
阅读量:0
前言
文件分为打开的文件和没有打开的文件!上一期以及以前我们都谈的是打开的文件,他们是在内存中存放;然而大部分文件都是没有被打开的(当前不需要访问的)他们是在磁盘当中存放的!打开的文件要被管理,那没有被打开的文件是不是也要被管理呀!OK,对打开文件的管理和对没有被打开文件的管理,称为文件系统!本期就来介绍一下没有被打开的文件和Ext2文件系统!
本期内容介绍
• 磁盘的介绍
• Ext2文件系统
• 再次理解目录
• 再次理解文件的增删查改
磁盘的介绍
我们知道没被打开的文件是在磁盘存储的!但什么是磁盘我们其实并不了解,所以下面我们先来介绍一下计算机中的唯一一个机械外设即磁盘!注意,这里说的磁盘不是我们笔记本上的固态硬盘SSD!
磁盘的物理结构
我们先来大致的了解一下磁盘的物理结构:

磁盘中一片一片的类似于光盘的片,叫做盘片!他和我们的光盘不同,光盘是一面可读写的,他是两面都可以读取/写入和擦除的, 在一个磁盘中有一摞盘片!
盘片上类似于一个指向标的东西叫做磁头,他是悬浮在盘面上的,主要负责读取和写入数据的,由于每个盘片两面是可读可写的所以每一个盘片有两个磁头,一面一个!
磁盘在工作时,在盘片中间的马达带动下盘片高速旋转,磁头也在马达的带动下左右移动!这样就可以来寻找访问的位置了!其实磁盘之所以可以永久的存储数据主要是通过磁性来存储的,计算机的数据本质都是一堆的0和1,而我们知道磁铁分为NS两级,所以可以想象成每个盘面上有很多的小磁铁,在写入操作时磁头可以生成相关的磁场改变这些小磁铁的NS,达到写入操作;在读取时,磁头靠近盘面,检测每个小磁铁的NS生成相应的二进制!
磁盘的存储结构
简单的了解了磁盘的物理结构后我们来介绍一下磁盘的存储结构:
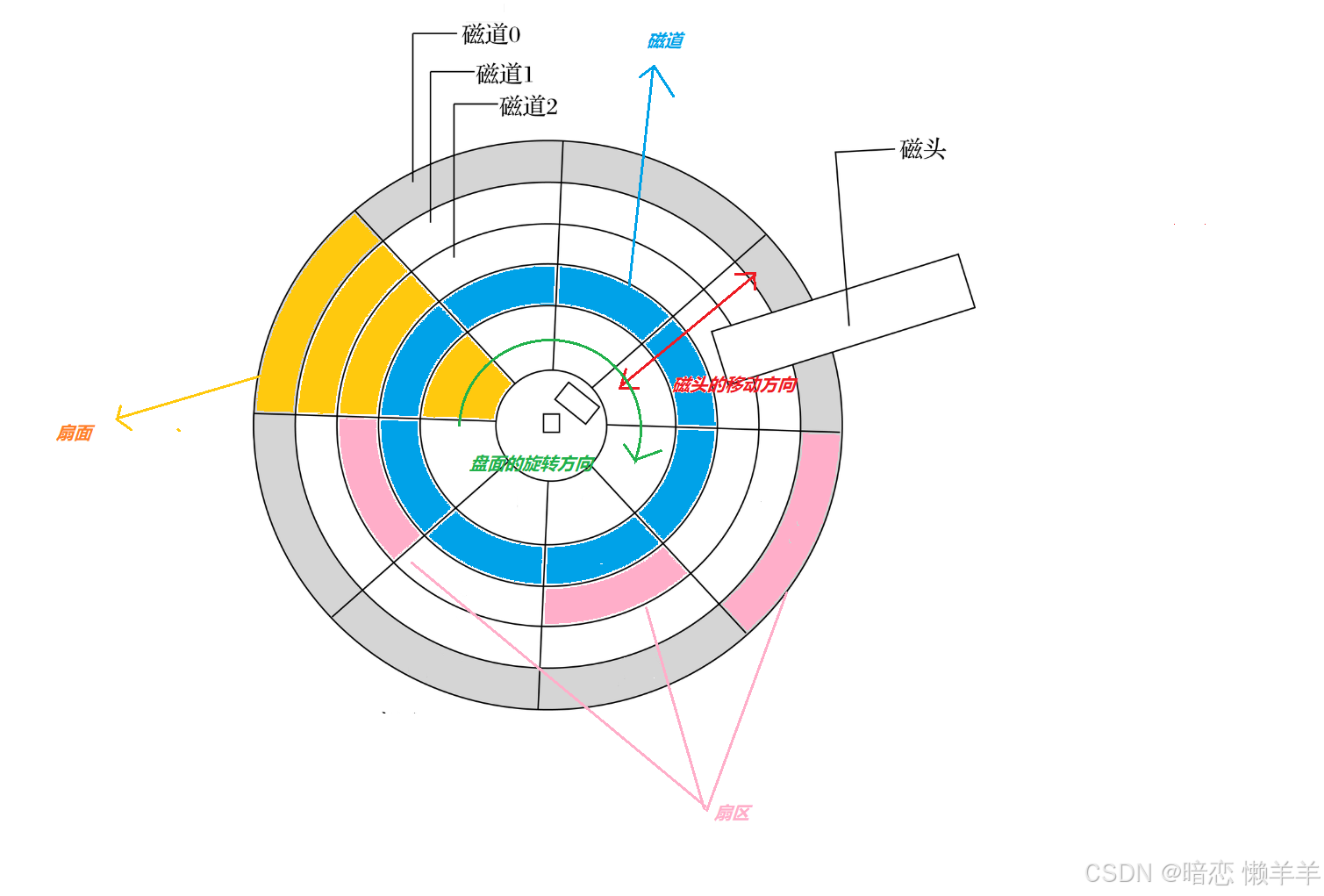
这是磁盘的存储结构的俯视图!我们可以看到,一个盘面是由无数个同心圆组成的,每一个同心圆环叫做磁道/柱面!而一个盘面又被分成了很多扇形, 以整个圆盘的半径为边的大扇形叫做扇面!每一个小的扇行叫做扇区!
