
阅读量:0
论文概述
本文是遥感领域的大模型相关的一篇工作,发表在CVPR2024。
本文标题:GeoChat : Grounded Large Vision-Language Model for Remote Sensing
论文地址:https://arxiv.org/abs/2311.15826
开源代码:https://github.com/mbzuai-oryx/GeoChat
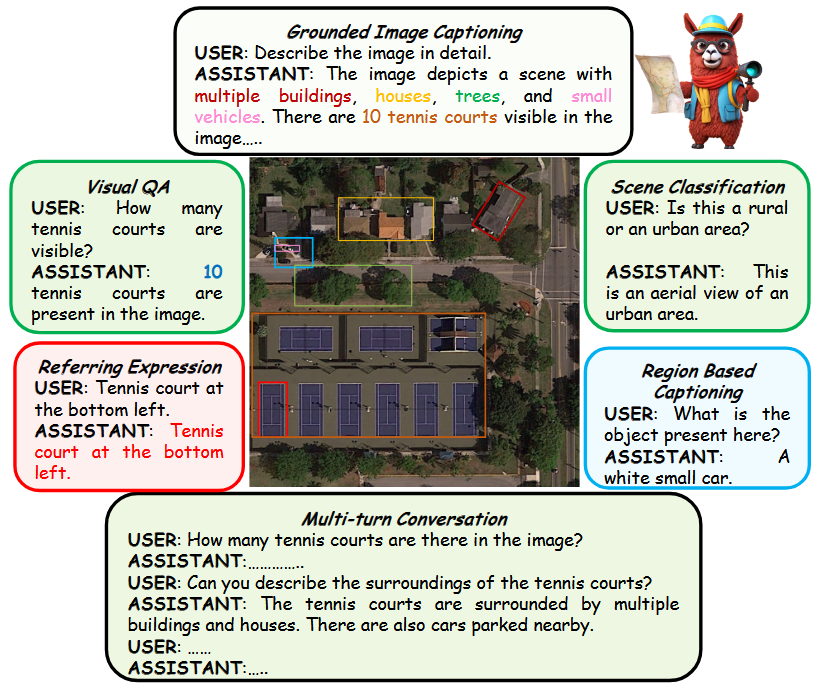
通过大模型,可以完成多个领域任务,该工作支持的任务包括:
- 关联图像描述:Grounded Image Captioning
- 视觉问答:Visual QA
- 指代表达:Referring Expression
- 场景分类:Scene Classification
- 区域描述:Region Based Captioning
- 多轮交流:Multi-turn Conversation
注:部分任务翻译可能不太精准,如Grounded Image Captioning,很难找到完全准确的翻译,有些文章将“Grounded"直译为“接地”,造成误解,实际该任务目的为对给定的一张图片,模型在生成该图片描述时,生成词语的attention map要集中在正确对应的图中物体上[1]。
1.动机
