阅读量:0

一、整数在内存中的存储
关于整数在内存中的存储形式,在博主之前写的文章里已经介绍了!友友们可以去点下面链接去看,这里就不过多介绍。
我们以整型在内存中的存储形式为基础,探究后面的内容:整型提升与截断、算数转换、大小端字节序和字节序判断、强制类型转换的原理、浮点数在内存中的存储!!
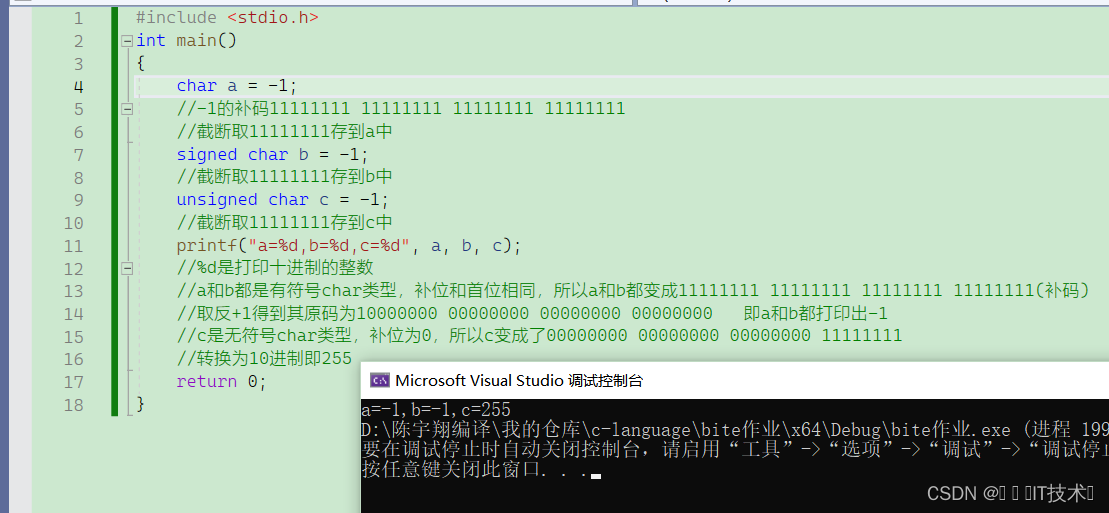
二、整型提升与截断
C语⾔中,整型算术运算总是⾄少以缺省(缺省就是默认的意思)整型类型的精度来进⾏的。
为了获得这个精度,表达式中的字符和短整型操作数在使⽤之前被转换为普通整型,这种转换称为整型提升。
2.1 整型提升的意义
表达式的整型运算要在CPU的相应运算器件内执⾏,CPU内整型运算器(ALU)的操作数的字节⻓度⼀ 般就是int的字节⻓度,同时也是CPU的通⽤寄存器的⻓度。
因此,即使两个char类型的相加,在CPU执⾏时实际上也要先转换为CPU内整型操作数的标准⻓度。
通⽤CPU(general-purpose CPU)是难以直接实现两个8⽐特字节直接相加运算(虽然机器指令中 可能有这种字节相加指令)。所以,表达式中各种⻓度可能⼩于int⻓度的整型值,都必须先转换为 int或unsigned int,然后才能送⼊CPU去执⾏运算。
也就是说,假设c1和c2是char类型,那么要先将要实现c1+c2,就需要对c1和c1进行整型提升之后进行运算,那么假设我们用char类型的c3去接收c1和c2的结果,由于char类型是一个字节,所以会发生截断。截断之后,只会保留低位的字节存储在c3中!!
2.2 如何进行整体提升呢?
