
阅读量:0
目录
一、RxJava 响应式编程语法
背景
之前 AI 生成相关的功能是等所有内容全部生成后,再返回给前端,用户可能要等待较长的时间。
有没有办法进行优化呢?
仔细阅读智谱 AI 的官方文档,提供了 流式 接口调用方式:
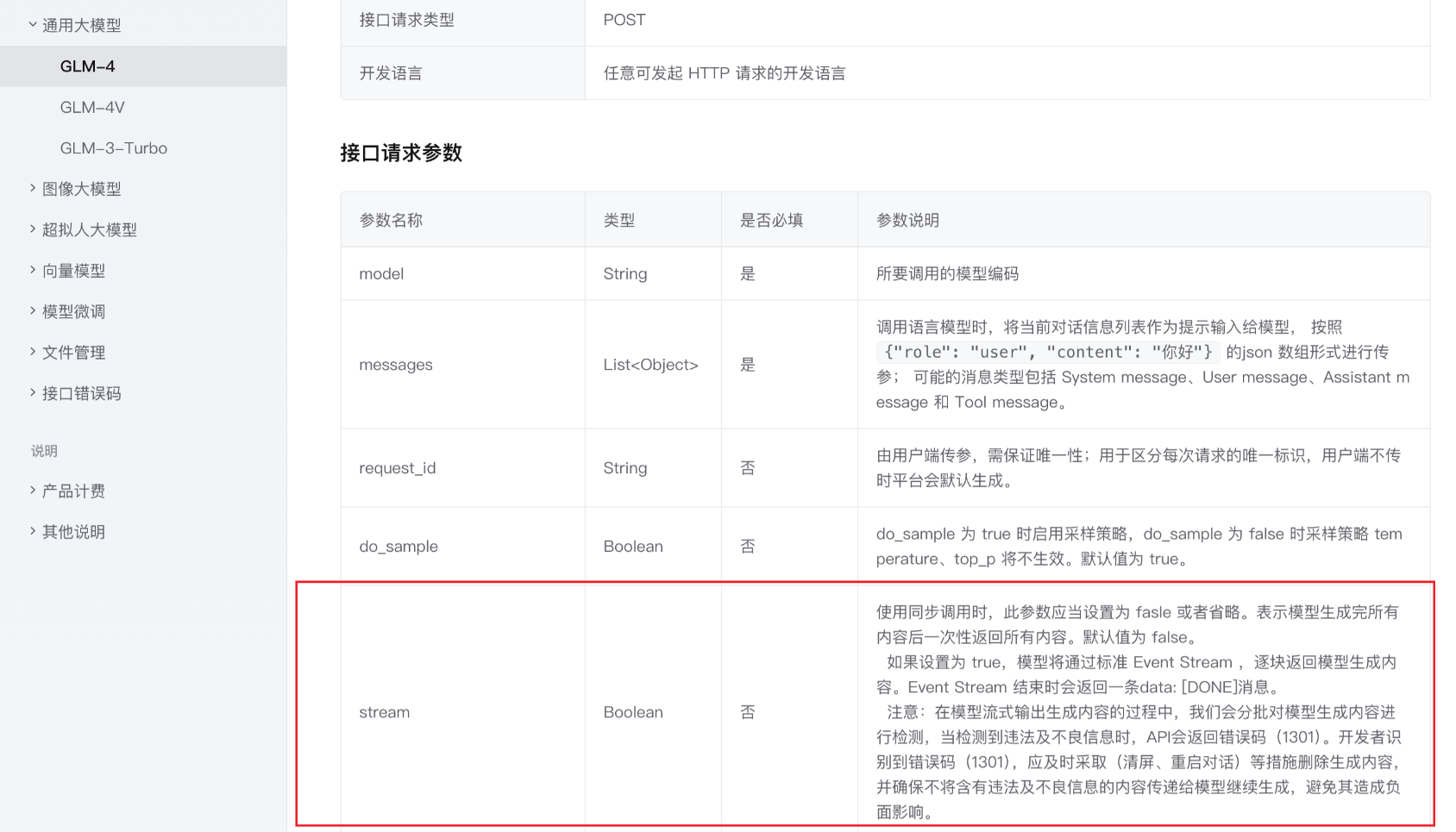
通过设置 stream 为 true 来开启流式:
官方提供了一段示例代码,如果 stream 设置为 true,需要从返回结果中获取到 flowable 对象:

映射到代码中来需要这样构造请求参数:
/** * 流式请求 * @param messages 消息列表 * @param stream 是否流式传输 * @param temperature 温度参数 * @return 返回模型数据的Flowable */ public Flowable<ModelData> doRequestFlowable(List<ChatMessage> messages, Boolean stream, Float temperature) { // 构造请求 ChatCompletionRequest chatCompletionRequest = ChatCompletionRequest.builder() .model(Constants.ModelChatGLM4) .stream(stream) .invokeMethod(Constants.invokeMethod) .temperature(temperature) .messages(messages) .build(); ModelApiResponse invokeModelApiResp = clientV4.invokeModelApi(chatCompletionRequest); return invokeModelApiResp.getFlowable(); } 这个流式请求是意思?Flowable 又是什么?可以给我们的项目带来哪些优化呢?
