
阅读量:0
目录
2 .描述进程-PCB(process control block)进程控制块
一、冯诺依曼体系结构

1.输入单元:包括键盘, 鼠标,扫描仪, 写板等 2.中央处理器(CPU):含有运算器和控制器等 3.输出单元:显示器,打印机等注意:
这里的存储器指的是内存 不考虑缓存情况,这里的CPU能且只能对内存进行读写,不能访问外设(输入或输出设备) 外设(输入或输出设备)要输入或者输出数据,也只能写入内存或者从内存中读取。 一句话,所有设备都只能直接和内存打交道。
二、操作系统(Operator System)
1 .概念
任何计算机系统都包含一个基本的程序集合,称为操作系统(OS)。笼统的理解,操作系统包括:内核(进程管理,内存管理,文件管理,驱动管理) 其他程序(例如函数库,shell程序等等)
2 .设计OS的目的
与硬件交互,管理所有的软硬件资源
为用户程序(应用程序)提供一个良好的执行环境
3 . 定位
在整个计算机软硬件架构中,操作系统的定位是:一款纯正的“搞管理”的软件

1. 描述起来,用struct结构体 2. 组织起来,用链表或其他高效的数据结构
4 . 系统调用和库函数概念
在开发角度,操作系统对外会表现为一个整体,但是会暴露自己的部分接口,供上层开发使用,这部分由操作系统提供的接口,叫做系统调用。 系统调用在使用上,功能比较基础,对用户的要求相对也比较高,所以,有心的开发者可以对部分系统调用进行适度封装,从而形成库,有了库,就很有利于更上层用户或者开发者进行二次开发。
三、进程
1 .基本概念
课本概念:程序的一个执行实例,正在执行的程序等 内核观点:担当分配系统资源(CPU时间,内存)的实体。
2 .描述进程-PCB(process control block)进程控制块
操作系统中,进程可以同时存在非常多
一个进程一定要有一个pcb
进程=PCB+自己的代码和数据~~ 进程=内核task_struct结构体+程序的代码和数据
进程信息被放在一个叫做进程控制块的数据结构中,可以理解为进程属性的集合。 课本上称之为PCB(process control block),Linux操作系统下的PCB是: task_structtask_struct-PCB的一种
在Linux中描述进程的结构体叫做task_struct。 task_struct是Linux内核的一种数据结构,它会被装载到RAM(内存)里并且包含着进程的信息。task_ struct内容分类
标示符(pid): 描述本进程的唯一标示符,用来区别其他进程。状态: 任务状态,退出代码,退出信号等。 优先级: 相对于其他进程的优先级。 程序计数器: 程序中即将被执行的下一条指令的地址。 内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针 上下文数据: 进程执行时处理器的寄存器中的数据[休学例子,要加图CPU,寄存器]。 I/O状态信息: 包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。 记账信息: 可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。 其他信息
进程动态运行:只要我们的进程task_struct,将来在不同的队列中,进程就可以访问不同的资源
进程的调度运行,本质就算让进程控制块task_struct 进行排队!
3 . 组织进程
可以在内核源代码里找到它。所有运行在系统里的进程都以task_struct链表的形式存在内核里。 对进程的管理,就变成了对链表的增删查改!
4 . 查看进程
