
阅读量:0
Ubuntu部署K8S集群
1. 模版机系统环境准备
1.1 安装Ubuntu
看这篇文章:
https://blog.csdn.net/weixin_52799373/article/details/139341024
根据上面的文章安装一个Ubuntu系统,确保系统:
- 安装后可以联网
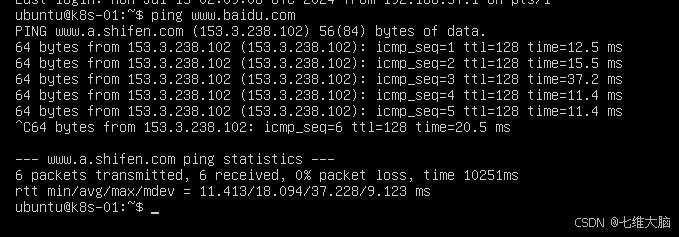
安装完以后,登录系统,输入以下命令:
ping www.baidu.com 提示类似以下输出,则代表可联网:
注意:
Ctrl+C退出ping命令。
- 可以使用SSH工具连接
- 已设置root密码
如果没有设置,请看上面文章的第5.1步骤
确保可以通过命令正常切换root用户:
su - root 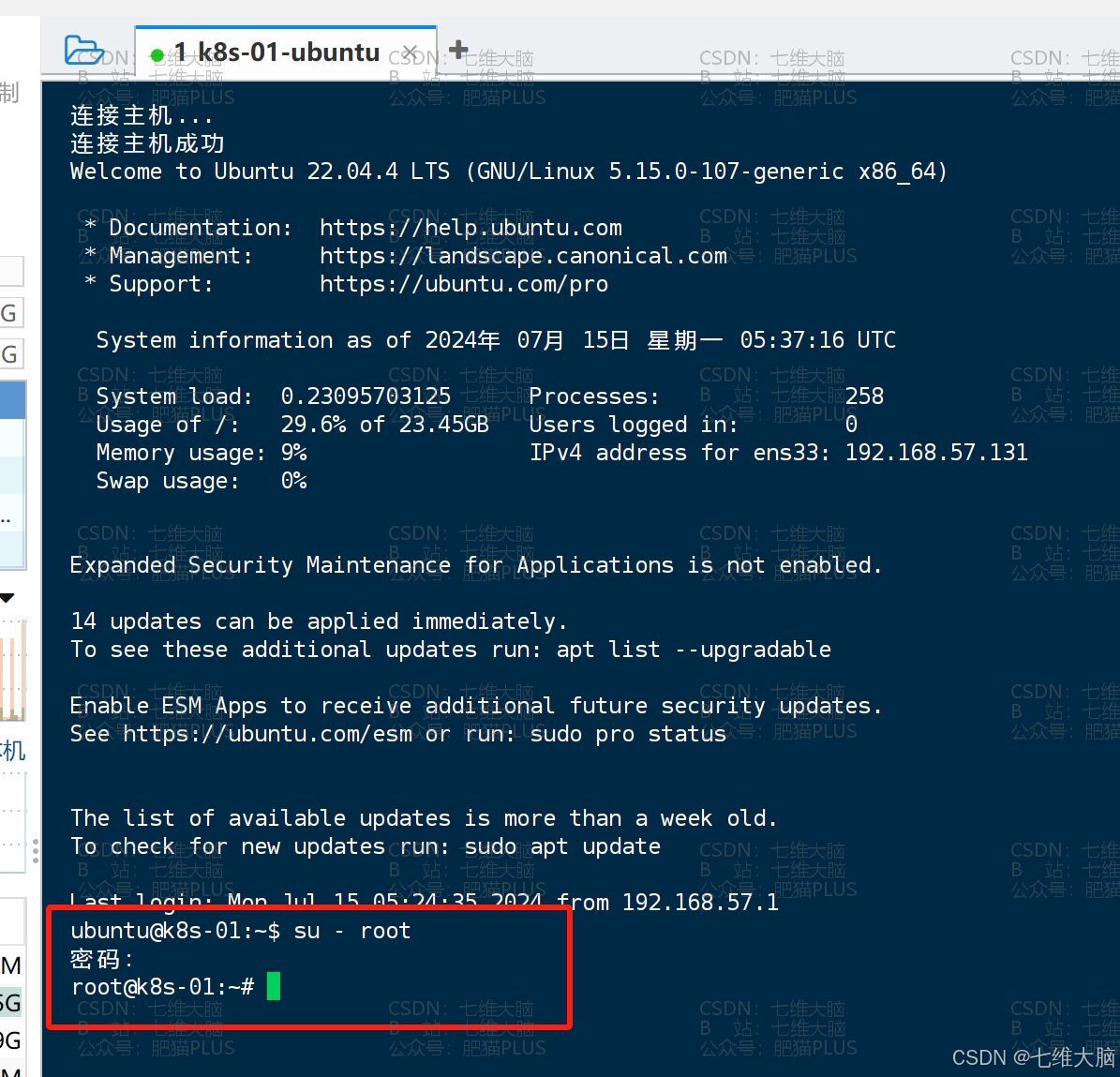
1.2 设置静态IP地址
- 通过命令切换到
root用户:
su - root 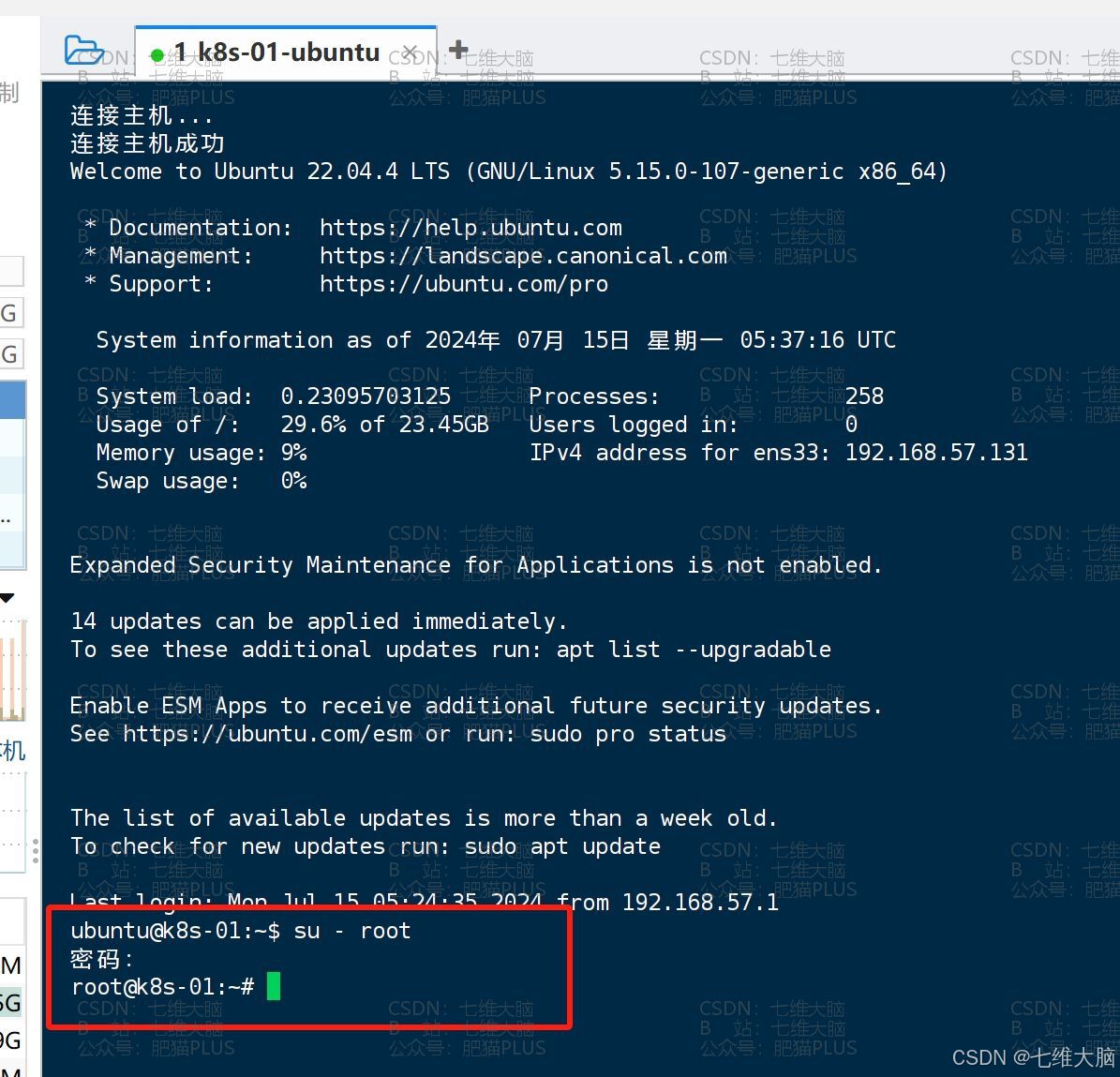
- 备份网络配置文件
执行以下命令,先备份一下配置文件:
cp /etc/netplan/00-installer-config.yaml /etc/netplan/00-installer-config.yaml.bak 
- 修改配置文件
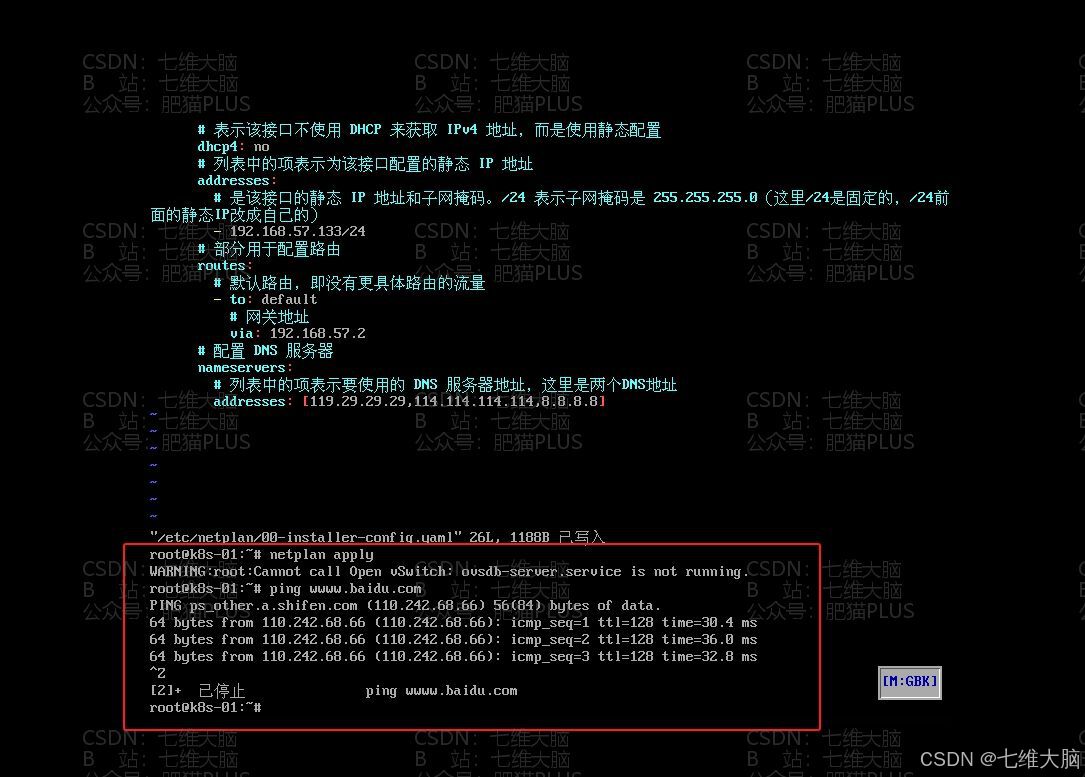
vim /etc/netplan/00-installer-config.yaml 将配置文件原有的内容删除,把下面的配置,复制到配置文件中:
(复制的时候一定要注意缩进!)
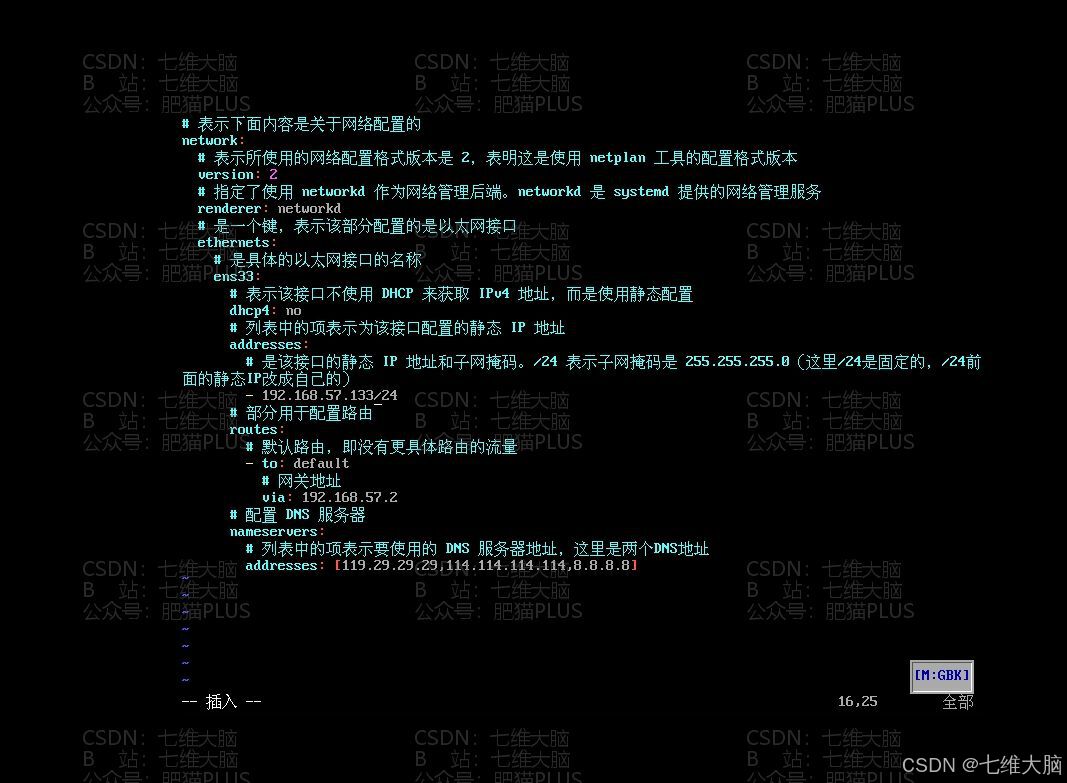
# 表示下面内容是关于网络配置的 network: # 表示所使用的网络配置格式版本是 2,表明这是使用 netplan 工具的配置格式版本 version: 2 # 指定了使用 networkd 作为网络管理后端。networkd 是 systemd 提供的网络管理服务 renderer: networkd # 是一个键,表示该部分配置的是以太网接口 ethernets: # 是具体的以太网接口的名称 ens33: # 表示该接口不使用 DHCP 来获取 IPv4 地址,而是使用静态配置 dhcp4: no # 列表中的项表示为该接口配置的静态 IP 地址 addresses: # 是该接口的静态 IP 地址和子网掩码。/24 表示子网掩码是 255.255.255.0(这里/24是固定的,/24前面的静态IP改成自己的) - 192.168.57.141/24 # 部分用于配置路由 routes: # 默认路由,即没有更具体路由的流量 - to: default # 网关(这个要去VMware看一下自己的网关是多少,改成自己的) via: 192.168.57.0 # 配置 DNS 服务器 nameservers: # 列表中的项表示要使用的 DNS 服务器地址,这里是三个DNS地址 addresses: [119.29.29.29,114.114.114.114,8.8.8.8] 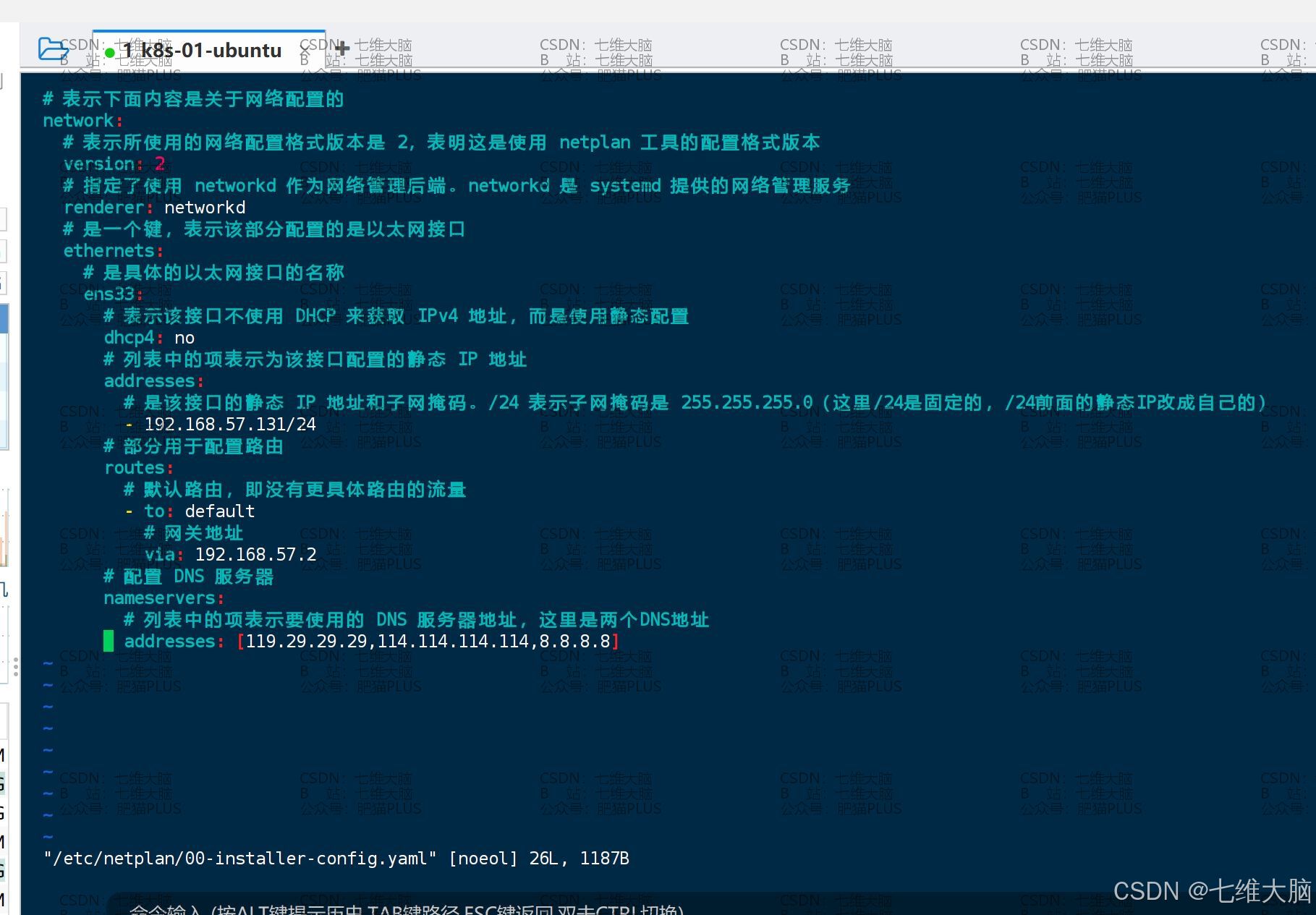
其中