实际上 Flowable 是 RxJava 响应式编程库中定义的类,为了更好地进行流式开发,我们要先来了解下响应式编程和 RxJava。
什么是响应式编程?
响应式编程(Reactive Programming)是一种编程范式,它专注于 异步数据流 和 变化传播。
响应式编程的核心思想是“数据流是第一等公民”,程序的逻辑建立在数据流的变化之上。
响应式编程的几个核心概念:
1)数据流:响应式编程中,数据以流(Streams)的形式存在。流就像一条河,源源不断、有一个流向(比如从 A 系统到 B 系统再到 C 系统),它可以被过滤、观测、或者跟另一条河流合并成一个新的流。
比如用户输入、网络请求、文件读取都可以是数据流,可以很轻松地对流进行处理。
比如 Java 8 的 Stream API,下列代码中将数组作为一个流,依次进行过滤、转换、汇聚。
list.stream() .filter() .map() .collect()2)异步处理:响应式编程是异步的,即操作不会阻塞线程,而是通过回调或其他机制在未来某个时间点处理结果。这提高了应用的响应性和性能。
3)变化传播:当数据源发生变化时,响应式编程模型会自动将变化传播到依赖这些数据源的地方。这种传播是自动的,不需要显式调用。
举个例子,有一只股票涨了,所有 订阅 了这只股的人,都会同时收到 APP 的通知,不用你自己盯着看。
注意,响应式编程更倾向于声明式编程风格,通过定义数据流的转换和组合来实现复杂的逻辑。比如,可以利用 map、filter 等函数来实现数据转换,而不是将一大堆复杂的逻辑混杂在一个代码块中。
什么是 RxJava?
RxJava 是一个基于事件驱动的、利用可观测序列来实现异步编程的类库,是响应式编程在 Java 语言上的实现。
这个定义中有几个概念,我们分别解释。
1、事件驱动
事件可以是任何事情,如用户的点击操作、网络请求的结果、文件的读写等。事件驱动的编程模型是通过事件触发行动。
比如前端开发中,用户点击按钮后会进行弹窗,这就是“点击事件”触发了“弹窗行动”
// 前端按钮点击 btn.onClick(()->{ // 弹窗 showModal(); })在 RxJava 中,事件可以被看作是数据流中的数据项,称为“事件流”或“数据流”。每当一个事件发生,这个事件就会被推送给那些对它感兴趣的观察者(Observers)。
2、可观测序列
可观测序列是指一系列按照时间顺序发出的数据项,可以被观察和处理。可观测序列提供了一种将数据流和异步事件建模为一系列可以订阅和操作的事件的方式。
可以理解为在数据流的基础上封装了一层,多加了一点方法。
RxJava 的核心知识点
观察者模式
RxJava是基于观察者模式实现的,分别有观察者和被观察者两个角色,被观察者会实时传输数据流,观察者可以观测到这些数据流。
基于传输和观察的过程,用户可以通过一些操作方法对数据进行转换或其他处理。
在RxJava中,观察者就是Observer,被观察者是Observable和Flowable。
Observable适合处理相对较小的、可控的、不会迅速产生大量数据的场景。它不具备背压处理能力,也就是说,当数据生产速度超过数据消费速度时,可能会导致内存溢出或其他性能问题。
Flowable是针对背压(反向压力)问题而设计的可观测类型。背压问题出现于数据生产速度超过数据消费速度的场景。Flowable提供了多种背压策略来处理这种情况,确保系统在处理大量数据时仍然能够保持稳定。
被观察者.subscribe(观察者),它们之间就建立的订阅关系,被观察者传输的数据或者发出的事件会被观察者观察到。
常用操作符
前面提到用户可以通过一些方法对数据进行转换或其他处理,RxJava提供了很多操作符供我们使用,这块其实和Java8的Stream类似,概念上都是一样的。
操作符主要可以分为以下几大类:
1)变换类操作符,对数据流进行变换,如map、flatMap等。
比如利用map将int类型转为string:
Flowable<String> flowable = Flowable.range(0, Integer.MAX_VALUE) .map(i -> String.valueOf(i));2)聚合类操作符,对数据流进行聚合,如toList、toMap等。
将数据转成一个list:
Flowable.range(0, Integer.MAX_VALUE).toList();3)过滤操作符,过滤或者跳过一些数据,如filter、skip等。
将大于10的数据转成一个list:
Flowable.range(0, Integer.MAX_VALUE).filter(i -> i > 10).toList();4)连接操作符,将多个数据流连接到一起,如concat、zip等。
创建两个Flowable,通过concat连接得到一个被观察者,进行统一处理:
// 创建两个Flowable对象 Flowable<String> flowable1 = Flowable.just("A", "B", "C"); Flowable<String> flowable2 = Flowable.just("D", "E", "F"); // 使用concat操作符将两个Flowable合并 Flowable<String> flowable = Flowable.concat(flowable1, flowable2);5)排序操作符,对数据流内的数据进行排序,如sorted:
Flowable<String> flowable = Flowable.concat(flowable1, flowable2).sorted();事件
RxJava也是一个基于事件驱动的框架,我们来看看一共有哪些事件,分别在什么时候触发:
1)onNext,被观察者每发送一次数据,就会触发此事件。
2)onError,如果发送数据过程中产生意料之外的错误,那么被观察者可以发送此事件。
3)onComplete,如果没有发生错误,那么被观察者在最后一次调用onNext之后发送此事件表示完成数据传输。
对应的观察者得到这些事件后,可以进行一定处理,例如:
flowable.observeOn(Schedulers.io()) .doOnNext(item -> { System.out.println("来数据啦" + item.toString()); }) .doOnError(e -> { System.out.println("出错啦" + e.getMessage()); }) .doOnComplete(() -> { System.out.println("数据处理完啦"); }).subscribe();DEMO 演示
