
阅读量:0
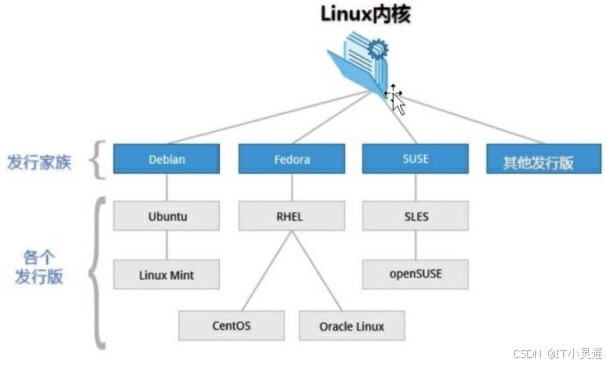
Linux系统版本
Ubuntu RedHat CentOS Debian Fedora SuSE OpenSUSE

shell是系统的用户界面.提供了用户与内核进行交互操作的一种接口。它接收用户输入的命令并把它送入内核去执行。
Linux内核
Linux根分区“/”
在启动的时候需要使用的文件载入内存,有一个分区作为起始分区,这个分区被称为根分区,根是由内核直接访问的。
绝对路径:从顶层/(根)开始的路径
相对路径:从非/(根)开始的路径
./表示当前目录
../表示父级目录
目录是路径的映射符
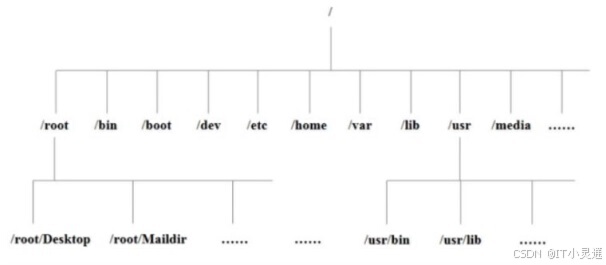
Linux系统中的目录:
树状目录结构:
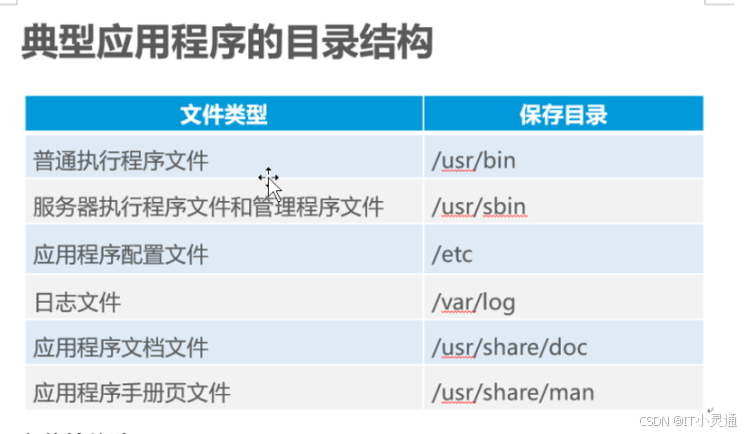
/bin:所有可执行的程序
/sbin:管理员可执行的程序
/usr/bin
/usr/sbin
/boot:存储系统引导文件;内核、ramfs文件、bootloader(grub)
/dev:设备文件存放目录
/etc:配置文件的存放目录
/etc/sysconfig:系统网络配置目录
/etc/init.d:系统服务脚本
/home:普通用户,默认在/home下有一个与其同名的目录,作为用户的家目录
/root:管理员的家目录
/lib、/lib64:库文件
/media:专用挂载位置,通常用来挂载便携式设备
/mnt:专用挂载位置,挂载额外存储设备
/opt:备用目录,但通常用来安装第三方软件
/proc:伪文件系统,系统内核参数的映射
/proc/loadavg:负载
/sys:伪文件系统,系统级别的用于配置外围设备的参数
/srv:为服务提供数据存放的位置
/tmp:存放临时文件系统
/usr:默认软件,用户工具和应用程序,共享,只读
/usr/local:默认的软件安装目录c盘
/usr/lnclude:头文件
/usr/src:源码安装目录
/var:频繁发生变化的文件
/var/log:日志文件存放目录
/var/log/messages
/var/log/secure:系统用户登录日志
authentication failure:登陆失败
/var/lib:变化的状态信息
/var/lock:锁文件
/var/run:有些进程在运行时产生的数据
/var/cache:缓存
Linux命令行的辅助操作:
- Tab键:自动补齐
- 反斜杠"\":强制换行
- 快捷键ctrl+u:清空至行首
- 快捷键ctrl+k:清空至行尾
- 快捷键ctrl+l或 clear:清屏
- 快捷键ctrl+c:取消本次命令编辑
- 快捷键ctrl+d:相当于输入exit,退出
- 快捷键ctrl+a:行首
- 快捷键ctrl+e:行尾
Linux文件类型:
- -:普通文件
- d:目录文件
- b:块设备文件(block)磁盘设备文件
- c:字符设备文件
- l:符号连接文件
- p:命令管道文件
- s:套接字文件
linux命令大全
修改主机名称
hostnamectl set-hostname +名称
logout
重启网卡
systemctl restart network
获取帮助命令
内部命令 help 命令 查看bash内部命令的帮助信息
外部命令 命令--help 适用于大多数外部命令
使用man命令阅读手册页
man命令
使用page up和page down键翻页
按q或Q键推出阅读环境,按“/”键查找内容
用type命令可以分辨内部命令和外部命令
文件和目录
cd /home 进入 '/ home' 目录'
cd .. 返回上一级目录
cd ../.. 返回上两级目录
cd 进入个人的主目录
cd - 返回上次所在的目录
pwd 显示工作路径
1s:查看当前目录的文件及目录
-l=ll长格式
-t按照时间排序
-h做单位转换
-a显示隐藏文件
-A与-a参数类似,显示目录下除了"."与".."以外的其他所有文件
-ld显示目录自身属性
-R递归显示
-S以文件大小排序
-1(一)以列表形式只输出文件及目录
du:统计当前路径下所有文件或目录大小
-s统计当前目录下文件的总大小
-h以大小单位方式显示
touch:创建文件(最主要的功能是更新文件的时间戳)
-c不创建任何文件,更新所有属性时间
-a更新文件最近一次访问时间
-m更新文件最近一次修改时间
拓展:touch /{1..100}.txt (创建100个文件)
stat:显示文件的详细信息(显示文件最近一次访间,修改,改变时间)
mkdir:创建目录
-p创建多級目录
-ⅴ显示创建过程
cp:复制
例:cp源 目标
-r递归复制(可以复制目录)
-f强行复制
-p复制过来,保存文件原有属性(只有管理员有此权限)
-P复制链接文件
-a归档复制,保持文件及目录、连接文件原有的所有属性(用于备份)
-v显示复制过程
rm:删除文件
-f强制不提示删除
-r递归删除
mv:移动/重命名文件
-f强制移动
-v显示过程
which:来查看一个可执行命令的具体路径
find:精细查找文件或目录
-name按名称查找
-size按文件大小查找
-user按文件属性查找
-type按文件类型查找
cat:查看文件内容
-n带行号显示
-s多个连续的空白行显示为一个空白行
-A显示文件里所有字符
more/less –N:分屏查看(q退出) less –N:带行号显示
tac:类似于cat,倒序查看文件内容
tail{-n #或-#}:查看文件尾部或尾部的第几行
head{-n #或-#}:查看文件开头或开头的第几行
tailf=tail –f:实时查看
-f或f实时查看
-F实时查看,并不断尝试
wc:字符统计显示的值为 行、单词个数、字节(包括空白字节)
-l只显示行
-w只显示单词数
-c只显示字节数
-m只显示字符数
压缩、解压缩命令(压缩格式:gz,bz2,xz,zip,Z)
压缩算法:算法不同,压缩比也会不同
gzip:.gz(仅用于文件) 会删除原文件
gzip 文件名:压缩(压缩完成后会删除源文件)
-d解压缩
gunzip 压缩名:解压完成后会删除原文件
zcat 压缩包名:不解压查看压缩包里面的内容
bzip2:.bz2(仅用于文件) 比gzip有着更大的压缩比的压缩工具,使用格式相似 会删除原文件
bzip2 要压缩的文件名
-d解压缩
bunzip2 压缩包名:用于解压缩
-k压缩时保留原文件
bzcat不解压查看压缩包里面内容
zip:既归档又压缩的工具(用于压缩文件或目录及目录下文件)不会删除原文件
自动压缩目录下的所有文件:zip name.zip a/*
zip压缩后的名.zip 要压缩的目录或文件(压缩后不删除原文件)
unzip压缩包名.zip:解压缩
zcat 压缩包名:不解压查看压缩包里面的内容
xz: .xz(仅用于文件,使用时需要用yum安装xz压缩工具包)会删除原文件压缩比最好,速度慢
xz 要压缩的文件
-d解压缩
-k压缩时保留原文件
unxz用于解压
xzcat不解压查看压缩包里面内容
tar:.tar归档工具(最好用相对路径)不会删除原文件
tar 参数 归档后的名称(必须为.tar)要归档的文件或目录。
-f 文件名.tar:操作的归档文件
-p 打包解包时保留文件及目录的权限
-v显示过程
-tf 查看归档文件内容
-cf 创建归档文件(tar -cf 压缩包名.tar 目录或文件)
-rf 添加文件到已经压缩的tar文件(tar rf ***.tar /root/a.txt)
-xf 展开归档(tar -xf 压缩包名.tar)(可以跟-zxf -jxf -Jxf)
-C释放的目的地(tar xf a.tar -C /usr/)
-tpf 不展开归档,直接查看归档了那些文件(可以跟-zxf -jtf)
--xattrs 归档时,保留文件的扩展属性信息
-zcpf 归档并调用gzip 压缩或zip压缩(归档压缩.tar.gz 或 .tar.z 或.tar.zip)
tar -zcf name.tar.gz name 或 tar -zcf name.tar.z name
-zxpf :调用gzip/zip解压缩并展开归档 -z 选项可省略
-jcpf 归档并调用bzip2压缩(归档压缩.tar.bz2 或 .tar.bz)
tar -jcf name.tar.bzip2 name或tar -jcf name.tar.bz name
-jxpf :调用bzip2解压缩并展开归档 tar.bz2或tar.bz
-Jcpf归档并调用xz压缩(tar -Jcf xx.tar.xz 文件名/目录)
-Jxpf 解压.tar.xz的压缩包(用于红帽6版本)
如果对文件压缩时出现tar:从成员名中删除开头的“/”报错,但依然成功压缩
造成该问题的原因是因为使用相对路径和绝对路径引起的,另外还有一种解决方法时使用相对路径
-P 可以解决这个错误
Vim编辑器的使用
vim是vi编辑器增强版:文本编辑器,字处理器
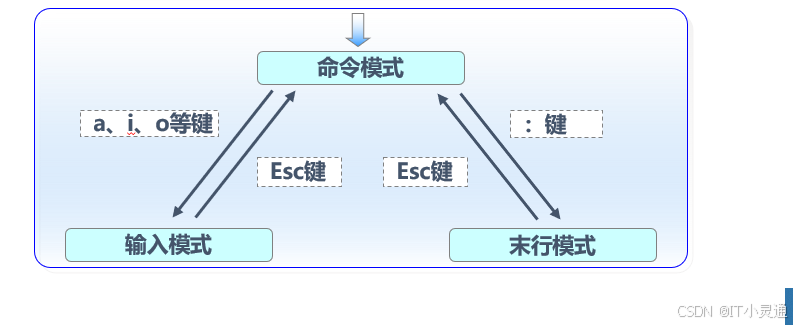 三种模式:末行、输入、编辑
三种模式:末行、输入、编辑
末行-->编辑:按两下esc
全屏编辑器,模式化编辑器
- 移动到光标所在行的上一行行首
i在当前光标所在字符的前面,转为输入模式
I 在当前光标所在行行首,转换为输入模式
a在当前光标所在字符的后面,转为输入模式
A在当前光标所在行的行尾,转入输入模式
o在当前光标所在行的下方,新建一行,并转为输入模式
O在当前光标所在行的上方,新建一行,并转为输入模式
R替换光标处的单个字符
在末行模式中可以执行的命令
:nd n表示数字,d表示删除,结合起来为删除第几行
:n 2nd表示删除第n行2n行中间的所有行(格式:..,$d)
:X加密或取消加密
:!ls/root可以执行命令
:q/q! 退出
:wq/x/wq!保存退出
:e!撤销所有操作
查找
/要搜索的内容:从首部向文件尾部查找
?要搜索的内容:从尾部向文件首部查找
n:从上向下查找下一个
N:从下向上查找下一个
查找并替换
在末行模式下使用s命令
单行替换:s/要替换的内容/替换后的内容/g
全文替换:%s/要替换的内容/替换后的内容/g
显示或取消显示行号
:set number
:set nu
:set nonu
移动光标(编辑模式)
逐字符移动
K 上
h 左 l右(空格键)
j下或(回车键)
行内跳转
shift +i、0、^ 、home 行首
shift+a 、$ 、end 行尾
行间跳转
G/]] 最后一行
nG 跳转至第n行
1G、gg 、[[ 第一行
dG 删除当前到行尾所有行
d1G删除当前到行首所有行
末行格式下,直接给出行号即可
翻屏
Ctrl+f:向下翻一屏
Ctrl+b:向上翻一屏
Ctrl+d:向下翻半屏
Ctrl+u:向上翻半屏
删除单个字符
X删除光标所在处的单个字符(向后删除)
#x删除光标所在处及向后的共#个字符
删除命令d
dd 删除当前光标所在行
粘贴命令 p
复制命令y(用法同d命令)
yy:复制一整行内容
替换R(替换单个字符)
R:进入替换模式,输入的字符替换光标后的字符,按esc键退出替换模式
撤销编辑操作u
u撤销前一次的编辑操作
连续u命令可撤销此前的n次编辑操作
编辑文件内容后,在编辑模式下可直接保存退出ZZ
vim+n 打开文件,并定位在文件第n行(格式vim +2文件名)
vim+ 打开文件,定位至最后一行(格式vim + 文件名)
Linux命令扩展-1
reset重新初始化屏幕
tty显示当前终端对应终端设备文件
uname-r/-a:查看linux内核版本号
cat/etc/redhat-release:查看系统版本
Linux版本号 X.YY.ZZ
X:主版本号、YY:次版本号、ZZ:末版本号,YY奇数- 开发版,增加新功能,偶数- 稳定版,修改错误
hostname/uname-n查看主机名
file 文件名 查看文件类型
cd 切换目录、cd..退到上级目录、cd - 返回上次所在目录
pwd查看当前所在路径
cal 显示日历 格式cal 年份
-1只显示当前月份(默认)
-3显示上个月、当月和下个月
-s周日作为一周第一天
-m周一用为一周第一天
-j输出在当年的第几天
-y输出整年
-V显示版本信息并退出
bc 计算器
exit退出当前登录
watch周期性的执行指定命令,并以全屏方式显示结果
格式:watch -n # ‘命令’
cat /proc/meminfo 查看系统内存信息
cat /proc/cpuinfo 查看cpu信息
history查看命令历史
-c清空历史命令
! 编号 重执行命令
echo打印输入的字符 echo $ 输出变量
tree查看目录树
shutdown -r now #重启
shutdown -h now #关机
关机 init 0 、halt、poweroff
重启 init 6、reboot
linux软件包安装
RPM Package Manger
由Red Hat公司提供,被众多Linux发行版本所采用。
建立统一的数据库文件,详细记录软件包安装、卸载等变化信息,能够自动分析软件包依赖关系。
RPM包是经过编译的,不能看到源代码,但是它安装更快,报错更容易解决,只有依赖性问题。RPM包不需要指定安装位置,它会安装到系统默认位置。
RPM包默认安装路径
/etc/ 配置文件安装目录
/usr/bin/ 可执行的命令安装目录
/usr/lib/ 程序所使用的函数库保存位置
rpm包格式
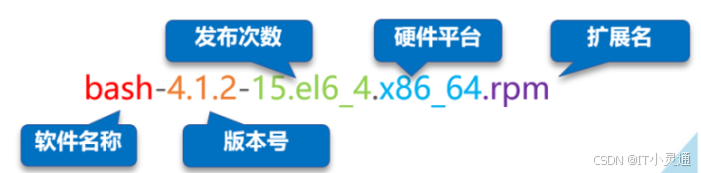
rpm包(二进制格式):组成部分
主包 bind-9.7.1-1.el5.i586.rpm
子包 bind-libs-9.7.7-1.el5.i586.rpm
重建数据库
rpm --rebuilddb:重建数据库,一定会重新建立
rpm –initdb: 初始化数据库,没有才建立,有就不用建立
rpm 选项 /路径/rpm软件包名
-i安装软件包
-h以#显示进度,每个#表示2%
-v显示详细过程
-e软件包名 #卸载软件包
--nodeps忽略依赖关系(如果有依赖关系,软件装上去也运行不了)
--fore强行安装,可以实现重装或升级
升级(注意不要升级内核)
rpm –Uvh /路径/新rpm软件包名:如果装有老版本则升级,否则安装
rpm –Fvh /路径/新rpm软件包名:如果装有老版本,则升级,否则退出
查询已安装的rpm包
-qa 查询已安装的所有安装包
-qi 查询指定包的说明信息
-ql 查询指定包安装后生成的文件列表
-qc 查询指定包安装的配置文件
-qd 查询指定包安装的帮助信息
-qf /路径/文件名 查询文件所属的软件包
查询尚未安装的rpm包
rpm –qpi /路径/软件包名:查询其说明信息
rpm –qpl /路径/rpm软件包名:安装以后会生成的文件
示例
rpm –ivh /media/Packges/lynx-2.8.8-0.3.dev15.el7.*86_64.rpm
安装有依赖关系的多个软件时,被依赖的软件包需要先安装,可同时指定多个.rpm包文件进行安装。
卸载有依赖关系的多个软件时,依赖其他程序的软件包需要先卸载,可同时指定多个软件名进行卸载。
yum
yum是一个在fedora和RedHat以及CentOS中的shell前端软件包管理器。基于rpm包管理,能够从指定的服务器自动下载rpm包并且安装,可以自动处理依赖关系,并且一次安装所有依赖的软件包,无需繁琐的一次次下载、安装。
#挂载光盘镜像
mount /dev/sr0 /media/
mount: /dev/sr0 写保护,将以只读方式挂载
#把其他yum 源移动到一个目录中不让系统加载使用
cd /etc/yum.repos.d/
mkdir a
mv * a
#构建新的本地yum源
vim yum.repo
[base] yum仓库名
name=base yum仓库名
baseurl=file:///media 指定光盘挂载的位置
enabled=1 启用yum仓库
gpgcheck=0 默认是0不检测 1检测 检测光盘RPM包的合法性
#清除本地yum源缓存
yum clean all
#构建本地yum缓存
yum makecache
使用示例 yum –y 不进行交互
安装:yum -y install 软件名
卸载:yum -y remove(或erase) 软件名
升级:yum -y update 软件名
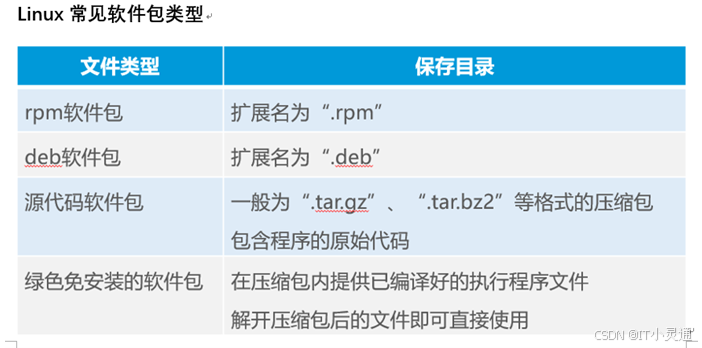
源码包介绍
源码包是开源的,比RPM包安装更自由,但是它安装更慢,更容易报错;
源码包安装位置:源码包是人为手工设置安装位置,安装在指定位置当中,一般是/usr/local/软件名/
源码包安装的好处:可以自行调整编译参数,最大化地定制安装结果
源码安装可以选择最新的软件包,而Linux系统(包括FreeBSD)自带的软件包一般都是最稳定的版本,但不能保证是最新的
源码安装的性能是最优异的
源码包安装的软件卸载时极为方便简单,更重要的是,他比较安全,尤其是对线上生产环境而言
迁移也比较方便,如果不涉及系统库文件,复制到另一台机器上也可以使用
完整性校验
md5sum,sha512sum校验工具
校验示例
Apache Tomcat® - Apache Tomcat 8 Software Downloads
http://mirror.bit.edu.cn/apache/tomcat/tomcat-8/v8.5.42/src/apache-tomcat-8.5.42-src.tar.gz

- 确认源代码编译环境
需安装支持C/C++程序语言的编译器
rpm –qa gcc
gcc -4.8.5-36.el7_6.2*86_64
rpm –qa gcc-c++
gcc -c++-4.85-36.el7_6.2.*86_64
