
阅读量:0
一、kafka-manager 简介
为了简化开发者和服务工程师维护Kafka集群的工作,yahoo构建了一个叫做Kafka管理器的基于Web工具,叫做 Kafka Manager。
这个管理工具可以很容易地发现分布在集群中的哪些topic分布不均匀,或者是分区在整个集群分布不均匀的的情况。
它支持管理多个集群、选择副本、副本重新分配以及创建Topic。同时,这个管理工具也是一个非常好的可以快速浏览这个集群的工具,有如下功能:
1.管理多个kafka集群
2.便捷的检查kafka集群状态(topics,brokers,备份分布情况,分区分布情况)
3.选择你要运行的副本
4.基于当前分区状况进行
5.可以选择topic配置并创建topic(0.8.1.1和0.8.2的配置不同)
6.删除topic(只支持0.8.2以上的版本并且要在broker配置中设置delete.topic.enable=true)
7.Topic list会指明哪些topic被删除(在0.8.2以上版本适用)
8.为已存在的topic增加分区
9.为已存在的topic更新配置
10.在多个topic上批量重分区
11.在多个topic上批量重分区(可选partition broker位置)
kafka-manager 项目地址:https://github.com/yahoo/kafka-manager
二、安装
1. 环境要求
1、jdk openjdk version "1.8.0_302" 2、kafka集群信息 服务器: 192.168.131.171:9092 192.168.131.171:9093 192.168.131.171:9094 软件: kafka_2.12-2.6.2 apache-zookeeper-3.5.9 2. 下载安装 kafka-manager
2.1 下载kafka-manager
想要查看和管理Kafka,完全使用命令并不方便,我们可以使用雅虎开源的Kafka-manager,GitHub地址如下:
https://github.com/yahoo/kafka-manager
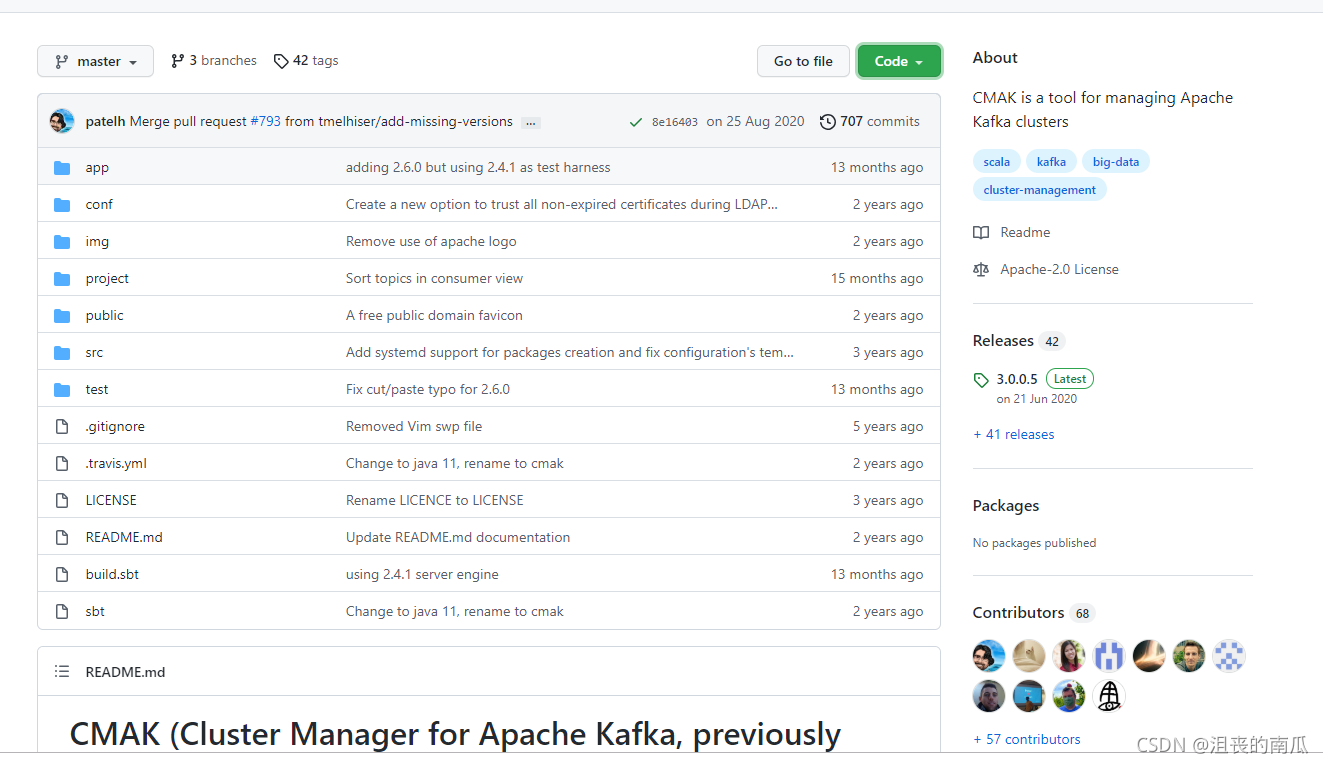
我们可以使用Git或者直接从Releaseshttps://github.com/yahoo/CMAK/releases中下载,此处从下面的地址下载 3.0.0.5 版本
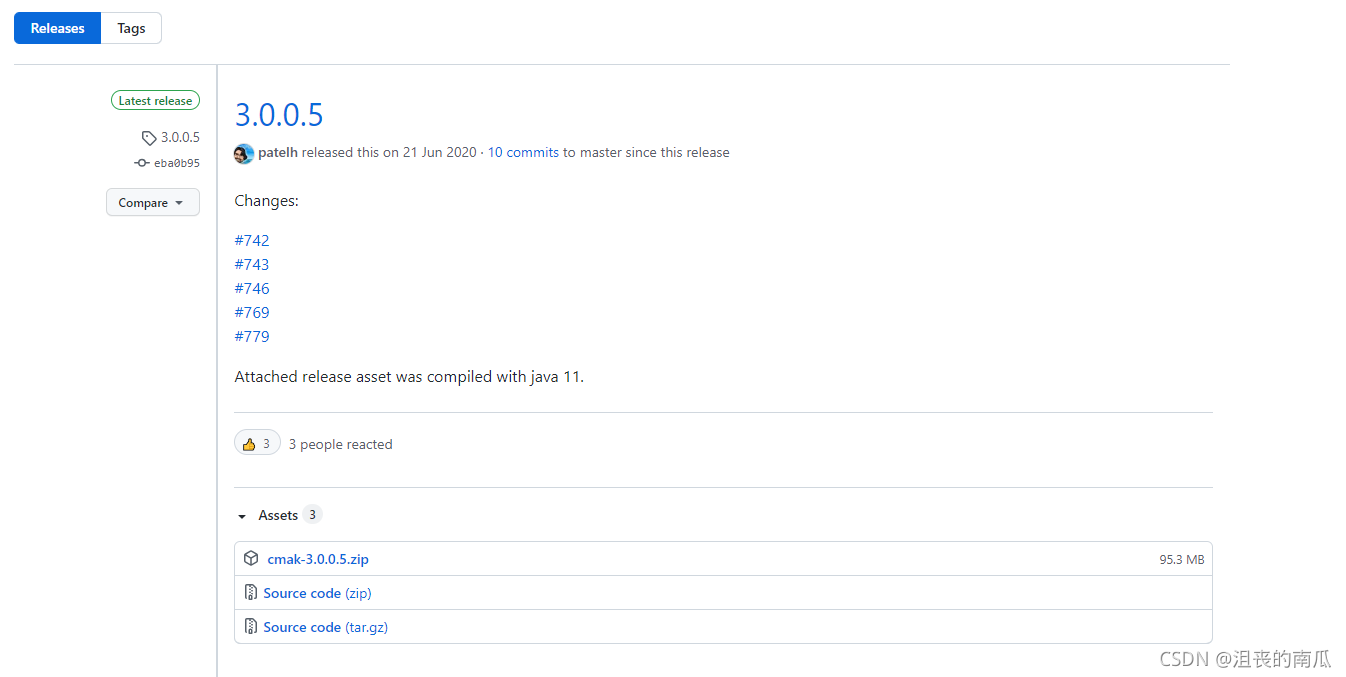
我们选择第一个zip包进行下载。下载完成后上传到Linux服务器上。
2.2 编译
进入到源码目录,执行./sbt clean dist 进行编译
编译完成后会生成一个kafka-manager-1.3.3.23.zip文件,这个文件就是编译后的文件
这个编译过程太漫长了… 没等到… 建议大家用下面编译好的。
注意:上面下载的是源码,下载后需要按照后面步骤进行编译。如果觉得麻烦,可以直接从下面地址下载编译好的 kafka-manager-1.3.3.7.zip。
链接:https://pan.baidu.com/s/1qYifoa4
密码:el4o

我这里使用的是百度网盘中编译好的kafka-manager-1.3.3.7.zip。
2.3 解压
我们创建一个kafka-manager的文件夹,然后进行解压:

unzip kafka-manager-2.0.0.2.zip 
2.4 修改配置 conf/application.conf
将kafka-manager.zkhosts="kafka-manager-zookeeper:2181"中的zookeeper地址换成自己安装的。
vi conf/application.conf # kafka-manager.zkhosts="localhost:2181" kafka-manager.zkhosts="192.168.131.171:2181" # 如果是集群,参考如下 # kafka-manager.zkhosts="10.0.0.50:2181,10.0.0.60:2181,10.0.0.70:2181" 只需要修改zk的连接地址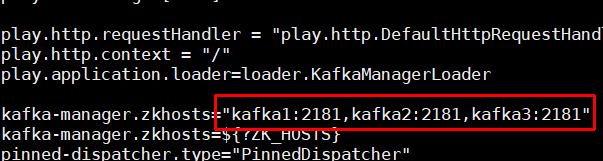
2.5 启动 kafka manager
确保自己本地的ZK已经启动了之后,我们来启动Kafka-manager。
kafka-manager 默认的端口是9000。
可通过 -Dhttp.port,指定端口; -Dconfig.file=conf/application.conf指定配置文件:
我们使用默认端口号启动吧:
#前台启动 bin/kafka-manager -Dhttp.port=8081 后台启动 nohup bin/kafka-manager -Dconfig.file=conf/application.conf -Dhttp.port=8081 >/dev/null 2>&1 & 输入地址:localhost:8081即可 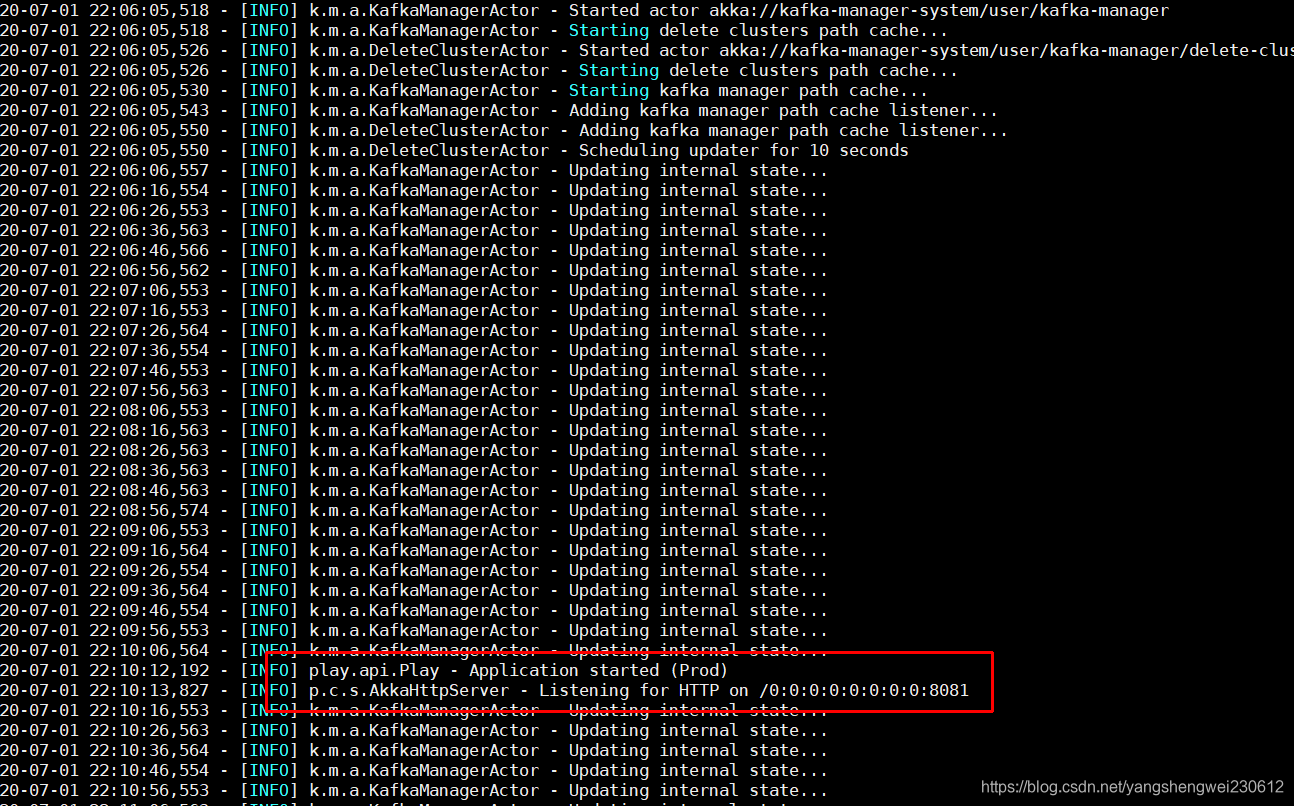
我们使用bin/kafka-manager这个命令来启动,会使用默认配置文件和端口号9000.