1)引入依赖
注意,智谱 AI 的 SDK 默认引入了 2.x 版本的 RxJava,在我们的项目中可以不用引入该依赖。
如果要在新项目中使用 RxJava,单独引入 Java 需要的、对应版本的依赖即可:GitHub - reactive-streams/reactive-streams-jvm: Reactive Streams Specification for the JVM
示例代码:
<dependency> <groupId>org.reactivestreams</groupId> <artifactId>reactive-streams</artifactId> <version>1.0.4</version> </dependency>2)编写单元测试
@Test void rxJavaDemo() throws InterruptedException { // 创建一个流,每秒发射一个递增的整数(数据流变化) Flowable<Long> flowable = Flowable.interval(1, TimeUnit.SECONDS) .map(i -> i + 1) .subscribeOn(Schedulers.io()); // 指定创建流的线程池 // 订阅 Flowable 流,并打印每个接受到的数字 flowable.observeOn(Schedulers.io()) .doOnNext(item -> System.out.println(item.toString())) .subscribe(); // 让主线程睡眠,以便观察输出 Thread.sleep(10000L); }二、AI 生成题目优化
需求分析
原先 AI 生成题目的场景响应较慢,如果题目数过多,容易产生请求超时;并且界面上没有响应,用户体验不佳。
需要 流式化改造 AI 生成题目接口,一道一道地实时返回已生成题目给前端,而不是让前端请求一直阻塞等待,最后一起返回,提升用户体验且避免请求超时。
首先智谱 AI 为我们提供了流式响应的支持,数据已经可以一点一点地返回给后端了,那么我们要思考的问题是如何让后端接收到的一点一点的内容实时返回给前端?
需要进行一些调研,来了解前后端实时通讯的方案。
前后端实时通讯方案
几种主流的实现方案:
1)轮询(前端主动去要)
前端间隔一定时间就调用后端提供的结果接口,比如 200ms 一次,后端处理一些结果就累加放置在缓存中。
2)SSE(后端推送给前端)
前端发送请求并和后端建立连接后,后端可以实时推送数据给前端,无需前端自主轮询。
3)WebSocket
全双工协议,前端能实时推送数据给后端(或者从后端缓存拿数据),后端也可以实时推送数据给前端。
大家可能对 SSE 技术比较陌生,下面重点讲解。
SSE 技术
基本概念
服务器发送事件(Server-Sent Events)是一种用于从服务器到客户端的 单向、实时 数据传输技术,基于 HTTP协议实现。
它有几个重要的特点:
- 单向通信:SSE 只支持服务器向客户端的单向通信,客户端不能向服务器发送数据。
- 文本格式:SSE 使用 纯文本格式 传输数据,使用 HTTP 响应的
text/event-streamMIME 类型。 - 保持连接:SSE 通过保持一个持久的 HTTP 连接,实现服务器向客户端推送更新,而不需要客户端频繁轮询。
- 自动重连:如果连接中断,浏览器会自动尝试重新连接,确保数据流的连续性。
SSE 数据格式
SSE 数据流的格式非常简单,每个事件使用 data 字段,事件以两个换行符结束。还可以使用 id 字段来标识事件,并且 retry 字段可以设置重新连接的时间间隔。
示例格式如下:
data: First message\n \n data: Second message\n \n data: Third message\n id: 3\n \n retry: 10000\n data: Fourth message\n \n自主实现 SSE
实现 SSE 非常简单,无论是 Java 服务端还是前端 HTML5 都支持了 SSE,以下内容仅作了解。
1)服务器端
需要生成符合 SSE 格式的响应,并设置合适的 HTTP 头。使用 Servlet 来实现 SSE 示例:
import java.io.IOException; import java.io.PrintWriter; import javax.servlet.ServletException; import javax.servlet.annotation.WebServlet; import javax.servlet.http.HttpServlet; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; @WebServlet("/sse") public class SseServlet extends HttpServlet { protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { response.setContentType("text/event-stream"); response.setCharacterEncoding("UTF-8"); PrintWriter writer = response.getWriter(); for (int i = 0; i < 10; i++) { writer.write("data: Message " + i + "\n\n"); writer.flush(); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } writer.close(); } } 当然,如果是 Spring 项目,还有更简单的实现方式,直接给请求返回 SseEmitter 对象即可。
@GetMapping("/sse") public SseEmitter testSSE() { // 建立 SSE 连接对象,0 表示不超时 SseEmitter emitter = new SseEmitter(0L); ... 业务逻辑处理 return emitter; }应用场景
