
阅读量:0
一、开发背景
DenseNet(稠密连接网络)是由Cornell大学的Gao Huang等人于2017年提出的深度学习网络架构。它的设计灵感来自于ResNet(残差网络)以及其前身 Highway Networks 的思想。
论文链接:https://arxiv.org/pdf/1608.06993.pdf
代码的github链接:https://github.com/liuzhuang13/DenseNet
这是作者发表的一篇CVPR顶会上的一篇论文,代码的地址,大家可以自行下载。
在深度卷积神经网络中,通常存在梯度消失或梯度爆炸等问题,尤其是随着网络层数的增加,这种问题变得尤为严重,上篇讲到的残差网络引入了残差连接(跨层连接)来解决了这些问题,从而允许网络更深地训练,但是,ResNet中的跨层连接是通过相加的方式实现的,这意味着每一层只能直接访问前一层的输出。
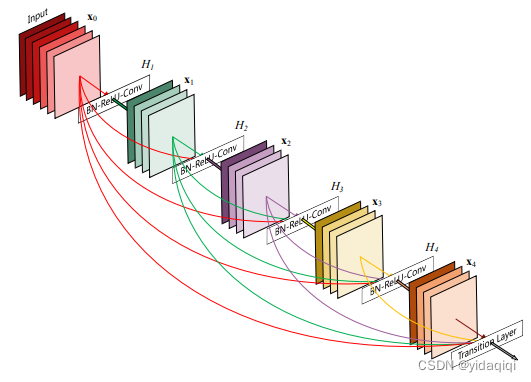
DenseNet(密集卷积网络)的核心思想(创新之处)是密集连接,使得每一层都与所有之前的层直接连接,即某层的输入除了包含前一层的输出外还包含前面所有层的输出。
这样的话,有很多的优点:
(1)梯度复用:每一层都可以直接访问之前所有层的特征图,从而促进了特征的重用,有助于提取更丰富和更具有表征能力的特征,这句话更文学点的说法是可以理解成多尺度融合。
(2)梯度传播:密集连接使得梯度可以更轻松地传播到较早的层,有助于缓解梯度消失和梯度爆炸问题,从而使得更深的网络可以训练,和残差网络一样都具备这个优点。
(3)参数效率:参数量要少一些和残差网络大差不差。
二、模型讨论
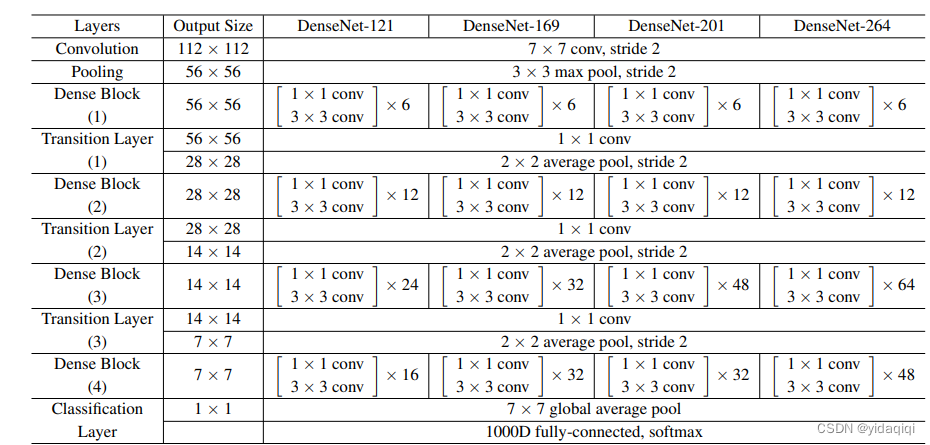
整个网络主要是包含了三个核心结构,分别是DenseLayer(模型中最基础的原子单元,利用卷积完成一次最基础的特征提取)、DenseBlock(整个模型密集连接的基础单元,整个网络最核心的部分)和Transition(通常用于两个相邻的Dense块之间,主要的两个作用是减小特征图的大小和特征图的数量),通过上述的三个核心的结构的拼接加上其他层来完成整个模型的搭建。

DenseLayer层包含BN + Relu + 1*1Conv + BN + Relu + 3*3Conv。第L个DenseLayer层的第一个1*1Conv的输入通道层数为num_input_features+(L-1)*growth_rate,输出通道层数为bn_size*growth_rate;第二个3*3Conv的输入通道数为bn_size*growth_rate,输出通道数为growth_rate。整个DenseLayer层内特征层宽度不变,不存在stride=2或者池化的情况。这里有一点特殊之处,DenseLayer层的第一个结构是BN层而不是像其它模型那样是Conv。在BN层前面还存在一个Concatenation操作,负责本DenseBlock模块内前面所有层的输出以及第一层的输出进行拼接操作。
DenseBlock模块其实就是堆叠一定数量的DenseLayer层,在整个DenseBlock模块内不同DenseLayer层之间会发生密集连接,在DenseBlock模块内特征层宽度不变,不存在stride=2或者池化的情况。在一个block内部(即特征图大小都相同),将所有的层都进行连接,即第一层的特征会直接传输给后面的所有的层,后面的层会接受前面所有层的输出特征,一个块中有多个卷积层,每个卷积层的输入来自前面所有层的输出。
Transition模块包含BN + Relu + 1*1Conv + 2*2AvgPool,1*1Conv负责降低通道数,2*2AvgPool负责降低特征层宽度,降低到1/2。Transition模块的作用是连接不同的DenseBlock模块,之所以这样设计原因是,密接连接必须保证特征层的宽度是一致的,原因是连接方式为沿通道维拼接,如果整个模型都采用密集连接,那势必导致整个模型从输入到输出特征层宽度都不变,那最后无法完成分类任务,也无法压缩特征。
Dense连接只会在每个Dense block内部进行,不会进行跨block的Dense连接。
整体的这个流程可以看一下下边的model.py这个文件,感觉前边有一些内容也不是梳理的很清楚,后期有时间在进行修改。
三、代码+注释
一、划分数据集
import os from shutil import copy, rmtree import random def mk_file(file_path: str): if os.path.exists(file_path): # 如果文件夹存在,则先删除原文件夹再重新创建 rmtree(file_path) os.makedirs(file_path) def main(): # 保证随机可复现 random.seed(0) # 将数据集中10%的数据划分到验证集中 split_rate = 0.1 # 指向解压后的flower_photos文件夹 # getcwd():该函数不需要传递参数,获得当前所运行脚本的路径 cwd = os.getcwd() # join():用于拼接文件路径,可以传入多个路径 data_root = os.path.join(cwd, "flower_data") origin_flower_path = os.path.join(data_root, "flower_photos") # 确定路径存在,否则反馈错误 assert os.path.exists(origin_flower_path), "path '{}' does not exist.".format(origin_flower_path) # isdir():判断某一路径是否为目录 # listdir():返回指定的文件夹包含的文件或文件夹的名字的列表 flower_class = [cla for cla in os.listdir(origin_flower_path) if os.path.isdir(os.path.join(origin_flower_path, cla))] # 创建训练集train文件夹,并由类名在其目录下创建子目录 train_root = os.path.join(data_root, "train") mk_file(train_root) for cla in