启动完毕后可以查看端口是否启动,由于启动过程需要一段时间,端口起来的时间可能会延后。
使用ip地址:端口访问测试
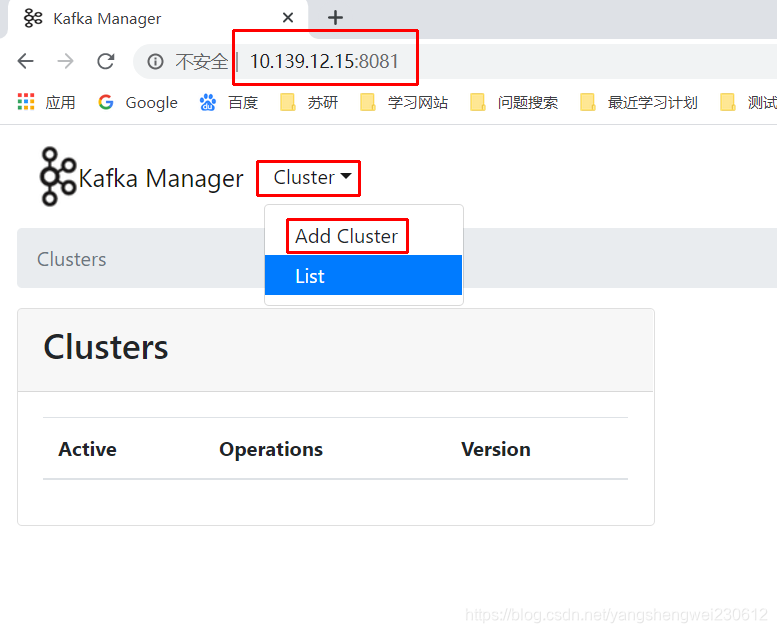
可以看到,此时已经启动成功了。
三、测试 kafka-mamager
3.1新建 Cluster
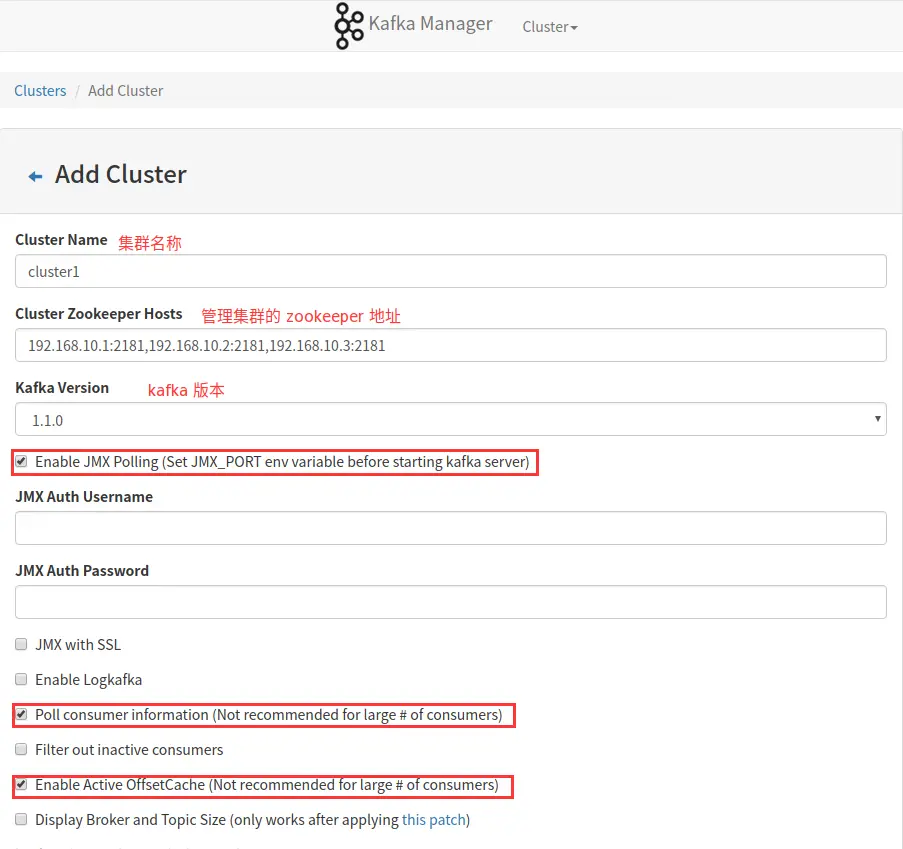
点击【Cluster】>【Add Cluster】打开如下添加集群的配置界面:
输入集群的名字(如Kafka-Cluster-1)和 Zookeeper 服务器地址(如localhost:2181),选择最接近的Kafka版本(如0.8.1.1)
注意:如果没有在 Kafka 中配置过 JMX_PORT,千万不要选择第一个复选框。
Enable JMX Polling
如果选择了该复选框,Kafka-manager 可能会无法启动。
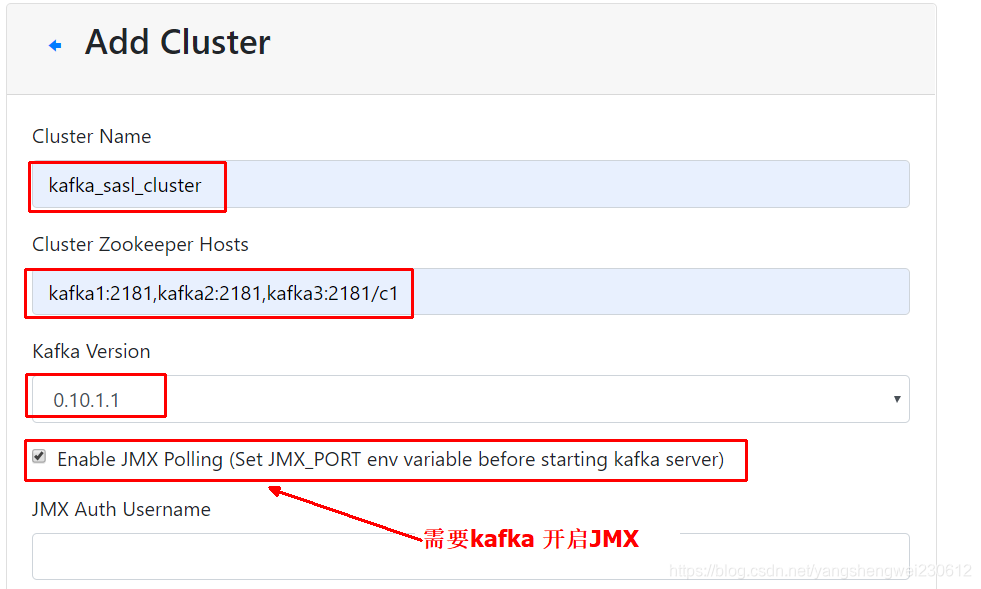
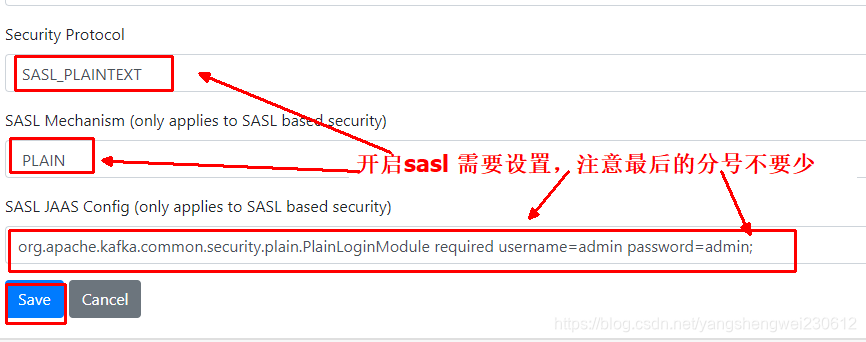
其他broker的配置可以根据自己需要进行配置,默认情况下,点击【保存】时,会提示几个默认值为1的配置错误,需要配置为>=2的值。提示如下。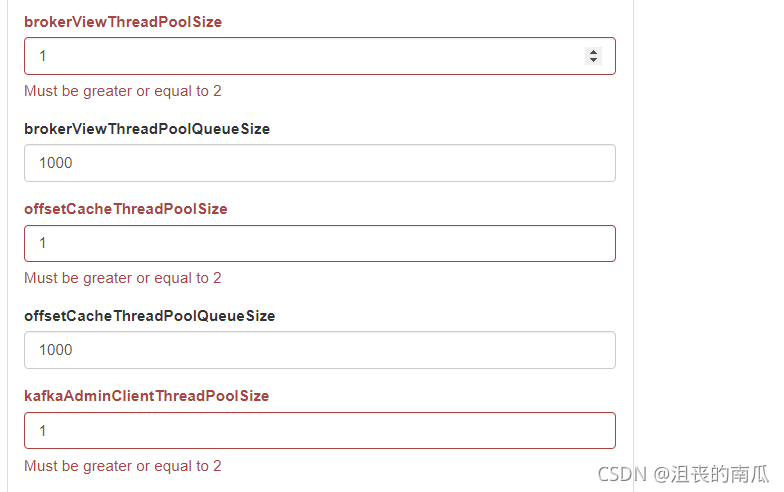
设置SASL成功会看到kafka manager 日志打印如下信息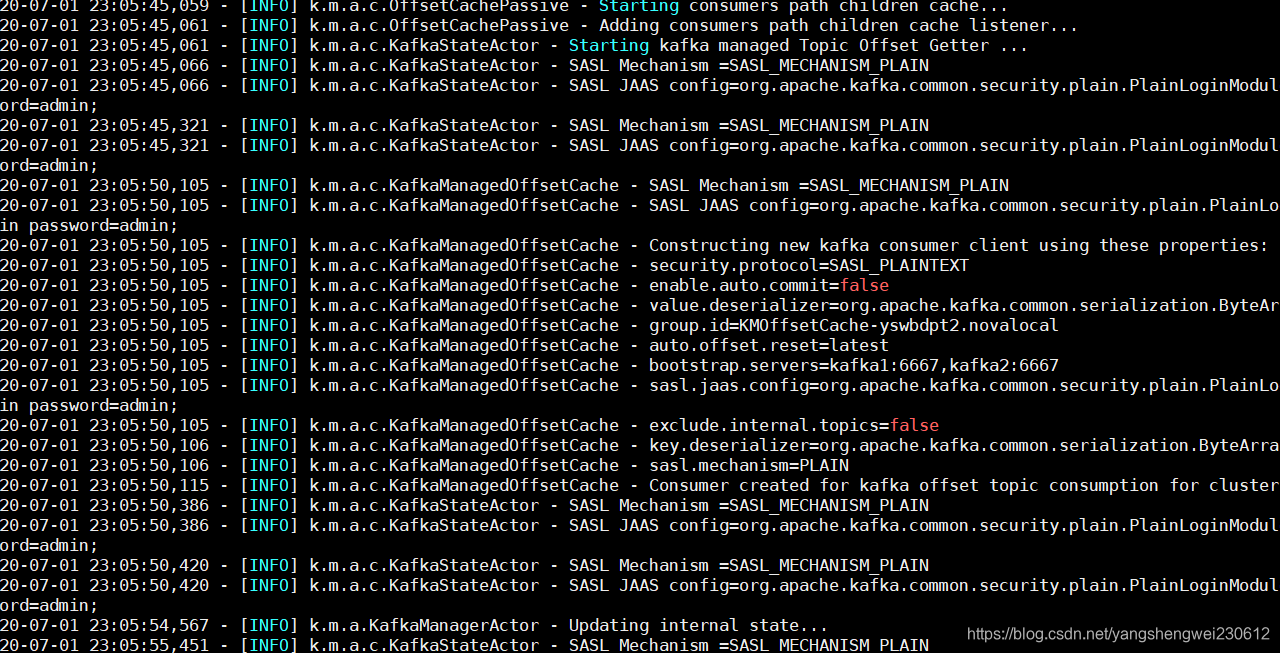
3.2 监控信息
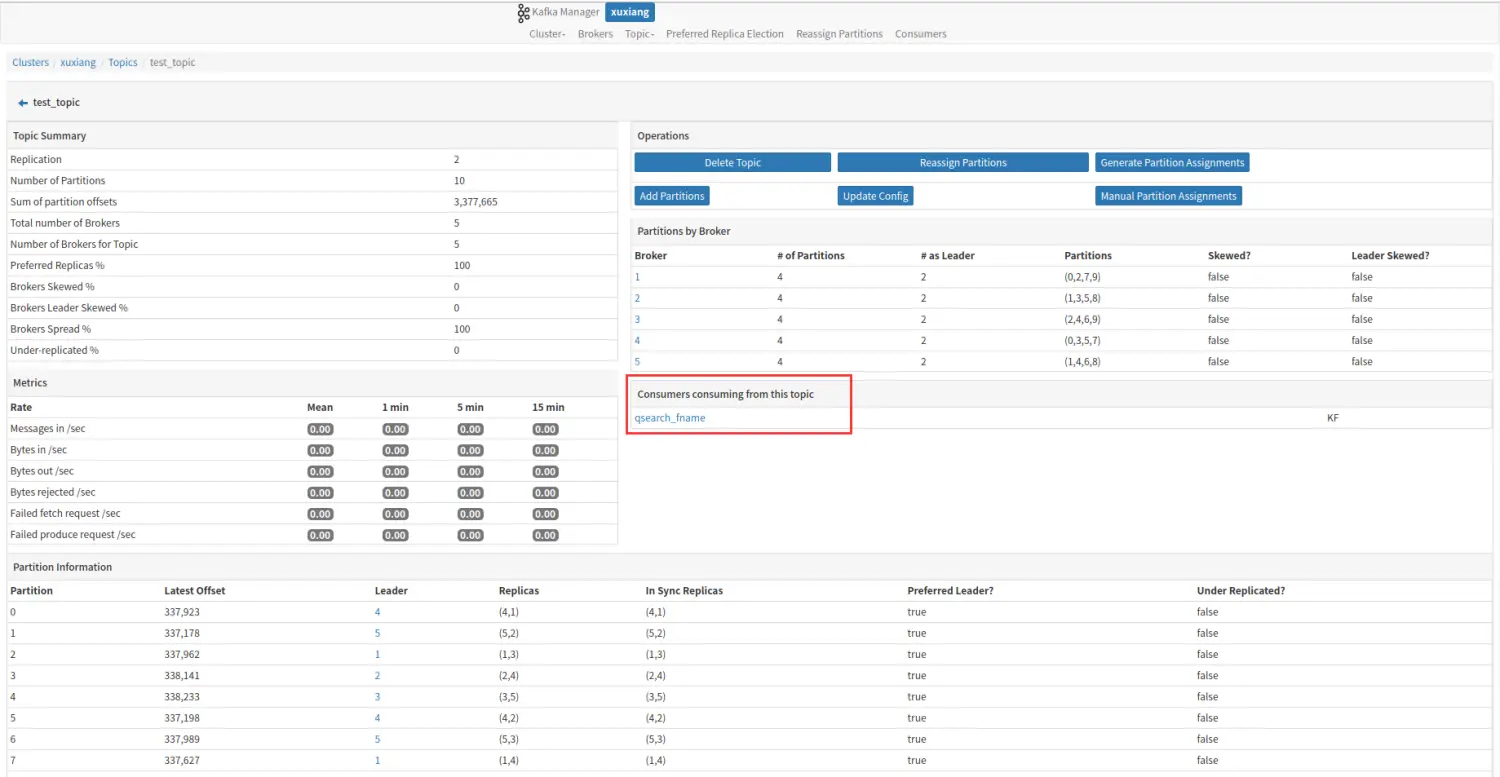
3.2.1 topic 相关信息
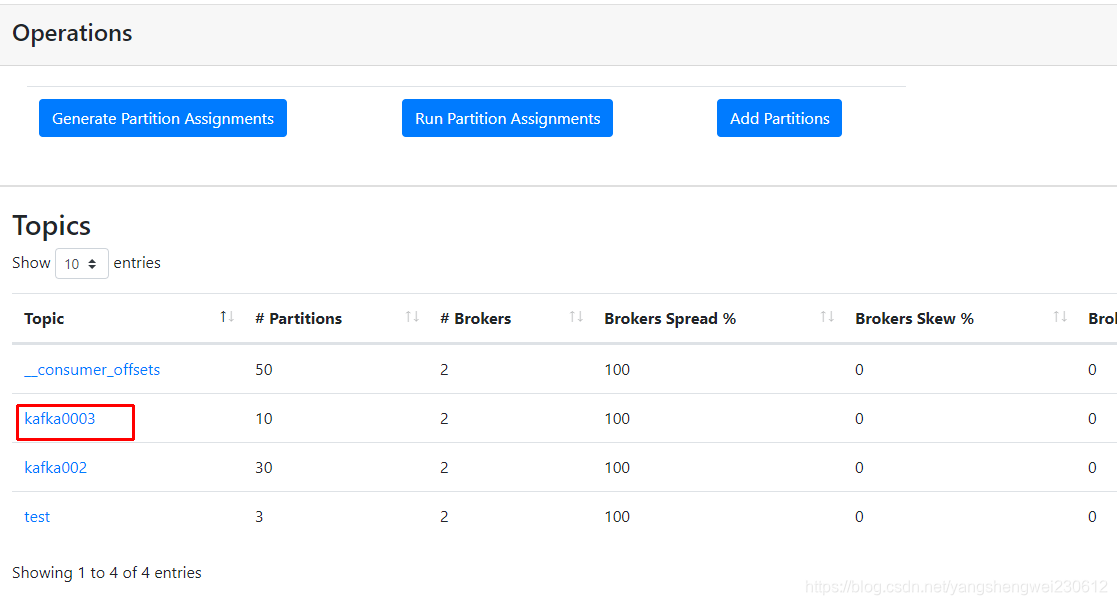
3.2.2 集群相关信息
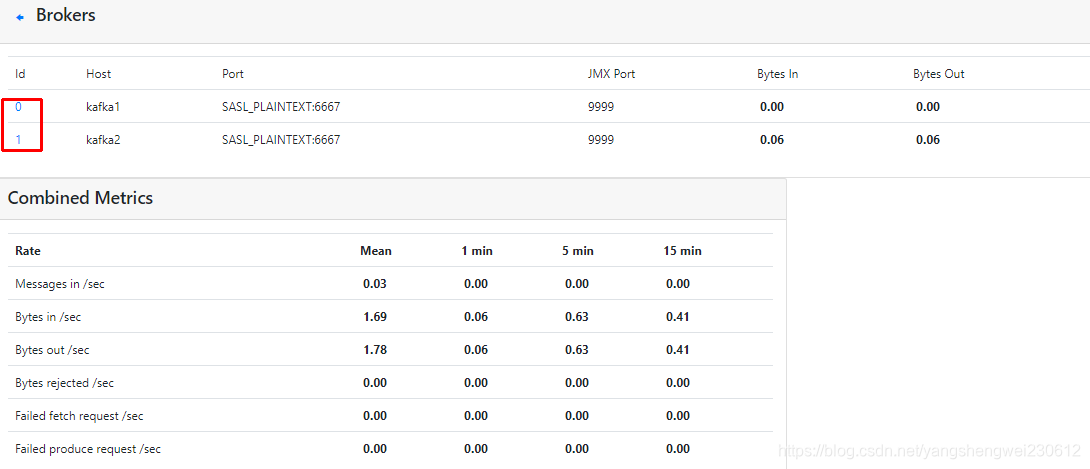
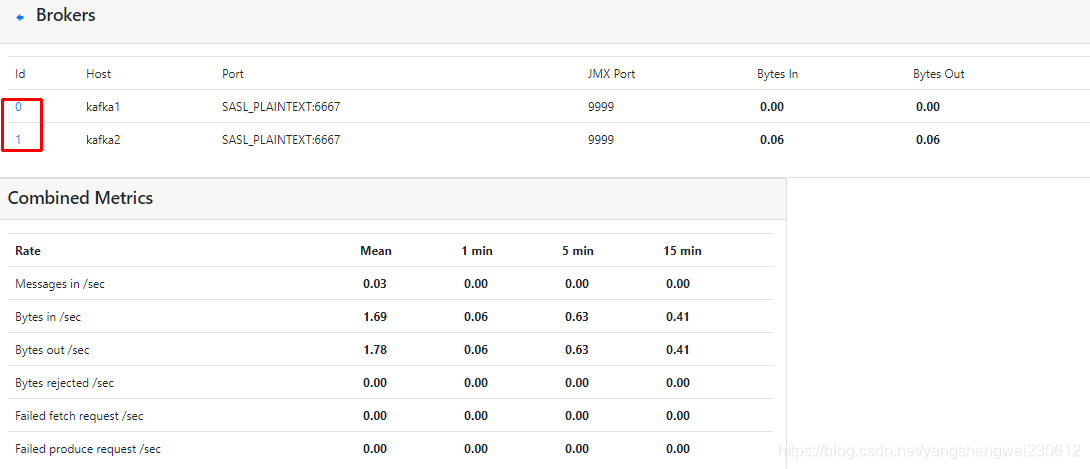
3.2.3 broker相关信息
3.3 添加集群
3.3.1 常用参数说明
下面已常用的选项作说明