1. 有符号整数提升是按照变量的数据类型的符号位来提升的
2. ⽆符号整数提升,⾼位补0
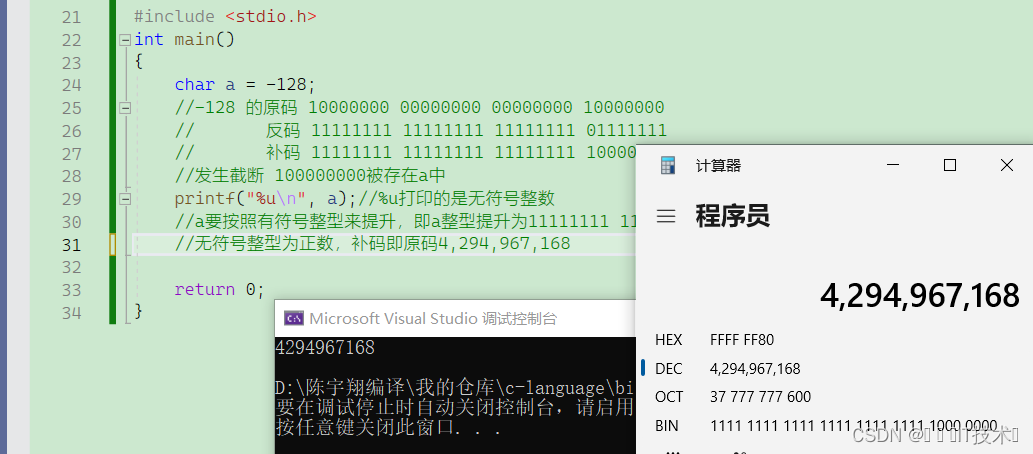
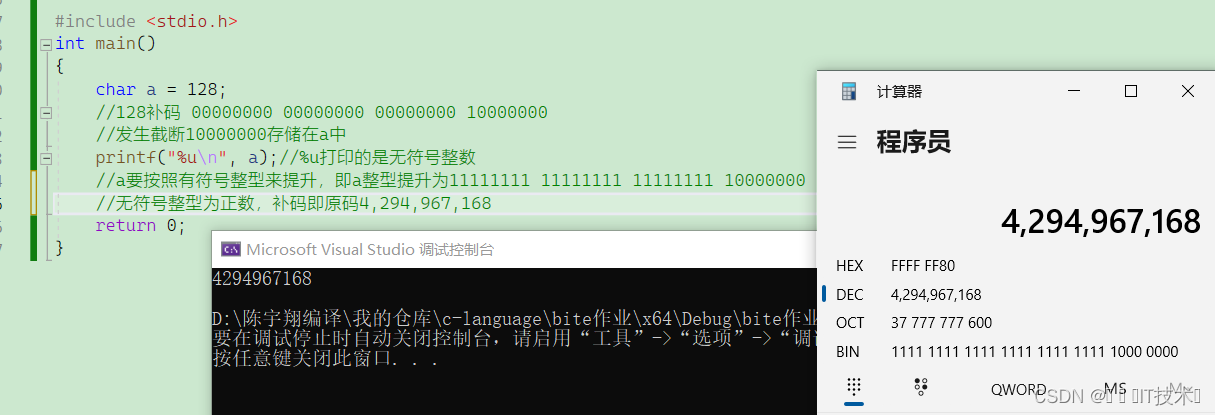
2.3 如何进行截断呢?
当长字节的数据类型用短字节的数据类型进行存储时,会发生截断,截断就是通过简单地将高位丢弃,保存低位来实现
补充一条知识:
C语言规定,char类型默认是否带有正负号,由当前的系统决定,也就是说char类型可能等价于signed char也可能等价于unsigned char,这一点与int不同,int必然等价于signed int,但是在大多数的编译器环境下,包括当前的vs,char等价于signed char!
下面我将通过一道例题来深入解析整型提升和截断的全过程!!!

大家可以看我的注释,写的比较详细!
我们会发现,当char类型进行运算时,会进行整型提升,而当计算的结果保存在char类型时,会对整型提升后的结果进行截断,只保留低位。
三、算数转换
明白了整型提升与截断,我们考虑到了计算字符和短整型操作数使用前的情况,那如果操作数类型都大于等于4个字节呢???
如果某个操作符的各个操作数属于不同的类型,那么除非其中一个操作数转换为另一个操作数的类型,否则操作将无法进行。那么为了判别两个操作数转换的优先级,设置了如下层次体系,该体系杯成为寻常算数转换。
long double double float unsigned long int long int unsigned int int类型排名较低的操作数应该转换成类型排名高的操作数进行计算
比方说float a+int b,那计算前会先把b转换成float类型运算
如果是float a +double b,那计算前会先把a转换成double类型运算
四、大小端字节序和字节序判断
当我们了解了整数在内存中存储后,我们调试看⼀个细节:
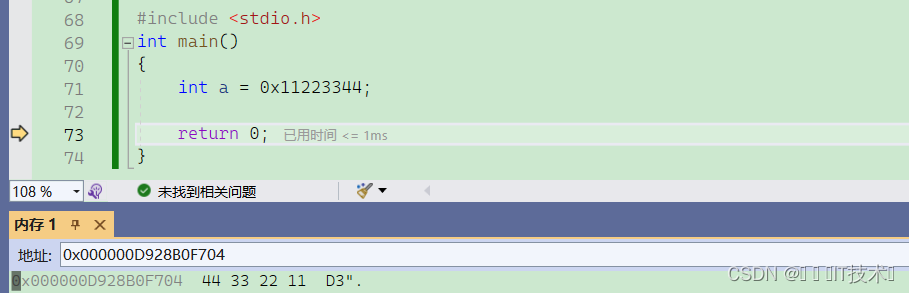
调试的时候,我们可以看到在a中的 0x11223344 这个数字是按照字节为单位,倒着存储的。这是为什么呢?下面就要讲到大小端概念!
