阅读量:0
🤖️ DB-GPT简介(转自官网https://dbgpt.site/)
DB-GPT是一个开源的AI原生数据应用开发框架(AI Native Data App Development framework with AWEL(Agentic Workflow Expression Language) and Agents)。
目的是构建大模型领域的基础设施,通过开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单,更方便。
🚀 数据3.0 时代,基于模型、数据库,企业/开发者可以用更少的代码搭建自己的专属应用。
一、私域问答&数据处理&RAG(Retrieval-Augmented Generation)
支持内置、多文件格式上传、插件自抓取等方式自定义构建知识库,对海量结构化,非结构化数据做统一向量存储与检索
二、多数据源&GBI(Generative Business Intelligence)
支持自然语言与Excel、数据库、数仓等多种数据源交互,并支持分析报告。
三、多模型管理
海量模型支持,包括开源、API代理等几十种大语言模型。如LLaMA/LLaMA2、Baichuan、ChatGLM、文心、通义、智谱、星火等。
四、自动化微调
围绕大语言模型、Text2SQL数据集、LoRA/QLoRA/Pturning等微调方法构建的自动化微调轻量框架, 让TextSQL微调像流水线一样方便。
五、Data-Driven Multi-Agents&Plugins
支持自定义插件执行任务,原生支持Auto-GPT插件模型,Agents协议采用Agent Protocol标准
六、隐私安全
通过私有化大模型、代理脱敏等多种技术保障数据的隐私安全
一、环境搭建
windows11安装双系统(Ubuntu)
在你的电脑上再安装一个Ubuntu系统,教程可以看我上一篇文章
接下来的操作都在Ubutn系统中完成
安装python3.10
更新apt软件包:
sudo apt update 安装依赖
sudo apt install build-essential zlib1g-dev libncurses5-dev libgdbm-dev libnss3-dev libssl-dev libreadline-dev libffi-dev libsqlite3-dev wget libbz2-dev 从官网下载源文件
wget https://www.python.org/ftp/python/3.10.0/Python-3.10.0.tgz 解压缩Python3.10文件
tar -zvxf Python-3.10.0.tgz 开始安装
cd Python-3.10.0/ ./configure --enable-optimizations 编译
如果找不到make命令,就安装下,使用命令“sudo make install”