进程的信息可以通过 /proc 系统文件夹查看如:要获取PID为1的进程信息,你需要查看 /proc/1 这个文件夹。 大多数进程信息同样可以使用top和ps这些用户级工具来获取
5 .通过系统调用获取进程标示符
进程id(PID) 父进程id(PPID)
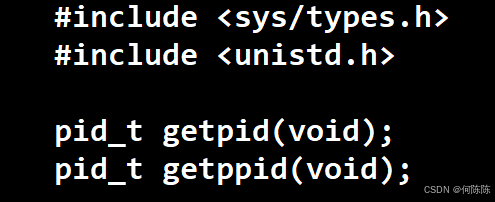
#include <stdio.h> #include <sys/types.h> #include <unistd.h> int main() { printf("pid: %d\n", getpid()); printf("ppid: %d\n", getppid()); return 0; }
6 .通过系统调用创建进程-fork
fork是一个函数,他是操作系统提供的
运行 man fork 认识fork fork有两个返回值 父子进程代码共享,数据各自开辟空间,私有一份(采用写时拷贝)
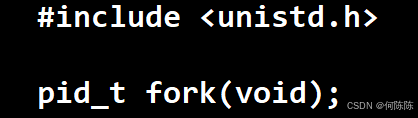
#include <stdio.h> #include <sys/types.h> #include <unistd.h> int main() { int ret = fork(); printf("hello proc : %d!, ret: %d\n", getpid(), ret); sleep(1); return 0; }fork 之后通常要用 if 进行分流
#include <stdio.h>
#include <sys/types.h> #include <unistd.h> int main() { int ret = fork(); if(ret < 0) { perror("fork"); return 1; } else if(ret == 0) { //child printf("I am child : %d!, ret: %d\n", getpid(), ret); } else { //father printf("I am father : %d!, ret: %d\n", getpid(), ret); } sleep(1); return 0; }
进程每次启动,对应的pid都不一样是正常的,每次都会由操作系统分配一个pid
fork之后,父子代码共享,创建一个进程,本质是系统中多一个进程,多一个进程就是多一个:
1. 内核task_struct
2. 有自己的代码和数据(父进程的代码和数据从磁盘中加载而来,子进程的代码和数据默认情况继承父进程的代码和数据)
为什么要创建子进程?
我们创建子进程目的是想让子进程执行和父进程不一样的代码
进程具有独立性,父子进程也是两个不同的进程,也应该具有独立性,原则上数据要分开。因此,子进程的数据是只读的。
fork是一个函数,为什么能返回两次(父子进程)
当fork执行快要结束(return之前)创建子进程的核心代码已经完成,就是子进程已经创建成功,这个时候return 语句也是代码同样的也被继承,父子进程各自返回自己的函数;
7 . 进程运行
启动:
a. ./xxx,本质就算让系统创建进程并运行——我们自己写的代码形成的可执行==系统命令==可执行文件。在linux中运行的大部分执行操作,本质都是运行进程!
b. 每一个进程都要有自己的唯一标识符,叫做进程pid (unsigned int)
c. 一个进程想知道自己的pid,可以通过系统调用getpid()
d. ctrl就是在用户层面终止进程,kill -9 pid 可以直接杀死进程
e. 进程每次启动的时候,会记录自己当前在哪个路径下启动,在运行过程中做的操作也会默认对应这个路径
四、进程状态
1 .Linux内核源代码