扇区是磁盘读写的基本单位,一般的大小固定为512 byte
这里你就可能会有疑问,距离圆心近的和距离圆心远的他们的面积都不一样,怎么他们都固定都是512byte呢?其实在磁盘生产的时候,厂商会保证每一块的小磁铁的密度相同,所以即使他们的面积不同但是容量大小是固定的!
所以计算机在磁盘访问文件时,是只需要找到该文件的所有扇区即可!如何找到呢?
1、先确定是哪一个面,即找到指定的磁头 Header
2、在找到是在那一个磁道 / 柱面 Cylinder
3、最后确定在磁道的那一个扇区 Sector
这种方法也称作CHS定址法!介绍到这里也就可以明白为什么盘面要高速旋转,磁头要左右移动了!盘面要高速旋转是为了确定扇区,磁头高速移动就可以确定磁道了!
磁盘的逻辑结构
以我们对操作系统的了解,操作系统是绝对不都会反访问文件时直接拿着CHS去访问的!其实,OS是可以直接拿着CHS去访问二文件的但是为什么不直接拿着CHS访问呢?一是,磁盘是外设I/O效率较低,另外,软硬件的耦合度太高,不方便内核的管理!所以他一般会对某些设备的管理抽象成某种特定数据结构的管理!OK,我们下面就来介绍一下磁盘的抽象逻辑结构!

不知道大家见过磁带没有!他也是一盘的和磁盘类似!他在读写时是将圆盘的磁带进行拉直进行读写的!
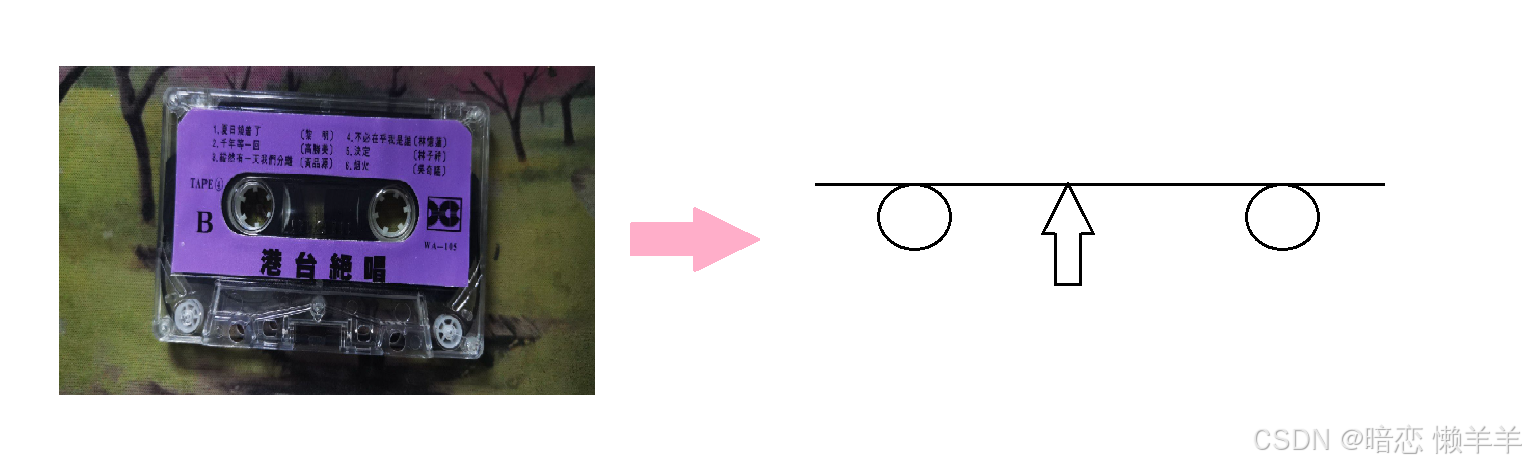
那能不能将磁盘也抽象呢?当然可以!可以将每个扇区看作一个数组的元素,因为每个面的扇区数都相等所以所有的面的扇区就可以看作是一个巨大的数组!