4.1 什么是大小端呢?
“大端”和“小端”可以追溯到1726年的Jonathan Swift的《格列佛游记》,其中一篇讲到有两个国家因为吃鸡蛋究竟是先打破较大的一端还是先打破较小的一端而争执不休,甚至爆发了战争。1981年10月,Danny Cohen的文章《论圣战以及对和平的祈祷》(On holy wars and a plea for peace)将这一对词语引入了计算机界。这么看来,所谓大端和小端,也就是big-endian和little-endian,其实是从描述鸡蛋的部位而引申到计算机地址的描述,也可以说,是从一个俚语衍化来的计算机术语。
这个术语引入的目的是什么呢?
计算机中,内存被分为了一个个内存单元,每个内存单元的大小是1个字节,所以当我们需要存储数据超过一个字节时,就涉及到了存储顺序的问题,根据存储顺序的不同,我们分为了大端字节序存储和小端字节序存储的概念。
⼤端(存储)模式:是指数据的低位字节内容保存在内存的⾼地址处,⽽数据的⾼位字节内容,保存 在内存的低地址处。
⼩端(存储)模式:是指数据的低位字节内容保存在内存的低地址处,⽽数据的⾼位字节内容,保存 在内存的⾼地址处。
这样直接记忆概念可能有点困难,那有没有更为简单的记忆呢?
在裘宗燕翻译的《程序设计实践》里,这对术语并没有翻译为“大端”和小端,而是“高尾端”和“低尾端”,这就好理解了:如果把一个数看成一个字符串,比如11223344看成"11223344",末尾是个'\0','11'到'44'个占用一个存储单元,那么它的尾端很显然是44,前面的高还是低就表示尾端放在高地址还是低地址,它在内存中的放法非常直观,如下图:
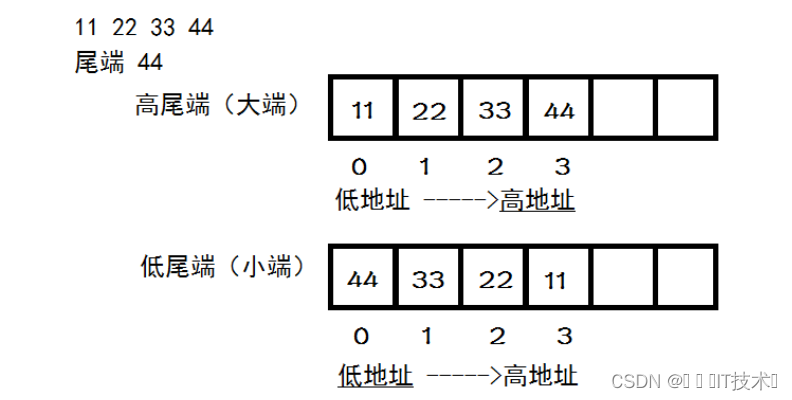
我们可以利用高尾端和低尾端来记住大端小端的概念,因为尾端的数字对应的就是低位字节,如果尾端的数字在较高地址处,就是高尾端,就是大端,也就是低位字节被保存在高地址处。同理,如果尾端的数字在较低地址处,就是低尾端,也就是低位字节被保存在低地址处。
4.2 为什么有大小端