由于现代浏览器普遍支持 SSE,所以它的应用场景非常广泛,AI 对话就是 SSE 的一个典型的应用场景。
再举一些例子:
- 实时更新:股票价格、体育比赛比分、新闻更新等需要实时推送的应用。
- 日志监控:实时监控服务器日志或应用状态。
- 通知系统:向客户端推送系统通知或消息。
方案设计
最终方案
回归到本项目,具体实现方案如下:
1)前端向后端发送普通 HTTP 请求
2)后端创建 SSE 连接对象,为后续的推送做准备
3)后端流式调用智谱 AI,获取到数据流,使用 RxJava 订阅数据流
4)以 SSE 的方式响应前端,至此接口主流程已执行完成
5)异步:基于 RxJava 实时获取到智谱 AI 的数据,并持续将数据拼接为字符串,当拼接出一道完整题目时,通过 SSE 推送给前端。
6)前端每获取一道题目,立刻插入到表单项中
明确方案后,下面进行开发。
后端开发
1、封装通用的流式调用 AI 接口
跟之前的请求方法不同的是:
- 将请求的 stream 参数为 true,表示开始流式调用。
- 返回结果为 Flowable 类型,为流式结果。
代码如下:
/** * 通用流式请求(简化消息传递) * * @param systemMessage * @param userMessage * @param temperature * @return */ public Flowable<ModelData> doStreamRequest(String systemMessage, String userMessage, Float temperature) { List<ChatMessage> chatMessageList = new ArrayList<>(); ChatMessage systemChatMessage = new ChatMessage(ChatMessageRole.SYSTEM.value(), systemMessage); chatMessageList.add(systemChatMessage); ChatMessage userChatMessage = new ChatMessage(ChatMessageRole.USER.value(), userMessage); chatMessageList.add(userChatMessage); return doStreamRequest(chatMessageList, temperature); } /** * 通用流式请求 * * @param messages * @param temperature * @return */ public Flowable<ModelData> doStreamRequest(List<ChatMessage> messages, Float temperature) { // 构建请求 ChatCompletionRequest chatCompletionRequest = ChatCompletionRequest.builder() .model(Constants.ModelChatGLM4) .stream(Boolean.TRUE) .temperature(temperature) .invokeMethod(Constants.invokeMethod) .messages(messages) .build(); try { ModelApiResponse invokeModelApiResp = clientV4.invokeModelApi(chatCompletionRequest); return invokeModelApiResp.getFlowable(); } catch (Exception e) { e.printStackTrace(); throw new BusinessException(ErrorCode.SYSTEM_ERROR, e.getMessage()); } }2、新建 AI 生成题目的 SSE 接口
1)首先定义接口,注意 SSE 必须是 get 请求:
@GetMapping("/ai_generate/sse") public SseEmitter aiGenerateQuestionSSE( AiGenerateQuestionRequest aiGenerateQuestionRequest) { ... }2)建立 SSE 连接对象,并返回:
// 建立 SSE 连接对象,0 表示不超时 SseEmitter emitter = new SseEmitter(0L); return emitter;3)调用 AI 获取数据流:
// AI 生成,sse 流式返回 Flowable<ModelData> modelDataFlowable = aiManager.doStreamRequest(GENERATE_QUESTION_SYSTEM_MESSAGE, userMessage, null);4)异步对流进行解析和转换,转为单个字符,便于处理:
modelDataFlowable // 异步线程池执行 .observeOn(Schedulers.io()) .map(chunk -> chunk.getChoices().get(0).getDelta().getContent()) .map(message -> message.replaceAll("\\s", "")) .filter(StrUtil::isNotBlank) .flatMap(message -> { // 将字符串转换为 List<Character> List<Character> charList = new ArrayList<>(); for (char c : message.toCharArray()) { charList.add(c); } return Flowable.fromIterable(charList); })5)异步拼接 JSON 单题数据,并利用 SSE 推送至前端
括号匹配算法:
// 左括号计数器,除了默认值外,当回归为 0 时,表示左括号等于右括号,可以截取 AtomicInteger counter = new AtomicInteger(0); // 拼接完整题目 StringBuilder stringBuilder = new StringBuilder(); flowable.doOnNext(c -> { { // 识别第一个 [ 表示开始 AI 传输 json 数据,打开 flag 开始拼接 json 数组 if (c == '{') { flag.addAndGet(1); } if (flag.get() > 0) { contentBuilder.append(c); } if (c == '}') { flag.addAndGet(-1); if (flag.get() == 0) { // 累积单套题目满足 json 格式后,sse 推送至前端 // sse 需要压缩成当行 json,sse 无法识别换行 emitter.send(JSONUtil.toJsonStr(contentBuilder.toString())); // 清空 StringBuilder contentBuilder.setLength(0); } } } }) 6)监听 flowable 完成事件,并开启订阅:
flowable .doOnComplete(emitter::complete) .subscribe()完整代码如下:
@GetMapping("/ai_generate/sse") public SseEmitter aiGenerateQuestionSSE(AiGenerateQuestionRequest aiGenerateQuestionRequest) { ThrowUtils.throwIf(aiGenerateQuestionRequest == null, ErrorCode.PARAMS_ERROR); // 获取参数 Long appId = aiGenerateQuestionRequest.getAppId(); int questionNumber = aiGenerateQuestionRequest.getQuestionNumber(); int optionNumber = aiGenerateQuestionRequest.getOptionNumber(); // 获取应用信息 App app = appService.getById(appId); ThrowUtils.throwIf(app == null, ErrorCode.NOT_FOUND_ERROR); // 封装 Prompt String userMessage = getGenerateQuestionUserMessage(app, questionNumber, optionNumber); // 建立 SSE 连接对象,0 表示永不超时 SseEmitter sseEmitter = new SseEmitter(0L); // AI 生成,SSE 流式返回 Flowable<ModelData> modelDataFlowable = aiManager.doStreamRequest(GENERATE_QUESTION_SYSTEM_MESSAGE, userMessage, null); // 左括号计数器,除了默认值外,当回归为 0 时,表示左括号等于右括号,可以截取 AtomicInteger counter = new AtomicInteger(0); // 拼接完整题目 StringBuilder stringBuilder = new StringBuilder(); modelDataFlowable .observeOn(Schedulers.io()) .map(modelData -> modelData.getChoices().get(0).getDelta().getContent()) .map(message -> message.replaceAll("\\s", "")) .filter(StrUtil::isNotBlank) .flatMap(message -> { List<Character> characterList = new ArrayList<>(); for (char c : message.toCharArray()) { characterList.add(c); } return Flowable.fromIterable(characterList); }) .doOnNext(c -> { // 如果是 '{',计数器 + 1 if (c == '{') { counter.addAndGet(1); } if (counter.get() > 0) { stringBuilder.append(c); } if (c == '}') { counter.addAndGet(-1); if (counter.get() == 0) { // 可以拼接题目,并且通过 SSE 返回给前端 sseEmitter.send(JSONUtil.toJsonStr(stringBuilder.toString())); // 重置,准备拼接下一道题 stringBuilder.setLength(0); } } }) .doOnError((e) -> log.error("sse error", e)) .doOnComplete(sseEmitter::complete) .subscribe(); return sseEmitter; }三、AI 评分优化
需求分析
目前的 AI 评分功能存在 2 个问题:
- AI 调用需要费用,用户对同样的题目做出同样的选择,理论会得到一样的解答,不需要每次都询问 AI
- AI 评分的响应时间较长,效率有待提升。
如何解决这些问题呢?
答案必然是 “缓存”。只要提到“响应慢”、“数据可复用”,就要想到缓存。
方案设计
技术选型
缓存的技术选型上,一般是本地缓存和 Redis 分布式缓存。
如果项目不考虑分布式或扩容、且不要求持久化,一般用本地缓存能解决的问题,就不要用分布式缓存,会增加系统的复杂度。
对于我们的缓存需求,哪怕是多机部署,每台服务器上分别缓存也是 ok 的,不用保证多台机器缓存间的一致性,所以采用 Caffeine 本地缓存。
Caffeine 官方文档:GitHub - ben-manes/caffeine: A high performance caching library for Java
缓存设计
要缓存哪些内容?如何设计缓存的 key / value 结构呢?