大模型目前比较多,但遥感领域的大模型相对较少,此前已有相关工作如RSGPT(2023)构建了遥感领域的Benchmark,但该工作存在以下两个缺点:1.需要对每个任务进行微调,使用麻烦不可推广;2.无法进行区域推理以及区域视觉文本关联。该工作主要解决这两个问题。
2.贡献
对此,本文主要做了以下三点贡献:
- 利用Vicuna-v1.5对现有的对象检测数据集创建简短描述,构建了一个遥感多模态指令数据集。
- 使用构建的数据集,对LLaVA-1.5进行LoRA微调,创建了遥感领域视觉语言模型GeoChat。
- 建立了大语言模型在遥感领域的评估机制。
这三个贡献点关联的还是比较紧密的,先解决数据集的问题,之后利用数据集构建算法,最后对算法进行评估
3.数据集构建
为了突出GeoChat这套模型架构,本文将数据集构建部分放在了第四节,而把模型架构放在了第三节介绍,这里从贡献点的顺序出发,首先看数据集构建部分。
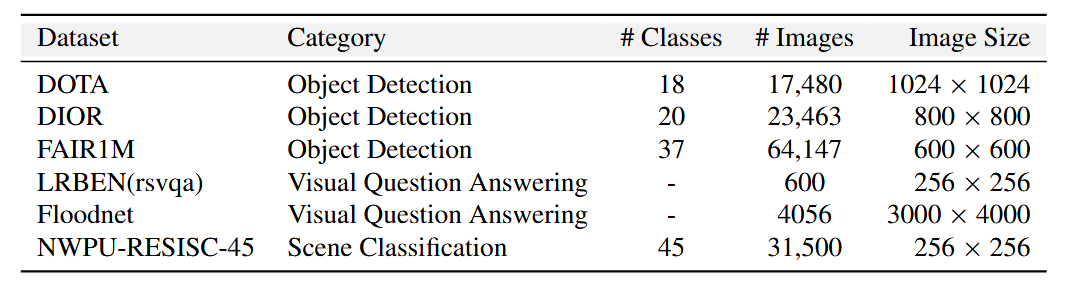
本文使用以下6种遥感数据集:
- 合并数据集
这6种数据集来自三个不同任务:目标检测、场景分类和视觉问答,本文对其进行合并。 - 填补缺失类
不同数据集的类别不尽相同,为了构建基本类别的数据集,需要对缺乏基本类(如建筑物,道路,树木)的数据集进行标签补充。对此,本文使用ViTAE-RVSA模型,在LoveDA数据集上进行预训练,之后再用于在SAMRS数据集上推断这些类,产生伪标签。 - 属性提取
对于每一个目标,构建以下五个属性:

(1)类别(category)
比较容易获取,对于目标检测任务,每一个gt box都有类别注释。(2)颜色(color)
无法直接获取,本文是采用像素聚类的方式,对于每一个box中的像素,使用K-Means 进行聚类,选择最大集群的中心作为对象的颜色。(3)相对尺寸(relative size)
无法直接获取,本文统计所有gt box的大小,由小到大进行排序,前20%作为小(small)对象,后20%作为大(large)对象,其余作为中等(normal)对象。(4)相对定位(relative location)
无法直接获取,本文将整个图像划分为3×3网格,定义区域,如右上、上、左上、左、中、右、右下、左下和下。根据对象的中心像素坐标,指定其相对位置。(5)对象关系(relation)
无法直接获取,本文根据边界框之间的距离对不同的对象进行分组,同时考虑目标本身的类别,选择合适的关系描述词,如下图所示: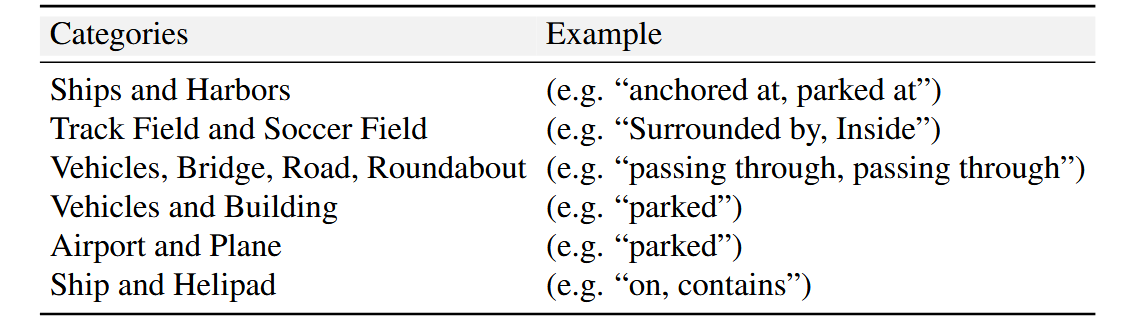
- 生成描述
本文采用了基于 Rsvg 的预定义文本模板,对每一个目标生成一句统一格式的描述:The/A <relative size><color> category <in/on the relative location> - 视觉关联描述
对于不同的任务,采用不同的prompts描述,具体如下表所示: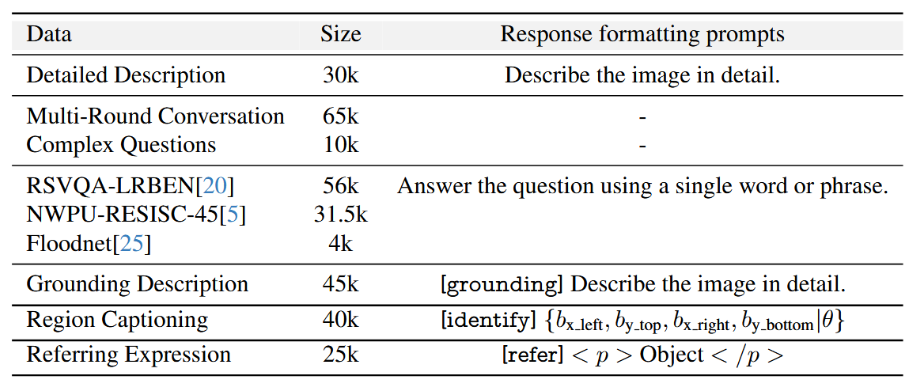