为什么会有⼤⼩端模式之分呢?这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都 对应着⼀个字节,⼀个字节为8 bit 位,但是在C语⾔中除了8 bit 的 char 之外,还有16 bit 的 short 型,32 bit 的 long 型(要看具体的编译器),另外,对于位数⼤于8位的处理器,例如16位 或者32位的处理器,由于寄存器宽度⼤于⼀个字节,那么必然存在着⼀个如何将多个字节安排顺序的问题。因此就导致了⼤端存储模式和⼩端存储模式。
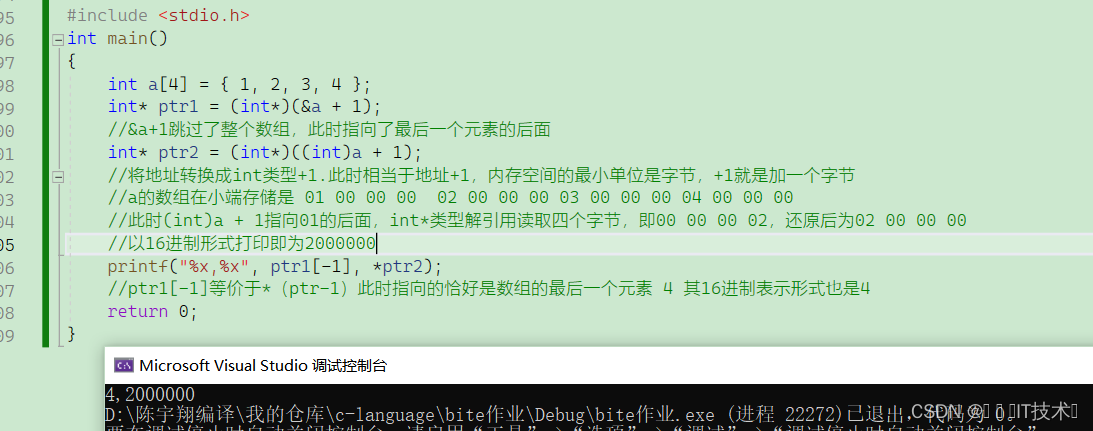
例如:⼀个 16bit 的 short 型 x ,在内存中的地址为 0x0010 , x 的值为 0x1122 ,那么 0x11 为⾼字节, 0x22 为低字节。对于⼤端模式,就将 0x11 放在低地址中,即 0x0010 中, 0x22 放在⾼地址中,即 0x0011 中。⼩端模式,刚好相反。我们常⽤的 X86 、x64结构是⼩端模式,⽽ KEIL C51 则为⼤端模式。很多的ARM,DSP都为⼩端模式。有些ARM处理器还可以由硬件来选择是⼤端模式还是小端模式。
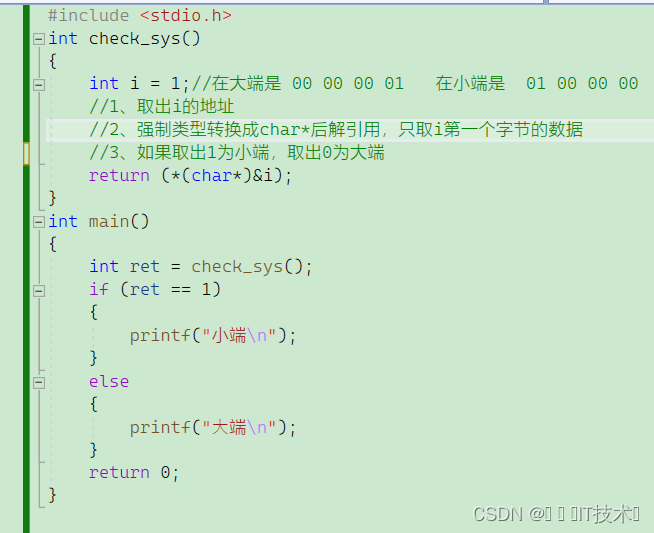
4.3 编写一个程序判断当前机器的字节序
4.4 大小端谁好谁坏?
小端模式:
1、强制类型转换数据不需要调整字节内容。(在强制类型转换原理会解释)
2、CPU做数值运算时从内存中依顺序依次从低位到高位取数据进行运算,直到最后刷 新最高位的符号位,这样的运算方式会更高效
大端模式:
符号位判断固定为第一个字节,容易判断正负,便于人类阅读。
总结:大小端没有谁更优更劣,各种优点就是对方劣势。
五、强制类型转换的原理
5.1 int数据类型强转char数据类型
int数据类型强转char数据类型的原理就是字节截断!截断就是通过简单地将高位丢弃,保存低位来实现

5.2 char数据类型强转int数据类型
char数据类型强转int数据类型的原理就是整型提升!
1. 有符号整数提升是按照变量的数据类型的符号位来提升的
2. ⽆符号整数提升,⾼位补0
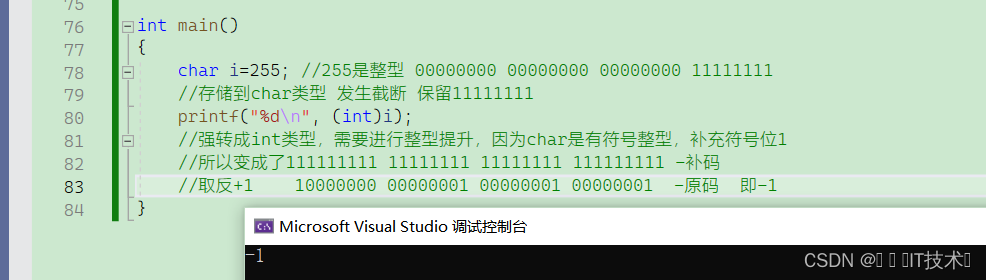
5.3 大小端和强制类型转换的关系
大小端(endianness)是指多字节数据在存储时的字节顺序。在C语言中,赋值操作是不受大小端影响的。
其中截断是通过简单地将高位丢弃来实现的,而与数据存储的字节顺序无关 。
既然无关,那为什么说小端的优势就是强制类型转换数据不需要调整字节内容??