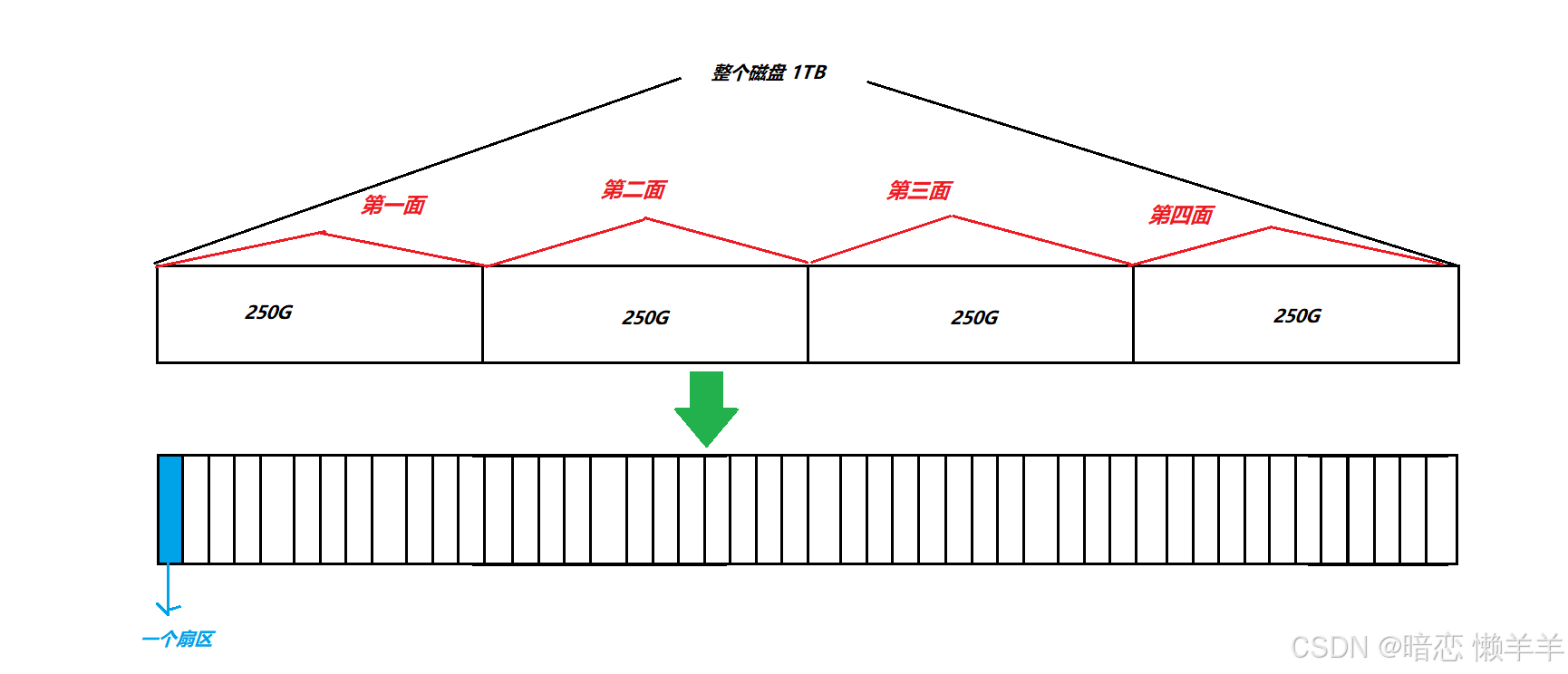
而数组是有下标的,所以后期访问时OS直接可以拿着下标通过/ 和 % 转换为CHS地址访问!所以此时对磁盘的管理就变成了对扇区数组的管理!
上面说过,扇区是磁盘的读写单位,其大小是固定的是512byte,但是操作系统嫌每次I/O时只能访问(读写)512 byte的数据,效率有些低!所以OS一般以4KB为基本的读写单位!4KB = 512* 8,也就是连续的8个扇区!所以OS每次对磁盘的读写都是以8个扇区为单位的!哪怕你今天直写入一个字节的内容,操作系统也是会为你在磁盘开出4KB的空间的!注意,这并不意味着磁盘空间被浪费了。文件系统通常会使用某种形式的空间回收或压缩机制来优化磁盘空间的使用。
OS对4KB的连续扇区空间称之为数据块!有了数据块之后OS会对上面的扇区数据进一步抽象成块数组!也就是OS以后读写数据 的单位变成了数据块了!