4.GeoChat模型架构
下面进入到本文核心提出来的GeoChat模型架构,如下图所示:
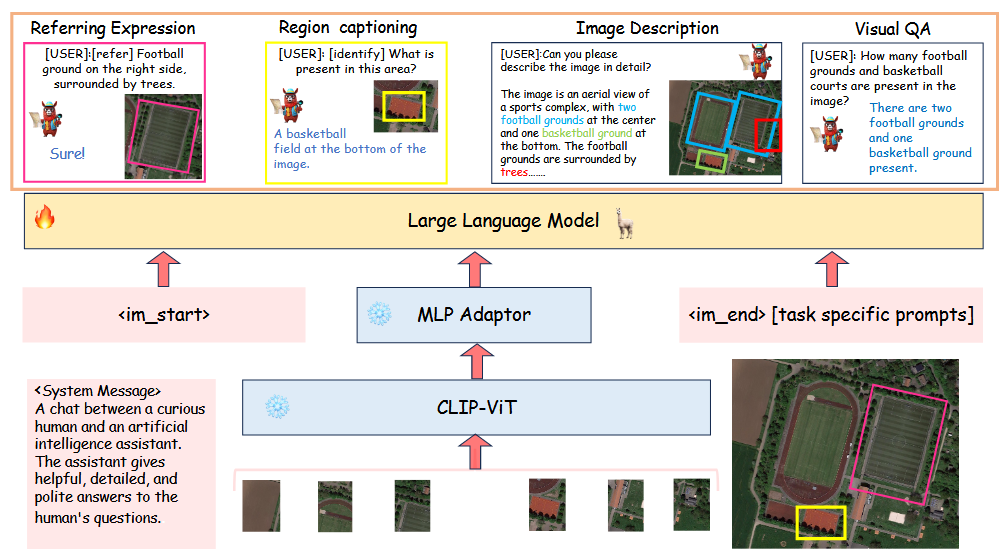
核心架构主要包括图像编码器,MLP和大语言模型(LLM)三部分组成。
这样设计的思路其实不难理解,本文的主要目的是通过大语言模型对遥感图像进行理解和对话,因此输入是遥感图像和prompts,输出是文本回答。
因此,首先需要利用一个多模态转换器将图像数据编码成Token,本文采用了 CLIP-ViT(L-14) 作为预训练主干网络,该网络输入的分辨率为336x336。考虑到遥感数据的分辨率普遍大于该值,因此对位置编码进行插值,使输入图像的分辨率上升为504x504。
之后,为了将编码好的Token直接能输入后面的LLM之中,通过MLP将编码器得到的1024维度的Token映射成4096维度,并使用GeLU作为激活函数。
最后,通过LLM输出结果。这里的LLM采用Vicuna-v1.5 作为基础,通过低秩自适应(LoRA)的策略对LLM进行微调。使用时,LLM会被植入前置系统命令,以完成初始化:A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions. 训练时,冻结CLIP-ViT和MLP Adaptor部分,仅对LLM进行微调。
5.实验试玩
论文里对不同任务进行了实验测试,由于对其它任务指标并不了解,这里略过,下面来试用该工作开源的代码。