- 解包
习惯上将软件包释放到/usr/src/目录
解包后的源代码文件位置/usr/src/软件名-版本号/
- 配置
使用源码目录中的configure脚本
执行“./configure –help” 可查看帮助
典型的配置选项:--prefix=软件安装目录
- 编译
执行make命令
- 安装
执行make install命令
示例
tar xf nginx-1.16.0.tar.gz
cd nginx-1.16.0/
./configure -–prefix=/usr/local/nginx
make
make install
cd /usr/local/nginx/
cd conf/sbin/
./nginx 启动应用
ss –tnl 验证程序是否启动 浏览器访问验证
用户及文件权限管理
用户账号
管理员用户(UID=0)
普通用户(UID=>500)
程序用户(1=<UID<500)(不可登录)
UID:UID(用户标识号)
id 用户名:可以查看用户UID
-gn 查看用户基本组
-u 查看UID
-g 查看GID
用户账号文件(用户名称,宿主目录,登录shell等基本信息)/etc/passwd
root: x: 0: 0: root: /root: /bin/bash
账号名 密码占位符 UID GID 用户备注 宿主目录 登录的shell
登录的shell若为/sbin/nologin,则不能登录
系统中的用户及密码文件/etc/shadow
root:$6$K5jsNO9pxE3RbD40$Eiw1N66vtN6ZvrRwNzwNmjhfVKqpXjVN8WbK2P03.6ck7pLWJsYPPmIW5qfzsr5BVu2GnxK..Kq8m/HBtraDq0::0:99999:7:::
第一字段 root: 用户名
第二字段 $6……Dq0: 密文
第三段 :账号上次修改时间距1970.01.01过去多少天
第四段 0:距上次密码修改起多少天内不能再次修改密码,单位“天”,“0”表示随时可以修改密码
第五段99999:密码过期天数(99999表示永久可以使用)
第六字段7:强制密码修改提醒时间
第七字段 :密码过期后经过多少天账号被禁用
第八字段 :密码过期时间,若设置则显示为过期日期距1970.01.01多少天
useradd=adduser:创建用户 格式:useeradd 选项 用户名
-u 创建用户时指定用户UID
-e 创建用户时指定失效时间,年月日
-d 创建用户时指定家目录名
-g 创建用户时指定用户基本组名
-G 创建用户时指定附加组名
-M 创建用户时不创建主目录
-s 指定使用shell
创建用户的模板文件
vim /etc/login.defs
创建账号时会从/etc/skel/目录中复制用户初始文件到其家目录
.bash_logout:每次退出时要执行的文件
.bash_profile:每次登录时要执行的文件
设置/更改用户口令 passwd 格式:passwd 选项 用户名
-d 删除用户密码
-l 锁定用户
-S 查看账号的密码状态
-u 解锁用户
-x 密码最长有效时间(天)
-n 密码最短有效时间(天)
-w 密码过期前警告时间(天)
-i 密码过期后多少天被禁用(天)
修改用户账户的属性 usermod 格式:usermod 选项 用户名
-l 更改用户的用户名{usermod –l 新用户名 用户名}
-L 锁定用户账号
-U 解锁用户账号
-s 更改shell环境
删除用户账号 userdel 格式:userdel 选项 用户名
-r 连同账户家目录一起删除
finger:查询用户账号的详细信息 格式:finger 用户名
users、w、who、whoami:查询已登录到主机的用户信息
用户组管理
用户组类别:
管理员组 管理员所在的组
基本组(私有组)创建账号会创建一个同名的组
附加组(共有组)额外添加的组
GID:GID(组标识号)
组账号文件
/etc/group:保存组账号基本信息
/etc/gshadow:保存组账号的密码信息
groupadd:创建组
-g 指定GID
gpasswd:添加删除组成员 gpasswd 组名 设置组密码
-a 用户名 组名:把某个用户添加到指定组
-d 用户名 组名:把某个用户从指定组中删除
-M 定义组成员列表,以逗号分隔
groupdel:删除组 格式:groupdel 组名
groups:查询用户所属的组 格式:groups 用户名
文件权限归属管理
文件权限
读权限 r=4:允许查看文件内容,显示目录列表
写权限 w=2:允许修改文件内容,允许在目录中新建、移动、删除文件或子目录
可执行 x=1:允许运行程序,切换目录
归属(所有权)
属主:拥有该文件或目录的用户账号
属组:拥有该文件或目录的组账号
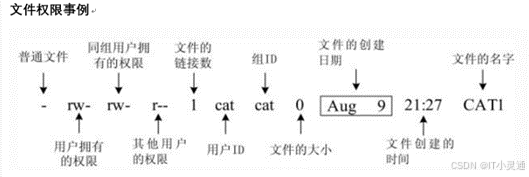
设置文件和目录的权限chmod
格式:chmod 777 文件/目录 或chmod u+/-/=[rwx] 文件/目录
-R 递归修改指定目录及其下所有文件的权限
u 代表属主
g 代表属组
o 代表其他
设置文件和目录的归属 chown
chown 属主 文件/目录
chown :属组 文件/目录
chown 属主:属组 文件或目录
-R:递归修改指定目录下所有文件、子目录的归属
权限掩码 umask
作用:控制新建的文件或者目录的权限
默认权限去除umask的权限就为新建的文件或者目录的权限
满权限-umask=创建文件的权限
umask的查看:umask
设置umask值:umask 020
Linux命令扩展-2
cut –d分隔符 –f打印的列 文件名
-c输出 这些 字符
sort 排序 格式:sort 参数 文件
-n 按照数值大小排序(正向排序)
-r 逆向排序
-t 指定字段排序分隔符(默认空格)
-k 以哪个区间进行排序(-t和-k一起使用)
-u 排序后相同的行显示一次
uniq: 去除重复行或统计
-d 只显示重复的行
-D 显示重复行所有字符
-c 显示重复的行说明重复的次数
-u 仅显示不重复的行
date:显示系统时间
+%F 、+%Y-%m-%d:年月日
+%T 、+%H:%M:%S:时分秒
%Y 四位年份
%m 月
%d 日
%H 时
%M 分
%S 秒
-s “年月日 时:分:秒”修改主机时间
同步主机时间:ntpdate pool.ntp.org(ntp:基于UDP的网络时间协议)
ln 参数 源文件 目标文件
-s:创建软连接
-v:显示创建过程
硬链接:(相当于copy)
- 只能对文件创建,不能应用于目录;
- 不能跨文件系统
- 创建硬链接会增加文件被链接的次数
- 删除链接源文件后硬链接文件还在
软链接(符号链接):ln –sv 源文件绝对路径 目标文件绝对路径(快捷方式)
- 可以用于目录,文件
- 可以跨文件系统
- 不会增加被链接文件的链接次数
- 删除链接源文件后软链接的文件不在
- 其大小为指定的路径所包含的字符个数
总结
- 每个目录下都有一个硬链接“.”,和对应上级目录的硬链接“..”
- 在父级目录中创建子目录,会增加父目录的链接次数(每个子目录里都有..来指向父目录)
- 在父目录中创建文件,不会增加父目录链接次数
密码安全性策略:
足够复杂
够长
交叉应用数字、大写字母、小写字母和特殊中的至少三种
尽量避免使用易猜测的密码
定期更换
禁止用户登录并带提示(解禁更改shell即可):
useradd –s /sbin/nologin test
passwd test
echo “账号被禁用,请联系管理员[please contact the administrator]”>/etc/nologin.txt
su –test
账号被禁用,请联系管理员[please contact the administrator]
find 查找路径 查找条件 文件名
查找条件:
-name ‘文件名’:对文件名做精确匹配 find /路径 –name 文件名
-user 用户名:根据属主查找 find /root –user root
-group 组名:根据属组查找
-uid UID:根据UID查找 find /root –uid
-gid GID:根据GID查找
-type:根据文件属性查找 find /etc –type d
f 普通文件
d 目录
c 字符设备
b 块设备
l 链接文件
P 管道设备
S 套接字文件
-size[+表示大于,-表示小于,不带+-号表示等于],常用单位:k、M、G
find /etc –size 10k
组合条件
-a、-and:与,满足两个条件
-o、-or:或,多个条件满足一个条件即可
find /tmp –user root –a –type d
过滤一个文件中的关键字:grep “关键字” 文件名
I/O重定向:
<:重定向输出
>:重定向覆盖写入
>>:追加输入重复定向
<<:追加输出重定向
1>:正确重定向echo“www”1>1.txt 2>2.txt
表示将正确的信息输入到1.txt文件中,将错误的信息输入到2.txt文件中
1>>:表示正确追加写入
2>:重定向错误覆盖输出
2>>:错误追加
&>:标准重定向,将正确及错误反馈信息输入至一个文件
&>>:将正确及错误信息追加到一个文件中
命令||命令:表示前一个命令执行不成功,后面的命令才执行
命令&&命令:表示前一个命令执行成功后面的命令才执行
命令;命令:表示无论前一个命令执行是否成功,都执行后面的命令
|:管道,将前一个命令的输出作为下一个命令的输入
echo “123456****”|passwd --stdin userl(给一个用户设置密码)
sync 同步数据
磁盘管理
磁盘结构:
1.硬盘的物理结构
盘片:硬盘有多个盘片,每个盘片2面
磁头:每面一个磁头
2.硬盘的数据结构
扇区:盘片被分为多个扇形区域,每个扇形区存放512字节的数据
磁道:统一盘片不同半径的同心圆
柱面:不同盘片相同半径构成的圆柱面
3.硬盘存储容量= 磁头数 * 磁道(柱面)数 * 每道扇区数 * 每扇区字节数
4.可以用柱面/磁头/扇区来唯一定位磁盘上的每一个区域
磁盘接口
1.IDE (并口)
2.SATA(串口)
速度快
纠错能力强
3.SCSI
转速快
CPU占用资源低
支持热拔插
MBR
1.定义:MBR(Master Boot Record)主引导记录
2.位置:MBR位于硬盘的0柱面、0磁道、1扇区的前512字节(第一个物理扇区处)
3.MBR中包含硬盘的主引导程序和硬盘分区表。分区表有4个分区记录区,每个分区记录区占16个字节,共64字节。446字节存放主引导程序,2字节校验。
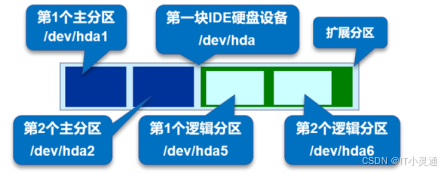
磁盘分区表示
1.linux中将硬盘等设备均表示为文件
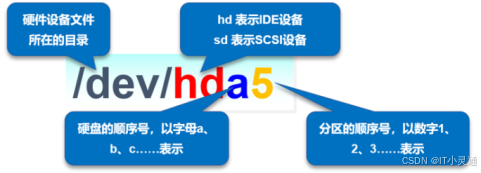
2.磁盘分区结构
硬盘中的主分区数目只有4个,因此主分区和扩展分区的序号也就限制在1~4。扩展分区为逻辑分区,逻辑分区的序号始终从5开始。
文件系统类型
- XFS文件系统
存放文件和目录数据的分区
高性能的日志型文件系统
Centos7系统中默认使用的文件系统
- EXT4,第四代扩展(Extended)文件系统
存放文件和目录数据的分区
典型的日志型文件系统
系统中默认使用的文件系统
- SWAP,交换文件系统
为Linux系统建立交换分区,类似于Windows系统的虚拟缓存
- Linux支持的其它系统文件类型
FAT16、FAT32、NIFS、NTFS、JFS……
fdisk:查看或管理磁盘分区 格式:fdisk /dev/磁盘设备 (只能分2T以下的硬盘)
查看当前磁盘fdisk –l 磁盘设备 或fdisk 磁盘设备
p 显示当前硬件的分区
n 创建新分区
e扩展分区
p主分区
d删除一个分区
w保存退出
q不保存退出
t修改分区类型
L查看分区类型
l显示所支持的所有类型
超过2T的磁盘用 parted命令划分分区 parted -l 查看新硬盘
常用命令说明:q/quit 保存并退出
p/print 打印 查看
mklabel 改变磁盘文件类型
mkpart 分区
rm n 删除某分区
查看已分的分区 ls –l /dev/sdb*
格式化分区 mkfs.ext4 /dev/sdb2
挂载使用 mount /dev/sdb* /要挂载的目录/
误删除分区救援 rescue
mkfs 格式化文件系统
-t 指定格式成什么类型的文件系统
-b 指定block大小字节
-q 不显示任何信息
-l inode 大小
-U 设置UUID号
-N 设置inode数量
mkfs –t 文件类型 磁盘设备 或 mkfs.文件类型 磁盘设备
mkswap 创建交换文件系统 (swap 交换文件系统)
mkswap 分区设备 创建交换分区
swapoff 分区设备 关闭交换分区
swapon 分区设备 开启交换分区
swapon -s 查看交换分区信息
swapon -a 启动/etc/fstab中的所有交换分区
swapoff -a 关闭/etc/fstab中的所有交换分区
示例
基于文件创建启用swap分区示例(也可以测试磁盘性能)
dd if=/dev/zero of=/var/swapfile bs=1M count=1024
解释:从/dev/zero分区(无限大小)取大小,复制到/var/目录下取名叫swapfile,每次取1M 取1024次
mkswap /var/swapfile 创建交换分区
swapon /var/swapfile 启用交换分区
创建虚拟分区swapfile ,然后启用虚拟分区
swap 多大为好:2G、4G =4G 2G- =2*物理内存 8G+ =4G
cat /proc/meminfo |grep SwapTotal 查看交换分区的大小
free -m 查看内存(以MB)
blkid +磁盘设备 查看磁盘UID
mount 挂载文件系统 ,ISO镜像
mount 查看当前挂载
mount [-t 类型] 存储设备 挂载点目录 mount /dev/sd** /media/
mount -o -loop ISO镜像文件 挂载点目录
mount -a 挂载/etc/fstab中已记录的所有挂载
umount 卸载已挂载文件系统
umount 存储设备位置或umount 挂载点目录
umount -a 卸载所有/etc/fstab已记录的挂在(!危险操作)
如果卸载不掉,用下列命令: umount –lf [挂载点]
设置文件系统的自动挂载
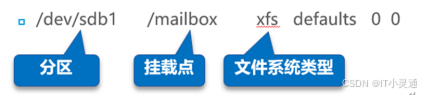
/etc/fstab 配置文件,此目录内包含需要开机后自动挂载的文件系统记录
default 默认
auto 系统自动挂载
noauto 开机不自动挂载
user 任何用户都可以挂载
nouser 只允许管理可以挂载
r0 按只读权限挂载
rw 按读写权限挂载
dump 备份设置,为1时,允许dump程序进行备份,为0时忽略备份
fsck 检查磁盘,为0时,永远不检查,根分区永远为1,其他分一般为2
df 查看文件系统分区情况及block 格式:df 选项 文件
-h 显示磁盘空间大小
-i 显示磁盘inode使用情况
-T 查看洗盘格式
查看UUID
blkid 查询或查看磁盘设备的相关属性
blkid /dev/设备名
blkid /dev/sdb1 >>/etc/fstab
LVM逻辑卷(Logical Volume Manager)
作用:动态调整磁盘容量,从而提高磁盘管理的灵活性
注意:/boot分区用于存放引导文件,不能基于LVM创建
LVM基本概念
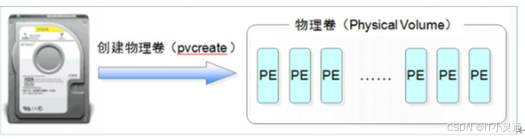
PV (Physical Volume),物理卷
整个硬盘,或使用fdisk等工具建立普通分区
包括许多默认4M大小的PE(Physical Extent,基本单元/物理单元)
VG(Volume Group)卷组

LV(Logical Volume)逻辑卷
从卷组中分割出的一块空间,用于建立文件系统
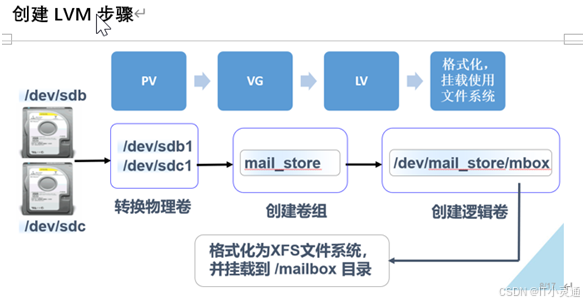
常见的LVM管理命令
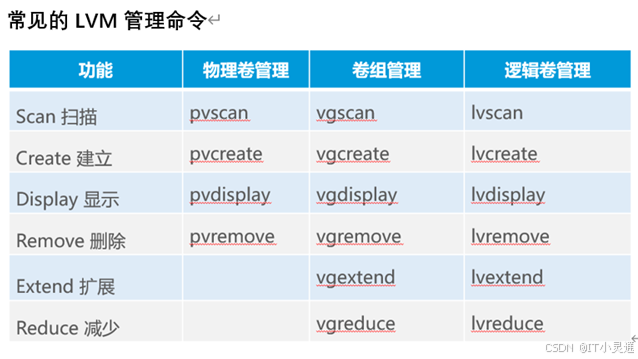
创建PVpvcreate 设备名1 设备名2 例:pvcreate /dev/sdb* /dev/sdb*
创建vgvgcreate 卷组名 物理卷名1 物理卷名2 例:vgcreate vg名字 /dev/sdb* /dev/sdb*
创建lvlvcreate –l PE数 –n 逻辑卷名 卷组名 例:lvcreate –l PE数 –n lv01 vg01
缩减VG:首先要手动将这个pv数据移动到其他地方,然后pvmove 磁盘名 删除要缩减的pv名
pvmove /dev/sdb* /dev/sda* 将/dev/sdb*这个磁盘的数据移动到其他pv中
vgreduce vg名 磁盘名 减小vg大小
vgreduce testvg /dev//sdb* 将/dev/sdb*从vg中移除
pvremove 磁盘名 移除vg中减小掉的pv
扩容VG:首先保证还有可用的PV卷,才可扩容VG
将磁盘转化为PV
vgextend vg名 磁盘名 扩展vg大小
lvreate –L 5G testlv testvg
lvcreate –l 100%VG –n lv01 vg01 (一般用lvexten –l PE数 /dev/vg01/lv01)
创建完成后直接mke2fs格式化/dev/vg名/lv名
mount挂载使用
lvm在线扩容:首先保证还有可用的PV卷,才可扩容VG
先扩展lv物理容量
lvextend –L 大小(不要超过剩余VG大小) lv名
-L[不带+是扩展到,带+号表示扩展了]
-l 按照pe大小看来扩展