1)缓存 key 设计
回归到需求“用户对同样的题目做出同样的选择,理论会得到一样的解答”
所以可以将应用 id 和用户的答案列表作为 key。
但答案列表可能很长,可以利用哈希算法(md5)来压缩 key,节省空间。
注意,如果是分布式缓存,还需要在 key 开头拼接业务前缀。此处我们可以单独为每个业务创建本地缓存,相互隔离,所以 key 可以简单一些。
2)缓存 value 设计
缓存 AI 回答的结果,为了可读性可以存 JSON 结构,为了压缩空间可以存二进制等其他结构。
3)缓存过期时间设置
**必须设置缓存过期时间!**假设有 20 道题目,那么不同选择累计总次数一共是 2 的 20 次方,100 多万。
过期时间根据实际业务场景和缓存空间的大小、数据的一致性的要求设置,合适即可,此处可以设置为 1 天。
业务流程
1)在 AI 回答前,哈希处理用户答题选择,得到摘要,拼接缓存 key。
2)通过摘要查找缓存,若命中则直接返回答题结果。
3)若缓存中未找到,则请求 AI 回答。
4)正确解析 AI 返回的 JSON 后,将其放置在缓存中。
注意事项
1)应用题目发生变更时,需要清理缓存(自行实现即可,重点是怎么识别该应用的缓存,比如 appId 不做 MD5,就可以根据 appId 去清理特定前缀的缓存)
2)主要针对 AI 去缓存
缓存击穿问题解决
思考:如果同一时刻有大量的用户答题,比如 1w 个用户,且答题选择都是一致的,但没有命中缓存(刚好过期),这时候会有 1w 个请求并发访问 AI。
这其实就是缓存击穿问题,即大量请求并发访问热点数据,刚好热点数据过期,会直接绕过缓存,命中数据库或 AI 接口。
在 AI 场景因接口限流,AI 应该不会崩溃,但是 token(钱)浪费了,而且搞不好平台会以为你的服务器是攻击者,把你的 IP 封禁。
在数据库场景,所有请求打到数据库上,数据库可能直接宕机。
因此,我们需要避免缓存击穿,一种常见的解决方式就是加锁。如果服务部署在多个机器上,就必须要使用分布式锁。
分布式锁不建议自己实现,理解原理即可。可以直接使用 Redisson 客户端,它为 Redis 提供了多种数据结构的支持,并提供了线程安全的操作,简化了在 Java 中使用 Redis 的复杂度。
Redisson 对 Redis 的一些功能进行了增强,如分布式锁、计数器、队列等,使得 Redis 的使用更加方便。
后端
1、引入所需依赖
包括本地缓存 + Redisson 分布式锁:
<dependency> <groupId>org.redisson</groupId> <artifactId>redisson</artifactId> <version>3.21.0</version> </dependency> <dependency> <groupId>com.github.ben-manes.caffeine</groupId> <artifactId>caffeine</artifactId> <version>2.9.2</version> </dependency>caffeine 必须引入 2.x 版本,因为 3.x 要求 Java >= 11。
2、本地缓存实现
在 AiTestScoringStrategy 中创建本地缓存,此处为了测试方便,缓存时间可以设置小一点。
private final Cache<String, String> answerCacheMap = Caffeine.newBuilder().initialCapacity(1024) // 缓存5分钟移除 .expireAfterAccess(5L, TimeUnit.MINUTES) .build();构建缓存 key 的方法:
private String buildCacheKey(Long appId, String choicesStr) { return DigestUtil.md5Hex(appId + ":" + choicesStr); }在评分功能的开头补充逻辑,有缓存则直接返回:
String answerJson = answerCacheMap.getIfPresent(key); // 命中缓存则直接返回结果 if (StrUtil.isNotBlank(answerJson)) { UserAnswer userAnswer = JSONUtil.toBean(answerJson, UserAnswer.class); userAnswer.setAppId(appId); userAnswer.setAppType(app.getAppType()); userAnswer.setScoringStrategy(app.getScoringStrategy()); userAnswer.setChoices(choicesStr); return userAnswer; }如果没缓存,调用 AI 后,需要设置缓存:
// 4. 构造返回值,填充答案对象的属性 UserAnswer userAnswer = JSONUtil.toBean(answerJson, UserAnswer.class); userAnswer.setAppId(appId); userAnswer.setAppType(app.getAppType()); userAnswer.setScoringStrategy(app.getScoringStrategy()); userAnswer.setChoices(choicesStr); // 5. 缓存 AI 结果 answerCacheMap.put(key, answerJson);3、Redisson 分布式锁
