
阅读量:0
前言:
前面我们已经学习了简单的数据结构,包括栈与队列、二叉树、红黑树等等,今天我们继续数据结构的学习,但是难度上会逐渐增大,在高阶数据结构中我们要学习的重点是图等
目录
一、并查集的原理
在某些情况下,对于一组元素,我们会把它们划分成不同的集合。起初每个元素组成一个单元素集合,然后按照一定规律将归于同一种类型的集合合并,同时在这个过程中我们可能会反复用到查询某个元素属于哪个集合的运算,这种管理集合所对应的抽象概念就是并查集
并查集,也称为链接-切割数据结构,是一种用于管理集合的高效数据结构。它特别适用于处理“动态连接”的问题,即动态地合并集合或查询两个元素是否属于同一个集合。并查集在计算机科学中有着广泛的应用,如用于解决最小生成树问题(Prim算法和Kruskal算法)、解决网络连通性问题、解决图论中的问题等。
下面来看这样一个例子:某旅游团内有游客10人,其中西安4人,成都3人,武汉3人,10个人来自不同的地方,起先互不相识,每个游客都是一个独立的小团体,现给这些游客进行编号:{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}; 给以下数组用来存储该小集体,数组中的数字代表:该小集团中具有成员的个数(负数的意义下文讲解)

旅行结束后,游客们要乘车回家,每个地方的游客自发组织成小分队一起上路,于是:西安游客小分队s1={0,6,7,8},成都游客小分队s2={1,4,9},武汉游客小分队s3={2,3,5}就相互认识了,10个人形成了三个小团体。假设右三个群主0,1,2担任队长,负责大家的出行。
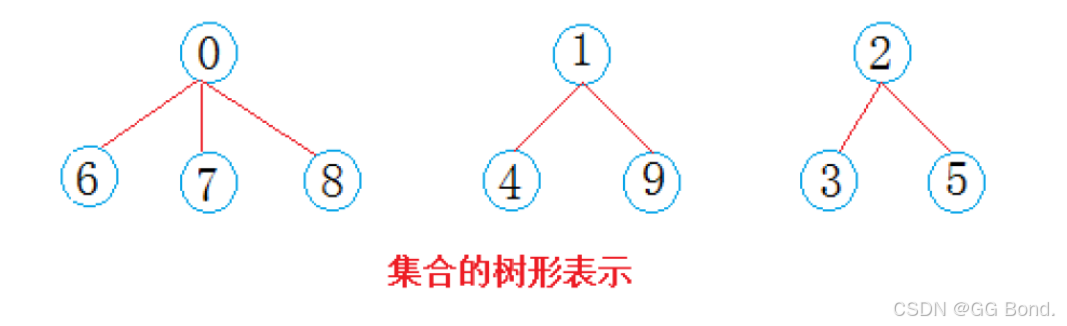
一趟火车之旅后,每个小分队成员就互相熟悉,称为了一个朋友圈。
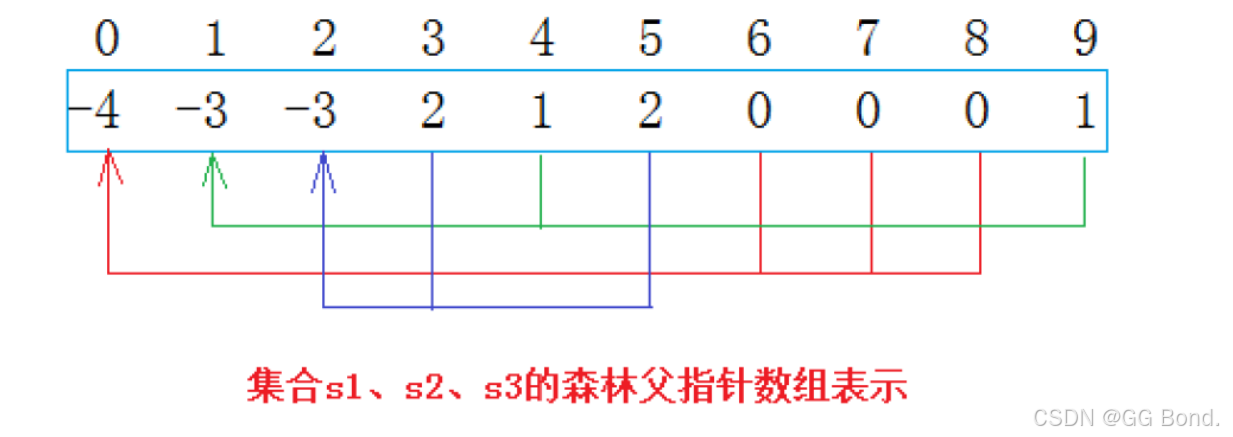
从上图可以看出:编号6,7,8游客属于0号小分队,该小分队中有4人(包含队长0);编号为4和9的同学属于1号小分队,该小分队有3人(包含队长1),编号为3和5的游客属于2号小分队,该小分队有3个人(包含队长1)。 仔细观察数组中内融化,可以得出以下结论:
1. 数组的下标对应集合中元素的编号
2. 数组中如果为负数,负号代表根,数字代表该集合中元素个数
3. 数组中如果为非负数,代表该元素双亲在数组中的下标
回家一段时间后,西安小分队中8号游客与成都小分队1号游客奇迹般的走到了一起,两个小圈子的游客相互介绍,最后成为了一个小圈子:
 现在0集合有7个人,2集合有3个人,总共两个朋友圈
现在0集合有7个人,2集合有3个人,总共两个朋友圈 通过以上例子可知,并查集一般可以解决一下问题:
1. 查找元素属于哪个集合
沿着数组表示树形关系以上一直找到根(即:树中中元素为负数的位置)
2. 查看两个元素是否属于同一个集合
沿着数组表示的树形关系往上一直找到树的根,如果根相同表明在同一个集合,否则不在
3. 将两个集合归并成一个集合
将两个集合中的元素合并
将一个集合名称改成另一个集合的名称 4. 集合的个数
遍历数组,数组中元素为负数的个数即为集合的个数。
二、并查集的基本操作
并查集主要支持以下三种基本操作:
- 查找(Find):确定一个元素属于哪个集合。
- 合并(Union):将两个集合合并为一个集合。
- 初始化(Init):为每个元素创建一个独立的集合。
三、并查集的实现(简略版)