示例:lvextend –L 8G /dev/vg*/lv*
再扩展lv逻辑容量
resize2fs /dev/vg名/lv名 大小
resize2fs –p 表示扩展到最大 /dev/vg*/lv*
在contos7中,如果文件系统是xfs. 执行resize2fs报错
解决办法:执行 xfs_growfs /dev/vg01/lv01
卸载LVM
先卸载挂载 umount 挂载路径
卸载顺序:lv 、vg、 pv
LV lvremove /dev/vg01/lv01
Vg vgremove vg01
Pv pvremove /dev/sd**
附加命令:重读分区表:partprobe /dev/sd*
扩展:快照卷(相当于灾备)
用于备份某一不能超出快照卷大小时段卷组上的文件
- 生命周期为整个数据时常,在这段时长内,数据的增长量不能超出快照卷大小
- 快照卷应该是只读的
- 跟原卷在同一卷组内
服务器RAID
磁盘阵列介绍
RAID简介:RAID(Redundant Array of lnexpensive Disks)称为廉价磁盘冗余阵列。RAID的基本想法是把多个便宜的小磁盘组合到一起,成为一个磁盘组,使性能达到或超过一个容量巨大、价格昂贵的磁盘。
RAID有两种:硬件RAID技术和软件RAID技术
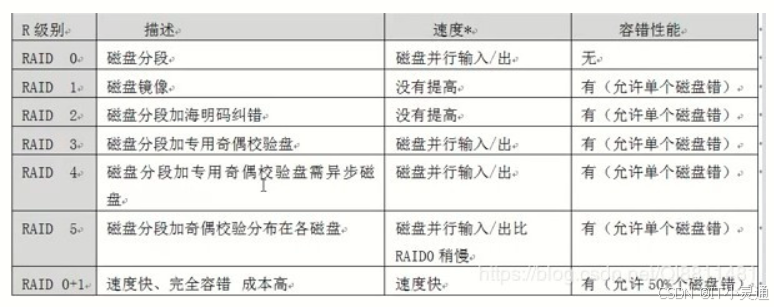
RAID级别介绍(每块磁盘大小应相等,否则按最小磁盘来计算总大小)
RAID 0:也称条带模式(striped),把连续的数据分散到多个磁盘上存取,当系统有数据请求就可以被多个磁盘并行的执行,每个磁盘执行属于他自己的那部分数据请求。这种数据上的并行操作可以充分利用总线的带宽,显著提高磁盘整体存取性能。读取和写入是在设备上并行完成的,读取和写入性能将会增加。RAID 0没有数据冗余,无法恢复数据
RAID 1:又称为镜像(Mirroring),一个具有全冗余的模式。把用户写入一个磁盘的数据百分之百的自动复制到另一个磁盘上,从而实现存储双份的数据优点:可靠性高。缺点:有效容量减小到总容量的一半。
RAID 4:需3块或更多的磁盘。他在一个驱动器上保存校验信息,并以RAID 0方式将数据写入其他磁盘。因为一块磁盘是为校验信息保留的,所以阵列大小为(N-1)*S, S:阵列磁盘中最小驱动器大小,N:磁盘数。最多允许一块磁盘出现故障。缺点:在大量写入数据时很容易造成校验磁盘的瓶颈。
RAID 5:结合大量物理磁盘并且保留一些冗余,可以用在3块或更多的磁盘上并使用0块或更多的备用磁盘。RAID 5大小:(N-1)*S
RAID 5和RAID 4的区别:RAID 5校验信息均匀分布在各个驱动器上,可以有效避免RAID 4中出现的瓶颈问题。最多允许一块磁盘出现故障。 当出现多块磁盘出现故障,所有数据都会丢失
RAID 6:在RAID 5基础上扩展而来,在RAID 5基础上额外加一块校验磁盘,最少需要4块盘。最多允许两块磁盘发生故障。
RAID 1+0:最少用4块盘(必须为偶数)。有冗余,读写快
RAID 0+1:最少用4块盘(必须为偶数)。有冗余,读写快
RAID 5+0:最少用6块盘,具有RAID 5和RAID 0的共同特性。先用3块盘组成RAID 5,然后再由至少两组RAID 5组成RAID 0。 优点:高可靠性存储,高读取速度,高数据传输性能
RAID优缺点
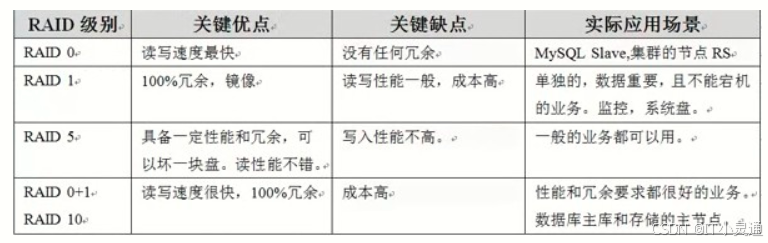
RAID级别定义
mdadm命令 实现软件RAID,跟随不同选项作用不同 格式:mdadm 选项 参数
-C/--create:创建一个新的软RAID,后面接RAID设备名称。例:/dev/md0 /dev/md1
-A/--assemble:加载一个新的软RAID,后面跟阵列以及设备名称
-S/-stop:停止指定的RAID设备
-D/--detail:输出指定RAID设备的详细信息
-s/--scan:扫描配置文件或/proc/mdstat文件来搜索软RAID的配置信息,该参数不能单独使用,只能配合其他参数才能使用
-l/--level:设置RAID的级别,例:“--level=5”则代表创建阵列的级别是RAID 5
-n/--raid-devices:指定阵列中活动磁盘的数目
-x:指定阵列中备用磁盘数
-G/--grow:改变在用阵列的大小或形态
-v/--verbose:显示细节
例:mdadm –Cv /dev/md5 –l 5 –n 3 –x 1 /dev/sdb1 /dev/sdc1 /dev/sdd1 创建raid 5
mkfs.xfs /dev/md5 格式化raid 5
mount /dev/md5 /要挂载的目录 挂载
阵列卡(raid卡)
阵列卡是实现RAID功能的板卡,由I/O处理器、硬盘控制器、硬盘连接器和缓存等构成
RAID卡的接口:IDE接口、SCSI接口、SATA接口、SAS接口
系统引导过程与服务控制
Contos7启动过程
开机进行BIOS自检à读MBR引导à加载GRUB界面à加载内核à启动systemd程序à读取系统运行级别à系统初始化à并行启动各种服务à显示用户登录界面
BIOS加电自检-->MBR的boot loader引导-->加载grub2菜单-->加载Kernel初始化{使用 initramfs(根)/vmlinuz 内核映像}-->启动 systemd(第一个程序)-->读取系统运行级别default.targete
- BIOS加电自检(检测计算机硬件信息)
- MBR(boot loader)引l导装载程序,centos7是grub2
- 加载装载程序的配置文件:/etc/grub.d/、/etc/default/grub,/boot/grub2/grub.cfg
- 加载initramfs驱动模块
- 加载内核选项
- 内核初始化,centos7使用systemd代替init
- 执行initrd.target所有单元,包括挂载/etc/stab
- 从initramfs根文件系统切换到磁盘根目录
- systemd执行默认target配置,配置文件/etc/systemd/system/default.target
- systemd执行sysinitarget初始化系统及basic.target准备操作系统
- systemd启动multi-user.target下的本机与服务器服务
- systemd执行multi-user.target下的/etc/rc.d/rc.local
- systemd执行multi-user.target下的getty.target及登录服务
- systemd执行graphical需要的服务
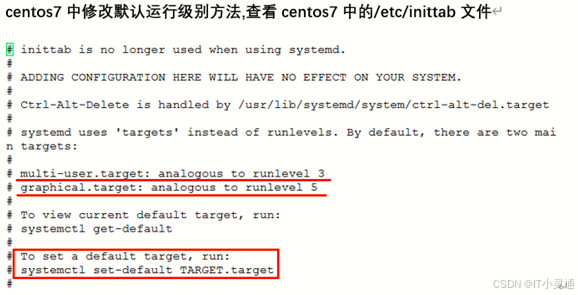
在centos7系统中,init进程软链到了systemd。此时systemd成为linux第一个进程(PID=1),接管系统启动。
systemd概述
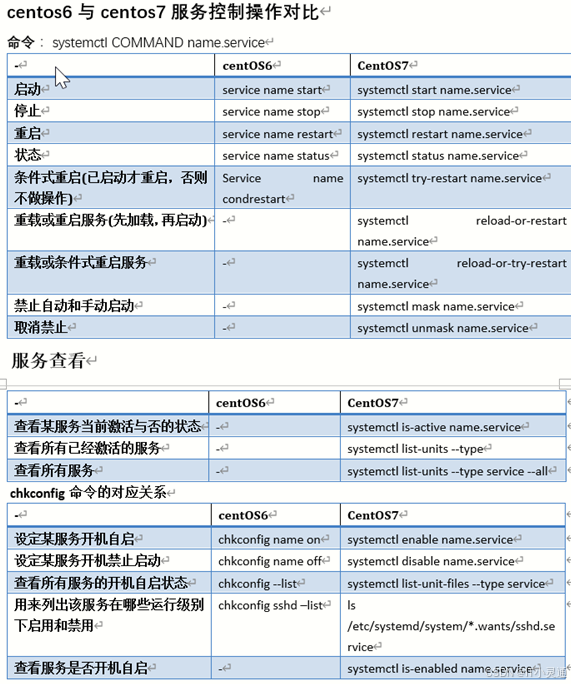
Systemd是Linux操作系统的一种init软件,CentOS7系统中采用了全新的Systemd启动方式,取代了传统的SysVinit。Systemd启动方式使系统初始化时诸多服务并行启动,大大增高了开机效率。CentOS7系统中“/sbin/init”是“/lib/systemd/system”的链接文件,换言之,CentOS7系统中运行的第一个init进程是lib/systemd/system。systemd守护进程负责Linux的系统和服务。systemctl用于控制Systemd管理的系统和服务状态.
systemctl 控制类型 服务名称 系统服务控制(systemctl restart sshd)
控制类型
start:启动
stop:停止
restart:重新启动
reload:重新加载
status:查看服务状态
systemctl list-unit-files 查询系统开机启动项
enabled(开机启动) disabled(开机不启动)
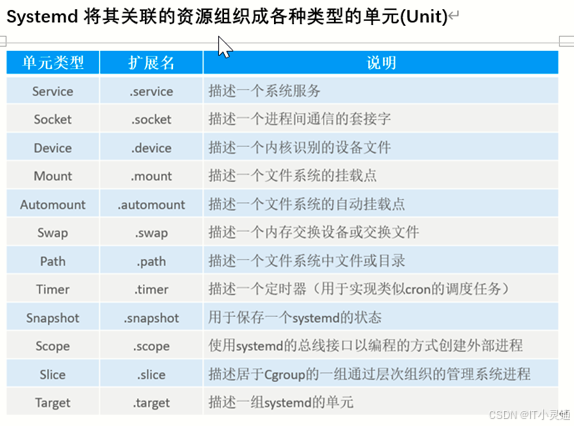
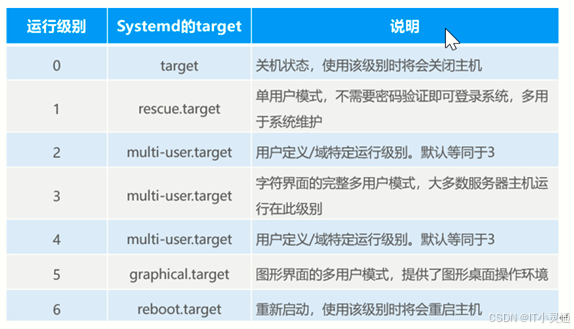
系统启动级别
Linux系统服务是指运行在后台并提供特定功能的应用程序。如网站服务、FTP服务等.Linux通过将不同的系统服务进行搭配组合来协同满足不同的功能需求。不同的服务组合其实现的功能也各不相同,就好比不同的药方能医治不同的病症一样。
早期Linux操作系统中的SysVinit机制默认包括七种不同的服务搭配方式,其中每一种搭配方式称为运行级别,类似于Windows系统中的正常启动,安全模式、不带网络连接的安全模式等,这些运行级别分别使用数字,1...6来表示,为了向下兼容SysVinit系统,Systemd使用了相应的target(目标)模拟了SysVinit的运行级别
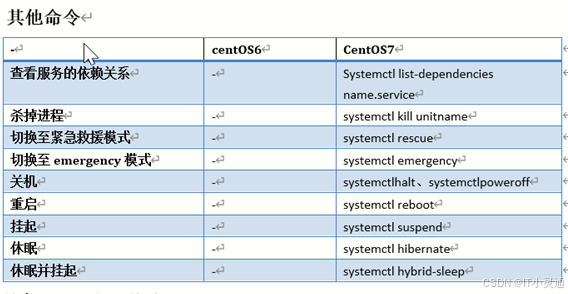
init 服务启动命令
修复MBR扇区故障
损坏MBR扇区
mount /dev/sdb1 /mbr
dd if=/dev/sda of=/mbr/mbr.bak bs=512 count=1
dd if=/dev/zero of=/dev/sda bs=512 count=1
进入急救模式下
mkdir /mbr
mount /dev/sdb1 /mbr
dd if=/mbr/mbr.bak of =/dev/sda bs=1 count=512
修复GRUB引导故障
方法一:尝试手动输入(提前先记下内核的UUID或者存储绝对路径)
cat /boot/grub2/grub.cfg
insmod xfs
set root='hd0,msdos1
linux16/mlinuz-3.10.0-957.21.2.el7.x86 64 root-UUID-2fc91db1-9e47-44bd-8ab9-
99eea702f788
initrd16/initramfs-3.10.0-957.21.2.el7x86 64.img
模拟grub.ctg文件损坏
mv /boot/grub2/grub.cfg{,.bak}
shutdown -r now
修复
insmod xfs
set root=’hd8, msdos1’
linux16/mlinuz-3.10.0-957.21.2.el7.x86 64 root-UUID-2fc91db1-9e47-44bd-8ab9-
99eea702f788
initrd16/initramfs-3.10.0-957.21.2.el7x86 64.img
boot
开机后
mv /boot/grub2/grub.cfg.bak /boot/grub2/grub.cfg
方法二:进入急救模式,重建grub程序。(挂载sdbl,并备份sda的前446字节数据,然后毁坏前446字节数据,reboot重启)
mkfs.xfs /dev/sdb1
mkdir /mbr mount /dev/sdb1 /mbr/
dd if=/dev/sda of=/mbr/grub.bak bs=1M count=446
dd if=/dev/zero of=/dev/sda bs=1M count=446
修复
mount /dev/sdb1 /mbr
1s /mbr
dd if=/mbr/grub.bak of =/dev/sda bs=1M count=416
reboot
修改Linux的root账户密码
开机进入此界面快速按方向键暂停启动,按e进入编辑模式找到以linux16开头的行,在行尾加入内核参数(空格)rd.break,按ctrl+X引导
将/sysroot下的所有文件设置为可读写模式(mount –o remount,rw /sysroot/)
修改系统根目录到/sysroot用passwd root修改密码(输入两次密码)(chroot /sysroot/)
(passwd root)
由于系统默认开启selinux安全机制,所以输入“touch /.autorelabel”,来创建文件系统的安全标签。
(touch /.autorelabel)
(exit)
(reboot)
重启后密码已修改
程序和进程的关系
1.程序
保存在硬盘、光盘等介质中的可执行代码和数据
静态保存的代码
2.进程
在CPU及内存中运行的程序代码
动态执行的代码
父、子进程:每一个进程可以创建一个或多个进程
/proc目录下每个数字目录对应一个进程init:进程号(PID)为1
ps统计查看进程信息(ps aux /ps -elf)
a:所有与终端有关的进程
u:启动此进程的用户
x:所有与终端无关的进程
-e:显示系统内的所有进程信息
-1:使用长(long)格式显示进程信息
-f:使用完整的(full)格式显示进程信息
ps aux|grep “进程名称”(查看某个进程的详细信息)
ps aux:以简单列表的形式显示出进程信息
显示信息的每列解释
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
用户 | PID号 | 占CPU百分比 |
| 虚拟内存 | 常驻内存 | 运行终端 | 运行状态 | 启动时间 | 占CUP的时长 | 此进程的运行命令(带中括号的为内核线程)
进程状态:
D:不可中断的睡眠
R:运行或就绪
S:可中断的睡眠
T:停止
Z:僵死
<:高优先级进程
N:低优先级进程
+:前台进程组中的进程
1:多线程进程
s:会话进程首进程
top动态查看进程统计信息
top命令会在当前终端以全屏交互式的界面显示进程排名,及时跟踪包括CPU、内存等系统资源占用情况,默认情况下三秒刷新一次,默认以CPU占用率排序。
选项:
-d:指定刷新的间隔时间,单位秒
-b:以批量处理模式操作,一般与-n同时使用
-n:指定循环显示的次数
-u:指定用户名
-p:指定进程号
常用交互命令
P:根据CPU使用百分比大小进行排序(默认进入时即为此排序)
M:根据驻留内存大小进行排序
T:根据累积时间进行排序
k:终止一个进程
q:退出程序
当CPU占用率过高时,不应再直接执行top命令查看,可以将信息存入一个文件内查看,以免CPU占用率过高导致崩溃。操作如下:
top –b –n 1 >/topinfo.txt
cat /topinfo.txt
uptime 查询linux系统负载的
top显示信息解释
top-16:58:24 [当前系统时间]
1:54 [系统已经运行1小时54分钟]
2 users [当前登录2个用户]
load average:0.00.00.0.00 [系统平均负载:1分钟的,5分钟的,15分钟的]
Tasks:108 total [任务:108个总进程]
1 running [1个进程正在运行]
107 sleeping [107 个进程睡眠]
o stoppd [0个进程停止]
- zombie [0个僵尸进程(冻结进程)]
cpu(s):0sus [用户控件占用CPU百分比]
0.0%sy [内核空间占用CPU百分比]
0.0%ni [用户进程空间内改变过优先级的进程占用CPU百分比]
100.0% [空闲CPU百分比]
0.0%wa [等待输入输出的CPU时间百分比]
0.0%hi [硬件中断]
0.0%si [软件中断]
Mem:1012352k total [物理内存总量1012352k]
465816k used [使用了465816k的物理内存]
546536kfree [空闲546536k的物理内存]
61064k buffe [61064k用作内核缓存]
Swap:2031608k total [交换分区总量2031608k]
Ok used [没有使用交换分区]
2031608k free
[空闲的交换分区总量2031608k]
267580k cache [缓冲的交换分区总量267580k]
PID:进程号
USER:进程所有者的用户名
PR:优先级
NI:nice值。值表示高优先级,正值表示低优先级
VIRT:进程使用的虚拟内存总量,单位kb
RES:进程使用的、未被换出的物理内存大小,单位kb
SHR:共享内存大小,单位kb
S:进程状态
%CPU:上次更新到现在的CPU时间占用百分比
%MEM:进程使用的物理内存百分比
TIME+:进程使用的CPU时间总计单位1/100秒
COMMAND:使用的命令
查看进程信息
pgrep:根据特定条件查询PID信息
-1 显示进程名
-U 指定特定用户
-t 指定终端
pstree以树形结构列出进程信息
-a 显示完整信息
-u 列出对应用户名
-p 列出对应PID号
进程启动方式
手工启动:
前台启动:用户输入命令,直接执行程序
后台启动:在命令行尾加入"&"符号
进程的前后台调度
Ctrl+Z将当前进程挂起,即调入后合并停止执行
jobs 查看处于后台的任务列表,加-1同时显示PID号
fg 将后台进程恢复到前台运行,可指定任务程序号
bg 将后台暂停的进程调至后台运行

示例:vim/etc/ssh/sshd_config 进入到vim编辑器中按Ctrl+z
终止进程的运行
1>Ctr+C中断正在执行的命令
2>kill或 killall
kill 用于终止指定PID号的进程
killall 用于终止指定名称的所有进程
-9选项 用于强制终止
pkill 根据特定条件终止相应的进程
-U 根据进程所属的用户名终止相应进程
-t 根据进程所在的终端终止相应进程
调度启动
使用at命令,设置一次性任务计划
启动at服务:systemctl start atd
设置格式:at 时间 年月日 (设置当天的任务计划可不加日期)
基本操作: Ctri+D保存退出
atq查询现有的一次性任务计划
atrm[任务序号]删除第几项任务
crontab命令设置周期性计划任务
服务名称:cronde
全局主要配置文件:/etc/crontabe
计划任务配置文件:1l /etc/cron*