Enable JMX Polling
是否开启 JMX 轮训,该部分直接影响部分 kafka broker 和 topic 监控指标指标的获取(生效的前提是 kafka 启动时开启了 JMX_PORT。主要影响如下之指标的查看:
Poll consumer information
是否开启获取消费信息,直接影响能够在消费者页面和 topic 页面查看消费信息。
Enable Active OffsetCache
是否开启 offset 缓存,决定 kafka-manager 是否缓存住 topic 的相关偏移量。
3.3.2 其余参数说明
| 参数名 | 参数说明 | 默认值 | 备注 |
|---|---|---|---|
| brokerViewUpdatePeriodSeconds | Broker视图周期更新时间/单位(s) | 30 | |
| clusterManagerThreadPoolSize | 集群管理线程池大小 | 2 | |
| clusterManagerThreadPoolQueueSize | 集群管理线程池列队大小 | 100 | |
| KafkaCommandThreadPoolSize | Kafka命令线程池大小 | 2 | |
| logkafkaCommandThreadPoolQueueSize | logkafka命令线程池列队大小 | 100 | |
| logkafkaUpdatePeriodSeconds | Logkafka周期更新时间/单位(s) | 30 | |
| partitionOffsetCacheTimeoutSecs | Partition Offset缓存过期时间/单位(s) | 5 | |
| brokerViewThreadPoolSize | Broker视图线程池大小 | 8 | 3 * number_of_brokers |
| brokerViewThreadPoolQueue Size | Broker视图线程池队列大小 | 1000 | 3 * total # of partitions across all topics |
