
阅读量:0
MangoDB是一个流行的分布式文档型数据库,它非常适合处理大量数据和实时分析场景。Navicat是一款强大的数据库管理工具,可以方便地操作MongoDB。下面是一些基本步骤来使用Navicat创建聚合管道(Aggregation Pipeline):
打开Navicat: 打开Navicat连接到你的MongoDB服务器。
选择数据库和集合: 点击左侧的“Server”然后选择相应的数据库,接着点击右侧的"Collections"来查看并选择你需要进行聚合的集合。
打开查询编辑器: 在顶部菜单栏,点击 “Database” -> “Run SQL” 或者右键选择 “Execute Query” 来进入查询编辑器。
创建聚合管道:
- 输入命令:在SQL编辑区域输入
db.collection.aggregate(),collection替换为你的集合名。 - 添加阶段(Stages)
- 输入命令:在SQL编辑区域输入
运行聚合: 输入完所有阶段后,点击下方的绿色三角形(运行按钮),或者在命令行输入
db.collection.aggregate(pipeline),其中pipeline是你设置好的数组形式的聚合管道。查看结果: 聚合完成后,结果会出现在下方的网格视图里,你可以查看生成的聚合输出。
聚合创建工具
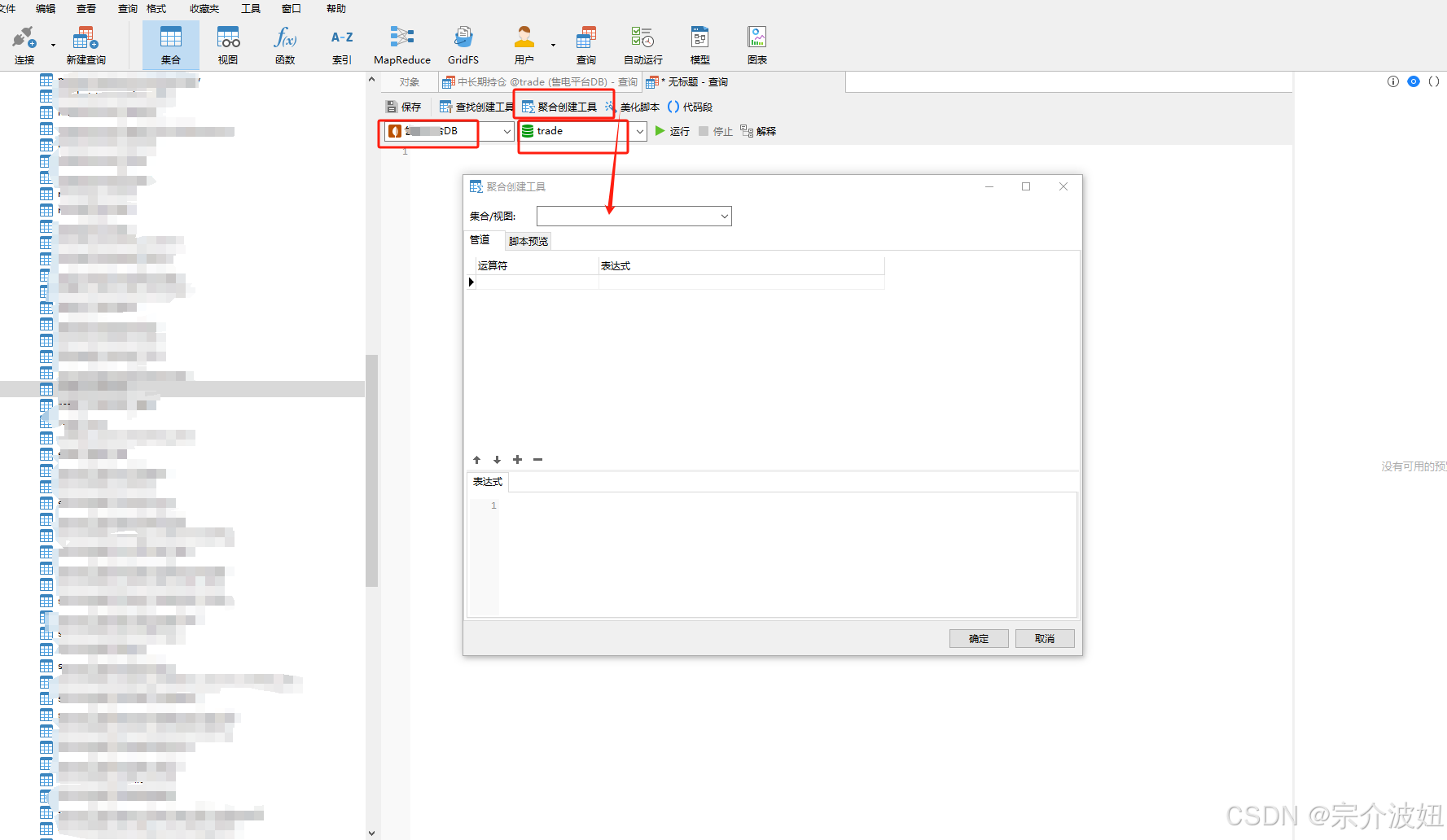 选择DB数据库,选择trade表,点击聚合创建工具 会弹出一个工具框
选择DB数据库,选择trade表,点击聚合创建工具 会弹出一个工具框工具框的介绍
1>点击脚本预览--会显示当前脚本情况,默认显示
db.getCollection("").aggtrgate([])
