
阅读量:0
今天我要和大家分享一个新功能更新——微软的文本转语音和语音转文本功能。最近,微软对其AI语音识别和语音合成技术进行了重大升级,效果非常好,现在我将分别为大家介绍这两个功能。
先来听下这个效果吧
微软文本转语音和语音转文本功能更新
文本转语音
文本转语音(Text-to-Speech, TTS)是一种将文本信息转换为自然听起来的语音的技术。微软的文本转语音功能提供了多种语言和语音选项,支持多种平台和设备,使得用户可以轻松将文本转换为语音。
更新后的文本转语音功能在语音合成方面有了很大的提升。它不仅能够更自然地模拟人类语音的语调、语速和语调变化,还能够根据上下文智能调整发音,使得合成的语音更加自然流畅。
python代码如下:运行后,会在终端运行的目录下生成一个output.mp3文件
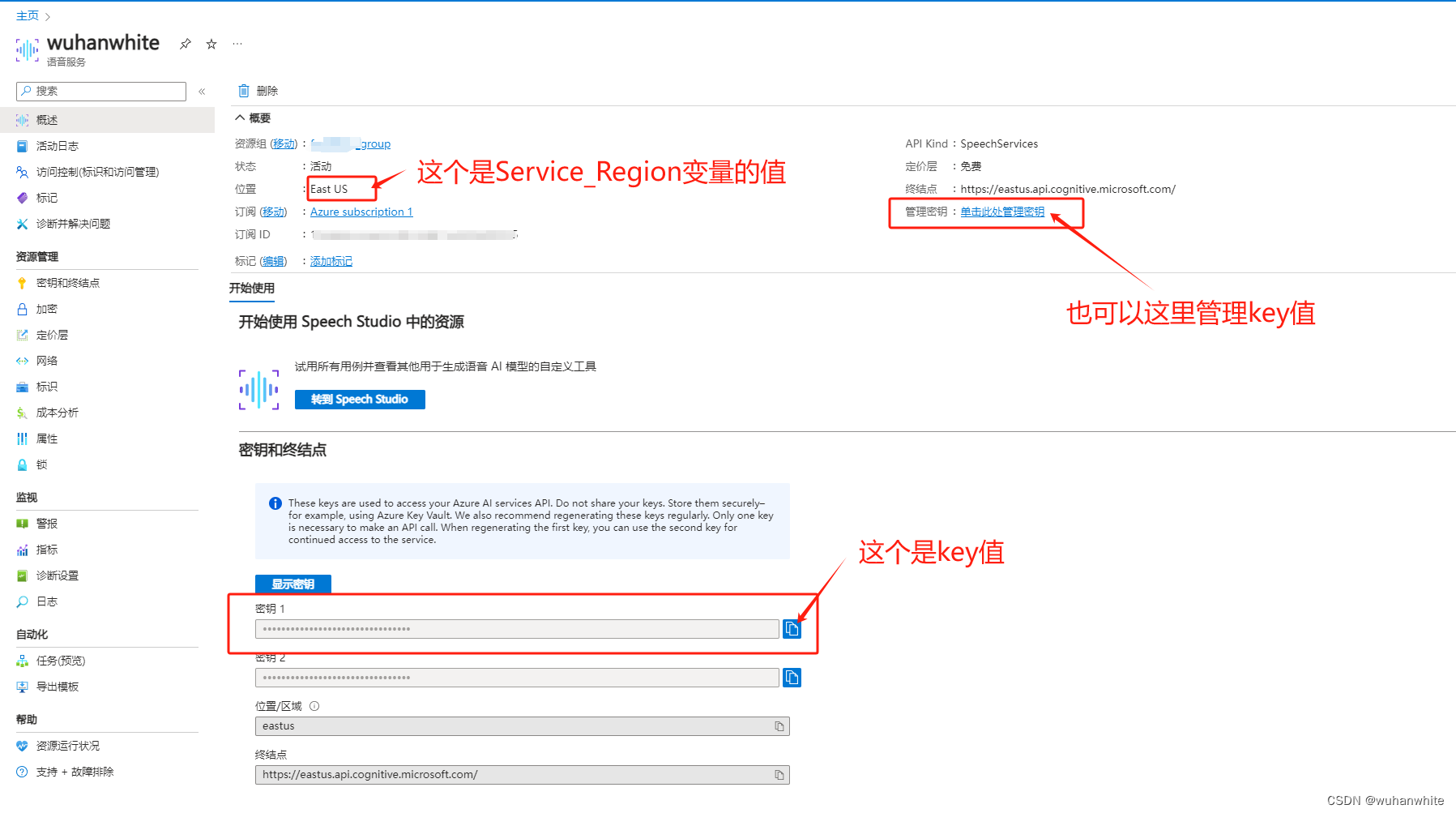
from azure.cognitiveservices.speech import SpeechConfig, SpeechSynthesizer, AudioConfig from azure.cognitiveservices.speech.audio import AudioOutputConfig from azure.cognitiveservices.speech import ResultReason, CancellationReason # 创建SpeechConfig对象 speech_config = SpeechConfig(subscription="key", region="service_region") # 创建音频配置对象 audio_config = AudioConfig(filename="output.mp3") # 输出到MP3文件 # 创建语音合成器 speech_synthesizer = SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config) text="How To Unlock Cyberpunk 2077’s New Ending In Phantom Liberty" # 定义SSML文本 ssml_string2=""" <!--ID=B7267351-473F-409D-9765-754A8EBCDE05;Version=1|{"VoiceNameToIdMapItems":[{"Id":"390baec9-d867-4c01-bdcf-04e5848ee7dc","Name":"Microsoft Server Speech Text to Speech Voice (zh-CN, XiaoxiaoMultilingualNeural)","ShortName":"zh-CN-XiaoxiaoMultilingualNeural","Locale":"zh-CN","VoiceType":"StandardVoice"}]}--> <!--ID=FCB40C2B-1F9F-4C26-B1A1-CF8E67BE07D1;Version=1|{"Files":{}}--> <!--ID=5B95B1CC-2C7B-494F-B746-CF22A0E779B7;Version=1|{"Locales":{"zh-CN":{"AutoApplyCustomLexiconFiles":[{}]},"de-DE":{"AutoApplyCustomLexiconFiles":[{}]}}}--> <speak xmlns="http://www.w3.org/2001/10/synthesis" xmlns:mstts="http://www.w3.org/2001/mstts" xmlns:emo="http://www.w3.org/2009/10/emotionml" version="1.0" xml:lang="zh-CN"><voice name="zh-CN-XiaoxiaoMultilingualNeural"><lang xml:lang="zh-CN"><s />但我现在对这个职业的热爱还是非常的,呵呵,非常的,嗯,怎么说呢?日月可鉴的,哈哈,嗯还是希望可以把这个职业做下去或者做这个声音相关领域的工作,嗯,就是把自己的优势发挥的大一点,尽可能能用到自己擅长的东西,而不是说为了工作,为了挣钱而工作。<s /></lang></voice></speak> """ # 使用SSML文本进行语音合成 result = speech_synthesizer.speak_ssml_async(ssml_string2).get() # 检查结果 if result.reason == ResultReason.SynthesizingAudioCompleted: print("Speech synthesized to [output.mp3] for text [{}]".format(ssml_string2)) elif result.reason == ResultReason.Canceled: cancellation_details = result.cancellation_details print("Speech synthesis canceled: {}".format(cancellation_details.reason)) if cancellation_details.reason == CancellationReason.Error: if cancellation_details.error_details: print("Error details: {}".format(cancellation_details.error_details)) print("Did you update the subscription info?") 其中,Service_region和key值需要到azure中去获取,先选语音服务