| offsetCacheThreadPoolSize | Offset缓存线程池大小 | 8 | |
| offsetCacheThreadPoolQueueSize | Offset缓存线程池列队大小 | 1000 | |
| kafkaAdminClientThreadPoolSize | Kafka管理客户端线程池大小 | 8 | |
| kafkaAdminClientTheadPoolQueue Sizec | Kafka管理客户端线程池队列大小 | 1000 | |
| kafkaManagedOffsetMetadataCheckMillis | Offset元数据检查时间 | 30000 | (这部分解释属自己理解) |
| kafkaManagedOffsetGroupCacheSize | Offset组缓存大小 | 100000 | (这部分解释属自己理解) |
| kafkaManagedOffsetGroupExpireDays | Offset组缓存保存时间 | 7 | (这部分解释属自己理解) |
| Security Protocol | 安全协议 | PLAINTEXT | [SASL_PLAINTEXT,SASL_SSL,SSL] |
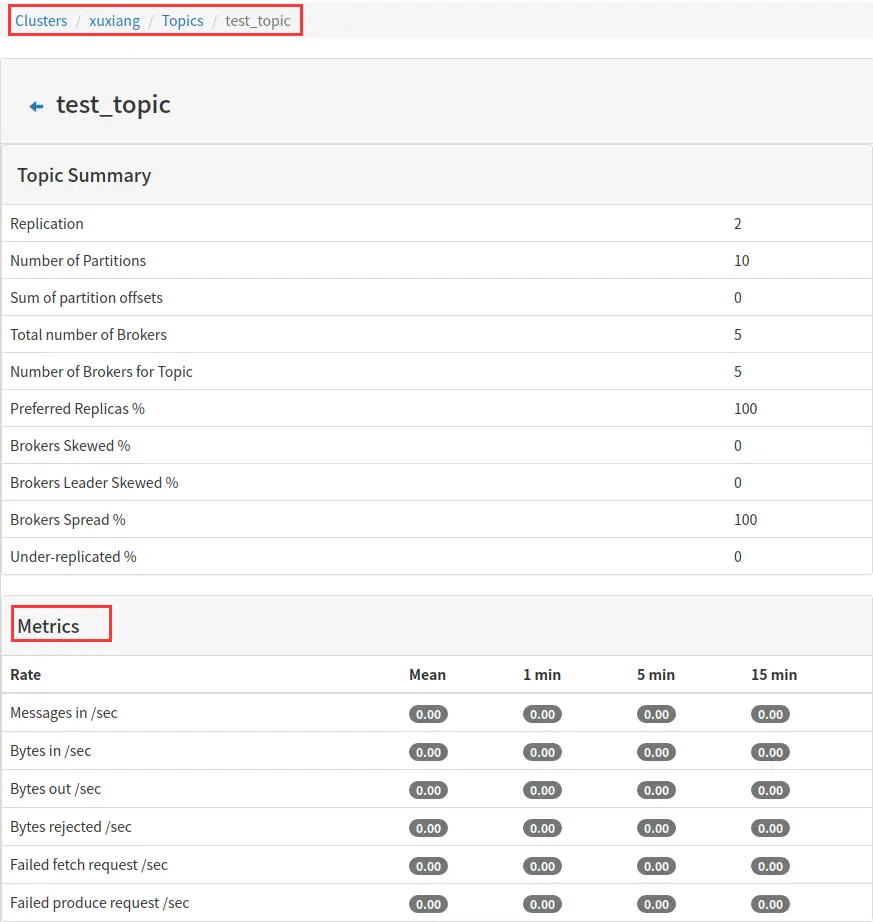
3.3 topic 的管理
3.3.1 topic 列表
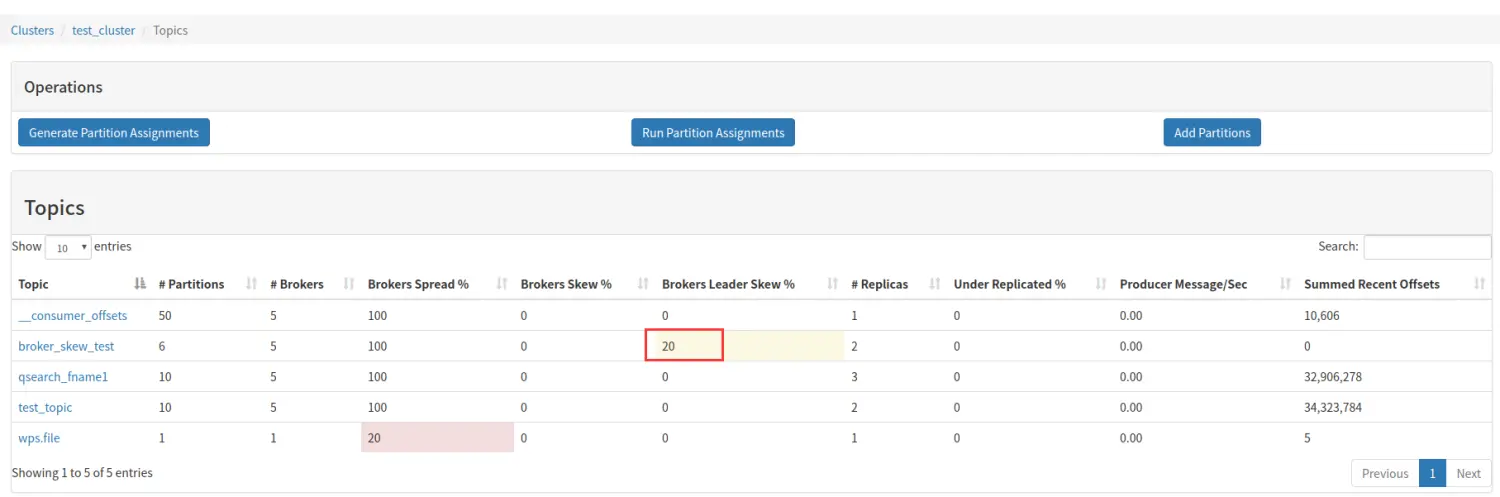
下面对画方框的三列做着重解释。
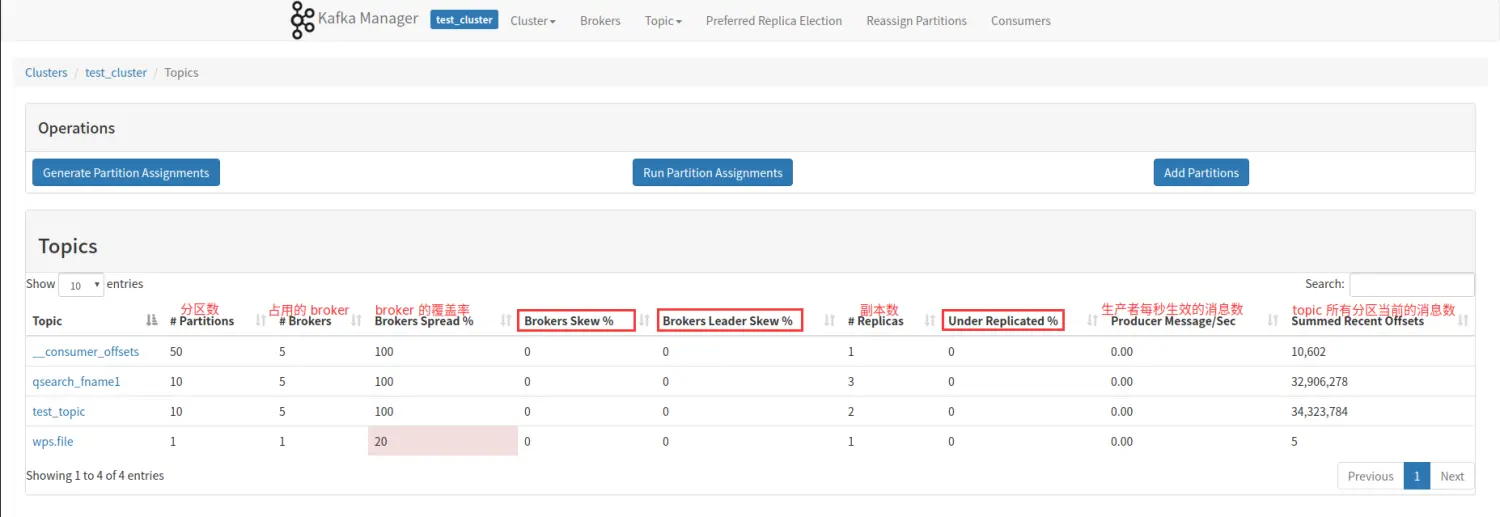
Brokers Skew% (broker 倾斜率)
该 topic 占有的 broker 中,拥有超过该 topic 平均分区数的 broker 所占的比重。举个例子说明:
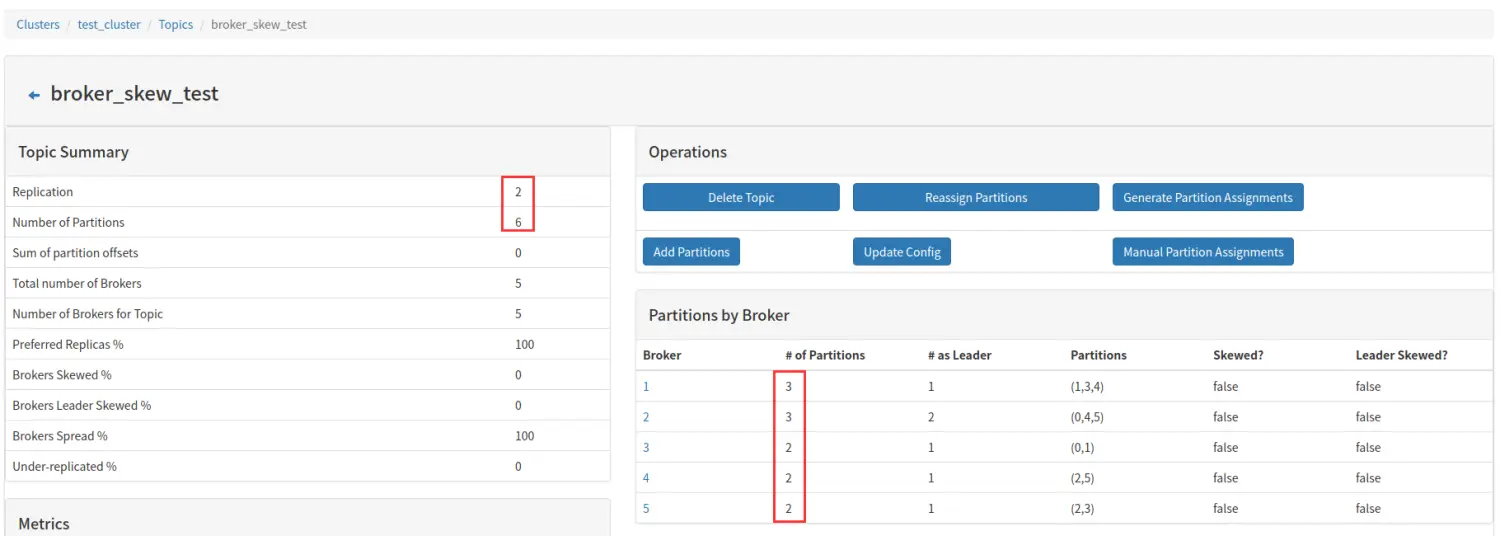
上图,我们以一个 6 个分区,2 个副本的 topic 举例,该 topic 一共 6 * 2 = 12 个 分区,分布在 5 个 broker 上,平均一个 broker 应该拥有 2.4 个分区,因为分区为整数,所以 2 个或者 3 个都是属于平均范围,5 个 broker 并没有那个拥有超过平均分区数的,所以 Brokers Skew% 为 0。