在次基础上根据选择的不同运算符,进行填充命令
2>集合/视图,这里选择对应查询的集合
3>点击"+"进行添加运算符
4>运算符的介绍
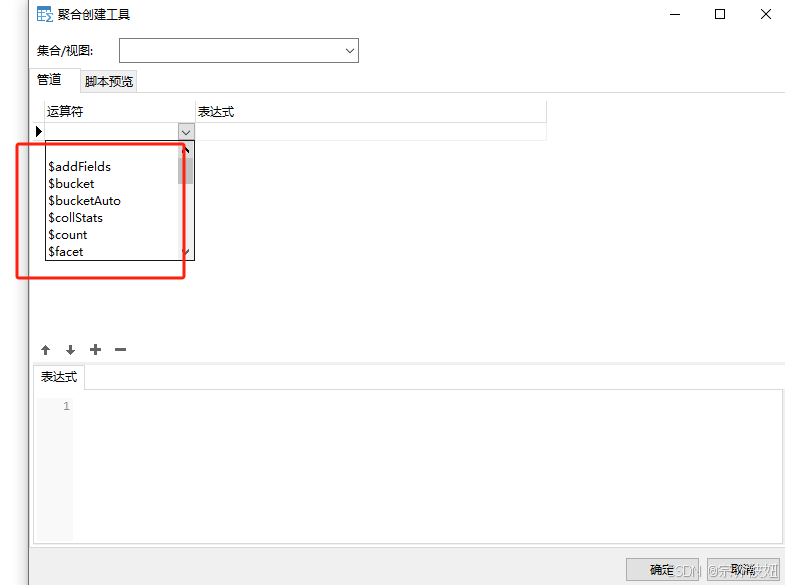
$match:用于过滤文档。例如,{ $match: { field: value } }。$group:按某个字段分组并计算汇总值。如{ $group: { _id: "$field", sum: { $sum: "$value" } } }。sort:对结果排序。例如{ $sort: { date: -1 } }。limit:限制返回的文档数量。如有需要添加{ $limit: 10 }。- $unwind: 对集合中的列有聚合的数据使用,提取Array中的数据使用 {$unwind:"$列名"}
- $project: 对集合中Array中的数据列表进行条件过滤或则命名 {$project:{
company: 1,
day: 1,
contractId: 1,
price:"$pointInfos.price",
dianliang: "$pointInfos.electricity",
time: {
$convert: {
input: {
$substr: [
"$pointInfos.time",
0,
2
]
},
to: "int"
}
}
}} 1代表全部,pointInfos代表Array中的数据列 - $convert:数值字符串转int time: {
$convert: {
input: {
$substr: [
"$pointInfos.time",
0,
2
]
},
to: "int"
}
}
