
阅读量:0
23年12月来自上海AI实验室、上海交大、香港大学、香港中文大学和清华大学的论文“EmbodiedScan: A Holistic Multi-Modal 3D Perception Suite Towards Embodied AI“。
在计算机视觉和机器人领域,具身智体有望探索其环境并执行人类指令。这就需要有能力充分理解3D场景的第一人称观察结果,并将其置于上下文的语言进行交互。然而,传统的研究更多地集中在全局视图的场景级输入和输出设置上。
为了解决这一差距,本文引入EmbodiedScan,这是一个多模态、以自我为中心的3D感知数据集和整体3D场景理解的基准。它包括5k次以上的扫描,封装了1M个以自我为中心的RGB-D视图、1M个语言提示、跨越760多个类别、160k个面向3D的边框,其中一些与LVIS部分一致,还有80个常见类别的密集语义占用格。在这个数据库的基础上,引入一个名为Embedded Perceptron的基线框架。它能够处理任意数量的多模态输入,并在建立的两个系列基准中,即基础3D感知任务和语言落地的任务中,以及“在野外采集的”数据,都表现出非凡的3D感知能力。
EmbodiedScan如图所示:

考虑到现有数据集已经提供了现成的3D室内场景扫描,首先将这些以自我为中心的RGB-D捕捉与相应的相机姿势相集成。考虑到ScanNet[15]、3RScan[57]和Matterport3D[7]的兼容性,选择具有必要注释的高质量部分来形成EmbodiedScan的初始版本。ARKitScenes[3]拥有不同的数据组织、深度传感器和注释,考虑未来纳入。
尽管这些数据集都有RGB-D数据,但数据格式、采样频率和视点之间的关系各不相同。首先将格式统一为一个通用的多视图情况,适应Matterport3D,方法是在加载图像时添加随机性,但在推理过程中保持ScanNet和3RScan的顺序连续性。因此,模型可以处理时域和随机捕获的多视图图像。此外,根据官方注释将Matterport3D的建筑规模场景划分为多个区域,选择深度点(depth points)落入该区域的相应图像。对于ScanNet和3RScan视频中图像的不同采样率,为ScanNet每10帧采样一个关键帧,并保留3RScan的所有图像。均匀抽样一般符合实际情况。
全球坐标系是聚合多视图观测并作为输出参考所必需的。遵循ScanNet的惯例,导出一个原点围绕场景中心的系统,水平面位于地面,轴与墙对齐[39]。这种后处理协调了数据分布,略微提高了基准测试的性能。实际应用可能没有这样一个先验的全球系统,或者根据观测结果而变化,给未来的探索带来了另一个有趣的问题。
如图是EmbodiedScan注释和统计信息。(a) 三维边框注释的用户界面。选择关键帧并使用相应的轴对齐边框生成SAM掩码。通过简单的点击,注释器可以为目标物体创建3D框,并在三个正交视图和图像中针对参考进一步调整。(b) 小框(< 1 m^3)可增加更多和及时的统计信息。obj/avg/des指目标/平均值/描述。(c) 显示每个类别(300个类)的实例数。对于ScanNet中存在的类别,绘制了绝对增长图,并观察到显著的改善。(d) 绘制了每个类别的占用率分布,并看到了不同的单词云分布。这两个云显示了该数据集的不同方面,即占用空间与实例数量。