如果此时,我将 broker 1 上的分区 1 的副本移动到 broker 2 上,如下图所示:
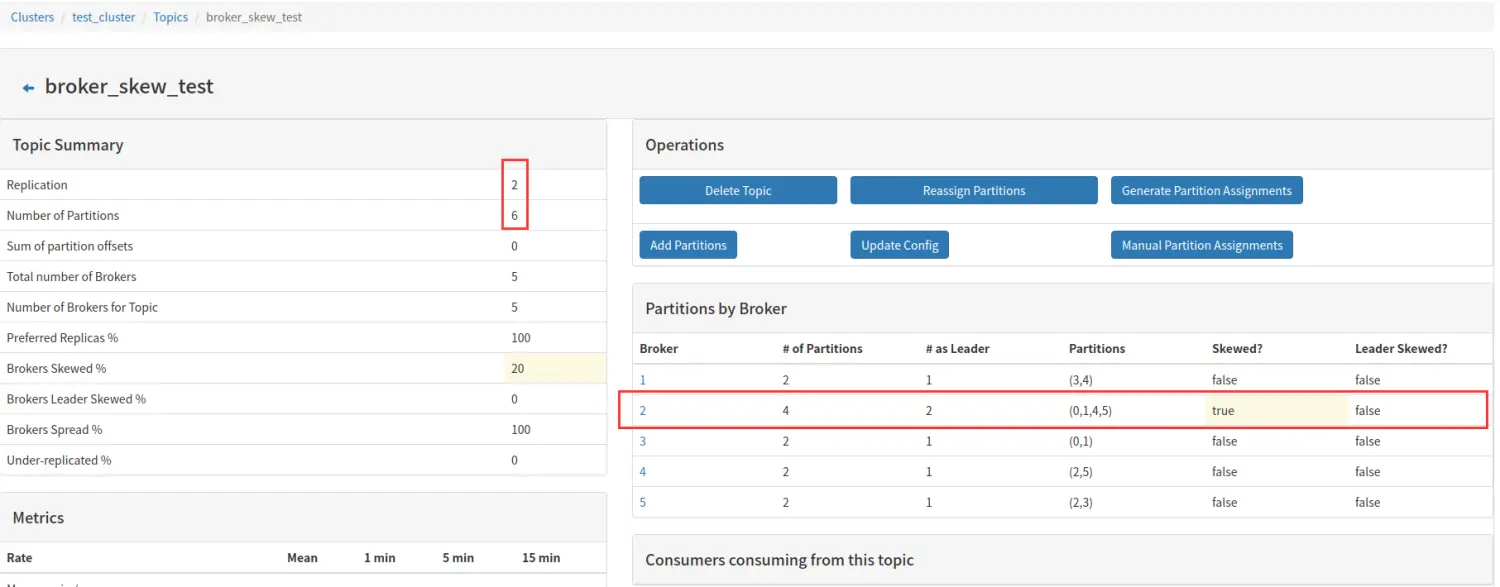
上图,broker 2 上拥有 4 个分区,超过平均的 2 个或 3 个的平均水平,broker 2 就倾斜了,broker 倾斜率 1/5=20%。
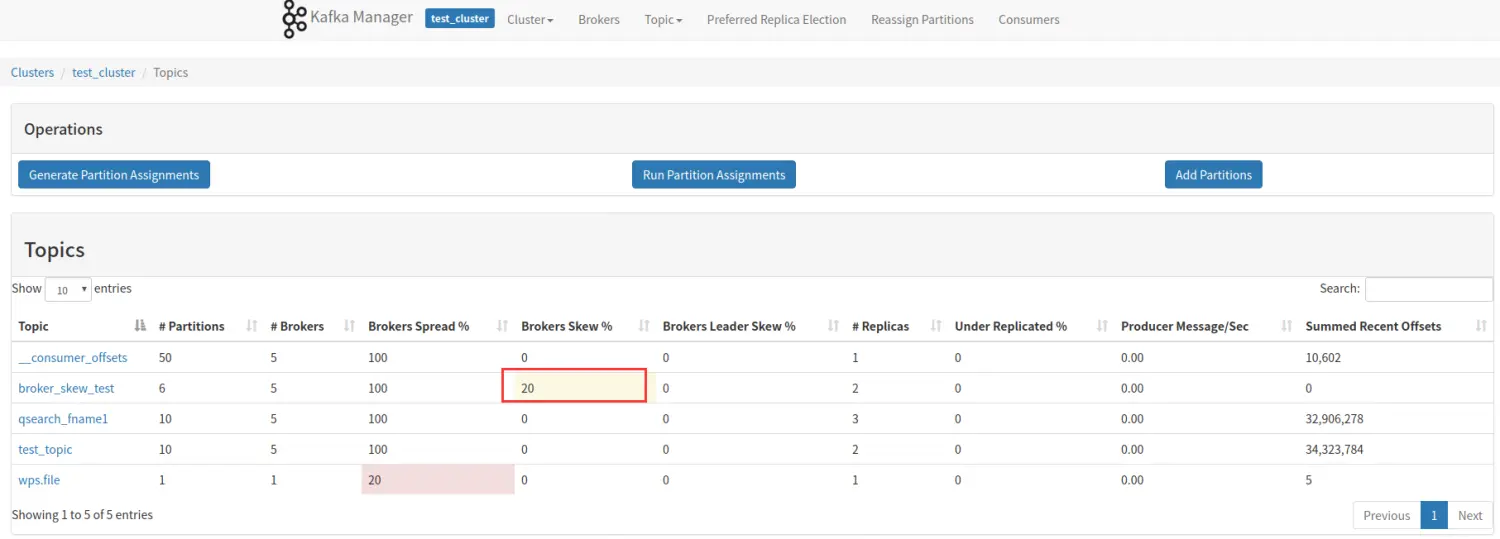
注意如下这种情况也是不计算作倾斜的。
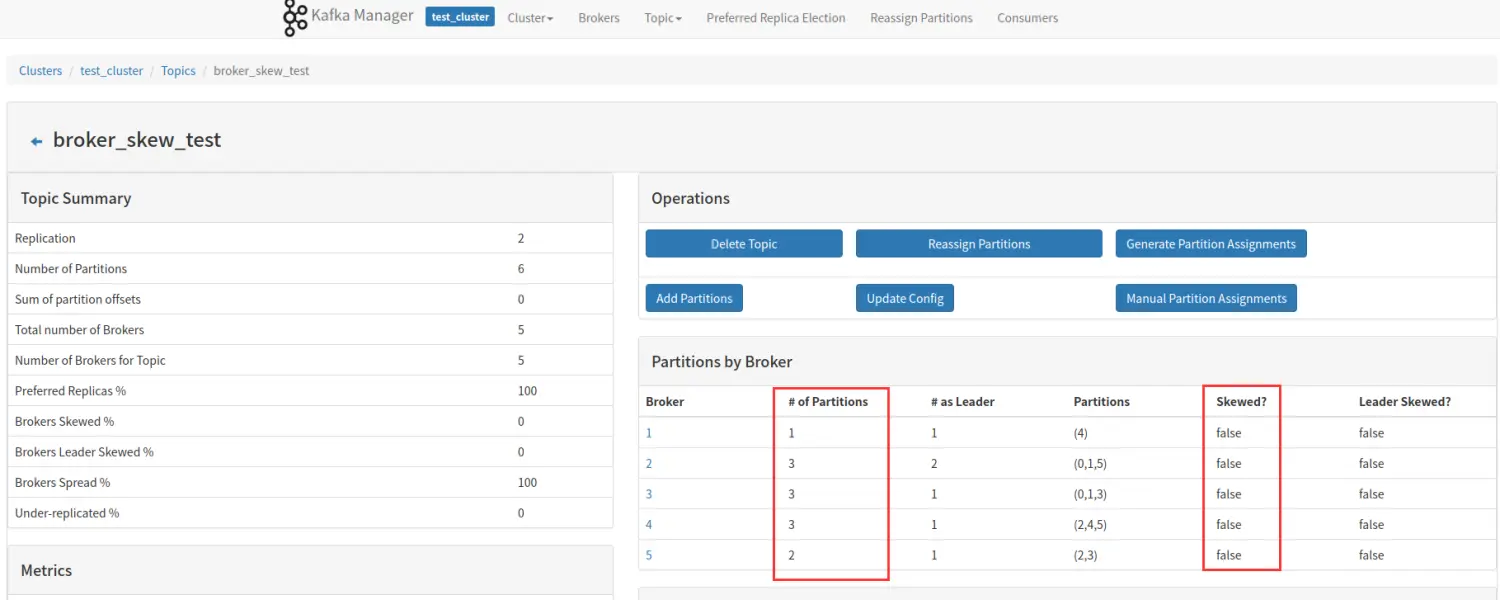
Brokers Leader Skew% (broker leader 分区倾斜率)
该 topic 占有的 broker 中,拥有超过该 topic 平均 Leader 分区数的 broker 所占的比重。同样举个例子说明:
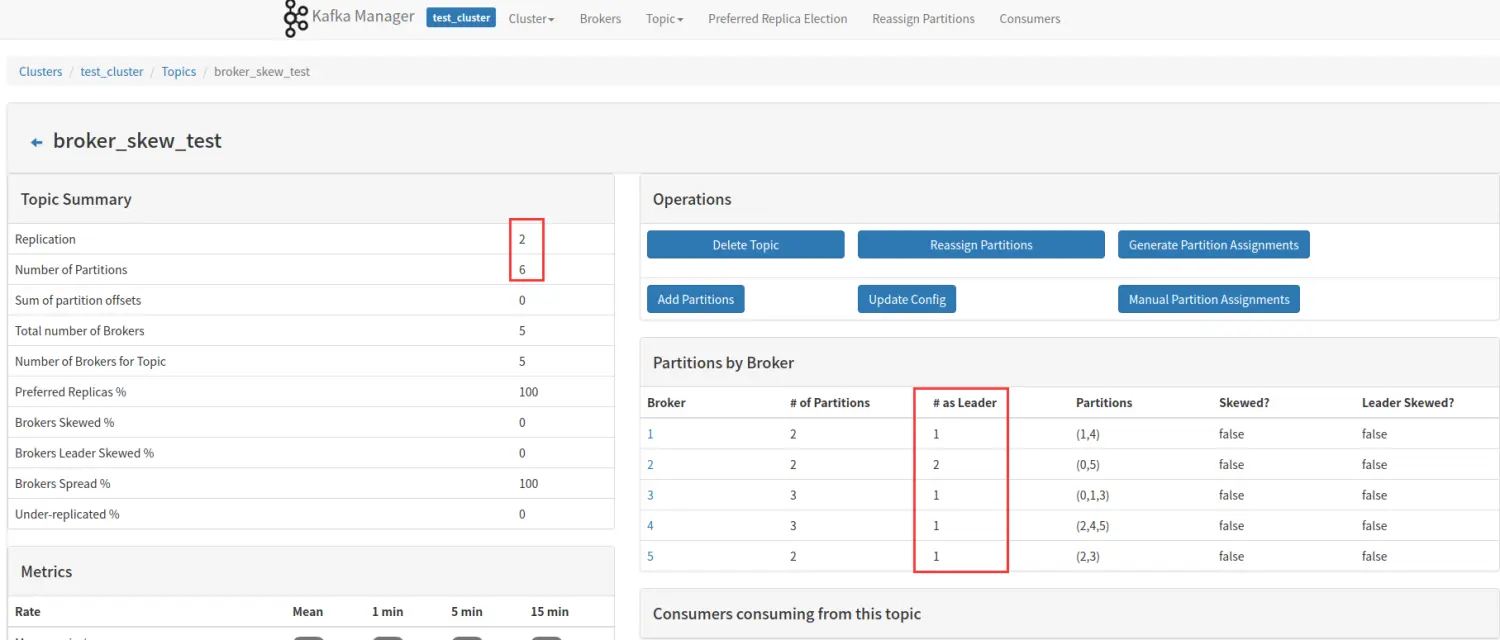
我们还是以一个 6 个分区,2 个副本的 topic 举例,该 topic 一共有 6 个 Leader 分区,分布在 5 个 broker 上,平均一个 broker 应该拥有 1.2 个 Leader 分区,因为分区为整数,所以 1 个或者 2 个都是属于平均范围,如图所示,5 个 broker 没有那个拥有超过 2 个的 Leader 分区,所以 Brokers Leader Skew% 为 0。
如果此时,我们将 broker3 的 Leader 分区移动到 broker2,如下图所示:
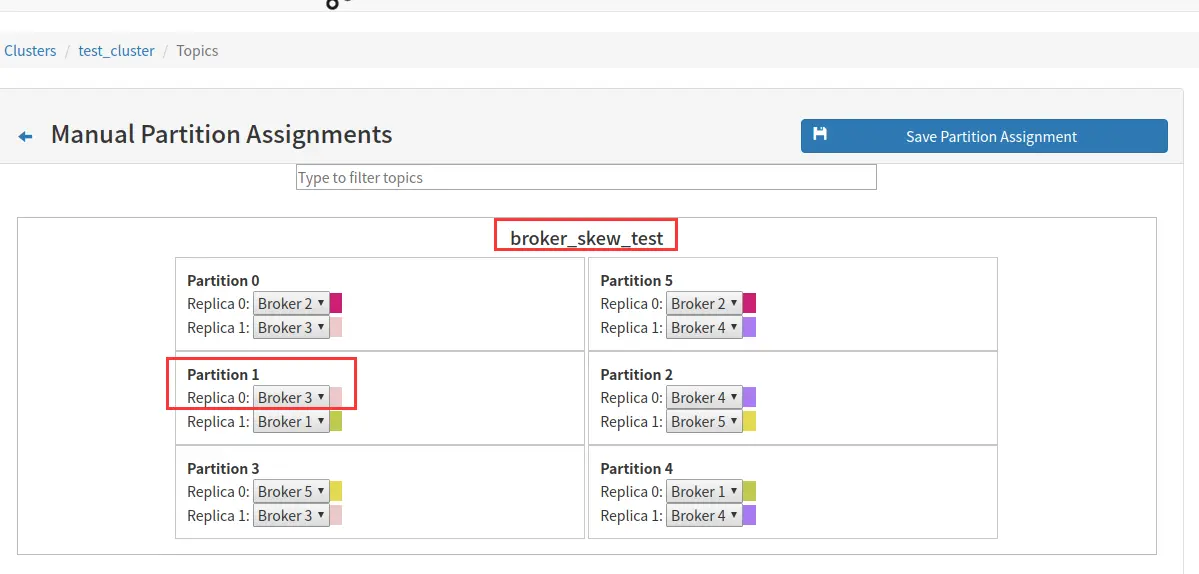
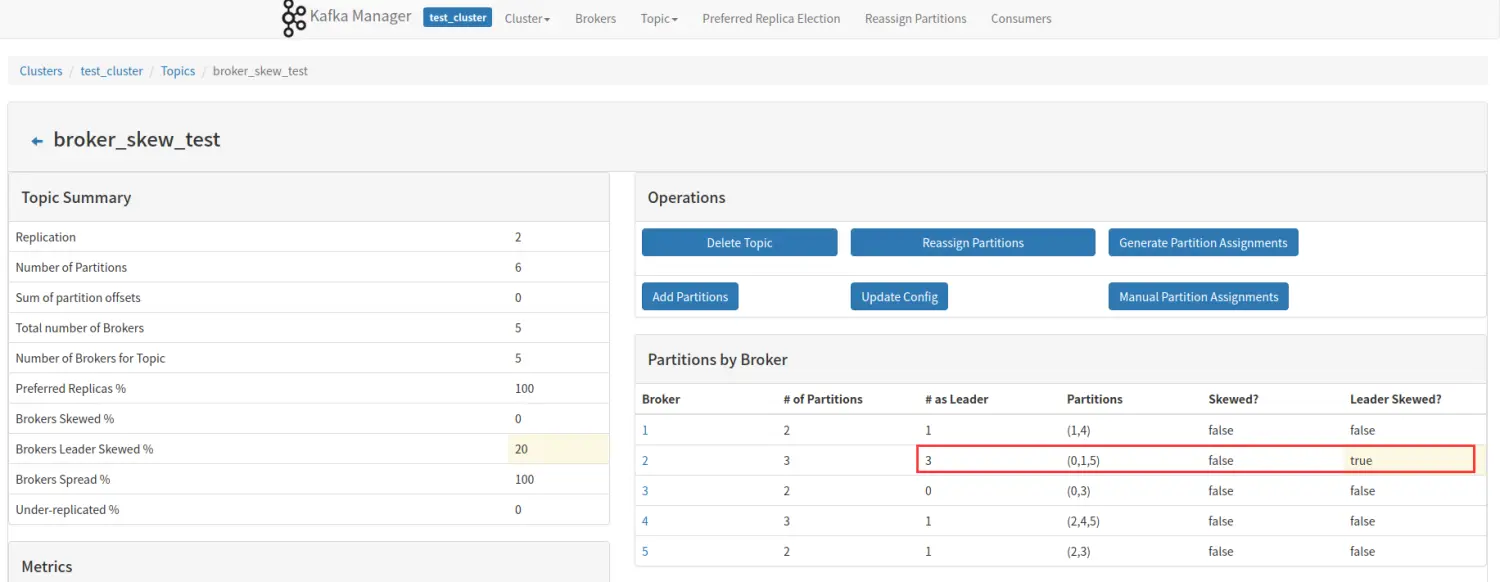
此时,broker2 拥有 3 个 leader 分区,超过平均范围的 2 个,所以 broker2 就 Leader 分区倾斜了,倾斜率 1/5=20%。
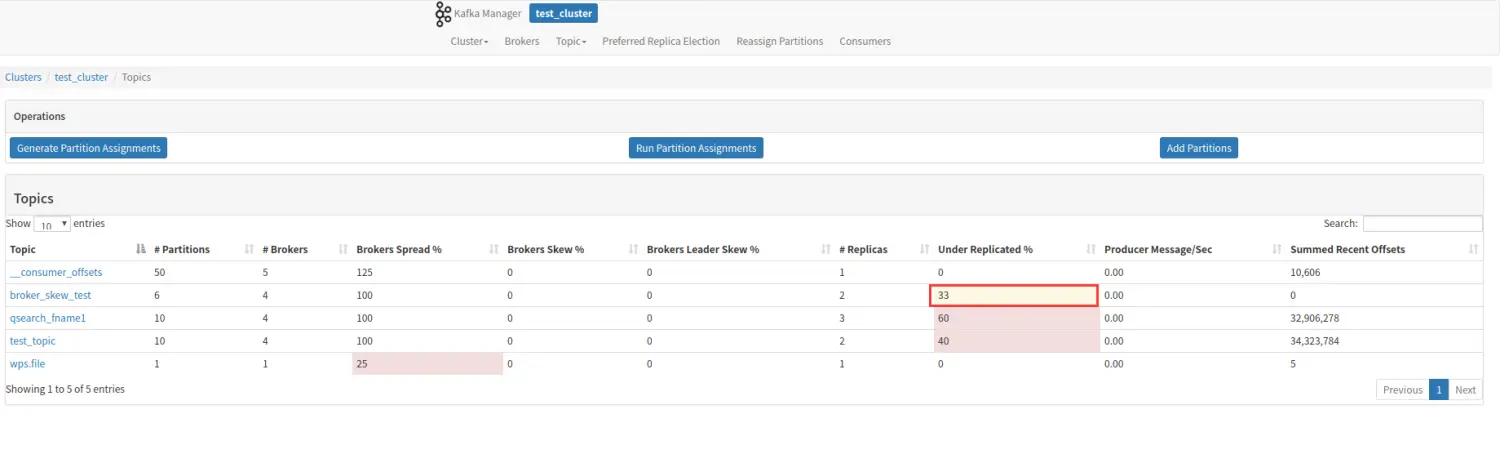