(1) 配置环境
该仓库提供了pyproject.toml文件,可通过仓库介绍直接安装相关依赖。
实际测试发现,直接安装deepspeed会报错,而该依赖并不影响推理过程,因此可以将pyproject.toml文件第二十行删除:
"deepspeed==0.9.5", (2)下载模型
作者将模型放在了Hugging Face上,下载地址:https://huggingface.co/MBZUAI/geochat-7B
由于大模型训练时,往往是多卡训练,因此下载模型时,需要将整个模型文件夹下载下来:
放置模型,在geochat_demo.py中修改模型路径:
parser.add_argument("--model-path", type=str, default="weights") (3)运行交互
运行geochat_demo.py,弹出以下链接,表示运行成功。
在浏览器输入:
http://localhost:7860/ 弹出以下界面: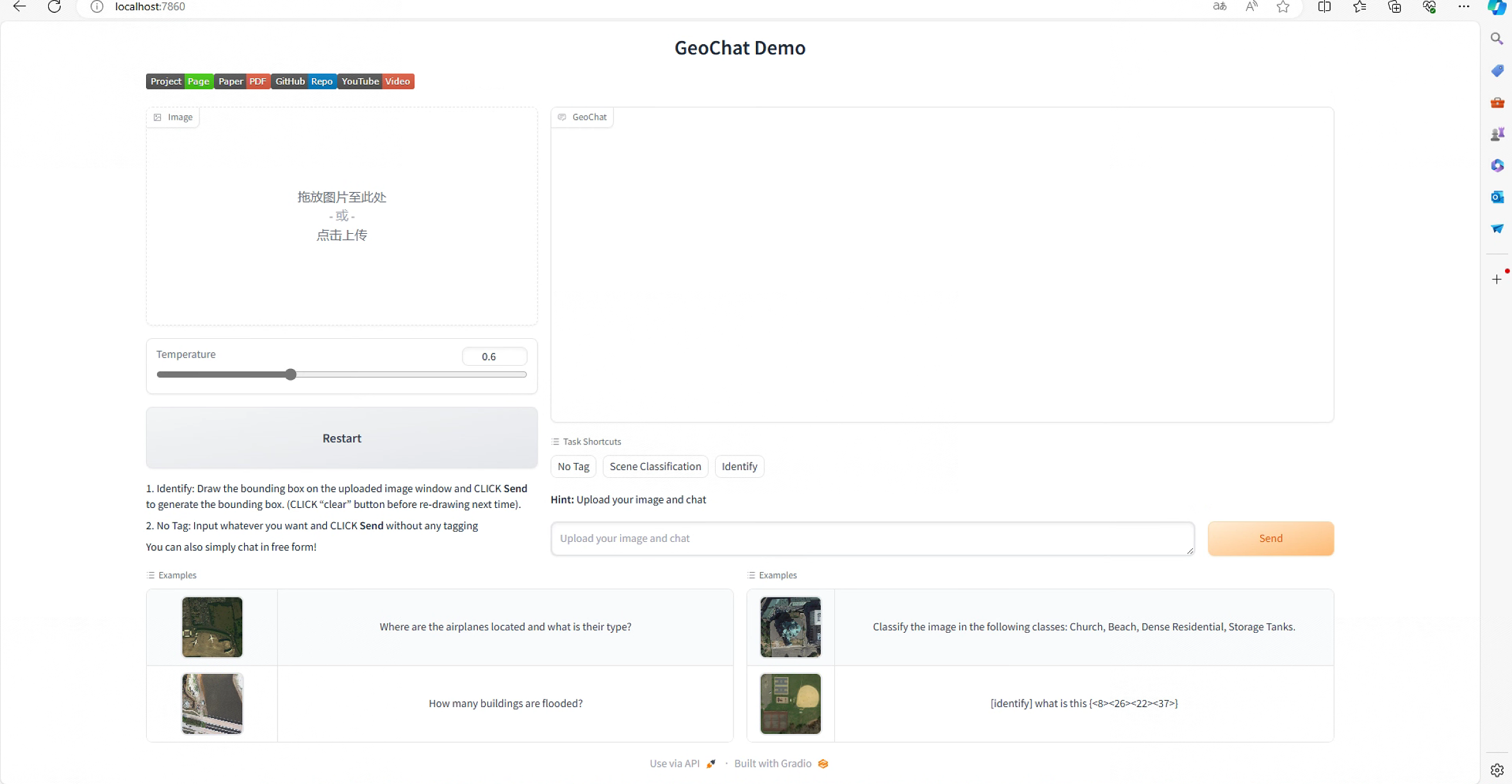
该Demo中,已包含下面四个Example,也可以上传自己的图片,下面我上传了一张VisDrone数据集中的图片,问它里面有多少车,并告诉方位。
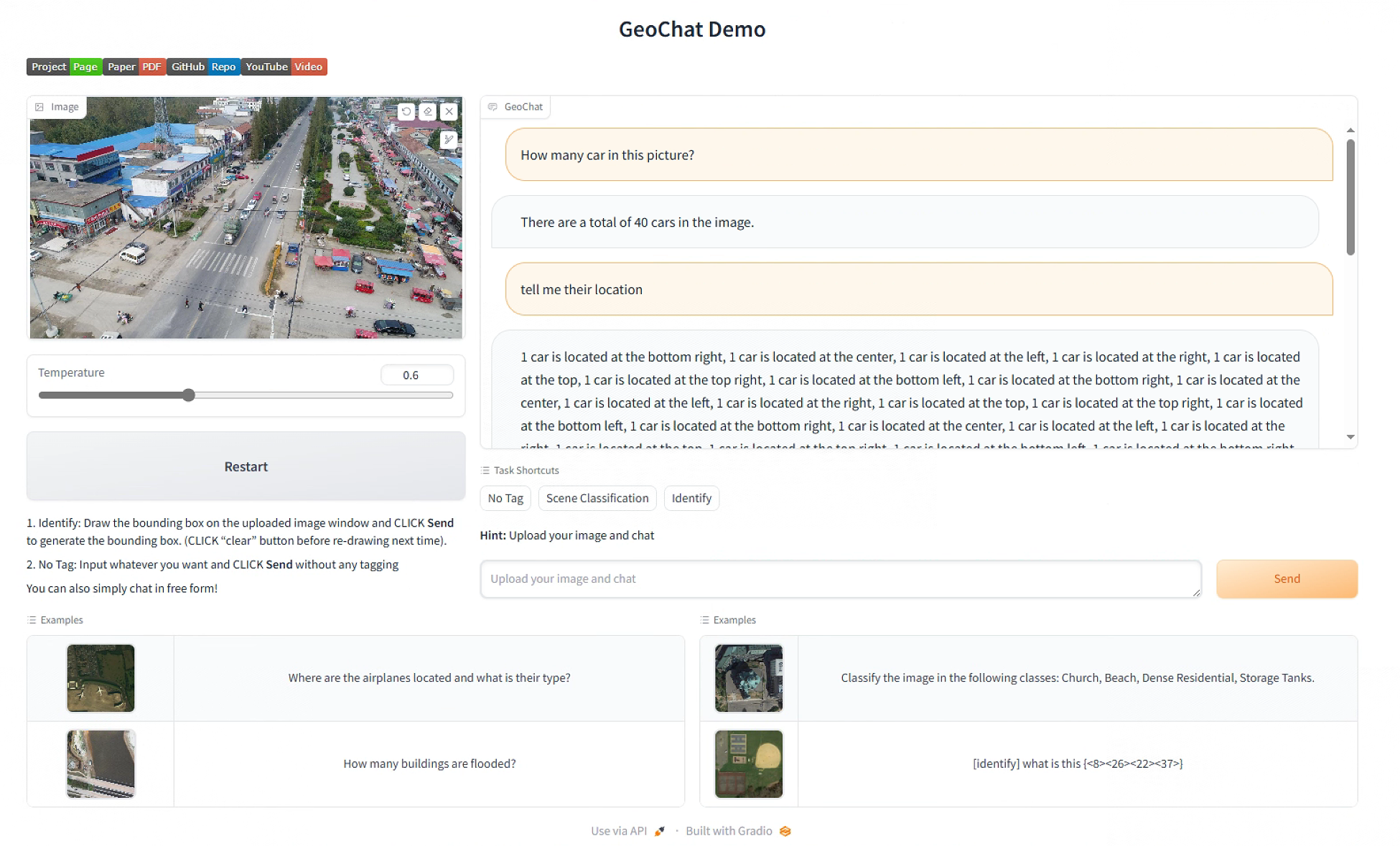
实验环境采用的是一张4090显卡,推理时约需10GB显存,单轮推理约5秒出结果。