cron.d/ 系统级别定时任务
cron.daily/ 每天执行一次
cron.deny 黑名单
cron.hourly/ 每小时一次
cron.monthly 每月一次
crontab cron.weekly/ 每周一次
定义的计划任务位置:/var/spool/cron/
管理cron计划任务
crontab
-1 列出当前用户的所有cron任务
-e 编辑用户自己的cron配置文件(可以帮助检查语法错误)
-r 移除所有任务
-u 用户名 管理其用户的cron任务
管理员为普通用户创建任务计划
crontab –u 用户名 –e:为其他用户编辑计划任务
crontab –u 用户名 –r:清空此用户的计划任务
crontab任务配置的格式 (* * * * * crontab)注:需要执行的命令用绝对路径
格式:分钟 小时 日 月 周 用户任务(系统自己执行不需要用户设置)
第一段应该定义的是:分钟,表示每个小时的第几分钟来执行。范围是从0-59
第二段应该定义的是:小时,表示从第几个小时来执行,范围是从0-23
第三段应该定义的是:日,表示从每个月的第几天执行,范围从1-31
第四段应该定义的是:月,表示每年的第几个月来执行,范围从1-12
第五段应该定义的是:周,表示每周的第几天执行,范围从0-7,其中0表示星期日
第六段应该定义的是:用户名,也就是执行程序要通过哪个用户来执行,这个一般可以省略
第七段应该定义的是:执行的命令和参数
计划任务时间格式
时间的有效取值:分钟0-59 小时0-23 日1-31 月1-12 周0-7,0和7都表示周日
时间通配符表示
*:对应时间的所有有效取值
,:离散时间点连续时间点
-:连续时间点
/:对应取值范围内每多久一次
系统安全及应用
基本安全措施
对系统账号的操作
将非登录用户的shell设为/sbin/nologin
方法一:usermod -s
方法二:chsh命令,交互式修改
方法三:chsh -s
方法四:vim编辑/etc/passwd文件进行修改
锁定长期不使用的账号
方法一:passwd -1(将在密文前增加2个“!!”)解锁 passwd-u 查看 passwd
方法二:usermod -L(将在密文前增加1个“!”)解锁usermod -U
也可以直接vim编辑/etc/shadow文件进行修改。
删除无用的账号:userdel[-r]用户名
锁定账号文件/etc/passwd,/etc/shadowe
锁定:chattr +i/etc/passwd/etc/shadow
解锁:chattr-i/etc/passwd/etc/shadow
查看:Isattr/etc/passwd/etc/shadow
注意:锁定后即使是超户,也不能修改该文件,即不能创建、删除、修改用户信息。
密码安全控制
设置密码有效期
修改某个已存在用户的密码有效期:
chage –M 天数 用户名
passwd –x 天数 用户名
设置今后添加用户时的默认密码有效期:
方法:vim编辑/etc/login.defs文件,修改"PASS_MAX_DAY"后面的数值
要求用户下次登录时修改密码
方法:chage –d 0用户名
命令历史限制
减少历史的命令条数
方法一:vim编辑/etc/profile文件,修改"HISTSIZE-"后面的数值
方法二:export HISTSIZE=数值
示例:方法一[全局生效]:vi编辑/etc/profile文件,修改"HISTSIZE=5"
(vim +46/etc/profile)
仅当前用户环境下生效:export HISTSIZE=100
注销时自动清空历史命令
方法:vim编辑宿主目录下的".bash logout"文件,添加"history -c"
终端自动注销
方法一:vim编辑/etc/profile文件,添加"TMOUT=数值"(全局生效)
方法二:export TMOUT=数值(仅当前用户环境下生效)
source/etc/profile 或 . /etc/profile 重读环境变量
/etc/profile的作用:
通常每个用户默认的环境变量都是相同的,这个默认的环境变量实际上就是一组环境变量的定义。用户可以对自己的运行环境进行定制,其方法就是修改相应的系统环境变量。
在profile文件中修改环境变量,这里修改的内容就是对所有用户起作用的变量环境。
在修改完成后需要输入命令source /etc/profile来立即生效。
切换用户su命令
格式:su[-]目标用户(有“-”初始化环境变量,无“-”环境变量不改变)
查看su操作记录
安全日志文件:/var/log/secure
sudo提升权限
su命令的缺点:在使用su命令时,不指定用户名默认切换至root用户,需要输入root密码,但实示生产中root密码是不可以被广泛告知的。如果需要执行root用户才有权限的命令,需要通过sudo命令设置来实现。
sudo命令:以其他用户身份(默认root身份)执行授权的命令sudo授权的命令
默认设置为首次执行时,需输入当前用户的登录密码,5分钟内再次执行sudo命令时则无需再输入密码。
配置sudo授权:编辑visudo(检查语法正确性)或者vim /etc/sudoers(不检查语法正确性),添加配置内容格式:指定的用户(tab键)主机名=(以哪个用户身份)(tab键)要执行的命令绝对路径
注意:多个命令中间要用逗号 “,”隔开,命令前加 “!”表示“除了” 此命令
test01 ALL=(root) /usr/sbin/useradd,/usr/bin/passwd, !/sbin/reboot
wheel组授权
gpasswd -a 用户名 wheel
设置用户或组的别名
visudo
##Allows people in group wheel to run all commands
User_ Alias WWW = test01,%test
WWW ALL=(ALL) ALL
设置别名
添加格式:用户别名 主机别名=命令别名(所有别名均大写)
设置sudo操作记录(visudo –c检测visudo的语法性)
第一步:rpm -qa sudo rsyslog 查看这个安装包是否安装,未安装安装
第二步:visudo或者vi /etc/sudoers 添加"Defaults logfile=/var/log/sudo"
第三步:cat/var/log/sudo
扩展:免输sudo密码执行sudo命令
visudo
test01 ALL=(root) NOPASSWD: /usr/bin/sudo, /bin/su
PAM安全认证
su命令的安全隐患
默认情况下,任何用户都允许使用su命令,从而有机会反复尝试其他用户(如root)的登录密码,带来安全风险。为了加强su命令的使用控制,可以借助于PAM认证模块只允许极个别用户使用su命令进行切换
PAM可插拔式认证模块
PAM是一种高效而且灵活便利的用户级别的认证方式,它也是当前Linux服务器普遍使用的认证方式
PAM提供了对所有服务进行认证的中央机制,适用于login,远程登录(telent,rlogin,ftsh,ftp),su等应用程序。系统管理员通过PAM配置文件来制定不同应用程序的不同认证策略。
PAM认证原理
PAM认证一般遵循的顺序:Service(服务)àPAMàpam*.so
PAM认证首先要确定哪一项服务,然后加载相应的PAM的配置文件(位于/etc/pam.d下),最后调用认证文件(32位系统位于/lib/security下,64位系统位于/lib64/security下)进行安全认证。下图为Linux x86 64位系统中PAM的配置文件
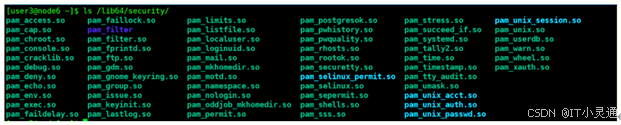
用户访问服务的时候,服务器的某一个服务进程把用户的请求发送到PAM模块进行认证。不同的应用程序所对应的PAM模块也是不同的。如果想查看某个程序是否支持PAM认证,可以用ls命令进行查看,(如查看su是否支持PAM模块认证 ls /etc/pam.d|grep su )
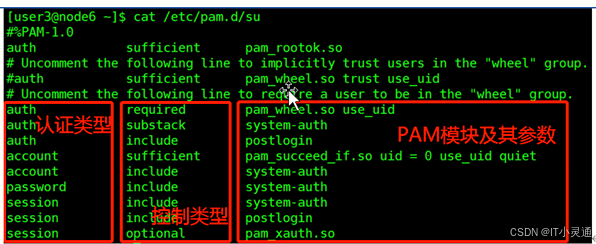
PAM认证的构成
每一行都是一个独立的认证过程
每一行可以区分为三个字段:认证类型、控制类型、PAM模块及其参数
示例:查看su的PAM配置文件
常见的四种认证类型

常见的五种控制类型
(1)required验证失败时仍然继续,但返回Fail
(2)requisite验证失败则立即结束整个验证过程,返回Fail
(3)sufficient验证成功则立即返回,不再继续,否则忽略结果并继续
(4)optional不用于验证,只是显示信息(通常用于session类型)
(5)include不进行认证,转到后面PAM模块进行认证
PAM安全认证流程
控制类型也可以称做Control Flags.用于PAM验证类型的返回结果
1.required验证失败时仍然继续,但返回Fail
2.requisite验江失败则立即结束整个验证过程,返回Fail
3.sufficient验证成功则立即返回,不再继续,否则忽路结果并继续
4.optional不用于验证,只显示信息(通常用于session类型)
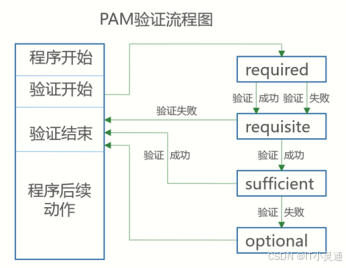

使用PAM认证模块,限制某个命令或是服务的使用权限
1.vim编辑该命令在/etc/pam.d/su下对应的配置文件,启用pam_wheel模块
2.添加授权用户到wheel组
gpasswd-M amber,user1 wheele
grep wheel/etc/group
wheel:x:10:amber.user1
开关机安全控制
调整BIOS引导设置
将第一引导设备设为当前系统所在硬盘
设置BIOS管理密码
给BIOS程序引导进入系统加密
禁用重启热键Ctrl+Alt+Del
目的:避免用户误操作
方法:vim /etc/inittabe
如果ctrl-alt-del.target文件没有找到(初始安装的系统无此文件),即已经禁用Ctri-Alt-Del热键,如果ctr-alt-del.target文件能找到,将ctrl-alt-del target删除即可
/usr/lib/systemd/system/ctrl-alt-del.target
grub莱单加密及密码清除
示例:查看grub登录用户名/etc/grub.d/01_users,我们可以看到用户名为root
设置grub密码
grub2-setpassword 输入此命令,设置grub密码123.com
确认grub密码,cat /boot/grub2/user.cfg
sync
重启验证
grub密码清除
grub2-setpassword 为空
rm –rf /boot/grub2/user.cfg
sync
终端登录安全控制
减少开放终端个数
方法:vim编/etc/sysctl.conf配置文件,在行尾添加kernel.pty.max =3,并执行sysctl -p命令
限制root只在安全终端登录(没什么用,忽略此案)
方法:vim编辑/etc/securetty配置文件,将禁止的终端注解掉(文件修改后立即生效)
禁止普通用户登录
方法:touch /etc/nologin,删除/etc/nologin这个空文件即可恢复。
弱口令检测JR(Joth the Ripper)
JR(Joth the Ripper)简介:一款密码分析工具,支持字典式的暴力破解,通过对shadow文件的口令分析,可以检测密码,官方网站:http://www.openwall.com/iohn/
安装JRI具
tar包解压
进到解压后的src目录下,执行make clean
进到解压后的run目录下,执行命令
john使用
下载包
tar xf john-1.8.0.tar.xz
cd john-1.8.0/src/
编译安装
make
make clean linux-x86-64
规则:
--stdout 输出结果到屏幕
--restore 从上次解密中断的地方继续执行,ctrl+c 中断执行,当前的状态会被存放在一个名为restor的文档内,使用--restore可以从restore内读取上次中断的位置,然后继续破解下去
--session 设定当前记录档的名称
--make-charset 字元频率表,他会以破解出来的密码为基础来产生字元频率表,可用于Incremental模式
--show 显示已经破解密码,因为john.POT并不存储账号信息,使用show的时候应该输入相关的passwd文件
--test 测试机器执行各种类型密码的破解速度
--users 只破解某个账号的密码,可以是用户名或者UID号码,前面加‘-’表示不破解相关用户密码
--groups 只破解某个组内的用户密码,前面加上‘-’表示不破解某个组内用户的密码
--shells 之破解使用某种类型shell的用户,前面加上‘-’表示不破解
--salts 只破解salts大于count的密码,salts是unix用来作为密码编码的基础单位
--format 预定义密码破解的类型 DES/BSDI/MD5/BF/AFS/LM/
标准模式
破解简单密码(如123456等或与账户名相同)
cd /opt/john-1.8.0/run
普通用户:./unshadow /etc/shadow > /root/john-1.7.8/run/passwd.test
root:cat /etc/shadow > passwd.test
./john passwd.test -single
查看破解密码:
./john passwd.test -show
字典模式
破解稍微变化密码(大小写等)(使用默认的password.lst)(这个时候已经很慢了)
./john -wordlist=password.lst passwd.test
./john -wordlist=password.lst -rules passwd.test
清空破解记录(>john.pot)
如果不清空破解记录会报错,没有密码哈希值可以破解(请参阅常见问题解答)
完全模式(如果电脑够强大,可以试试。我自认配置不够)
./john --incremental=All passwd.test
总结
john是一个不错的测试工具,可以检查系统里的账号是否有弱密码。并且当配置达到足够要求后,可以尝试爆破所以用户的密码。建议在云平台上自建一台虚拟机用以爆破,不然等待时间是非常漫长的。正因为破解速度不足,这款破解工具没太大实际意义,只用于检测即可。
端口检测 NMAP
NMAP简介:一款强大的网络扫描、安全检测工具
官方网站:http://nmap.org/、
可从光盘中安装nmap-5.51-3.el6 x86_64.rpm
NMAP的扫描语法 127.0.0.1 本机IP
nmap[扫描类型][选项]<扫描目标>
常用的扫描
-sS TCP SYN扫描(半开)
-sT TCP链接扫描(全开)
-sF TCP FIN扫描
-sU UDP扫描
-sP ICMP扫描
-s0 跳过ping检测【较少使用】
常用选项
-n 禁止DNS反向解析
-p 指定端口中
查看端口占用
netstat -anlp | grep 8888
ss -anlp | grep 80
192.168.1.0/24 含义
192.168.1.0/24表示网段是192.168.1.0,子网掩码是24位,子网掩码为:255.255.255.0,用二进制表示为:11111111 11111111 11111111 00000000 ,这里为什么是24呢,就是因为子网掩码里面的前面连续的“1”的个数为24个,一定要连续的才行。 再给你举个例子,192.168.1.0/28表示的意思是网段是192.168.1.0,子网掩码为:255.255.255.240,用二进制表示为:11111111 11111111 11111111 11110000。 这时候你也许就疑惑了,就是24和28两个字不一样,为什么网段是一样的呢? 24位说明网络位是24位,那么主机位就是32-24=8位了,则子网的IP个数是254个,即是从00000001到11111110. 28位说明网络位是28位,那么主机位4位,则子网的IP个数是14个,即是从00000001到00001110.
安装nmap
mount/dev/sro/media/
mount: /dev/sr0 写保护,将以只读方式挂载
rpm –ivh /media/Packages/nmap-6.40-16.el7.x86_64.rpm
Linux文件系统日志
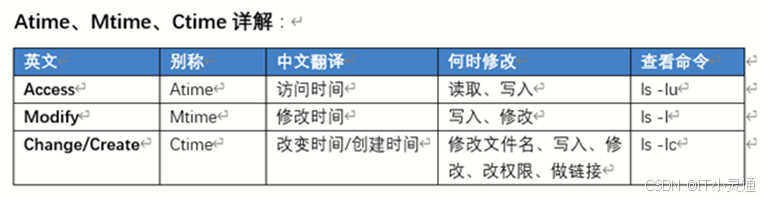
inode和block概述
文件储存在硬盘上,硬盘的最小储存单位叫"扇区"(sector),每个扇区储存512字节
操作系统读取硬盘的时候,不会一个个扇区的读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个“块"(block)。这种由多个扇区组成的"块",是文件存取的最小单位。“块”的大小,最常见的是4KB,即连续八个sector组成个block。block存储文件数据
文件数据存储在“块"中,那么还必须找到一个地方存储文件的元信息,比如文件的所属用户,文件所属组,文件的类型,文件的权限,文件的创建时间,文件的修改时间,文件的访问时间,文件使用的block信息,文件的硬链接数,文件的大小等等属性信息。这种储存文件元信息的区域叫做inode,中文译名为"索引节点",也叫i节点
inode和block是文件系统组成的基本核心概念,文件系统是在分区格式化的时候形成的,文件系统负责组织文件在分区上的存放
注意
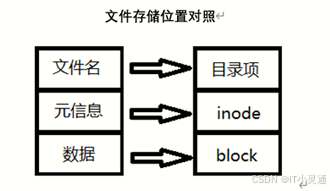
inode不包含文件名,文件名是存储在目录的目录项中
一个文件必须占用一个inode,但至少占用一个block.