- Under Replicated%
该 topic 下的 partition,其中副本处于失效或者失败的比率。失败或者失效是指副本不处于 ISR 队列中。目前控制副本是否处于 ISR 中由 replica.log.max.ms 这个参数控制。
replica.log.max.ms: 如果一个follower在这个时间内没有发送fetch请求或消费leader日志到结束的offset,leader将从ISR中移除这个follower,并认为这个follower已经挂了,默认值 10000 ms
用下图举例说明:
broker1 此时拥有 partition1 和 partition4,其中 partition4 时 Leader,partition1 是副本,如果此时 broker 故障不可用,则会出现如下情况:
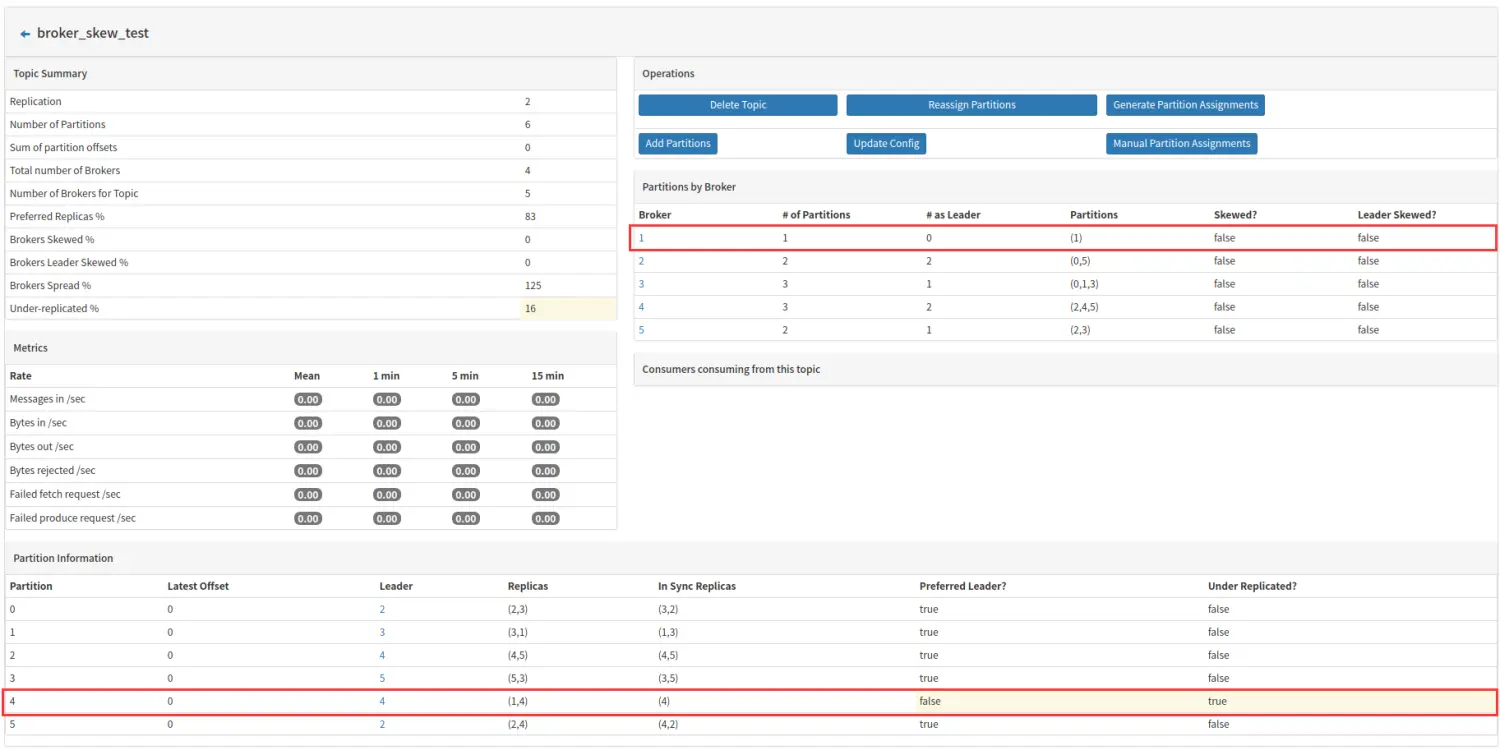
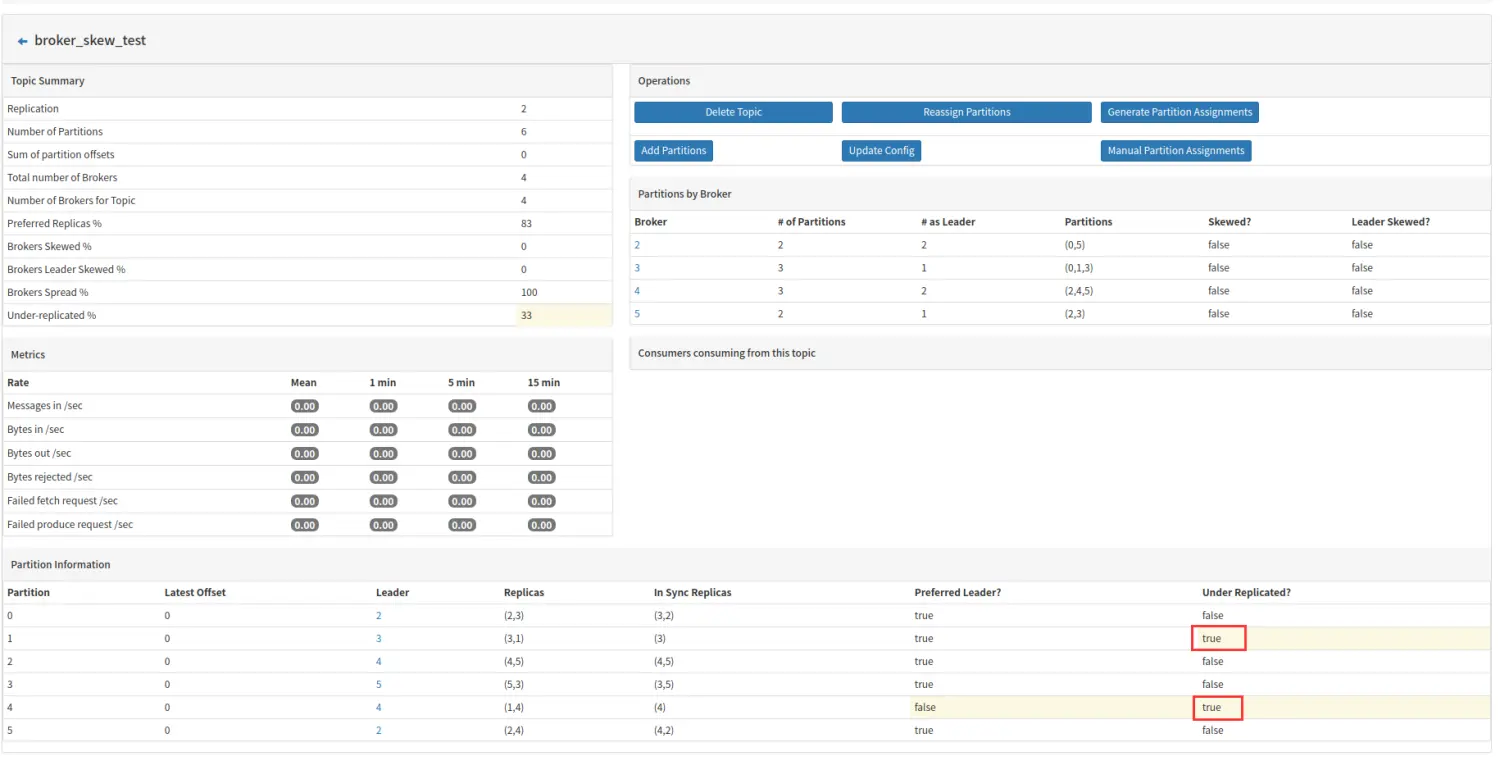
上述两张图片时接连展现,先是发现borker1 上 partition4 这个 Leader 分区失效,继而从 ISR 队列中取出 broker4 上的副本作为 Leader 分区,然后在后期同步检测过程中发现broker1 上 partition1 这个副本失效。最后导致的结果就是 partition1 和 partition4 都出于副本失效或者失败的状态。此时 Under Replicated 的数值为:2/6=33%。
3.3.2 总结
上面三个参数对于衡量 topic 的稳定性有重要的影响:
Broker Skew: 反映 broker 的 I/O 压力,broker 上有过多的副本时,相对于其他 broker ,该 broker 频繁的从 Leader 分区 fetch 抓取数据,磁盘操作相对于其他 broker 要多,如果该指标过高,说明 topic 的分区均不不好,topic 的稳定性弱;
Broker Leader Skew:数据的生产和消费进程都至于 Leader 分区打交道,如果 broker 的 Leader 分区过多,该 broker 的数据流入和流出相对于其他 broker 均要大,该指标过高,说明 topic 的分流做的不够好;