R运行状态(running): 并不意味着进程一定在运行中,它表明进程要么是在运行中要么在运行队列里。 S睡眠状态(sleeping): 意味着进程在等待事件完成(这里的睡眠有时候也叫做可中断睡眠 (interruptible sleep))比如scanf函数。 D磁盘休眠状态(Disk sleep)有时候也叫不可中断睡眠状态(uninterruptible sleep),在这个状态的进程通常会等待IO的结束。不可被杀,深度睡眠,不可中断睡眠 T停止状态(stopped): 可以通过发送 SIGSTOP 信号给进程来停止(T)进程。这个被暂停的进程可以通过发送 SIGCONT 信号让进程继续运行。 t 停止状态:当进程遇见断点时 X死亡状态(dead):这个状态只是一个返回状态,你不会在任务列表里看到这个状态。
2 .进程状态查看
ps aux / ps axj 命令
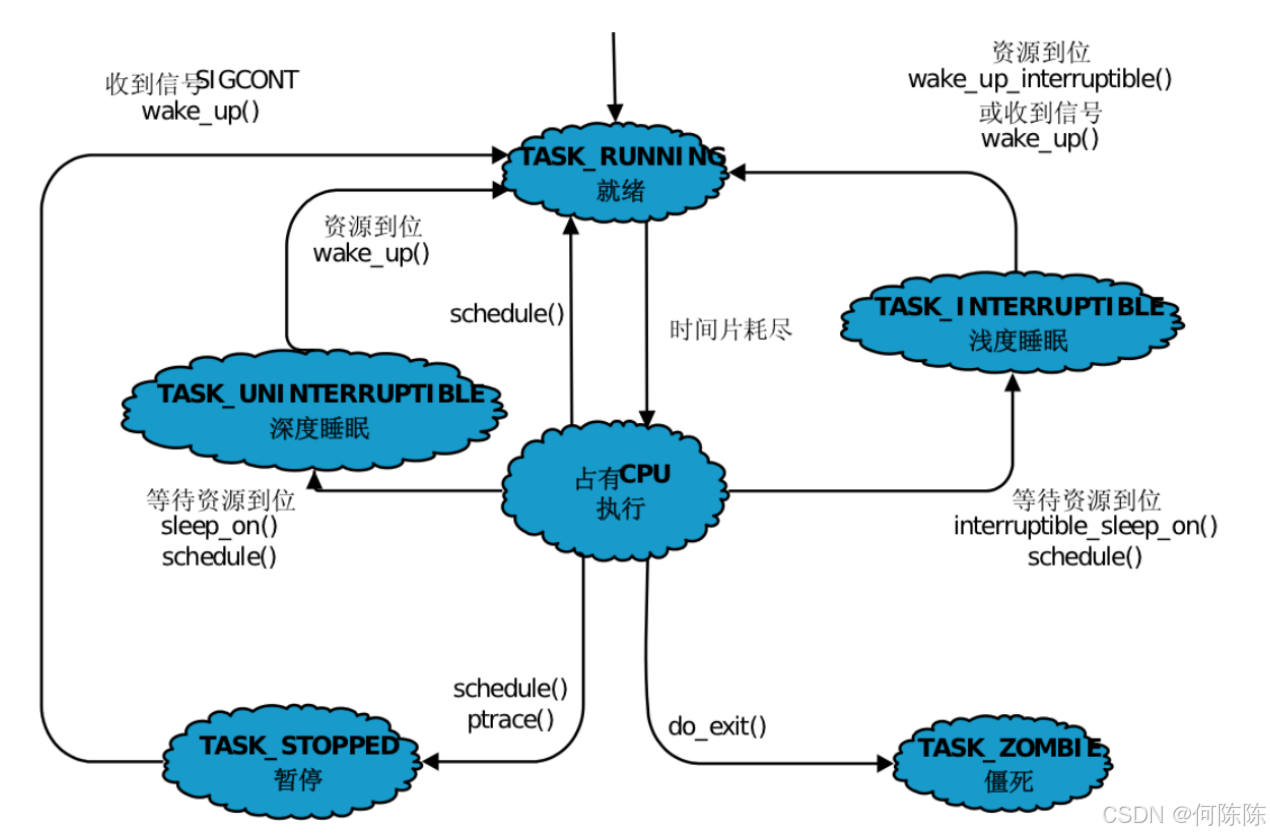
3 . Z(zombie)-僵尸进程
僵死状态(Zombies)是一个比较特殊的状态。当进程退出并且父进程(使用wait()系统调用)没有读取到子进程退出的返回代码时就会产生僵死(尸)进程没有读取到子进程退出的返回代码时就会产生僵死(尸)进程 僵死进程会以终止状态保持在进程表中,并且会一直在等待父进程读取退出状态代码。 所以,只要子进程退出,父进程还在运行,但父进程没有读取子进程状态,子进程进入Z状态僵尸进程危害
进程的退出状态必须被维持下去,因为他要告诉关心它的进程(父进程),你交给我的任务,我办的怎么样了。可父进程如果一直不读取,那子进程就一直处于Z状态 维护退出状态本身就是要用数据维护,也属于进程基本信息,所以保存在task_struct(PCB)中,换句话说,Z状态一直不退出,PCB一直都要维护 (内存泄漏) 那一个父进程创建了很多子进程,就是不回收,是不是就会造成内存资源的浪费?是的!因为数据结构对象本身就要占用内存,想想C中定义一个结构体变量(对象),是要在内存的某个位置进行开辟空间! 内存泄漏
4 . 孤儿进程
父进程如果提前退出,那么子进程后退出,进入Z之后,那该如何处理呢? 父进程先退出,子进程就称之为“孤儿进程” 孤儿进程被1号init进程领养(bash),为保证子进程正常被回收,避免内存泄漏,所以要有init进程回收。
5 .进程运行态(R)
如图:每一个进程都有自己task_struct ,里面储存这进程对应的信息,另外他还可能存储着下一个pcb的地址,方便作为链表样式来管理;