查看文件的inode信息,stat命令
目录文件的结构
目录也是一种文件

每个inode都有一个号码,操作系统用inode号码来识别不同的文件
Linux文件系统内部不使用文件名引用文件,而是使用inode号码来识别文件。对于文件系统来说,文件名只是inode号码便于识别的别称,文件名是目录的数据
inode的号码
系统内部打开文件的步骤:
1用户在目录中看到要访问的文件名
2通过目录的数据找到这个文件名对应的inode号码
3通过inode号码,获取inode信息(文件的元信息)
4根据inode信息,找到文件数据所在的block,读出数据
inode一般为128字节或256字节,每个inode中都记录着文件所在的block号的信息,每条记录着block号的信息占用4字节。inode中关于block号的记录一共包含有12个直接、1个间接、1个双间接和1个三间接。
12个直接连接,共占用48字节磁盘空闹,包含着12个直接指向block号的信息,若此文件系统默认的block大小为4KB,则仅仅可以指向12*4=48KB大小的文件内容,然而我们的文件若较大时,则需要使用到更多的block,肯定要多于12个block,进而有间接、双间接和三间接。
间接指的是,inode中所记录这4字节的内容,所指向一个block,这个block中存放的不是真实的文件内容,而是真实文件所存放位置的block号信息,若每个block大小为4KB,那么可以存放1024个block号信息,1个间接可以存放的文件大小为:1024x4-4096KB
双间接则可以存放更大的文件内容,即在间接的基础上再进行间接,若此时block大小为默认的4KB,则1个双间接可以存放的文件内容大小为:1024*1024x4=4096MB
三间接即在双间接的基础上在进行间接,若此时block大小为默认的4KB,则1个三间接可以存放的文件内容大小为:1024*1024*1024*4=4096GB,也就是说,在一个block大小默认为4KB的文件系统中,一个文件最大存储可以达到48KB+4096KB+4096MB+4096GB,约为4100GB,
查看文件的inode号码
ls -i文件名
stat 文件名
Superblock里面存储着文件系统所有lnode.block的相关信息
当一个用户在Linux系统中试图访问一个文件时,系统会先根据文件名去查找它的inode.看该用户是否具有访问这个文件的权限。如果有,就指向相对应的数据block;如果没有就返回 Permission denied(拒绝访问)
删除指定inode号所对应的文件
格式:find ./ -inum inode号 -exec rm -i {} \;
查看文件系统的inode与block的信息 df –i 设备名(文件系统已挂载时查询,查询inode总数与已用数量)
inode的数量与大小在磁盘格式化的时候就已经固定了
解决inode耗尽故障案例
#新加一块5G硬盘,格式化成ext4文件系统挂载到/data目录下
mkdir/data
mkfs.ext4 -N 10000 -b 1024 /dev/sdb1
mount/dev/sdb1/data/
df-i/data/
touch/data/{1..10230}.txt
df-i/data/
df-Th/data/
此时查看/dev/sdb1的空间大小并没有被占满,由此可见是inode数量不足了
解决inode耗尽导致的磁盘故障方法:
1>删除不使用的文件
2>将文件备份,重新格式化此文件系统,指定较多的inode个数
格式化时指定文件系统的inode个数与block大小方法:
mkfs.ext4 -N inode数 –b 块大小(单位字节) 设备名
深入理解Linux文件系统软硬链接原理
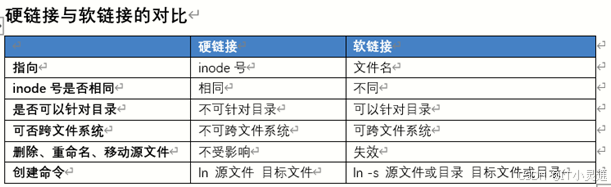
硬链接 (方法:ln 源文件 目标文件)
特点:硬链接指向的文件inode号,新生成的硬链接文件的inode号与源文件的inode号相同,不可针对目录进行硬链接,必须在同一文件系统内。删除一个文件名,不影响另外一个的访问。
软链接 (方法:ln –s 源文件或目录 目标文件或目录)
特点:软链接指向文件名,新生成的软链接文件的inode号与源文件不同,目录也可以生成软链接,软链接文件与源文件可以不在同一文件系统内,软链接文件的内容是源文件的路径读取时系统会自动导向源文件,根据原文件找到文件内容,但当源文件移动或重命名时,软链接将报错。
恢复误删除的文件理论:
注意:在数据被误删除后,第一时间要做的就是卸载被删除数据所在的分区,如果是根分区的数据遭到误删,就需要将系统进入单用户模式,并且将根分区以只读模式挂载。这样做的原因很简单,因为将文件删除后,仅仅是将文件的inode节点中的扇区指针清零,实际文件还储存在磁盘的block上,如果磁盘继续以读写模式挂载,这些已删除的文件的数据块就可能被操作系统重新分配出去,在这些数据库被新的数据覆盖后,这些数据就真的丢失了,恢复工具也无力回天。所以以只读模式挂载磁盘可以尽量降低数据库中数据被覆盖的风险,以提高恢复数据成功的比例。
分析日志文件
日志文件的作用
日志文件是用于记录Linux系统中各种运行信息的文件,相当于Linux主机的“日记”。不同的日志文件记载了不同类型的信息,如Linux内核消息、用户登录事件、程序错误等。
日志文件对于诊断和解决系统中的问题很有帮助,因为在Linux系统中运行的程序通常会把系统消息和错误消息写入相应的日志文件,这样系统一旦出现问题就会"有据可查"。此外,当主机遭受攻击时,日志文件还可以帮助寻找攻击者留下的痕迹。
日志文件的分类
内核及系统日志:
内核及系统日志:这种日志数据由系统服务rsyslog统一管理,根据其主配置文件/etc/rsyslog.conf中的设置决定将内核消息及各种系统程序消息记录到什么位置。系统中大部分的程序会把自己的日志文件交由给rsyslog管理,因而这些应用程序使用的日志记录格式都很相似
/etc/rsyslog.conf配置文件中,常见的配置格式及其含义:
“.”:比后面等级要高(包含该等级)的都记录。例如:*.info
“=”:只记录该等级。例如:=debug
“!”:除了该等级都记录。例如:!info
“-”:当有记录信息需要记录时,先存到缓存中,到一定大小时一次性写入,以减少对磁盘读写性能的占用。例如:-/var/og/maillog
用户日志:用于记录Linux系统用户登录及退出系统的相关信息,包括用户名、登录的终端、登录时间、来源主机、正在使用的进程操作等。
程序日志:有些应用程序会选择由自己独立管理一份日志文件,而不是交给rsyslog服务管理,用于记录本程序运行过程中的各种事件信息。由于这些程序只负责管理自己的日志文件,因此不同程序所使用的日志记录格式也会存在较大的差异
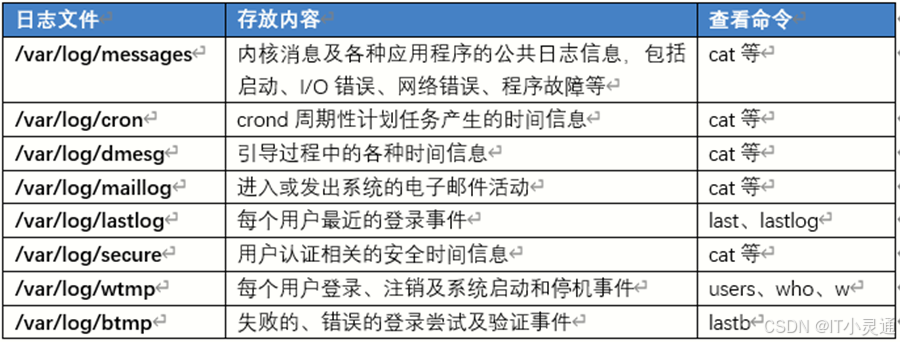
日志文件的位置
Linux系统本身和大部分服务器程序的日志文件默认放在/var/log/下。一部分程序共用一个日志文件,一部分程序使用单个日志文件。而有些大型服务器程序日志由于日志文件不止一个,所以会在/var/log/目录中建立相应的子目录来存放日志文件,这样既保证了日志文件目录的结构清晰,又可以快速定位日志文件。有一部分日志只有root用户才有权限读取,这保证了相关日志信息的安全性。
常见的日志文件及查看方式
日志消息级别
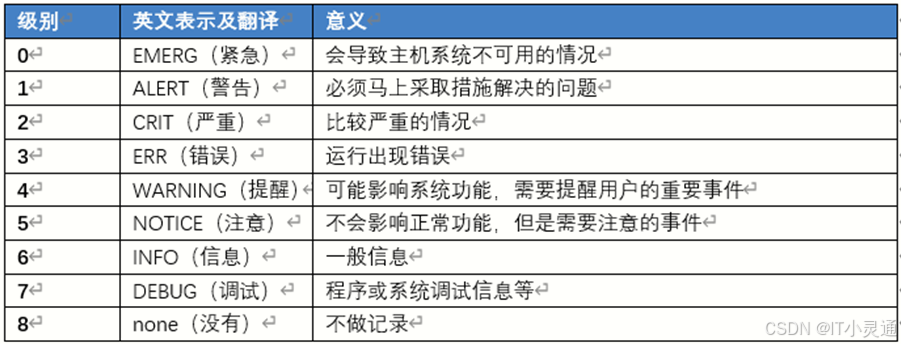
在Linux内核中,根据日志消息的重要程度不同,将其分为不同的有限级别(数字等级越小,优先级越高,消息越重要)
日志文件分析
内核及大多数系统消息
内核及系统日志主要由默认安装的rsyslog软件包提供rsylog服务所使用的配置文件为/etc/rsyslog.conf,通过查看配置文件内容,可以了解到系统默认的日志位置
内核及大多数系统消息被记录到公共日志文件/ar/log/message中,而其他一些程序消息被记录到各自独有的日志文件中,此外日志消息还能够记录到特定的存储设备中,或者直接发送给指定用户查看
格式解释:
时间标签:消息发出的日期和时间
主机名:生成消息的计算机的名称
子系统名称:发出消息的应用程序的名称
消息:消息的具体内容
syslog日志服务是一个常会被攻击的目标,破坏了它将使运维人员很难发现入侵及入侵的痕迹,因此需要特别监控其守护进程及配置文件
用户日志
存放位置:Nar/log/wtmp,Nvar/log/btmp.Nar/log/lastloge
查询命令:users,who,w,last,lastlog,lastb等
users命令:只是简单的输出当前登录的用户名,每一个显示的用户名对应一个会话。
who命令:用于报告当前登录到系统中的每个用户的信息。默认输出包括用户名、终端类型、登录日期及远程主机
w命令:用于显示当前操作系统中的每个用户及其远程所运行的进程信息
last命令:用于查询成功登录到系统的用户记录,最近的登录情况在最前面。通过last命令可以及时掌握linux主机的登陆情况若发现未经授权的用户登陆过,则表示当前主机可能已经被入侵
-a:把从何处登录系统的主机名称或IP地址,显示在最后一行
-d:将IP地址转换成主机名称
-f[记录文件]:指定记录文件
-R:不显示登入系统的主机名称或IP地址
-x:显示系统关闭,重新开机,以及执行等级的改变等
-n:n代表数字,表示最近n次登录的记录
lastlog命令:用于显示系统中所有用户最近一次登录信息
lastb命令:用于显示用户错误的登录列表,此指令可以发现系统的登录异常如登陆的用户名错误,密码不正确等情况都会记录在案,登陆失败的情况属于安全事件,因此消失可能有人在尝试破解密码除了使用lastb命令外,可以直接从安全日志文件Nar/log/secure中获取相关信息
程序日志
在linux操作系统中,还有一部分应用程序没有使用rsyslog服务来管理日志,而是由程序自己维护日志记录,例如http网站服务程序使用两个日志access_log和error_log分别记录客户访问事件和错误事件,不同应用程序的日志记录格式差别较大,没有严格使用统一的记录格式
日志文件分析注意事项
总的来说,作为一名合格的系统管理人员,应该提高警惕,随时注意各种可疑的状况定期并随机的检查各种系统日志文件,包括一般信息日志、网络连接日志、文件传输日志及用户登录日志记录等。在检查这些日志时,要注意是否有不合常理的时间或操作记录。例如出现以下一些现象就应该多加注意:
1、用户在非常规的时间登录,或者用户登录系统的IP地址和以往不一样的
2、用户登录失败的日志记录,尤其是那些一再连续尝试进入失败的日志记录
3、非法使用或不正当使用超级用户权限
4、无故或者非法重新启动各项网络服务的记录
5、不正常的日志记录,如日志残缺不全,或者是诸如wtmp这样的日志文件无故缺少了中间的记录文件
注意:需要提醒运维人员的是日志并不是完全可靠的,高明的黑客在入侵系统后经常会打扫现场,所以管理人员需要运用综上的所有知识全面,综合的进行审查和检测
日志管理
针对日志定期备份,异地备份(保留1-3个月的日志记录)
针对日志定期切割(0 0 * * * mv /var/log/messages /var/log/messages-时间)
针对日志的权限要求严格(为防止敏感信息泄露)
针对日志做集中管理
对于日志文件的保护
chattr +a 日志文件,a选项为append(追加)only,即给日志文件加上a权限后,将只可以追加,不可以删除和修改之前的内容。
root用户在vi编辑器的命令模式,按dd删除了两行内容后进行wq!强制保存退出,报错
lsattr 查看
lsattr -R递归查看
chattr +a –R 递归式增加a权限
课外补充 chattr +a –R递归式增加a权限
网络参数管理
查看及测试网络
ifconfig命令介绍:
#查活动的网络接口 ifconfig
#查看所有的网络接口 ifconfig -a
#查看指定的网络接口 ifconfig ens32
ifconfig命令信息
ens32:flags=标志位<UP,BROADCAST,RUNNING,MULTICAST> mtu 最大传输单元
inet IPv4地址 netmask 子网掩码broadcast 广播地址
inet6 IPv6地址 prefixlen msc长度 scopeid 0x20<link>
ether mac地址 txqueuelen 传输缓冲区大小(Ethernet)
RX packets 接收数据包 bytes 大小(单位统计)
RX errors 错误 dropped 丢弃 overruns 过载 frame 帧数
TX packets 发送数据包 bytes 大小(单位统计)
TX errors 错误 dropped 丢弃 overruns 过载 carrier 载波 collisions 冲撞
查看网络接口数据链路层详细信息
ip link
查看网络接口网络层信息
ip a
查看指定网络接口速率,模式等信息
ethtool ens32
查看主机名
hostname
查看路由表
不执行DNS反向查找,直接显示数字形式的IP地址 route -n
打印网络连接信息
netstat
-r查看路由表
-n不执行DNS反向查找,直接显示数字形式的IP地址
-a显示当前主机所有活动的网络连接信息
-t显示TCP协议相关信息
-u显示UDP协议相关信息
-p显示进程号和进程名称信息
-1查看监听状态
netstat -anpt|head-5
netstat –anpu|head-5
扩展: ss –anpt(获取 socket统计信息) lsof -i:22(列出当前系统打开文件的工具)
网络测试命令
ping测试网络连通性
-c指定发送数据包个数
-i当ping通时,指定间隔多少秒发送下一个数据包
-w当ping不通时,发送的每个数据包的超时时间s
-s指定数据包大小
跟踪数据包路由途径
traceroute -n www.baidu.com
-n:不执行DNS反向查找,直接显示数字形式的IP地址
常见的TTL生存周期值:
windows:128
linux:64
uinux:255
cisco:255
设置IP地址
配置临时IP
ifconfig 网卡名 IP地址
ifconfig ens32 IP
ifconfig ens32 IP/24
ifconfig ens32 IP netmask 255.255.255.0
配置永久IP
vim /etc/sysconfig/network-scripts/ifcfg-ens32
TYPE="Ethernet" #类型(以太网)
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="none" #引导协议(dhcp/static/none)
DEFROUTE="yes"
IPV4 FAILURE FATAL="no"
IPVGINIT="yes"
PV6 AUTOCONF="yes"
IPV6 DEFROUTE="yes"
IPV6 FAILURE FATAL="no"
IPV6 ADDR GEN MODE="stable-privacy"
NAME="ens32" #设备名
UUID="37d3f81e-8bf6-48d1-8aee-b845e491e0cc" #UUID
DEVICE-"ens32" #设备名
ONBOOT="yes" #是否开机自启动
IPADDR=192.168.75.111 #ipv4 协议地址
PREFIX=24 NETMASK= 255.255.255.0#子网掩码
GATEWAY=192.168.75.1 #网关
DNS1=8.8.8.8 #DNS域名解析服务
HWADDR=00:0C:29:8F:D8:E0#物理地址MAC (可以不用填写)
PV6 PRIVACY=no(可以不用填写)
设置临时网卡子接口
ifconfig ens32:0 IP/24 (0为序号,默认排序:0 01 02 03…)
ifconfig ens32:sec IP/24
设置永久网卡子接口 /etc/sysconfig/network-scripts/
cp ens32 ens32:0
vim ens32:0
临时修改网卡状态
ifconfig ens32 down
ifconfig ens32 up
重新加载网络配置文件
systemctl restart network
ifdown ens32;ifup ens32
设置主机名
修改新主机名(临时生效)
hostname name
修改永久主机名
方法一:hostnamectl set-hostname name
方法二:vim/etc/hostname
配置路由
临时添加删除路由记录
route –n 查看路由条目
route add –net 网段/短格式子网掩码 gw 网关地址
route del –net 网段/24
临时添加,删除默认网关
route add default gw网关地址
route del default gw网关地址
配置永久路由
方法一
vim/etc/rc.local
route add –net 网段/24 gw 网关
route add –net 网段/24 dev ens32
方法二
在ens32网卡配置文件中指定网关
方法三
vim/etc/sysconfig/static-routes(手动建立)
any net网段/24 gw网关地址
any net网段 netmask 255.255.255.0 gw网关
开启IP转发(路由功能)
临时
echo"1" >/proc/sys/net/ipv4/ip_forward
永久
vim/etc/sysctl.conf net.ipv4.ip_forward=1
sysctl-p 查看ip转发功能
配置DNS域名解析
方法一
在ens32网卡中设置DNS1=8.8.8.8
方法二
vim /etc/resolv.conf
nameserver IP
域名解析本地主机映射文件 :/etc/hosts
DHCP介绍:
动态主机设置协议,是一个局域网的网络协议,使用UDP协议工作,采用C/S架构主要作用是集中的管理、分配IP地址,避免IP地址冲突,减少管理员工作量,使client动态的获得网卡的IP地址、默认网关地址、子网掩码、对应的网络地址、广播地址、DNS服务器地址等,并能够提升地址的使用率
端口:67(DHCP server)服务端,68(DHCP client)客户端
DHCP地址类型分配
自动分配方式
DHCP服务器为主机指定一个永久性的IP地址,一旦DHCP客户端第一次成功从DHCP服务器端租用到IP地址后就可以永久性的使用该地址。
动态分配方式
DHCP服务器给主机指定一个具有时间限制的IP地址,时间到期或主机明确表示放弃该地址时,该地址可以被其他主机使用(当然也可以续约继续使用)。
手工分配方式
客户端的IP地址是由网络管理员指定的,DHCP服务器只是将指定的IP地址告诉客户端主机。
三种地址分配方式中,只有动态分配可以重复使用客户端不再需要的地址。
DHCP租约过程
客户机从DHCP服务器获取IP地址的过程称为DHCP的租约过程。
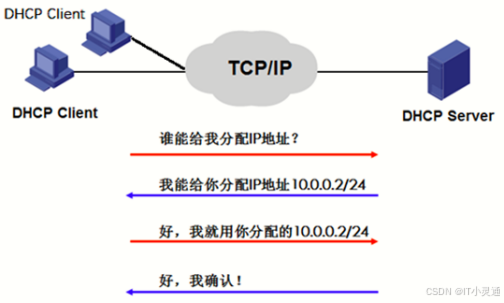
租约过程分为四个步骤:
1>客户机请求IP(客户机发DHCP Discover广播包)
当一个DHCP客户机启动时,客户机还没有IP地址所以客户机需要通过DHCP获取一个合法的地址。此时DHCP客户机以广播方式(因为DHCP服务器的IP地址对客户机来说是未知的)发送DHCP Discover发现信息来寻找DHCP服务器。广播信息中包含DHCP客户机的MAC地址和计算机名,以便DHCP服务器确定是哪个客户机发送的请求。
2>服务器响应(服务器发DHCP Offer广播包)
当DHCP服务路接收到来自客户机请求IP地址的信息时,它就在自己的IP地址池中查找是否有合法的IP地址提供给客户机如果有,DHCP服务器就会将此IP地址做上标记加入到DHCP Offer的消息中,然后DHCP服务器就广播一则包含下列信息的DHCP Offer消息DHCP客户机的MAC地址、DHCP服务器提供的合法IP地址、子网掩码、默认网关、租约的期限、DHCP服务器的P地址。
3>客户机选择IP(客户机发DHCP Request广播包)
DHCP客户机从接收到的第一个DHCP Offer消息中提取IP地址,发出IP地址的DHCP服务 将该地址保留,这样该地址就不能再分配给另一个DHCP客户机。当客户机从第个DHCP服务器接收到DHCP Offer消息并提取了IP地址后,客户机将DHCP Request消息广播到所有的DHCP服务器表明它接受提供的内容。DHCP Request消息包括为客户机提供IP配置的服务照的服务标识符(服务器IP地址),DHCP服务器查看服务器标识符字段以确定提供的IP是否被接受,如果DHCP Offer被拒绝,则DHCP服务路取消并保留其IP地址以提供给下一个IP租约的的请求。
4>服务器确定租约(服务器发DHCP ACK广播包)
DHCP服务器接收到DHCP Request消息后,以DHCP ACK消息的形式向客户机广播成功确认,该消息包括含有IP地址的有效租约和其他可配息,当户机收到DHCP ACK消息时,它就配置了IP地址,完成TCPAP的初始化。
重新登录
DHCP客户机每次重新登录网络时不需要再发送DHCP Discaver信息,而是直接发送包含前一次所分配的IP地址的DHCP Request请求信息。当DHCP服务器接收到这一信息后,它会尝试让DHCP客户机继续使用原来的IP地址并回答一个DHCP ACK确认信息。
如果此IP地址已无法再分配给原来的DHCP客户机使用(如IP地址已经分配给其他的DHCP客户机使用)DHCP服务器给DHCP客户机回答一个DHCP Nack否认信息。当原来的DHCP密户机接收到此DHCP Nack否认信息后,它就必须重新发送DHCP Discover发现信息来请求信的IP地址
更新租约
当DHCP服务器向客户机出租的IP地址租期达到50%时,就需要更新租约。客户机直接向提供租约的服务器发送DHCP Request包,要求更新现有的地址租约。若此时DHCP服务器无法正常回复DHCP客户机的请求客户机的此IP地址可以继续使用到最大租约时间的87.5%
DHCP中继原理
当企业的内部网络规模较大时通常被划分为多个不同的子网,网络内配置了VLAN。
VLAN能隔离广播,而DHCP协议使用广播。DHCP服务器在VLAN 100中就只有VLAN100内的客户机能从DHCP服务器那里获取IP地址,如果VLAN 2或VLAN 3的客户机也需要通过这台DHCP服务器来获取IP地址,该怎么办呢?