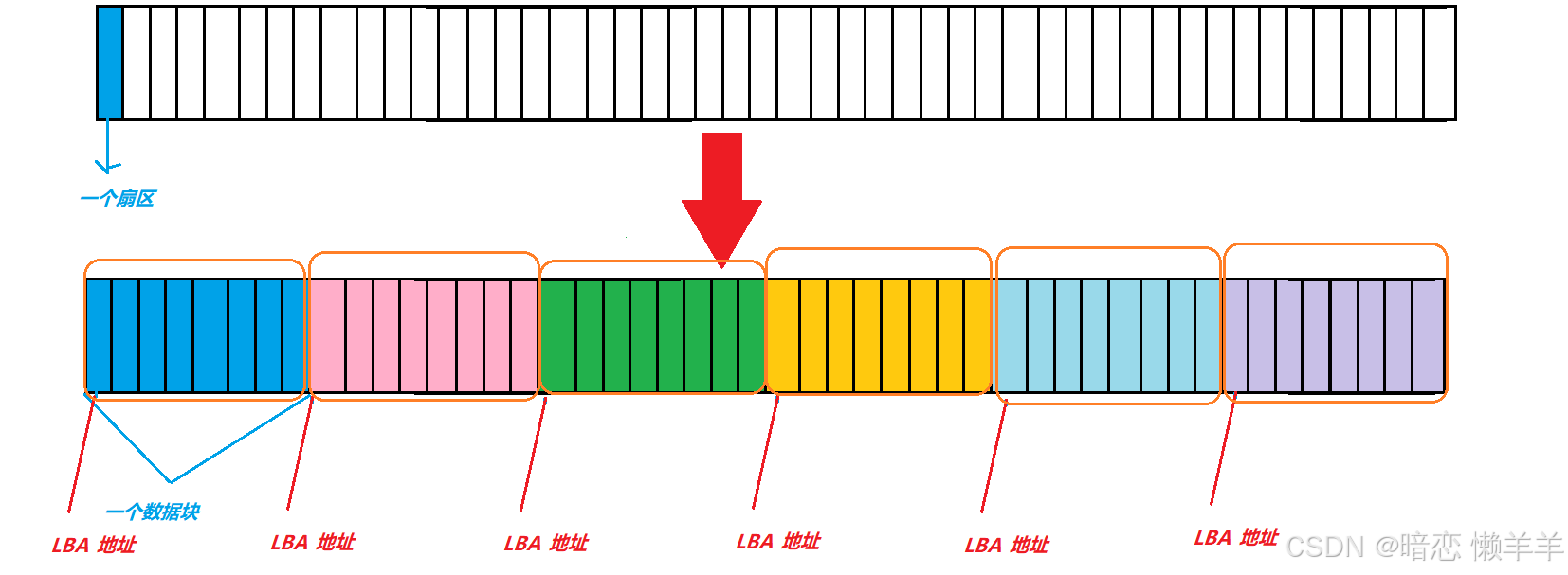
并且OS会对上面的数据块数组进行重新编址,每个块的地址叫做LBA地址(Logical Block Address)此时当OS访问磁盘的文件时,只需要知道LBA地址,再依次向后偏移8位就可以知道整块中的所有扇区的地址了,转换成线性地址(扇区数组),然后转换成为CHS就可以访问指定的扇区了!这就实现了先描述,在组织!先描述是用一个LBA的下标描述一个块,在组织是将整个磁盘的管理变成了对LBA数组的管理!
Ext2文件系统
目前Linux的文件系统是Ext3以及Ext4等,而我们今天介绍的是 Ext2,和Ext3/4差不多且较好入门,所以我们就以Ext2进行介绍!
分区和分组
我们知道,一个学校人很多,校长一个人是很难管理好的所以就对学校就进行了分出二级学院进行管理,例如:信息工程学院、医学院、艺术院、经管院等!同理,磁盘的空间也是巨大的,整体管理起来不太好管理!所以就会对磁盘进行分区管理,例如:C盘、D盘等 !但是一个区域还是不太好管理,所以再对分区进行分成若干的组!只要管理好一个组,同区的其他小组也可以按照,管理当前组的方式来管理,这样一个区域就被管理好了!一个区域管理好了,另外的区域也可以按照这套规则管理!所以现在如何管理好一个磁盘的就转换成了如何管理好一个组!其实这是一种分治的思想!
