
阅读量:0
目录
1.概述
hadoop有三种安装模式
单机模式,只在一台机器上运行,存储用的本地文件系统而不是HDFS。
伪分布式模式,存储采用HDFS,名称节点和数据节点在同一台机器上。
分布式模式,标准的分布式集群。
做实验或者学习阶段选择伪分布式就好,本文将详细讲解在Linux搭建起一个伪分布式的hadoop集群。
2.环境准备
1.安装JDK
略,这一步应该就不用多赘述了吧,作者用的Oracle版的JDK8
2.配置ssh免密登录
由于名称节点要通过ssh来拉起数据节点的守护进程(用来上报信息),所以要先配置一下节点间的ssh免密登录,不然的话集群根本就起不来。
Ubuntu默认安装了ssh client,除此之外还要安装ssh server、生成密钥
apt-get install openssh-server
cd ~/.ssh
ssh-keygen -t rsa
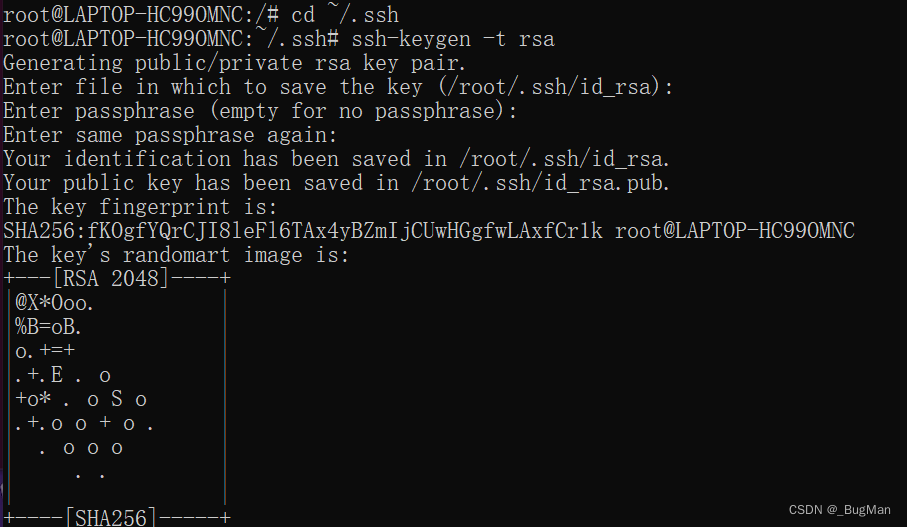
并将密钥追加到允许无密码登录的密钥列表文件中去:
cd /root/.ssh
cat id_rsa.pub >>authorized_keys
3.hadoop安装
3.1.下载安装配置
下载地址:
版本:
3.1.3
下载后直接解压即可。
用version参数看看解压是否正确:

测试一下单机模式是否能正常运行:
测试可以使用自带的demo来看运行是否正常,通过一个正则表达式去匹配指定格式的字符串,然后去查看output中存放的统计结果。
mkdir ./input cp /etc/*.xml ./input ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep ./input/ ./output 'dfs[a-z.]+' cat ./output/*
搭建伪分布式集群:
hadoop的配置文件所在路径:
<安装路径>/etc/hadoop
core-site.xml:
<configuration <property> <name>hadoop.tmp.version</name> <value>file:/usr/local/hadoop/tmp</value> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
hdfs-site.xml:
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/data</value> </property> </configuration>
配置好配置文件后,下一步是什么?当然是格式化namenode了,这一步会根据配置文件去初始化好namenode节点:
./bin/hdfs namenode -format
格式化成功后的提示:

配置环境:
按道理说配置完配置文件后直接启动即可了对吧,但是在hadoop 3.1.3这个版本有个hadoop的环境配置文件etc/hadoop/hadoop-env.sh。这个配置里面要指定JAVA_HOME的路径已经可以启动Hadoop的用户,不然的话启动会报用户没有启动权限或者JAVA_HOME找不到。这是一个小坑以下是作者的配置:
JAVA_HOME=/jdk/jdk8/ export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root
启动:
./sbin/start-dfs.sh
启动完成后:
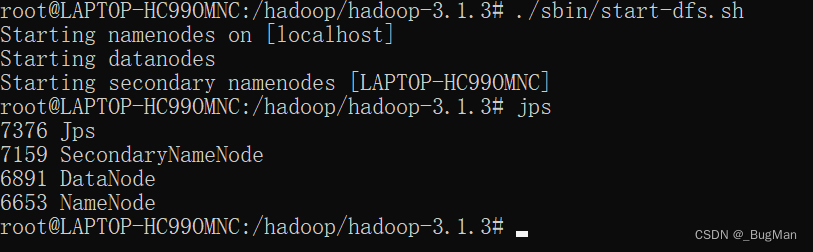
3.2.伪分布式集群
HDFS做了资源隔离,要使用HDFS的前提是先在HDFS中为用户创建用户目录。
./bin/hdfs dfs -mkdir -p /user/root
在/user/root/下创建一个input目录:
./bin/hdfs dfs -mkdir input
把测试数据拷贝过去:
./bin/hdfs dfs -put ./etc/hadoop/*.xml input
这不是报错,不用管:

跑计算任务的demo:
跑demo的jar包的时候可以指定输入输出路径和一个正则表达式来指定匹配规则,下面的正则表达式会匹配dfs开头后面是a-z的字符的所有单词。
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep input output 'dfs[a-z.]+'
查看结果:

3.3.注意事项
下次再进行测试的时候一定要将output文件夹删掉,不然冲突会报错。
4.Hadoop集群的组成
伪分布式的hadoop集群其实就两大核心组件构成:
HDFS
MapReduce
回顾一下上面启动hadoop后我们用JDK的JPS命令看到的JAVA进程:
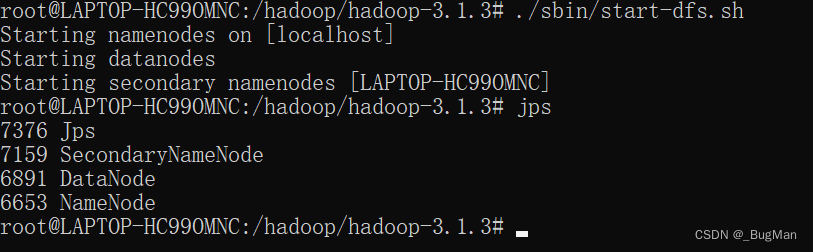
可以看到一共有三个东西:
secondNameNode
DataNode
NameNode
这三个东西是属于HDFS的,dataNode是具体存放数据的节点,nameNode用来记录所有dataNode的信息,secondNameNode是nameNode的备份:
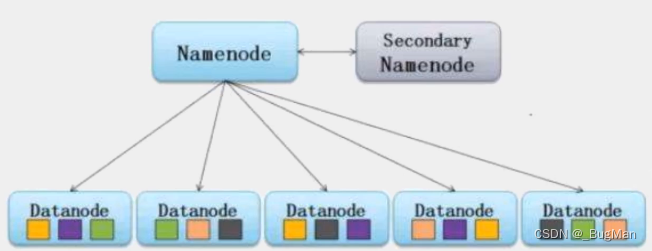
以上是节点在HDFS维度扮演的角色,除此之外节点还在MapReduce维度扮演有角色,MapReduce在跑一个大的任务的时候会把节点分为两类:
jobTracker,负责总的来协调位于不同节点的小任务,将多个小任务的计算结果汇成最终的结果。
taskTracker,dataNode节点上跑的小任务。