- addresses:要改成自己要设置的IP!!!,IP的前三段要跟网关一致。(可以改成目前系统的IP地址,也就是ssh连接所用的IP地址)
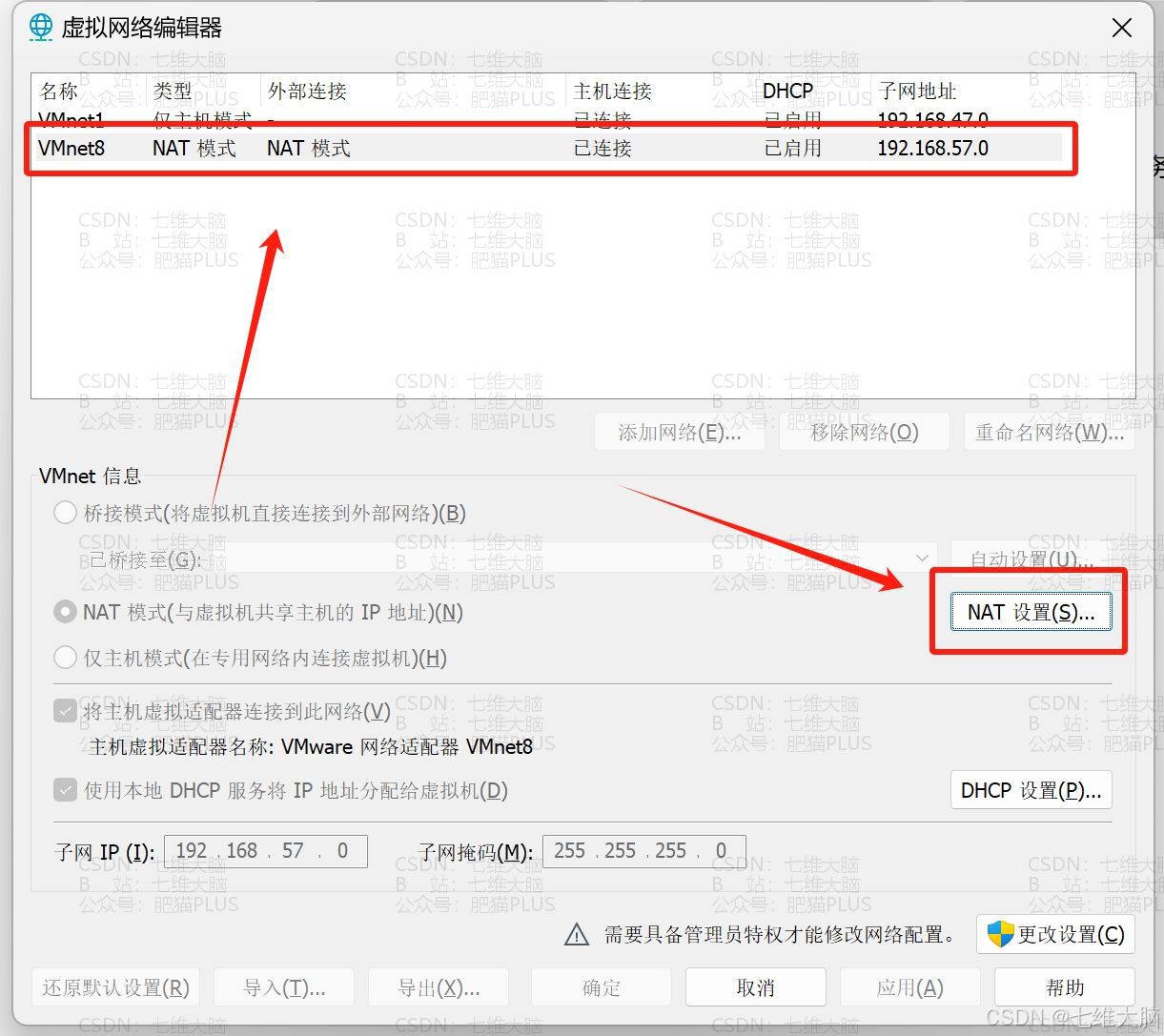
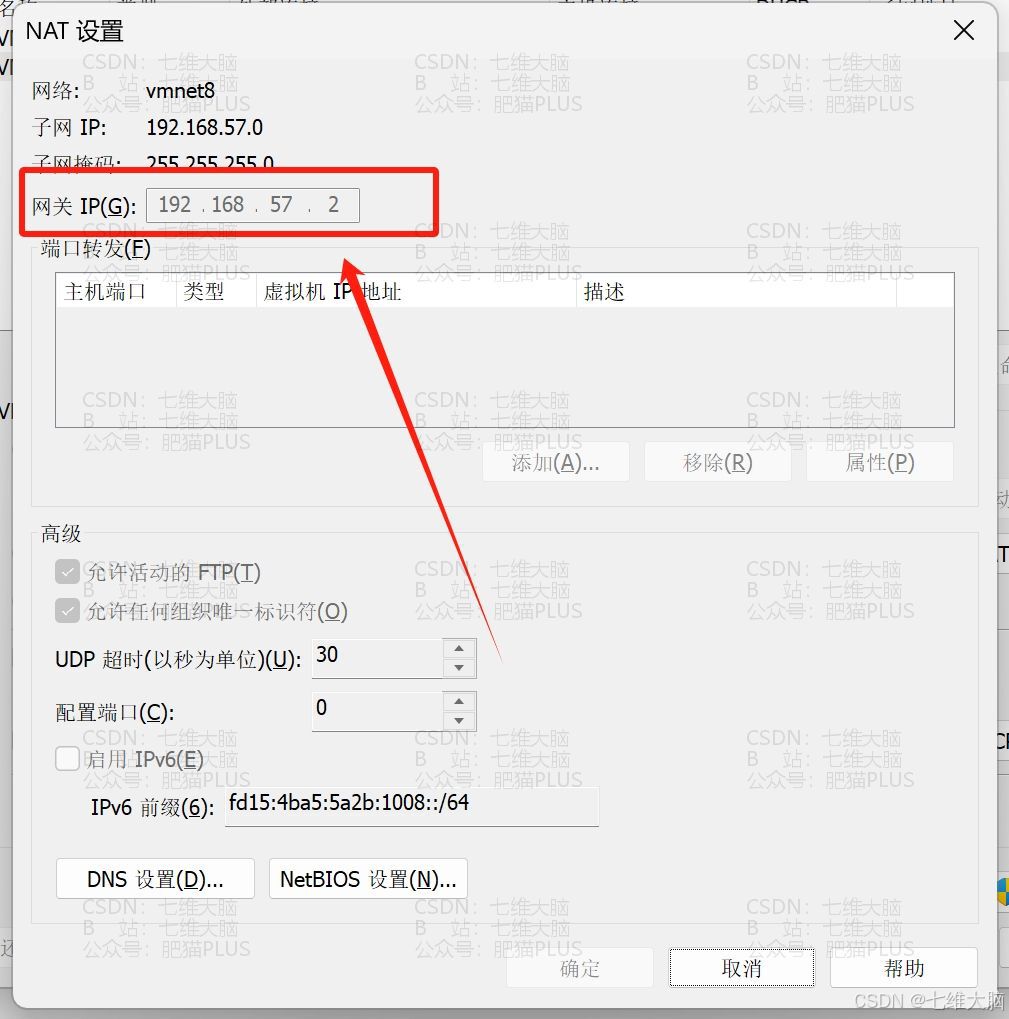
- via :要改成自己的网关地址!!!下面的图片是告诉你怎么看的:
- 使配置生效
输入以下命令,使配置生效:
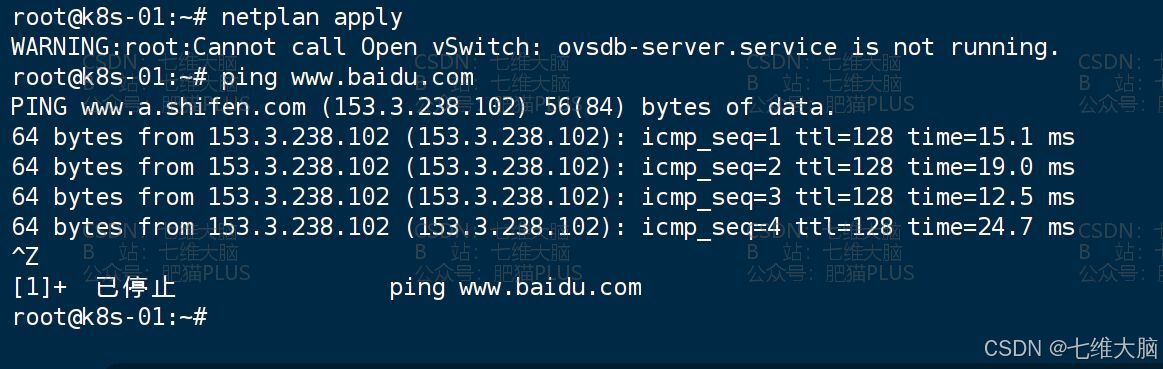
netplan apply 生效以后,再 ping 一下 www.baidu.com,看网络是否正常,如果正常则修改成功了:
2. 主机准备
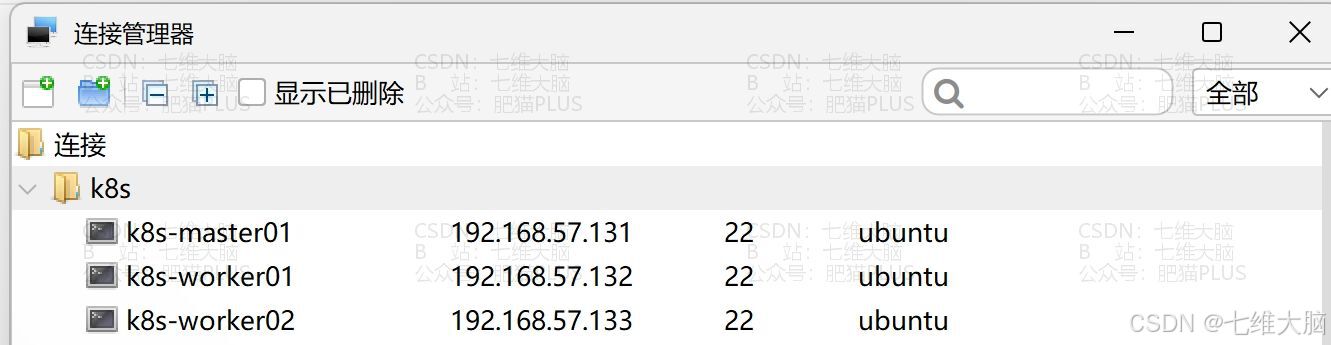
2.1 使用模板机创建主机
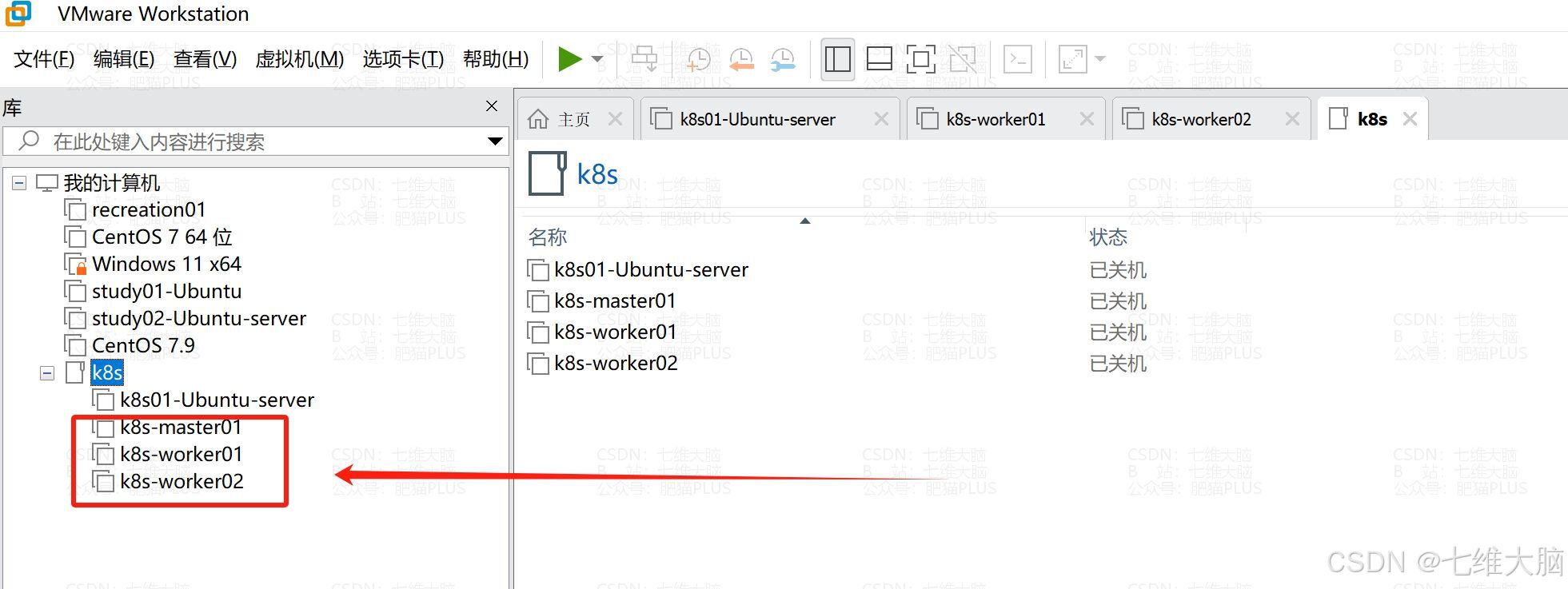
这里我们直接通过上面的模板机克隆出三台机器即可
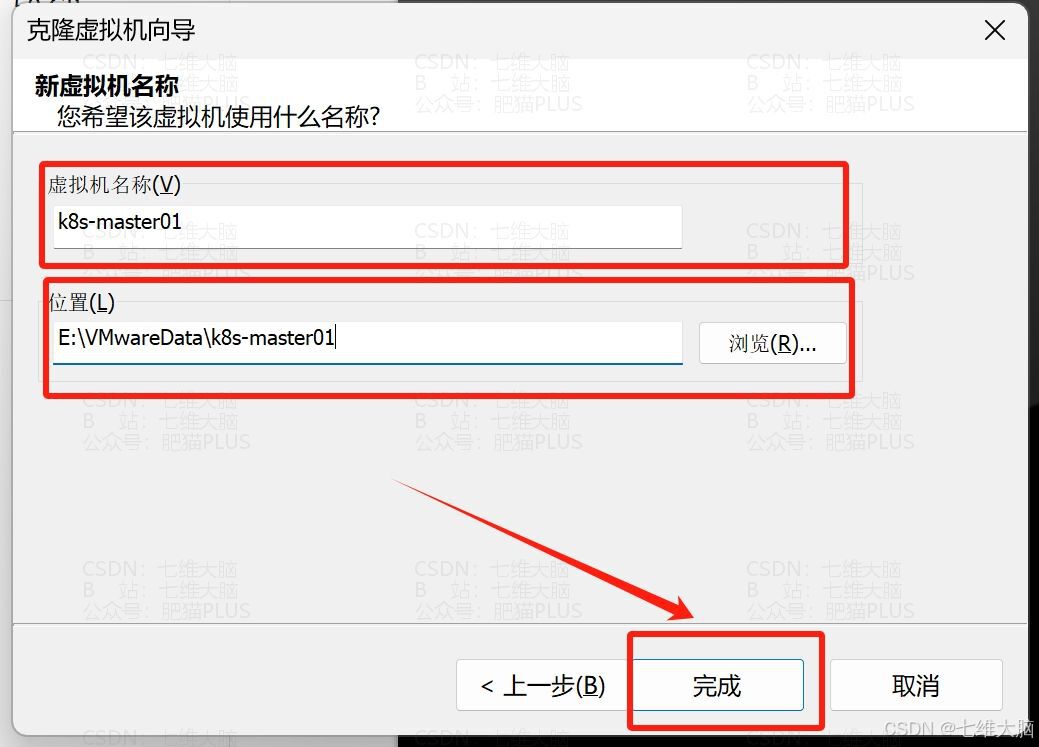
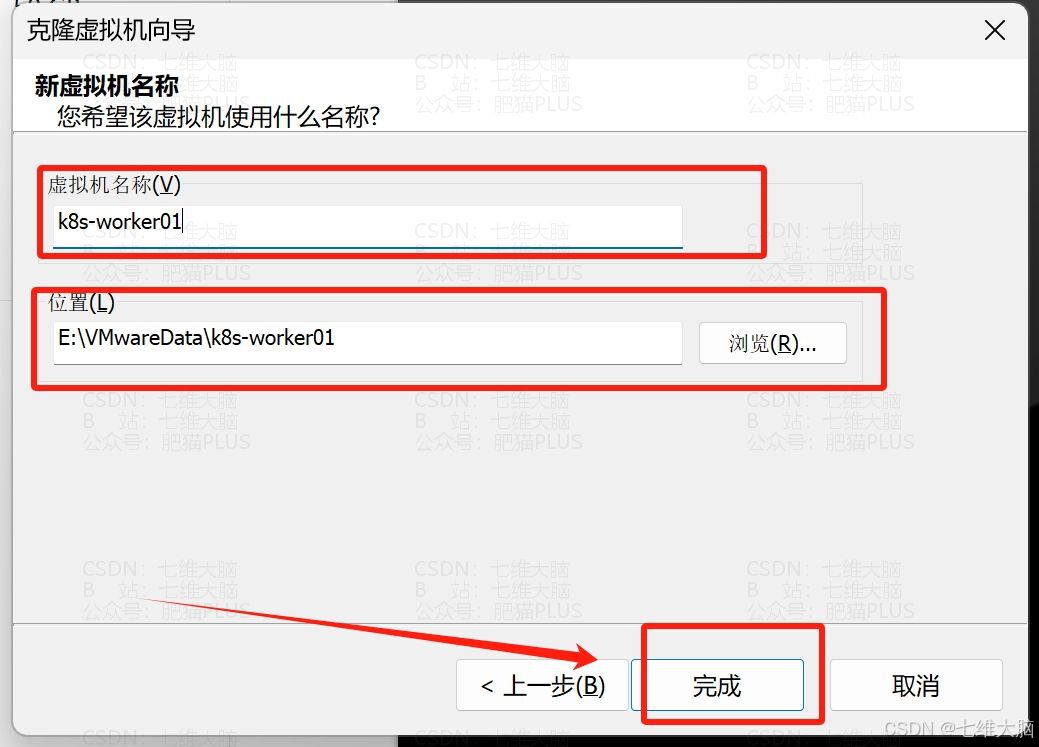
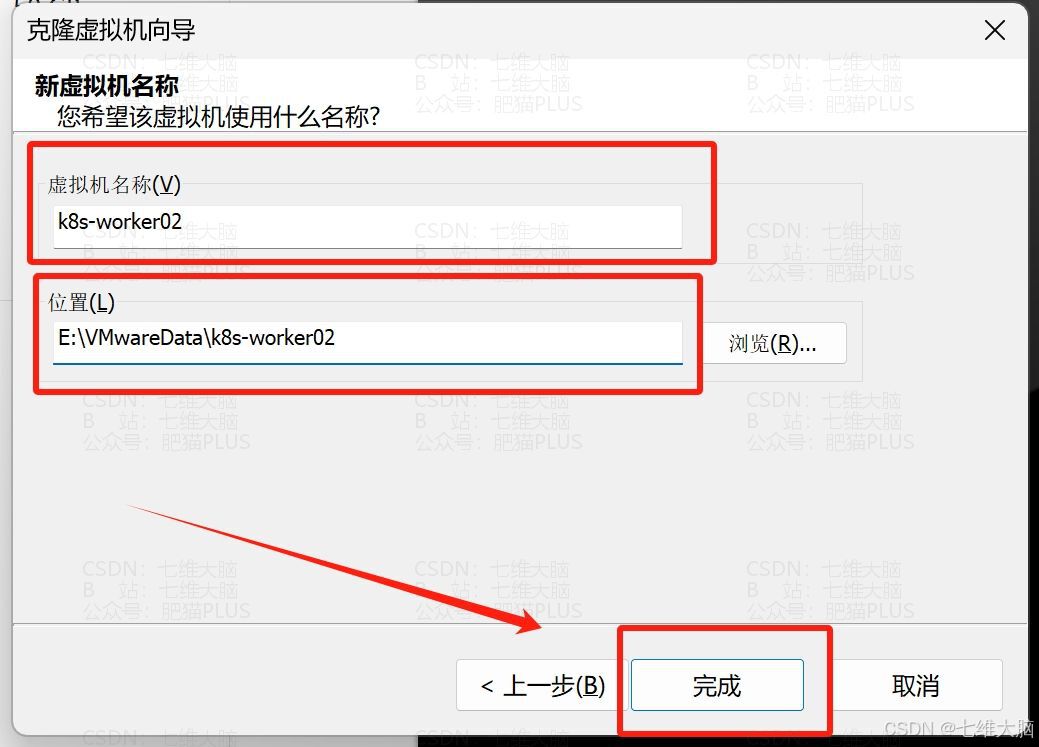
分别起名为:
- k8s-master01
- k8s-worker01
- k8s-worker02
首先执行关机命令将模板机关机:
shutdown now 然后到VMwar上,找到我们的模板机,右键 —— 管理 —— 克隆:
(三台机器克隆过程一致,唯一的区别就是起名字那块)
下面看图操作:
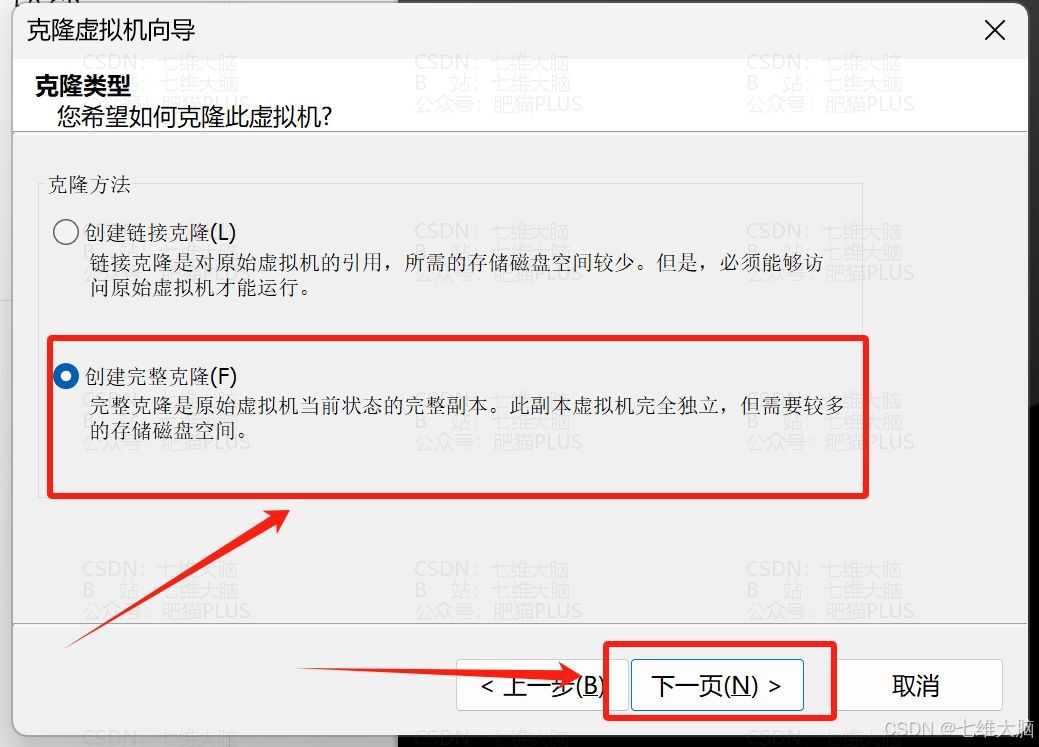
这里我直接把克隆时三台不一样的地方截图了。只有名字和位置需要改一下:
2.2 主机配置
2.2.1 修改静态IP
以下针对所有主机,每次执行操作都需要保证三台机器都执行了且没有错误。
(如果其中一台用模板机IP,只操作其余两台即可)
克隆完以后,我们要分别把刚刚克隆的三台机器开机,需要改一下静态IP地址
第一台 k8s-master01 可以不用改,我们直接用模板机的即可。k8s-worker01 和 k8s-worker02 需要改一下,不然三个主机IP一样会冲突。
温馨提示:
su - root切换root用户
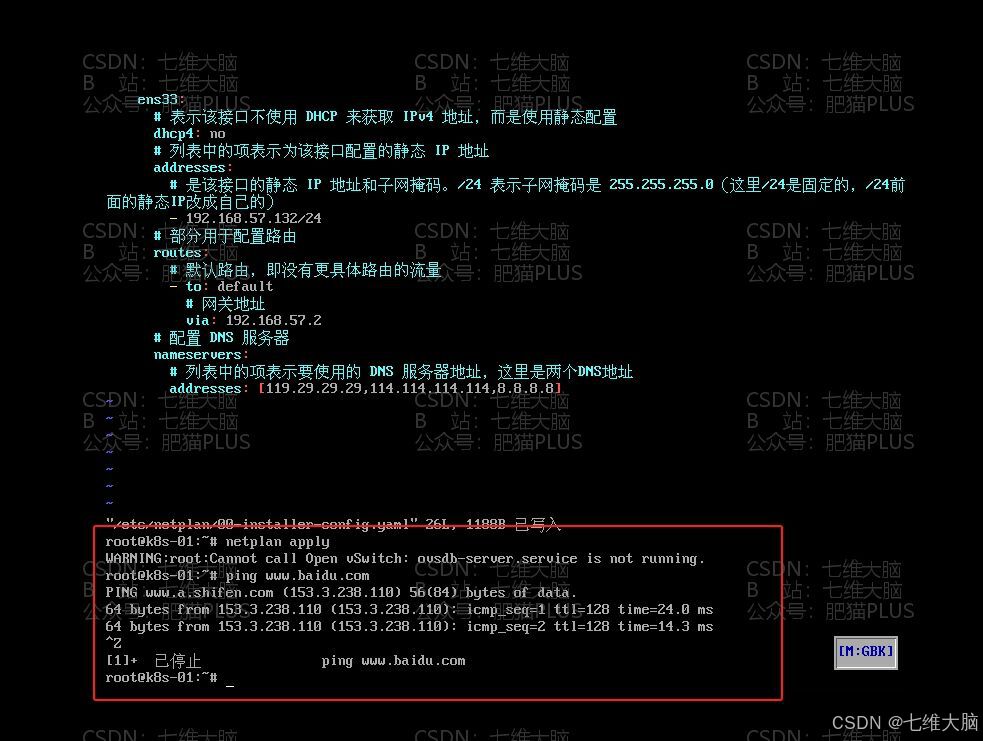
vim /etc/netplan/00-installer-config.yaml 输入以上命令,编辑网络配置文件,修改截图部分,IP的第四段部分:(只要是别的虚机没用过的都可以,我这里主节点是131,两个node节点分别是132和133)
- k8s-worker01

- k8s-worker02
修改以后保存,然后输入以下命令使配置生效:
netplan apply 生效以后,再 ping 一下 www.baidu.com,看网络是否正常,如果正常则修改成功了:
k8s-worker01
k8s-worker02
改完以后我们就可以用远程工具连接这三台主机了:
2.2.2 修改主机名
以下针对所有主机,每次执行操作都需要保证三台机器都执行了且没有错误。
- k8s-master01
hostnamectl set-hostname k8s-master01 
- k8s-worker01
hostnamectl set-hostname k8s-worker01 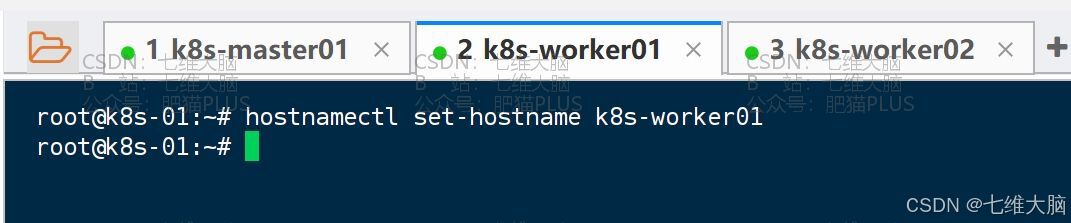
- k8s-worker02
hostnamectl set-hostname k8s-worker02 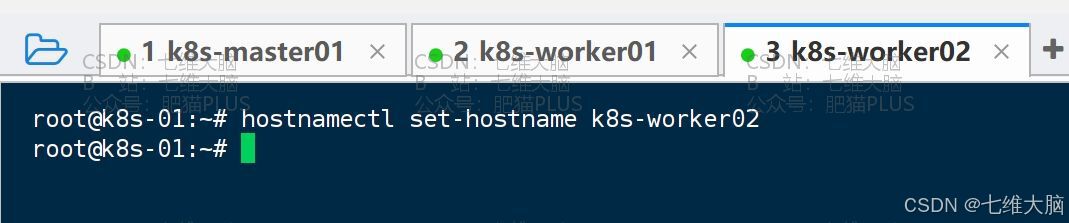
最后我们重新切换一下 root 账户,让显示生效:
(这里我就不截图了,太简单了。)
先输入以下命令退出 root 账户:
exit 然后重新切换到 root 账户:
su - root 2.2.3 主机名-IP地址解析
以下针对所有主机,每次执行操作都需要保证三台机器都执行了且没有错误。
我们到 finalshell 中,在下方切换到 命令,然后最下面下拉框更改为 全部会话:(这样的话我们就可以直接将一条命令同步发送给三台主机了)
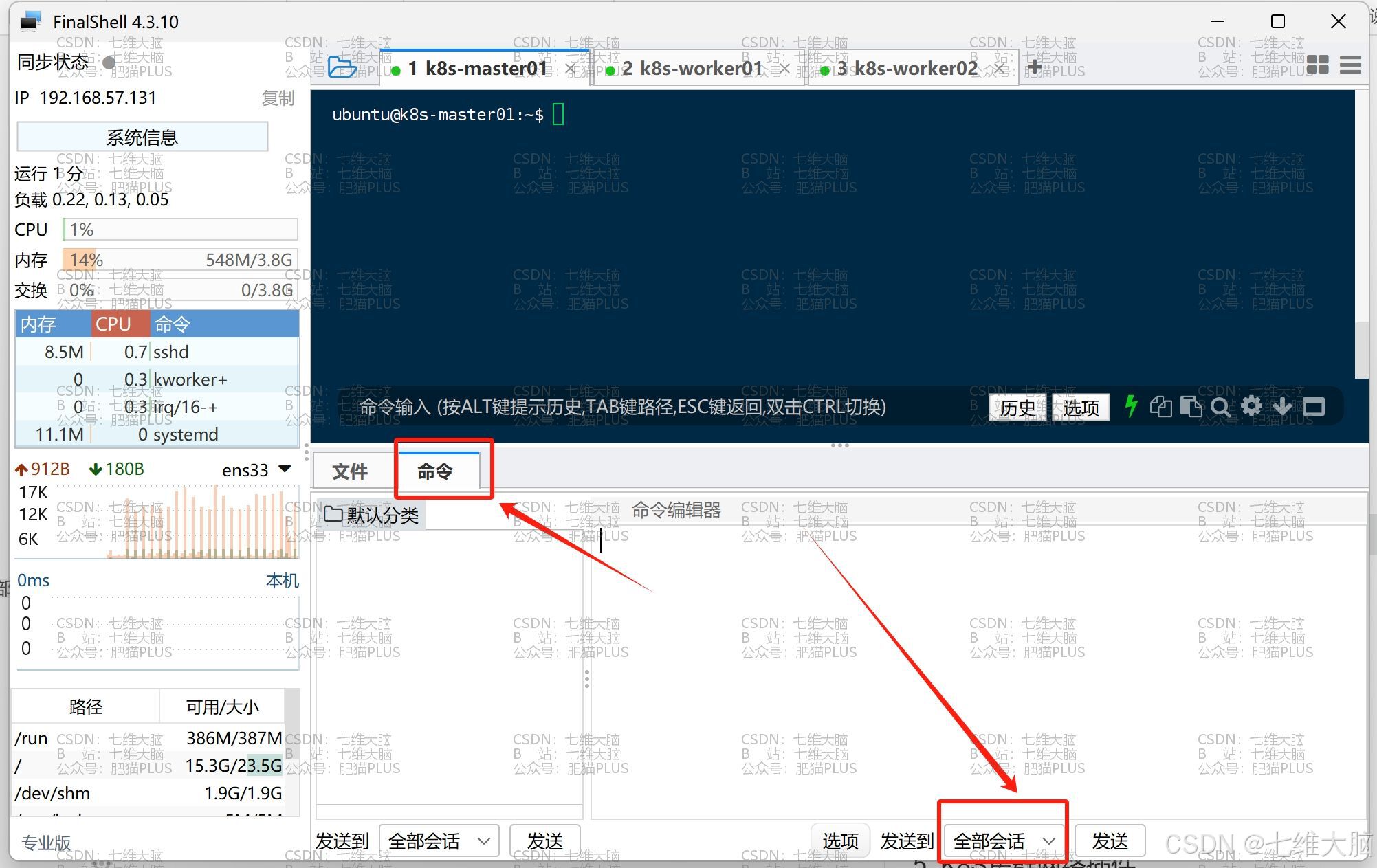
然后在 命令编辑器 输入以下命令后,点击 发送:
cat >> /etc/hosts << EOF 192.168.57.131 k8s-mater01 192.168.57.132 k8s-worker01 192.168.57.133 k8s-worker02 EOF 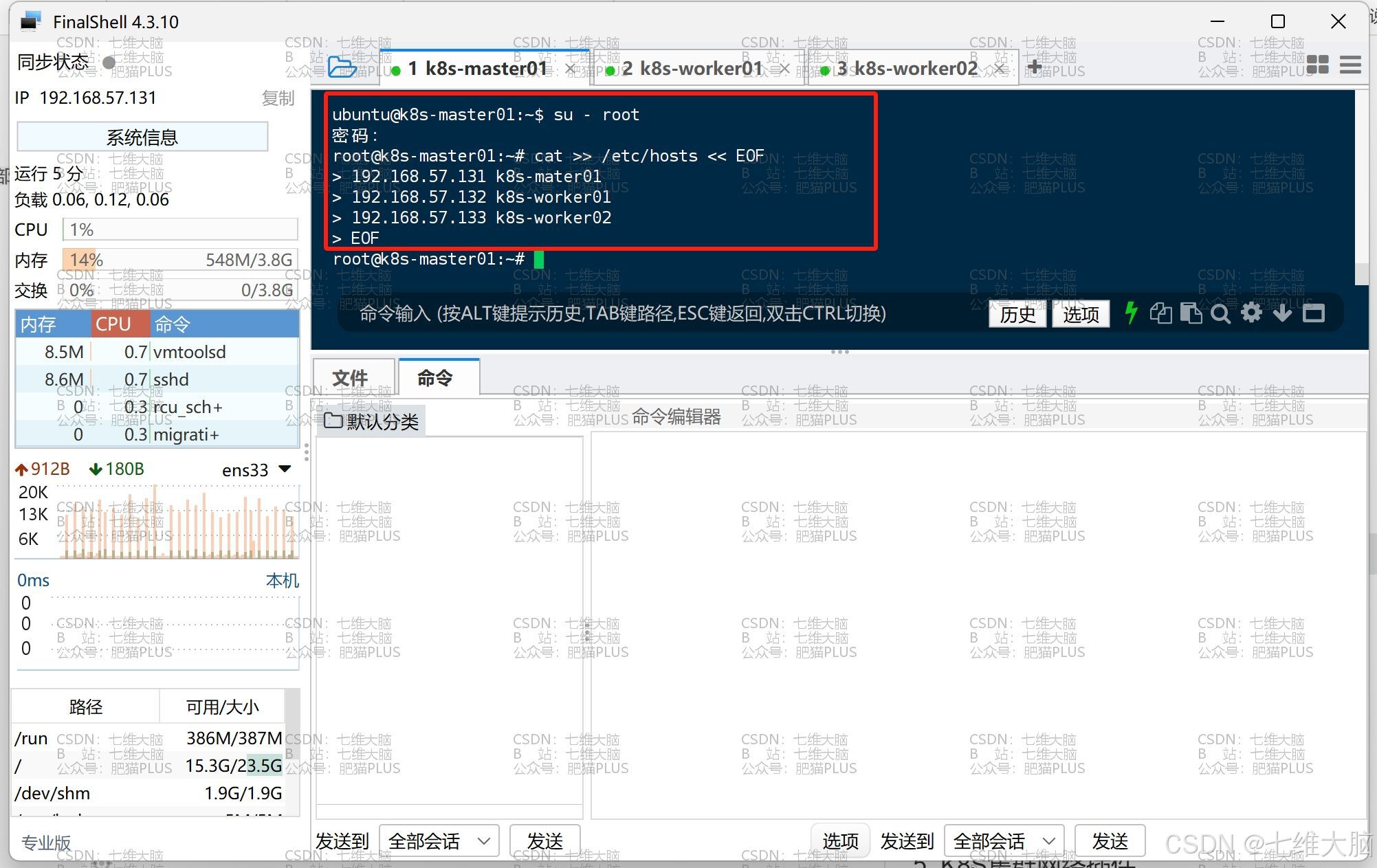
执行完以后,我们可以验证一下是否添加成功:(三个主机都看一眼)
cat /etc/hosts 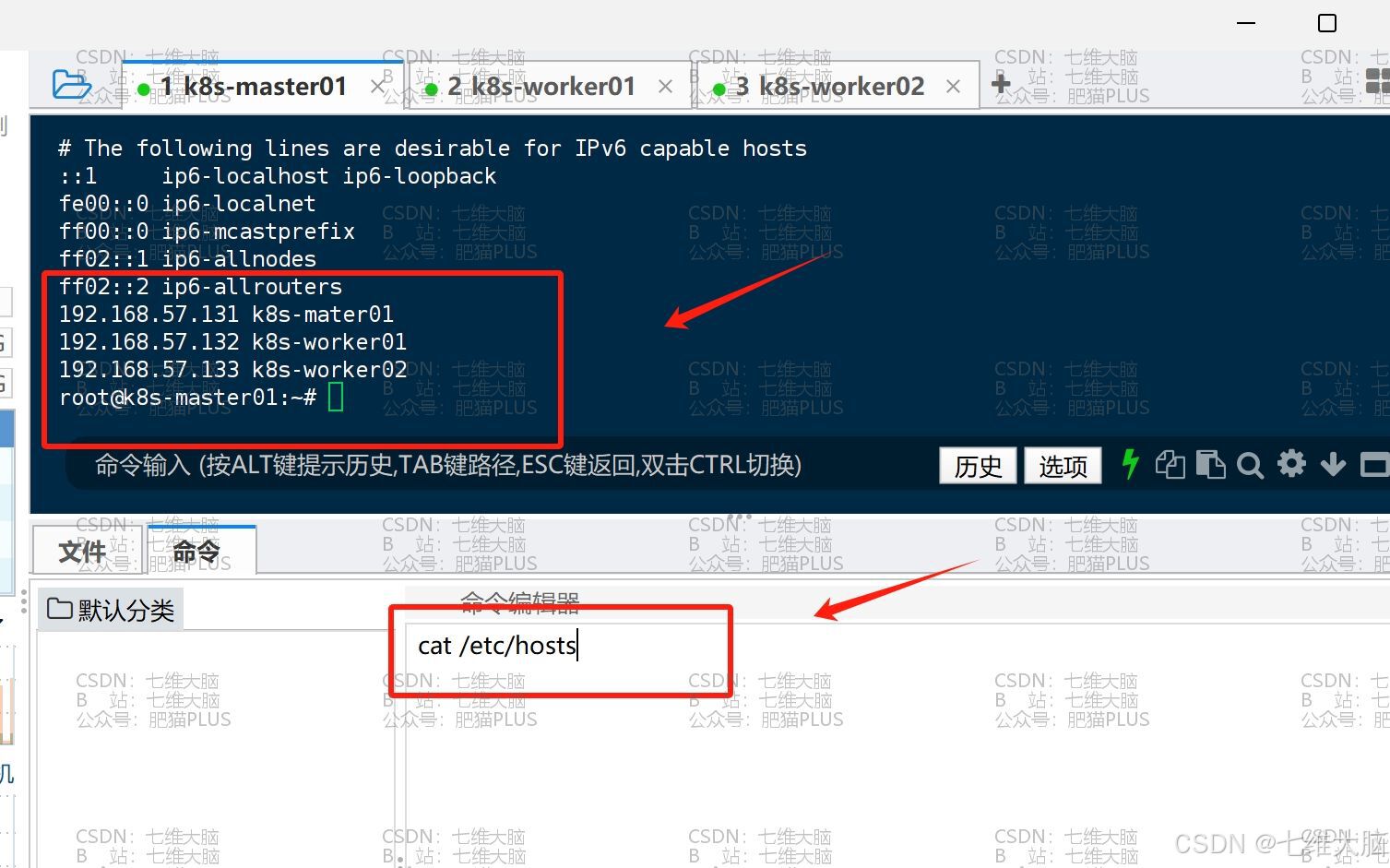
2.2.4 时间同步
以下针对所有主机,每次执行操作都需要保证三台机器都执行了且没有错误。
- 更换时区
timedatectl set-timezone Asia/Shanghai 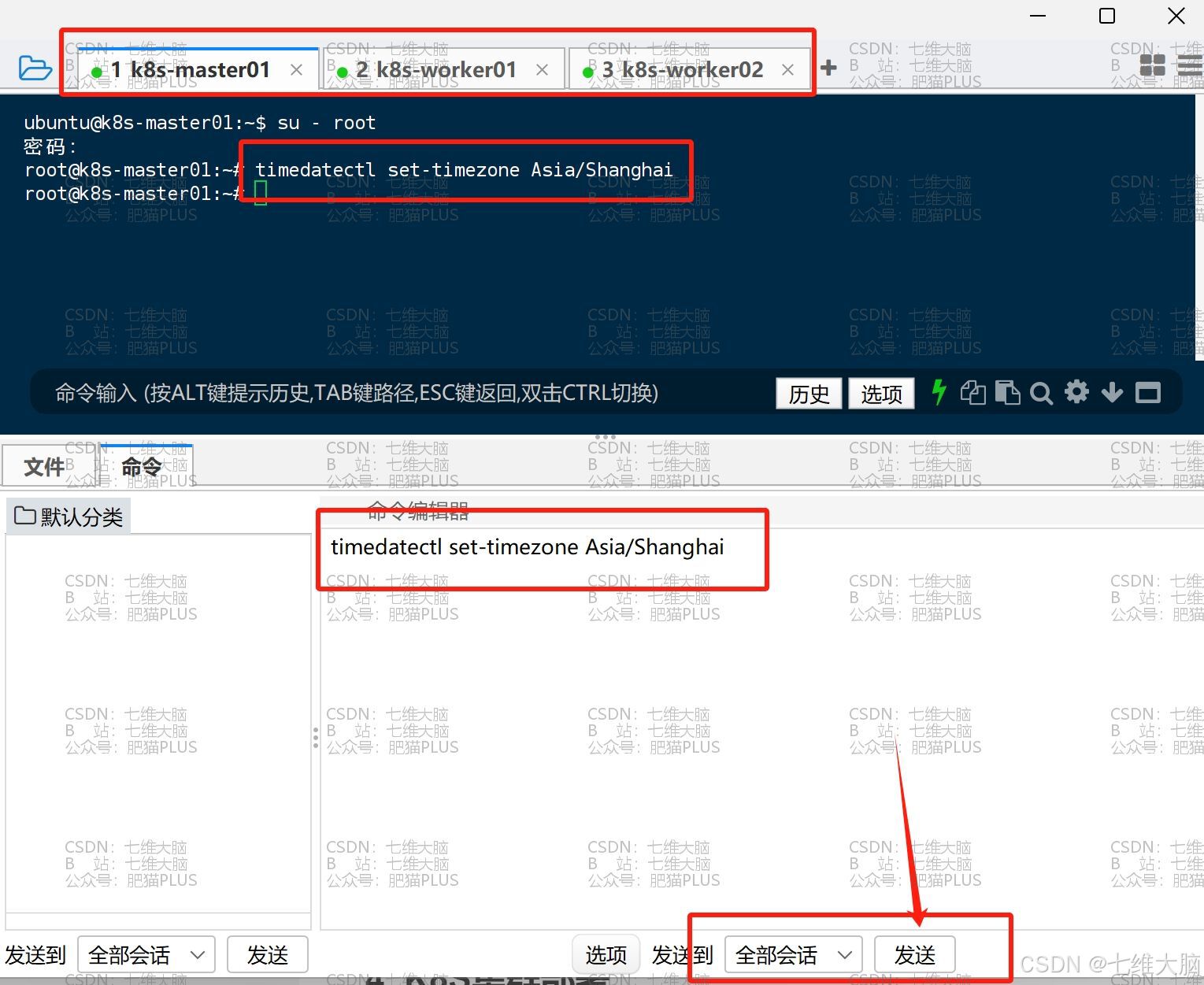
- 安装ntpdate
apt-get install ntpdate 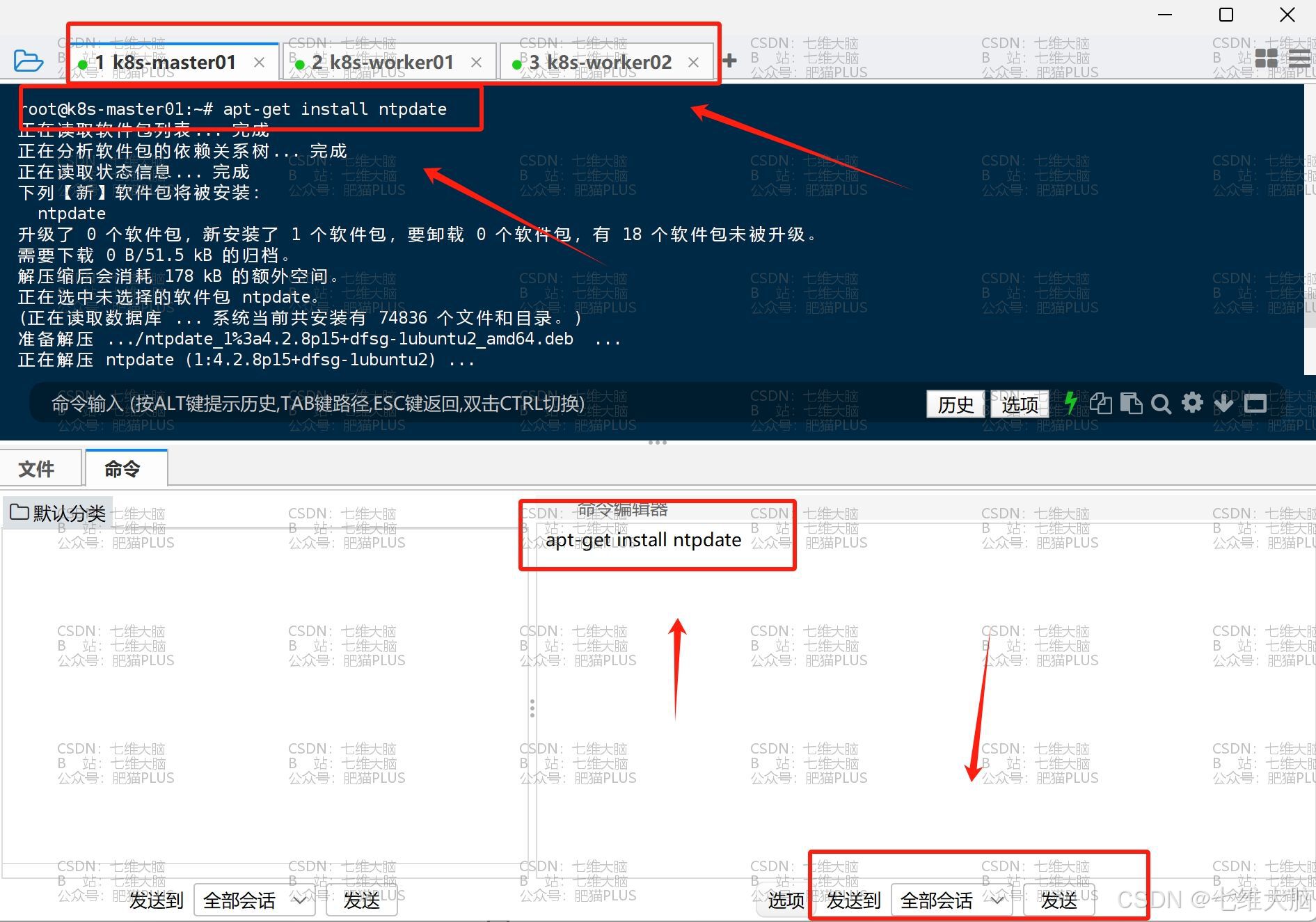
- 使用ntpdate命令同步时间
ntpdate time1.aliyun.com 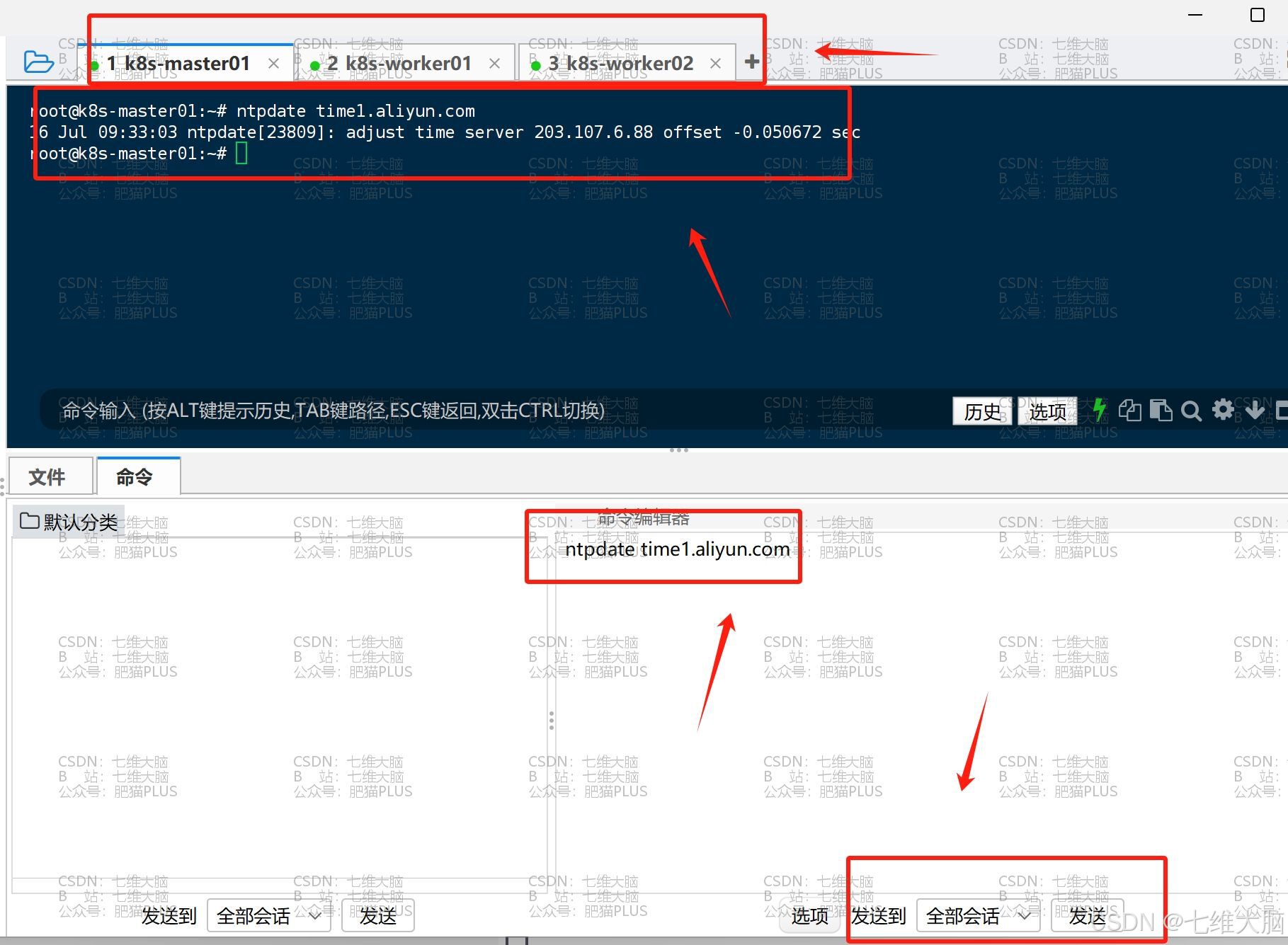
- 通过计划任务实现同步时间
crontab -e 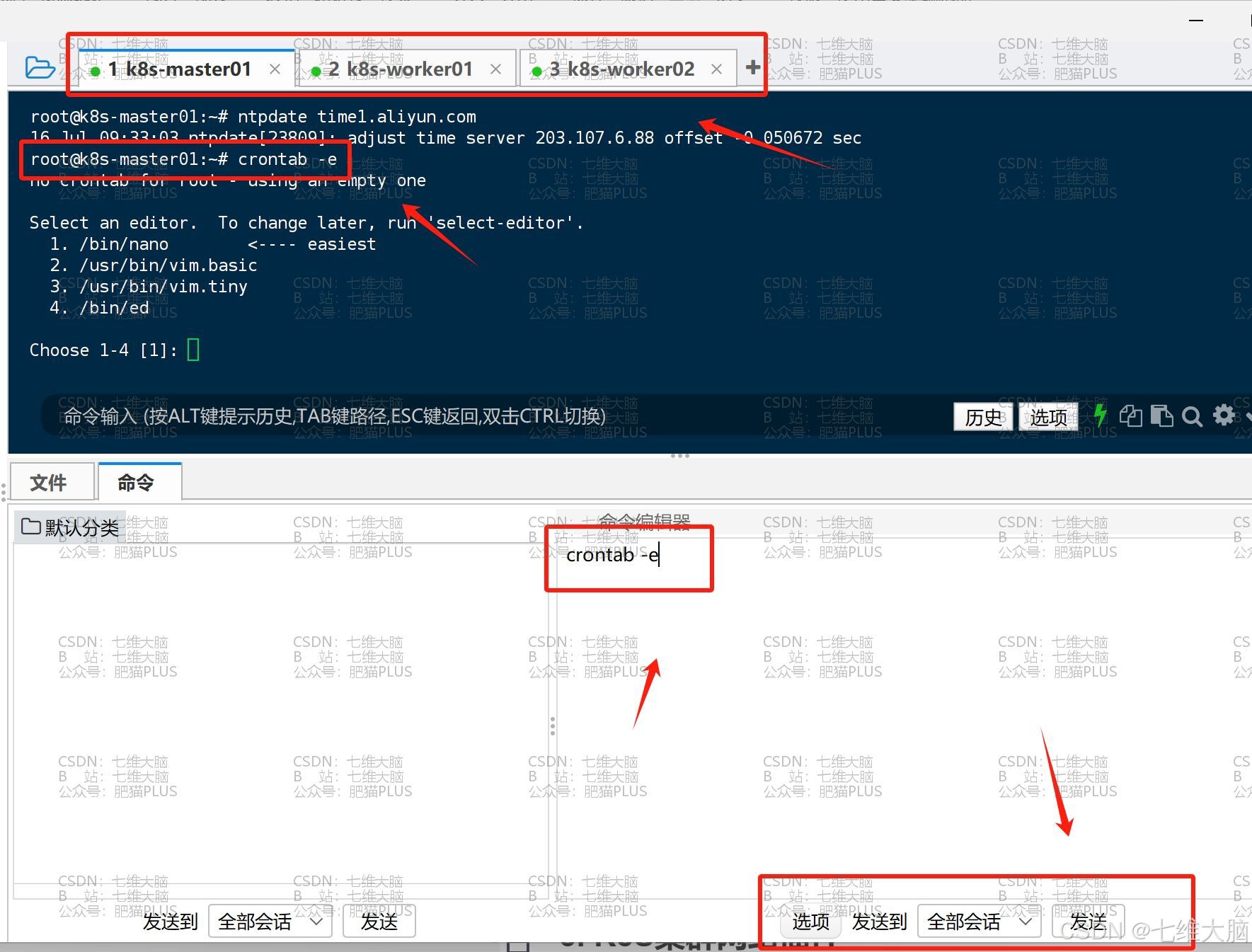
然后这里选择输入 2 :
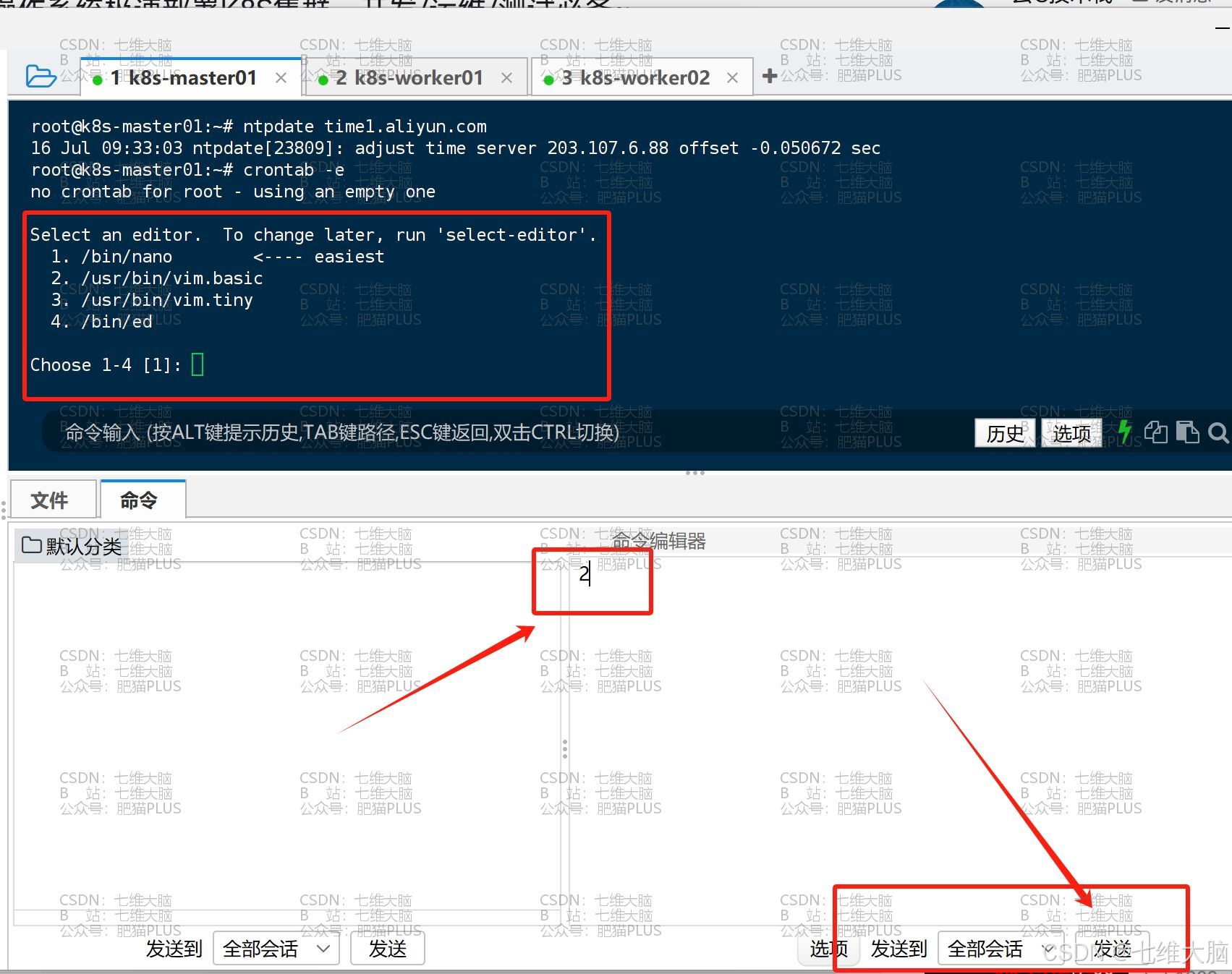
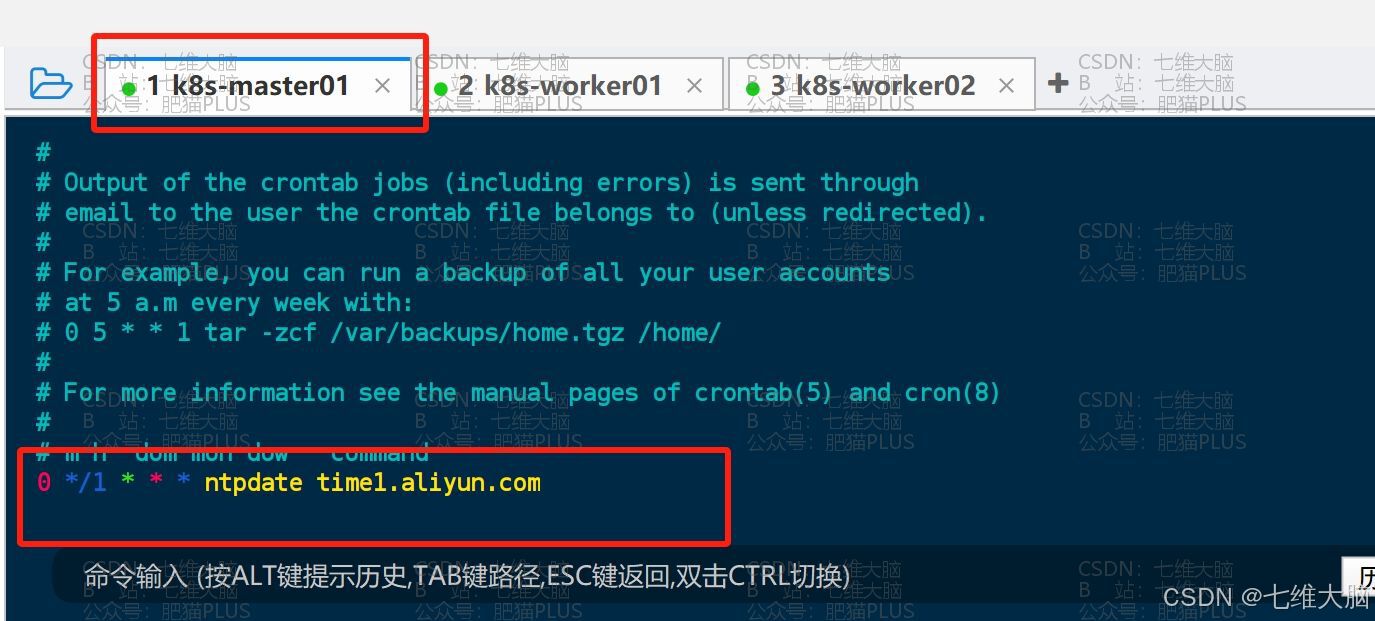
然后在这个文件的最后一行加入下方的cron表达式:(每个主机都要加!!!)
