
阅读量:0
电脑环境:
语言环境:Python 3.8.0
编译器:Jupyter Notebook
深度学习环境:tensorflow 2.15.0
一、前期工作
1.设置GPU(如果使用的是CPU可以忽略这步)
import tensorflow as tf gpus = tf.config.list_physical_devices("GPU") if gpus: tf.config.experimental.set_memory_growth(gpus[0], True) #设置GPU显存用量按需使用 tf.config.set_visible_devices([gpus[0]],"GPU") 2. 导入数据
from tensorflow import keras from tensorflow.keras import layers,models import numpy as np import matplotlib.pyplot as plt import os,PIL,pathlib data_dir = "./49-data/" data_dir = pathlib.Path(data_dir) image_count = len(list(data_dir.glob('*/*.png'))) print("图片总数为:",image_count) 输出:图片总数为: 1200
二、数据预处理
1、加载数据
使用image_dataset_from_directory方法将磁盘中的数据加载到tf.data.Dataset中。
batch_size = 32 img_height = 224 img_width = 224 train_ds = tf.keras.preprocessing.image_dataset_from_directory( data_dir, validation_split=0.2, subset="training", seed=123, image_size=(img_height, img_width), batch_size=batch_size) val_ds = tf.keras.preprocessing.image_dataset_from_directory( data_dir, validation_split=0.2, subset="validation", seed=123, image_size=(img_height, img_width), batch_size=batch_size) 我们可以通过class_names输出数据集的标签。标签将按字母顺序对应于目录名称。
class_names = train_ds.class_names print(class_names) 输出:
[‘Dark’, ‘Green’, ‘Light’, ‘Medium’]
2、数据可视化
plt.figure(figsize=(10, 4)) # 图形的宽为10高为5 for images, labels in train_ds.take(1): for i in range(10): ax = plt.subplot(2, 5, i + 1) plt.imshow(images[i].numpy().astype("uint8")) plt.title(class_names[labels[i]]) plt.axis("off") 
for image_batch, labels_batch in train_ds: print(image_batch.shape) print(labels_batch.shape) break 输出:
(32, 224, 224, 3)
(32,)
3、配置数据集
AUTOTUNE = tf.data.AUTOTUNE train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE) val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE) normalization_layer = layers.experimental.preprocessing.Rescaling(1./255) train_ds = train_ds.map(lambda x, y: (normalization_layer(x), y)) val_ds = val_ds.map(lambda x, y: (normalization_layer(x), y)) image_batch, labels_batch = next(iter(val_ds)) first_image = image_batch[0] # 查看归一化后的数据 print(np.min(first_image), np.max(first_image)) 输出:
0.0 1.0
三、构建CNN网络
调用官方的VGG-16网络框架:
from keras.applications import VGG16 VGG16 = VGG16(weights='imagenet') VGG16.summary() 网络结构:
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) [(None, 224, 224, 3)] 0 block1_conv1 (Conv2D) (None, 224, 224, 64) 1792 block1_conv2 (Conv2D) (None, 224, 224, 64) 36928 block1_pool (MaxPooling2D) (None, 112, 112, 64) 0 block2_conv1 (Conv2D) (None, 112, 112, 128) 73856 block2_conv2 (Conv2D) (None, 112, 112, 128) 147584 block2_pool (MaxPooling2D) (None, 56, 56, 128) 0 block3_conv1 (Conv2D) (None, 56, 56, 256) 295168 block3_conv2 (Conv2D) (None, 56, 56, 256) 590080 block3_conv3 (Conv2D) (None, 56, 56, 256) 590080 block3_pool (MaxPooling2D) (None, 28, 28, 256) 0 