虽然截断与数据存储的字节顺序(大小端)无关,但是大小端对于截断效率是不一样的,假设在小端模式下把int的4字节强制转换成short的2字节时,就直接把int数据存储的前两个字节给short就行,因为其前两个字节刚好就是最低的两个字节,符合转换逻辑。
这就是说明了大小端对截断效率有影响,这就好比化学反应加了催化剂一样,加与不加的结果是一样,但是速度不一样!!
5.4 相同字节数据类型的强制类型转换
上述讲的都是不同字节的数据类型的强转,那如果是相同数据类型的强制转换,比如说int强转float,那恰好都是4个字节,就不需要补位,也不需要截断。那他们强转之后会有区别吗??
我们来看下面这个代码
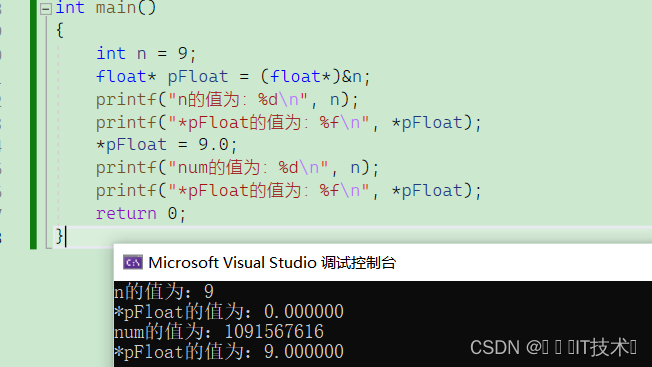
我们会发现,当我们用int类型存储9,再用float类型取出9时,得到的结果是0.000000,而用float类型去存储9.0时,用int类型取出来时1091567616
按道理来说,这两种类型都是四个字节,不会出现截断和整型提升,存储的内容并没有发生改变,为什么会出现这样的情况??
原因就是因为,float类型和int类型的存储方式不一样!!!下面将介绍浮点数在内存中的存储!
六、浮点数在内存中的存储
常⻅的浮点数:3.14159、1E10(E表示底数是10)等,浮点数家族包括: float(4字节)、double(8字节)、long double(8字节) 类型。
浮点数表⽰的范围:float.h中定义
6.1 浮点数的存储形式
根据国际标准IEEE(电⽓和电⼦⼯程协会) 754,任意⼀个⼆进制浮点数V可以表⽰成下⾯的形式:

为什么是这样的形式呢?这就跟科学计数法有关系。下面通过一个例子来说明:
10进制的5.5应该怎么转换成二进制呢?
5变成2进制是101 ,0.5变成2进制是2^-1,所以可以其二进制形式可以写成101.1,用科学计数法来表示就是1.011*2^2,类比上图的表示形式我们可以发现,此时S=0,M=1.011,E=2.
既然浮点数可以写成科学计数法的形式,并且可以算出对应的S M E,所以我们实际上只需要在内存中将S M E 存储起来即可!!