0 */1 * * * ntpdate time1.aliyun.com k8s-master01
k8s-worker01
k8s-worker02
2.2.5 内核转发、网桥过滤配置
以下针对所有主机,每次执行操作都需要保证三台机器都执行了且没有错误。
配置依赖模块到 /etc/modules-load.d/k8s.conf ,后期可开机自动加载:
cat << EOF | tee /etc/modules-load.d/k8s.conf overlay br_netfilter EOF 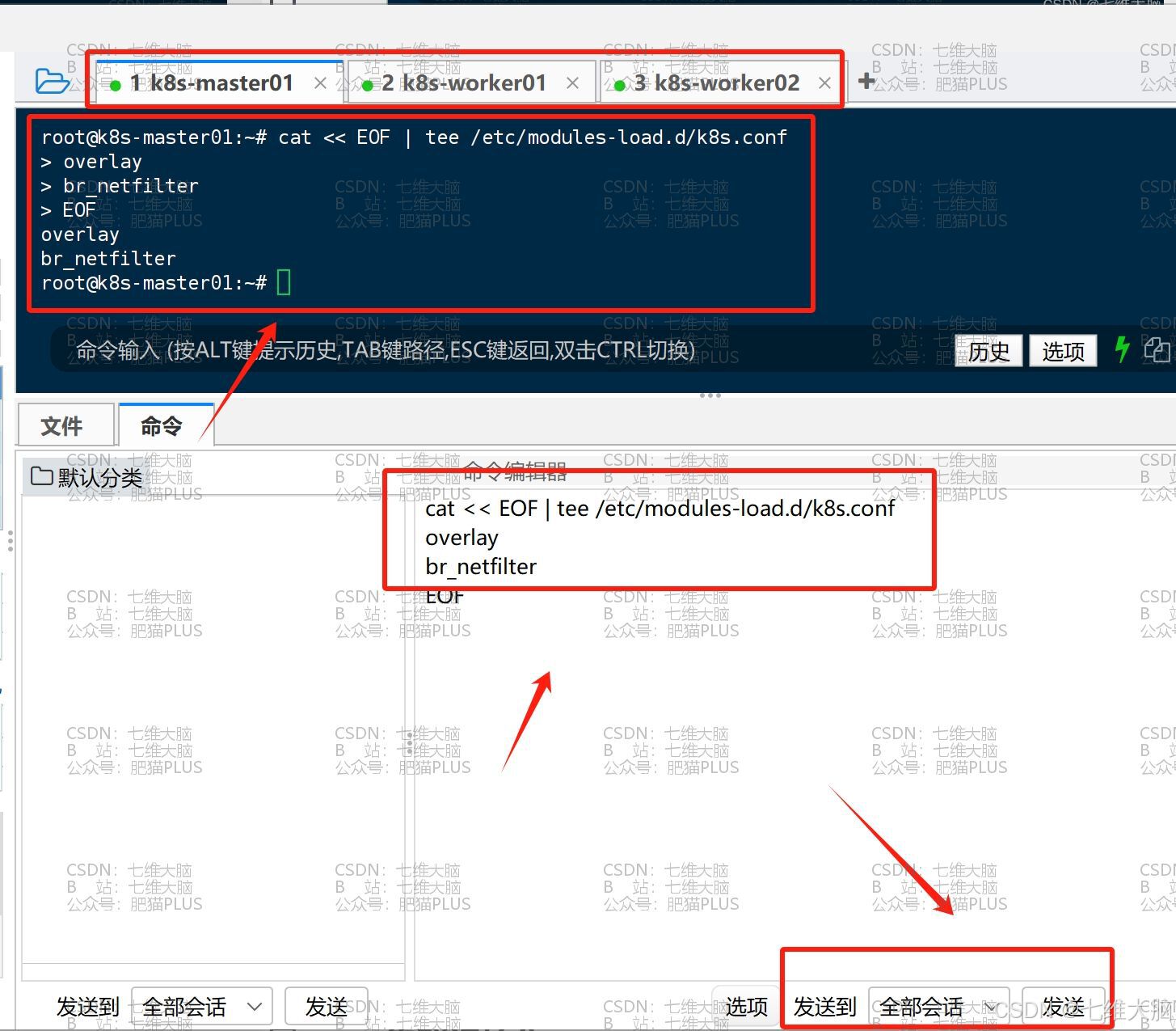
上面只是开机自动加载,但我们本次还需要用,所以使用下面两条命令进行启用:
modprobe overlay modprobe br_netfilter 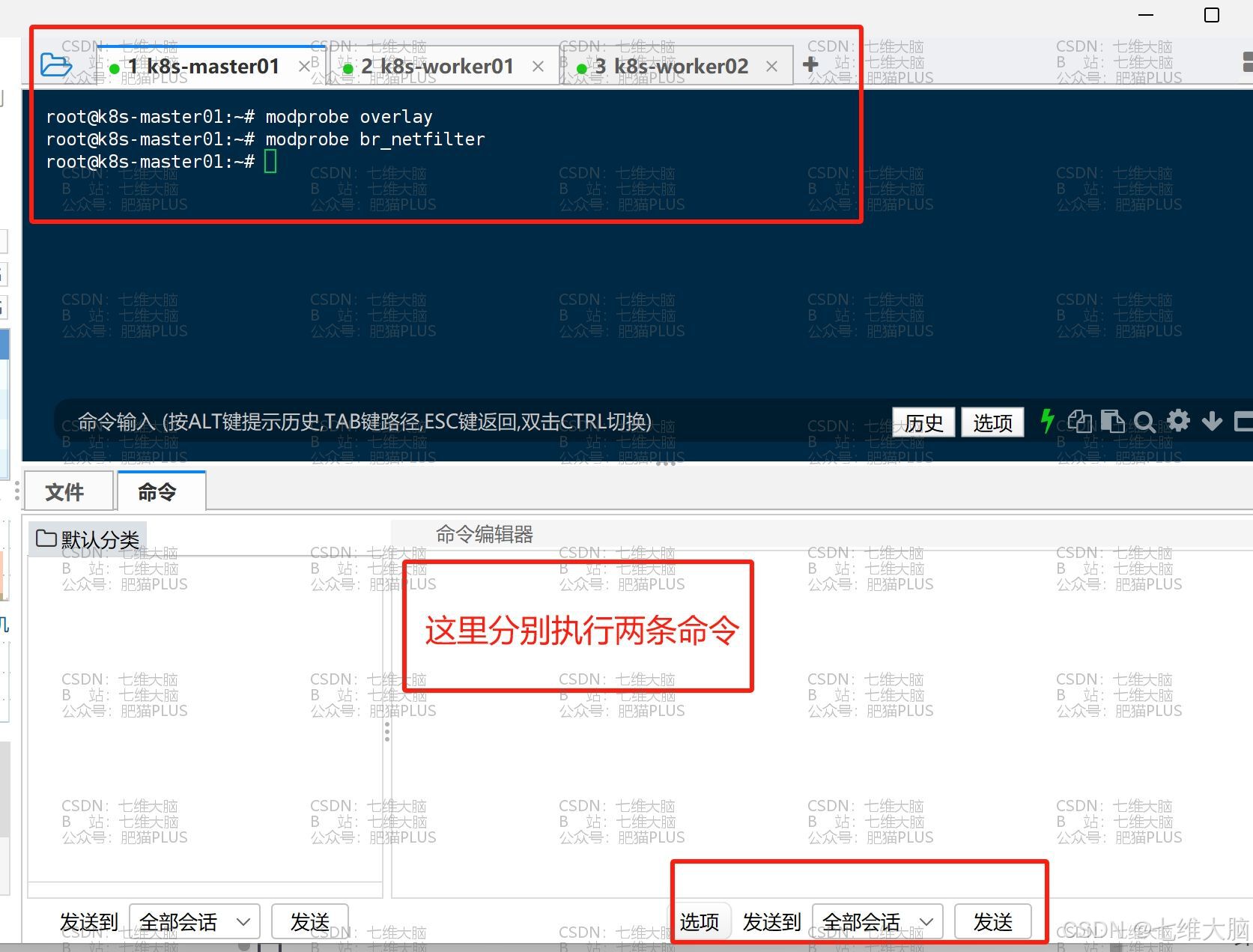
启用完以后,我们可以用下方命令查看是否成功:
lsmod | egrep "overlay" lsmod | egrep "br_netfilter" 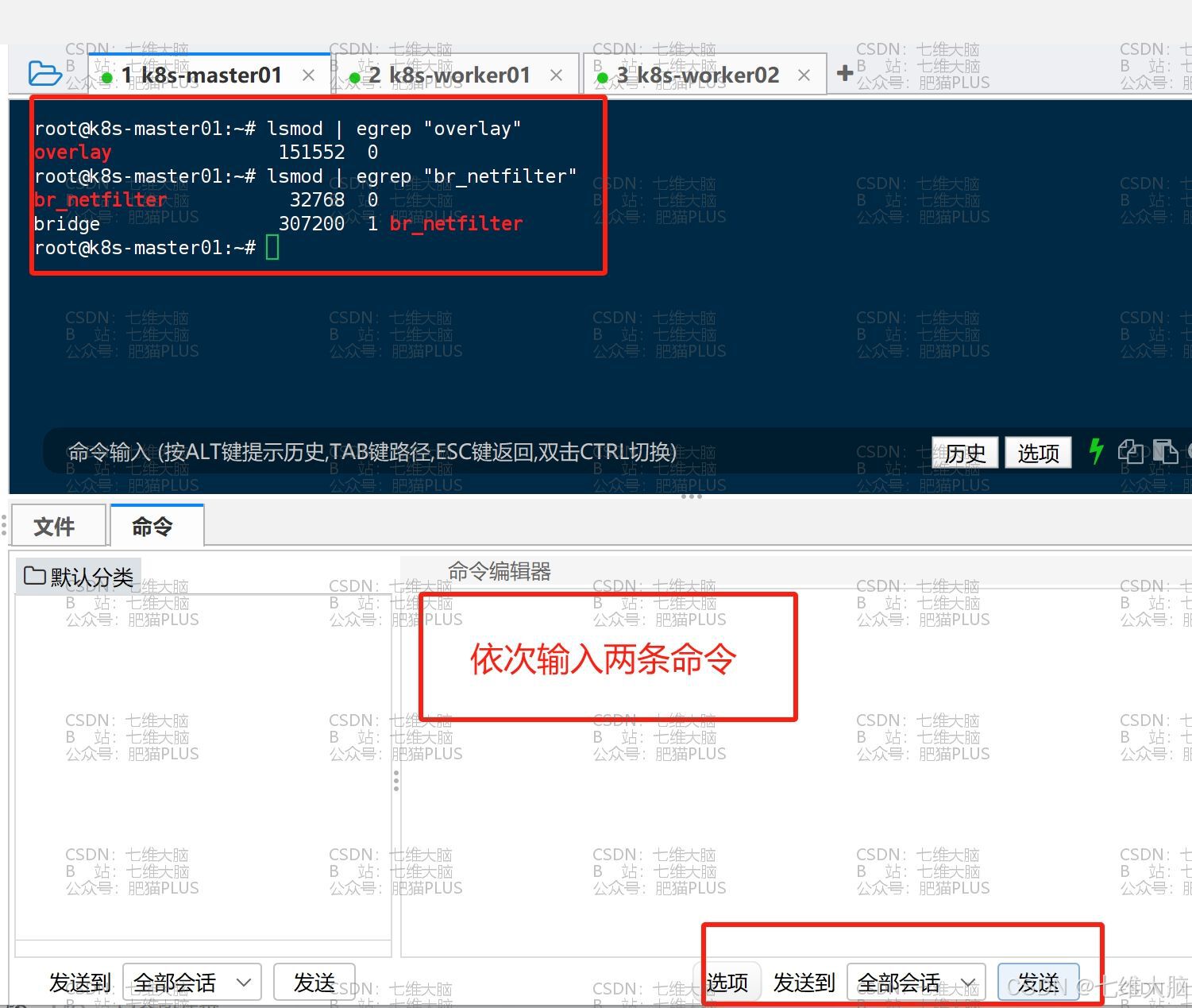
然后我们把网桥过滤和内核转发追加到 k8s.conf 文件中:
cat << EOF | tee /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 EOF 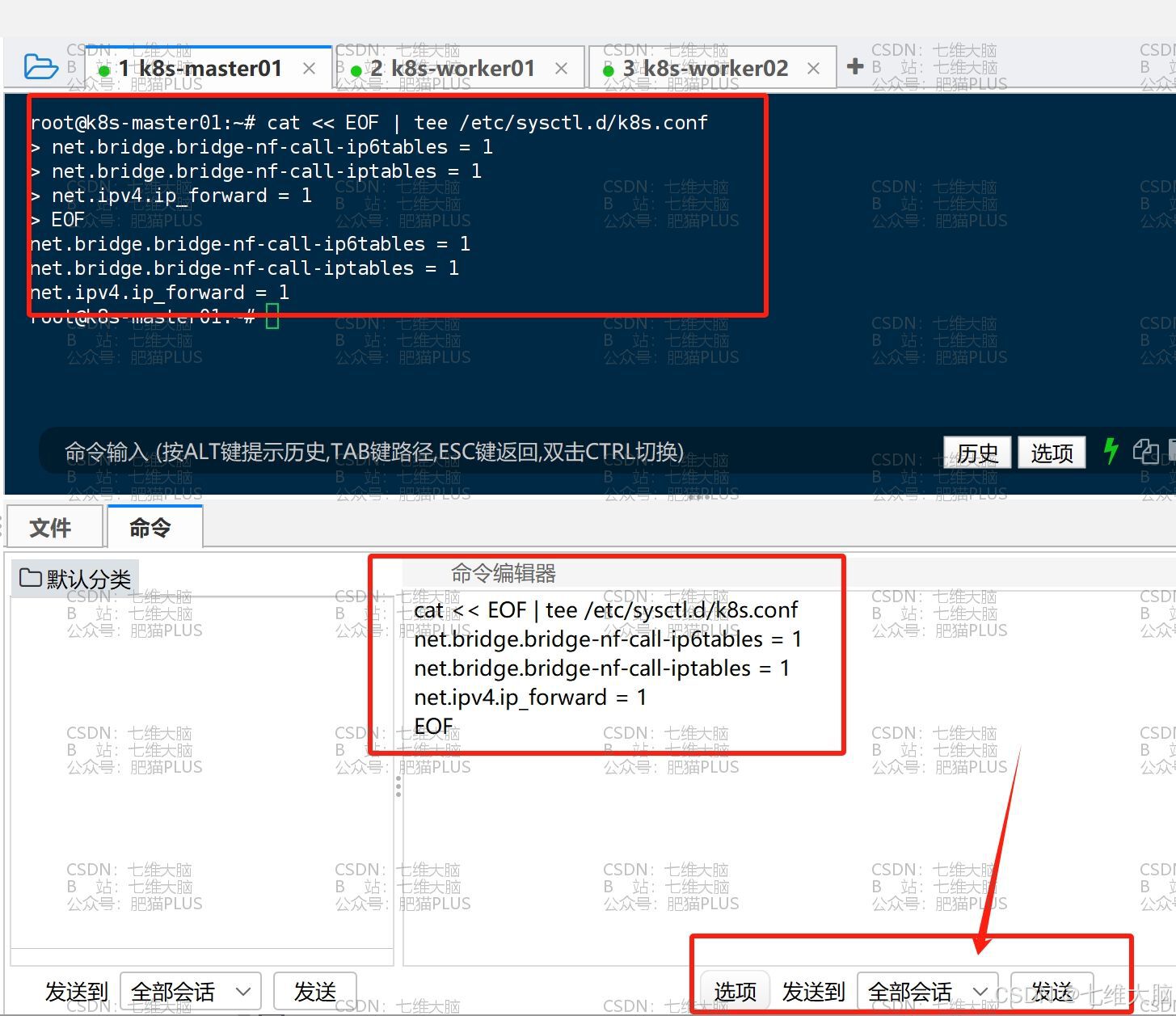
最后我们加载内核参数:
sysctl --system 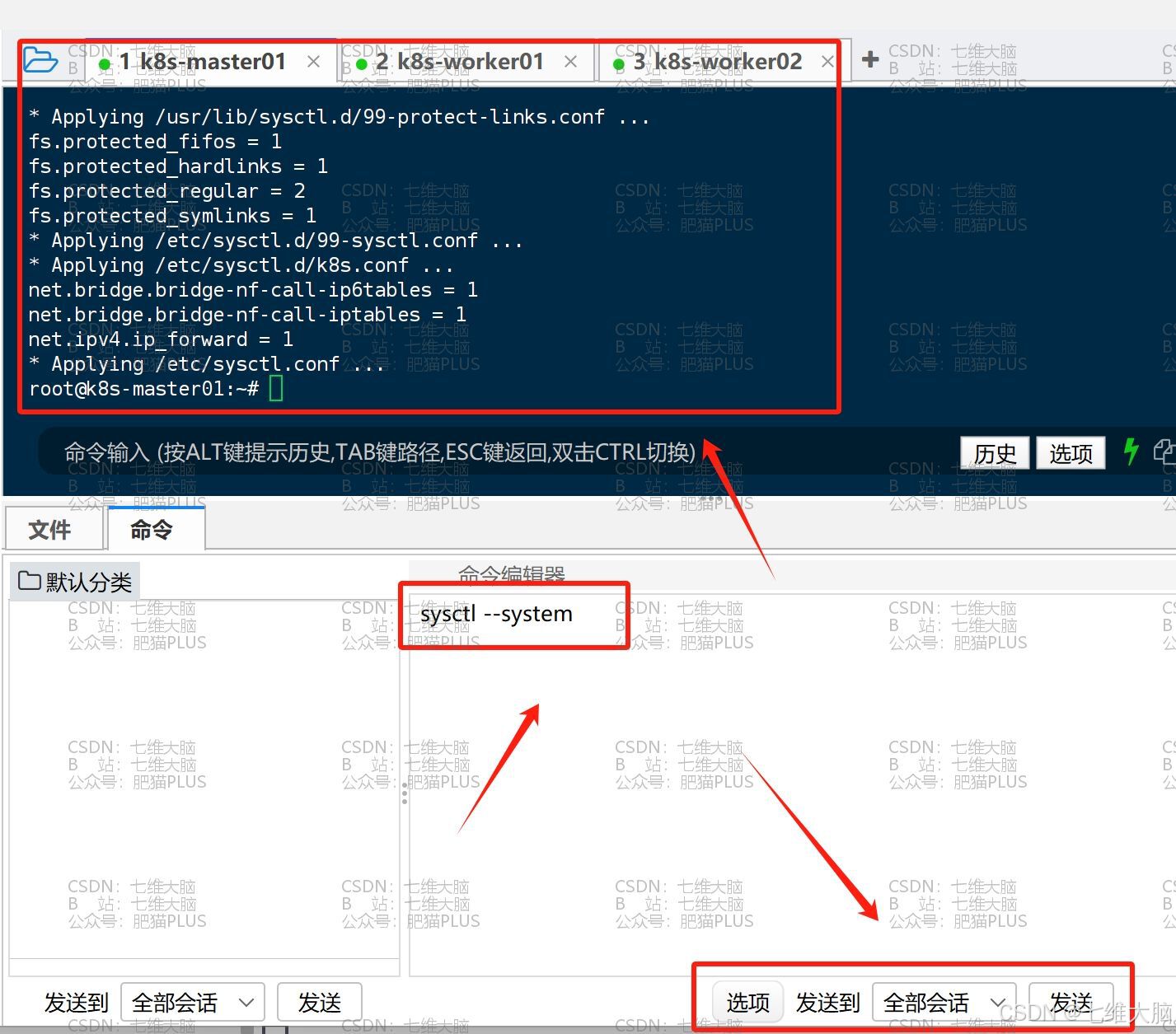
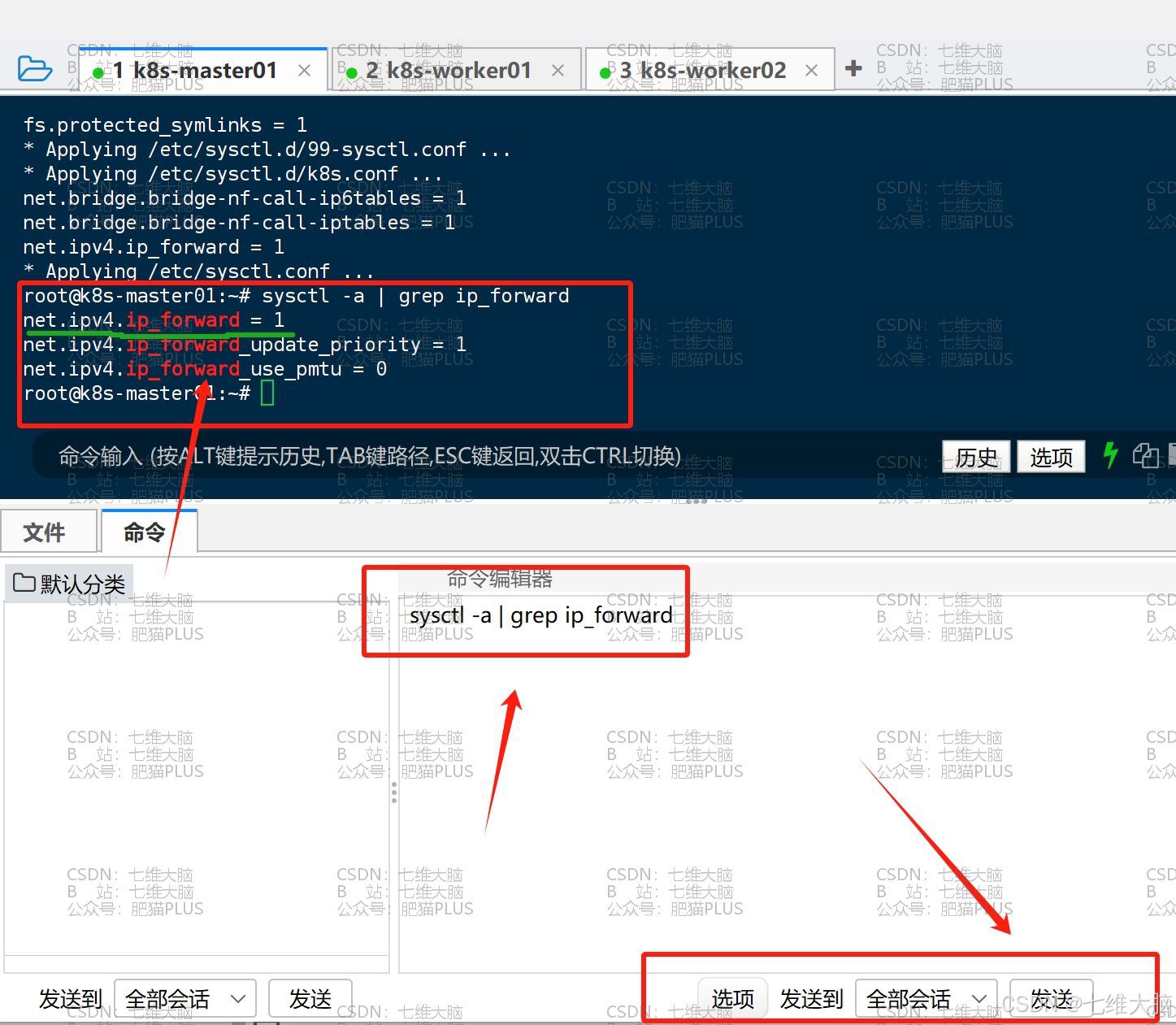
加载完成后,我们可以用下方命令看下内核的路由转发有没有成功打开:
sysctl -a | grep ip_forward 变成 1 了,说明成功了:
2.2.6 安装ipset和ipvsadm
以下针对所有主机,每次执行操作都需要保证三台机器都执行了且没有错误。