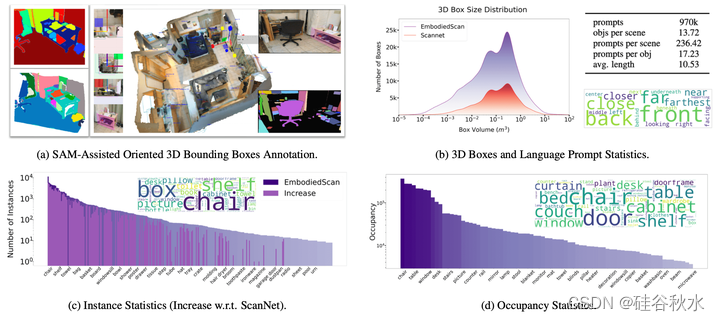
三维边框。根据标准定义[3,4],长方体由其三维中心、大小和ZXY欧拉角方向定义。用Segment Anything Model(SAM)[24]和基于[26]的定制注释工具(上图a)来解决现有3D框注释的局限性,即缺乏方向和小目标注释。它支持在三个正交视图中注释具有方向的三维框的传统功能。此外,根据相机姿势的变化,对几个具有清晰成像的关键帧进行采样,并确保它们覆盖非重叠区域和大多数目标,生成SAM掩码和轴对齐框,用于进一步调整。与注释团队合作,最终检查所有标签的质量。每个场景大约需要10-30分钟的时间进行注释,这取决于场景的复杂性。
语义占用。语义占用需要跨语义区域的精确边界,无需考虑目标姿态或召回所有目标,因此原始点云分割注释更适合用于推导真值。对于每个体素,指定最多点的类别作为该单元的语义标签。感知粒度和计算效率之间的折衷导致沿着X-Y(水平)平面和Z(垂直)轴在感知范围[-3.2m~3.2m,−3.2m~3.2 m,−0.78m~1.78m]内产生40×40×16的占用图。
语言描述。给定方向注释的更新3D边框,按照SR3D[1],导出描述目标之间空间关系的语言提示。它们作为语言落地感知模型的提示输入,用于执行3D视觉落地。由于注释后目标密度增加,识别独特目标变得更具挑战性。为了克服这一点,将多个空间关系提示组合去落地目标。
给定该数据集,可以进行多模态输入,包括RGB图像、从深度图中导出的点云以及语言提示,提取多模态表示并执行不同的下游任务。文中提供了一个基线,即Embedded Perceptron,该基线具有统一的框架和定制的设计,用于从自我为中心的视角理解整体3D场景。
该框架包括用于提取目标和场景表示的多模态D编码器,以及用于各种下游任务的稀疏和密集解码器。此外,还自定义输出的参数化和训练目标,适应稀疏解码器中定向3D边框的公式。
如图所示,多模态3D编码器首先具有用于不同模态的单独编码器-用于2D图像的ResNet50[19]和FPN[29](可选),用于点云的Minkowski ResNet34[12],以及用于文本的BERT[16]。在提取这些特征后,进一步将其融合并处理为稀疏或密集特征,用于不同的下游任务。
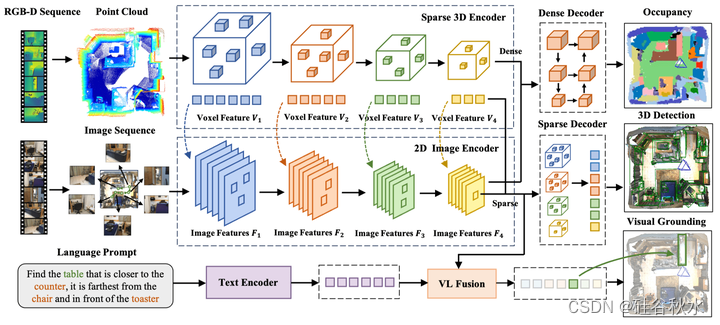
给定典型编码器的多模态特征,对稀疏和密集任务使用单独的融合流。这导致来自同构稀疏融合的四个级别稀疏体素特征FkS和用于解码和预测的单个密集特征FD。然后对其进行处理,以获得3D盒子和占用预测。
基准测试基于数据样本有三类:基于场景、基于视图和基于提示。基于场景的基准是指样本基于不同的场景,涵盖连续和多视角感知。基于视图的基准测试将以自我为中心的视图用于单目3D检测等任务。最后,基于构建的语言提示,给出了三维视觉落地的样例。
对于度量,用基于3D IoU的平均精度(AP),阈值为0.25和0.5,用于3D检测和视觉落地。还提供了平均召回率(AR)以供参考。对于占用率预测,用平均并集交集(mIoU)作为性能度量。