IEEE 754规定:
对于32位的浮点数,最⾼的1位存储符号位S,接着的8位存储指数E,剩下的23位存储有效数字M 对于64位的浮点数,最⾼的1位存储符号位S,接着的11位存储指数E,剩下的52位存储有效数字M

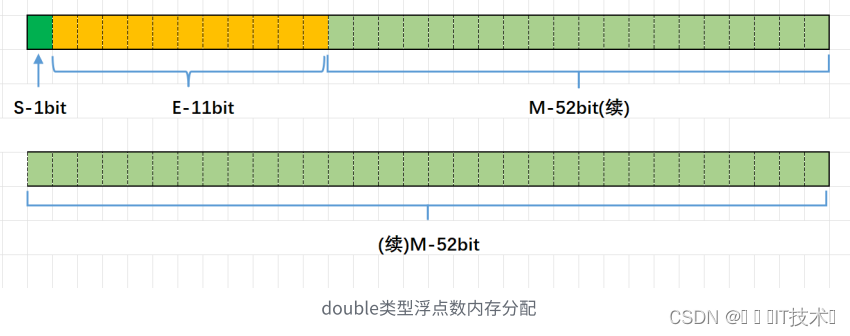
6.2 浮点数存的过程
IEEE 754对有效数字M和指数E,还有⼀些特别规定。
6.2.1 M
前⾯说过, 1≤M<2 ,也就是说,M可以写成 1.xxxxxx 的形式,其中xxxxxx表⽰⼩数部分。 IEEE 754规定,在计算机内部保存M时,默认这个数的第⼀位总是1,因此可以被舍去,只保存后⾯的 xxxxxx部分。⽐如保存1.01的时候,只保存01,等到读取的时候,再把第⼀位的1加上去。这样做的⽬ 的,是节省1位有效数字(这样的话精度会更高!!)。以32位浮点数为例,留给M只有23位,将第⼀位的1舍去以后,等于可以保存24位有效数字。
6.2.2 E
⾄于指数E,情况就⽐较复杂。
⾸先,规定E为⼀个⽆符号整数(unsigned int)
这意味着,如果E为8位,它的取值范围为0~255;如果E为11位,它的取值范围为0~2047。但是,我 们知道,科学计数法中的E是可以出现负数的,所以IEEE 754规定,存⼊内存时E的真实值必须再加上 ⼀个中间数,对于8位的E,这个中间数是127;对于11位的E,这个中间数是1023。⽐如,2^10的E是 10,所以保存成32位浮点数时,必须保存成10+127=137,即10001001。
6.3 浮点数取的过程
6.3.1 E不全为0或不全为1(常规方式)
这时,浮点数就采⽤下⾯的规则表⽰,即指数E的计算值减去127(或1023),得到真实值,再将有效数字M前加上第⼀位的1。 ⽐如:0.5 的⼆进制形式为0.1,由于规定正数部分必须为1,即将⼩数点右移1位,则为1.0*2^(-1),其 阶码为-1+127(中间值)=126,表⽰为01111110,⽽尾数1.0去掉整数部分为0,补⻬0到23位00000000000000000000000
则其⼆进制表示形式为:0 01111110 00000000000000000000000
6.3.2 E全为0
这时,浮点数的指数E等于1-127(或者1-1023)即为真实值,有效数字M不再加上第⼀位的1,⽽是还 原为0.xxxxxx的⼩数。这样做是为了表⽰±0,以及接近于0的很⼩的数字。
6.3.3 E全为1
这时,如果有效数字M全为0,表⽰±⽆穷⼤(正负取决于符号位s)
6.4 题目解析
明白了浮点数的存储形式,我们就一起对5.4的那道题进行解析
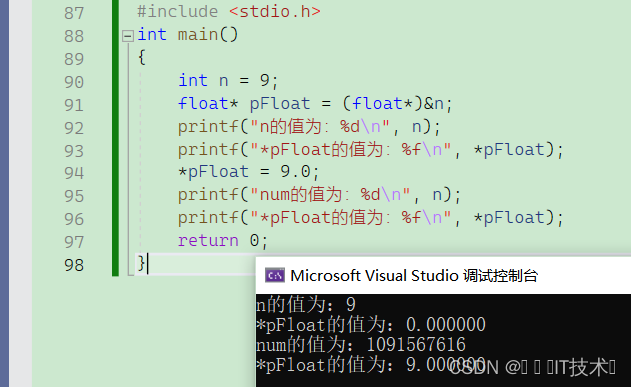
6.4.1 为什么9还原成浮点数变成了0.000000?
9为整型,在内存中存储为00000000 00000000 00000000 00001001
转换为float类型后,将其按照浮点数形式拆分,得到第1位符号位s=0,后面8位指数位为00000000,最后23位有效数字M=000 0000 0000 0000 0000 1001
因为指数E全为0,所以符合E全为0的情况
V=(-1)^0*0.00000000000000000001001*2^(-126)=1.001*2^(-146)
显然V是一个接近于0的正数,且%f占位符最多保存6位,所以打印出来就是0.000000
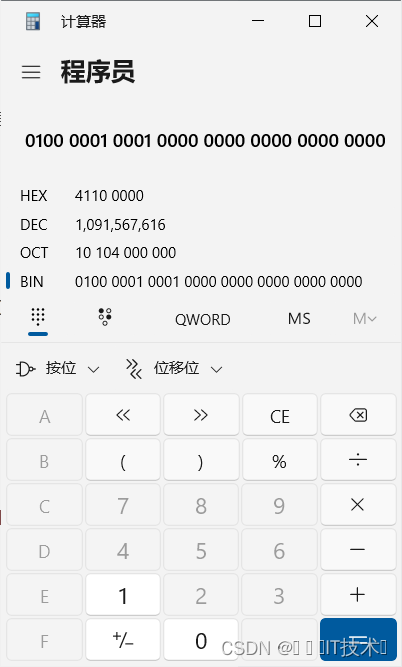
6.4.2 为什么浮点数9.0,用整数打印是1091567616?