首先安装 ipset 和 ipvsadm :
(我们后续使用一些负载均衡器的时候需要用到,这个配置是一定要做的)
apt-get install ipset ipvsadm 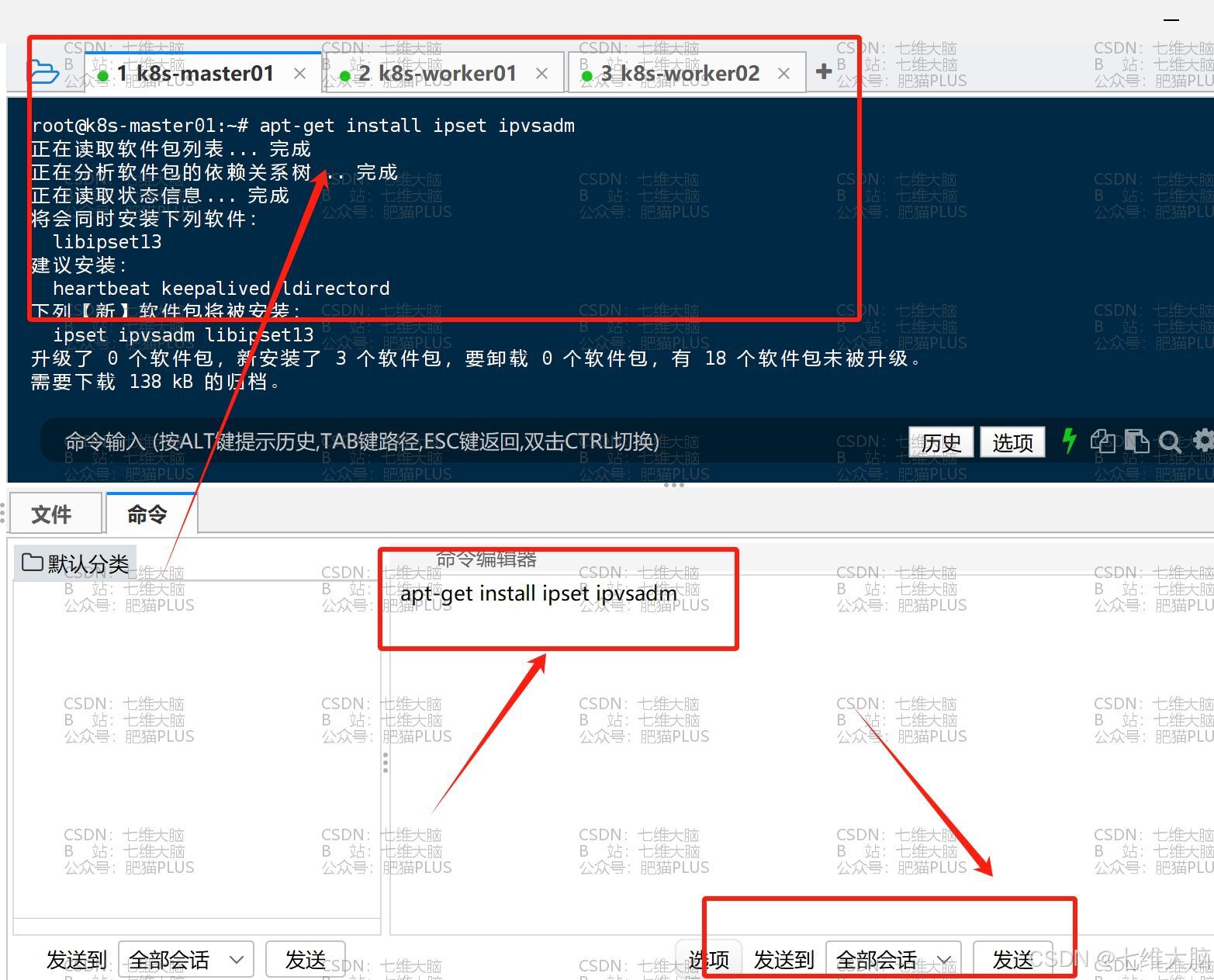
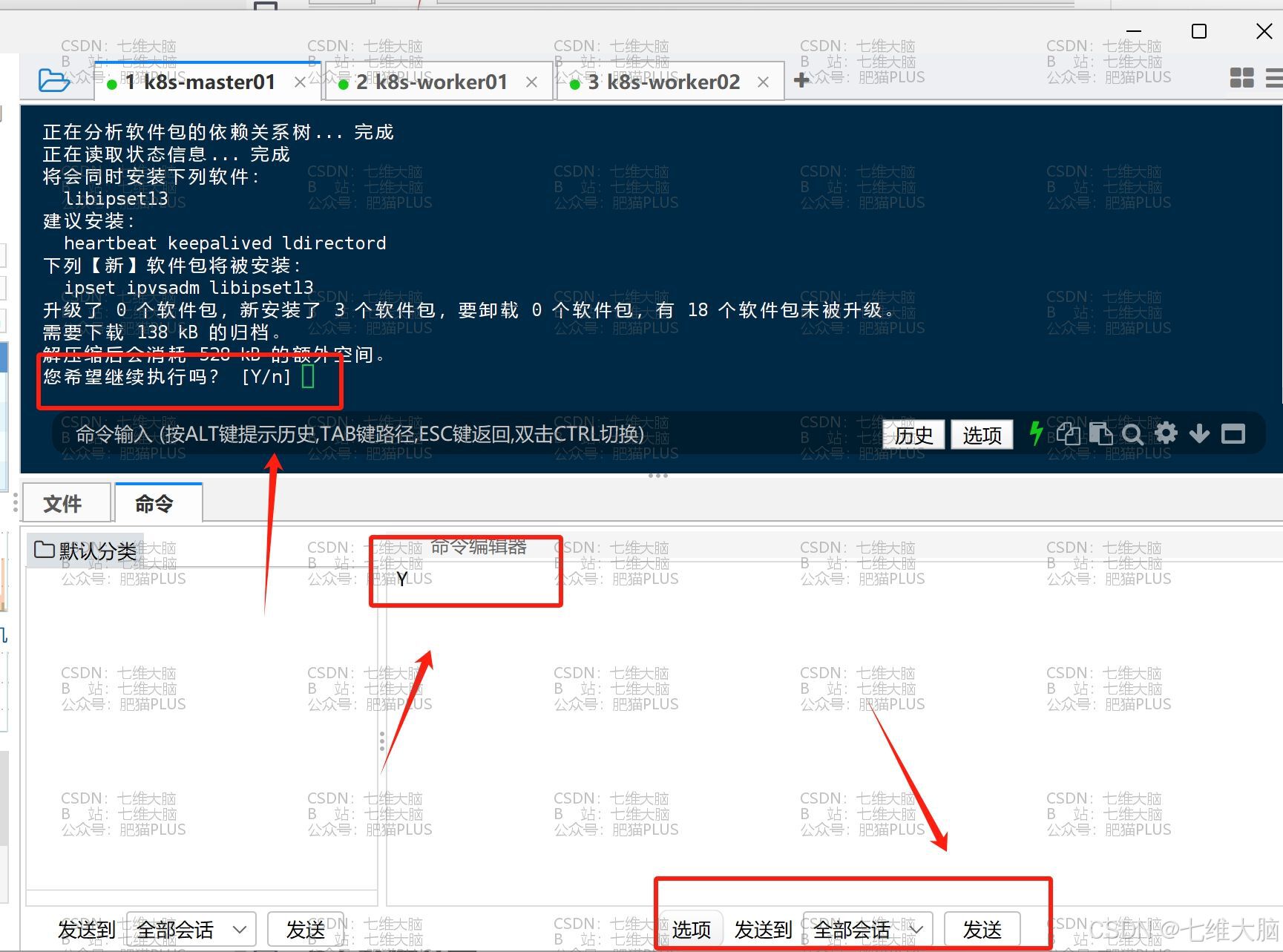
中间会让你输入一次 Y 确认,我们直接输入发送即可:
安装完成后,我们需要配置 ipvsadm 模块加载,添加需要加载的模块:(这样我们后续开机就可以自动加载了)
cat << EOF | tee /etc/modules-load.d/ipvs.conf ip_vs ip_vs_rr ip_vs_wrr ip_vs_sh nf_conntrack EOF 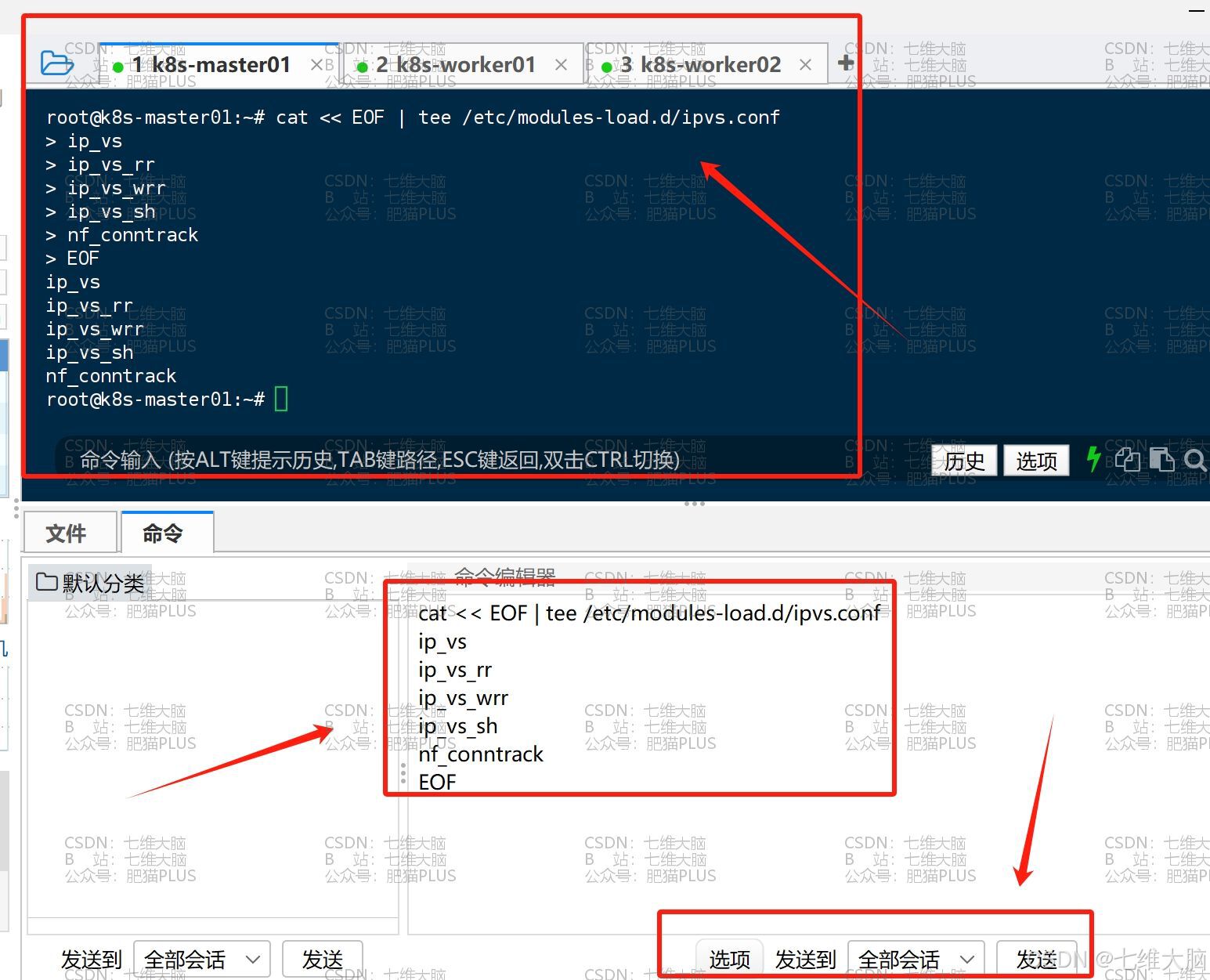
上面只是开机自动加载,但我们本次还需要用,所以我们本次要用的话可以将生效命令放到一个脚本文件中,然后执行他:
cat << EOF | tee ipvs.sh #!/bin/sh modprobe -- ip_vs modprobe -- ip_vs_rr modprobe -- ip_vs_wrr modprobe -- ip_vs_sh modprobe -- nf_conntrack EOF 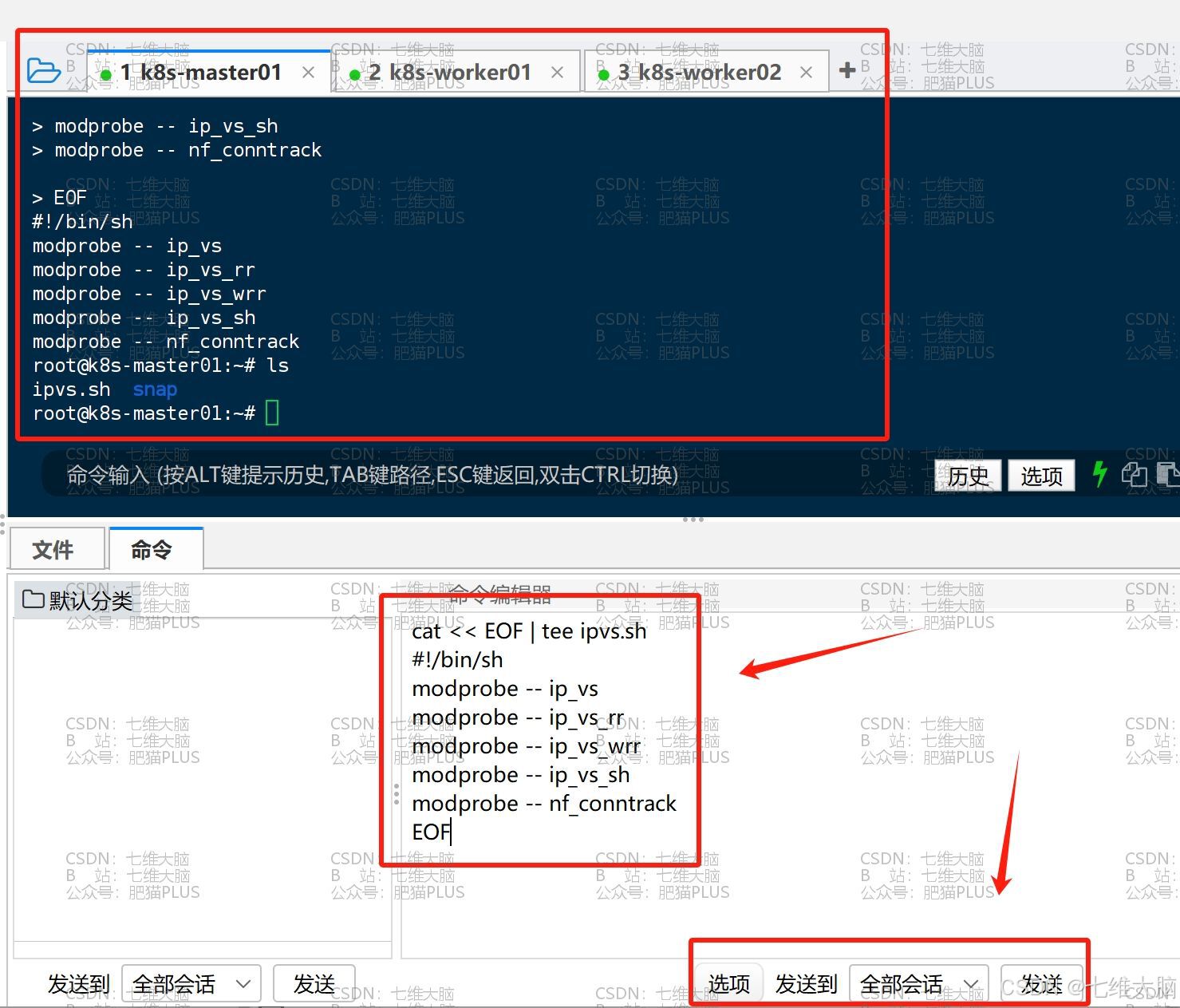
执行我们刚刚创建的脚本文件:
sh ipvs.sh 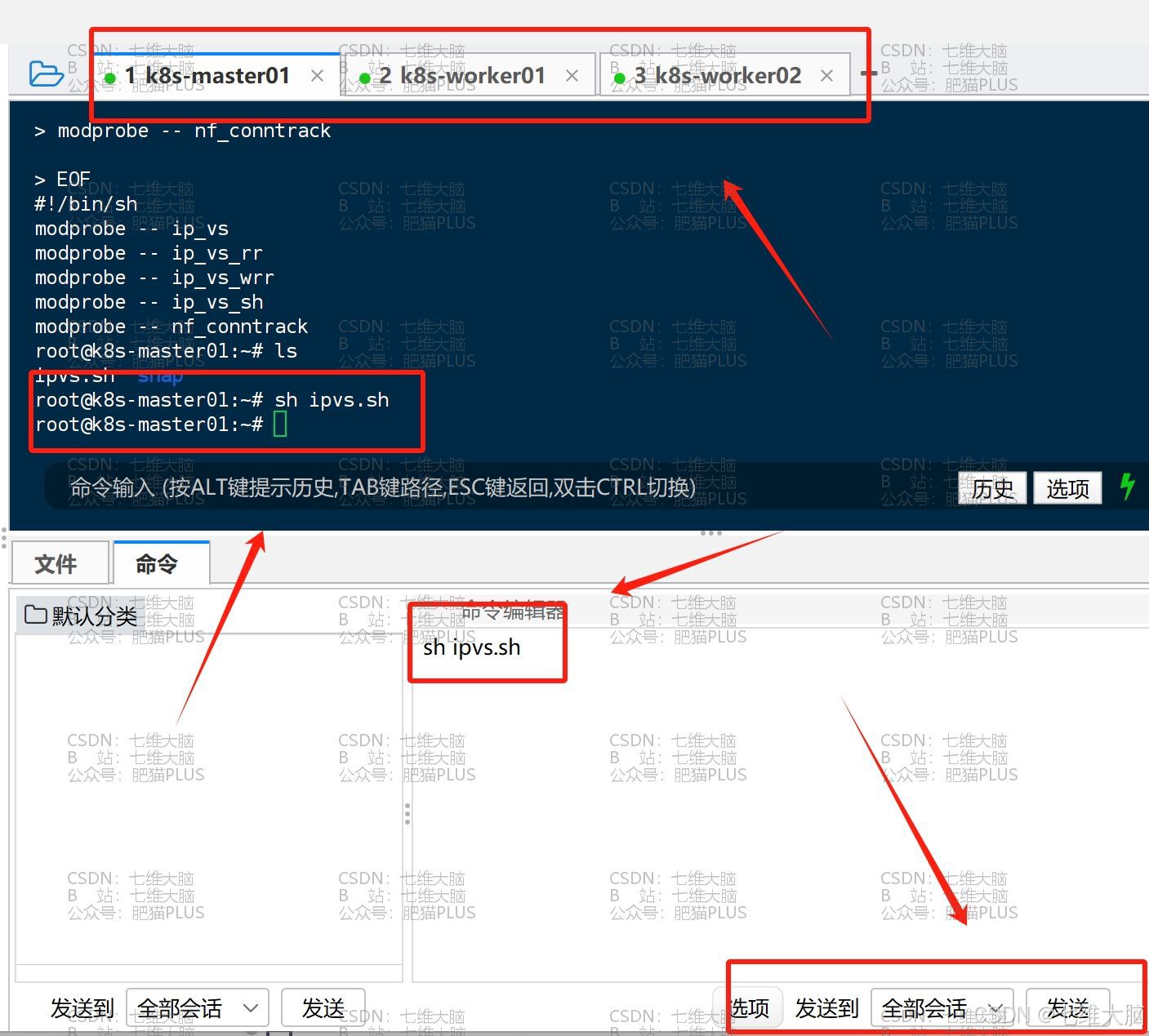
我们可以用以下命令查看是否已经加载:
lsmod | grep ip_vs 如下图所示,可以看到都加载进来了:
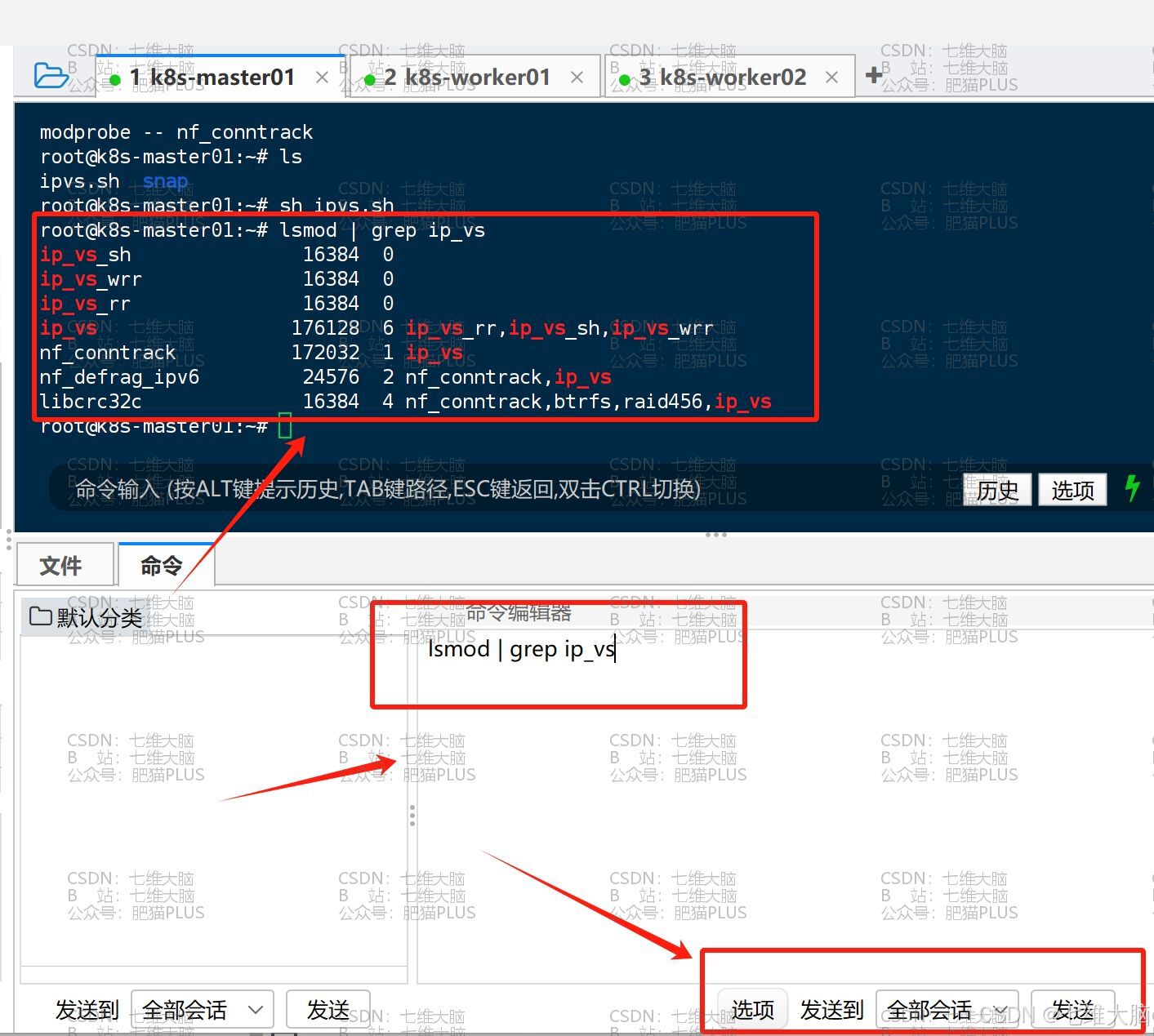
2.2.7 关闭SWAP分区
以下针对所有主机,每次执行操作都需要保证三台机器都执行了且没有错误。
虽然教程版本的k8s集群,也就是 1.28,说是可以使用node上的 SWAP 分区,但在初始化的时候还是会出现报错,所以,我们还是需要关闭 SWAP 分区。
