阅读量:0
目录
实现 master/master 的 Keepalived 双主架构
一、集群相关概念简述
HA是High Available缩写,是双机集群系统简称,指高可用性集群,是保证业务连续性的有效解决方案,一般有两个或两个以上的节点,且分为活动节点及备用节点。
1、集群的分类
- LB:负载均衡集群
- lvs负载均衡
- nginx反向代理
- HAProxy
- HA:高可用集群
- heartbeat
- keepalived
- redhat5 : cman + rgmanager , conga(WebGUI) --> RHCS(Cluster Suite)集群套件
- redhat6 : cman + rgmanager , corosync + pacemaker
- redhat7 : corosync + pacemaker
- 数据库,redis
- HPC:高性能集群
- SPoF: Single Point of Failure,解决单点故障
2.系统可用性的计算公式
SLA:Service-Level Agreement 服务等级协议(提供服务的企业与客户之间就服务的品质、水准、性能等方面所达成的双方共同认可的协议或契约)A=MTBF/(MTBF+MTTR)
- A:高可用性,指标:95%, 99%, 99.5%, ...., 99.999%,99.9999%等
- MTBF:平均无故障时间
- MTTR:平均修复时间
3.系统故障
硬件故障:设计缺陷、wear out(损耗)、非人为不可抗拒因素 软件故障:设计缺陷 bug
4.实现高可用
提升系统高用性的解决方案:降低MTTR- Mean Time To Repair(平均故障时间) 解决方案:建立冗余机制active/passive 主/备 active/active 双主 active --> HEARTBEAT --> passive active <--> HEARTBEAT <--> active
二.keepalived
1.Keepalived介绍
Keepalived是Linux下一个轻量级别的高可用解决方案。高可用(High Avalilability,HA),其实两种不同的含义:广义来讲,是指整个系统的高可用行,狭义的来讲就是之主机的冗余和接管,
它与HeartBeat RoseHA 实现相同类似的功能,都可以实现服务或者网络的高可用,但是又有差别,HeartBeat是一个专业的、功能完善的高可用软件,它提供了HA 软件所需的基本功能,比如:心跳检测、资源接管,检测集群中的服务,在集群节点转移共享IP地址的所有者等等。HeartBeat功能强大,但是部署和使用相对比较麻烦,
与HeartBeat相比,Keepalived主要是通过虚拟路由冗余来实现高可用功能,虽然它没有HeartBeat功能强大,但是Keepalived部署和使用非常的简单,所有配置只需要一个配置文件即可以完成,
Keepalived起初是为LVS设计的,专门用来监控集群系统中各个服务节点的状态,它根据TCP/IP参考模型的第三、第四层、第五层交换机制检测每个服务节点的状态,如果某个服务器节点出现异常,或者工作出现故障,Keepalived将检测到,并将出现的故障的服务器节点从集群系统中剔除,这些工作全部是自动完成的,不需要人工干涉,需要人工完成的只是修复出现故障的服务节点。
后来Keepalived又加入了VRRP的功能,VRRP(Vritrual Router Redundancy Protocol,虚拟路由冗余协议)出现的目的是解决静态路由出现的单点故障问题,通过VRRP可以实现网络不间断稳定运行,因此Keepalvied 一方面具有服务器状态检测和故障隔离功能,另外一方面也有HA cluster功能.
2.keepalived相关概念
- vrrp协议:Virtual Redundant Routing Protocol 虚拟冗余路由协议
- Virtual Router:虚拟路由器
- VRID(0-255):虚拟路由器标识
- master:主设备,当前工作的设备
- backup:备用设备
- priority:优先级,优先级越大优先工作,具体情况示工作方式决定
- VIP:虚拟IP地址,正真向客户服务的IP地址
- VMAC:虚拟MAC地址(00-00-5e-00-01-VRID)
- 抢占式:如果有优先级高的节点上线,则将此节点转为master
- 非抢占式:即使有优先级高的节点上线,在当前master工作无故障的情况运行抢占;等到此master故障后重新按优先级选举master
- 心跳:master将自己的心跳信息通知集群内的所有主机,证明自己正常工作
- 安全认证机制:
- 无认证:任何主机都可成为集群内主机,强烈不推荐
- 简单的字符认证:使用简单的密码进行认证
- AH认证
- sync group:同步组,VIP和DIP配置到同一物理服务器上
- MULTICAST:组播,多播
- Failover:master故障,故障切换,故障转移
- Failback:故障节点重新上线,故障切回
3.VRRP协议与工作原理
在现实的网络环境中。主机之间的通信都是通过配置静态路由或者(默认网关)来完成的,而主机之间的路由器一旦发生故障,通信就会失效,因此这种通信模式当中,路由器就成了一个单点瓶颈,为了解决这个问题,就引入了VRRP协议。
VRRP可以将两台或者多台物理路由器设备虚拟成一个虚拟路由,这个虚拟路由器通过虚拟IP(一个或者多个)对外提供服务,而在虚拟路由器内部十多个物理路由器协同工作,同一时间只有一台物理路由器对外提供服务,这台物理路由设备被成为:主路由器(Master角色),一般情况下Master是由选举算法产生,它拥有对外服务的虚拟IP,提供各种网络功能,如:ARP请求,ICMP 数据转发等,而且其它的物理路由器不拥有对外的虚拟IP,也不提供对外网络功能,仅仅接收MASTER的VRRP状态通告信息,这些路由器被统称为“BACKUP的角色”,当主路由器失败时,处于BACKUP角色的备份路由器将重新进行选举,产生一个新的主路由器进入MASTER角色,继续提供对外服务,整个切换对用户来说是完全透明的。
每个虚拟路由器都有一个唯一的标识号,称为VRID,一个VRID与一组IP地址构成一个虚拟路由器,在VRRP协议中,所有的报文都是通过IP多播方式发送的,而在一个虚拟路由器中,只有处于Master角色的路由器会一直发送VRRP数据包,处于BACKUP角色的路由器只会接受Master角色发送过来的报文信息,用来监控Master运行状态,一一般不会发生BACKUP抢占的情况,除非它的优先级更高,而当MASTER不可用时,BACKUP也就无法收到Master发过来的信息,于是就认定Master出现故障,接着多台BAKCUP就会进行选举,优先级最高的BACKUP将称为新的MASTER,这种选举角色切换非常之快,因而保证了服务的持续可用性。
VRRP相关术语
VRRP路由器:执行VRRP协议一个或多个实例的路由器
虚拟路由器:由一个Master路由器和多个Backup路由器组成。当中,不管Master路由器还是Backup路由器都是一台VRRP路由器,下行设备将虚拟路由器当做默认网关。
VRID:虚拟路由器标识,在同一个VRRP组内的路由器必须有相同的VRID,事实上VRID就相当于一个公司的名称,每一个员工介绍自己时都要包括公司名称,表明自己是公司的一员,相同的道理,VRID表明了这个路由器属于这个VRRP组。
Master路由器:虚拟路由器中承担流量转发任务的路由器
Backup路由器:当一个虚拟路由器中的Master路由器出现问题时,可以取代Master路由器工作的路由器
虚拟IP地址:虚拟路由器的IP地址,一个虚拟路由器能够拥有一个或多个虚拟IP地址。
IP地址拥有者:接口IP和虚拟路由器IP地址同样的路由器就叫做IP地址拥有者。
主IP地址:从物理接口设置的IP地址中选择,一个选择规则是总是选用第一个IP地址,VRRP通告报文总是用主IP地址作为该报文IP包头的源IP。
虚拟MAC地址:组成方式是00-00-5E-00-01-{VRID},前三个字节00-00-5E是IANA组织分配的,接下来的两个字节00-01是为VRRP协议指定的,最后的VRID是虚拟路由器标识,取值范围[1,255]
VRRP相关技术
通告:心跳,优先级等;周期性 工作方式:抢占式,非抢占式 安全认证: 无认证 简单字符认证:预共享密钥 MD5 工作模式: 主/备:单虚拟路由器 主/主:主/备(虚拟路由器1),备/主(虚拟路由器2)
4.keepalived功能
vrrp 协议的软件实现,原生设计目的为了高可用 ipvs服务 官网:http://keepalived.org/ 功能: 基于vrrp协议完成地址流动 为vip地址所在的节点生成ipvs规则(在配置文件中预先定义) 为ipvs集群的各RS做健康状态检测 基于脚本调用接口完成脚本中定义的功能,进而影响集群事务,以此支持nginx、haproxy等服务
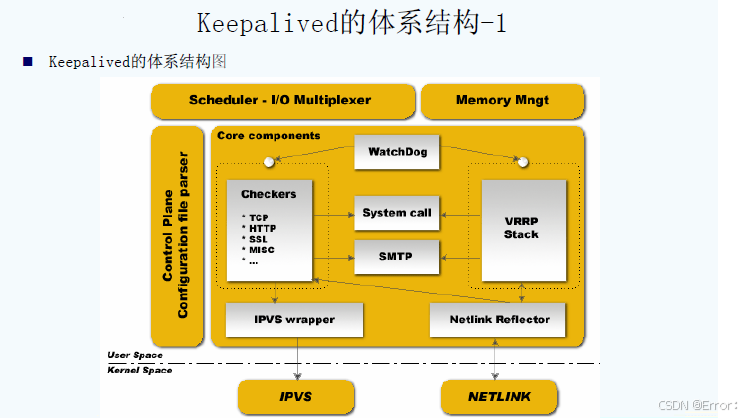
5.Keepalived体系结构
Keepalived起初是为LVS设计的,由于Keeplalived可以实现对集群节点的状态检测,而IPVS可以实现负载均衡功能,因此,Keepalived借助于第三方模块IPVS就可以很方便地搭建一套负载均衡系统,在这里有个误区,由于Keepalived可以和IPVS一起很好的工作,所以会有人以为Keepalived就是一个负载均衡软件,这种理解是错误,
在Keepalived当中IPVS模块是可配置的,如果需要负载均衡功能,可以在编译Keepalived时开打负载均衡功能,也可以通过编译参数关闭。
NetLINK模块主要用于实现一些高级路由框架和一些相关参数的网络功能,完成用户空间层Netlink Reflector模块发来的各种网络请求。
这个图我们可以看到用户空间层(user space),是建立在内核空间层之上的(kernel sapce),
用户空间层,主要有4个部分:
Scheduler I/O Multiplexer 是一个I/O复用分发调度器,它负载安排Keepalived所有内部的任务请求,
Memory Mngt 是一个内存管理机制,这个框架提供了访问内存的一些通用方法
Control Plane 是keepalived的控制版面,可以实现对配置文件编译和解析
Core componets 这部分主要保护了下面5个部分
1.Watchdog:是计算机可靠领域中极为简单又非常有效的检测工具,Keepalived正是通过它监控Checkers和VRRP进程的。
2.Checkers: 这是Keepalived最基础的功能,也是最主要的功能,可以实现对服务器运行状态检测和故障隔离。
3.VRRP Stack: 这时keepalived后来引用VRRP功能,可以实现HA集群中失败切换功能。
4.IPVS wrapper: 这个是IPVS功能的一个实现,IPVS warrper模块将可以设置好的IPVS规则发送的内核空间并且提供给IPVS模块,最终实现IPVS模块的负载功能。
5.Netlink Reflector:用来实现高可用集群Failover时虚拟IP(VIP)的设置和切换 ,
Netlink Reflector的所有请求最后都发送到内核空间层的NETLINK 模块来完成。
6.keepalived环境准备
要求:各节点时间必须同步:ntp,chrony, 关闭防火墙和selinux
7.keepalived相关配置文件
软件包名:keepalived 主程序文件:/usr/sbin/keepalived 主配置文件:/etc/keepalived/keepalived.conf 配置文件示例:/usr/share/doc/keepalived/ Unit File:/lib/systemd/system/keepalived.service Unit File的环境配置文件:/etc/sysconfig/keepalived安装软件包
# yum install keepalived 配置文件参数详解
全局配置
! Configuration File for keepalived global_defs { notification_email { 594233887@qq.com #keepalived 发生故障切换时邮件发送的目标邮箱,可以按行区分写多个 timiniglee-zln@163.com } notification_email_from keepalived@KA1.timinglee.org #发邮件的地址 smtp_server 127.0.0.1 #邮件服务器地址 smtp_connect_timeout 30 #邮件服务器连接timeout router_id KA1.timinglee.org #每个keepalived主机唯一标识 #建议使用当前主机名,但多节点重名不影响 vrrp_skip_check_adv_addr #对所有通告报文都检查,会比较消耗性能 #启用此配置后,如果收到的通告报文和上一个报文是同一 #个路由器,则跳过检查,默认值为全检查 vrrp_strict #严格遵循vrrp协议 #启用此项后以下状况将无法启动服务: #1.无VIP地址 #2.配置了单播邻居 #3.在VRRP版本2中有IPv6地址 #建议不加此项配置 vrrp_garp_interval 0 #报文发送延迟,0表示不延迟 vrrp_gna_interval 0 #消息发送延迟 vrrp_mcast_group4 224.0.0.18 #指定组播IP地址范围: }配置虚拟路由器
vrrp_instance VI_1 { state MASTER interface eth0 #绑定为当前虚拟路由器使用的物理接口,如:eth0,可以和VIP不在一个网卡 virtual_router_id 51 #每个虚拟路由器惟一标识,范围:0-255,每个虚拟路由器此值必须唯一 #否则服务无法启动 #同属一个虚拟路由器的多个keepalived节点必须相同 #务必要确认在同一网络中此值必须唯一 priority 100 #当前物理节点在此虚拟路由器的优先级,范围:1-254 #值越大优先级越高,每个keepalived主机节点此值不同 advert_int 1 #vrrp通告的时间间隔,默认1s authentication { #认证机制 auth_type AH|PASS #AH为IPSEC认证(不推荐),PASS为简单密码(建议使用) uth_pass 1111 #预共享密钥,仅前8位有效 #同一个虚拟路由器的多个keepalived节点必须一样 } virtual_ipaddress { #虚拟IP,生产环境可能指定上百个IP地址 <IPADDR>/<MASK> brd <IPADDR> dev <STRING> scope <SCOPE> label <LABEL> 172.25.254.100 #指定VIP,不指定网卡,默认为eth0,注意:不指定/prefix,默认32 172.25.254.101/24 dev eth1 172.25.254.102/24 dev eth2 label eth2:1 } }keepalived虚拟路由管理