首先浮点数9.0等于二进制的1001.0,换成科学计数法就是1.001*2^3
即S=0,M=1.001,E=3
首先是第一位符号位S=0,有效数字M等于001后面再加20个0,凑满23位,指数E等于3+127=130,即10000010
按照S+E+M的方式写成二进制就是
0 10000010 001 0000 0000 0000 0000 0000
转换成10进制就是就是1091567616
6.5 浮点数的存储可能有什么问题??
6.5.1 浮点数在内存中可能存在部分数无法精确保存
对于float(double)类型来说,留给M的只有23(52)位,有可能存在某些数及时将全部位都用上了,都凑不齐,下面有个例子99.7
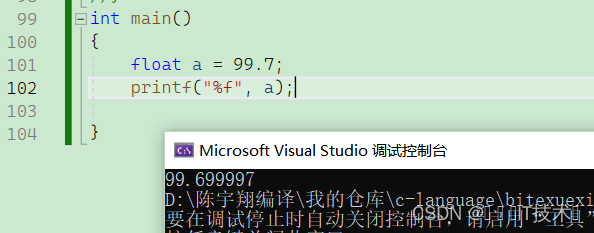
6.5.2 double类型的精度比float类型高
double类型留给E和M的位数都更大,所以相对来说精度会更高!
6.5.3 两个浮点数比较大小时,直接使用==可能会存在问题。
因为浮点数在内存中有时候无法精确保存,所以使用==可能会存在问题,所以一般来说,我们会设置一个我们可以接收的精度,如果他们之间的差距在这个精度之内,就把他们视为相等。
比如我想要判断浮点数a==5.6,假设我们设置的精度是0.000001,那么我们可以将if(a==5.6)改写成if(abs(f-5.6)<=0.000001)。
关于浮点数的比较在 《C语言深度解剖》这本书中有介绍。
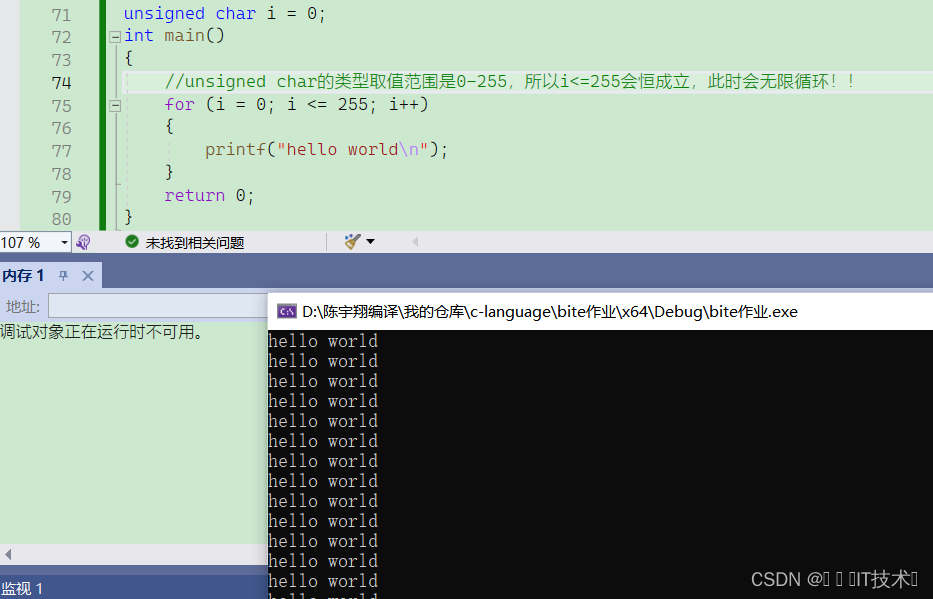
七、signed char和unsigned char的取值范围
