
阅读量:0
系列篇章💥
| No. | 文章 |
|---|---|
| 1 | 【GLM-4开发实战】Function Call进阶实战:外部函数调用回顾 |
| 2 | 【GLM-4开发实战】Function Call进阶实战:常见挑战之意图识别处理 |
| 3 | 【GLM-4开发实战】Function Call进阶实战:常见挑战之海量函数处理 |
| 4 | 【GLM-4开发实战】Function Call进阶实战:常见挑战之并发调用处理 |
目录
引言
在人工智能的快速发展中,Function Call作为智能系统的核心功能之一,其并发调用能力成为衡量系统性能的关键指标。然而,随着应用场景的复杂化,如何高效地处理函数的并发调用成为了一个技术挑战。本文将深入探讨这一问题,并提供有效的解决策略。
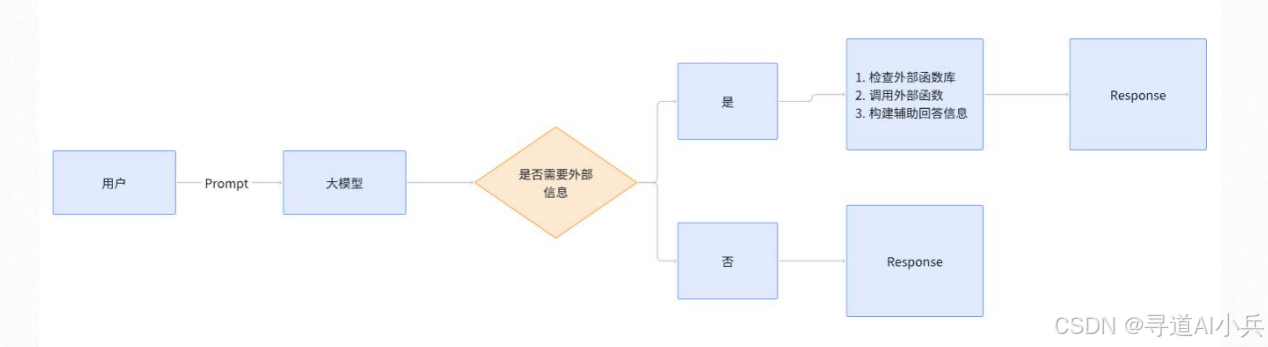
一、概述
函数并发调用涉及到两个主要场景:
1、串行调用:在某些情况下,一个Prompt需要按顺序依次调用多个外部函数。
2、并行调用:在其他情况下,一个Prompt可能需要同时调用多个外部函数以提高效率。
这两种调用方式各有优势和挑战,需要根据具体应用场景进行选择和优化。
二、串行调用的场景
1、测试样例
prompt = "请问1234567与7654321的和与积作差等于几?" # Agent message=[] message.append({"role": "user", "content": prompt + "解决这个问题要分几步?\ 记住只告诉我步骤,不要解决问题,也不要说额外的话\ 请按照'1. xxx;2. xxx;...;的格式列举\ 步骤与步骤之间使用半角分号;相隔,整个句子请用半角分号;结尾"}) response_step = client.chat.completions.create( model="glm-4", messages=message, temperature = 0.1 ) 2、查看调用结果
response_step 输出:
Completion(model='glm-4', created=1718216123, choices=[CompletionChoice(index=0, finish_reason='stop', message=CompletionMessage(content='1. 计算两个数的和: 将1234567与7654321相加; \n2. 计算两个数的积: 将1234567与7654321相乘; \n3. 计算和与积的差: 将步骤1得到的和减去步骤2得到的积; \n4. 得出最终结果: 得到步骤3计算出的差值。 \n\n整个解决问题过程分为4步。', role='assistant', tool_calls=None))], request_id='8741747907789403382', id='8741747907789403382', usage=CompletionUsage(prompt_tokens=88, completion_tokens=98, total_tokens=186)) 3、查看消息内容
print(response_step.choices[0].message.content) 输出:
1. 计算两个数的和: 将1234567与7654321相加; 2. 计算两个数的积: 将1234567与7654321相乘; 3. 计算和与积的差: 将步骤1得到的和减去步骤2得到的积; 4. 得出最终结果: 得到步骤3计算出的差值。 整个解决问题过程分为4步。 4、获取执行步骤
str_content=response_step.choices[0].message.content # 定义正则表达式模式 pattern = r'(.*?;)' # 使用re.findall提取所有匹配项 steps = re.findall(pattern, str_content) # 去除最后一个不完整的匹配项 steps = [step.strip() for step in steps if step.strip()] for step in steps: print(step) 输出:
1. 计算两个数的和: 将1234567与7654321相加; 2. 计算两个数的积: 将1234567与7654321相乘; 3. 计算和与积的差: 将步骤1得到的和减去步骤2得到的积; 5、分步调用测试
step_answer = "" # 步骤之间相互独立或者有联系,都可以用 for step in steps: message = [{"role":"assistant","content":prompt + "正在分步骤解决问题。已知条件是" + step_answer}] message.append({"role":"user","content":"当前步骤是" + step}) response_per_step = client.chat.completions.create( model="glm-4", messages=message, tools = basic_math_tools, tool_choice = True, temperature = 0.1 ) try: function_calls = response_per_step.choices[0].message.tool_calls[0] function_to_call = available_math_functions[function_calls.function.name] function_args = json.loads(function_calls.function.arguments) function_response = function_to_call(**function_args) except: function_response = response_per_step.choices[0].message.content step_answer = step + "答案是" + str(function_response) print(step_answer) #经历完整的步骤、获得答案之后再返回 message = [] message.append({ "role": "assistant", "content": "你使用了tools工具,最终获得的答案是" + str(function_response), }) message.append({"role": "user", "content": prompt + "请仅仅回答答案的数字,不要包括其他描述"}) response_a = client.chat.completions.create( model="glm-4", # 填写需要调用的模型名称 messages=message ) print(response_a.choices[0].message.content) 测试结果:
1. 计算两个数的和: 将1234567与7654321相加;答案是8888888 2. 计算两个数的积: 将1234567与7654321相乘;答案是9449772114007 3. 计算和与积的差: 将步骤1得到的和减去步骤2得到的积;答案是-6419754 -6419754 三、并行调用的场景
1、测试样例
prompts = """添加如下用户信息: 1. {name:"zhangsan",age:33} 2. {name:"lisi",age=44} 3. {name:"wangwu",age=55} 4. {name:"zhaoliu",age=66} """ 2、LangChain实现的方式
messages1 = [SystemMessage(content="你是一位乐于助人的智能小助手"), HumanMessage(content="请帮我介绍一下什么是机器学习"),] messages2 = [SystemMessage(content="你是一位乐于助人的智能小助手"), HumanMessage(content="请帮我介绍一下什么是AIGC"),] messages3 = [SystemMessage(content="你是一位乐于助人的智能小助手"), HumanMessage(content="请帮我介绍一下什么是大模型技术"),] 1)批量调用
reponse = chat.batch([messages1, messages2, messages3,]) reponse 2)也可以使用异步调用的方式
reponse1 = await chat.ainvoke(messages1) reponse2 = await chat.ainvoke(messages2) reponse3 = await chat.ainvoke(messages3) reponse4 = await chat.ainvoke(messages4) 3、GLM batch调用
1)创建 Batch 文件
Batch 文件的格式应为 .jsonl,其中每个请求占据一行(JSON 对象)。每一行包含 API 单个请求的详细信息。每个请求的定义如下:
{ "custom_id": "request-1", #每个请求必须包含custom_id且是唯一的,用来将结果和输入进行匹配 "method": "POST", "url": "/v4/chat/completions", "body": { "model": "glm-4", #每个batch文件只能包含对单个模型的请求,支持 glm-4、glm-3-turbo. "messages": [ {"role": "system","content": "你是一个意图分类器."}, {"role": "user", "content": """ # 任务:对以下用户评论进行情感分类和特定问题标签标注,只输出结果, # 评论:review = "订单处理速度太慢,等了很久才发货。" # 输出格式: { "分类标签": " ", "特定问题标注": " " } """ } ], "temperature": 0.1 } } 2)批量文件样例
构建的 .jsonl 文件如下,本示例中包含 10 个请求,单个文件最多支持 50000 个请求且大小不超过 100M:
{"custom_id": "request-1", "method": "POST", "url": "/v4/chat/completions", "body": {"model": "glm-4", "messages": [{"role": "system", "content": "你是一个意图分类器."},{"role": "user", "content": "#任务:对以下用户评论进行情感分类和特定问题标签标注,只输出结果,# 评论:review = \"订单处理速度太慢,等了很久才发货。\"# 输出格式:'''{\"分类标签\": \" \", \"特定问题标注\": \" \" } '''"}]}} {"custom_id": "request-2", "method": "POST", "url": "/v4/chat/completions", "body": {"model": "glm-4", "messages": [{"role": "system", "content": "你是一个意图分类器."},{"role": "user", "content": "#任务:对以下用户评论进行情感分类和特定问题标签标注,只输出结果,# 评论:review = \",商品有点小瑕疵,不过客服处理得很快,总体满意。\",# 输出格式:'''{\",分类标签\": \" \", \"特定问题标注\": \" \" } '''"}]}} {"custom_id": "request-3", "method": "POST", "url": "/v4/chat/completions", "body": {"model": "glm-4", "messages": [{"role": "system", "content": "你是一个意图分类器."},{"role": "user", "content": "#任务:对以下用户评论进行情感分类和特定问题标签标注,只输出结果,# 评论:review = \"这款产品性价比很高,非常满意。\"# 输出格式:'''{\"分类标签\": \" \", \"特定问题标注\": \" \" } '''"}]}} {"custom_id": "request-4", "method": "POST", "url": "/v4/chat/completions", "body": {"model": "glm-4", "messages": [{"role": "system", "content": "你是一个意图分类器."},{"role": "user", "content": "#任务:对以下用户评论进行情感分类和特定问题标签标注,只输出结果,# 评论:review = \"说明书写得不清楚,看了半天也不知道怎么用。\"# 输出格式:'''{\"分类标签\": \" \", \"特定问题标注\": \" \" } '''"}]}} {"custom_id": "request-5", "method": "POST", "url": "/v4/chat/completions", "body": {"model": "glm-4", "messages": [{"role": "system", "content": "你是一个意图分类器."},{"role": "user", "content": "#任务:对以下用户评论进行情感分类和特定问题标签标注,只输出结果,# 评论:review = \"总体还不错,但价格偏高,不太划算。\"# 输出格式:'''{\"分类标签\": \" \", \"特定问题标注\": \" \" } '''"}]}} {"custom_id": "request-6", "method": "POST", "url": "/v4/chat/completions", "body": {"model": "glm-4", "messages": [{"role": "system", "content": "你是一个意图分类器."