block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160 block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808 block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808 block4_pool (MaxPooling2D) (None, 14, 14, 512) 0 block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808 block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808 block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808 block5_pool (MaxPooling2D) (None, 7, 7, 512) 0 flatten (Flatten) (None, 25088) 0 fc1 (Dense) (None, 4096) 102764544 fc2 (Dense) (None, 4096) 16781312 predictions (Dense) (None, 1000) 4097000 ================================================================= Total params: 138357544 (527.79 MB) Trainable params: 138357544 (527.79 MB) Non-trainable params: 0 (0.00 Byte) _________________________________________________________________ 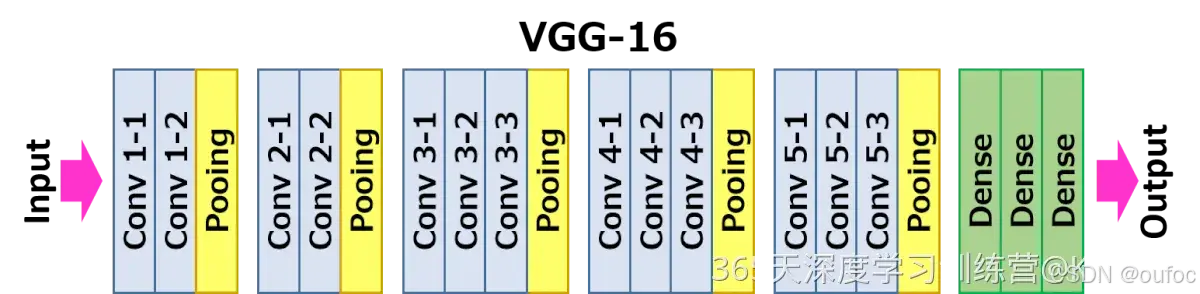
四、编译
# 设置初始学习率 initial_learning_rate = 1e-4 lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay( initial_learning_rate, decay_steps=30, # 敲黑板!!!这里是指 steps,不是指epochs decay_rate=0.92, # lr经过一次衰减就会变成 decay_rate*lr staircase=True) # 设置优化器 opt = tf.keras.optimizers.Adam(learning_rate=initial_learning_rate) model.compile(optimizer=opt, loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy']) 五、训练模型
epochs = 20 history = model.fit( train_ds, validation_data=val_ds, epochs=epochs ) 输出:
30/30 ━━━━━━━━━━━━━━━━━━━━ 250s 2s/step - accuracy: 0.2618 - loss: 2.4494 - val_accuracy: 0.5917 - val_loss: 0.9642 Epoch 2/20 30/30 ━━━━━━━━━━━━━━━━━━━━ 33s 574ms/step - accuracy: 0.5156 - loss: 0.9331 - val_accuracy: 0.7167 - val_loss: 0.5675 Epoch 3/20 30/30 ━━━━━━━━━━━━━━━━━━━━ 20s 567ms/step - accuracy: 0.7658 - loss: 0.4992 - val_accuracy: 0.8542 - val_loss: 0.3884 Epoch 4/20 30/30 ━━━━━━━━━━━━━━━━━━━━ 20s 557ms/step - accuracy: 0.8599 - loss: 0.3491 - val_accuracy: 0.9458 - val_loss: 0.2667 Epoch 5/20 30/30 ━━━━━━━━━━━━━━━━━━━━ 20s 556ms/step - accuracy: 0.9275 - loss: 0.2271 - val_accuracy: 0.9708 - val_loss: 0.1413 Epoch 6/20 30/30 ━━━━━━━━━━━━━━━━━━━━ 21s 563ms/step - accuracy: 0.9844 - loss: 0.0544 - val_accuracy: 0.9750 - val_loss: 0.0923 Epoch 7/20 30/30 ━━━━━━━━━━━━━━━━━━━━ 21s 571ms/step - accuracy: 0.9813 - loss: 0.0494 - val_accuracy: 0.9833 - val_loss: 0.0411 Epoch 8/20 30/30 ━━━━━━━━━━━━━━━━━━━━ 20s 560ms/step - accuracy: 0.9852 - loss: 0.0428 - val_accuracy: 0.9958 - val_loss: 0.0133 Epoch 9/20 30/30 ━━━━━━━━━━━━━━━━━━━━ 21s 568ms/step - accuracy: 0.9824 - loss: 0.0479 - val_accuracy: 0.9875 - val_loss: 0.0341 Epoch 10/20 30/30 ━━━━━━━━━━━━━━━━━━━━ 21s 569ms/step - accuracy: 0.9967 - loss: 0.0119 - val_accuracy: 0.9875 - val_loss: 0.0725 Epoch 11/20 30/30 ━━━━━━━━━━━━━━━━━━━━ 20s 571ms/step - accuracy: 0.9833 - loss: 0.0462 - val_accuracy: 0.9583 - val_loss: 0.1175 Epoch 12/20 30/30 ━━━━━━━━━━━━━━━━━━━━ 17s 562ms/step - accuracy: 