char类型是1个字节,一共是8个比特位
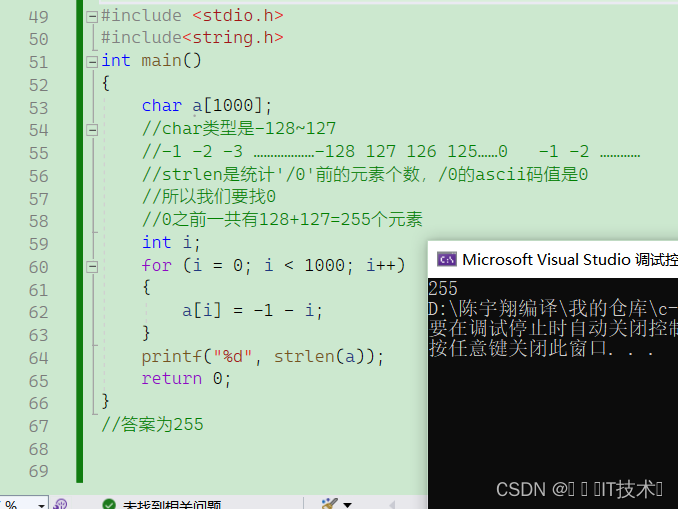
对于signed char来说,首位是符号位,后面7位是数值位,所以最大应该是01111111即127,最小应该位11111111即-127,但是由于10000000和00000000一个表示-0,一个表示0,为了避免0的两种表示形式,将10000000定为-128,所以signed char的取值范围是-128~127。
对于unsigned char来说,8个位都是数值位,所以最大为11111111即255,最小为00000000即0,所以unsigned char类型的取值范围是0~255.
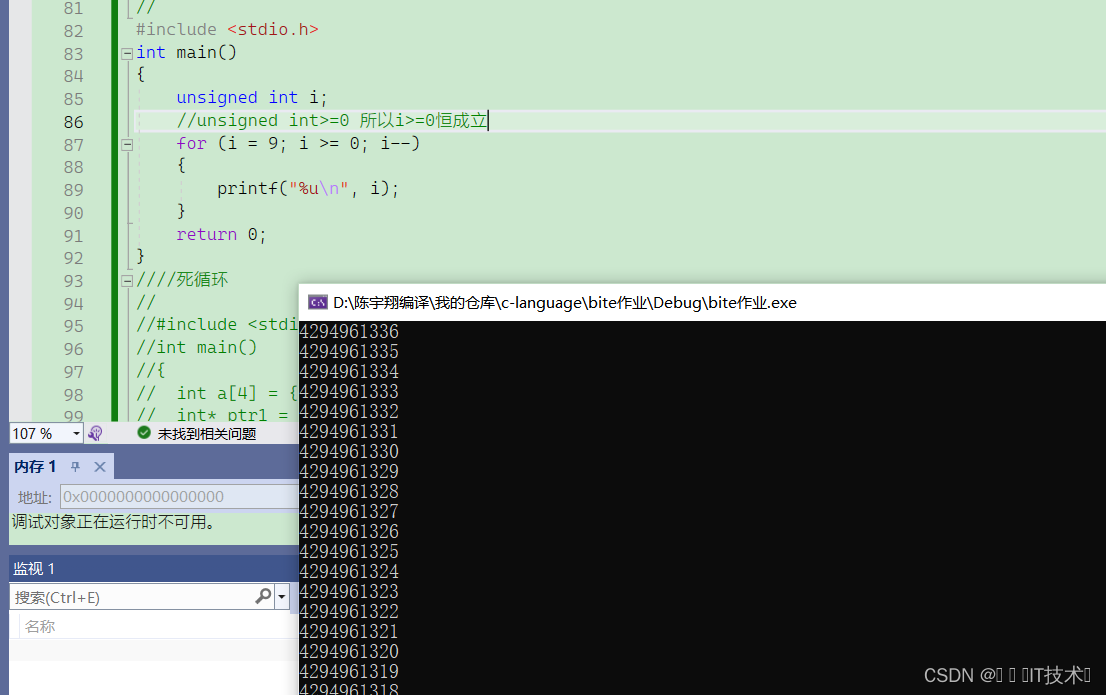
八、进制数的轮回
这是一个做题技巧,以char类型为例,我们从00000000开始举出char类型的所以可能性
00000000、00000001、000000010………………01111111、10000000、10000001……11111111
从左到右是0 1 2 3 4 5 …………当到达011111111达到最大正数127,再+1得到10000000是最大负数-128 再往下加就是-127 -126……………………一直到-1。
我们发现从00000000开始,不断+1是从0-127 127跳到-128 -128--1 这是一个轮回。11111111再+时变成100000000 此时达到9位,首位丢失,所以又是00000000即0,所以如果一直+1,会一直按照0-127 -128--1 这样循环下去!!
九、经典例题