flower_class: # 建立每个类别对应的文件夹 mk_file(os.path.join(train_root, cla)) # 创建验证集val文件夹,并由类名在其目录下创建子目录 val_root = os.path.join(data_root, "val") mk_file(val_root) for cla in flower_class: # 建立每个类别对应的文件夹 mk_file(os.path.join(val_root, cla)) # 遍历所有类别的图像并按比例分成训练集和验证集 for cla in flower_class: cla_path = os.path.join(origin_flower_path, cla) # iamges列表存储了该目录下所有图像的名称 images = os.listdir(cla_path) num = len(images) # 随机采样验证集的索引 # 从images列表中随机抽取k个图像名称 # random.sample:用于截取列表的指定长度的随机数,返回列表 # eval_index保存验证集val的图像名称 eval_index = random.sample(images, k=int(num * split_rate)) for index, image in enumerate(images): if image in eval_index: # 将分配至验证集中的文件复制到相应目录 image_path = os.path.join(cla_path, image) new_path = os.path.join(val_root, cla) copy(image_path, new_path) else: # 将分配至训练集中的文件复制到相应目录 image_path = os.path.join(cla_path, image) new_path = os.path.join(train_root, cla) copy(image_path, new_path) # '\r'回车,回到当前行的行首,而不会换到下一行,如果接着输出,本行以前的内容会被逐一覆盖 # end="":将print自带的换行用end中指定的str代替 print("\r[{}] processing [{}/{}]".format(cla, index + 1, num), end="") print() print("processing done!") if __name__ == '__main__': main()二、模型文件
import torch import torch.nn as nn import torch.nn.functional as F from collections import OrderedDict class _DenseLayer(nn.Sequential): def __init__(self, num_input_features, growth_rate, bn_size, drop_rate):# 第一个参数是输入的通道数,第二个是增长率是一个重要的超参数,它控制了每个密集块中特征图的维度增加量, # 第四个参数是Dropout正则化上边的概率 super(_DenseLayer, self).__init__()# 调用父类的构造方法,这句话的意思是在调用nn.Sequential的构造方法 self.add_module('norm1', nn.BatchNorm2d(num_input_features)), # 批量归一化 self.add_module('relu1', nn.ReLU(inplace=True)), # ReLU层 self.add_module('conv1', nn.Conv2d(num_input_features, bn_size * growth_rate, kernel_size=1, stride=1, bias=False)), # 表示其输出为4*k 其中bn_size等于4,growth_rate为k 不改变大小,只改变通道的个数 self.add_module('norm2', nn.BatchNorm2d(bn_size * growth_rate)), # 批量归一化 self.add_module('relu2', nn.ReLU(inplace=True)), # 激活函数 self.add_module('conv2', nn.Conv2d(bn_size * growth_rate, growth_rate, kernel_size=3, stride=1, padding=1, bias=False)), # 输出为growth_rate:表示输出通道数为k 提取特征 self.drop_rate = drop_rate def forward(self, x): new_features = super(_DenseLayer, self).forward(x) if self.drop_rate > 0: new_features = F.dropout(new_features, p=self.drop_rate, training=self.training) return torch.cat([x, new_features], 1) # 通道维度连接 class _DenseBlock(nn.Sequential): # 构建稠密块 def __init__(self, num_layers, num_input_features, bn_size, growth_rate, drop_rate): # 密集块中密集层的数量,第二参数是输入通道数量 super(_DenseBlock, self).__init__() for i in range(num_layers): layer = _DenseLayer(num_input_features + i * growth_rate, growth_rate, bn_size, drop_rate) self.add_module('denselayer%d' % (i + 1), layer) class _Transition(nn.Sequential): def __init__(self, num_input_features, num_output_features):# 输入通道数 输出通道数 super(_Transition, self).