0.9858 - loss: 0.0534 - val_accuracy: 0.9500 - val_loss: 0.1280 Epoch 13/20 30/30 ━━━━━━━━━━━━━━━━━━━━ 21s 567ms/step - accuracy: 0.9805 - loss: 0.0719 - val_accuracy: 0.9917 - val_loss: 0.0282 Epoch 14/20 30/30 ━━━━━━━━━━━━━━━━━━━━ 17s 561ms/step - accuracy: 0.9886 - loss: 0.0376 - val_accuracy: 0.9625 - val_loss: 0.1005 Epoch 15/20 30/30 ━━━━━━━━━━━━━━━━━━━━ 21s 567ms/step - accuracy: 0.9901 - loss: 0.0305 - val_accuracy: 0.9917 - val_loss: 0.0467 Epoch 16/20 30/30 ━━━━━━━━━━━━━━━━━━━━ 21s 569ms/step - accuracy: 1.0000 - loss: 0.0024 - val_accuracy: 0.9917 - val_loss: 0.0475 Epoch 17/20 30/30 ━━━━━━━━━━━━━━━━━━━━ 17s 571ms/step - accuracy: 0.9955 - loss: 0.0090 - val_accuracy: 0.9625 - val_loss: 0.1122 Epoch 18/20 30/30 ━━━━━━━━━━━━━━━━━━━━ 20s 559ms/step - accuracy: 0.9949 - loss: 0.0186 - val_accuracy: 0.9917 - val_loss: 0.0140 Epoch 19/20 30/30 ━━━━━━━━━━━━━━━━━━━━ 21s 568ms/step - accuracy: 0.9992 - loss: 0.0022 - val_accuracy: 0.9958 - val_loss: 0.0140 Epoch 20/20 30/30 ━━━━━━━━━━━━━━━━━━━━ 20s 569ms/step - accuracy: 1.0000 - loss: 4.4589e-04 - val_accuracy: 1.0000 - val_loss: 0.0025 六、可视化结果
acc = history.history['accuracy'] val_acc = history.history['val_accuracy'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs_range = range(epochs) plt.figure(figsize=(12, 4)) plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label='Training Accuracy') plt.plot(epochs_range, val_acc, label='Validation Accuracy') plt.legend(loc='lower right') plt.title('Training and Validation Accuracy') plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label='Training Loss') plt.plot(epochs_range, val_loss, label='Validation Loss') plt.legend(loc='upper right') plt.title('Training and Validation Loss') plt.show() 
七、轻量化模型
上边我们可以看到官方的VGG16模型的Total params: 138 357 544 (527.79 MB)。
1、冻结VGG16网络
现在尝试只加载下图的除去绿色的部分,并且冻结模型的卷基层的权重参数,让它们不参加训练,手动加上自定义的全连接层和Dropout层。
VGG16 = tf.keras.applications.VGG16(weights="imagenet", include_top=False, input_shape=(224, 224, 3)) VGG16.trainable = False # 创建输入层 inputs = tf.keras.Input(shape=(224, 224, 3)) # 使用 VGG16 作为卷积基 x = VGG16(inputs, training=False) # 添加自定义的全连接层 x = layers.Flatten()(x) x = layers.Dense(256, activation='relu')(x) x = layers.Dropout(0.4)(x) x = layers.Dense(128, activation='relu')(x) x = layers.Dropout(0.4)(x) outputs = layers.Dense(len(class_names))(x) # 创建完整的模型 model = tf.keras.Model(inputs, outputs) # 查看模型结构 model.summary() 输出:
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━┩ │ input_layer_11 (InputLayer) │ (None, 224, 224, 3) │ 0 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ vgg16 (Functional) │ (None, 7, 7, 512) │ 14,714,688 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ flatten_6 (Flatten) │ (None, 25088) │ 0 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ dense_12 (Dense) │ (None, 256) │ 6,422,784 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ dropout_6 (Dropout) │ (None, 256) │ 0 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ dense_13 (Dense) │ (None, 128) │ 32,896 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ dropout_7 (Dropout) │ (None, 128) │ 0 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ dense_14 (Dense) │ (None, 4) │ 516 │ └──────────────────────────────────────┴─────────────────────────────┴─────────────────┘ Total params: 21,170,884 (80.76 MB) Trainable params: 6,456,196 (24.63 MB) Non-trainable params: 14,714,688 (56.13 MB) 这里咱们可以看到Total params: 21,170,884 (80.76 MB),相比于原模型,降低了很多。使用这个模型重新训练。当然要重新编译一次,并且增加了epochs=30。
# 设置初始学习率 initial_learning_rate = 1e-4 lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay( initial_learning_rate, decay_steps=30, # 敲黑板!!!这里是指 steps,不是指epochs decay_rate=0.92, # lr经过一次衰减就会变成 decay_rate*lr staircase=True) # 设置优化器 opt = tf.keras.optimizers.Adam(learning_rate=initial_learning_rate) model.compile(optimizer=opt, loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy']) epochs = 30 history = model.fit( train_ds, validation_data=val_ds, epochs=epochs ) 输出:
Epoch 1/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 14s 317ms/step - accuracy: 0.2922 - loss: 1.5063 - val_accuracy: 0.7542 - val_loss: 0.9573 Epoch 2/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 14s 163ms/step - accuracy: 0.6025 - loss: 1.0074 - val_accuracy: 0.8042 - val_loss: 0.7020 Epoch 3/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 5s 179ms/step - accuracy: 0.7010 - loss: 0.7734 - val_accuracy: 0.8042 - val_loss: 0.5710 Epoch 4/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 5s 174ms/step - accuracy: 0.7596 - loss: 0.6712 - val_accuracy: 0.8417 - val_loss: 0.4787 Epoch 5/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 10s 166ms/step - accuracy: 0.8236 - loss: 0.5016 - val_accuracy: 0.8625 - val_loss: 0.4037 Epoch 6/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 5s 161ms/step - accuracy: 0.8319 - loss: 0.4423 - val_accuracy: 0.8875 - val_loss: 0.3518 Epoch 7/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 5s 162ms/step - accuracy: 0.8855 - loss: 0.3870 - val_accuracy: 0.9208 - val_loss: 0.3057 Epoch 8/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 5s 164ms/step - accuracy: 0.8768 - loss: 0.3587 - val_accuracy: 0.9042 - val_loss: 0.2942 Epoch 9/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 5s 162ms/step - accuracy: 0.9260 - loss: 0.2672 - val_accuracy: 0.9167 - val_loss: 0.2513 Epoch 10/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 5s 174ms/step - accuracy: 0.9284 - loss: 0.2532 - val_accuracy: 0.9083 - val_loss: 0.2328 Epoch 11/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 5s 172ms/step - accuracy: 0.9358 - loss: 0.2266 - val_accuracy: 0.9083 - val_loss: 0.2321 Epoch 