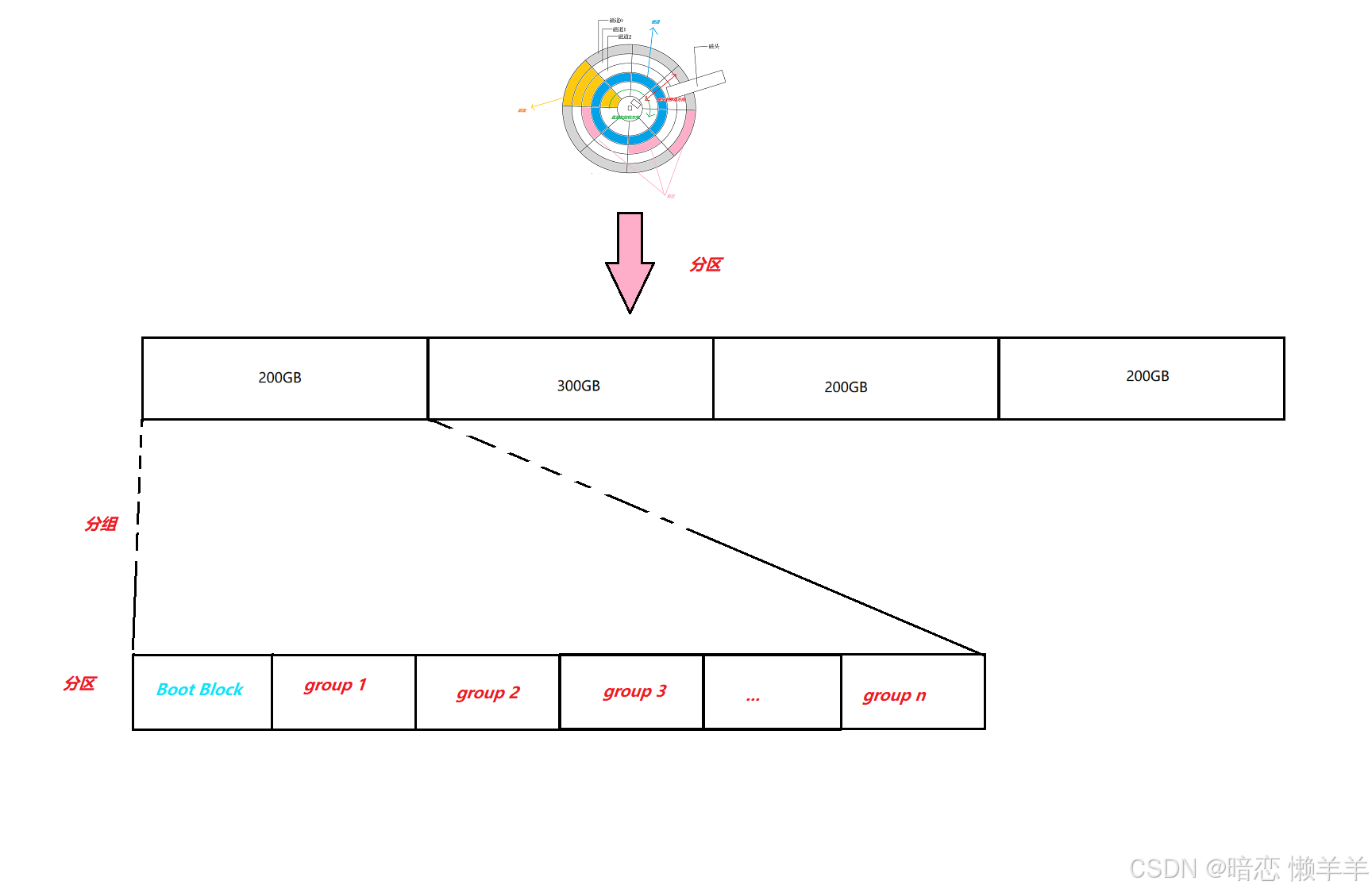
块组信息
上面介绍了管理好整个磁盘最终转换成了如何管理好一个组,所以我们下面介绍的就是如何管理好每一个组块的!
下面是组块的信息图:
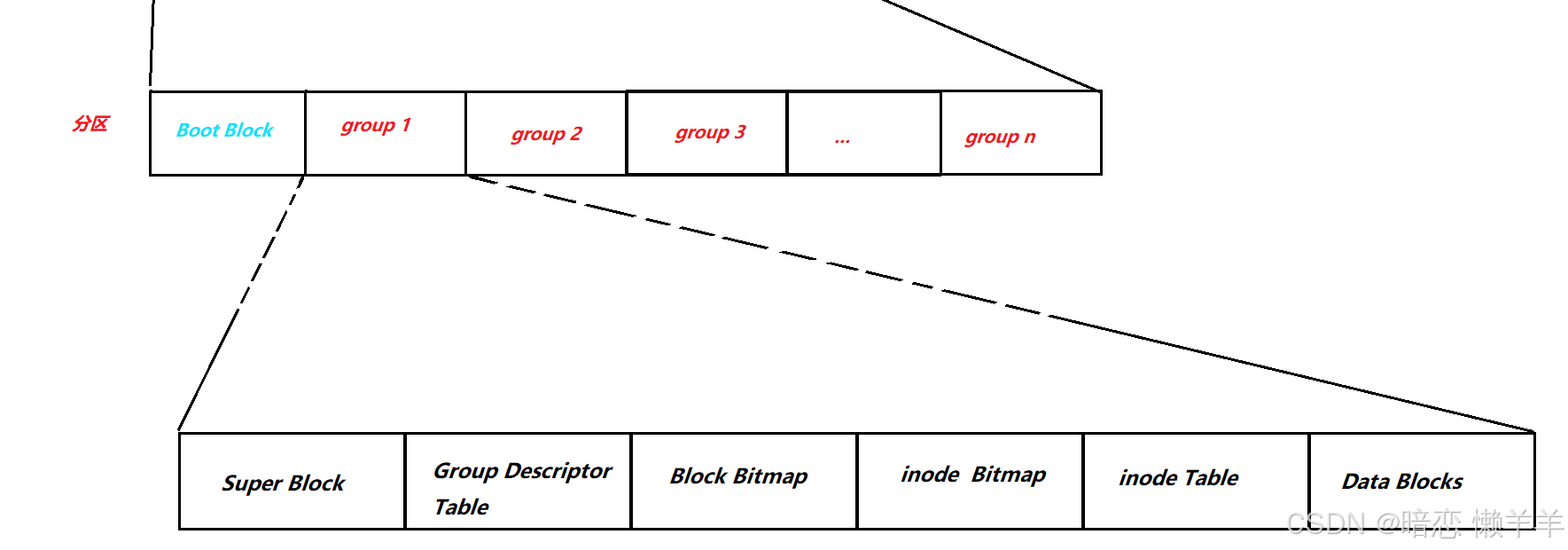
• inode Table&inode Bitmap
我们知道:在磁盘存的是文件,而 文件 = 内容 + 属性 其实属性也本质是数据,也是要存储到磁盘的!Linux文件系统规定:文件的属性 和 文件的内容 是分开存储的!
inode是描述Linux中的文件属性是一个的结构体, 他的大小固定的128byte
在一个分组中有很多的文件,每个文件都要有inode结构体对象来存储自己的文件属性!一个分组中的所有inode对象都存储在inode Table中!为了标记inode Table 中的inode对象是否被分配,每个分组又维护了一张位图inodeBitmap ,用每个inode对象的编号对应的位来做标记!