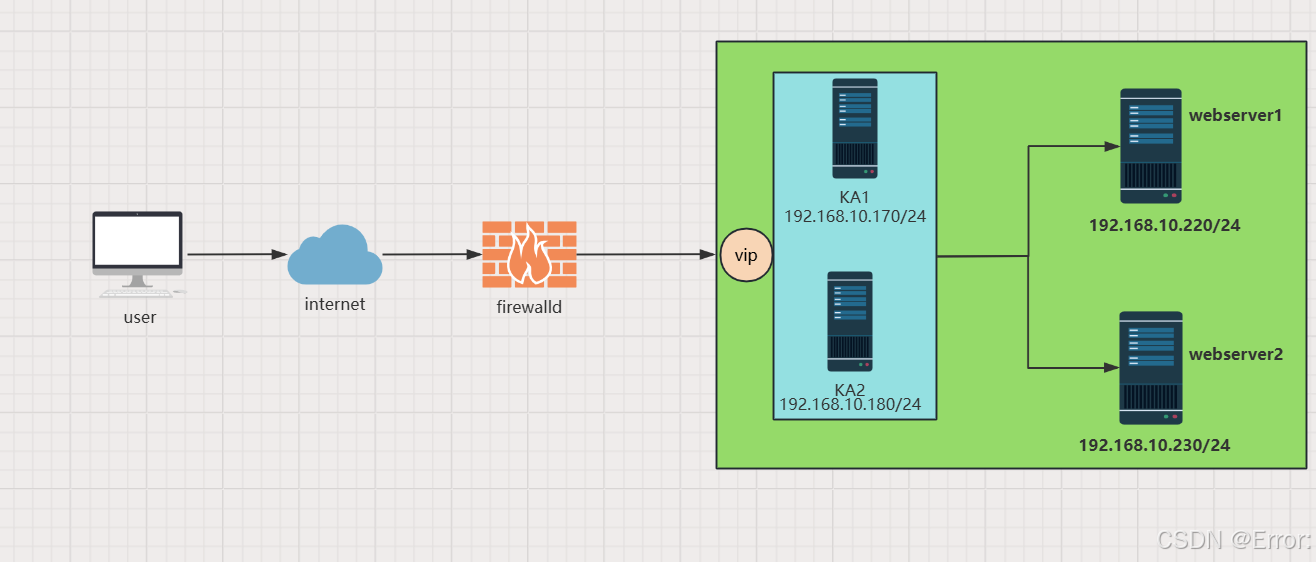
实验环境
| 设备 | 角色 | IP |
| ka1 | keepalived1 | 192.168.10.170/24 |
| ka2 | keepalived2 | 192.168.19.180/24 |
| webserver1 | real server | 192.168.10.220/24 |
| webserver2 | real server | 192.168.10.230/24 |
注:vip设置为192.168.10.240/24
四台主机全部关闭防火墙和selinux
webserver1,webserver2上安装web服务,后面的测试可以更加清晰的看出结果
[root@webserver1 ~]# yum install httpd -y [root@webserver1 ~]# echo webserver1 - 192.168.10.220 > /var/www/html/index.html [root@webserver1 ~]# systemctl restart httpd.service [root@webserver1 ~]# curl 192.168.10.220 webserver1 - 192.168.10.220 [root@webserver2 ~]# yum install httpd -y [root@webserver2 ~]# echo webserver2 - 192.168.10.230 > /var/www/html/index.html [root@webserver2 ~]# systemctl restart httpd.service [root@webserver2 ~]# curl 192.168.10.230 webserver2 - 192.168.10.230 ka1,ka2上安装keepalived软件包
[root@ka1 ~]# yum install keepalived -y [root@ka2 ~]# yum install keepalived -y在ka1上进行配置
[root@ka1 ~]# vim /etc/keepalived/keepalived.conf # 全局设定 global_defs { notification_email { 2948250195@qq.com # 发送邮件通知给谁 } notification_email_from keep@li.org #发送的邮件从哪来 smtp_server 127.0.0.1 # 邮件服务器ip smtp_connect_timeout 30 # 连接邮件服务器的超时时间 router_id ka1 # 虚拟路由的id vrrp_skip_check_adv_addr # 同一来源的只检测一次 # vrrp_strict # 强制使用vrrp协议 vrrp_garp_interval 0 vrrp_gna_interval 0 vrrp_mcast_group4 224.0.0.18 # 接收通告数据的IP地址(组播地址) } # 虚拟路由器配置 vrrp_instance VI_1 { state MASTER # 主设备 interface ens33 # vip使用的真实设备是谁 virtual_router_id 100 # 虚拟路由id(唯一的) priority 100 # 优先级 advert_int 1 authentication { auth_type PASS # 发通告带的信息 auth_pass 1111 } virtual_ipaddress { # vip id # 设定网卡子接口 192.168.10.240/24 dev ens33 label ens33:0 } } [root@ka1 ~]# systemctl restart keepalived.service # 重启服务[root@ka1 ~]# ifconfig ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.10.170 netmask 255.255.255.0 broadcast 192.168.10.255 inet6 fe80::20c:29ff:feea:fe5a prefixlen 64 scopeid 0x20<link> ether 00:0c:29:ea:fe:5a txqueuelen 1000 (Ethernet) RX packets 88607 bytes 6246698 (5.9 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 65079 bytes 4618871 (4.4 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 ens33:0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.10.240 netmask 255.255.255.0 broadcast 0.0.0.0 ether 00:0c:29:ea:fe:5a txqueuelen 1000 (Ethernet) # vip 为 192.168.10.240 ka2和ka1配置相同,所以我们可以使用scp,进行复制
[root@ka1 ~]# scp /etc/keepalived/keepalived.conf root@192.168.10.180:/etc/keepalived/keepalived.conf The authenticity of host '192.168.10.180 (192.168.10.180)' can't be established. ECDSA key fingerprint is SHA256:Yrid63PgwDQh7wiaQmCGsLuxK3Cht8v/wekHTAza/XI. ECDSA key fingerprint is MD5:d7:be:70:41:82:ff:81:40:5b:a7:40:10:d1:0c:ca:bf. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added '192.168.10.180' (ECDSA) to the list of known hosts. root@192.168.10.180's password: keepalived.conf 100% 4143 4.5MB/s 00:00 唯一要变的就是我们将ka1当作主设备,ka2当作从,使用需要改两个配置
[root@ka1 ~]# vim /etc/keepalived/keepalived.conf vrrp_instance VI_1 { state BACKUP # 从设备 interface ens33 # vip使用的真实设备是谁 virtual_router_id 100 # 虚拟路由id(唯一的) priority 80 # 优先级改为80,两个设备优先级不一样 advert_int 1 authentication { auth_type PASS # 发通告带的信息 auth_pass 1111 } virtual_ipaddress { # vip id # 设定网卡子接口 192.168.10.240/24 dev ens33 label ens33:0 } } [root@ka2 ~]# systemctl restart keepalived.service 测试:
[root@ka1 ~]# tcpdump -i ens33 -nn host 224.0.0.18 [root@ka1 ~]# tcpdump -i ens33 -nn host 224.0.0.18 tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes 19:06:36.826789 IP 192.168.10.170 > 224.0.0.18: VRRPv2, Advertisement, vrid 100, prio 100, authtype simple, intvl 1s, length 20 19:06:37.828337 IP 192.168.10.170 > 224.0.0.18: VRRPv2, Advertisement, vrid 100, prio 100, authtype simple, intvl 1s, length 20 19:06:38.829688 IP 192.168.10.170 > 224.0.0.18: VRRPv2, Advertisement, vrid 100, prio 100, authtype simple, intvl 1s, length 20 19:06:39.831263 IP 192.168.10.170 > 224.0.0.18: VRRPv2, Advertisement, vrid 100, prio 100, authtype simple, intvl 1s, length 20 19:06:40.832678 IP 192.168.10.170 > 224.0.0.18: VRRPv2, Advertisement, vrid 100, prio 100, authtype simple, intvl 1s, length 20 19:06:41.833834 IP 192.168.10.170 > 224.0.0.18: VRRPv2, Advertisement, vrid 100, prio 100, authtype simple, intvl 1s, length 20 # 使用tcpdump进行抓包 # -i 就是ens33接收到底数据 # -nn 表示不做解析 # host指定观察的那个ip # 224.0.0.18 组播地址ka1的优先级高于ka2所以正常情况看不到ka2的数据。若此时ka1发生故障,ka2则会迅速补上,此时在ka1上的vip也会跑到ka2上
[root@ka1 ~]# systemctl stop keepalived.service [root@ka1 ~]# tcpdump -i ens33 -nn host 224.0.0.18 tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes 19:09:39.386202 IP 192.168.10.180 > 224.0.0.18: VRRPv2, Advertisement, vrid 100, prio 80, authtype simple, intvl 1s, length 20 19:09:40.387629 IP 192.168.10.180 > 224.0.0.18: VRRPv2, Advertisement, vrid 100, prio 80, authtype simple, intvl 1s, length 20 19:09:41.388011 IP 192.168.10.180 > 224.0.0.18: VRRPv2, Advertisement, vrid 100, prio 80, authtype simple, intvl 1s, length 20 19:09:42.389522 IP 192.168.10.180 > 224.0.0.18: VRRPv2, Advertisement, vrid 100, prio 80, authtype simple, intvl 1s, length 20 19:09:43.390689 IP 192.168.10.180 > 224.0.0.18: VRRPv2, Advertisement, vrid 100, prio 80, authtype simple, intvl 1s, length 20 19:09:44.391255 IP 192.168.10.180 > 224.0.0.18: VRRPv2, Advertisement, vrid 100, prio 80, authtype simple, intvl 1s, length 20 [root@ka2 ~]# ifconfig ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.10.180 netmask 255.255.255.0 broadcast 192.168.10.255 inet6 fe80::20c:29ff:fe2c:7bd prefixlen 64 scopeid 0x20<link> ether 00:0c:29:2c:07:bd txqueuelen 1000 (Ethernet) RX packets 119533 bytes 8259027 (7.8 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 39657 bytes 3009635 (2.8 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 ens33:0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.10.240 netmask 255.255.255.0 broadcast 0.0.0.0 ether 00:0c:29:2c:07:bd txqueuelen 1000 (Ethernet) 因为默认是抢占模式,当ka1好了之后,vip则会跑到ka1上,流量也会回到ka1上