语音转文本
语音转文本(Speech-to-Text, STT)则是一种将语音信息转换为文本的技术。微软的语音转文本功能支持多种语言和方言,能够实时将语音转换为文本,并提供了强大的噪声抑制和回声消除功能,使得识别准确率大大提高。
python代码如下:
import os import tkinter as tk from tkinter import filedialog, ttk import azure.cognitiveservices.speech as speechsdk from datetime import datetime # 配置Azure语音服务的密钥和区域 speech_key = "key" service_region = "service_region" def recognize_speech(): # 获取选择的WAV文件路径 wav_file = filedialog.askopenfilename(filetypes=[("WAV Files", "*.wav")]) if wav_file: # 更新状态标签 status_label.config(text="正在识别...") # 创建语音配置对象,并设置语言为中文 speech_config = speechsdk.SpeechConfig(subscription=speech_key, region=service_region) speech_config.speech_recognition_language = "zh-CN" # 创建音频配置对象 audio_config = speechsdk.audio.AudioConfig(filename=wav_file) # 创建语音识别器对象 speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config) # 定义识别结果的回调函数 recognized_text = [] def handle_final_result(evt): recognized_text.append(evt.result.text) progress_bar.step(10) # 每次识别结果更新进度条 # 连接识别结果的事件处理程序 speech_recognizer.recognized.connect(handle_final_result) # 定义识别状态的标志变量 is_recognizing = True # 定义识别结束的回调函数 def handle_session_stopped(evt): nonlocal is_recognizing is_recognizing = False # 连接识别结束的事件处理程序 speech_recognizer.session_stopped.connect(handle_session_stopped) # 执行连续识别 speech_recognizer.start_continuous_recognition() # 等待连续识别完成 while is_recognizing: window.update() # 停止连续识别 speech_recognizer.stop_continuous_recognition() # 获取当前时间戳 timestamp = datetime.now().strftime("%Y%m%d_%H%M%S") # 构建保存文件的路径 save_path = os.path.join("C:\\temp", f"recognized_text_{timestamp}.txt") # 将识别结果保存到文件 with open(save_path, "w", encoding="utf-8") as file: file.write("\n".join(recognized_text)) # 更新状态标签 status_label.config(text="识别完成,结果已保存到文件: " + save_path) # 重置进度条 progress_bar["value"] = 0 # 创建图形化界面 window = tk.Tk() window.title("语音识别") # 创建选择文件按钮 select_button = tk.Button(window, text="选择WAV文件", command=recognize_speech) select_button.pack(pady=10) # 创建状态标签 status_label = tk.Label(window, text="请选择要识别的WAV文件") status_label.pack() # 创建进度条 progress_bar = ttk.Progressbar(window, length=200, mode="determinate") progress_bar.pack(pady=10) # 运行图形化界面 window.mainloop()运行后,效果如下:

总结
总的来说,微软的文本转语音和语音转文本功能的这次更新,无疑是一次重大的技术突破。它不仅为用户提供了更加自然流畅的语音合成体验,还极大地提高了语音识别的准确率。这对于需要使用语音识别和语音合成功能的用户来说,无疑是一个巨大的福音。
好了,今天的分享就到这里。如果你对这两个功能有更多的疑问或者想法,欢迎在评论区留言讨论。我们下期再见!