__init__() self.add_module('norm', nn.BatchNorm2d(num_input_features)) self.add_module('relu', nn.ReLU(inplace=True)) self.add_module('conv', nn.Conv2d(num_input_features, num_output_features, kernel_size=1, stride=1, bias=False)) self.add_module('pool', nn.AvgPool2d(kernel_size=2, stride=2)) # DenseNet网络模型基本结构 class DenseNet(nn.Module): def __init__(self, growth_rate=32, block_config=(6, 12, 24, 16), num_init_features=64, bn_size=4, drop_rate=0, num_classes=4): super(DenseNet, self).__init__() # First convolution self.features = nn.Sequential(OrderedDict([ ('conv0', nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False)), ('norm0', nn.BatchNorm2d(num_init_features)), ('relu0', nn.ReLU(inplace=True)), ('pool0', nn.MaxPool2d(kernel_size=3, stride=2, padding=1)), ])) # Each denseblock num_features = num_init_features for i, num_layers in enumerate(block_config): block = _DenseBlock(num_layers=num_layers, num_input_features=num_features, bn_size=bn_size, growth_rate=growth_rate, drop_rate=drop_rate) self.features.add_module('denseblock%d' % (i + 1), block) num_features = num_features + num_layers * growth_rate if i != len(block_config) - 1: trans = _Transition(num_input_features=num_features, num_output_features=num_features // 2) self.features.add_module('transition%d' % (i + 1), trans) num_features = num_features // 2 # Final batch norm self.features.add_module('norm5', nn.BatchNorm2d(num_features)) # Linear layer self.classifier = nn.Linear(num_features, num_classes) # Official init from torch repo. for m in self.modules(): if isinstance(m, nn.Conv2d): nn.init.kaiming_normal(m.weight.data) elif isinstance(m, nn.BatchNorm2d): m.weight.data.fill_(1) m.bias.data.zero_() elif isinstance(m, nn.Linear): m.bias.data.zero_() def forward(self, x): features = self.features(x) out = F.relu(features, inplace=True) out = F.avg_pool2d(out, kernel_size=7, stride=1).view(features.size(0), -1) out = self.classifier(out) return out def densenet121(**kwargs): model = DenseNet(num_init_features=64, growth_rate=32, block_config=(6, 12, 24, 16), **kwargs) return model def densenet169(**kwargs): model = DenseNet(num_init_features=64, growth_rate=32, block_config=(6, 12, 32, 32), **kwargs) return model def densenet201(**kwargs): model = DenseNet(num_init_features=64, growth_rate=32, block_config=(6, 12, 48, 32), **kwargs) return model def densenet161(**kwargs): model = DenseNet(num_init_features=96, growth_rate=48, block_config=(6, 12, 36, 24), **kwargs) return model if __name__ == '__main__': # 'DenseNet', 'densenet121', 'densenet169', 'densenet201', 'densenet161' # Example net = DenseNet() print(net) 三、训练文件