配置 Redisson 客户端,读取项目中的 redis 配置,注入为 Bean:
@Configuration @ConfigurationProperties(prefix = "spring.redis") @Data public class RedissonConfig { private String host; private Integer port; private Integer database; private String password; @Bean public RedissonClient redissonClient() { Config config = new Config(); config.useSingleServer() .setAddress("redis://" + host + ":" + port) .setDatabase(database) .setPassword(password); return Redisson.create(config); } }配置文件补充 Redis 配置:
# Redis 配置 spring: redis: database: 0 host: xxxx port: xxx timeout: 2000 password: xxx尝试启动项目,如果用的是编程导航的后端模板,记得取消启动类对 Redis 的移除。
在 AI 评分逻辑中补充分布式锁,先创建一把锁,需要给分布式锁设置一个业务前缀,防止和其他系统冲突。
private static final String AI_ANSWER_LOCK = "AI_ANSWER_LOCK"; RLock lock = redissonClient.getLock(AI_ANSWER_LOCK + key);调用获取锁方法:
try { // 竞争分布式锁,等待 3 秒,15 秒自动释放 boolean res = lock.tryLock(, 15, TimeUnit.SECONDS); if (res){ // 抢到锁的业务才能执行 AI 调用 } } finally { if (lock != null && lock.isLocked()) { if(lock.isHeldByCurrentThread()) { lock.unlock(); } } }这个方法是用于尝试获取锁,在给定的等待时间内,如果锁可用,就获取锁并返回 true;如果在等待时间内无法获取到锁,则返回 false。各参数含义:
- waitTime:等待获取锁的时间,即最长等待时间。
- leaseTime:获取到锁后的租期时间,即锁的持有时间。
- unit:时间单位,用于指定 waitTime 和 leaseTime 的时间单位。
注意,一定要加 try ... finally 块,保证锁被加锁的线程及时释放,否则会影响业务。
四、分库分表实战
需求分析
如果我们的平台发展迅速,用户量激增,从数据库层面去思考,哪个表的数据会最大呢?
回顾一下我们的数据库设计:
1)app 应用表
显然不会,成百上千的应用已经多,但对数据库而已,这还是小量级
2)question 题目表
不太可能,一个应用一般最多也就几十个题目
3)scoring_result 评分结果表
不太可能,一个应用对应不会有多少结果,比如 MBTI 也就 16 个。
4)user 表
有可能,如果用户达到几千万级,那么确实挺多了
5)user_answer 用户答题记录表
一个用户可以对同个应用多次答题,也可以在多个应用多次答题,理论上如果用户量足够大,那么这个表肯定是最先遇到瓶颈的。
除了清理数据外,常见的一种优化方案是分库分表。
分库分表概念
这里我们先简单了解下分库分表的场景。
随着用户量的激增和时间的堆砌,存在数据库里面的数据越来越多,此时的数据库就会产生瓶颈,出现资源报警、查询慢等场景。
首先单机数据库所能承载的连接数、I/O 及网络的吞吐等都是有限的,所以当并发量上来了之后,数据库就渐渐顶不住了。
而且如果单表的数据量过大,查询的性能也会下降。因为数据越多底层存储的 B+ 树就越高,树越高则查询 I/O 的次数就越多,那么性能也就越差。
分库和分表怎么区分呢?
把以前存在 一个数据库 实例里的数据拆分成多个数据库实例,部署在不同的服务器中,这是分库。
把以前存在 一张表 里面的数据拆分成多张表,这是分表。
一般而言:
- 分表:是为了解决由于单张表数据量多大,而导致查询慢的问题。大致三、四千万行数据就得拆分,不过具体还是得看每一行的数据量大小,有些字段都很小的可能支持更多行数,有些字段大的可能一千万就顶不住了。
- 分库:是为了解决服务器资源受单机限制,顶不住高并发访问的问题,把请求分配到多台服务器上,降低服务器压力。
比如电商网站的使用人数不断增加, 用户数不断增加,订单数也日益增长,此时就应该把用户库和订单库拆开来,这样就能降低数据库的压力,且对业务而言数据分的也更清晰,并且理论上订单数会远大于用户数,还可以针对订单库单一升配。
由于电商网站品类不断增加,在促销活动的作用下订单取得爆炸式增长,如果所有订单仅存储在一张表中,这张表得有多大?