我们在运行进程的时候,每一个PCB会被放在一个运行队列当中,在队列当中的状态就算是R状态。
当然一个进程时间太长的话也不会一直占用cpu,他们可能会按照时间片的方式进行切换,这样在一个时间段内同时得以推进的代码,就叫做并发
在任何时刻,都同时有多个进程在真的运行,我们叫做并行
6 .进程阻塞(S,D)
当我们在使用scanf之类的函数的时候,他运行的时候,会等待键盘资源是否就绪,键盘上面有没有被用户按下的按键,若有,按键数据交给进程。
阻塞和运行的状态变化,往往伴随着pcb被连入不同的队列中。入队列的不是进程的什么代码而是进程的pcb
这里我们要知道,不是只有cpu才有运行队列,各种设备也有自己的wait_queue .当pcb需要各种设备的数据的时候,他会被排进该设备的等待队列,等待拿到数据,拿到之后,pcb重新排入运行队列,这里就会有S~R,S~D相关的状态切换。

7 .进程挂起
进程挂起是用时间(效率)换空间的做法:
当我们内存不够用的时候,os会将一部分数据(存储在磁盘上面(唤出),以便有更多可用的内存空间,当需要使用该数据的时候,再将该数据加载回内存中(唤入)。这样的处理方法,可能会经常使用I/O,效率大大降低。
8 .进程切换
进程会根据时间片进行切换,在切换的过程中,最重要的一件事情是:上下文数据的保护和恢复
cpu内的寄存器本身是硬件,具有数据存储的能力,cpu的寄存器硬件只有一套(很多个),cpu内部的数据,可以有多套,有几个进程,就有几套和该进程对应的上下文数据。但是:寄存器!= 寄存器内容
进程上下文:cpu内部的所有的寄存器中的临时数据。
五、进程优先级
1 .基本概念
cpu资源分配的先后顺序,就是指进程的优先权(priority)。 优先权高的进程有优先执行权利。配置进程优先权对多任务环境的linux很有用,可以改善系统性能。还可以把进程运行到指定的CPU上,这样一来,把不重要的进程安排到某个CPU,可以大大改善系统整体性能。
2 .查看系统进程
ps –l命令