import os import sys import json import torch import torch.nn as nn import torch.optim as optim from torchvision import transforms, datasets from tqdm import tqdm # 训练resnet34 from model import densenet121 def main(): # 如果有NVIDA显卡,转到GPU训练,否则用CPU device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") print("using {} device.".format(device)) data_transform = { # 训练 # Compose():将多个transforms的操作整合在一起 "train": transforms.Compose([ # RandomResizedCrop(224):将给定图像随机裁剪为不同的大小和宽高比,然后缩放所裁剪得到的图像为给定大小 transforms.RandomResizedCrop(224), # RandomVerticalFlip():以0.5的概率竖直翻转给定的PIL图像 transforms.RandomHorizontalFlip(), # ToTensor():数据转化为Tensor格式 transforms.ToTensor(), # Normalize():将图像的像素值归一化到[-1,1]之间,使模型更容易收敛 transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]), # 验证 "val": transforms.Compose([transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])} # abspath():获取文件当前目录的绝对路径 # join():用于拼接文件路径,可以传入多个路径 # getcwd():该函数不需要传递参数,获得当前所运行脚本的路径 data_root = os.path.abspath(os.getcwd()) # 得到数据集的路径 image_path = os.path.join(data_root, "data") # exists():判断括号里的文件是否存在,可以是文件路径 # 如果image_path不存在,序会抛出AssertionError错误,报错为参数内容“ ” assert os.path.exists(image_path), "{} path does not exist.".format(image_path) train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"), transform=data_transform["train"]) # 训练集长度 train_num = len(train_dataset) # {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4} # class_to_idx:获取分类名称对应索引 flower_list = train_dataset.class_to_idx # dict():创建一个新的字典 # 循环遍历数组索引并交换val和key的值重新赋值给数组,这样模型预测的直接就是value类别值 cla_dict = dict((val, key) for key, val in flower_list.items()) # 把字典编码成json格式 json_str = json.dumps(cla_dict, indent=4) # 把字典类别索引写入json文件 with open('class_indices.json', 'w') as json_file: json_file.write(json_str) # 一次训练载入16张图像 batch_size = 16 # 确定进程数 # min():返回给定参数的最小值,参数可以为序列 # cpu_count():返回一个整数值,表示系统中的CPU数量,如果不确定CPU的数量,则不返回任何内容 nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) print('Using {} dataloader workers every process'.format(nw)) # DataLoader:将读取的数据按照batch size大小封装给训练集 # dataset (Dataset):输入的数据集 # batch_size (int, optional):每个batch加载多少个样本,默认: 1 # shuffle (bool, optional):设置为True时会在每个epoch重新打乱数据,默认: False # num_workers(int, optional): 决定了有几个进程来处理,默认为0意味着所有的数据都会被load进主进程 train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=nw) # 加载测试数据集 validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"), transform=data_transform["val"]) # 测试集长度 val_num = len(validate_dataset) validate_loader = torch.utils.data.DataLoader(validate_dataset, batch_size=batch_size, shuffle=False, num_workers=nw) print("using {} images for training, {} images for validation.".format(train_num, val_num)) # 模型实例化 net = densenet121() net.to(device) # 加载预训练模型权重 # model_weight_path = "./resnet34-pre.pth" # exists():判断括号里的文件是否存在,可以是文件路径 # assert