永久关闭 SWAP 分区:(重启系统才会生效)
用 vim 打开 /etc/fstab
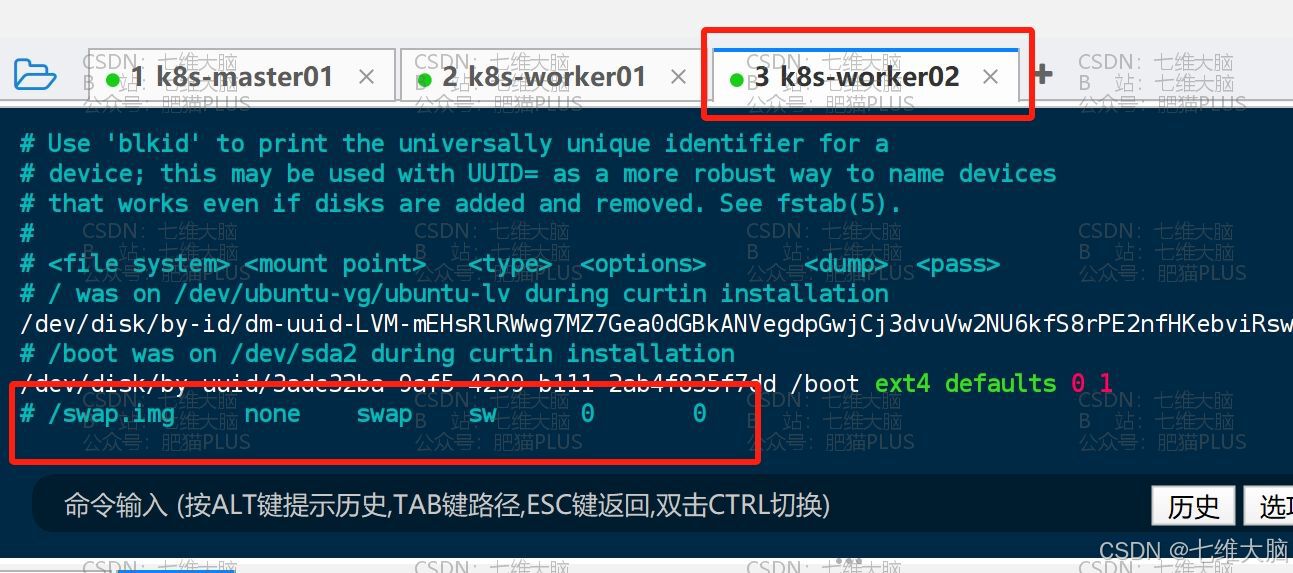
vim /etc/fstab 打开后找到 /swap.img none swap sw 0 0 这一行,给注释掉:(三台主机都需要操作)
k8s-master01
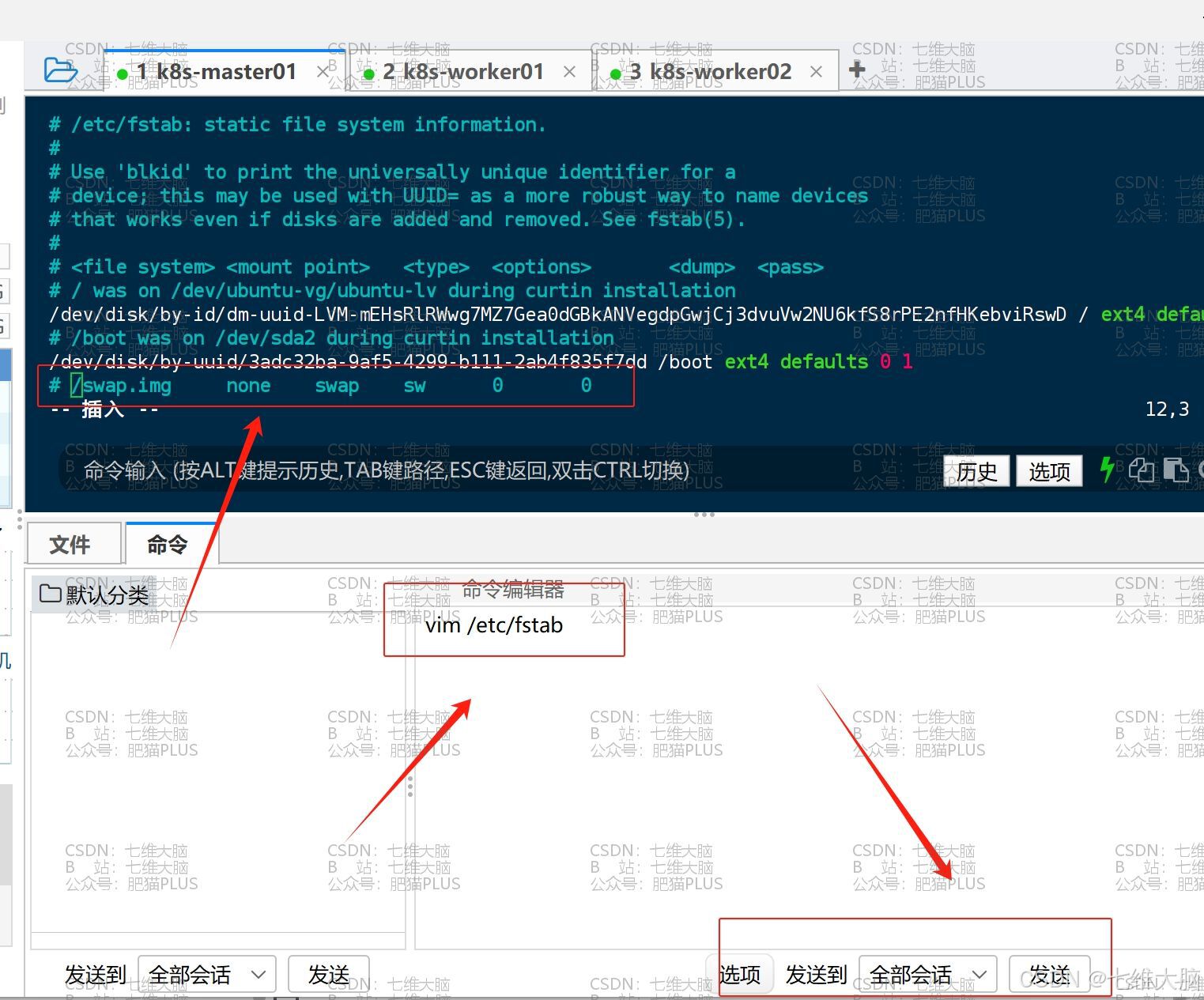
k8s-worker01
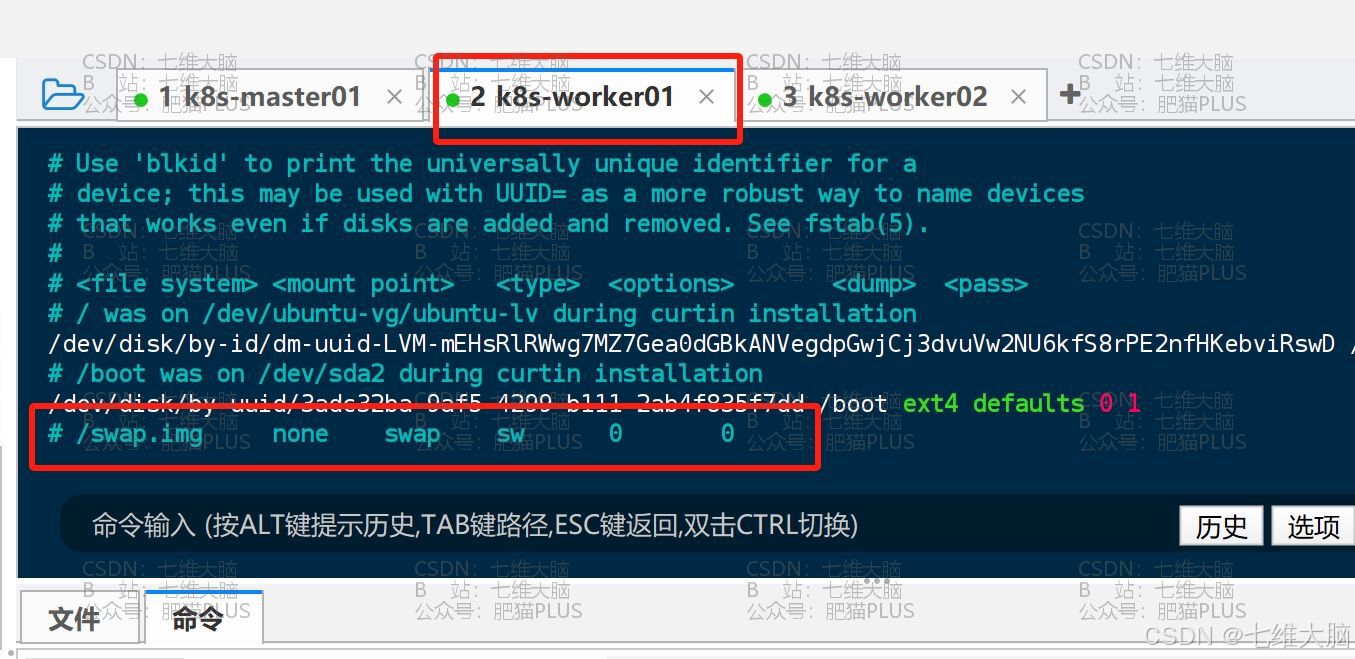
k8s-worker02
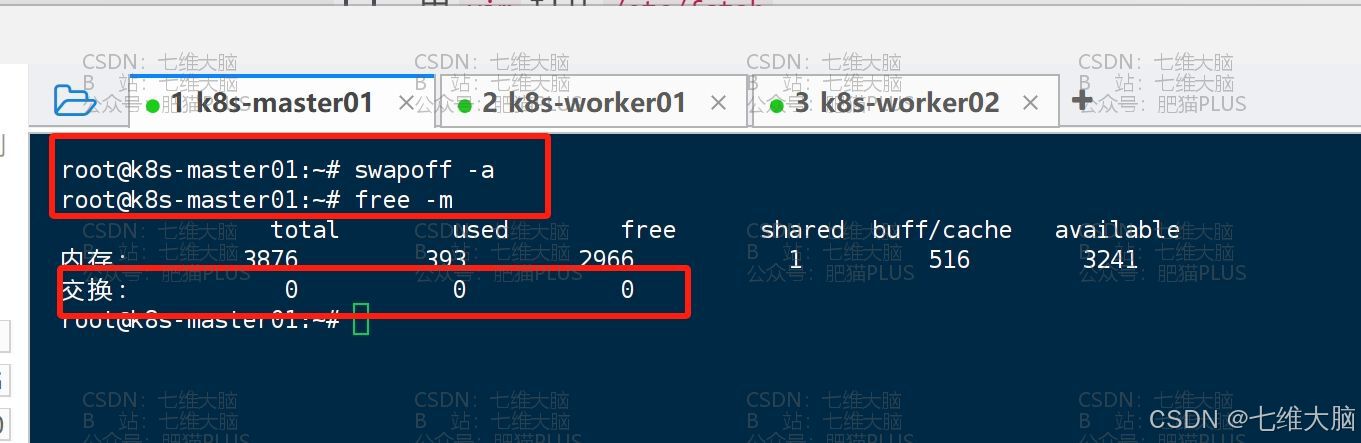
上面的操作,我们重启系统才会生效,我们本次要用,但不想重启系统,所以可以先临时关闭 SWAP 分区:
swapoff -a 然后我们可以用以下命令,查看是否关闭成功:
free -m 这样就是关闭成功了:
3. 容器运行时 Containerd 准备
3.1 获取Containerd安装包
以下针对所有主机,每次执行操作都需要保证三台机器都执行了且没有错误。
执行以下命令下载安装包:(如果提示连接被拒绝之类的提示,这是由于GitHub在外网,请使用魔法上网,或者多试几次)
wget https://github.com/containerd/containerd/releases/download/v1.7.5/cri-containerd-1.7.5-linux-amd64.tar.gz 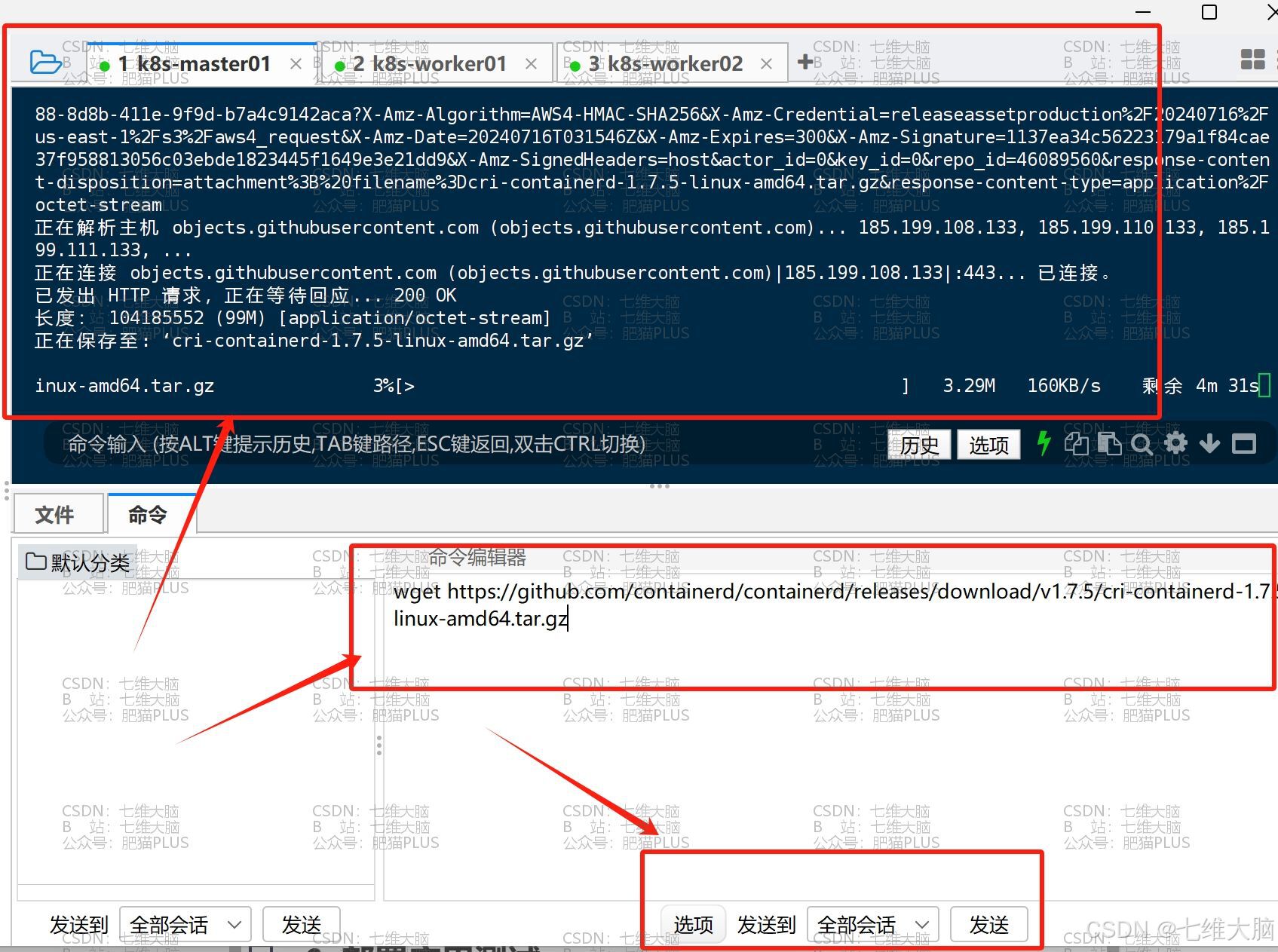
这里等待时间可能较长,请耐心等待下载完成,一定要确保三台主机都下载完了,再进行后续操作!!!
k8s-master01 下载完成
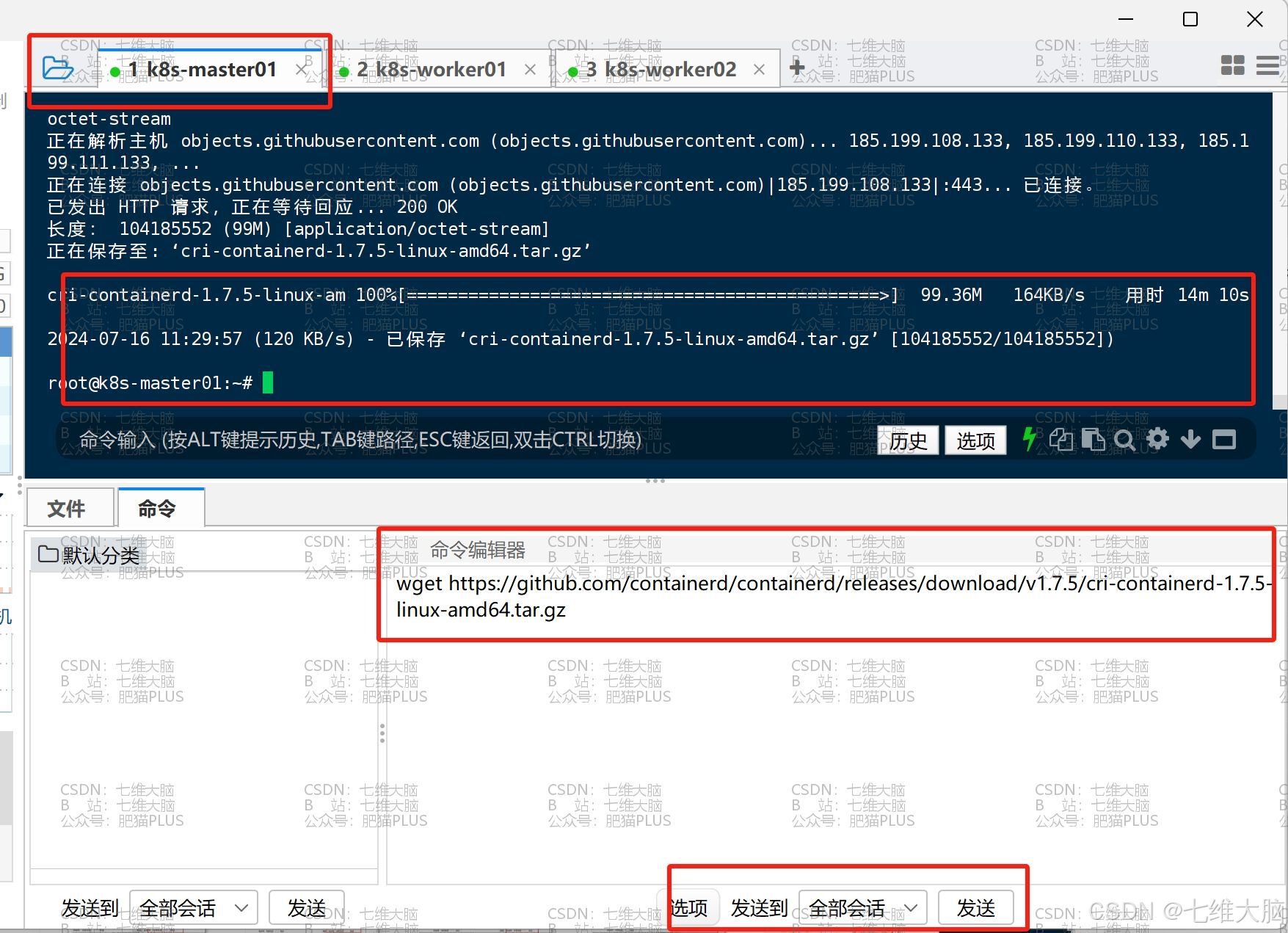
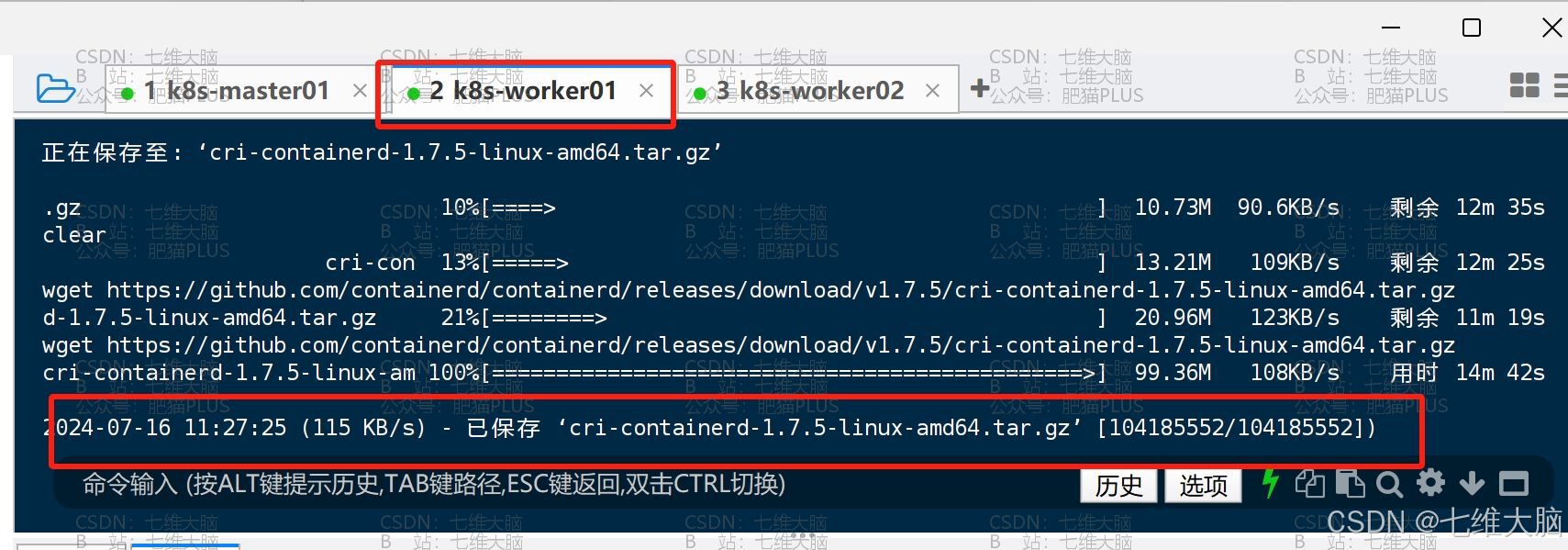
k8s-worker01 下载完成