[root@ka1 ~]# systemctl start keepalived.service [root@ka1 ~]# ifconfig ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.10.170 netmask 255.255.255.0 broadcast 192.168.10.255 inet6 fe80::20c:29ff:feea:fe5a prefixlen 64 scopeid 0x20<link> ether 00:0c:29:ea:fe:5a txqueuelen 1000 (Ethernet) RX packets 92906 bytes 6566009 (6.2 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 67173 bytes 4781344 (4.5 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 ens33:0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.10.240 netmask 255.255.255.0 broadcast 0.0.0.0 ether 00:0c:29:ea:fe:5a txqueuelen 1000 (Ethernet) [root@ka1 ~]# tcpdump -i ens33 -nn host 224.0.0.18 tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes 19:13:06.604998 IP 192.168.10.170 > 224.0.0.18: VRRPv2, Advertisement, vrid 100, prio 100, authtype simple, intvl 1s, length 20 19:13:07.605229 IP 192.168.10.170 > 224.0.0.18: VRRPv2, Advertisement, vrid 100, prio 100, authtype simple, intvl 1s, length 20 19:13:08.605816 IP 192.168.10.170 > 224.0.0.18: VRRPv2, Advertisement, vrid 100, prio 100, authtype simple, intvl 1s, length 20 19:13:09.606386 IP 192.168.10.170 > 224.0.0.18: VRRPv2, Advertisement, vrid 100, prio 100, authtype simple, intvl 1s, length 20 keepalived虚拟路由的通讯设定
此时ka1,ka2是ping不通vip的,因为防止被攻击,所有的数据流量打过来后可能会有恶意攻击,我们最终的数据流量是要转到real server上的,所以他默认会把你的vip访问功能给🈲掉
[root@ka1 ~]# ping 192.168.10.240 PING 192.168.10.240 (192.168.10.240) 56(84) bytes of data. ^Z [7]+ 已停止 ping 192.168.10.240 [root@ka1 ~]# iptables -nL Chain INPUT (policy ACCEPT) target prot opt source destination DROP all -- 0.0.0.0/0 0.0.0.0/0 match-set keepalived dst Chain FORWARD (policy ACCEPT) target prot opt source destination Chain OUTPUT (policy ACCEPT) target prot opt source destination 这就是导致ping不通的原因---- match-set keepalived dst
如果要想ping通,就需要在配置文件中添加参数 ka1,ka2相同
global_defs { notification_email { 2948250195@qq.com # 发送邮件通知给谁 } notification_email_from keep@li.org #发送的邮件从哪来 smtp_server 127.0.0.1 # 邮件服务器ip smtp_connect_timeout 30 # 连接邮件服务器的超时时间 router_id ka1 # 虚拟路由的id vrrp_skip_check_adv_addr # 同一来源的只检测一次 vrrp_strict # 强制使用vrrp协议 vrrp_garp_interval 0 vrrp_gna_interval 0 vrrp_mcast_group4 224.0.0.18 # 接收通告数据的IP地址(组播地址) vrrp_iptables } # 在最后一行添加 # 或者将vrrp_strict 注释掉,效果相同测试:
[root@ka1 ~]# ping 192.168.10.240 PING 192.168.10.240 (192.168.10.240) 56(84) bytes of data. 64 bytes from 192.168.10.240: icmp_seq=1 ttl=64 time=0.021 ms 64 bytes from 192.168.10.240: icmp_seq=2 ttl=64 time=0.028 ms 64 bytes from 192.168.10.240: icmp_seq=3 ttl=64 time=0.035 ms 64 bytes from 192.168.10.240: icmp_seq=4 ttl=64 time=0.034 ms ^C --- 192.168.10.240 ping statistics --- 4 packets transmitted, 4 received, 0% packet loss, time 2998ms rtt min/avg/max/mdev = 0.021/0.029/0.035/0.007 ms [root@ka1 ~]# iptables -nL Chain INPUT (policy ACCEPT) target prot opt source destination Chain FORWARD (policy ACCEPT) target prot opt source destination Chain OUTPUT (policy ACCEPT) target prot opt source destination keepalived日志独立
默认情况下keepalived的日志和其他的服务是捆在一起的
要想将其日志独立出来就要修改其配置文件
[root@ka1 ~]# vim /etc/sysconfig/keepalived # Options for keepalived. See `keepalived --help' output and keepalived(8) and # keepalived.conf(5) man pages for a list of all options. Here are the most # common ones : # # --vrrp -P Only run with VRRP subsystem. # --check -C Only run with Health-checker subsystem. # --dont-release-vrrp -V Dont remove VRRP VIPs & VROUTEs on daemon stop. # --dont-release-ipvs -I Dont remove IPVS topology on daemon stop. # --dump-conf -d Dump the configuration data. # --log-detail -D Detailed log messages. # --log-facility -S 0-7 Set local syslog facility (default=LOG_DAEMON) # KEEPALIVED_OPTIONS="-D -S 6" # 指定采集日志用的id是6,0-7都行 重启服务
[root@ka1 ~]# systemctl restart keepalived.service 编辑rsyslog.conf文件
#### RULES #### # Log all kernel messages to the console. # Logging much else clutters up the screen. #kern.* /dev/console # Log anything (except mail) of level info or higher. # Don't log private authentication messages! *.info;mail.none;authpriv.none;cron.none /var/log/messages # The authpriv file has restricted access. authpriv.* /var/log/secure # Log all the mail messages in one place. mail.* -/var/log/maillog # Log cron stuff cron.* /var/log/cron # Everybody gets emergency messages *.emerg :omusrmsg:* # Save news errors of level crit and higher in a special file. uucp,news.crit /var/log/spooler # Save boot messages also to boot.log local7.* /var/log/boot.log local6.* /var/log/keepalived.log 在rules模块下可以添加 将日志采集在那个文件中,可以自定义,local加id
重启服务
[root@ka1 ~]# systemctl restart rsyslog.service 测试:
[root@ka1 ~]# systemctl restart rsyslog.service [root@ka1 ~]# ll /var/log/keepalived.log -rw-------. 1 root root 55473 8月 12 19:40 /var/log/keepalived.log [root@ka1 ~]# tail -f /var/log/keepalived.log Aug 12 19:40:20 ka1 Keepalived_healthcheckers[3771]: Adding sorry server [192.168.200.200]:1358 to VS [10.10.10.2]:1358 Aug 12 19:40:20 ka1 Keepalived_healthcheckers[3771]: Removing alive servers from the pool for VS [10.10.10.2]:1358 Aug 12 19:40:20 ka1 Keepalived_healthcheckers[3771]: Remote SMTP server [127.0.0.1]:25 connected. Aug 12 19:40:20 ka1 Keepalived_healthcheckers[3771]: SMTP alert successfully sent. Aug 12 19:40:20 ka1 Keepalived_healthcheckers[3771]: Timeout connecting server [192.168.201.100]:443. Aug 12 19:40:20 ka1 Keepalived_healthcheckers[3771]: Check on service [192.168.201.100]:443 failed after 3 retry. Aug 12 19:40:20 ka1 Keepalived_healthcheckers[3771]: Removing service [192.168.201.100]:443 from VS [192.168.200.100]:443 Aug 12 19:40:20 ka1 Keepalived_healthcheckers[3771]: Lost quorum 1-0=1 > 0 for VS [192.168.200.100]:443 Aug 12 19:40:20 ka1 Keepalived_healthcheckers[3771]: Remote SMTP server [127.0.0.1]:25 connected. Aug 12 19:40:20 ka1 Keepalived_healthcheckers[3771]: SMTP alert successfully sent. ^Z [8]+ 已停止 tail -f /var/log/keepalived.log keepalived独立子配置文件
当生产环境复杂时, /etc/keepalived/keepalived.conf 文件中内容过多,不易管理 将不同集群的配置,比如:不同集群的VIP配置放在独立的子配置文件中利用include 指令可以实现包含子配置文件格式:include /path/file 可以指定一个路径
[root@ka1 ~]# vim /etc/keepalived/keepalived.conf } # vrrp_instance VI_1 { # state MASTER # 主设备 # interface ens33 # vip使用的真实设备是谁 # virtual_router_id 100 # 虚拟路由id(唯一的) # priority 100 # 优先级 # advert_int 1 # authentication { # auth_type PASS # 发通告带的信息 # auth_pass 1111 # } # virtual_ipaddress { # vip id # 设定网卡子接口 # 192.168.10.240/24 dev ens33 label ens33:0 # } #} include "/etc/keepalived/conf.d/*.conf" # 将以上注释的内容指定在这个文件中 # 我们将以上的内容独立出来,放在一个新的文件里面,include指向新文件,前提是一定要有这个文件[root@ka1 ~]# mkdir -p /etc/keepalived/conf.d [root@ka1 ~]# vim /etc/keepalived/conf.d/192.168.10.240.conf vrrp_instance VI_1 { state MASTER # 主设备 interface ens33 # vip使用的真实设备是谁 virtual_router_id 100 # 虚拟路由id(唯一的) priority 100 # 优先级 advert_int 1 authentication { auth_type PASS # 发通告带的信息 auth_pass 1111 } virtual_ipaddress { # vip id # 设定网卡子接口 192.168.10.240/24 dev ens33 label ens33:0 } } [root@ka1 ~]# systemctl restart keepalived.service 测试:
[root@ka1 ~]# ifconfig ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.10.170 netmask 255.255.255.0 broadcast 192.168.10.255 inet6 fe80::20c:29ff:feea:fe5a prefixlen 64 scopeid 0x20<link> ether 00:0c:29:ea:fe:5a txqueuelen 1000 (Ethernet) RX packets 107150 bytes 7643447 (7.2 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 75971 bytes 5480440 (5.2 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 ens33:0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.10.240 netmask 255.255.255.0 broadcast 0.0.0.0 ether 00:0c:29:ea:fe:5a txqueuelen 1000 (Ethernet) 注意:将原配置文件独立出来后,原来的文件要么注释掉,要么删掉,否则独立出来的文件会和之前的文件冲突
keepalived非抢占和延迟抢占
非抢占模式 nopreempt
默认为抢占模式preempt,即当高优先级的主机恢复在线后,会抢占低先级的主机的master角色, 这样会使vip在KA主机中来回漂移,造成网络抖动, 建议设置为非抢占模式 nopreempt ,即高优先级主机恢复后,并不会抢占低优先级主机的master角色 非抢占模块下,如果原主机down机, VIP迁移至的新主机, 后续也发生down时,仍会将VIP迁移回原主机
注意:要关闭 VIP抢占,必须将各 keepalived 服务器state配置为BACKUP
ka1,和ka2配置相同
vim /etc/keepalived/keepalived.conf } vrrp_instance VI_1 { state BACKUP interface ens33 # vip使用的真实设备是谁 virtual_router_id 100 # 虚拟路由id(唯一的) priority 100 # 优先级 advert_int 1 nopreempt authentication { auth_type PASS # 发通告带的信息 auth_pass 1111 } virtual_ipaddress { # vip id # 设定网卡子接口 192.168.10.240/24 dev ens33 label ens33:0 } } # 设置非抢占模式 需要将state 改为 BACKUP 以及加一行参数 nopreempt[root@ka2 ~]# vim /etc/keepalived/keepalived.conf vrrp_instance VI_1 { state BACKUP interface ens33 # vip使用的真实设备是谁 virtual_router_id 100 # 虚拟路由id(唯一的) priority 80 # 优先级 advert_int 1 nopreempt authentication { auth_type PASS # 发通告带的信息 auth_pass 1111 } virtual_ipaddress { # vip id # 设定网卡子接口 192.168.10.240/24 dev ens33 label ens33:0 我先重启ka2再重启ka1,vip将会跑到ka2上,并且不会回去,当ka2挂掉,vip才会回去,不管优先级
[root@ka2 ~]# ifconfig ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.10.180 netmask 255.255.255.0 broadcast 192.168.10.255 inet6 fe80::20c:29ff:fe2c:7bd prefixlen 64 scopeid 0x20<link> ether 00:0c:29:2c:07:bd txqueuelen 1000 (Ethernet) RX packets 142318 bytes 10033173 (9.5 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 45810 bytes 3472473 (3.3 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 ens33:0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.10.240 netmask 255.255.255.0 broadcast 0.0.0.0 ether 00:0c:29:2c:07:bd txqueuelen 1000 (Ethernet) [root@ka2 ~]# systemctl stop keepalived.service [root@ka1 ~]# ifconfig ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.10.170 netmask 255.255.255.0 broadcast 192.168.10.255 inet6 fe80::20c:29ff:feea:fe5a prefixlen 64 scopeid 0x20<link> ether 00:0c:29:ea:fe:5a txqueuelen 1000 (Ethernet) RX packets 111441 bytes 7967231 (7.5 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 78058 bytes 5653940 (5.3 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 ens33:0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.10.240 netmask 255.255.255.0 broadcast 0.0.0.0 ether 00:0c:29:ea:fe:5a txqueuelen 1000 (Ethernet) 延迟抢占preempt_delay
抢占延迟模式,即优先级高的主机恢复后,不会立即抢回VIP,而是延迟一段时间(默认300s)再抢回VIP
注意:需要各keepalived服务器state为BACKUP,并且不要启用 vrrp_strictpreempt_delay # #指定抢占延迟时间为#s,默认延迟300s
[root@ka1 ~]# vim /etc/keepalived/keepalived.conf vrrp_instance VI_1 { state BACKUP interface ens33 # vip使用的真实设备是谁 virtual_router_id 100 # 虚拟路由id(唯一的) priority 100 preempt_delay 10s # 抢占延迟10s advert_int 1 # nopreempt authentication { auth_type PASS # 发通告带的信息 auth_pass 1111 } virtual_ipaddress { # vip id # 设定网卡子接口 192.168.10.240/24 dev ens33 label ens33:0 } [root@ka2 ~]# vim /etc/keepalived/keepalived.conf vrrp_instance VI_1 { state BACKUP interface ens33 # vip使用的真实设备是谁 virtual_router_id 100 # 虚拟路由id(唯一的) priority 80 # 优先级 advert_int 1 preempt_delay 10s # nopreempt authentication { auth_type PASS # 发通告带的信息 auth_pass 1111 } virtual_ipaddress { # vip id # 设定网卡子接口 192.168.10.240/24 dev ens33 label ens33:0 } 测试:由于pa1的优先级高于pa2,我先启动pa2 ,down掉pa1,vip会到pa2上,我再启动pa1,vip不会立刻回到pa1上,而是10秒后
[root@ka2 ~]# systemctl restart keepalived.service [root@ka2 ~]# ifconfig ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.10.180 netmask 255.255.255.0 broadcast 192.168.10.255 inet6 fe80::20c:29ff:fe2c:7bd prefixlen 64 scopeid 0x20<link> ether 00:0c:29:2c:07:bd txqueuelen 1000 (Ethernet) RX packets 146839 bytes 10374458 (9.8 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 47473 bytes 3611473 (3.4 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536 inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10<host> loop txqueuelen 1000 (Local Loopback) RX packets 607 bytes 44033 (43.0 KiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 607 bytes 44033 (43.0 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 [root@ka1 ~]# date 2024年 08月 12日 星期一 20:19:31 CST [root@ka1 ~]# systemctl restart keepalived.service [root@ka1 ~]# ifconfig ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.10.170 netmask 255.255.255.0 broadcast 192.168.10.255 inet6 fe80::20c:29ff:feea:fe5a prefixlen 64 scopeid 0x20<link> ether 00:0c:29:ea:fe:5a txqueuelen 1000 (Ethernet) RX packets 115304 bytes 8272918 (7.8 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 79935 bytes 5800622 (5.5 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 ens33:0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.10.240 netmask 255.255.255.0 broadcast 0.0.0.0 ether 00:0c:29:ea:fe:5a txqueuelen 1000 (Ethernet) lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536 inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10<host> loop txqueuelen 1000 (Local Loopback) RX packets 942 bytes 69116 (67.4 KiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 942 bytes 69116 (67.4 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 [root@ka1 ~]# date 2024年 08月 12日 星期一 20:19:48 CST #差不多就是这个意思 VIP单播配置
默认keepalived主机之间利用多播相互通告消息,会造成网络拥塞,可以替换成单播,减少网络流量[!NOTE] 注意:启用 vrrp_strict 时,不能启用单播
#在所有节点vrrp_instance语句块中设置对方主机的IP,建议设置为专用于对应心跳线网络的地址,而非使 用业务网络 unicast_src_ip <IPADDR> #指定发送单播的源IP unicast_peer { <IPADDR> #指定接收单播的对方目标主机IP ...... } #启用 vrrp_strict 时,不能启用单播,否则服务无法启动,并在messages文件中记录下面信息 Jun 16 17:50:06 centos8 Keepalived_vrrp[23180]: (m44) Strict mode does not support authentication. Ignoring. Jun 16 17:50:06 centos8 Keepalived_vrrp[23180]: (m44) Unicast peers are notsupported in strict mode Jun 16 17:50:06 centos8 Keepalived_vrrp[23180]: Stopped - used 0.000606 user time, 0.000000 system time Jun 16 17:50:06 centos8 Keepalived[23179]: Keepalived_vrrp exited with permanent error CONFIG. Terminating Jun 16 17:50:06 centos8 systemd[1]: keepalived.service: Succeeded. Jun 16 17:50:06 centos8 Keepalived[23179]: Stopped Keepalived v2.0.10 (11/12,2018)