UID : 代表执行者的身份 PID : 代表这个进程的代号 PPID :代表这个进程是由哪个进程发展衍生而来的,亦即父进程的代号 PRI :代表这个进程可被执行的优先级,其值越小越早被执行 NI :代表这个进程的nice值
3 . PRI and NI
PRI也还是比较好理解的,即进程的优先级,或者通俗点说就是程序被CPU执行的先后顺序,此值越小进程的优先级别越高 那NI:就是我们所要说的nice值了,其表示进程可被执行的优先级的修正数值 PRI值越小越快被执行,那么加入nice值后,将会使得PRI变为:PRI(new)=PRI(old)+nice 这样,当nice值为负值的时候,那么该程序将会优先级值将变小,即其优先级会变高,则其越快被执行 所以,调整进程优先级,在Linux下,就是调整进程nice值 nice其取值范围是-20至19,一共40个级别。
4 . PRI vs NI
需要强调一点的是,进程的nice值不是进程的优先级,他们不是一个概念,但是进程nice值会影响到进程的优先级变化。 可以理解nice值是进程优先级的修正数据
5 .查看进程优先级的命令
用top命令更改已存在进程的nice:top 进入top后按“r”–>输入进程PID–>输入nice值
6 .其他概念
竞争性: 系统进程数目众多,而CPU资源只有少量,甚至1个,所以进程之间是具有竞争属性的。为了高效完成任务,更合理竞争相关资源,便具有了优先级 独立性: 多进程运行,需要独享各种资源,多进程运行期间互不干扰 并行: 多个进程在多个CPU下分别,同时进行运行,这称之为并行 并发: 多个进程在一个CPU下采用进程切换的方式,在一段时间之内,让多个进程都得以推进,称之为并发
六、环境变量
命令行参数:
为什么要有命令行参数?
本质:命令行参数本质是交给我们程序的不同的选型,用来定制不同的程序功能。命令行中会携带很多的选项
例如:
#include<stdio.h> #include<stdlib.h> int main(int argc,char *argv[]) { int j=0; for(j=0;argv[j];j++) printf("%s\n",argv[j]); int i=0; for(i=0;i<argc;i++) { if(strcmp(argv[i],"-a")==0) printf("-aaaaaa\n"); else if(strcmp(argv[i],"-b")==0) printf("-bbbbbb\n"); else printf("-cccccccc\n"); } return 0; } 程序里面的参数,默认是输入给父进程bash的
1 .基本概念
环境变量(environment variables)一般是指在操作系统中用来指定操作系统运行环境的一些参数 如:我们在编写C/C++代码的时候,在链接的时候,从来不知道我们的所链接的动态静态库在哪里,但是照样可以链接成功,生成可执行程序,原因就是有相关环境变量帮助编译器进行查找。 环境变量通常具有某些特殊用途,还有在系统当中通常具有全局特性
Linux中,存在一些全局的设置,告诉命令行解释器,应该去哪些路径下去寻址可执行程序
系统中很多的配置,在我们登陆Linux系统的时候,已经被加载到了bash进程中(内存)。所以,默认我们查到的环境变量是内存级的(重启后会恢复到配置文件中的环境变量)
我像执行我们的命令 ,和系统指令一样。
最开始环境变量不是在内存中,而是在系统的对应的配置文件中,我们可以通过以下方式去更改:
vim .vash_profile
vim .bashrc
vim /etc/bashrc
bash进程启动的时候,默认会给我子进程形成两张表:
argv[]命令行参数表:用户输入命令行,动态获取,可以更新
env[]环境变量表:来自于os的配置文件,bash通过各种方式交给子进程
2 .常见环境变量
PATH : 指定命令的搜索路径 HOME :指定用户的主工作目录(即用户登陆到Linux系统中时,默认的目录) SHELL :当前Shell,它的值通常是/bin/bash。
3 . 查看环境变量方法
echo $NAME //NAME:你的环境变量名称
例如:
![]()
4 . 和环境变量相关的命令



没有export的变量是本地变量:
本地变量只在本bash内部有效,无法被子进程继承下去,导成环境变量,此时才能被获取
内建命令
80%的命令都是由bash创建子进程执行,而export和echo是内建命令,不会创建子进程他们由bash亲自执行。
5 .环境变量的组织方式

6 .通过代码如何获取环境变量
方法汇总有:

命令行第三个参数
#include <stdio.h> int main(int argc, char *argv[], char *env[]) { int i = 0; for(; env[i]; i++){ printf("%s\n", env[i]); } return 0; }通过第三方变量environ获取
#include <stdio.h> int main(int argc, char *argv[]) { extern char **environ; int i = 0; for(; environ[i]; i++){ printf("%s\n", environ[i]); } return 0; }执行结果:

7 .通过系统调用获取或设置环境变量
获取环境变量:getenv
#include <stdio.h> #include <stdlib.h> int main() { printf("%s\n", getenv("PATH")); return 0; }执行结果:
![]()
8 .环境变量通常是具有全局属性的
环境变量通常具有全局属性,可以被子进程继承下去#include <stdio.h> #include <stdlib.h> int main() { char * env = getenv("MYENV"); if(env) { printf("%s\n", env); } return 0; }直接查看,发现没有结果,说明该环境变量根本不存在
导出环境变量 export MYENV="hello world" 再次运行程序,发现结果有了!说明:环境变量是可以被子进程继承下去的!父进程的数据默认能被子进程看到并访问命令行中启动的程序,都会变成进程,实际上都是bash的子进程