os.path.exists(model_weight_path), "file {} does not exist.".format(model_weight_path) # net.load_state_dict(torch.load(model_weight_path, map_location='cpu')) # 输入通道数 # in_channel = net.fc.in_features # 全连接层 # net.fc = nn.Linear(in_channel, 5) # 定义损失函数(交叉熵损失) loss_function = nn.CrossEntropyLoss() # 抽取模型参数 params = [p for p in net.parameters() if p.requires_grad] # 定义adam优化器 # params(iterable):要训练的参数,一般传入的是model.parameters() # lr(float):learning_rate学习率,也就是步长,默认:1e-3 optimizer = optim.Adam(params, lr=0.0001) # 迭代次数(训练次数) epochs = 30 # 用于判断最佳模型 best_acc = 0.0 # 最佳模型保存地址 save_path = './DenseNet34.pth' train_steps = len(train_loader) for epoch in range(epochs): # 训练 net.train() running_loss = 0.0 # tqdm:进度条显示 train_bar = tqdm(train_loader, file=sys.stdout) # train_bar: 传入数据(数据包括:训练数据和标签) # enumerate():将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在for循环当中 # enumerate返回值有两个:一个是序号,一个是数据(包含训练数据和标签) # x:训练数据(inputs)(tensor类型的),y:标签(labels)(tensor类型) for step, data in enumerate(train_bar): # 前向传播 images, labels = data # 计算训练值 logits = net(images.to(device)) # 计算损失 loss = loss_function(logits, labels.to(device)) # 反向传播 # 清空过往梯度 optimizer.zero_grad() # 反向传播,计算当前梯度 loss.backward() optimizer.step() # item():得到元素张量的元素值 running_loss += loss.item() # 进度条的前缀 # .3f:表示浮点数的精度为3(小数位保留3位) train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1, epochs, loss) # 测试 # eval():如果模型中有Batch Normalization和Dropout,则不启用,以防改变权值 net.eval() acc = 0.0 # 清空历史梯度,与训练最大的区别是测试过程中取消了反向传播 with torch.no_grad(): val_bar = tqdm(validate_loader, file=sys.stdout) for val_data in val_bar: val_images, val_labels = val_data outputs = net(val_images.to(device)) # torch.max(input, dim)函数 # input是具体的tensor,dim是max函数索引的维度,0是每列的最大值,1是每行的最大值输出 # 函数会返回两个tensor,第一个tensor是每行的最大值;第二个tensor是每行最大值的索引 predict_y = torch.max(outputs, dim=1)[1] # 对两个张量Tensor进行逐元素的比较,若相同位置的两个元素相同,则返回True;若不同,返回False # .sum()对输入的tensor数据的某一维度求和 acc += torch.eq(predict_y, val_labels.to(device)).sum().item() val_bar.desc = "valid epoch[{}/{}]".format(epoch + 1, epochs) val_accurate = acc / val_num print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' % (epoch + 1, running_loss / train_steps, val_accurate)) # 保存最好的模型权重 if val_accurate > best_acc: best_acc = val_accurate # torch.save(state, dir)保存模型等相关参数,dir表示保存文件的路径+保存文件名 # model.state_dict():返回的是一个OrderedDict,存储了网络结构的名字和对应的参数 torch.save(net.state_dict(), save_path) print('Finished Training') if __name__ == '__main__': main()以上就是代码文件了,数据集的格式如下图所示
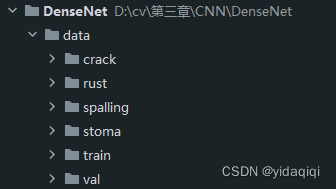
其中,crack、rust、spalling、stoma、这四个文件夹名是类别,这种还不需要标注了,到了目标检测的环节才需要标注,本次的博客也算是写完了,以后会不定期更新遇到的问题的。
四、参考文献
DenseNet网络结构的讲解与代码实现_transition层-CSDN博客
densenet的网络结构和实现代码总结(torch)_densenet结构-CSDN博客
链接:https://blog.csdn.net/BIT_Legend/article/details/124238533