解决的办法有两种:
为每个网段安装一台DHCP服务器,但这种方式存在资源上的浪费,而且不利于集中管理,在连接不同网段的设备上开启DHCP中继功能将DHCP这种特殊的广播信息在VLAN之间转发,让其他VLAN的客户机也能从DHCP服务器那里获得IP地址。
DHCP中继代理,其可以实现在不同子网和物理网段之间处理和转发dhcp信息的功能。如果DHCP客户机与DHCP服务器在同一个物理网段,则客户机可以正确地获得动态分配的ip地址。如果不在同一个物理网段,则需要中继代理,代理可以去掉在每个物理的网段都要有DHCP服务器的必要,它可以传递消息到不在同一个物理子网的DHCP服务器,也可以将服务器的消息传回给不在同一个物理子网的DHCP客户机。
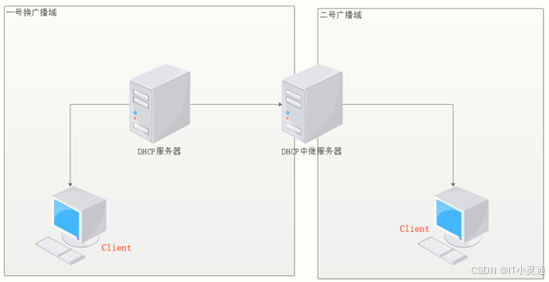
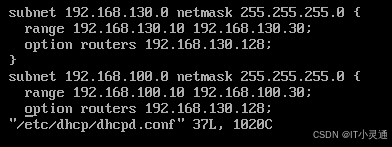
DHCP配置文件.
主配置文件/etc/dhcp/dhcpd.conf
执行程序/usr/sbin/dhcpd
服务名dhcpd
配置DHCP服务实验:
yum –y install dhcp 安装DHCP
vim /etc/sysconfig/network-scripts/ifcfg-ens32 修改本机IP为静态IP
systemctl restart network 重启本机网卡
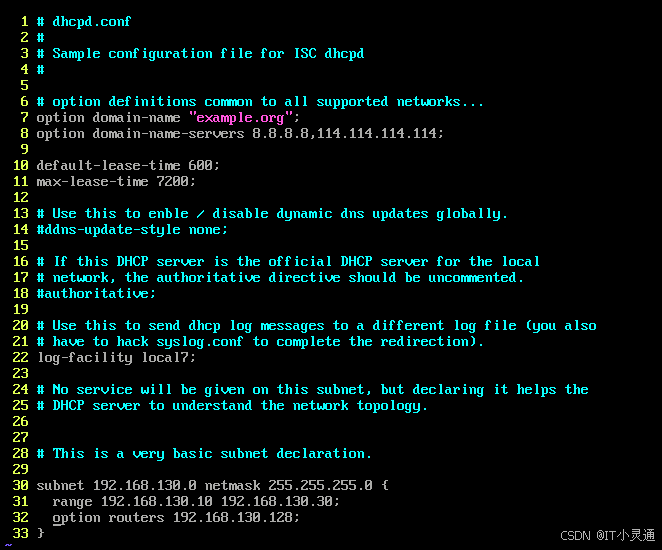
cp /usr/share/doc/dhcp-4.2.5/dhcpd.conf.example /etc/dhcp/dhcpd.conf 复制DHCP主配置文件
vim /etc/dhcp/dhcpd.conf 修改DHCP主配置文件
systemctl restart network 重启网卡
systemctl restart dhcpd 重启DHCP服务
netstat –anptul|grep 67 检索过滤服务端口是否开启
日志中捕获到四个过程
tailf /var/log/messages
租约信息
cat /var/lib/dhcpd/dhcpd.leases
客户端(网卡配置文件设置为DHCP)
dhclient –r ens32 释放IP
dhclient –d ens32 重新获取
针对部分主机可绑定MAC地址为其分配固定IP地址
修改DHCP主配置文件
host test{ //添加主机定义
hardware ethernet 00:0c:29:96:57:8a://客户机MAC地址
fixed-address 192.168.75.222: //为客户机绑定的IP地址
}
DHCP中继配置(扩展)
DHCP中继服务器
开启三个虚拟机:第一台为dhcp,第二台为dhcp中继器,第三台为客户端。
DHCP服务器,DHCP中继器安装dhcp包
配置dhcp ip地址
给dhcp中继器添加一个网卡
中继器拷贝一份网卡文件
配置dhcp中继网卡一网卡二的ip地址
开启dhcp中继服务器的路由转发功能 vim /etc/sysctl.conf net.ipv4.ip_forward=1
sysctl –p 查询中继器是否开启路由转发功能
重启dhcp的网卡以及dhcp中继的网卡
拷贝dhcp主配置文 cp /usr/share/doc/dhcp-4.2.55/dhcpd.conf.example /etc/dhcp/dhcpd.conf
修改dhcp主配置文件
在dhcp中继的虚拟机启动dhcp中继服务(dhcrelay dhcp的ip地址)
过滤dhcrelay进程(netstat -autlp|grep dhcrelay)
关闭VMware的本地dhcp分配
客户端网卡对应的是vm8网卡
在dhcp客户端测试dhcp中继是否给客户端分配了地址
修改客户端网卡为vm2
再次测试dhcp中继是否给客户端分配了地址
DNS概念
域名系统是互联网的一项服务。它作为将域名和IP地址相互映射的一个分布式数据库能够使人更方便地访问互联网。DNS使用TCP和UDP端口53
域名解析概念:把域名指向的网站IP,让人们通过域名就可以访问到所绑定域名的服务器上的服务
域名解析分类:
正向解析:根据域名查IP地址,将指定的域名解析为对应的IP,常用
反向解析:根据IP查找域名,将IP地址解析为对应的域名,不常用,在特殊场合(反垃圾邮件验证)才会用到
FQDN:完整域名格式,例如www.linux.com.
早期的域名必须以英文句号.结尾,例如我们访问www.jd.com时候就必须输入www.jd.com.
这样DNS才能进行域名解析,如今DNS服务器已经可以自动补上结尾的句号
DNS服务的类型:
缓存域名服务器:只提供域名解析结果的缓存功能,可以提高查询速度和效率,但没有自己控制的区域地址数据,在构建缓存服务器时必须设置根域或指定其它DNS服务器作为解析来源
主域名服务器:维护某一个特定DNS区域的地址数据库,对其中解析的记录有控制权限,是指定区域中唯一存在的权威服务器,构建主域名服务器时,需要自行建立所有区域的地址数据文件
从域名服务器:与主域名服务器提供相同的DNS服务,通常用于DNS服务的热备份,对于客户来说无论主从服务器,查询的结果都是一样的,区别从域名服务器提供的解析结果不由自己决定由主域名服务器决定,构建服务器时,要指定主域名服务器位置,让其能自动同步区域的地址数据库
转发器:发现不是本机负责查询的请求,不再向根域发请求,而是直接转发给指定的服务器,自身并不缓存结果
DNS服务器查询模式:
递归:DNS客户端设置使用的DNS服务器一般都是递归服务器,它负责全权处理客户端的DNS查询请求,直到返回最终结果(发出多次请求)
迭代:只发出一次请求,DNS服务器之间一般采用迭代查询方式
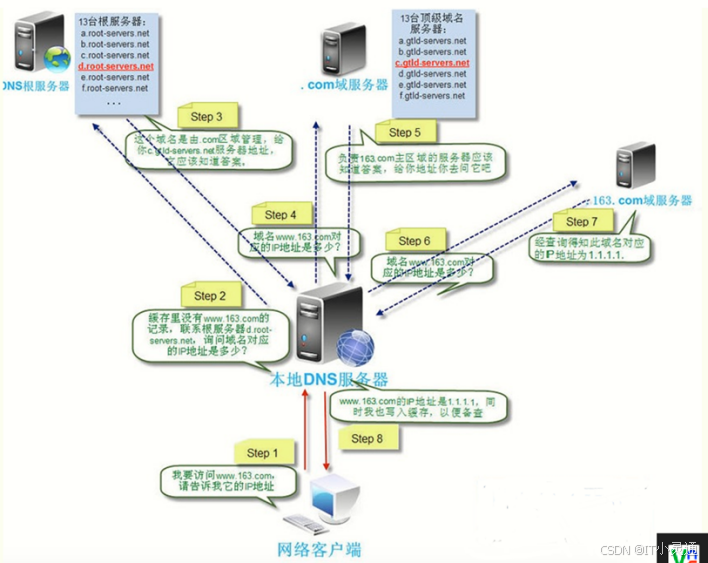
DNS请求流程描述
第一步:打开浏监器,想要请求访问京东,在地址栏输入了网址:www.jd.com(www.jd.com是域名就是一个IP地址的名称,IP地址不好记,所有有了域名)
第二步:先将请求信息发给了交换机,然后交给了路由器,路由发给DNS服务器,通过DNS协议去找我们要访问的京东的IP地址
第三步:查到的京东服务器对应的IP地址之后,路由器通过路由协议找到一个路由转发的最优路径,将你的请求信息还送给这个IP地址的京东的路由器
第四步:京东的路由器发给了京东网站的服务器上
第五步:京东网站服务器按照来的时候的路径,在返回给你他自己的网站
第六步:当你打开浏览器的时候,你的电脑给你的浏览器这个运行起来的程序给了一个编号,叫做端口号,当你的电脑收到京东发送过来的消息的时候,你的电脑通过端口号找到你的浏览器,你的浏览器拿到了京东的网站信息,然后将网站呈现在了自己的浏览器上
DNS配置文件介绍
/var/named 区域数据文件
/etc/named.conf DNS主配置文件
配置过程
实验条件:1台主DNS 1台从DNS 1台客户机
目的:客户机通过缓存DNS正逆向解析
安装软件包:yum –y install bind
修改主DNS主机名为 ns1.test.com
修改从DNS主机名为 ns2.test.com
配置主机IP和对应的主机名 vim /etc/hosts(两台DNS都需要配置)
设置主机IP为静态IP
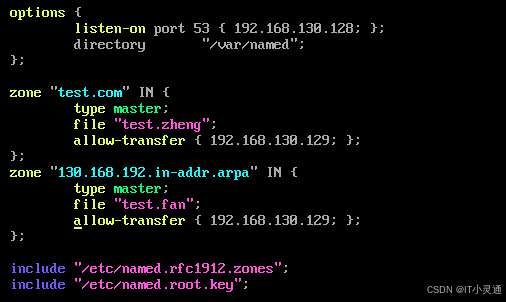
修改主DNS配置文件 vim /etc/named.conf
编辑区域配置文件正向解析文件 vim /var/named/test.zheng
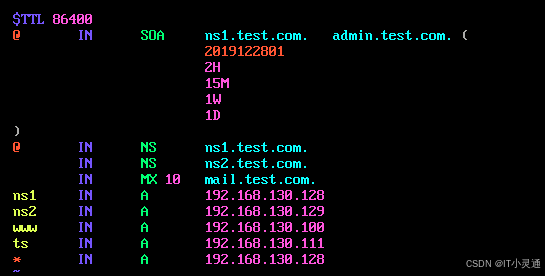
复制一份正向解析文件并重命名为test.fan,vim /var/named/test.fan
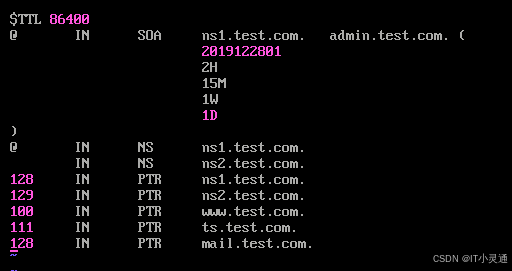
添加正反解析文件到named组里
chgrp named /var/named/test.zheng
chgrp named /var/named/test.fan
测试DNS配置文件格式是否正确
named-checkconf /etc/named.conf
测试DNS区域配置文件是否正确
named-checkzone test.com /var/named/test.zheng
重启DNS服务
systemctl restart named
配置从DNS主配置文件 vim /etc/named.cofg
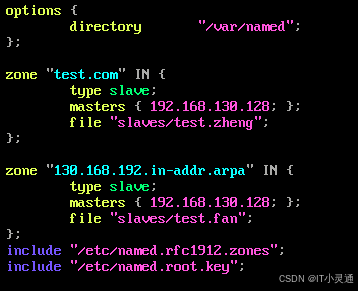
修改目录及其内部文件的属组 chown –R named.named /var/named/slaves
启动从DNS服务 systemctl start named
启动从DNS服务后,从DNS会自动同步主DNS的区域配置文件数据 ls /var/named/slaves/
查看客户机DNS指向 cat /etc/resolv.conf
将客户机DNS指向从DNS服务器测试 nslookup ip/地址
SSH远程登录服务
传统的网络服务程序,在本质上都是不安全的,因为它们在网络上用明文传送口令和数据,别有用心的人非常容易就可以截获这些口令和数据。而且这些服务程序的安全验证方式也是有其弱点的,就是很容易受到“中间人”攻击,所谓“中间人”,就是"中间人"冒充真正的服务器接收你传给服务器的数据,然后再冒充你把数据传给真正的服务器。服务器和你之间的数据传送被“中间人”一转手做了手脚之后,就会出现很严重的问题。
SSH为Secure Shell的缩写,是标准的网络协议,由IETF的网络小组(NetworkWorking Group)所制定;SSH为建立在应用层基础上的安全协议。SSH是目前较可靠,专为远程登录会话和其他网络服务提供安全性的协议。利用SSH协议可以有效防止远程管理过程中的信息泄露问题。可用于大多数操作系统,能够实现字符界面的远程登录管理,它默认使用22号端口,采用密文的形式在网络中传输数据,相对于通过明文传输的Telnet,具有更高的安全性。SSH提供了口令和密钥两种用户验证方式,这两者都是通过密文传输数据的。
对称加密和非对称加密区别
对称加密采用了对称密码编码技术,它的特点是文件加密和解密使用相同的密钥加密
也就是密钥也可以用作解密密钥,这种方法在密码学中叫做对称加密算法,对称加密算法使用起来简单快捷,密钥较短,且破译困难,除了数据加密标准(DES),另一个对称密钥加密系统是国际数据加密算法(IDEA),它比DES的加密性好,而且对计算机功能要求也没有那么高
与对称加密算法不同,非对称加密算法需要两个密钥:公开密钥(publckey)和私有密钥(privatekey)。
公开密钥与私有密钥是一对,如果用公开密钥对数据进行加密,只有用对应的私有密钥才能解密;如果用私有密钥对数据进行加密,那么只有用对应的公开密钥才能解密。因为加密和解密使用的是两个不同的密钥,所以这种算法叫作非对称加密算法。非对称加密算法实现机密信息交换的基本过程是:甲方生成一对密钥并将其中的一把作为公用密钥向其它方公开;得到该公用密钥的乙方使用该密钥对机密信息进行加密后再发送给甲方;甲方再用自己保存的另一把专用密钥对加密后的信息进行解密。
SSH程序介绍
SSH服务安装包(默认系统已经安装)
rpm -qa openssh*
openssh-clients-7.4p1-16.el7.x86_64
openssh-7.4p1-16.el7.x86_64
openssh-server-7.4p1-16.el7.x86_64
服务名 sshd
服务主程序 /usr/sbin/sshd #sshd服务端主程序
/etc/ssh/sshd_config #服务端配置文件(修改前一定要先备份)
/etc/ssh/ssh_config#客户端配置文件(一般不需要改动)
服务端配置参数(只要更改配置必须重启服务才能生效)
/etc/ssh/sshd_config
17 #Port 22 #并服务端端口(默认22号端口)
19 #ListenAddress 0.0.0.0 #服务监听的地址(默认监听所有地址)
115 UseDNS no #禁止DNS反向解析,提高响应速度
37 #LoginGraceTime 2m #登陆验证时间
38 #PermitRootLogin yes #禁止root用户登陆(默认允许,需要改为no)
40 #MaxAuthTries 6 #最大重试次数
64 #PermitEmptyPasswords no #禁止空密码用户登陆
Openssh服务访问控制
在服务端文件末尾添加 AllowUsers(白名单)用户名 或者 DenyUsers(黑名单)用户名 即可允许或者拒绝某些用户登陆(拒绝优先),多个用户空格隔开
重启服务
systemcti restart sshd
登陆验证方式(可以两种同时使用,也可以只使用其中一种)
密码验证:对服务器中本地系统用户的登录名称、密码进行验证。这种方式使用最为简便,但从客户端角度来看,正在连接的服务器有可能被假冒:从服务器角度来看,当遭遇穷举(暴力破解)攻击时防御能力比较弱。
密钥对验证:要求提供相匹配的密钥信息才能通过验证。通常先在客户端中创建一对密钥文件(公钥私钥),然后将公钥文件放到服务器中的指定位置。远程登录时,系统将使用公钥私钥进行加密/解密关联验证,大大增强了远程管理的安全性。该方式不易被假冒,且可以免交互登录,在Shell中被广泛使用。
当密码验证密钥对验证都启用时,服务器将优先使用密钥对验证。对于安全性要求的服务器。建议将密码验证方式禁用只允许启用密钥对验证方式若没有特殊要求,则两种方式都可启用。
vim /etc/ssh/sshd_config
43#PubkeyAuthentication yes #启用密钥对验证
47 AuthorizedKeysFile .ssh/authorized_keys #公钥文件位置
65 PasswordAuthentication yes #启用密码验证
SSH客户端命令
远程连接服务器:ssh 用户名@主机IP -p 端口
客户端推送文件到服务端
scp 文件名服务端用户@服务端IP:/服务端的文件位置
客户端拉取服务端文件
scp 服务端用户@服务端IP:/服务端文件位置 放在客户端的位置
sftp(安全的ftp)
登陆
sftp user@连接方IP
把客户端文件上传到服务器端
put 文件名
把服务端文件拉取到客户端
get 服务器端文件位置 客户端文件存放位置
常见的远程访问工具:Xshell、secureCRT、PuTTY、Xmanager
SSH秘钥验证
构建步骤:
a.首先要在SSH客户端创建密钥对
b.客户端将创建的公钥文件上传至SSH服务端
C.服务端将公钥信息导入用户的公钥数据库文件
d.客户端连接服务器端用户测试
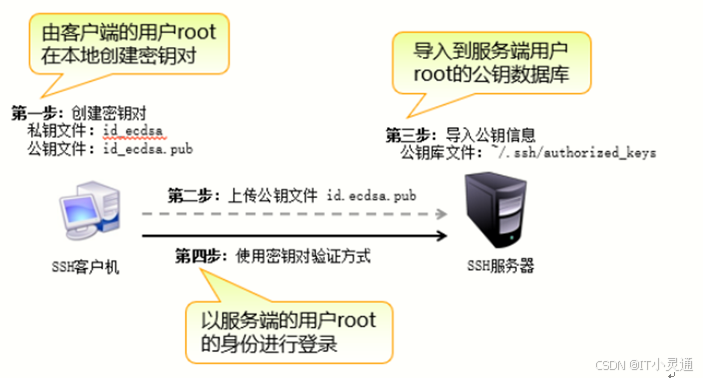
主机A与主机B之间做秘钥互信实现不需要密码登陆主机B
主机A执行
ssh-keygen-t 秘钥类型(dsa/rsa/...)