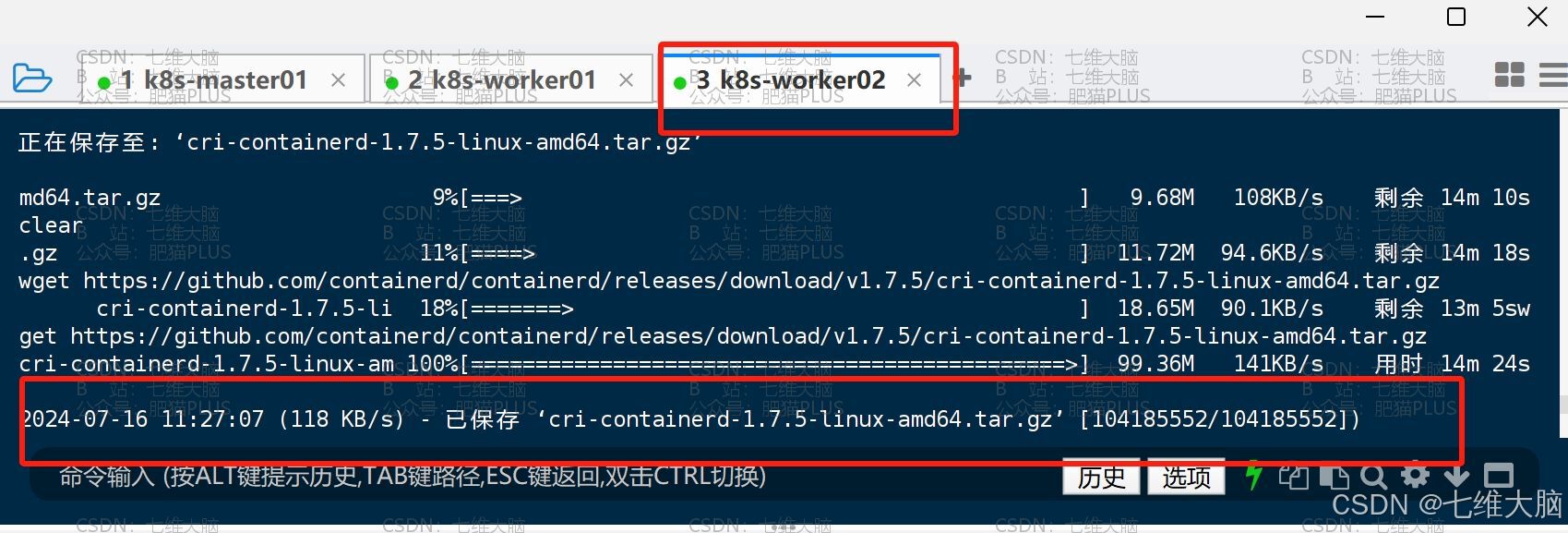
k8s-worker02 下载完成
3.2 安装 Containerd
以下针对所有主机,每次执行操作都需要保证三台机器都执行了且没有错误。
解压安装包到根目录(解压到根目录他就会自动归位了,不需要我们再去移动了):
tar xf cri-containerd-1.7.5-linux-amd64.tar.gz -C / 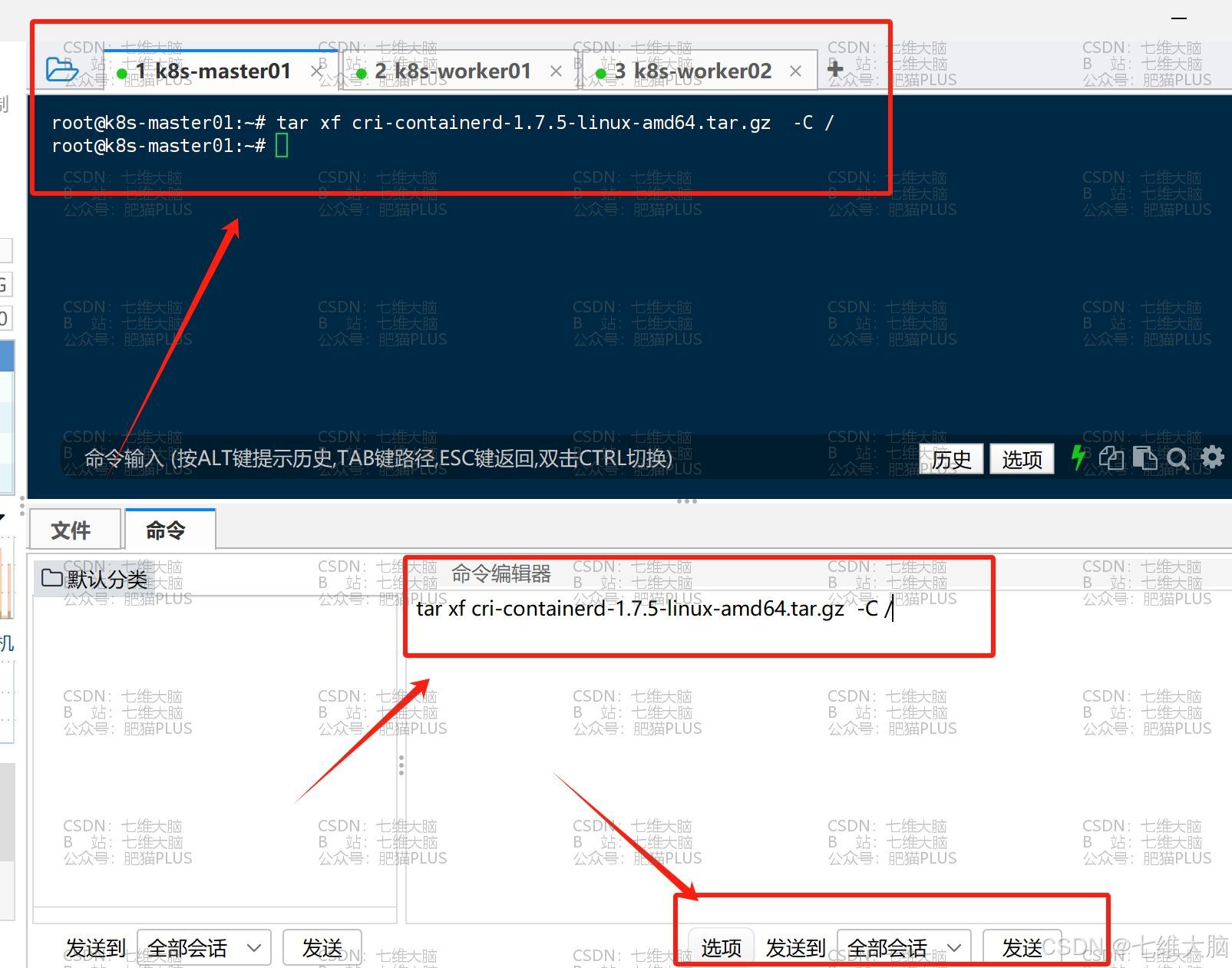
其实解压完以后就相当于安装完了,我们可以随便输一个命令来验证一下:
containerd --version 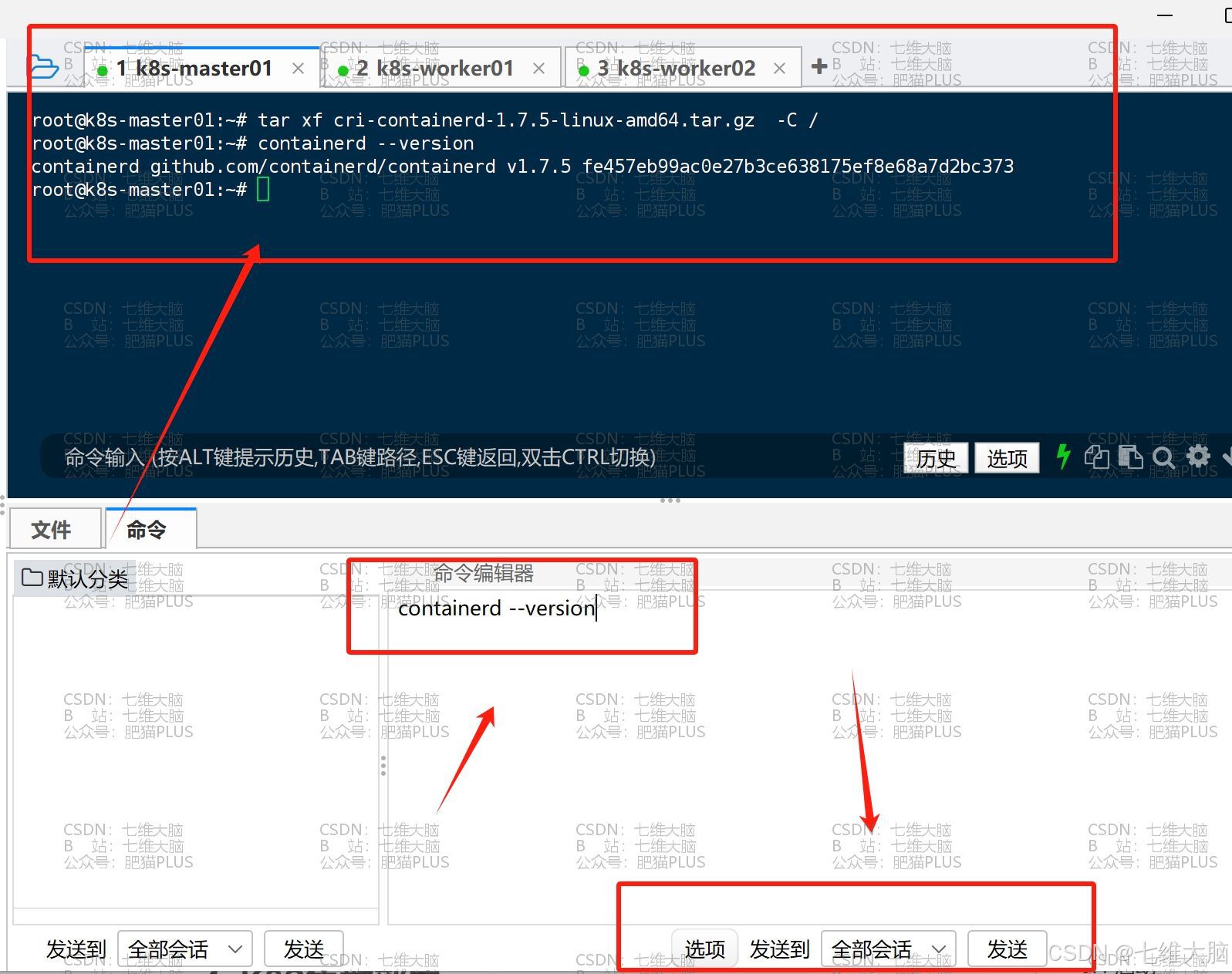
3.3 创建&修改配置文件
以下针对所有主机,每次执行操作都需要保证三台机器都执行了且没有错误。
首先创建配置文件所在目录:
mkdir /etc/containerd 生成默认配置文件:(Containerd的配置文件使用TOML格式)
containerd config default > /etc/containerd/config.toml 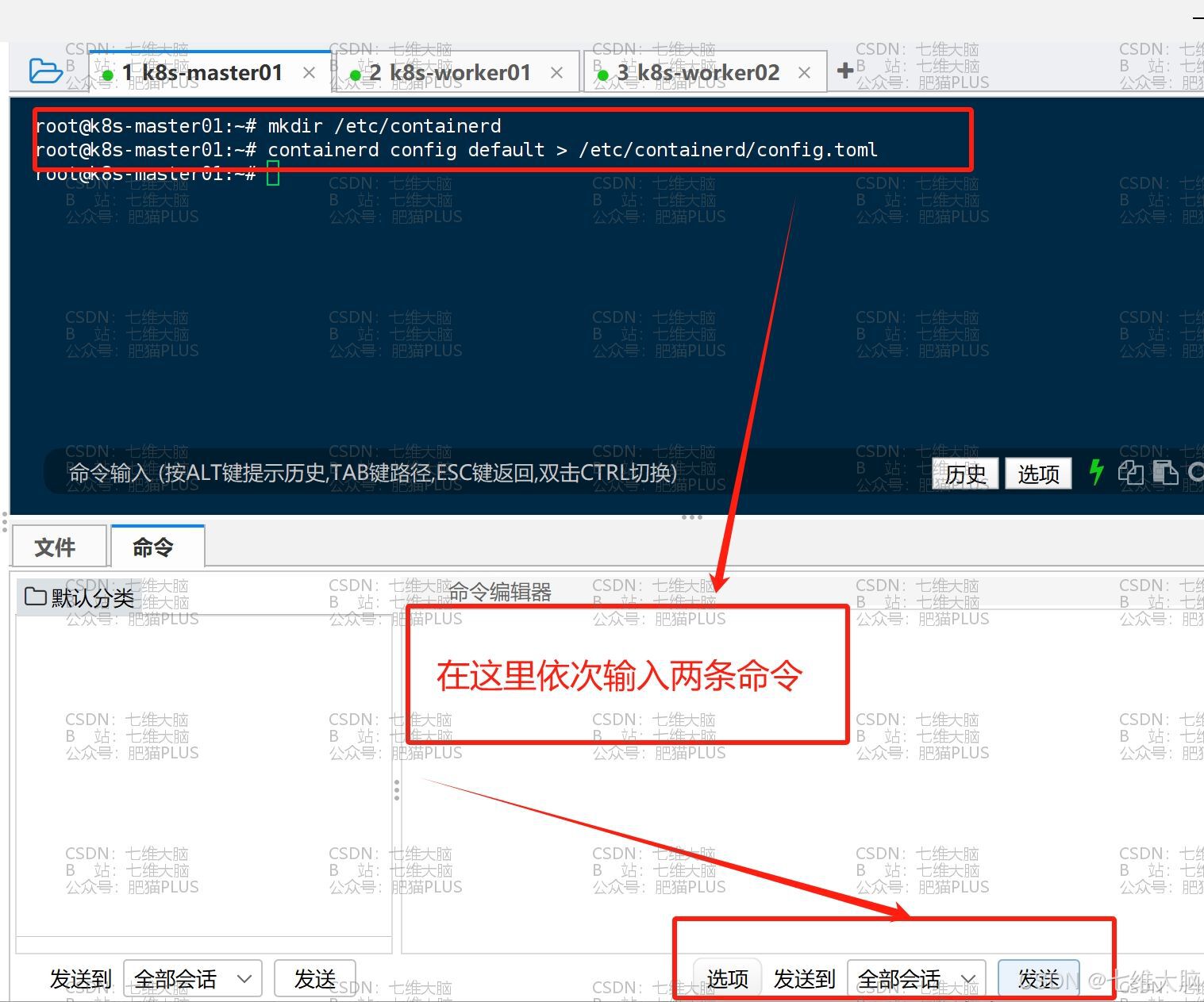
然后使用以下命令查看有没有生成成功:
ls /etc/containerd 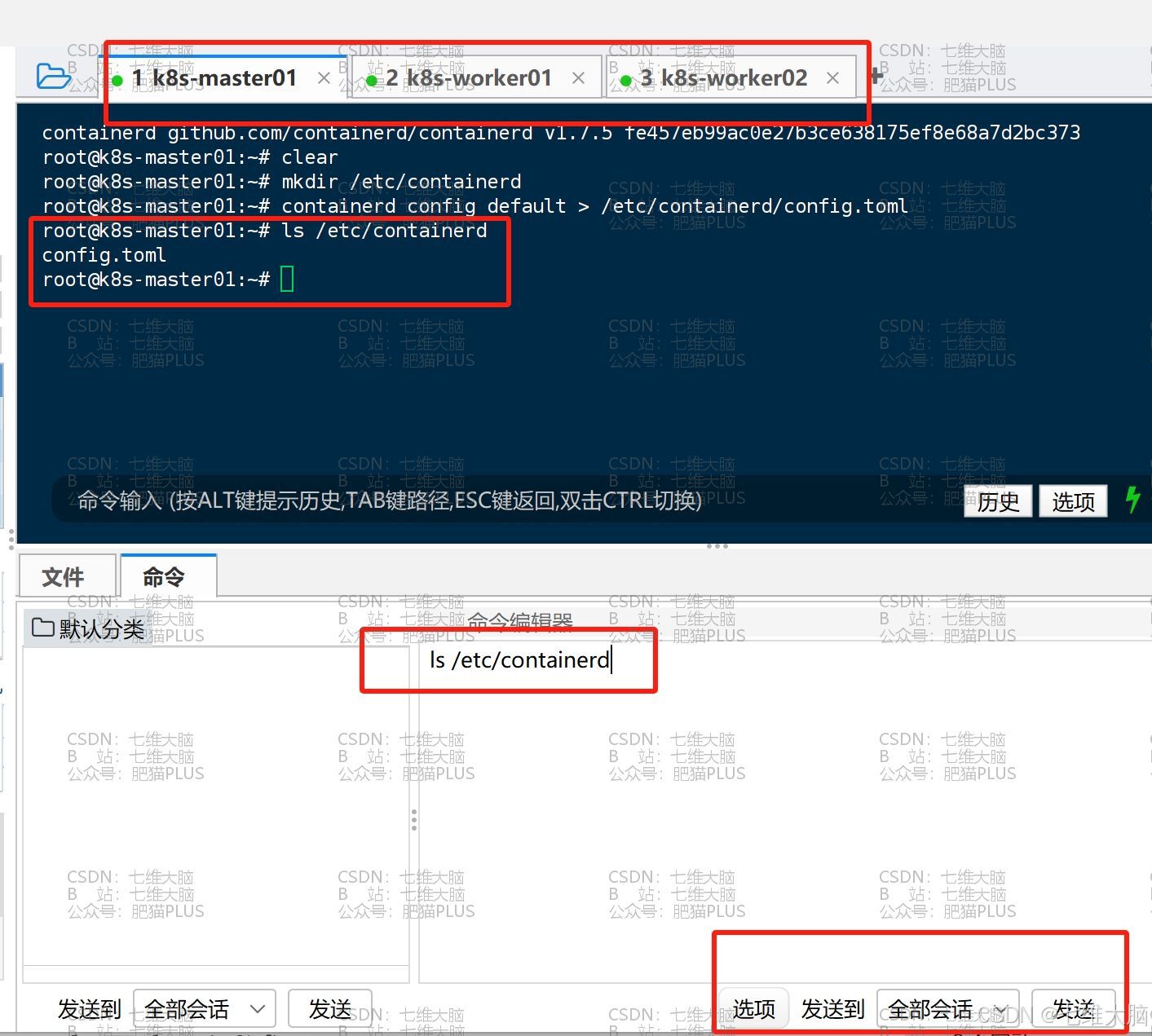
生成以后,我们需要对配置文件进行修改:
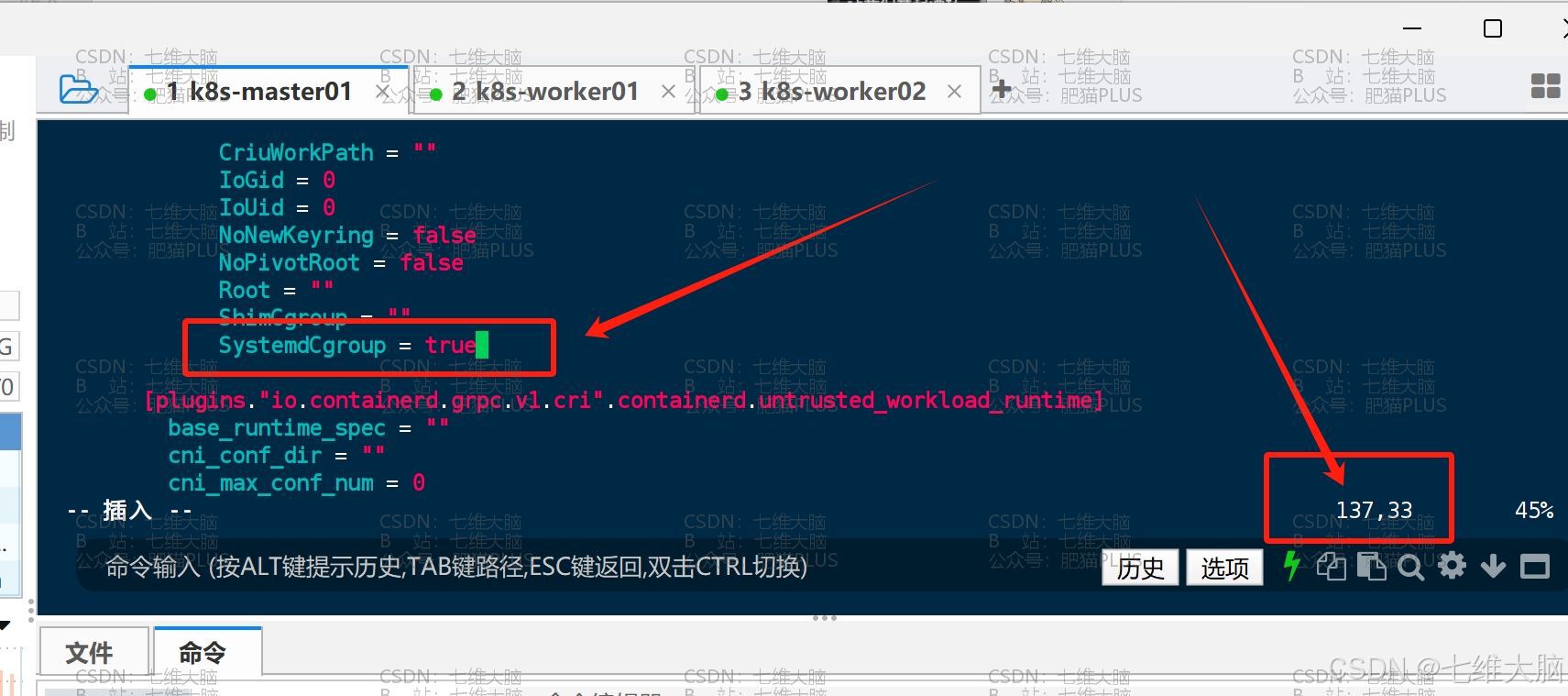
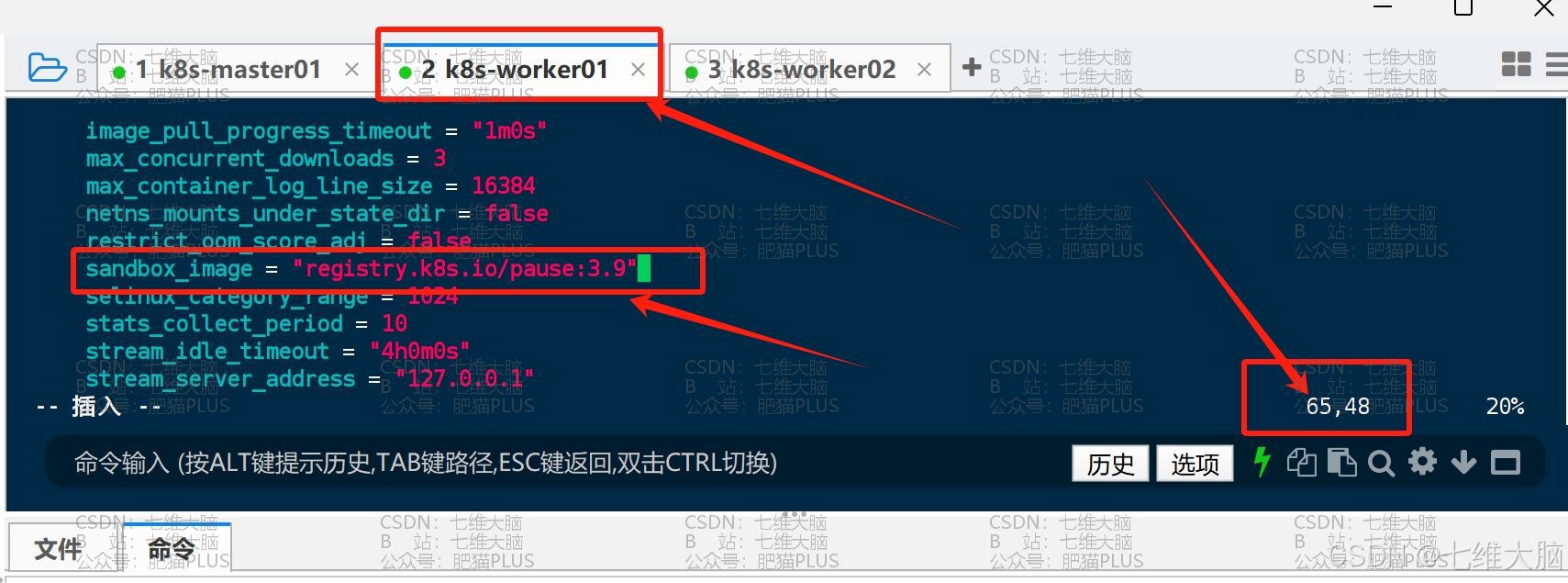
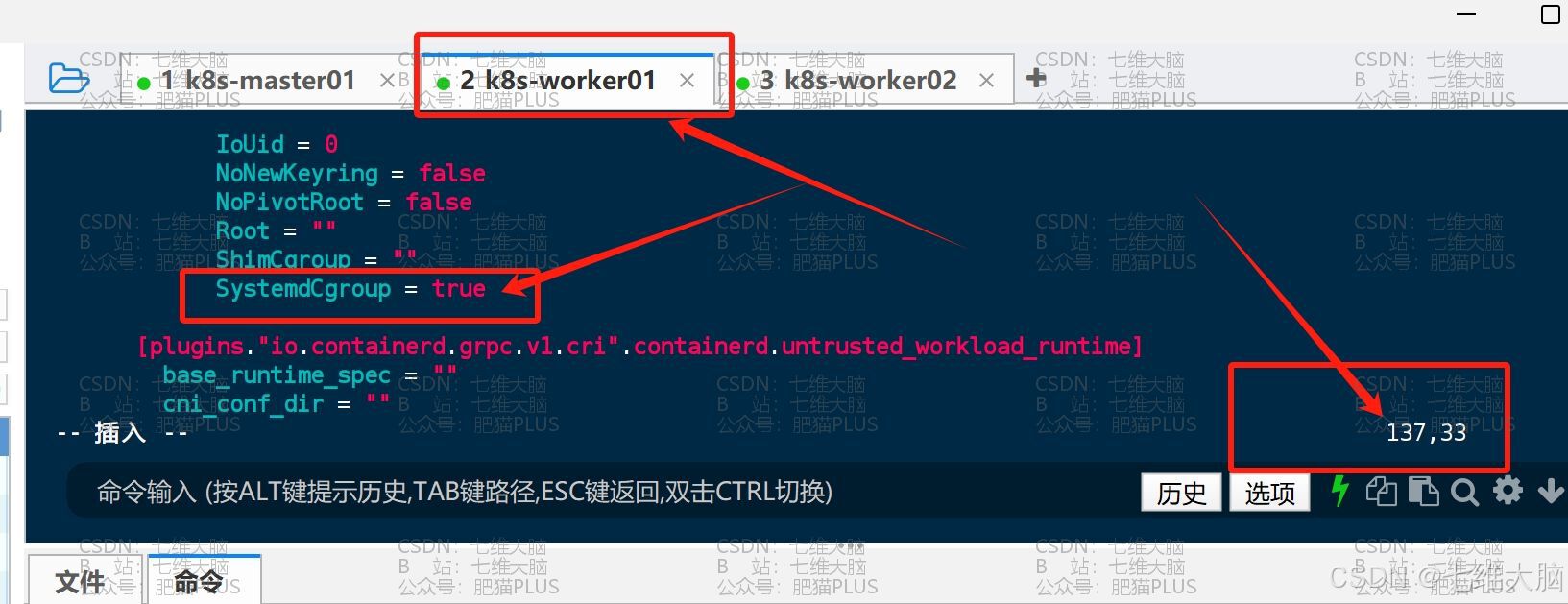
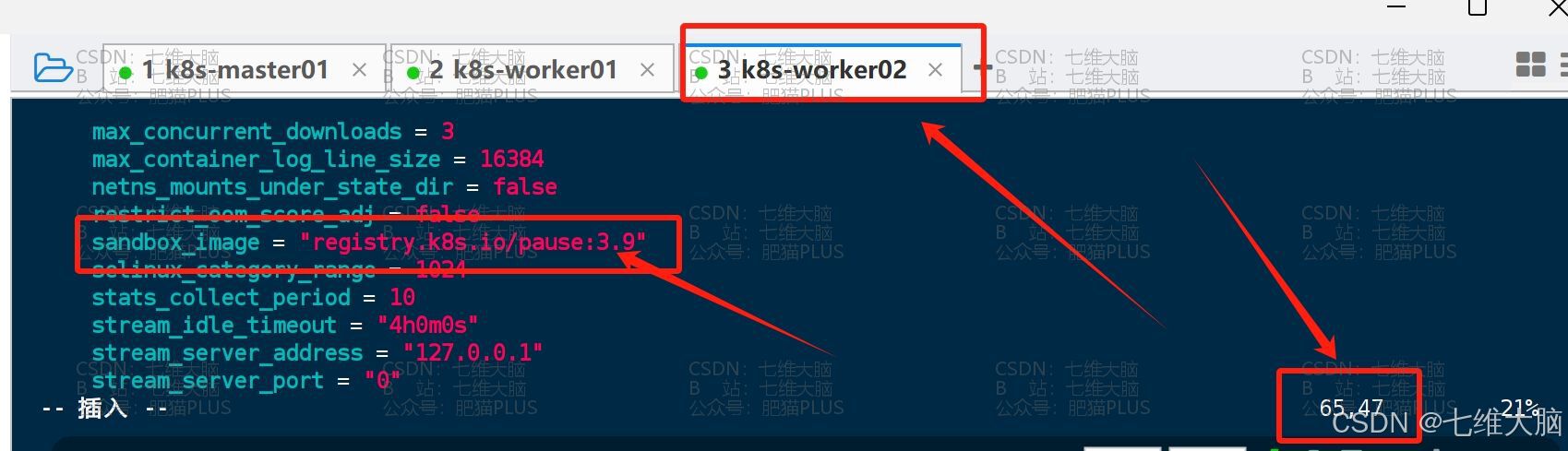
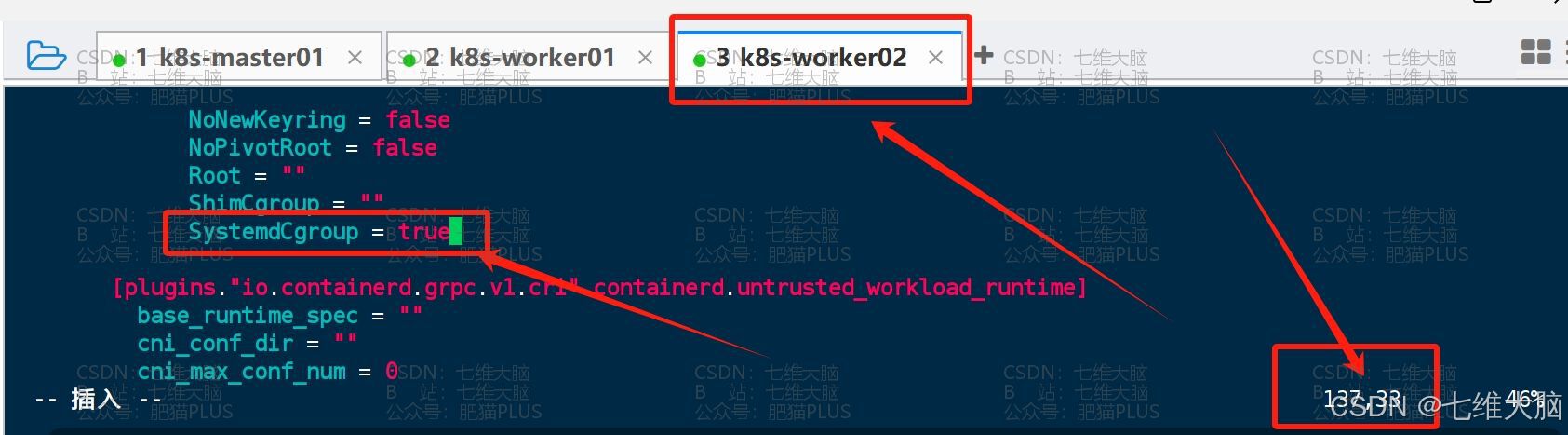
vim /etc/containerd/config.toml 要修改的地方有第65行、137行 (三台主机都需要改!)