Under Replicated: 该指标过高时,表明 topic 的数据容易丢失,数据没有复制到足够的 broker 上。
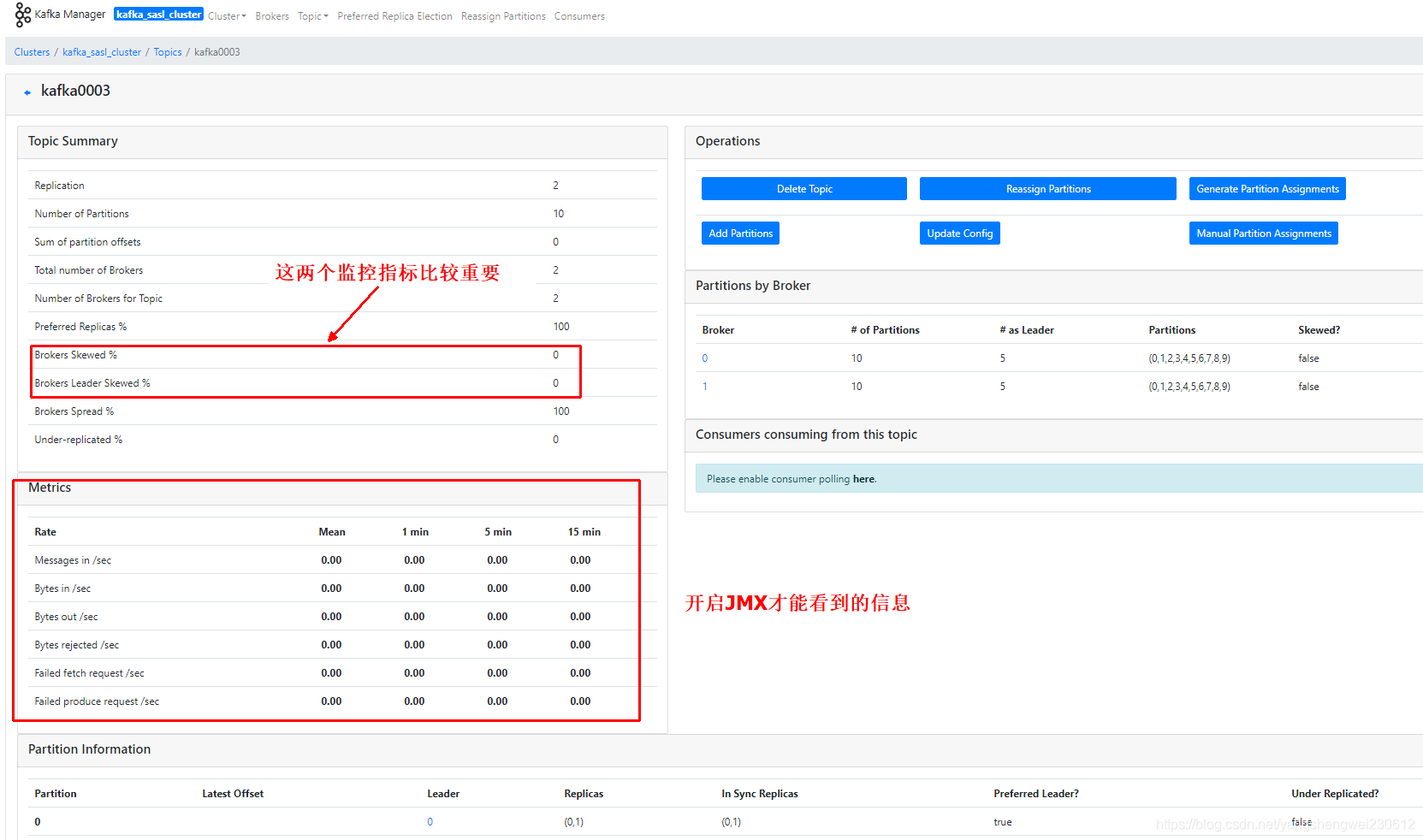
3.4 topic 详情
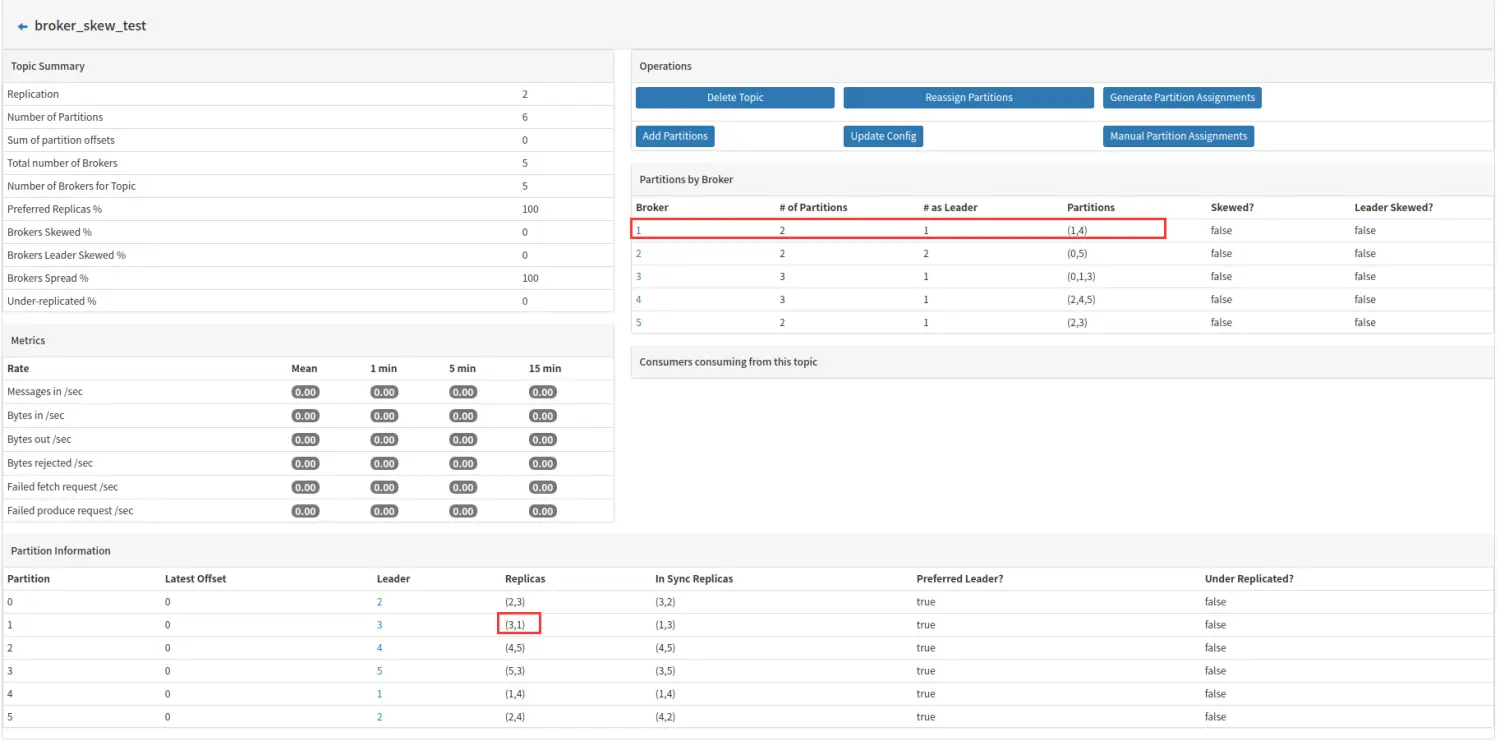
下面着重讲述红框部分:
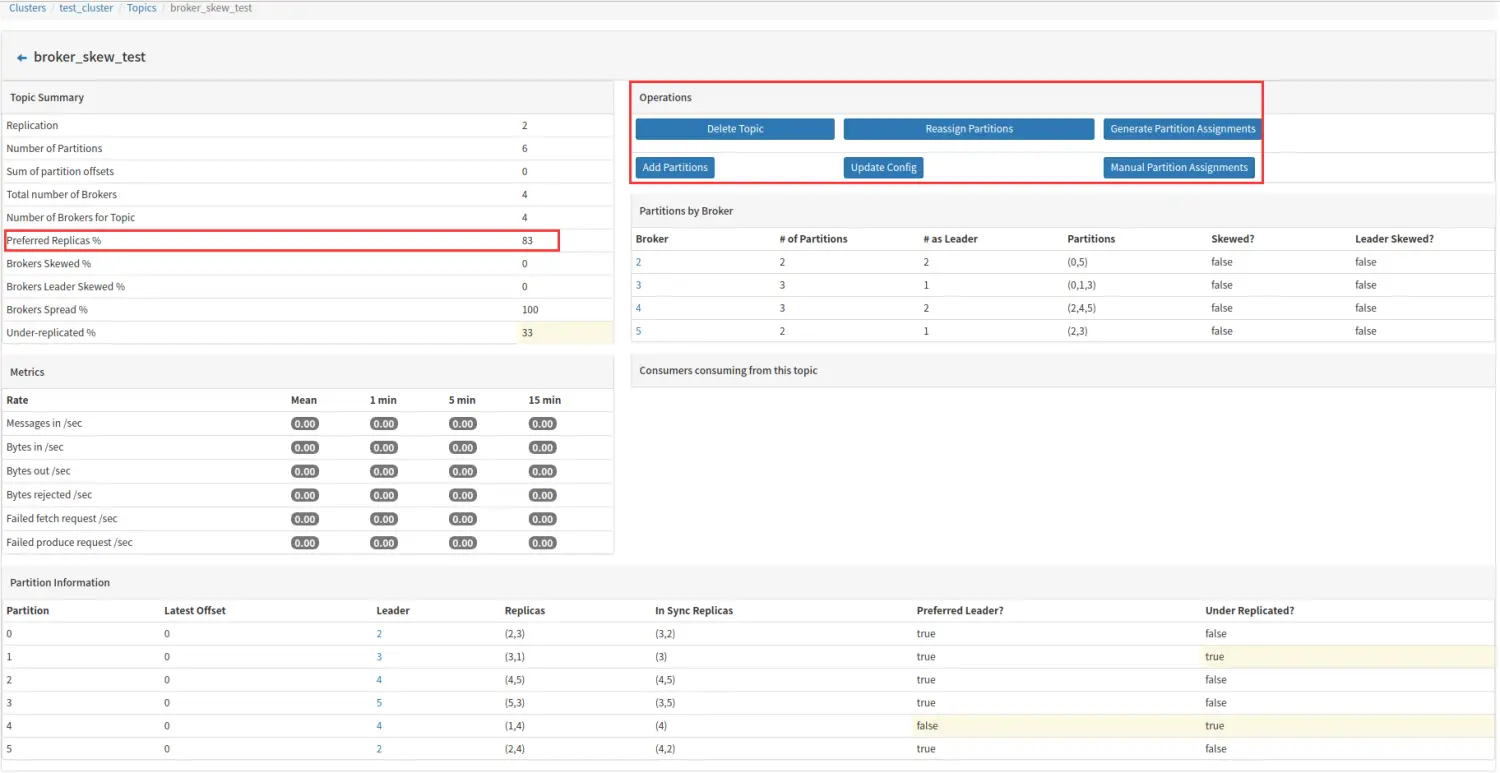
Preferred Replicas
分区的副本中,采用副本列表中的第一个副本作为 Leader 的所占的比重,如上图,6 个副本组,其中只有 partition4 不是采用副本中的第一个在 broker1 中的分区作为 leader 分区,所以 Preferred Replicas 的值为 5/6=83%。

In an ideal scenario, the leader for a given partition should be the “preferred replica”. This guarantees that the leadership load across the brokers in a cluster are evenly balanced.
上述是关于“优先副本”的相关描述,即在理想的状态下,分区的 leader 最好是 “优先副本”,这样有利于保证集群中 broker 的领导权比较均衡。重新均衡集群的 leadership 可采用 kafka manager 提供的工具:
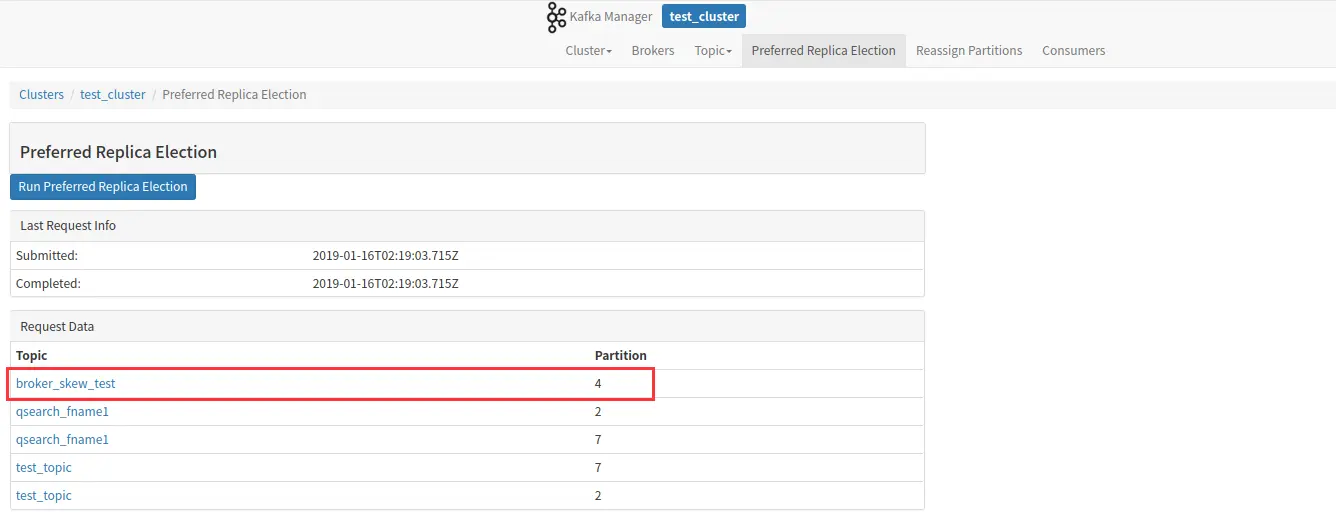
3.4.1 topic 操作
| 操作 | 说明 |
|---|---|
| Delete Topic | 删除 topic |
| Reassign Partitions | 平衡集群负载 |
| Add Partitions | 增加分区 |
| Update Config | Topic 配置信息更新 |