1s ssh/
ssh-copy-id-i.ssh/id dsa.pub rooto 主机B的IP
ssh root@主机B的IP
总结:
在主机A上创建密钥对,一个公钥(pub),一个私钥以公钥为准,如果想不需要输入密码连接到B服务器上,就把公钥拷贝到B服务器上,然后就可以连接这台服务器了新生成的密钥对文件中,idecdsa是私钥文件,默认为600,对于私钥文件必须妥善保管,不能泄露给他人。id ecdsa.pub是公钥文件,用来提供给SSH服务器。
连接过程:
你创建密钥对的这个机器(主机A)会拿自己私钥和你拷贝过去的公钥(主机B)做配对,如果配对成功即可不需要输入密码就可连接主机B.否则登陆失败
TCP Wrapperse
在Linux系统中,许多网络服务针对客户端提供了访问控制机制,如Samba、BIND、HTTPD、OpenSSH等。TCP Wrappers(TCP封装的套接宇)防护机制,是作为应用服务于网络之间的一道特殊防线,提供额外的安全保障。
TCP Wrappers保护原理
TCP Wrappers将TCP服务程序“包裹”起来,代为监听TCP服务程序的端口,增加了一个安全监测的过程,外来的连接请求必须先通过这层安全检测,获得许可后才能访问真正的服务程序。
保护机制的实现方式
方式1:通过tcpd主程序对其他服务程序进行包装
方式2:由其他服务程序调用libwrap.so.*链接库
TCP Wrappers保护的条件
(1)必须是采用TCP协议的服务
(2)函数库中必须包含libwrap.so.0(共享连接库)、大多数服务通过这种方式

#首先查看服务有没有libwrap库文件,有libwrap这个库文件的服务才能配置访问控制
ldd 服务名|grep "libwrap"
例:
ldd /usr/sbin/sshd|grep"libwrap"
libwrap.so.0 =>/ib64/libwrap.so.0(0x000072c02e41000)
访问控制策略配置文件(允许优先)
/etc/hosts.allow 白名单
/etc/hosts.deny黑名单
配置格式:服务名:ip
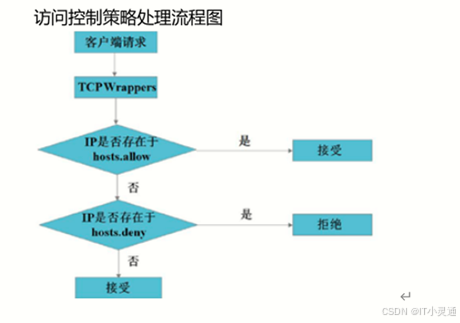
通配符: * 代替若干字符
?代替单个字符
部署yum源仓库
YUM软件仓库,可以完成安装,卸载自动升级rpm软件包等任务,能够自动查找并解决rpm包之间的依赖关系,并一次安装所有依赖的相关软件包。而无需管理员逐个,手工的去安装每个rpm包使管理员在维护大量Linux服务器时更加轻松自如。特别是在拥有大量Linux主机的本地网络中,在自己公司架设一台YUM服务器还可缓解软件安装、升级等对Internet的依赖。
源服务器:源服务器包含存放各种rpm安装包文件的软件仓库(Repository)和仓库数据(Repodata),仓库数据是用来收集仓库目录下rpm软件包的头部信息的。YUM软件仓库借助于HTTP或FTP协议进行发布,可以面向网络中的所有服务器,使其他Linux服务器(客户机)直接调用,而无须自己准备软件包
rpm软件包来源
Centos官方发布的rpm包
第三方组织发布的rpm包
用户自定义的rpm包
在CentOS7系统的安装光盘中,已针对目录Packages建立好repodata数据,因此只要简单地将整个光盘中的内容通过HTTP或FTP进行发布,就可以作为软件仓库了。
配置基于本地yum源服务器
mount /dev/sr0 /media 挂载光盘映像
cd /etc/yum.repos.d
mkdir a
mv * a
vim yum.repo
[base]
name=base
baseurl=file:///media
enabled=1
gpgcheck=0
yum clean all
yum makecache
配置基于HTTP协议的YUM源服务器(需安装httpd服务)
服务端配置
yum –y install httpd
mkdir /var/www/html/centos
mount /dev/sr0 /var/www/html/centos
systemctl restart httpd
客户端配置
cd /etc/yum.repos.d
mkdir a
mv * a
vim yum.repo
[base]
name=base
baseurl=http://192.168.130.128/centos
enabled=1
gpgcheck=0
yum clean all
yum makecache
基于FTP协议的YUM源服务器
服务端配置
mount /dev/sr0 /media/
rpm –ivh /media/Packages/vsftpd-3.0.2-25.el7.x86_64.rpm
umount /dev/sr0
mkdir –v /var/ftp/centos
mount /dev/sr0 /var/ftp/centos/
#用户手中的其他软件包需要手动创建repodata数据文件和存放目录
mkdir /var/ftp/other
cd/var/ftp/other/
createrepo–g /var/ftp/centos/repodata/repomd.xml ./ 指定本地软件仓库的组划分
ls -lh repodata/
systemctl start vsftpd
客户端配置
cd /etc/yum.repos.d
mkdir a
mv * a
vim yum.repo
[ftp]
name=ftp
#软件包URL访问路径(如果是本地源以file开头,如果是http源以http开头,如果是ftp源以ftp开头
baseurl=ftp://192.168.130.128/centos
enabled=1
gpgcheck=0
[other]
name=other
baseurl=ftp://192.168.130.128/other
enabled=1
gpgcheck=0
yum clean all
yum makecache
yum list
yum命令 yum 选项 所要进行的操作 安装包
选项:
-h 显示此帮助消息并退出
-t 忽略错误
-C 完全从系统缓存运行,不升级缓存
-c[config file] 配置文件路径
-R[minutes] 命令最长等待时间
-d[debug level] 调试输出级别
-e[error leve] 错误输出级别
-q 静默执行
-V 详尽的操作过程
-y 回答全部问题为是
所要进行的操作:
List 查看软件包列表
list installed 查看已安装的
list available 查看可用的(尚未安装)
list updates 查看可升级的
grouplist 查看软件包组信息
info 查询软件包的描述信息
groupinfo 查看软件包组中包含的软件
install 全部安装
remove 卸载软件包
update 全部升级
makecache 重建缓存
clean 删除yum缓存数据
localinstall 安装本地rpm包
repolist 显示启用的yum仓库配置
常用命令
yum-y install 安装包名
yum list all 查了yum源所有安装包
yum clean all 清除所有yum缓存数据
yum makecache 建立yum缓存
更换网络yum源
yum -y install wget
cd/etc/yum.repos.d/
mkdir a
mv * a
wget -O http://mirrors.aliyun.com/repo/Centos-7.repo(下载网络源)
NFS服务
NFS(Network File System)网络文件系统,是FreeBSD支持的文件系统中的一种,它允许网络中的计算机之间通过TCP/IP网络共享资源。主要功能是通过网络(一般是局域网),让不同的主机系统之间可以共享文件或目录。NFS客户端(一般为应用服务器,例如WEB服务器)可以通过挂载(mount)的方式,将NFS服务端共享的数据目录挂载到NFS客户端本地系统中(就是某一个挂载点目录下)
从NFS客户端的机器本地看,NFS服务端共享的目录就好像是客户自己的磁盘分区或者目录一样,而实际上确是远端的NFS服务端的目录。在NFS的应用中,本地NFS的客户端应用可以透明地读写位于远端NFS服务器上的文件,就像访问本地文件一样。NFS网络文件系统类似windows系统的网络共享、安全功能、网络驱动器映射,应用于互联网中小型集群架构后端作为数据共享,如果是大型网站,那么有可能还会用到更复杂的分布式文件系统,例如Moosefs,GlusterFS,FastDFS。
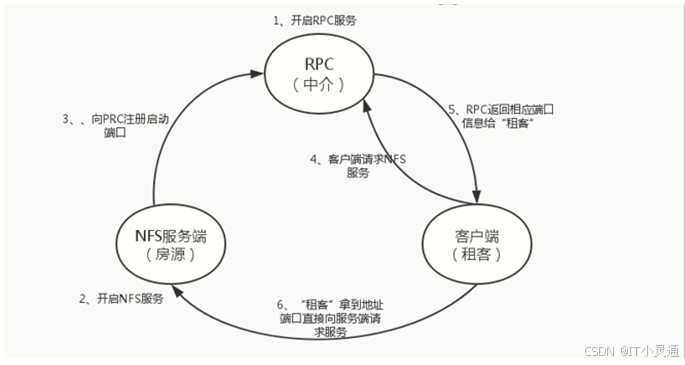
工作原理
client发请求到NFS服务器的portmapper(端口映射),然后portmapper告诉client端mountd的端口号,然后client端连接mountd,然后mountd发送令牌给client端,client再找nfsd
因为NFS支持的功能相当多,而不用的功能都会使用不同的程序来启动,每启动一个功能就会启用一些端口来传输数据,因此,NFS的功能所对应的端口不是固定的(小于1024的随机取值),但是客户端连接服务器端必须要知道对应端口。
那么我们就得需要远程过程调用(RPC)的服务协助,RPC最主要的功能就是在指定每个NFS功能所对应的port number,并且回传给客户端,让客户端可以连接到正确的端口上。所以在启动NFS之前,RPC需要先启动,否则NFS会无法向RPC注册。另外,RPC若重新重启,原本注册的数据会不见了,因此RPC重新启动后,它管理的所有服务都需要重新启动向RPC注册。
当客户端有NFS存取需求时,它会向服务器端的RPC(port 11)发出NFS档案存取功能的询问要求,服务器端找到对应的已注册的NFS daemon端口后,发送给客户端,客户端收到正确的端口后,就可以直接与NFS daemon来联机。
部署NFS服务
安装包
nfs-utils:NFS服务主程序包括rpc.nfsd、rpc.mountd两个daemons和相关文档说明及执行命令程序等。
rpcbind:RPC的主程序,NFS可以被视为一个RPC程序,在启动任何一个RPC程序之前,需要做好端口映射工作,这个映射工作就是由rpcbind服务来完成的。因此必须先启动rpcbind服务。
服务端配置
yum -y install nfs-utilsrpcbind
rpm -qa nfs-utils rpcbind
rpcbind-0.2.0-47.el7.x86_64
nfs-utils-1.3.0-0.61.el7.x86_64
#启动NFS相关服务
systemctl restart rpcbind
systemctl restart nfs
#查看111端口进程占用(rpc服务)
lsof –i:111
rpcinfo -p localhost
配置NFS服务
#NFS服务默认配置文件(默认为空) /etc/exports
#创建共享的数据目录
mkdir/data
touch /data/linux
#授权目录及主机
vim /etc/exports
/data 192.168.130.*(rw,sync)
systemctl restart nfs
#列出NFS服务器共享目录
showmount-e 127.0.0.1
showmount
-e 显示NFS服务输出的目录列表
-d 显示NFS服务中提供的共享目录
-a 以IP:/die格式显示NFS服务器IP和可被挂载的目录
客户端配置
yum -y install rpcbind
rpm -qa rpcbind
showmount -e 192.168.130.128
mount -t nfs 192.168.130.128:/data /mnt
df -Th
touch /mnt/abc
touch:无法创建"abc":权限不够
服务端(无法写入是因为权限问题)
ll /data/
id nfsnobody
chown -R nfsnobody /data/
ll /data/
生产环境推荐配置
vim/etc/exports
/data 192.168.10.*(rw,sync,all_squash)
exportfs –rv #加载配置生效,相当于重启NFS服务
在客户端测试是否能创建文件
把服务启动和挂载命令放在客户端的/etc/rc.local文件
/etc/rc.local 开机自动挂载配置文件
NFS主配置文件参数
rw读写权限, ro只读权限
sync请求或写入数据时,数据同步到NFS的硬盘中才返回,优点数据不会丢失,缺点性能下降
async请求或写入数据时,先返回请求,在将数据写入到内存缓存和硬盘,异步写入,降低数据安全性,不建议用
no_root_squash访问NFS共享目录的用户是root,对该共享目录具有root权限
root_squash访问NFS共享目录的用户是root,则它的权限将被压缩成匿名用户,UID和GID变成nfsnobody账号身份
all_squash无论NFS共享目是什么用户,权限都被压缩成匿名用户
配置文件完整参数设置的文件(很多配置是NFS默认参数,仅供参考)
cat /var/lib/nfs/etab
客户端挂载参数(了解)
cat /proc/mounts |tail-1
NFS优缺点
NFS优点
1、简单,容易上手,容易掌握。
2、NFS文件系统内数据是在文件系统之上的,即数据能看见。
3、方便,部署快速,维护简单,可控且满足需求。
4、可靠,从软件层面上看、数据可靠性高,经久耐用。数据是在文件系统之上的
5、稳定性。
NFS缺点
1、存在单点故障,如果nfs server关机了所有客户端都不能访问共享目录,可以通过负载均衡及高可用方案弥补。
2、在大数据高并发的场合,NFS效率、性能有限3、客户端认证是基于ip和主机名的,权限是根据ID识别,安全性一般(用于内部测试问题不大)。
4,NFS数据是明文的,NFS本身对数据完整性不作验证。
5、多台客户机器挂载一个NFS服务器时,连接管理维护麻烦(耦合度高)。尤其NFS服务出现问题后,所有NFS客户端不可用(测试环境可以使用autofs自动挂载解决)。
6、大中小型网站(2千万PV访问量以下)线上应用,都可用。
PXE高校批量网络装机
PXE:预启动执行环境
原理:
PXE Client需要安装操作系统的机器简称客户端
TFTP Server需要安装TFTPD服务的机器
DHCP Server需要安装DHCPD服务的机器
在实际工作中都是将TFTP Server,DHCP Server安装在一台机器上统称PXE服务端
工作流程:
1.客户端向服务器DHCP发送IP地址请求,DHCP服务器接收到客户端请求后把IP地址和启动文件pxelinux.0的位置一起发送给客户端
2.客户端向服务端TFTP发送获取pxelinux.0消息,TFTP接收到消息后向客户端发送pxelinux.0大小的信息,客户端反馈消息,当TFTP收到客户端返回的消息后,正式向客户端发送pxelinux.0
3.客户端接收pxelinux.0文件
4.客户端向TFTP发送针对本机的配置信息(在TFTP上的pxelinux.cfg目录下),TFTP将配置文件发送给客户端,客户端根据配置文件执行后续操作
5.客户端向TFTP发送Linux内核信息,TFTP接收到消息后将内核信息发送给客户端
6.客户端向TFTP发送根文件请求,TFTP接收到消息后将Linux根文件系统返回给客户端
7.客户端启动linux内核
8.客户端进入安装模式
使用场景:
无光驱或者光驱损坏,需要安装Linux系统
对系统维护不当,导致需要频繁安装linux系统
需要大规模批量部署linux系统
前提条件:
客户机网卡支持PXE协议主板支持网络引导(BIOS)
网络中有DHCP服务器为客户端自动分配网络地址,并指定引导文件位置
服务器通过TFTP提供引导镜像文件的下载
PXE 结合 Kickstart 配置实现无人值守自动安装
PXE严格来说不是一种安装方式,是一种引导方式,相当于咱们平时安装windows系统时候的U盘引导
Kickstart是一种无人值守安装方式,原理是记录安装过程需要人工干预的一些配置参数,生成一个名为ks.cfg的文件,服务端告诉客户端安装程序从哪里取ks.cfg,然后客户端安装程序会根据ks.cfg中的配置来执行安装步骤,最后完成安装
半自动化PXE引导安装Linux
配置yum仓库安装源(先将镜像挂载media目录,安装vsftpd。然后卸载再挂载到vsftpd,启动vsftpd服务,手写yum源为ftp)
yum –y install tftp-server xinetd dhcp syslinux system-config-kickstart
mount /dev/sr0 /media/
rpm –ivh /media/Packages/vsftpd-3.0.2-25.el7.x86_64.rpm
umount /media/
mkdir /var/ftp/centos/
mount /dev/sr0 /var/ftp/centos/
systemctl start vsftpd
cd /etc/yum.repos.d/
mkdir a
mv * a
vim yum.repo
[base]
name=nase
baseurl=ftp://192.168.130.128/centos
enabled=1
gpgcheck=0
yum clean all
yum makecache
yum list all
安装tftp,xinetd,dhcp服务
tftp服务由tftp-server软件包提供,默认通过xinetd超级服务进行管理,需要将/etc/xinetd.d/tftp中的disable=yes改为disable=no
这里大家对tftp和vsftp容易混乱,我分别说下他们两个的作用
安装tftp是为了存放引导文件及内核文件来用的
安装vsftp是为挂载镜像,存储cfg文件来用的
vim/etc/xinetd.d/tftp
disable=no
systemctl start tftp
准备linux内核,初始化镜像文件
linux内核文件和初始化镜像文件可以从光盘中找到,位于images/pxeboot下vmlinuz和initrd.img,将这两个文件复制到tftp服务的根目录下
cd /var/ftp/centos/images/pxeboot/
cp initrd.img vmlinuz /var/lib/tftpboot/
准备pxe引导程序,启动菜单文件
pxe网络安装的引导程序为pxelinux.0,由软件包syslinux提供,安装完软件包后将文件复制到tftp服务的根目录下
cp /usr/share/syslinux/pxelinux.0 /var/lib/tftpboot/
启动菜单用来指导客户端的引导过程,默认启动菜单为default,应放在tftp根目录的pxelinux.cfg 目录中
mkdir /var/lib/tftpboot/pxelinux.cfg
vim /var/lib/tftpboot/pxelinux.cfg/default
default linux#默认入口名称
prompt 0 #1表示等待用户控制,0表示不等待
timeout 30 #超时时间
label linux
kernel vmlinuz
append initrd=initrd.img devfs=nomount method=ftp://192.168.130.128/centos
定义了三个引导入口,分别是图形安装(默认),文本安装,救援模式
prompt 设置是否等待用户选择
label 定义并把多个启动项分开
Kernel append 定义引导参数
配置并启动DHCP服务
PXE客户端通常是没有安装系统的裸机,肯定要与服务器取得联系并下载相关的引导文件,所以需要预先配置好DHCP服务来自动分配地址并反馈引导文件位置.
cp /usr/share/doc/dhcp-4.2.5/dhcpd.conf.example /etc/dhcp/dhcpd.conf
vim /etc/dhcp/dhcpd.conf
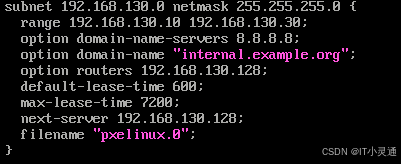
next-server 192.168.130.128 ; #ttp服务器地址
filename“pxelinux.0” #pxe 引导文件名
systemctl start dhcpd
systemctl restart xinetd
创建新的虚拟机并保证和服务端在同一个网卡模式上来验证
实现kickstart无人值守安装
使用kickstart工具配置安装应答文件,自动安装安装过程中的各种配置,不需要手动干预,提高效率
通过系统命令system-config-kickstart生成cfg配置文件,保存到/var/ftb/pub/目录下
修改pxe启动菜单文件 vim /var/lib/tftpboot/pxelinux.cfg/default
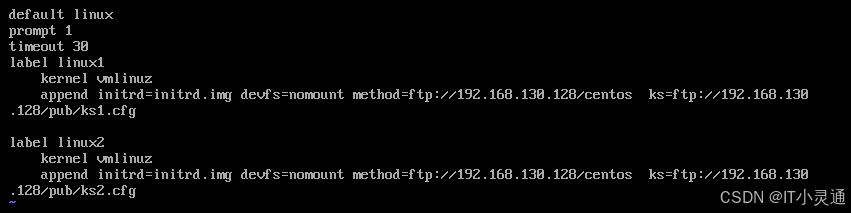
配置多台label时,使用system-config-kickstart命令来生成多个cfg文件,并将其写入pxe启动菜单文件中
Shell脚本
shell脚本的分类
图形化界面shell(GUI shell)
例如应用广泛的windows操作系统,还有linux shell其中linux shell还包括x window manager,以及功能更强大的GNOME,KDE等
命令行式shell(CLI shell)
传统意义上的shell就是命令行式的shell,shell是操作系统最外面的一层,shell管理你与操作系统之间的交互,等待你输入,向操作系统解释你的输入,并且处理各种各样的操作系统的输出结果
shell脚本的概念:
将平时使用的各种linux命令按顺序保存到一个文件中,添加上执行权限,就是一个shell脚本
shell的应用场景.