OK,比如说,你现在查找一个文件,他的inode的编号是50,假设你拿着去第一个组找,第一组会按照你的50去位图中查找50对应的标记是否是一!就可以判断inode的对象是否被分配!
inode的结构体大致如下:
struct inode { int size; //文件大小 mode_t mode;//权限 int creater;//创作者 int tmie;//ACM时间等 //... int inode_num;//文件对应的inode编号 int datablocks[N];//N 一般是15,指向内容的块号,可以有多级 };其中前面的我们都很好理解,但是这里面怎么没有文件名呢?其实文件名是给上层的用户看的,内核使用inode_num的编号来唯一标识一个文件的!也就是文件名和inode_num是一对<K,V>键值对!最后的datablocks数组是干啥的呢?其实这里面存的是指向文件内容存放的数据块!下面介绍!
• Datablocks&Block Bitmap
Datablocks是数据区,存放文件内容的!他里是很多个大小为4KB的数据块!其中每个块的编号唯一!
Block Bitmap和上面的inode Bitmap的作用类似,它是用块的编号来标记每一个块是否没使用了!
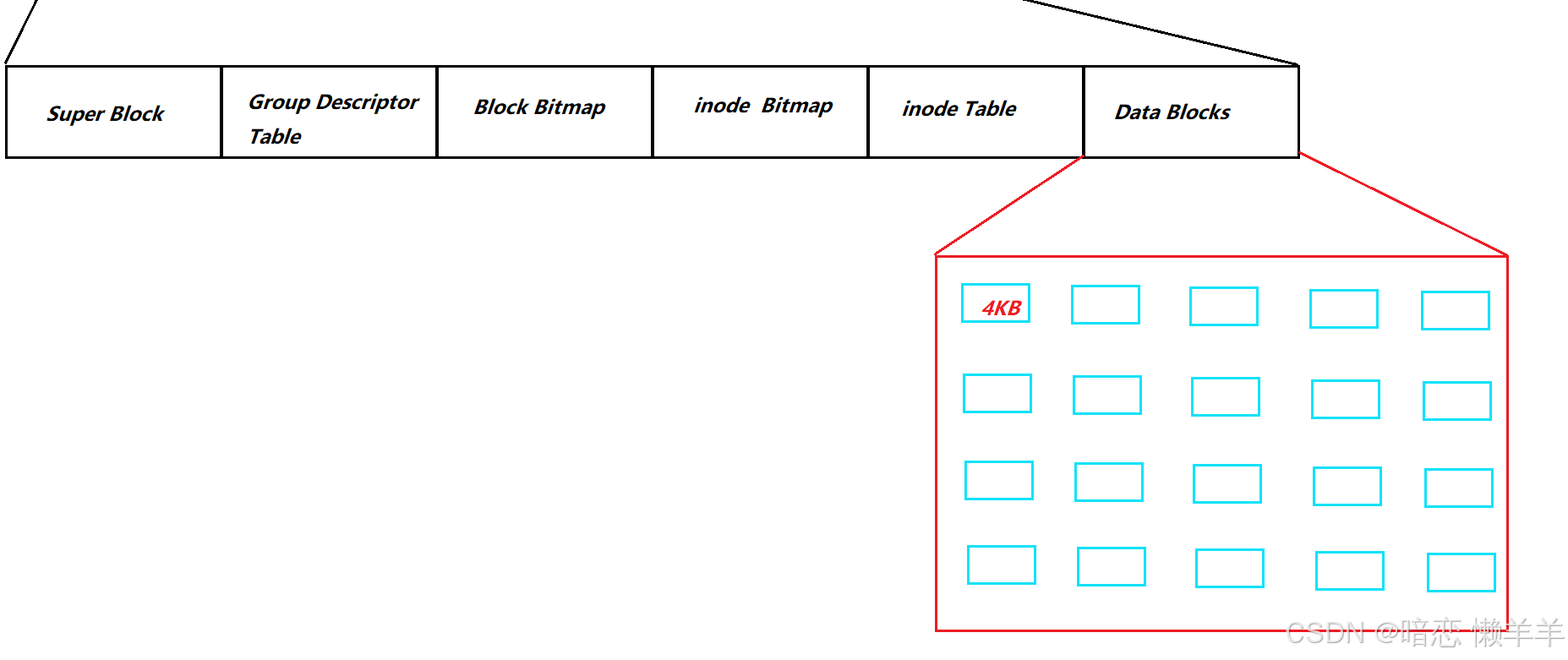
现在就可以谈上面留下的datablocks[N]了!
datablocks的大小一般是15,前12即[0,11]是直接指向文件内容对应的块号的,剩下的[12,14]是多级索引!
什么是多级索引呢?
多级索引就是当[0,11]的内容都填完了,但是文件内容还没有被填完,此时从12开始就不再是直接致指向文件内容的数据块了,而是会将第12下标指向的数据块划分成若干指向一级数据块的编号,也变相的等于扩容了!