make 验证是否安装成功
python3.10 --version 更新python默认指向
没有安装vim可以执行以下命令安装
sudo apt install vim 修改文件
vim ~/.bashrc # 自己安装python3.10的路径 alias python='/usr/local/bin/python3' source ~/.bashrc 验证Python指向
python --version 安装Miniconda
推荐通过conda的虚拟环境来进行Python虚拟环境的安装。关于Miniconda环境的安装,可以参见Miniconda安装教程。
wget https://repo.anaconda.com/miniconda/Miniconda3-py310_23.3.1-0-Linux-x86_64.sh sh Miniconda3-py310_23.3.1-0-Linux-x86_64.sh 二、源码部署
下载DB-GPT源码
没有安装git的需要安装下
sudo apt update sudo apt install git 克隆项目源码(也可以自己下载下来)
git clone https://github.com/eosphoros-ai/DB-GPT.git 创建Python虚拟环境
进入项目源码目录
# 根据自己的目录来 cd /home/yw/DB-GPT-main 为了确保某个项目的稳定运行,一般来说都会优先考虑为该项目单独创建一个虚拟环境,以隔
离项目所需依赖,以免和别的项目冲突。我们可以按照如下方式创建一个名为 dbgpt_env 的虚拟环境,用于安装DB-GPT相关依赖,以及运行该项目
conda create -n dbgpt_env python=3.10 如果是首次安装conda,则需要运行 conda init 命令来添加 conda 的配置到当前shell启动脚本中
conda init bash 重启命令行终端并使之生效
source ~/.bashrc 激活dbgpt_env环境
conda activate dbgpt_env 安装相关依赖
. 代表当前路径, [default] 代表项目所需全部依赖,在执行该命令前,需要确保处于DB-GPT的项目的主目录下
sudo pip install -e ".[default]" 下载Embedding模型
git-lfs是专门用于存储和下载大型文件的工具,在下载模型前需要下载和安装Git LFS。使用如下命令进行安装
sudo apt-get update sudo apt-get install git-lfs git lfs install 下载模型之前,首先需要在DB-GPT项目主目录下创建models文件夹
mkdir models 进入models文件夹
cd ./models 根据官方推荐,这里考虑下载 text2vec-large-chinese 模型作为基础Embedding模型。我们可以使用如下命令进行安装