组播变单播实验
ka1和ka2互相进行通告
[root@ka1 ~]# vim /etc/keepalived/keepalived.conf global_defs { notification_email { 2948250195@qq.com # 发送邮件通知给谁 } notification_email_from keep@li.org #发送的邮件从哪来 smtp_server 127.0.0.1 # 邮件服务器ip smtp_connect_timeout 30 # 连接邮件服务器的超时时间 router_id ka1 # 虚拟路由的id vrrp_skip_check_adv_addr # 同一来源的只检测一次 # vrrp_strict #注释此行,与vip单播模式冲突 vrrp_garp_interval 0 vrrp_gna_interval 0 vrrp_mcast_group4 224.0.0.18 # 接收通告数据的IP地址(组播地址) # vrrp_iptables } vrrp_instance VI_1 { state MASTER interface ens33 # vip使用的真实设备是谁 virtual_router_id 100 # 虚拟路由id(唯一的) priority 100 # preempt_delay 10s # 抢占延迟10s advert_int 1 # nopreempt authentication { auth_type PASS # 发通告带的信息 auth_pass 1111 } virtual_ipaddress { # vip id # 设定网卡子接口 192.168.10.240/24 dev ens33 label ens33:0 } unicast_src_ip 192.168.10.170 # 发送源,就是本机ip unicast_peer { 192.168.10.180 # 接收源,就是对端也就是ka2 } [root@ka2 ~]# vim /etc/keepalived/keepalived.conf global_defs { notification_email { 2948250195@qq.com # 发送邮件通知给谁 } notification_email_from keep@li.org #发送的邮件从哪来 smtp_server 127.0.0.1 # 邮件服务器ip smtp_connect_timeout 30 # 连接邮件服务器的超时时间 router_id ka1 # 虚拟路由的id vrrp_skip_check_adv_addr # 同一来源的只检测一次 # vrrp_strict # 注释此行,与vip单播模式冲突 vrrp_garp_interval 0 vrrp_gna_interval 0 vrrp_mcast_group4 224.0.0.18 # 接收通告数据的IP地址(组播地址) # vrrp_iptables vrrp_instance VI_1 { state BACKUP interface ens33 # vip使用的真实设备是谁 virtual_router_id 100 # 虚拟路由id(唯一的) priority 80 # 优先级 advert_int 1 # preempt_delay 10s # nopreempt authentication { auth_type PASS # 发通告带的信息 auth_pass 1111 } virtual_ipaddress { # vip id # 设定网卡子接口 192.168.10.240/24 dev ens33 label ens33:0 } unicast_src_ip 192.168.10.180 # 发送源,就是本机ip unicast_peer { 192.168.10.170 } 测试:
[root@ka1 ~]# tcpdump -i ens33 -nn src host 192.168.10.170 and dst 192.168.10.180 tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes 09:43:21.998624 IP 192.168.10.170 > 192.168.10.180: VRRPv2, Advertisement, vrid 100, prio 100, authtype simple, intvl 1s, length 20 09:43:23.005985 IP 192.168.10.170 > 192.168.10.180: VRRPv2, Advertisement, vrid 100, prio 100, authtype simple, intvl 1s, length 20 09:43:24.011231 IP 192.168.10.170 > 192.168.10.180: VRRPv2, Advertisement, vrid 100, prio 100, authtype simple, intvl 1s, length 20 09:43:25.017003 IP 192.168.10.170 > 192.168.10.180: VRRPv2, Advertisement, vrid 100, prio 100, authtype simple, intvl 1s, length 20 09:43:26.017906 IP 192.168.10.170 > 192.168.10.180: VRRPv2, Advertisement, vrid 100, prio 100, authtype simple, intvl 1s, length 20 09:43:27.024354 IP 192.168.10.170 > 192.168.10.180: VRRPv2, Advertisement, vrid 100, prio 100, authtype simple, intvl 1s, length 20 # 在170上看180到170的数据 # 在180上看170到180的数据邮件通知
当两台keepalived主机出现问题,或者身份发生转换时,通过邮件的形式告知运维人员
安装邮件发送工具[root@ka1 ~]# yum install mailx -y [root@ka2 ~]# yum install mailx -y 可以使用qq或者网易邮箱,打开账号与安全,开启POP3/IMAP/SMTP/Exchange/CardDAV 授权码,他会给你一个授权码,将授权码添加到/etc/mail.rc(邮件客户端的配置文件)文件中
[root@ka1 ~]# vim /etc/mail.rc '''''''''''省略''''''''''''''''''''' set from= # 后面添加你用哪一个邮箱,填上账号 set smtp=smtp.qq.com set smtp-auth-user= # 填自己的邮箱号 set smtp-auth-password= # 这个就是给你的授权码 set smtp-auth=login # 表示登陆 set ssl-verify=ignore # 不用加密协议 # 在文件的最后面加上 另一台主机同样配置。
测试:
[root@ka1 ~]# echo hello world | mail -s test 跟上你的邮箱账号 
实现 Keepalived 状态切换的通知脚本
通知脚本类型
当前节点成为主节点时触发的脚本notify_master <STRING>|<QUOTED-STRING>notify_backup <STRING>|<QUOTED-STRING>notify_fault <STRING>|<QUOTED-STRING>notify <STRING>|<QUOTED-STRING>notify_stop <STRING>|<QUOTED-STRING>脚本的调用方法
在 vrrp_instance VI_1 语句块的末尾加下面行notify_master "/etc/keepalived/notify.sh master" notify_backup "/etc/keepalived/notify.sh backup" notify_fault "/etc/keepalived/notify.sh fault"创建通知脚本
[root@KA1 ~]# vim /etc/keepalived/mail.sh # 自己创建文件 #!/bin/bash mail_dest='填邮箱账号' mail_send() { mail_subj="$HOSTNAME to be $1 vip 转移" # 邮件的标题 mail_mess="`date +%F\ %T`: vrrp 转移,$HOSTNAME 变为 $1" #邮件的正文 echo "$mail_mess" | mail -s "$mail_subj" $mail_dest # echo发邮件 } case $1 in master) mail_send master ;; backup) mail_send backup ;; fault) mail_send fault ;; *) exit 1 ;; esac[root@ka1 ~]# chmod +x /etc/keepalived/mail.sh # 给它一个可执行的权限调度:
[root@ka1 ~]# vim /etc/keepalived/keepalived.conf vrrp_instance VI_1 { state MASTER interface ens33 # vip使用的真实设备是谁 virtual_router_id 100 # 虚拟路由id(唯一的) priority 100 advert_int 1 authentication { auth_type PASS # 发通告带的信息 auth_pass 1111 } virtual_ipaddress { # vip id # 设定网卡子接口 192.168.10.240/24 dev ens33 label ens33:0 } unicast_src_ip 192.168.10.170 unicast_peer { 192.168.10.180 } notify_master "/etc/keepalived/mail.sh master" notify_backup "/etc/keepalived/mail.sh backup" notify_fault "/etc/keepalived/mail.sh fault" } ka1,ka2配置相同
测试:[root@ka1 ~]# bash /etc/keepalived/mail.sh 

[root@ka2 ~]# bash /etc/keepalived/mail.sh 
停止ka1keepalived服务,vip跑到ka2上自动发邮件
[root@ka1 ~]# systemctl stop keepalived.service
开启ka1,vip回到ka1上,自动发邮件
[root@ka1 ~]# systemctl start keepalived.service 

实现 master/master 的 Keepalived 双主架构
master/slave的单主架构,同一时间只有一个Keepalived对外提供服务,此主机繁忙,而另一台主机却很空闲,利用率低下,可以使用master/master的双主架构,解决此问题。master/master 的双主架构: 即将两个或以上VIP分别运行在不同的keepalived服务器,以实现服务器并行提供web访问的目的,提高服务器资源利用率
ka1上配置
[root@ka1 ~]# vim /etc/keepalived/keepalived.conf vrrp_instance VI_1 { state MASTER interface ens33 # vip使用的真实设备是谁 virtual_router_id 100 # 虚拟路由id(唯一的) priority 100 advert_int 1 authentication { auth_type PASS # 发通告带的信息 auth_pass 1111 } virtual_ipaddress { # vip id # 设定网卡子接口 192.168.10.240/24 dev ens33 label ens33:0 } # unicast_src_ip 192.168.10.170 # unicast_peer { # 192.168.10.180 # } } # include "/etc/keepalived/conf.d/*.conf" # 将以上注释的内容指定在这个文件中 vrrp_instance VI_2 { state BACKUP #备 interface ens33 virtual_router_id 200 priority 80 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.10.245 dev ens33 label ens33:1 } } ka2
} vrrp_instance VI_2 { state MASTER # zhu interface ens33 # vip使用的真实设备是谁 virtual_router_id 200 # 虚拟路由id(唯一的) priority 100 # 优先级 advert_int 1 # preempt_delay 10s # nopreempt authentication { auth_type PASS # 发通告带的信息 auth_pass 1111 } virtual_ipaddress { # vip id # 设定网卡子接口 192.168.10.245/24 dev ens33 label ens33:1 } unicast_src_ip 192.168.10.180 # 发送源,就是本机ip unicast_peer { 192.168.10.170 } } .。。。。。省略。。。。。。。测试:第一个vip应该在ka1上,第二个vip应该在ka2上