12/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 10s 164ms/step - accuracy: 0.9291 - loss: 0.2178 - val_accuracy: 0.9167 - val_loss: 0.2157 Epoch 13/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 5s 160ms/step - accuracy: 0.9431 - loss: 0.1964 - val_accuracy: 0.9042 - val_loss: 0.2257 Epoch 14/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 5s 172ms/step - accuracy: 0.9477 - loss: 0.1889 - val_accuracy: 0.9208 - val_loss: 0.2035 Epoch 15/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 5s 165ms/step - accuracy: 0.9608 - loss: 0.1353 - val_accuracy: 0.9417 - val_loss: 0.1697 Epoch 16/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 5s 173ms/step - accuracy: 0.9588 - loss: 0.1484 - val_accuracy: 0.9458 - val_loss: 0.1746 Epoch 17/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 10s 160ms/step - accuracy: 0.9762 - loss: 0.1211 - val_accuracy: 0.9458 - val_loss: 0.1554 Epoch 18/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 5s 172ms/step - accuracy: 0.9661 - loss: 0.1170 - val_accuracy: 0.9250 - val_loss: 0.1851 Epoch 19/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 5s 166ms/step - accuracy: 0.9814 - loss: 0.0967 - val_accuracy: 0.9458 - val_loss: 0.1436 Epoch 20/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 5s 163ms/step - accuracy: 0.9648 - loss: 0.1073 - val_accuracy: 0.9375 - val_loss: 0.1661 Epoch 21/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 5s 175ms/step - accuracy: 0.9728 - loss: 0.1074 - val_accuracy: 0.9375 - val_loss: 0.1564 Epoch 22/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 10s 161ms/step - accuracy: 0.9784 - loss: 0.0851 - val_accuracy: 0.9458 - val_loss: 0.1421 Epoch 23/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 5s 176ms/step - accuracy: 0.9789 - loss: 0.0706 - val_accuracy: 0.9500 - val_loss: 0.1287 Epoch 24/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 10s 172ms/step - accuracy: 0.9859 - loss: 0.0609 - val_accuracy: 0.9458 - val_loss: 0.1368 Epoch 25/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 5s 175ms/step - accuracy: 0.9770 - loss: 0.0786 - val_accuracy: 0.9500 - val_loss: 0.1299 Epoch 26/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 5s 172ms/step - accuracy: 0.9870 - loss: 0.0650 - val_accuracy: 0.9417 - val_loss: 0.1297 Epoch 27/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 10s 173ms/step - accuracy: 0.9949 - loss: 0.0503 - val_accuracy: 0.9500 - val_loss: 0.1228 Epoch 28/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 10s 176ms/step - accuracy: 0.9891 - loss: 0.0494 - val_accuracy: 0.9500 - val_loss: 0.1257 Epoch 29/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 5s 174ms/step - accuracy: 0.9915 - loss: 0.0540 - val_accuracy: 0.9583 - val_loss: 0.1188 Epoch 30/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 5s 176ms/step - accuracy: 0.9966 - loss: 0.0372 - val_accuracy: 0.9500 - val_loss: 0.1244 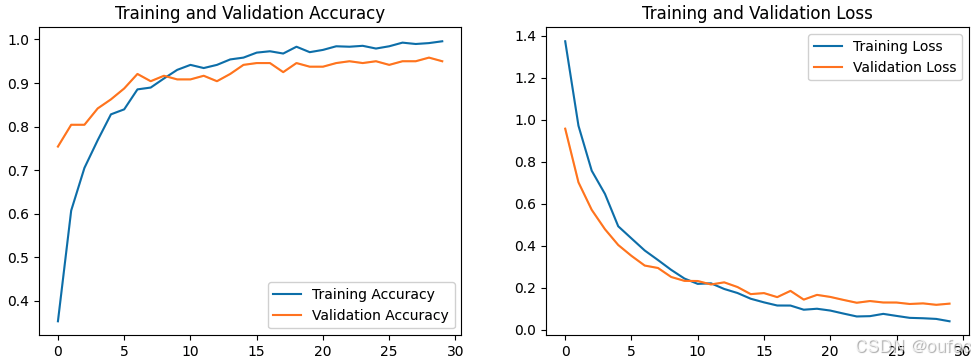