},{"role": "user", "content": "#任务:对以下用户评论进行情感分类和特定问题标签标注,只输出结果,# 评论:review = \"物流速度很慢,等了两个星期才收到货 \"# 输出格式:'''{\"分类标签\": \" \", \"特定问题标注\": \" \" } '''"}]}} {"custom_id": "request-7", "method": "POST", "url": "/v4/chat/completions", "body": {"model": "glm-4", "messages": [{"role": "system", "content": "你是一个意图分类器."},{"role": "user", "content": "#任务:对以下用户评论进行情感分类和特定问题标签标注,只输出结果,# 评论:review = \"收到的产品跟描述不符,有些失望。\"# 输出格式:'''{\"分类标签\": \" \", \"特定问题标注\": \" \" } '''"}]}} {"custom_id": "request-8", "method": "POST", "url": "/v4/chat/completions", "body": {"model": "glm-4", "messages": [{"role": "system", "content": "你是一个意图分类器."},{"role": "user", "content": "#任务:对以下用户评论进行情感分类和特定问题标签标注,只输出结果,# 评论:review = \"客服很耐心,解决问题很快,感谢!\"# 输出格式:'''{\"分类标签\": \" \", \"特定问题标注\": \" \" } '''"}]}} {"custom_id": "request-9", "method": "POST", "url": "/v4/chat/completions", "body": {"model": "glm-4", "messages": [{"role": "system", "content": "你是一个意图分类器."},{"role": "user", "content": "#任务:对以下用户评论进行情感分类和特定问题标签标注,只输出结果,# 评论:review = \"包装太简单,商品在运输过程中被压坏了。\"# 输出格式:'''{\"分类标签\": \" \", \"特定问题标注\": \" \" } '''"}]}} {"custom_id": "request-10", "method": "POST", "url": "/v4/chat/completions", "body": {"model": "glm-4", "messages": [{"role": "system", "content": "你是一个意图分类器."},{"role": "user", "content": "#任务:对以下用户评论进行情感分类和特定问题标签标注,只输出结果,# 评论:review = \"产品质量不错,但是颜色和图片上的不一样\"# 输出格式:'''{\"分类标签\": \" \", \"特定问题标注\": \" \" } '''"}]}} 3)上传文件
通过文件管理上传 Batch 文件并获取文件 ID。
from zhipuai import ZhipuAI client = ZhipuAI(api_key="") # 请填写您自己的APIKey result = client.files.create( file=open("product_reviews.jsonl", "rb"), purpose="batch" ) print(result.id) 创建 Batch 任务
成功上传输入文件后,您可以使Batch 文件的 id 创建 Batch 任务。在本示例中,我们假设文件 ID 为 file_123。
#创建batch任务 from zhipuai import ZhipuAI client = ZhipuAI() # 填写您自己的APIKey create = client.batches.create( input_file_id="file_123", endpoint="/v4/chat/completions", completion_window="24h", #完成时间只支持 24 小时 metadata={ "description": "Sentiment classification" } ) print(create) 检查 Batch 状态
Batch 任务将在 24 小时内处理完成,状态为 “completed” 表示任务已完成。
#打印batch流程 batch_job = client.batches.retrieve("batch_id") print(batch_job) 4)下载 Batch 结果
Batch 任务完成后,您可以使用 Batch 对象中的output_file_id 字段下载结果,并将其保存到本地。
注意:系统只保留您的数据30天。请及时下载和备份您的数据,过期后文件将自动删除,无法恢复。
from zhipuai import ZhipuAI client = ZhipuAI() # 填写您自己的APIKey # client.files.content返回 _legacy_response.HttpxBinaryResponseContent实例 content = client.files.content("file-456") # 使用write_to_file方法把返回结果写入文件 content.write_to_file("write_to_file_batchoutput.jsonl") 其他具体使用请查看:https://open.bigmodel.cn/dev/howuse/batchapi
结语
本文我们探索分析了Function Call中的函数并发调用问题,并提供了一系列的解决方案。我们希望这些内容能够帮助大家更好地应对这一挑战,推动人工智能技术的进一步发展。

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:我是寻道AI小兵,资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索。
📖 技术交流:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,加入技术交流群,开启编程探索之旅。
💘精心准备📚500本编程经典书籍、💎AI专业教程,以及高效AI工具。等你加入,与我们一同成长,共铸辉煌未来。
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!