class UnionFindSet { public: // 初始时,将数组中元素全部设置为-1 UnionFindSet(size_t size) : _ufs(size, -1) {} // 给一个元素的编号,找到该元素所在集合的名称 int FindRoot(int index) { // 如果数组中存储的是负数,找到,否则一直继续 while (_ufs[index] >= 0) { index = _ufs[index]; } return index; } bool Union(int x1, int x2) { int root1 = FindRoot(x1); int root2 = FindRoot(x2); // x1已经与x2在同一个集合 if (root1 == root2) return false; // 将两个集合中元素合并 _ufs[root1] += _ufs[root2]; // 将其中一个集合名称改变成另外一个 _ufs[root2] = root1; return true; } // 数组中负数的个数,即为集合的个数 size_t Count()const { size_t count = 0; for (auto e : _ufs) { if (e < 0) ++count; } return count; } private: vector<int> _ufs; };四、并查集的实现方式和优化策略
并查集有两种常见的实现方式:路径压缩和按秩合并。
- 路径压缩:在查找操作中,将查找路径上的所有节点的父节点直接指向根节点,以减少查找路径的深度。
- 按秩合并:在合并操作中,将秩较小的集合合并到秩较大的集合中,以减少树的高度。
为了提高查找操作的效率,通常结合使用路径压缩和按秩合并两种策略。路径压缩确保查找操作的时间复杂度接近常数,而按秩合并则减少了树的高度,进一步优化了合并操作的时间复杂度。
五、并查集的实现(完整版)
#include <iostream> #include <vector> class UnionFind { private: std::vector<int> parent; std::vector<int> rank; public: UnionFind(int n) : parent(n), rank(n) { for (int i = 0; i < n; ++i) { parent[i] = i; rank[i] = 1; } } int find(int x) { if (parent[x] != x) { parent[x] = find(parent[x]); // 路径压缩 } return parent[x]; } void unite(int x, int y) { int rootX = find(x); int rootY = find(y); if (rootX == rootY) return; if (rank[rootX] > rank[rootY]) { parent[rootY] = rootX; } else if (rank[rootX] < rank[rootY]) { parent[rootX] = rootY; } else { parent[rootY] = rootX; rank[rootX] += 1; } } bool connected(int x, int y) { return find(x) == find(y); } }; int main() { int n, m; std::cin >> n >> m; UnionFind uf(n); for (int i = 0; i < m; ++i) { int a, b; std::cin >> a >> b; uf.unite(a - 1, b - 1); // 转换为0-based索引 } for (int i = 0; i < m; ++i) { int a, b; std::cin >> a >> b; std::cout << (uf.connected(a - 1, b - 1) ? "YES" : "NO") << std::endl; } return 0; }六、总结
并查集的高效性在于其优化策略,使得查找和合并操作的时间复杂度保持在较低的水平,从而在处理大规模数据集时依然表现出色。平时我们在刷题或学习中还是会经常遇到并查集的
 感谢各位大佬观看,创作不易,还请各位大佬点赞支持!!!
感谢各位大佬观看,创作不易,还请各位大佬点赞支持!!!