因此此时就需要根据订单表进行分表,可以按时间维度,比如 order_202401、order_202402 来拆分,如果每天的订单量很大,则可以通过 order_20240101、order_20240102 这样拆分。
技术选型
常见的分库分表开源组件有:ShardingSphere、MyCat、Cobar 等。
Sharding-JDBC 原理
Sharding-JDBC 核心原理其实很简单,可以用几个字总结:改写 SQL
比如我们想根据 appId 来将对应的用户答题记录表进行分表。
将 appId % 2 等于 0 的应用的所有用户的答题记录都划分到 user_answer_0,等于 1 的应用的所有用户的答题记录都划分到 user_answer_1。
按照我们正常的想法处理逻辑就是:
if(appId % 2 == 0){ userAnswer0Service.save(userAnswer); } else { userAnswer1Service.save(userAnswer); }而用了 Sharding-JDBC 后,我们只要写好配置,Sharding-JDBC 就会根据配置,执行我们上面的逻辑,在业务代码上我们就可以透明化分库分表的存在,减少了很多重复逻辑!
它会解析 SQL ,根据我们指定的 分片键,按照我们设置的逻辑来计算得到对应的路由分片(数据库或者表),最终改写 SQL 后进行 SQL 的执行。
方案设计
分库分表的核心是确定按照什么维度(或者字段)进行拆分,一般会选择唯一的、业务合理的、能够均匀分配的字段。
个人建议:你在哪个字段加索引,就用哪个字段分表,核心在于用户的查询,一定要根据业务的实际情况来。尽量避免出现跨表和跨库查询。
对于本项目,user_answer 有个天然的拆分字段即 appId,不同应用的用户答题记录没有关联,因此我们可以根据 appId 拆解 user_answer 表。
实现流程比较简单:
- 新建 user_answer_0 和 user_answer_1,作为 user_answer 表的分表
- 引入 Sharding-JDBC
- 配置文件中设置分表逻辑
后端开发
1)新建表,直接复制 user_answer 的 DDL 表结构,改个名称即可。

2)maven 引入 Sharding-JDBC 依赖:
<dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId> <version>5.2.0</version> </dependency>仅需在 application.yml 配置一下参数:
spring: shardingsphere: #数据源配置 datasource: # 多数据源以逗号隔开即可 names: yudada yudada: type: com.zaxxer.hikari.HikariDataSource driver-class-name: com.mysql.cj.jdbc.Driver jdbc-url: jdbc:mysql://localhost:3306/yudada username: root password: 123456 # 规则配置 rules: sharding: # 分片算法配置 sharding-algorithms: # 自定义分片规则名 answer-table-inline: ## inline 类型是简单的配置文件里面就能写的类型,其他还有自定义类等等 type: INLINE props: algorithm-expression: user_answer_$->{appId % 2} tables: user_answer: actual-data-nodes: yudada.user_answer_$->{0..1} # 分表策略 table-strategy: standard: sharding-column: appId sharding-algorithm-name: answer-table-inline配置解析:
1)需要将数据源挪至 shardingsphere 下
2)定于数据源的名字和 url 等配置
3)自定义分片规则,即 answer-table-inline,分片算法为 user_answer_$->{appId % 2} ,这个含义就是根据 appId % 2 的结果拼接表名,改写 SQL
4)设置对应的表使用分片规则,即 tables:user_answer:table-strategy,指定分片键为 appId,分片的规则是 answer-table-inline
验证测试
新建表和配置后,直接使用单元测试即可测试结果:
@SpringBootTest public class UserAnswerShardingTest { @Resource private UserAnswerService userAnswerService; @Test void test() { UserAnswer userAnswer1 = new UserAnswer(); userAnswer1.setAppId(1L); userAnswer1.setUserId(1L); userAnswer1.setChoices("1"); userAnswerService.save(userAnswer1); UserAnswer userAnswer2 = new UserAnswer(); userAnswer2.setAppId(2L); userAnswer2.setUserId(1L); userAnswer2.setChoices("2"); userAnswerService.save(userAnswer2); UserAnswer userAnswerOne = userAnswerService.getOne(Wrappers.lambdaQuery(UserAnswer.class).eq(UserAnswer::getAppId, 1L)); System.out.println(JSONUtil.toJsonStr(userAnswerOne)); UserAnswer userAnswerTwo = userAnswerService.getOne(Wrappers.lambdaQuery(UserAnswer.class).eq(UserAnswer::getAppId, 2L)); System.out.println(JSONUtil.toJsonStr(userAnswerTwo)); } } 观察数据库中两张表的数据:
注意,分表后,一定不能更新分表字段!
如果有报错,可以把 appId 的更新设置为空来解决:
try { UserAnswer userAnswerWithResult = scoringStrategyExecutor.doScore(choices, app); userAnswerWithResult.setId(newUserAnswerId); userAnswerWithResult.setAppId(null); userAnswerService.updateById(userAnswerWithResult); } catch (Exception e) { e.printStackTrace(); throw new BusinessException(ErrorCode.OPERATION_ERROR, "评分错误"); } 