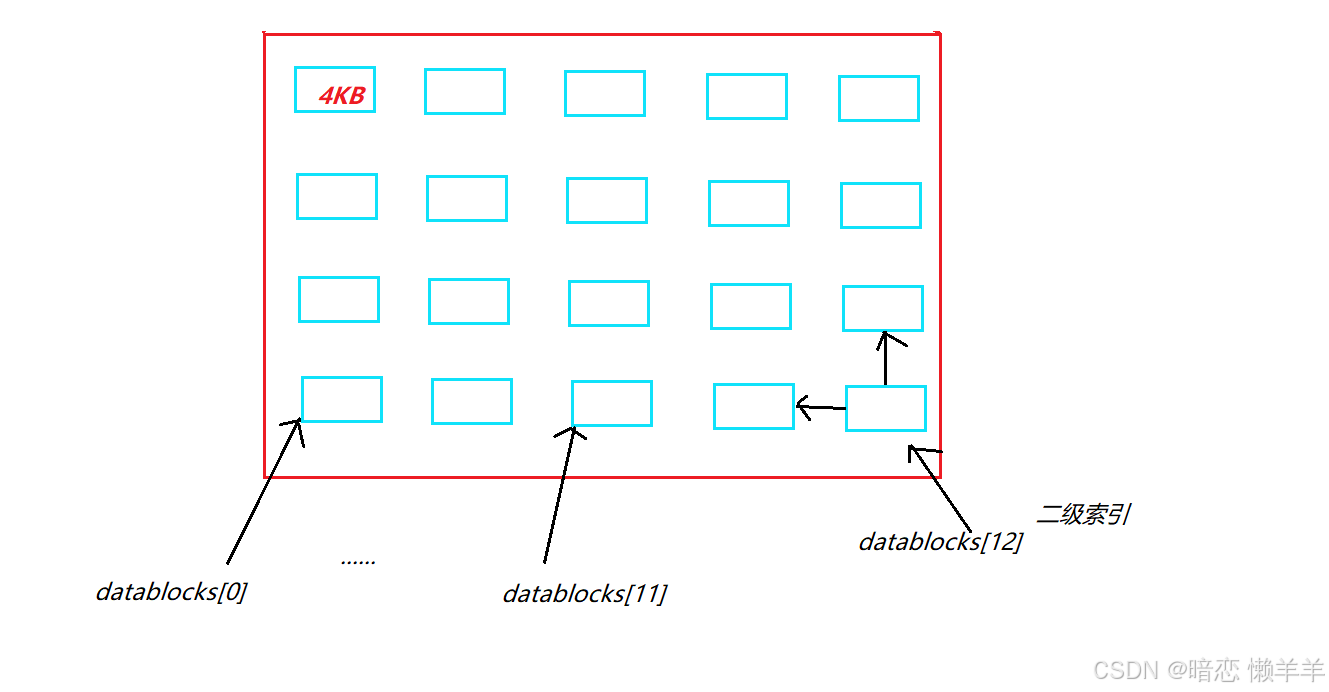
同理,当二级索引不够的时候,13,14依次会在变相的扩容,变成三级索引!
小Tips:inode 编号是以分区为单位进行统一分配的,而且不能跨分区,即每个分区中的 inode 编号都是从 0 开始,且一个分区中的 inode 个数是有上限的,因此可能会存在一下情况:一个分区中的 inode 被用完了,但是数据块还没有被用完,这种情况对应的就是创建了非常多的文件,但是每个文件的内容非常小;一个分区中的数据块被用完了,但是 inode 还没有被用完,这种情况就是创建的文件并不多,但是每个文件的大小非常大。
• GDT&Super Block&Boot Block
上面介绍了:文件 = 内容 + 属性!属性被inode Table管理,内容被dadablocks管理,那文件系统整体被谁管理呢?这里是GDT&Super Block&Boot Block的任务了!
GDT
Group Descriptor Table叫做块组描述符表,简称GDT,描述组的属性信息!
例如:当前分组的大小、使用情况,每个组都有自己的GDT
Super Block
Super Block:存放文件系统本身的信息,这里面记录了整个分区的信息
记录的信息主要有:bolck 和 inode的总量,未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。OK像这种宏观的描述分区的信息,应该只在一个分区有一个即可,为什么会出现在组里面呢?其实,并不是每个组都有,而是部分组有!由于Super Block的信息被破坏,可以说整个文件系统结构就被破坏了。所以防止意外使得磁盘中的Super Block的信息被破坏而导致整个分区不可以用了,所以在部分组中添加了Super Block的信息(可以认为是副本),一旦一个组的Super Block的信息被破坏就可以到其他的中找到Super Block给当前破坏的Super Block进行拷贝,这样就极大的保证了分区的安全!
Boot Block
Boot block: 启动块!用于计算机开机时加载磁盘的分区情况,帮助计算机加载操作系统等
大小固定为1KB
Boot Block不仅仅是一个分区只有一个,而是整个硬盘中只有一个,放在整个硬盘的第一个分区头部
总结:
Boot block描述整体硬盘的分区情况的
super block是描述一个分区的
GDT是描述一个组的
inode Bitmap和inode Table是标记和存储一个组中的文件的属性的
datablocks和block Bitmap是存储和标记当前组中文件的内容的
文件系统整体是基于分区的,也就是不同的分区可以有不同的文件系统!
在每一个分区进行分组,然后写入文件系统的管理数据,叫做格式化!
再次理解目录
我们知道;文件 = 内容 + 属性,目录也是文件,他的属性很好理解,但是他的内容存的是文件,目录的内部是如何存文件的呢?
目录文件内部存储的是文件名和inode编号的映射关系!
介绍到这里也就明白了为什么同一目录下不能有同名的文件?原因是目录存储的是文件名和inode的编号,上面介绍了,他俩是K,V键值对的关系(K,V均唯一),得保证相互可以找到,所以文件名一旦相同就意味着可以破坏了文件名和inodede一对一的关系,这就会导致无法定位和操作文件!所以,
查找文件的顺序就是,文件名转换为inode编号进行查找!