git clone https://huggingface.co/GanymedeNil/text2vec-large-chinese 创建配置文件
进入项目源码目录
# 根据自己的目录来 cd /home/yw/DB-GPT-main 复制 .env.template 文件的方法创建一个 .env 配置文件
cp .env.template .env 使用本地模型或调用代理模型(选一种)
本地模型
- 下载大模型
还是在models文件夹路径内,使用如下命令下载Qwen1.5-7B模型
git clone https://www.modelscope.cn/qwen/Qwen1.5-7B.git - 修改 model_config.py 文件
添加以下代码,其中Key是模型名称,而value中的 Qwen1.5-7B 则是模型项目文件名称
"qwen1.5-7b": os.path.join(MODEL_PATH, "Qwen1.5-7B"), - 修改 .env 文件(注意需要在项目根目录下执行)
sudo vim .env # 将文件内的LLM_MODEL赋值为qwen1.5-7b LLM_MODEL=qwen1.5-7b 代理模型
- 注册智谱AI账户并获取Api-Key https://open.bigmodel.cn/login

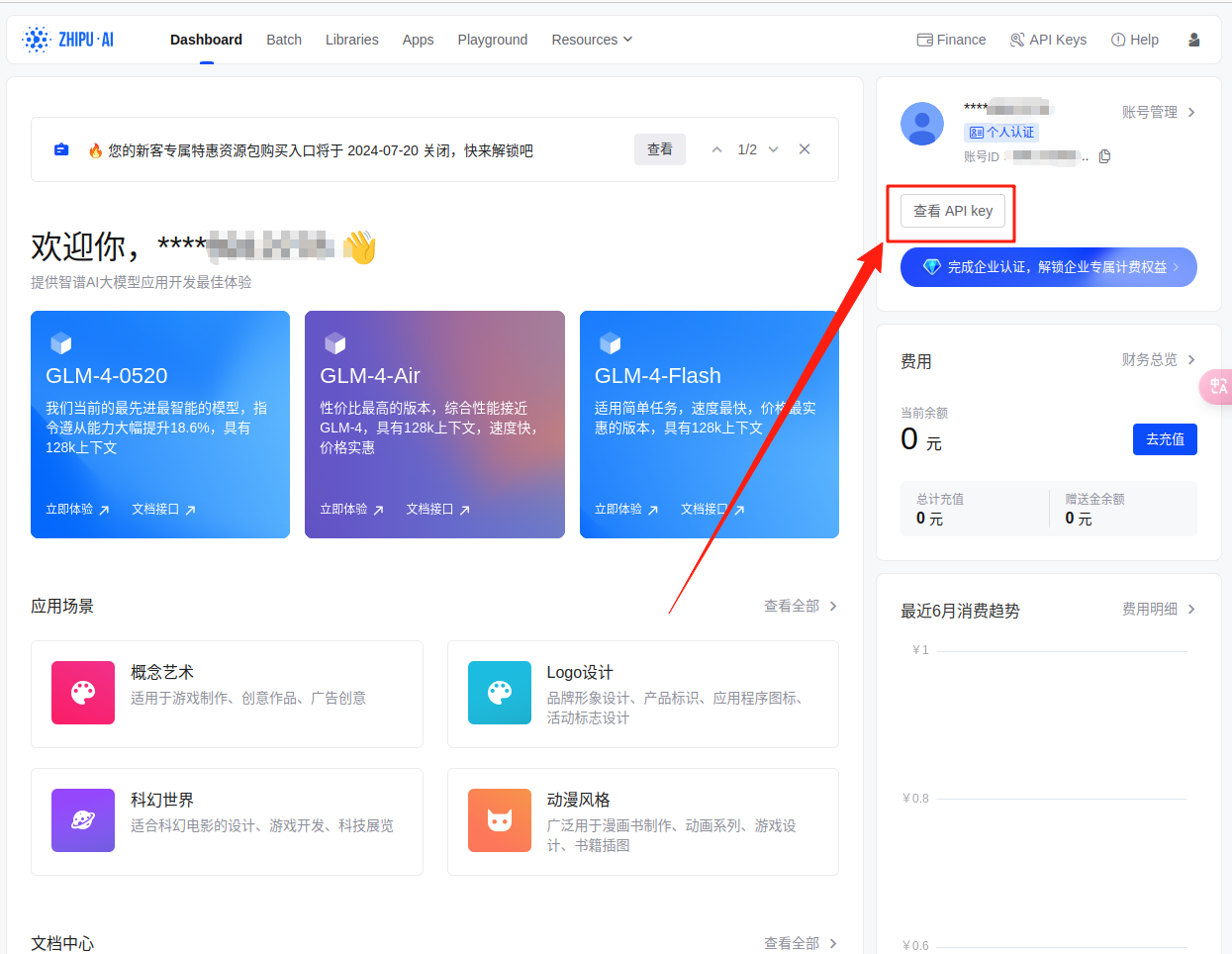

修改.env文件(注意需要在项目根目录下执行)
sudo vim .env LLM_MODEL=zhipu_proxyllm PROXY_SERVER_URL=https://open.bigmodel.cn/api/paas/v4/chat/completions ZHIPU_MODEL_VERSION=glm-4 ZHIPU_PROXY_API_KEY=这里是你的API-KEY 配置元数据
执行脚本初始化表结构, 如果是做版本升级需要提对应的DDL变更来更新表结构
你也可以找到文件运行到Navicat中
mysql -h127.0.0.1 -uroot -p{your_password} < ./assets/schema/dbgpt.sql 修改.env文件配置MySQL数据库
LOCAL_DB_TYPE=mysql LOCAL_DB_USER= {your username} LOCAL_DB_PASSWORD={your_password} LOCAL_DB_HOST=127.0.0.1 LOCAL_DB_PORT=3306 启动DB-GPT服务
sudo python dbgpt/app/dbgpt_server.py 三、基础使用
启动成功后访问“localhost:5670”

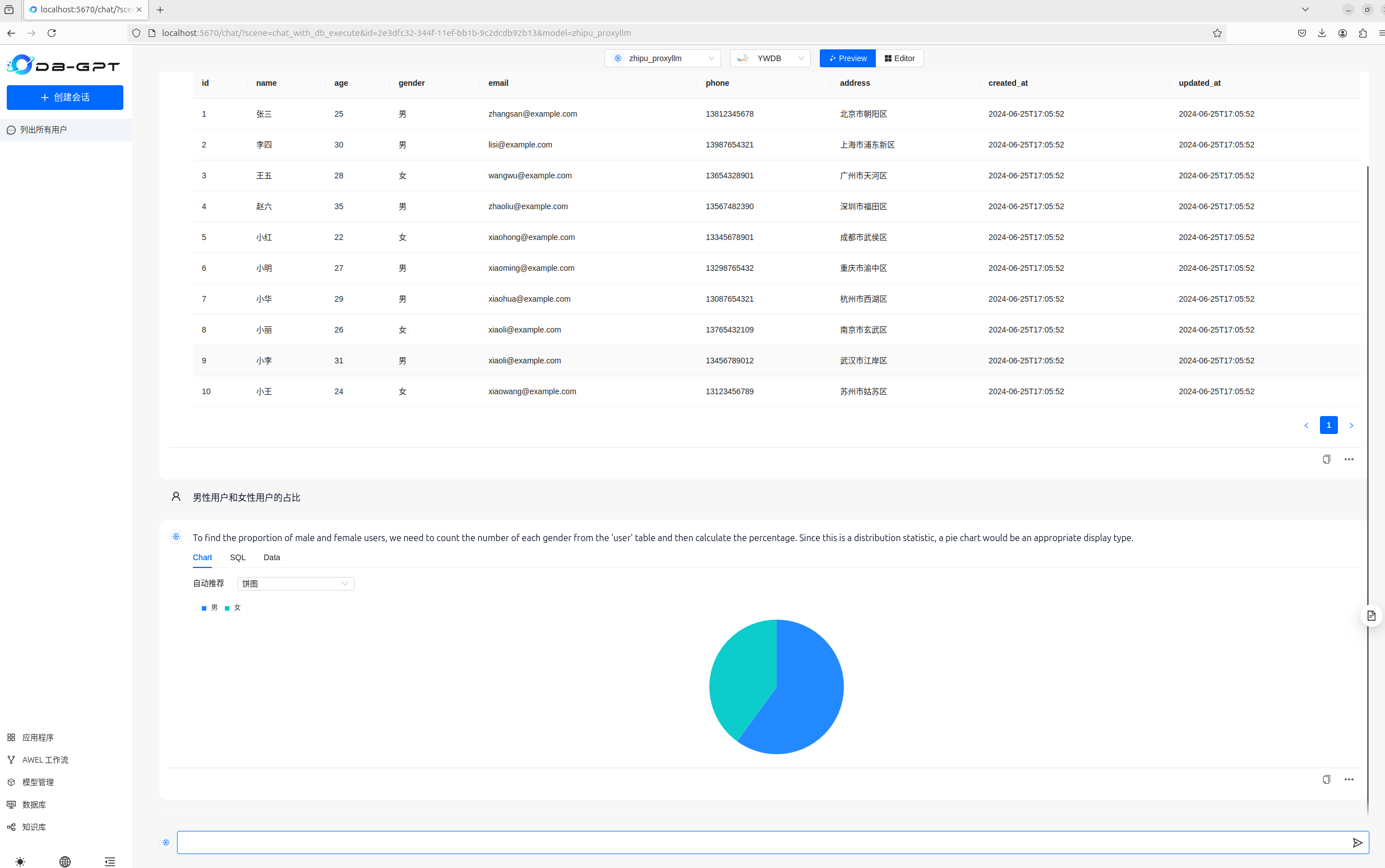
配置自己的数据库(我这里随便建了一个)


使用效果