重复性操作
批量事务处理
自动化运维
服务器运行状态监控
定时任务执行
shell的概念
shell是在操作系统最外层,介于操作系统和用户之间的一个命令解释器(翻译官)的角色,负责接收用户输入的指令并向内核进行逐条解释,并将输出的结果返回给用户
查看当前操作系统支持的Shell解释器
cat /etc/shells
/bin/sh
/bin/bash
/usr/bin/sh
/usr/bin/bash
/bin/tcsh
/bin/csh
/bin/sh = /bin/bash = usr/bin/sh = /usr/bin/bash
/bin/tcsh = /bin/csh
查看当前的系统用的shell解释器
echo $SHELL
切换shell解释器
/bin/csh
切换到子shell
bash
编写shell脚本的格式
1#!/bin/bash #表示脚本通过bash解释器来执行
2#表示注释信息,比如对脚本功能一个解释说明,或者需要注释某些shell语句等
3定义脚本中的变量
例如a="a是一个变量"
4定义脚本中的函数
func(){
echo“这是一个函数”
}
5控制流语句(if判断,while循环等)
6利用echo定义输出一些让人更容易看懂的信息,便于排错(中英文自便)
脚本执行方式(3种)
通过绝对路径执行
chmod +x job.sh #添加执行权限
./job.sh
进入到脚本所在的目录下执行(推荐使用,脚本文件没有执行权限或脚本开头没有指定解释器)
sh job.sh
bash job.sh
进入在脚本目录下
source job.sh (source常用于重新执行刚修改的初始化文件)
. job.sh
语法检查
bash –n 脚本名
查看shell脚本执行过程
bash- x 脚本名
shell脚本后缀名
.sh表示编写程序为bash
.pl表示编写的程序为perl
.csh表示编写程序为csh
.py表示编写程序为python
重定向和管道
交互式硬件设备文件:input,output,error,分别是
标准输入:从该设备接收到用户输入的数据,/dev/stdin,键盘
标准输出:通过该设备用户输出数据,/dev/stdout,显示器
错误输入:通过该设备报告执行出错信息,/dev/stderr,显示器
重定向操作
重定向输入
<,指定从文件中读取数据,而不是从键盘输入
passwd --stdin user < pwd.txt
wc-l</etc/passwd
重定向输出
>,将输出结果保存在指定文件中(覆盖原有内容)
echo"abcdefg"> output.txt
> test.txt
>>,将输出内容保存到指定文件中(追加到文件末尾)
echo"o98k">> output
标准错误输出
2>将错误信息保存到指定文件中(覆盖原有内容)
abc 2> error.txt
2>>将错误信息追加到指定文件中(追加内容)
www 2>> error.txt
混合输出,&>将错误输出和正确输出的内容保存至同一个文件中
ls -l error.txt o98k.txt&> file.txt
注意:/dev/null空文件,黑洞(无限大空间)
处理多行输出(EOF可以是任意字符)
cat << EOF > test.txt
黄山落叶松叶落山黄山西运煤车煤运西山
EOF
管道符 |
将管道前的命令输出的结果作为管道后的命令参数使用
xargs在某些特殊情况下,管道会失去作用,可以使用xargs,强制管道符后的命令使用管道前的命令输出的内容作为参数
awk命令基本使用
awk –F分隔符 ‘{print 列}’
df –Th|grep "/$"|awk ‘{print $6}’ /$:以/结尾的
shell 变量
常量:固定字符串,一般不轻易改变
变量类型:环境变量(全局变量)和局部变量
自定义变量,由用户自定义的变量,只在本地shell环境中生效,就是当前这个shell环境,变量名必须使用英文或下划线开头,变量名内不允许出现特殊符号,字母区分大小写
设置变量
变量名=变量值
查看变量
echo $变量名
特殊符号
双引号“”,可以引用一个有空格的变量值
单引号‘’,引号内的内容被视为完整的字符串,不能引用变量
反撇号``,引号内的执行结果作为变量名的变量值,引用命令使用,也可以使用$()
read命令
提示用户输入信息,从而简单的实现交互变量设置.
-p 设置提信息
-t 设置等待时间
read -p“提示信息”变量1 变量2
提示信息 变量值1 变量值2
read –p "请输入名字年龄":name age
echo $name
echo $age
设置变量生效范围
新定义的变量只能在当前shell环境中生效,又称局部变量
export将局部变量变成全局变量,对子shell有效,对父shell无效
#设置一个变量test,并在当前shell 环境中打印变量值test=“变量”
#echo $test
#切换到新的子shell环境再次查看(并没有这样的变量)
#echo $test
#退出子shell,重新使用export设置变量,再进入子shell环境,再次查看
#export test
#bash
#echo $test
也可使用export定义全局变量
export test2="这是个全局变量"
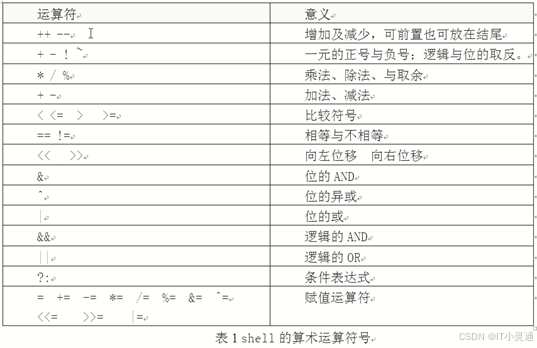
数值变量的运算
expr只能进整数运算,不支持小数运算
X=12
Y=22
expr $X+$Y
expr $X-$Y
expr $X\*$Y
expr $X/$Y
其他运算方式
echo $((100-33))
echo $[100-33]
echo"scale=2;100+33"|bc
echo $((1000*(1000+1)/2))100+1=n*(n+1)/2
判断文件或字符串的扩展名小案例:expr "text.pub" : ".*\.pub" && echo 1||echo 0

特殊的shell变量
环境变量
env 查看环境变量
由于运行需要而由linux系统提前创建的一类变量,主要用于设置用户的工作环境
/etc/profile环境变量全局配置文件,对所有用户都生效
~/.bash_profile 每个用户自己独立的环境变量
常用的环境变量
HOSTNAME
PWD
USER
set,env,export区别
env 显示用户的环境变量
set/declare 显示当前shell的自定义变量,包括用户的环境变量
export 显示当前登录用户的SHELL变量
unset 取消变量
位置变量
$0 获取当前执行的shell脚本的文件名,包括路径
$n 获取当前执行的shell脚本的第n个参数值,n=1..9,当n为0时表示脚本的文件名,如果n大于9要用大括号括起来${10}
$* 获取当前shell的所有参数,将所有的命令行参数视为单个字符串,相当于“$1$2$3$4”…注意与$#的区别
$@ 这个程序的所有参数 “$1” “$2” “$3” “…”,这是将参数传递给其他程序的最佳方式,因为它会保留所有内嵌在每个参数里的任何空白
$# 获取当前shell命令行中参数的总个数
进程状态变量
$$ 获取当前shell的进程号(PID)
$! 执行上一个指令的PID
$?获取执行上一个指令的返回值(0为成功,非0为失败) #à这个变量很常用
$_ 在此之前执行的命令或脚本的最后一个参数
$?反馈信息:0 成功,2 权限拒绝,1~125表示运行失败,脚本命令错误或参数传递错误,126 找到该命令了,但是无法执行,127 未找到要运行的命令,>128 命令被系统强制结束
附加命令:
driname $0 取出路径
basename $0 取出名称
shift语句
shift语句重新命名所有的位置参数变量,即S2成为$1,s3成为$2 在程序中每使用一次shift语句,都使所有的位置参数依次向左移动一个位置,并使位置参数S#减1,直到减到0为止。
脚本应用思路
确定命令操作(构思整体流程)
编写shell脚本(组织脚本过程)
设置计划任务(控制时间,调用脚本)
正则表达式概述
使用单个字符来匹配一系列符号句法规则的字符串广泛用于脚本编程文件编辑中,用来检索替换符合模式的文本,具有强大的文本匹配功能,能够高效的处理文本.
linux运维工作中,需要时刻面临大量日志,程序,命令的输入,迫切的需要过滤出我们需要的一部分内容,甚至是一个字符串,这个时候就需要用正则表达式来处理
通配符
* 任意长度任意字符,属于通配符
? 单个任意字符,属于通配符
基础正则表达式
\ 转义符
^ 匹配行首(锚定行首)
$ 匹配行尾
^$ 表示空行
. 匹配除换行符\n之外的任意单个字符
.* 匹配任意长度任意字符
[] 匹配包含在[字符]之中的任意一个字符
[^] 匹配[字符]之外的任意一个字符
^[^字符] 匹配非指定字符开头的行
\{n\} 匹配之前的项n次, n是可以为0的正整数
\{n,\} 之前的项至少需要匹配n次
\{n,m\} 指定之前的项至少匹配n次,最多匹配m次
单词锚定
\<:其后面的字符必须作为单词的首部出现,也可\b
\>:其前的字符必须作为单词的尾部出现,也可\b
\<root\<:root必须作为一行的单词出现,也可\broot\b
转义符
\a 响铃
\b 退格
\n 换行
\r 替换字符
\t 空一个tab键位置
\v 制表符
\\\ 代表一个反斜杠字符
扩展正则表达式
+ 匹配之前的项1次或者多次
? 匹配前边字符一次或0次
() 将括号中的字符串做为一个整体
| 交替匹配 | 两边的任意一项
shell中将一个或者多个字母进行大小写转换${test^}(^ 转换成大写,转换成小写)
grep
过滤关键字,根据模式搜索文本,并将符合模式的文本行显示出来,grep使用的是正则表达式
egrep=grep –E 是扩展grep,支持基本及扩展的正则表达式
grep 参数 ‘关键字’文件名
参数
-i 略大小写
-v 显示没有被模式匹配到的行相当于^[^]
-o 只显示被模式匹配到的字符串
-n 显示匹配行及行号
-c 只输出匹配行的计数
-1 查询多文件时只输出包含匹配字符的文件名
-L 打印不匹配的文件名
-e 满足多个过滤参数的条件
-r 递归查询
-E 使用扩展的正则表达式
-w 只显示全单词符合的行
-q 匹配内容不显示(静默模式)
sed
sed是一种在线编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为模式空间”,接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有改变除非你使用重定向存储输出。Sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等。
格式:sed 选项‘行定界 /old字符/new字符/列定界符 处理动作'文件名
定界符
s 替换指定的字符
g 全局替换
i 不区分字符大小写
选项
-i 直接编辑原文件
-e‘script'-e‘script':指定多个编辑指令
-n 静默模式(默认打印),或只显示匹配后的内容
处理动作
! 取反,如!w、!=、!d、!i\#、!r\#、!w\#
d 删除
c 取代,c后面可以接字串,这些字串可以取代n1,n2之间的行
p 打印,通常p会与参数-n一起
i或i\ 在被指定到行的上面插入文本
a或a\ 在被指定的行的下面插入文本
\n 换行
r文件 在指定位置把另外一个文件的内容插入
w文件 将符合条件的所有行保存至指定文件中
= 显示符合条件的行的行号
在文件中的每行后添加空行:sed ‘G’a.txt
创建多个用户:seq –w 10|sed -r 's/(.*)/useradd user\1/g'|bash
设置多用户密码: seq -w 5|sed -r 's/(.*)/psw=(123456);echo $psw|passwd --stdin user\1/g'|bash seq
生成序列[1...LAST] seq nums
生成序列[FIRST...LAST],步长为1 seq nums1 nums2
生成序列[FIRST INCREMENT LAST],步长为INCREMENT (两边是开头和结尾,中间为步长)
-s 指定分隔符
-w 输出01 02 03 04 05....
awk
grep,sed,awk是shell编程中经常用都的文本处理工具(shell编程三剑客),awk是一和编程语言,主要用于处理结构化的数据,awk可以在非交互式情况下完成相当复杂的文本处操作,awk倾向于将一行分为多个"字段"来处理。
格式
awk 选项 ‘模式或条件(编辑指令)’ 文件
要查找出/etc/passwd的用户名,用户ID,组ID使用awk就可完成
awk –F ‘:’‘{print $1,$3,$4}' /etc/passwd
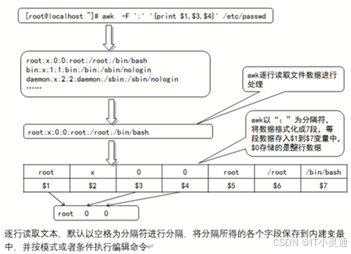
条件操作描述符
关系操作符>、>=、<、<=、==(精确匹配)、!=(不等于)
赋值操作符=、+=、*=、/=、%=、^=
条件表达操作符
或||、与&&、非!
匹配操作符 ~ ,!~ (模糊匹配)
算术操作符+、-、*、/、%、^(次方)
awk的常用的内置变量
FILENAME awk读取的文件名
FNR浏览文件的记录数(浏览文件次数,文件会累加记录)
NF浏览记录的域个数(当前行的字段数)
$NF表示最后一个区域
NR已读的记录行数(命令后跟的所有文件统一合并计数)
条件语句
单一的顺序结构脚本不够智能,难以处理复杂灵活的任务,使用if语句来使脚本增加灵活性,根据不同条件来完成不同的任务
条件测试
测试特定的条件是否成立,当条件成立则返回0,否则返回其他数值,根据命令的执行返回值来判断
0 真 执行成功 True
非0 假 执行失败 False
变量字串的常用操作:
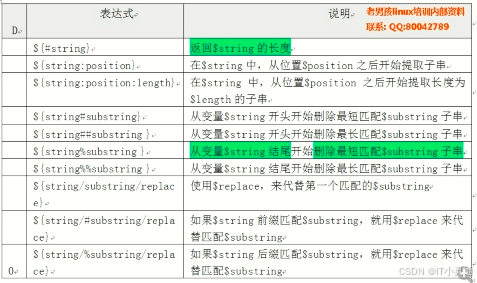
拓展:批量改拓展名àrename .jpg .JPG *

其他变量替换(初学者跳过)



test -f file && echo 1||echo 0 查看文件是否存在
[ -f file ] && echo 1||echo 0 查看文件是否存在
常用文件测试操作符
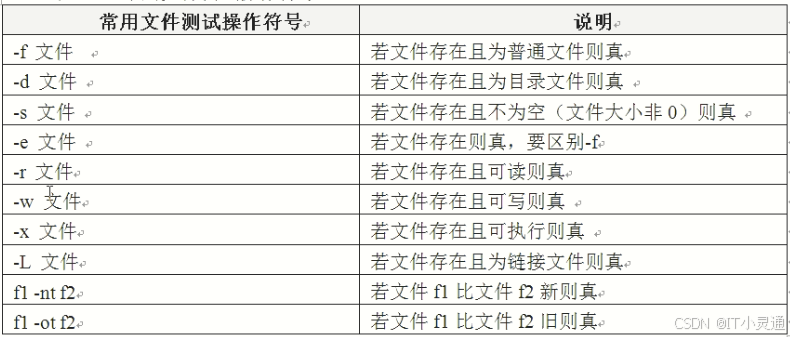
记忆方法: f=file(文件)
d=directory(目录)
s=size(大小)
e=exist(存在)
r=read(读)
w=write(写)
x=executable(执行)
nt=newer than
ot=older than
字符串操作测试符

整数二元比较操作符
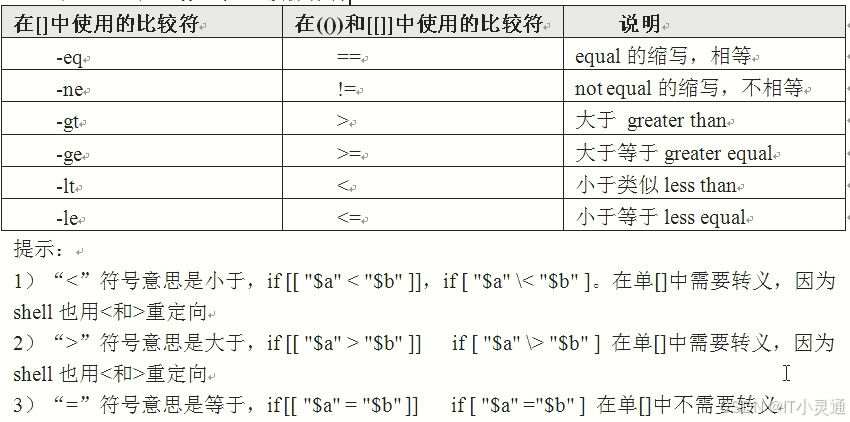
逻辑操作符
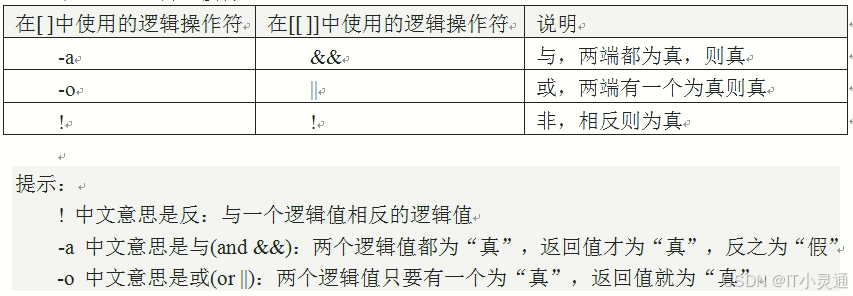
逻辑操作符运算规则
结论: -a&&的运算规则:只有两端都是1才为真
真1假0
and 1*0=0假
and 0*1=0假
and 1*1-1真
and 0*0=0假
只有两端都是1才为真
结论:-o,||两端都是0才为假,任何一端不为0都是真
or 1+0=1真
or 1+1=2真
or 0+1=1真
or 0+0=0假
两端都是0才为假,不为0就是真
if语句类型
单分支
if [ 条件测试语句 ]
then
命令序列
fi
如果条件成立,就执行命令序列,如果条件不成立则退出if语句
0 成立 非0 不成立
双分支
if [ 条件测试语句 ]
then
命令序列1
else
命令序列2
fi
如果条件成立就执行命令序列1,否则执行命令序列2
多分支
if [ 条件测试语句1 ]
then
命令序列1
elif [ 条件测试语句2 ]
then
命令序列2
else
命令序列3
fi
如果条件1成立就执行命令序列1,条件1不成立判断条件2,如果成立,就执行命令序列2,否则执行命令序列3
case结构条件语句
case “字符串变量”in
值1) 指令...
;;
值2) 指令...
;;
*) 指令...
esac
示例:
read -p "pls input a number:" ans
case "$ans" in
1)
echo "the num you input is 1."
;;
2)
echo "the num you input is 2."
;;
[3-9])
echo "the num you input is $ans."
;;
*)
echo "the num you input must be less 9."
exit
;;
esac
当型循环和直到型循环
while条件句
while 条件 (条件满足就执行)
do
指令...
done
示例:
while true
do
uptime
sleep 2
done
while true表示条件永远为真,因此会一直运行,像死循环一样,但是我们称呼为守护进程
until条件句(应用场景不多见,了解就好)
until 条件 (条件满足就退出)
do
指令...
done
for循环结构
for 变量名 in 变量取值列表
do
指令...
done
提示:在此结构中“in变量取值列表”可省略,省略时相当于in“$@”,使用for i相当于使用for i in“$@”
c语言型for循环结构
for((exp1;exp2;exp3))
do
指令...
done
学习方法:
for 男人 in 世界.
do
if [有房] && [有车] && [存款] && [会做家务] && [帅气] && [温柔] && [体贴] && [逛街买东西]; then
echo "我喜欢".
else
rm -f 男人
fi
done
shell脚本中取随机字符串
echo $RANDOM
openssl rand -base64 8|md5sum
date +%s%N
head /dev/random|cksum
cat /proc/sys/kernel/random/uuid
yum -y install expect -y mkpasswd|md5sum
echo “$RANDOM$(date +%N$t)”
检测字符串唯一性:mkpasswd|md5sum|cut -c 1-9|sort|uniq -c|sort -nk1
break continue exit 对比
break continue exit一般用于循环结构中控制循环的走向。
break:跳出整个循环,执行下面的其他程序
continue:跳出当前循环,进入下一个循环
exit:终止循环,并退出shell脚本程序