目录的r权限的本质就是,是否允许然能给我们查看文件名与inode的映射关系!
目录的w权限的本质就是,在目录文件中写入文件名和inode的映射关系!
路径的逆向解析
我们知道访问一个文件前,这个文件必须是有目录的!因为目录中存的是文件名和对应的inode编号!而我们刚介绍了目录也是文件,他也有inode编号,目录是如何获取他的inode的呢?
其实这就涉及一个文件路径的逆向解析!什么意思呢?举个栗子:比如你要查找当前的目录dir中的内容,而你的这个目录是
/home/cp/oslearn/lesson15/dir当前目录是lesson15的内容,他的inode存在lesson15,而lesson15是oslearn的内容,他的inode存在与oslearn的,这样一直会找到根目录,因为根目录的inode是固定的,所以就会向下逐层找到了对应的inode,当前的dir目录的inode也就找到了!就可以查看了!这就是我们在Linux中定位文件,任何时候都要带路径的原因!
再次理解文件的增删查改
• 新建文件
文件 = 内容 + 属性, 而Linux中内容和属性是分开存储的,属性存在inode对象里,内容存在datablocks中
- 查找空闲inode:
- 文件系统首先查看super block以获取空闲inode的数量。
- 接着,通过inode Bitmap找到一个未被使用的inode编号。
- 创建inode对象:
- 使用找到的inode编号在inode表中创建一个新的inode对象。
- 初始化inode的元数据,例如设置文件类型为普通文件,设置初始大小为0,修改和访问时间等。
- 在inode Bitmap中将对应的位标记为已使用(1)。
- 分配数据块:
- 如果文件非空,系统需要为文件内容分配数据块。
- 通过block Bitmap找到空闲的数据块。
- 分配数据块,并在block Bitmap中将对应的位标记为已使用(1)。
- 将数据块的位置信息记录在inode中,即数据块与inode建立映射关系。
- 建立文件名和inode的映射:
- 在目录的inode中,目录的内容(即文件名和inode编号的映射)被存储在数据块中。
- 在父目录的数据块中添加一个新的条目,该条目将新文件的文件名与其inode编号关联起来。
- 更新super block:
- 更新super block中关于空闲inode和空闲数据块数量的信息。
• 删除文件
1.解除文件名和inode的映射关系
2.更新inode Bitmap和block Bitmap
根据inode编号找到inode Table中的inode对象,然后将对应的inode Bitmap置为0,在根据inode对象找到与数据块datablocks的对应关系,将block Bitmap中对应的数据块置为0
3.更新super block:
将super block中空闲的inode和数据块的数量更新
其实这里也看到了,删除并不是真正的删除,而是将属性和内容的标记置为0,空闲的inode和数据块的数量增加!所以这就是为什么你删除一个文件时很快,而拷贝一个文件时很慢,因为删除只是设置标记,而拷贝要实际的走创建的过程!
• 查找文件
查找文件就很简单了,根据文件名称查找对应的inode编号,然后获取到相关的inode将对象的内容即文件的属性!(简单理解)
• 修改文件
1. 文件名到inode的映射
- 查找inode编号:当修改一个文件时,文件系统首先会根据提供的文件名,在包含该文件的目录的inode中查找对应的文件名与inode编号的映射。
2. 验证inode的存在
- 检查inode Bitmap:找到inode编号后,文件系统会检查inode bitmap来确定该inode编号是否已被使用(即对应的inode对象是否存在)。确保你访问的inode是有效的。
3. 加载inode和数据块
- 读取inode信息:如果inode存在,文件系统会从inode table中读取该inode的详细信息,包括文件的元数据(如权限、大小、时间戳等)和数据块的位置。
- 加载数据块:根据inode中记录的数据块位置,文件系统会从磁盘上读取文件的数据块到内核的缓存(struct file)中,以便进行修改。
4. 修改文件内容
- 在缓存中修改:在内核的缓存中,你可以对文件的内容进行修改。这些修改是临时的,仅影响内存中的文件副本。
5. 更新inode和文件数据
- 修改inode元数据:如果文件的内容被修改(如大小变化),或者文件的属性被更改(如权限、时间戳),则相应的inode元数据也需要更新。
- 准备写回:修改完成后,内核会准备将这些更改写回到磁盘。这包括更新后的inode元数据和文件数据块。
6. 同步到磁盘
- 调用写回机制:当内核认为时机合适时(如缓存满了、文件被关闭、显式调用
fsync()等),它会将缓存中的更改写回到磁盘。 - 更新inode Bitmap和inode Table:如果inode的状态或属性发生了变化(如inode被删除),inode bitmap和inode table中的相应条目也需要更新。
- 写回数据块:最后,修改后的数据块会被写回到磁盘上的相应位置。
• 了解dentry
其实Linux内核并不会直接拿着inode去找文件的,而是提前将大量的路径进行了解析,并用数据结构给组织了起来!用struct dentry进行了描述,用链表进行了组织,在dentry对象中存在着直接指向文件的指针,目的是为了避免从头找,提高了文件访问效率,其实本质上是一种路径的缓存!
OK,好兄弟,本期内容就到这里,我们下期再见!
结束语:征服自己,就是征服世界!