[root@ka1 ~]# ifconfig ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.10.170 netmask 255.255.255.0 broadcast 192.168.10.255 inet6 fe80::20c:29ff:feea:fe5a prefixlen 64 scopeid 0x20<link> ether 00:0c:29:ea:fe:5a txqueuelen 1000 (Ethernet) RX packets 30093 bytes 2256607 (2.1 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 20992 bytes 1524476 (1.4 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 ens33:0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.10.240 netmask 255.255.255.0 broadcast 0.0.0.0 ether 00:0c:29:ea:fe:5a txqueuelen 1000 (Ethernet) [root@ka2 ~]# ifconfig ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.10.180 netmask 255.255.255.0 broadcast 192.168.10.255 inet6 fe80::20c:29ff:fe2c:7bd prefixlen 64 scopeid 0x20<link> ether 00:0c:29:2c:07:bd txqueuelen 1000 (Ethernet) RX packets 22361 bytes 1479856 (1.4 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 10536 bytes 831566 (812.0 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 ens33:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.10.245 netmask 255.255.255.0 broadcast 0.0.0.0 ether 00:0c:29:2c:07:bd txqueuelen 1000 (Ethernet) 实现IPVS的高可用
相当于使用keepalived结合lvs去组成一个既具备高可用,又具备负载均衡的集群
keepalived解决了vip的问题
IPVS相关配置
虚拟服务器配置结构
virtual_server IP port { ... real_server { ... } real_server { ... } … }virtual server (虚拟服务器)的定义格式
virtual_server IP port #定义虚拟主机IP地址及其端口 virtual_server fwmark int #ipvs的防火墙打标,实现基于防火墙的负载均衡集群 virtual_server group string #使用虚拟服务器组虚拟服务器配置
virtual_server IP port { #VIP和PORT delay_loop <INT> #检查后端服务器的时间间隔 lb_algo rr|wrr|lc|wlc|lblc|sh|dh #定义调度方法 lb_kind NAT|DR|TUN #集群的类型,注意要大写 persistence_timeout <INT> #持久连接时长 protocol TCP|UDP|SCTP #指定服务协议,一般为TCP sorry_server <IPADDR> <PORT> #所有RS故障时,备用服务器地址 real_server <IPADDR> <PORT> { #RS的IP和PORT weight <INT> #RS权重 notify_up <STRING>|<QUOTED-STRING> #RS上线通知脚本 notify_down <STRING>|<QUOTED-STRING> #RS下线通知脚本 HTTP_GET|SSL_GET|TCP_CHECK|SMTP_CHECK|MISC_CHECK { ... } #定义当前主机健康状 态检测方法 } } #注意:括号必须分行写,两个括号写在同一行,如: }} 会出错应用层监测
应用层检测:HTTP_GET|SSL_GETHTTP_GET|SSL_GET { url { path <URL_PATH> #定义要监控的URL status_code <INT> #判断上述检测机制为健康状态的响应码,一般为 200 } connect_timeout <INTEGER> #客户端请求的超时时长, 相当于haproxy的timeout server nb_get_retry <INT> #重试次数 delay_before_retry <INT> #重试之前的延迟时长 connect_ip <IP ADDRESS> #向当前RS哪个IP地址发起健康状态检测请求 connect_port <PORT> #向当前RS的哪个PORT发起健康状态检测请求 bindto <IP ADDRESS> #向当前RS发出健康状态检测请求时使用的源地址 bind_port <PORT> #向当前RS发出健康状态检测请求时使用的源端口 }TCP监测
TCP_CHECK { connect_ip <IP ADDRESS> #向当前RS的哪个IP地址发起健康状态检测请求 connect_port <PORT> #向当前RS的哪个PORT发起健康状态检测请求 bindto <IP ADDRESS> #发出健康状态检测请求时使用的源地址 bind_port <PORT> #发出健康状态检测请求时使用的源端口 connect_timeout <INTEGER> #客户端请求的超时时长 #等于haproxy的timeout server }实战案例
keepalived+lvs实现高可用
实现单主的 LVS-DR 模式
在webserver1和webserver上将其环回设置为vip,以及对它们的arp广播进行一个只进不出的设定。
[root@webserver1 ~]# ip a a 192.168.10.240/32 dev lo # 临时设定 [root@webserver1 ~]# ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet 192.168.10.240/32 scope global lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:0c:29:6c:ee:7d brd ff:ff:ff:ff:ff:ff inet 192.168.10.220/24 brd 192.168.10.255 scope global noprefixroute ens33 valid_lft forever preferred_lft forever inet6 fe80::20c:29ff:fe6c:ee7d/64 scope link valid_lft forever preferred_lft forever [root@webserver2 ~]# ip a a 192.168.10.240/32 dev lo [root@webserver2 ~]# ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet 192.168.10.240/32 scope global lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:0c:29:f0:40:f5 brd ff:ff:ff:ff:ff:ff inet 192.168.10.230/24 brd 192.168.10.255 scope global noprefixroute ens33 valid_lft forever preferred_lft forever inet6 fe80::20c:29ff:fef0:40f5/64 scope link valid_lft forever preferred_lft forever [root@webserver1 ~]# sysctl -a | grep arp dev.parport.default.spintime = 500 dev.parport.default.timeslice = 200 net.ipv4.conf.all.arp_accept = 0 net.ipv4.conf.all.arp_announce = 2 net.ipv4.conf.all.arp_filter = 0 net.ipv4.conf.all.arp_ignore = 1 net.ipv4.conf.all.arp_notify = 0 net.ipv4.conf.all.proxy_arp = 0 net.ipv4.conf.all.proxy_arp_pvlan = 0 net.ipv4.conf.default.arp_accept = 0 net.ipv4.conf.default.arp_announce = 0 net.ipv4.conf.default.arp_filter = 0 net.ipv4.conf.default.arp_ignore = 0 net.ipv4.conf.default.arp_notify = 0 net.ipv4.conf.default.proxy_arp = 0 net.ipv4.conf.default.proxy_arp_pvlan = 0 net.ipv4.conf.ens33.arp_accept = 0 net.ipv4.conf.ens33.arp_announce = 0 net.ipv4.conf.ens33.arp_filter = 0 net.ipv4.conf.ens33.arp_ignore = 0 net.ipv4.conf.ens33.arp_notify = 0 net.ipv4.conf.ens33.proxy_arp = 0 net.ipv4.conf.ens33.proxy_arp_pvlan = 0 net.ipv4.conf.lo.arp_accept = 0 net.ipv4.conf.lo.arp_announce = 2 net.ipv4.conf.lo.arp_filter = 0 net.ipv4.conf.lo.arp_ignore = 1 net.ipv4.conf.lo.arp_notify = 0 net.ipv4.conf.lo.proxy_arp = 0 net.ipv4.conf.lo.proxy_arp_pvlan = 0 sysctl: reading key "net.ipv6.conf.all.stable_secret" sysctl: reading key "net.ipv6.conf.default.stable_secret" sysctl: reading key "net.ipv6.conf.ens33.stable_secret" sysctl: reading key "net.ipv6.conf.lo.stable_secret" 可以在这里面复制粘贴,然后光修改参数即可
[root@webserver1 ~]# vim /etc/sysctl.d/arp.conf # 可以自己创建文件 net.ipv4.conf.all.arp_announce=2 net.ipv4.conf.all.arp_ignore=1 net.ipv4.conf.lo.arp_announce = 2 net.ipv4.conf.lo.arp_ignore = 1 [root@webserver1 ~]# sysctl --system # 刷新生效 * Applying /usr/lib/sysctl.d/00-system.conf ... * Applying /usr/lib/sysctl.d/10-default-yama-scope.conf ... kernel.yama.ptrace_scope = 0 * Applying /usr/lib/sysctl.d/50-default.conf ... kernel.sysrq = 16 kernel.core_uses_pid = 1 kernel.kptr_restrict = 1 net.ipv4.conf.default.rp_filter = 1 net.ipv4.conf.all.rp_filter = 1 net.ipv4.conf.default.accept_source_route = 0 net.ipv4.conf.all.accept_source_route = 0 net.ipv4.conf.default.promote_secondaries = 1 net.ipv4.conf.all.promote_secondaries = 1 fs.protected_hardlinks = 1 fs.protected_symlinks = 1 * Applying /etc/sysctl.d/99-sysctl.conf ... * Applying /etc/sysctl.d/arp.conf ... net.ipv4.conf.all.arp_announce = 2 net.ipv4.conf.all.arp_ignore = 1 net.ipv4.conf.lo.arp_announce = 2 net.ipv4.conf.lo.arp_ignore = 1 * Applying /etc/sysctl.conf ... webserver1和webserver2配置相同,我们可以使用scp复制