| Manual Partition Assignments | 手动为每个分区下的副本分配 broker |
| Generate Partition Assignments | 系统自动为每个分区下的副本分配 broker |
一般而言,手动调整、系统自动分配分区和添加分区之后,都需要调用 Reassign Partition。
Manual Partition Assignments
一般当有 Broker Skew 时或者 Broker Leader Skew 后可以借助该功能进行调整,本文前面的 Broker Skew 和 Broker Leader Skew 的说明都借助了该工具。
例如将下图中的 broker1 的分区4 移动到 broker2 上。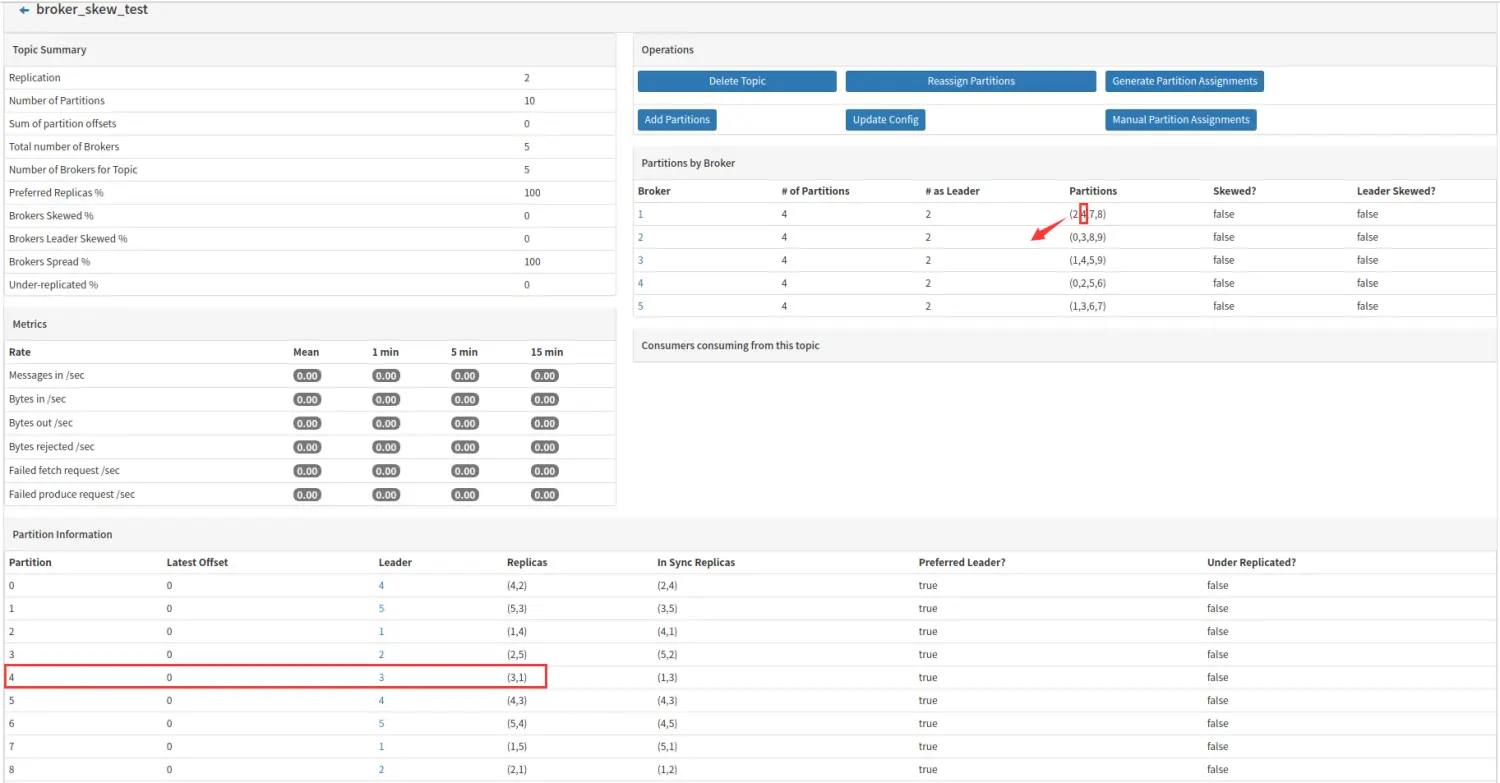
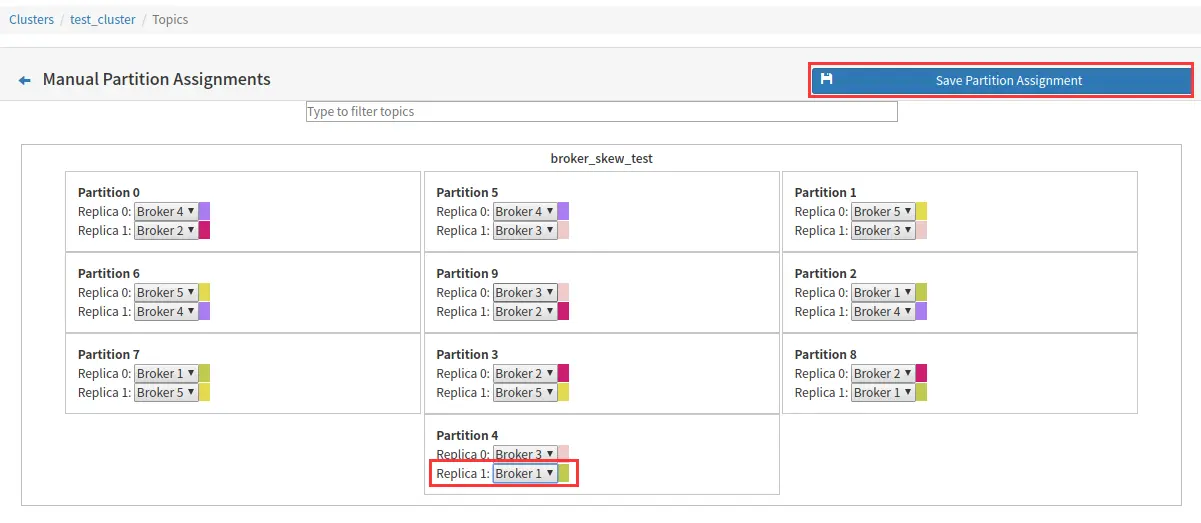
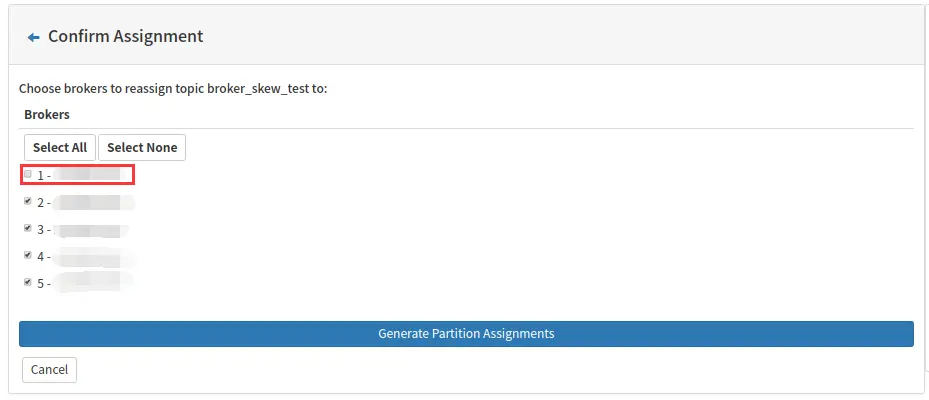
- Generate Partition Assignments
该功能一般在批量移动 partition 时比较方便,比如集群新增 broker 或者 topic 新增 partition 后,将分区移动到指定的 broker。
例如下图将 topic 由原来的分布在 5 个 broker 修改为 4 个 broker:
Update Config

image.png
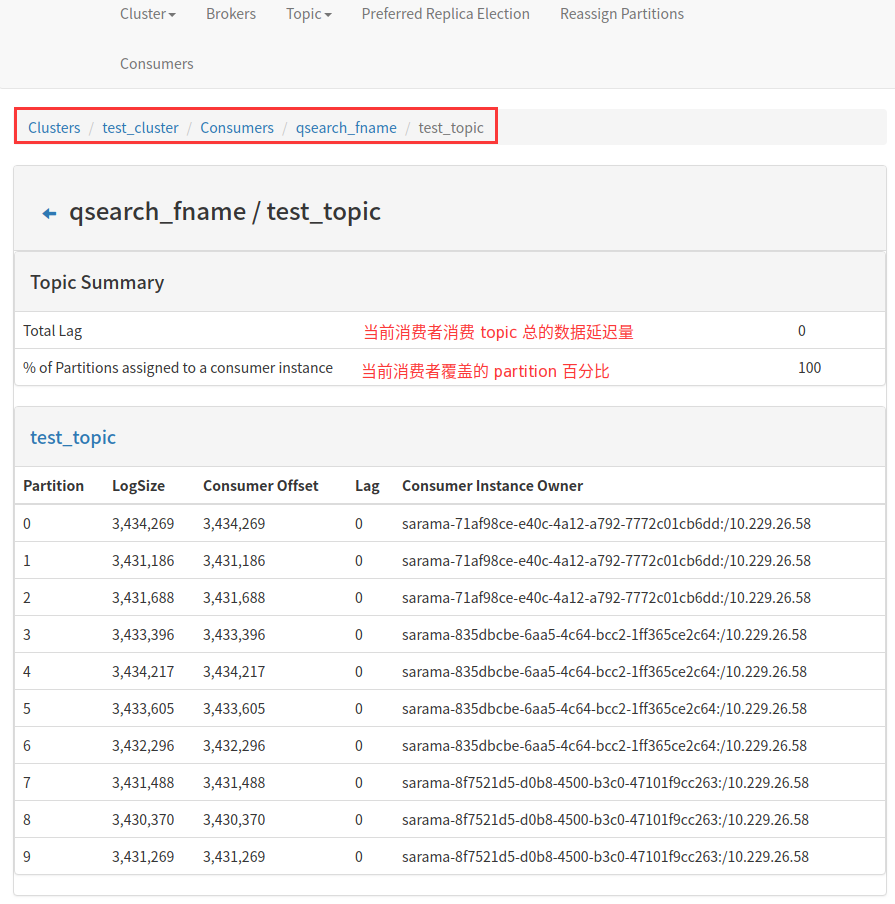
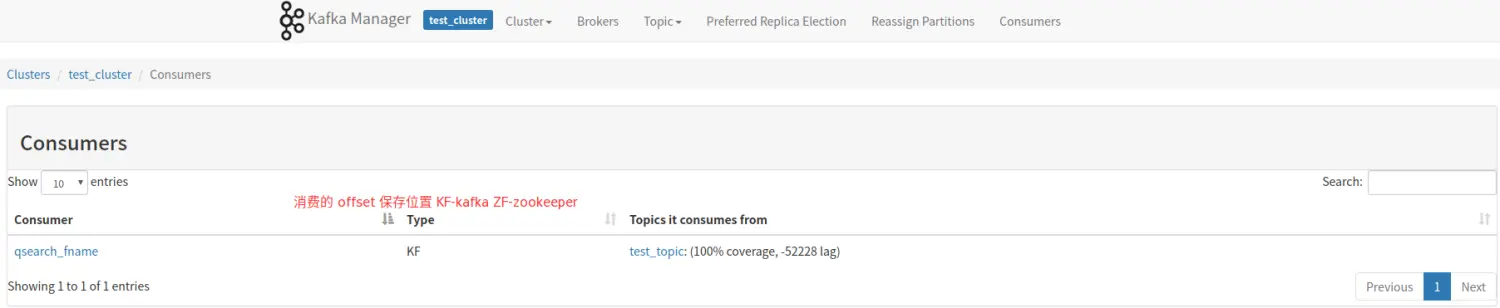
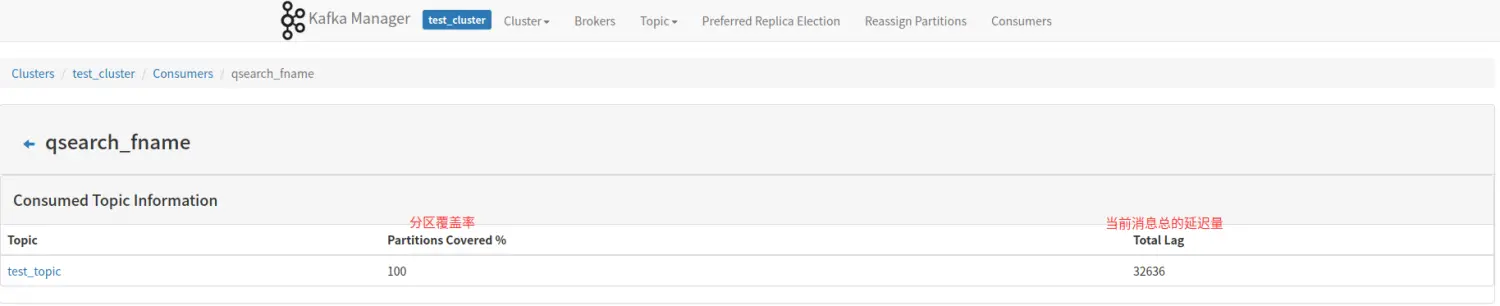
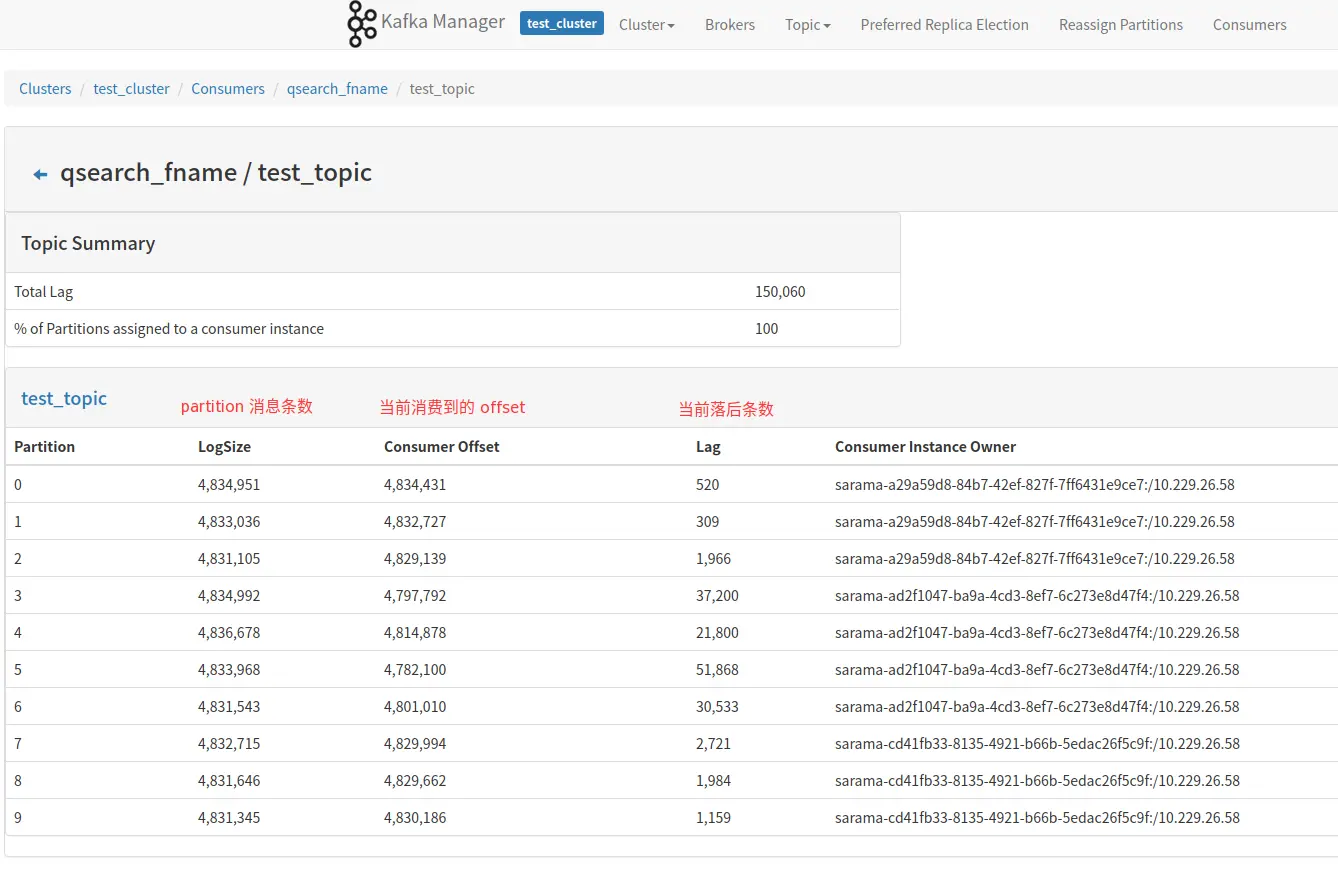
四、消费监控
kafka manager 能够获取到当前消费 kafka 集群消费者的相关信息。
参考
[1]: Kafka 副本同步机制理解
[2]: kafka 维护工具使用指南
[3]: kafka 中文文档
[4]: Replication tools