输出结果val_accuracy稍微有点降低。
2、模型微调
在上个冻结了模型所有卷基层的基础上,解冻最后的三个卷基层Conv5-1 ~ Conv5-3。就是只冻结下图的Conv1-1 ~ Conv4-3的卷基层权重参数,让最后三个卷基层加上全连接层的权重参数加入训练。
VGG16.trainable = True set_trainable = False for layer in VGG16.layers: if layer.name == 'block5_conv1': set_trainable = True if set_trainable: layer.trainable = True else: layer.trainable = False 把学习率调成1e-5。
# 设置初始学习率 initial_learning_rate = 1e-5 lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay( initial_learning_rate, decay_steps=30, # 敲黑板!!!这里是指 steps,不是指epochs decay_rate=0.92, # lr经过一次衰减就会变成 decay_rate*lr staircase=True) # 设置优化器 opt = tf.keras.optimizers.Adam(learning_rate=initial_learning_rate) model.compile(optimizer=opt, loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy']) epochs = 30 history = model.fit( train_ds, validation_data=val_ds, epochs=epochs ) 输出:
Epoch 1/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 21s 346ms/step - accuracy: 0.3300 - loss: 1.4454 - val_accuracy: 0.7750 - val_loss: 0.8242 Epoch 2/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 10s 287ms/step - accuracy: 0.6962 - loss: 0.7934 - val_accuracy: 0.8500 - val_loss: 0.3991 Epoch 3/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 10s 276ms/step - accuracy: 0.9098 - loss: 0.3187 - val_accuracy: 0.9542 - val_loss: 0.1491 Epoch 4/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 11s 288ms/step - accuracy: 0.9697 - loss: 0.1277 - val_accuracy: 0.9625 - val_loss: 0.0942 Epoch 5/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 10s 274ms/step - accuracy: 0.9853 - loss: 0.0623 - val_accuracy: 0.9792 - val_loss: 0.0659 Epoch 6/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 10s 282ms/step - accuracy: 0.9858 - loss: 0.0599 - val_accuracy: 0.9917 - val_loss: 0.0354 Epoch 7/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 10s 282ms/step - accuracy: 0.9999 - loss: 0.0190 - val_accuracy: 0.9958 - val_loss: 0.0305 Epoch 8/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 10s 272ms/step - accuracy: 0.9956 - loss: 0.0168 - val_accuracy: 0.9917 - val_loss: 0.0269 Epoch 9/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 10s 273ms/step - accuracy: 0.9986 - loss: 0.0110 - val_accuracy: 0.9917 - val_loss: 0.0347 Epoch 10/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 11s 284ms/step - accuracy: 0.9961 - loss: 0.0134 - val_accuracy: 0.9917 - val_loss: 0.0341 Epoch 11/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 9s 284ms/step - accuracy: 0.9977 - loss: 0.0107 - val_accuracy: 0.9750 - val_loss: 0.0644 Epoch 12/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 10s 275ms/step - accuracy: 0.9986 - loss: 0.0110 - val_accuracy: 0.9958 - val_loss: 0.0176 Epoch 13/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 