[root@webserver1 ~]# scp /etc/sysctl.d/arp.conf root@192.168.10.230:/etc/sysctl.d/arp.conf The authenticity of host '192.168.10.230 (192.168.10.230)' can't be established. ECDSA key fingerprint is SHA256:Yrid63PgwDQh7wiaQmCGsLuxK3Cht8v/wekHTAza/XI. ECDSA key fingerprint is MD5:d7:be:70:41:82:ff:81:40:5b:a7:40:10:d1:0c:ca:bf. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added '192.168.10.230' (ECDSA) to the list of known hosts. root@192.168.10.230's password: arp.conf 100% 131 251.9KB/s 00:00 [root@webserver2 ~]# sysctl --system * Applying /usr/lib/sysctl.d/00-system.conf ... * Applying /usr/lib/sysctl.d/10-default-yama-scope.conf ... kernel.yama.ptrace_scope = 0 * Applying /usr/lib/sysctl.d/50-default.conf ... kernel.sysrq = 16 kernel.core_uses_pid = 1 kernel.kptr_restrict = 1 net.ipv4.conf.default.rp_filter = 1 net.ipv4.conf.all.rp_filter = 1 net.ipv4.conf.default.accept_source_route = 0 net.ipv4.conf.all.accept_source_route = 0 net.ipv4.conf.default.promote_secondaries = 1 net.ipv4.conf.all.promote_secondaries = 1 fs.protected_hardlinks = 1 fs.protected_symlinks = 1 * Applying /etc/sysctl.d/99-sysctl.conf ... * Applying /etc/sysctl.d/arp.conf ... net.ipv4.conf.all.arp_announce = 2 net.ipv4.conf.all.arp_ignore = 1 net.ipv4.conf.lo.arp_announce = 2 net.ipv4.conf.lo.arp_ignore = 1 * Applying /etc/sysctl.conf ... 在ka1上下载一个ipvsadm软件包,查看ipvs规则
[root@ka1 ~]# yum install ipvsadm -y 在keepalived主机上配置策略
[root@ka1 ~]# vim /etc/keepalived/keepalived.conf virtual_server 192.168.10.240 80 { # 这就相当于使用ipvsadm -A 添加虚拟主机,ip就是vip delay_loop 6 lb_algo wrr lb_kind DR # persistence_timeout 50 protocol TCP ################################################### real_server 192.168.10.220 80 { # 这就是相当于ipvsadm -a 添加真实主机 weight 1 HTTP_GET { url { path / digest_code 200 } connect_timeout 3 nb_get_retry 2 delay_before_retry 2 } } ################################################### real_server 192.168.10.230 80 { weight 1 HTTP_GET { url { path / digest_code 200 } connect_timeout 3 nb_get_retry 2 delay_before_retry 2 } } webserver2和1相同
[root@ka2 ~]# vim /etc/keepalived/keepalived.conf virtual_server 192.168.10.240 80 { delay_loop 6 lb_algo wrr lb_kind DR # persistence_timeout 50 protocol TCP ############################################# real_server 192.168.10.220 80 { weight 1 HTTP_GET { url { path / digest_code 200 } connect_timeout 3 nb_get_retry 2 delay_before_retry 2 } } ############################################# real_server 192.168.10.230 80 { weight 1 HTTP_GET { url { path / digest_code 200 } connect_timeout 3 nb_get_retry 2 delay_before_retry 2 } } [root@ka1 ~]# ipvsadm -Ln IP Virtual Server version 1.2.1 (size=4096) Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn TCP 192.168.10.240:80 wrr -> 192.168.10.220:80 Route 1 0 0 -> 192.168.10.230:80 Route 1 0 0 TCP 10.10.10.2:1358 rr persistent 50 -> 192.168.200.2:1358 Masq 1 0 0 -> 192.168.200.3:1358 Masq 1 0 0 TCP 10.10.10.3:1358 rr persistent 50 -> 192.168.200.4:1358 Masq 1 0 0 -> 192.168.200.5:1358 Masq 1 0 0 查看策略,这些策略都是通过添加keepalived配置文件生成的
测试:访问vip

注:lvs是不提供后端检测的,就是你写完策略以后,不管它是不是好的,都往上仍,现在结合keepalived之后达到的效果就它可以检测你的策略是不是好的,后台的real server是否是正常的,如果real server异常,它就会被踢出我们的策略当中,如果有正常了,就会自动加入到我们的策略当中,全程都是自动的。
此时我们的ka2上面的策略是不生效的,因为ka2上面没有vip,当我们的ka1down掉,vip就会自动跑到我们的ka2上,此次ka2上的策略生效,不会影响我们客户的正常访问。
我们可以通过测试来看出
后台两个real server正常的情况下,策略是这样的
[root@ka1 ~]# ipvsadm -Ln IP Virtual Server version 1.2.1 (size=4096) Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn TCP 192.168.10.240:80 wrr -> 192.168.10.220:80 Route 1 0 0 -> 192.168.10.230:80 Route 1 0 0 TCP 10.10.10.2:1358 rr persistent 50 -> 192.168.200.2:1358 Masq 1 0 0 -> 192.168.200.3:1358 Masq 1 0 0 现在我把webserver1(192,.168.10.220)上的web服务down掉,我们再来看策略
[root@ka1 ~]# ipvsadm -Ln IP Virtual Server version 1.2.1 (size=4096) Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn TCP 192.168.10.240:80 wrr -> 192.168.10.230:80 Route 1 0 0 TCP 10.10.10.2:1358 rr persistent 50 -> 192.168.200.2:1358 Masq 1 0 0 -> 192.168.200.3:1358 Masq 1 0 0 我们可以使用watch来监控,这样看的更加清晰,是动态的
[root@ka1 ~]# watch -n 1 ipvsadm -Ln 实现HAProxy高可用
原理:由keepalived去监测haproxy的状态,如果主keepalived上haproxy主机出现了问题,主keepalived就将自己的优先级降低,优先级一降低,vip就会跑到我们备keepalived上去,备keepalived上的haproxy也可以正常调度,也可以正常访问real server。
主要是检测haproxy的状态,haproxy作为调度器,如果他出现了问题,就算你有vip也无法访问我们的real server
实现其它应用的高可用性 VRRP Script
keepalived利用 VRRP Script 技术,可以调用外部的辅助脚本进行资源监控,并根据监控的结果实现优先级动态调整,从而实现其它应用的高可用性功能 参考配置文件:/usr/share/doc/keepalived/keepalived.conf.vrrp.localcheck
VRRP Script 配置
分两步实现:1.定义脚本 vrrp_script:自定义资源监控脚本,vrrp实例根据脚本返回值,公共定义,可被多个实例调用,定义在vrrp实例之外的独立配置块,一般放在global_defs设置块之后。 通常此脚本用于监控指定应用的状态。一旦发现应用的状态异常,则触发对MASTER节点的权重减至低于SLAVE节点,从而实现 VIP 切换到 SLAVE 节点
vrrp_script <SCRIPT_NAME> { script <STRING>|<QUOTED-STRING> #此脚本返回值为非0时,会触发下面OPTIONS执行 OPTIONS }2.调用脚本
track_script:调用vrrp_script定义的脚本去监控资源,定义在VRRP实例之内,调用事先定义的vrrp_script
track_script { SCRIPT_NAME_1 SCRIPT_NAME_2 }定义 VRRP script
vrrp_script <SCRIPT_NAME> { #定义一个检测脚本,在global_defs 之外配置 script <STRING>|<QUOTED-STRING> #shell命令或脚本路径 interval <INTEGER> #间隔时间,单位为秒,默认1秒 timeout <INTEGER> #超时时间 weight <INTEGER:-254..254> #默认为0,如果设置此值为负数, #当上面脚本返回值为非0时 #会将此值与本节点权重相加可以降低本节点权重, #即表示fall. #如果是正数,当脚本返回值为0, #会将此值与本节点权重相加可以提高本节点权重 #即表示 rise.通常使用负值 fall <INTEGER> #执行脚本连续几次都失败,则转换为失败,建议设为2以上 rise <INTEGER> #执行脚本连续几次都成功,把服务器从失败标记为成功 user USERNAME [GROUPNAME] #执行监测脚本的用户或组 init_fail #设置默认标记为失败状态,监测成功之后再转换为成功状态 }调用 VRRP script
vrrp_instance test { ... ... track_script { check_down } }利用脚本实现主从角色切换
[root@ka1 ~]# vim /etc/keepalived/check_blue.sh #!/bin/bash [ ! -f /blue ] # 检测 /blue这个文件存不存在[root@ka1 ~]# bash /etc/keepalived/check_blue.sh [root@ka1 ~]# echo $? 0 [root@ka1 ~]# chmod +x /etc/keepalived/check_blue.sh # 给脚本一个可执行权限执行脚本后,通过其返回值来确定这个文件存不存在,若是0表示执行成功,文件不存在,若是其他值,表示执行失败,文件存在。
! Configuration File for keepalived global_defs { notification_email { 2948250195@qq.com # 发送邮件通知给谁 } notification_email_from keep@li.org #发送的邮件从哪来 smtp_server 127.0.0.1 # 邮件服务器ip smtp_connect_timeout 30 # 连接邮件服务器的超时时间 router_id ka1 # 虚拟路由的id vrrp_skip_check_adv_addr # 同一来源的只检测一次 # vrrp_strict # 强制使用vrrp协议 vrrp_garp_interval 0 vrrp_gna_interval 0 vrrp_mcast_group4 224.0.0.18 # 接收通告数据的IP地址(组播地址) # vrrp_iptables } vrrp_script check_file { script "/etc/keepalived/check_blue.sh" interval 1 # 检测时间间隔为1秒 weight -30 # 如果返回值不为0,优先级减30 fall 2 # 脚本执行两次,再者视为失败 rise 2 # 脚本连续两次执行成功,把服务器从失败转换为成功状态 timeout 2 # 脚本执行的超时时间 } # 检测脚本的配置文件放在 vrrp_instance VI_1 配置文件的上面 vrrp_instance VI_1 { state MASTER interface ens33 # vip使用的真实设备是谁 virtual_router_id 100 # 虚拟路由id(唯一的) priority 100 advert_int 1 authentication { auth_type PASS # 发通告带的信息 auth_pass 1111 } virtual_ipaddress { # vip id # 设定网卡子接口 192.168.10.240/24 dev ens33 label ens33:0 } unicast_src_ip 192.168.10.170 unicast_peer { 192.168.10.180 } track_script { check_file # 脚本名称 和上面定义脚本的名称一致 } } #调用脚本放在虚拟路由配置文件的里面测试:
当我们脚本中的文件不存在时,返回值为0,配置文件中的weight值就不生效。优先级就仍然为100,vip不会漂移
