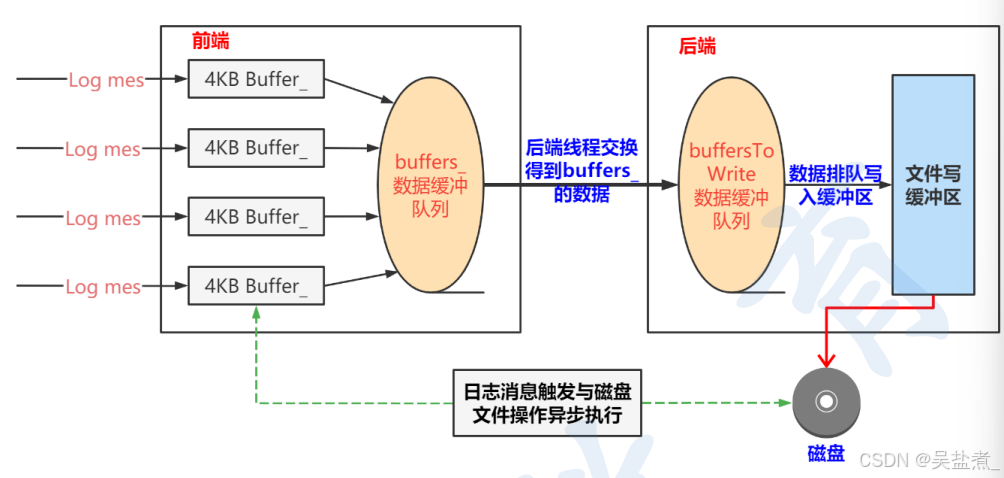
1、系统的设计:
日志系统采用的是双缓冲区技术,基本思路是准备两块buffer:A和B,前端负责往buffA填数据(日志消息),后端负责将bufferB的数据写入文件。当bufferA写满之后,交换A和B,让后端将bufferA的数据写入文件,而前端则往bufferB填入新的日志消息,如此王府。用两个buffer的好处是在新建日志消息的时候不必再等待磁盘文件操作,也避免每条新日志消息都触发后端日志线程。换言之,前端不是将一条条日志消息分别传送给后端,而是将多条日志消息拼成一个大的buffer传送给后端,相当于批处理,减少了线程唤醒的频度,降低开销。另外,为了及时将日志消息写入文件,即便BufferA未满,日志库也会每3秒(具体可以自己设计)执行一次上述交换写入操作。
四、日志系统的使用
ERROR:准确!
是错误信息--包括错误的类型,错误的内容,位置和场景,是否可恢复,等等。只有当错误会影响到系统的正常运行时,才应该作为错误日志输出。
WARN:提个醒
是提醒信息,要关注此处,目前还正常,不代表之后正常。
INFO:简洁
系统的基本运行过程,运行状态。
DEBUG:详细
系统运行过程与状态的细节信息,可用于调试。
TRACE:细致入微
系统结构与内容的细节信息,比如一些关键对象的内容,函数调用参数、结果等。