10s 274ms/step - accuracy: 0.9992 - loss: 0.0046 - val_accuracy: 0.9875 - val_loss: 0.0300 Epoch 14/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 10s 272ms/step - accuracy: 1.0000 - loss: 0.0041 - val_accuracy: 0.9958 - val_loss: 0.0173 Epoch 15/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 10s 272ms/step - accuracy: 0.9978 - loss: 0.0038 - val_accuracy: 0.9917 - val_loss: 0.0214 Epoch 16/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 9s 286ms/step - accuracy: 0.9980 - loss: 0.0032 - val_accuracy: 0.9958 - val_loss: 0.0172 Epoch 17/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 10s 274ms/step - accuracy: 1.0000 - loss: 0.0016 - val_accuracy: 0.9958 - val_loss: 0.0159 Epoch 18/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 10s 284ms/step - accuracy: 1.0000 - loss: 7.7434e-04 - val_accuracy: 0.9958 - val_loss: 0.0117 Epoch 19/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 10s 284ms/step - accuracy: 0.9999 - loss: 9.1304e-04 - val_accuracy: 0.9875 - val_loss: 0.0346 Epoch 20/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 10s 274ms/step - accuracy: 0.9979 - loss: 0.0085 - val_accuracy: 0.9792 - val_loss: 0.0438 Epoch 21/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 10s 274ms/step - accuracy: 1.0000 - loss: 0.0012 - val_accuracy: 0.9958 - val_loss: 0.0127 Epoch 22/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 10s 273ms/step - accuracy: 1.0000 - loss: 0.0012 - val_accuracy: 0.9958 - val_loss: 0.0208 Epoch 23/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 10s 272ms/step - accuracy: 1.0000 - loss: 0.0011 - val_accuracy: 0.9958 - val_loss: 0.0110 Epoch 24/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 11s 284ms/step - accuracy: 1.0000 - loss: 6.0428e-04 - val_accuracy: 0.9958 - val_loss: 0.0131 Epoch 25/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 10s 286ms/step - accuracy: 1.0000 - loss: 6.6759e-04 - val_accuracy: 0.9958 - val_loss: 0.0158 Epoch 26/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 10s 286ms/step - accuracy: 1.0000 - loss: 4.9527e-04 - val_accuracy: 0.9917 - val_loss: 0.0167 Epoch 27/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 10s 273ms/step - accuracy: 1.0000 - loss: 5.7670e-04 - val_accuracy: 0.9917 - val_loss: 0.0248 Epoch 28/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 10s 272ms/step - accuracy: 1.0000 - loss: 9.7004e-04 - val_accuracy: 0.9958 - val_loss: 0.0109 Epoch 29/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 11s 285ms/step - accuracy: 1.0000 - loss: 2.0821e-04 - val_accuracy: 0.9958 - val_loss: 0.0136 Epoch 30/30 30/30 ━━━━━━━━━━━━━━━━━━━━ 10s 286ms/step - accuracy: 1.0000 - loss: 1.2448e-04 - val_accuracy: 0.9958 - val_loss: 0.0149 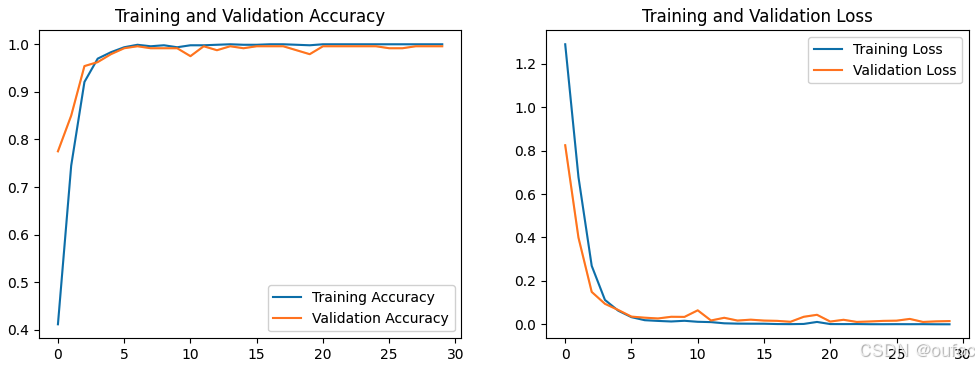
从输出结果看,val_accuracy最高为0.9958,接近1,精度损失这样的程度下,但是模型大小是降到了接近原模型的1/7,还算是成功。