[root@ka1 ~]# ll /blue ls: 无法访问/blue: 没有那个文件或目录 [root@ka1 ~]# ifconfig ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.10.170 netmask 255.255.255.0 broadcast 192.168.10.255 inet6 fe80::20c:29ff:feea:fe5a prefixlen 64 scopeid 0x20<link> ether 00:0c:29:ea:fe:5a txqueuelen 1000 (Ethernet) RX packets 297425 bytes 27436999 (26.1 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 234268 bytes 17810980 (16.9 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 ens33:0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.10.240 netmask 255.255.255.0 broadcast 0.0.0.0 ether 00:0c:29:ea:fe:5a txqueuelen 1000 (Ethernet) lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536 inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10<host> loop txqueuelen 1000 (Local Loopback) RX packets 2459 bytes 182483 (178.2 KiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 2459 bytes 182483 (178.2 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 当我们创建这个文件时,他存在,执行脚本后返回值不为0,我们的配置文件的weight值生效,我们的优先级就会减30,变为70,此时主keepalived的优先级低于备,使用vip就会漂移到ka2上
[root@ka1 ~]# touch /blue [root@ka1 ~]# ll /blue -rw-r--r--. 1 root root 0 8月 14 17:25 /blue [root@ka1 ~]# systemctl restart keepalived.service [root@ka1 ~]# ifconfig ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.10.170 netmask 255.255.255.0 broadcast 192.168.10.255 inet6 fe80::20c:29ff:feea:fe5a prefixlen 64 scopeid 0x20<link> ether 00:0c:29:ea:fe:5a txqueuelen 1000 (Ethernet) RX packets 298043 bytes 27493779 (26.2 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 234948 bytes 17862710 (17.0 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 [root@ka2 ~]# ifconfig ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.10.180 netmask 255.255.255.0 broadcast 192.168.10.255 inet6 fe80::20c:29ff:fe2c:7bd prefixlen 64 scopeid 0x20<link> ether 00:0c:29:2c:07:bd txqueuelen 1000 (Ethernet) RX packets 2709 bytes 262428 (256.2 KiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 3609 bytes 274342 (267.9 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 ens33:0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.10.240 netmask 255.255.255.0 broadcast 0.0.0.0 ether 00:0c:29:2c:07:bd txqueuelen 1000 (Ethernet) ens33:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.10.245 netmask 255.255.255.0 broadcast 0.0.0.0 ether 00:0c:29:2c:07:bd txqueuelen 1000 (Ethernet) 根据上面的实验,我们现在只需要把脚本的内容换成检测haproxy好坏,就可以实现我们的高可用。
实战案例
haproxy+keepalived实现高可用
在keepalived主机上装haproxy
[root@ka1 ~]# yum install haproxy -y [root@ka2 ~]# yum install haproxy -y [root@ka1 ~]# vim /etc/haproxy/haproxy.cfg .。。。。。。。省略。。。。。。。。。。。 #--------------------------------------------------------------------- # round robin balancing between the various backends #--------------------------------------------------------------------- backend app balance roundrobin server app1 127.0.0.1:5001 check server app2 127.0.0.1:5002 check server app3 127.0.0.1:5003 check server app4 127.0.0.1:5004 check listen webcluser bind 192.168.10.240:80 mode http balance roundrobin server webserver1 192.168.10.220:80 check inter 3 fall 2 rise 5 server webserver2 192.168.10.230:80 check inter 3 fall 2 rise 5 重启服务
[root@ka1 ~]# systemctl restart haproxy.service 因为我们在ka1上配置了bind 192.168.10.240 而ka2没有该ip使用无法监听,所以我们需要打开我们两个主机的内裤参数
[root@ka1 ~]# vim /etc/sysctl.conf # sysctl settings are defined through files in # /usr/lib/sysctl.d/, /run/sysctl.d/, and /etc/sysctl.d/. # # Vendors settings live in /usr/lib/sysctl.d/. # To override a whole file, create a new file with the same in # /etc/sysctl.d/ and put new settings there. To override # only specific settings, add a file with a lexically later # name in /etc/sysctl.d/ and put new settings there. # # For more information, see sysctl.conf(5) and sysctl.d(5). net.ipv4.ip_nonlocal_bind = 1 ~ [root@ka1 ~]# sysctl -p net.ipv4.ip_nonlocal_bind = 1 # 即使本地没有这个ip也可以正常访问 # 刷新配置ka1和ka2配置相同。
[root@ka1 ~]# netstat -antlupe | grep haproxy tcp 0 0 0.0.0.0:5000 0.0.0.0:* LISTEN 0 217544 10669/haproxy tcp 0 0 192.168.10.240:80 0.0.0.0:* LISTEN 0 217546 10669/haproxy udp 0 0 0.0.0.0:43413 0.0.0.0:* 0 217545 10668/haproxy # 查看端口是否开启去掉在webserver1和webserver2上的vip,换原arp响应
[root@webserver1 ~]# vim /etc/sysctl.d/arp.conf net.ipv4.conf.all.arp_announce=0 net.ipv4.conf.all.arp_ignore=0 net.ipv4.conf.lo.arp_announce=0 net.ipv4.conf.lo.arp_ignore=0 [root@webserver1 ~]# sysctl -pwebserver1和webserver2配置相同
#virtual_server 192.168.10.240 80 { # delay_loop 6 # lb_algo wrr # lb_kind DR ## persistence_timeout 50 # protocol TCP #################################################### # real_server 192.168.10.220 80 { # weight 1 # HTTP_GET { # url { # path / # digest_code 200 # } # connect_timeout 3 # nb_get_retry 2 # delay_before_retry 2 # } # } #################################################### # real_server 192.168.10.230 80 { # weight 1 # HTTP_GET { # url { # path / # digest_code 200 # } # connect_timeout 3 # nb_get_retry 2 # delay_before_retry 2 # } # } 注:将之前实验修改的real server全部注释掉,和hapoxy有冲突,ka1和ka2配置相同
测试:

检测haproxy的命令
在ka1和ka2上安装killall软件包,ka1,ka2配置相同
[root@ka1 ~]# yum install psmisc -y [root@ka1 ~]# killall -0 haproxy [root@ka1 ~]# echo $? 0 [root@ka1 ~]# systemctl stop haproxy.service [root@ka1 ~]# killall -0 haproxy haproxy: no process found [root@ka1 ~]# echo $? 1 当haproxy调度器正常工作时我们使用killall -0 haproxy 他返回的值为0,当haoroxy停止工作时,他返回的值为非0,我们可以根据这一点来修改之前的脚本,来判断haproxy是否正常运行,从而达到keepalived检测haproxy状态,使用keepalived优先级根据harprixy的变化而变化,实现vip的漂移。
[root@ka1 ~]# vim /etc/keepalived/check_blue.sh #!/bin/bash killall -0 haproxy ka2也相同操作,我就用scp直接复制了
[root@ka1 ~]# vim /etc/keepalived/keepalived.conf vrrp_script check_haproxy { script "/etc/keepalived/check_blue.sh" interval 1 # 检测时间间隔为1秒 weight -30 # 如果检测不为0,优先级减30 fall 2 # 脚本执行两次,再者视为失败 rise 2 # 脚本连续两次执行成功,把服务器从失败转换为成功状态 timeout 2 # 脚本执行的超时时间 } vrrp_instance VI_1 { state MASTER interface ens33 # vip使用的真实设备是谁 virtual_router_id 100 # 虚拟路由id(唯一的) priority 100 advert_int 1 authentication { auth_type PASS # 发通告带的信息 auth_pass 1111 } virtual_ipaddress { # vip id # 设定网卡子接口 192.168.10.240/24 dev ens33 label ens33:0 } unicast_src_ip 192.168.10.170 unicast_peer { 192.168.10.180 } track_script { check_haproxy } 重启keepalived和haproxy,
此时因为ka1的优先级高于ka2,且ka1上的haproxy正常运行,使用vip仍然在ka1上
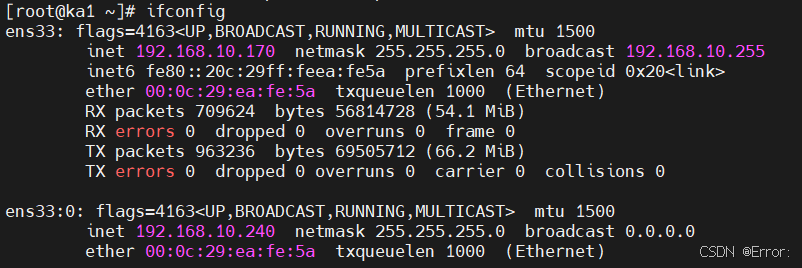
我们现在模拟故障,将ka1上的harproxy停掉,vip就会跑到ka2上
因为ka1上的haproxydown掉,脚本成功检测,返回值为非0,所以ka1上的优先级就会减30,变为70,此时的ka2上的优先级为80,所以vip就跑到了ka2上,在此期间,客户仍然可以正常访问,当我们ka1上的haproxy正常工作时,vip有会回到ka1上,因为我们设置的是2次脚本返回值为0,就把当前的harproxy标记为正常状态,优先级又回到了100