下面测试了一下区域推理,通过画笔在图片上圈出一个人,让它进行识别,它一开始认为这是个十字路口,再次询问,回答出是一个人。
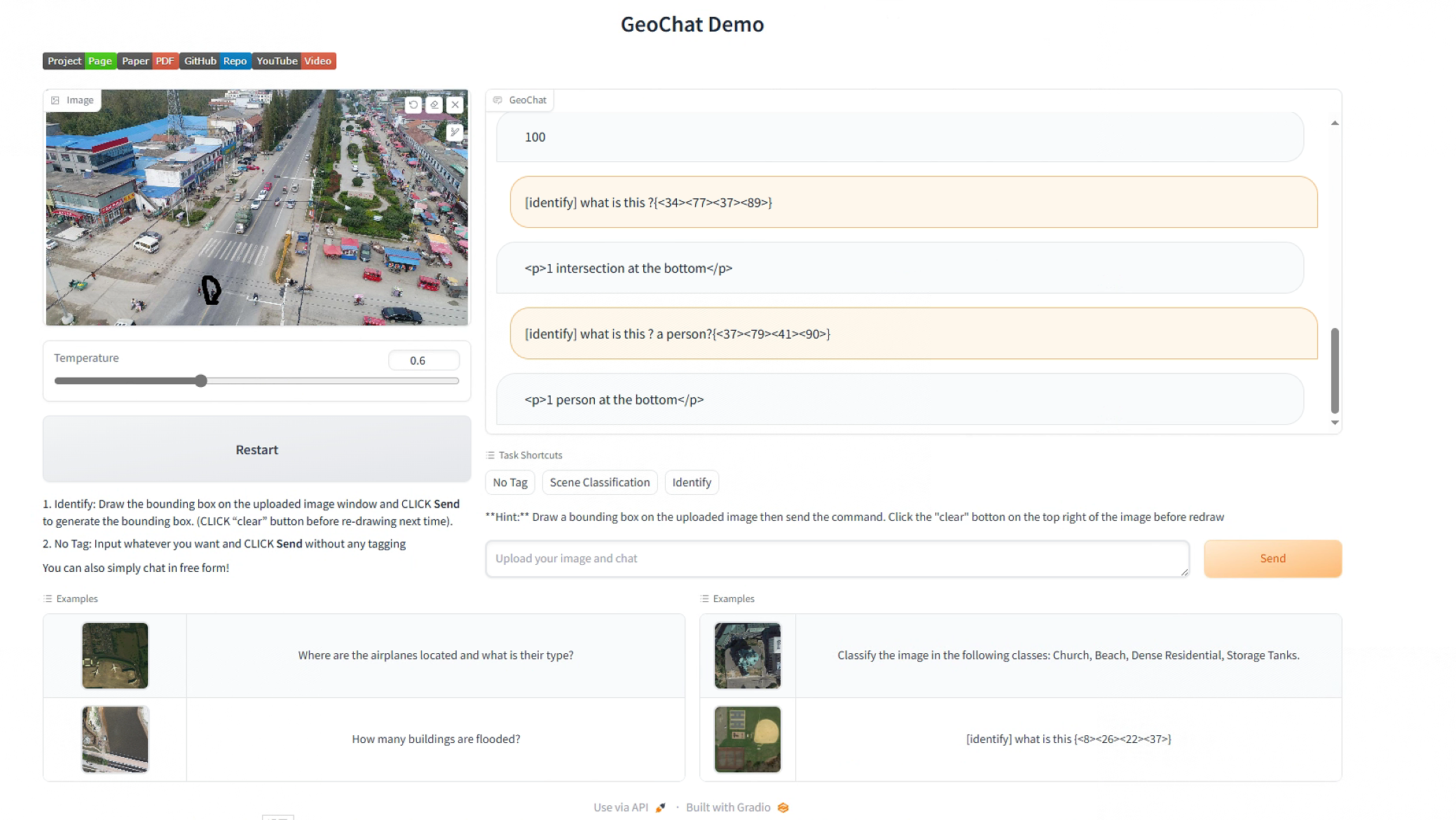
注:该demo中,可以调节Temperature,该值越大,则输出内容会越随机,此外,可以通过打Tag的方式来提示LLM具体做什么任务。
总结思考
本文提出的GeoChat思路不复杂,不过工作量巨大。这类工作不仅需要较大的算力和多领域数据集制作,而且还需要对不同领域的任务均有一定了解,工作具有一定门槛。同时,也引发了我进一步思考,在遥感图像分析工作中,是否有必要引入LLM,是否可以通过SAM等纯视觉大模型的路线完成一些通用工作。引入LLM的目的,是为了增强模型性能,还是为了拓展更多多模态的任务?这可能需要进一步分析探索。
参考
[1] 【论文分享】More Grounded Image Captioning by Distilling Image-Text Matching Model:https://zhuanlan.zhihu.com/p/358704852
[2] 【论文阅读】GeoChat : Grounded Large Vision-Language Model for Remote Sensing:https://blog.csdn.net/weixin_56603442/article/details/136145874