首先是65行的 sanbox_image = "registry.k8s.io/pause:3.8" 改成 sanbox_image = "registry.k8s.io/pause:3.9"
然后是137行的 SystemdCgroup = false 改成 SystemdCgroup = true
k8s-master01
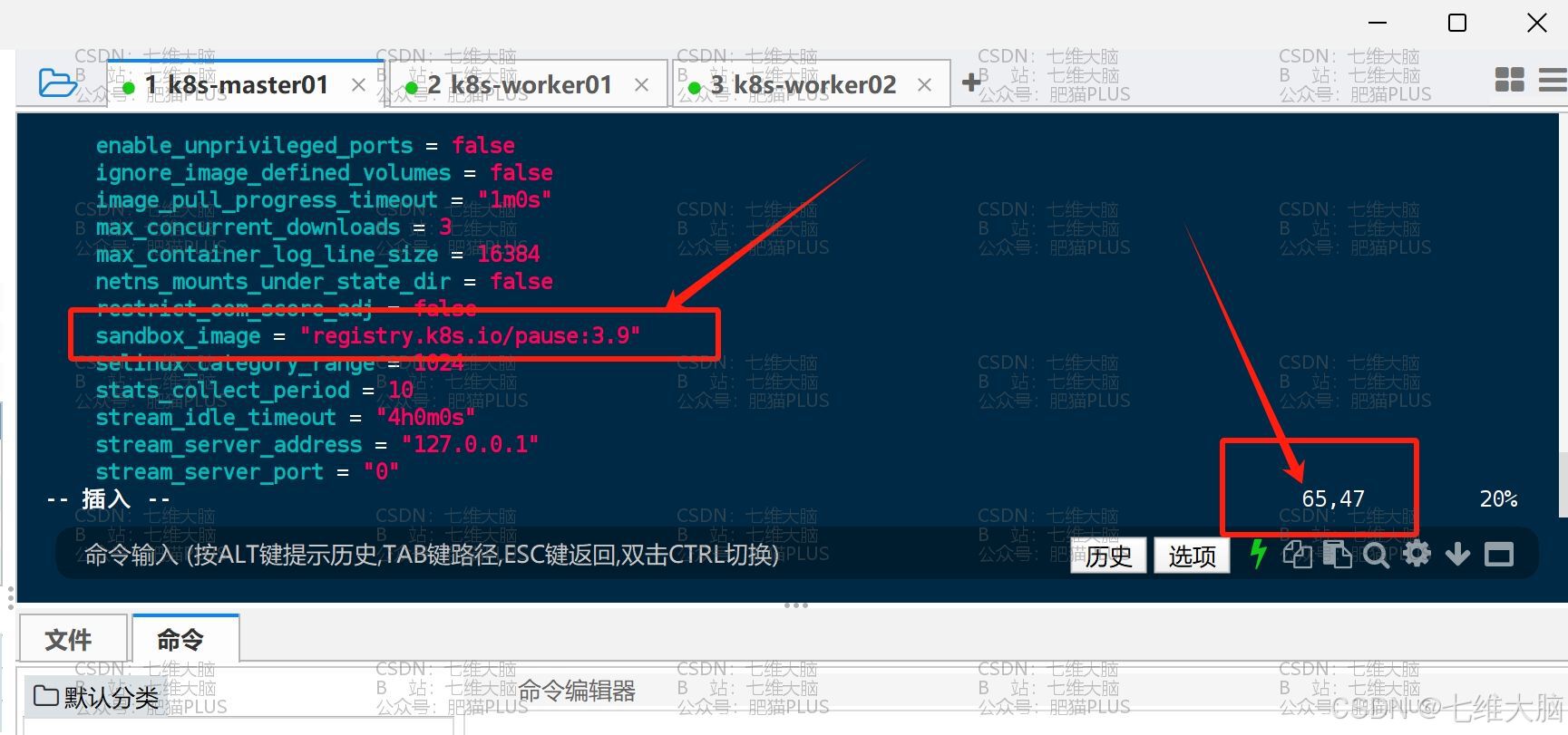
k8s-worker01
k8s-worker02
3.4 启动Containerd&开机自启
以下针对所有主机,每次执行操作都需要保证三台机器都执行了且没有错误。
执行以下命令,设置开机自启,并设置现在就启动:
--now 的意思就是现在启动
systemctl enable --now containerd 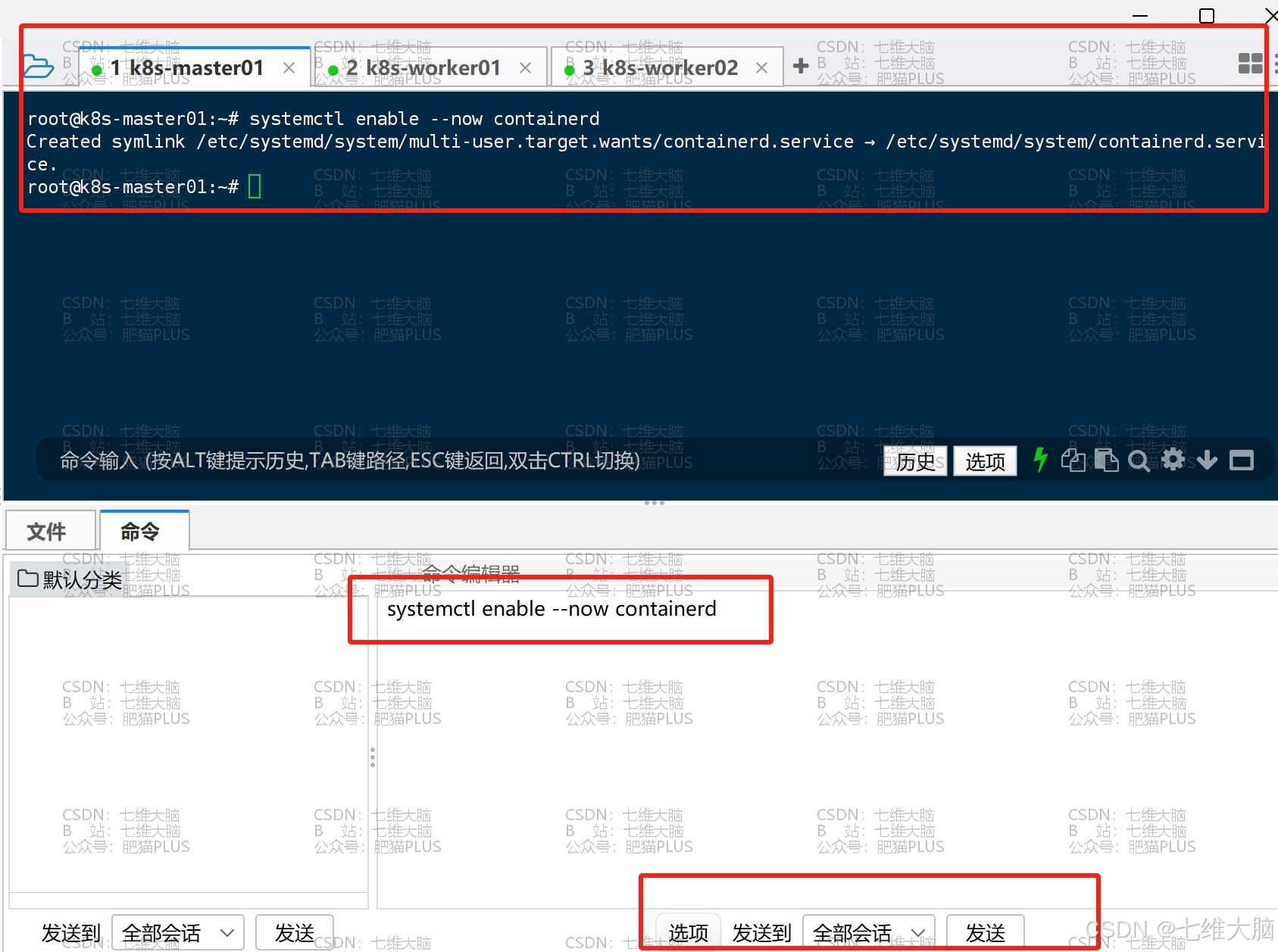
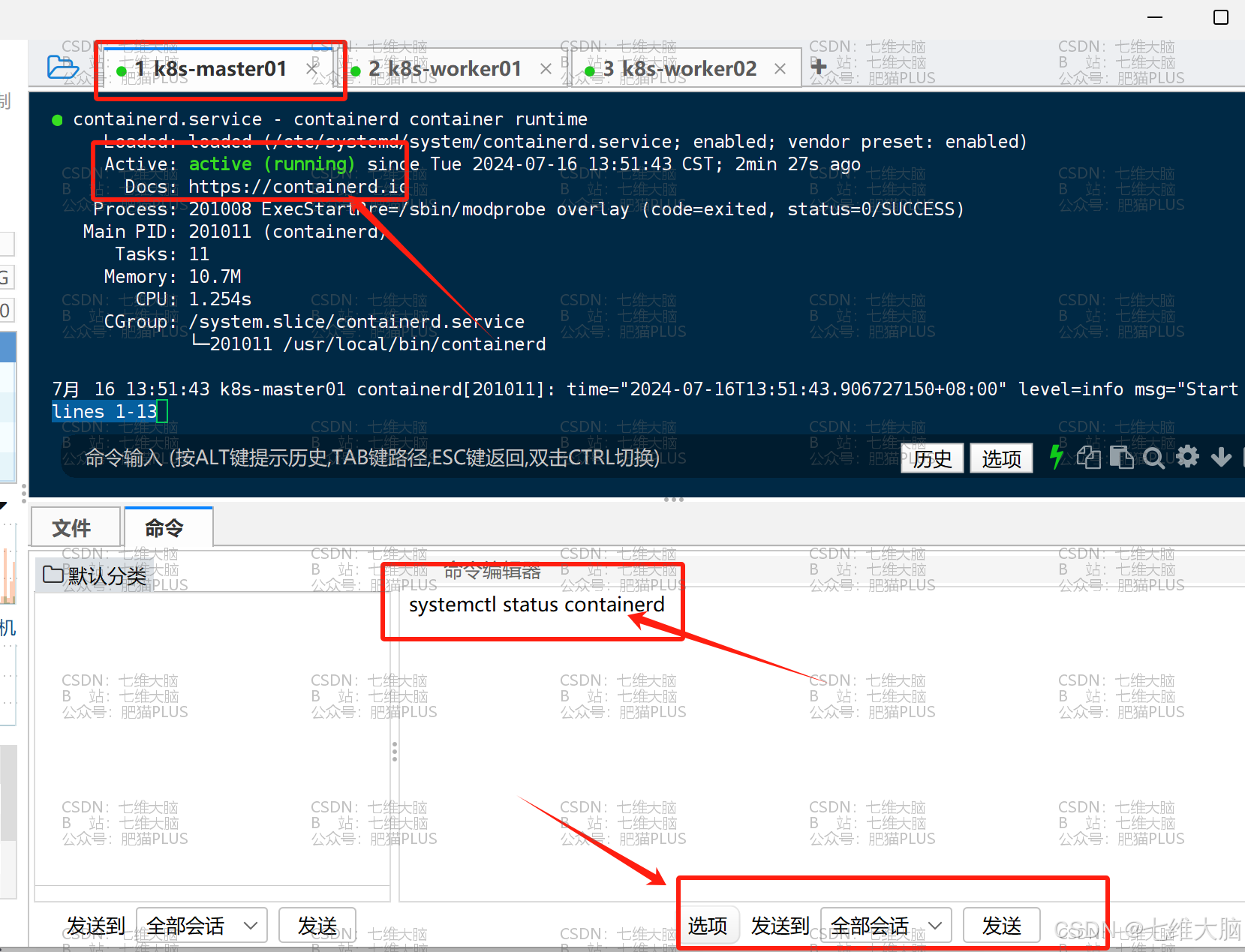
然后执行以下命令验证一下是否三台主机都已启动:
systemctl status containerd k8s-master01 已启动
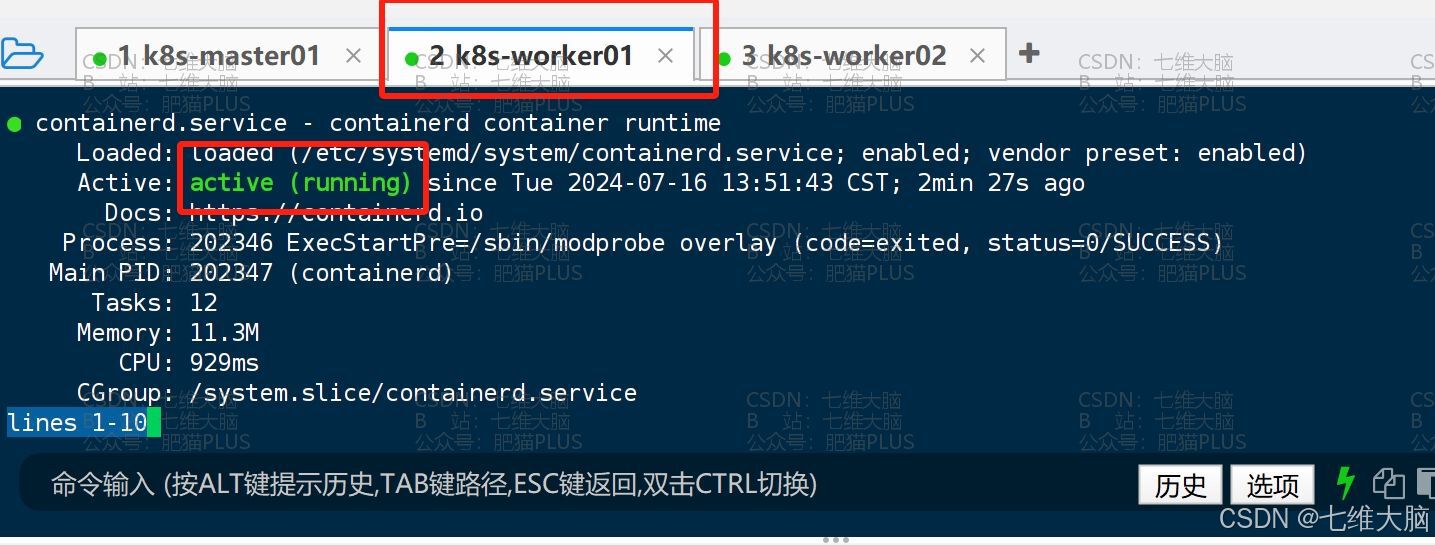
k8s-worker01 已启动
k8s-worker02 已启动
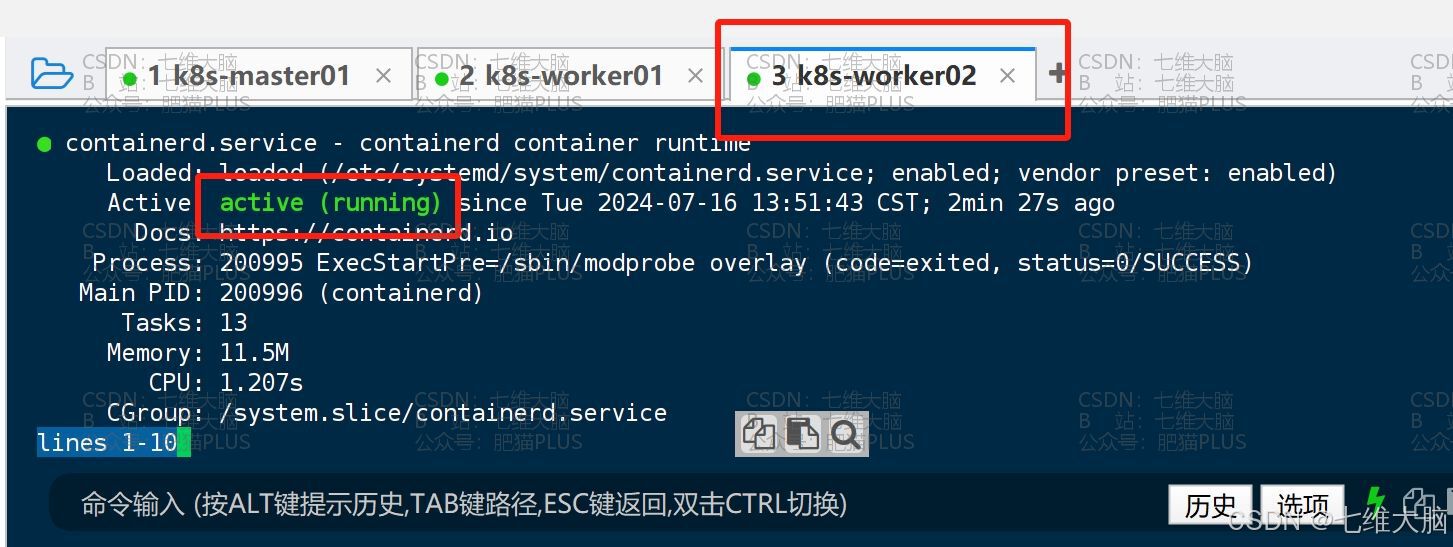
温馨提示:
Ctrl+Z可退出查看状态。
4. K8S集群部署
4.1 软件源准备
以下针对所有主机,每次执行操作都需要保证三台机器都执行了且没有错误。
使用阿里云提供的软件源:
echo "deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main" | sudo tee /etc/apt/sources.list.d/kubernetes.list 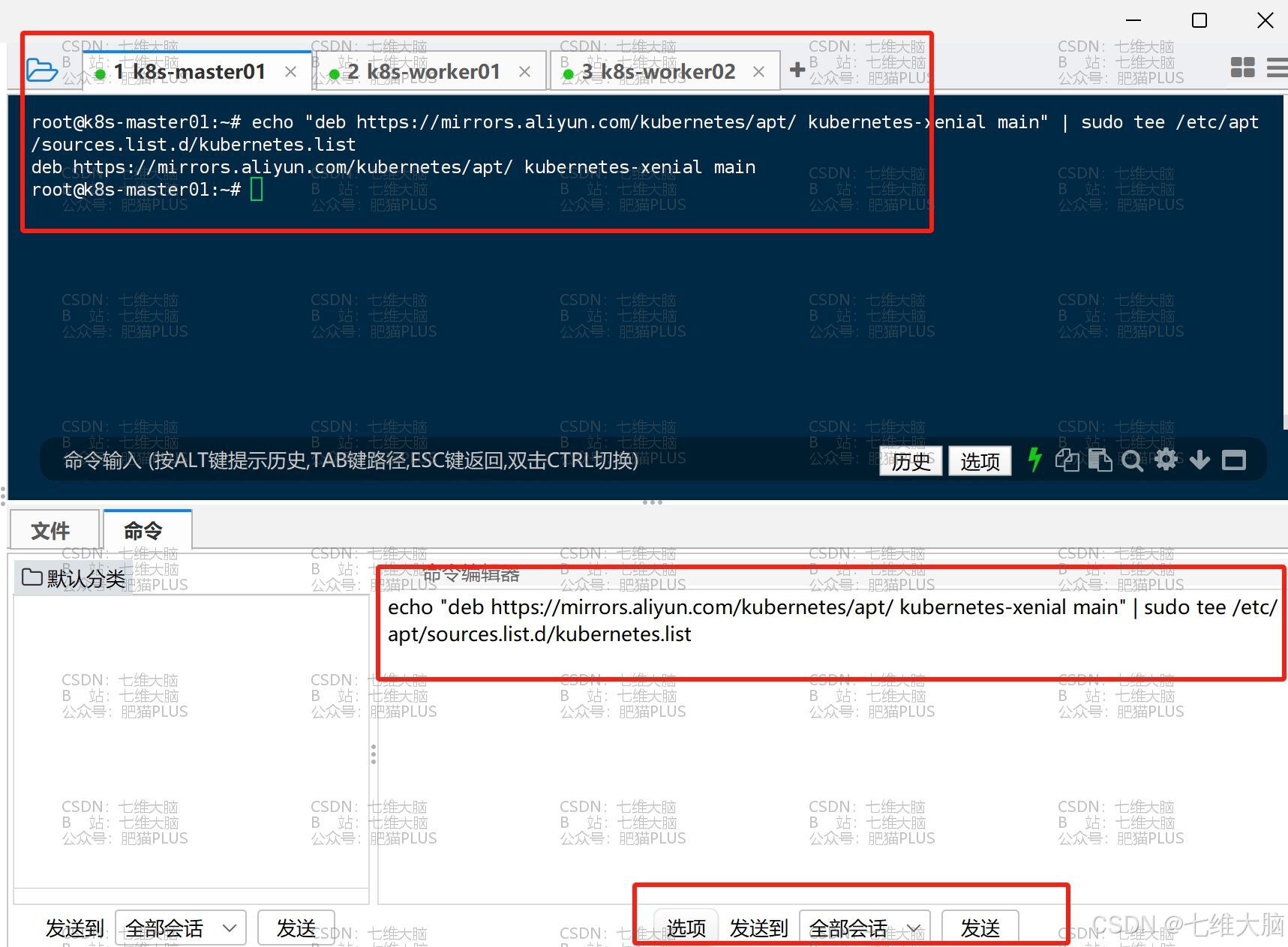
然后我们验证一下是否添加成功了:
ls /etc/apt/sources.list.d 
确定三台主机都成功了以后,我们更新软件源:
apt-get update 执行完以后会提示如下图所示的错误,这个主要是因为没有公钥,缺少 GPG 的key导致的:
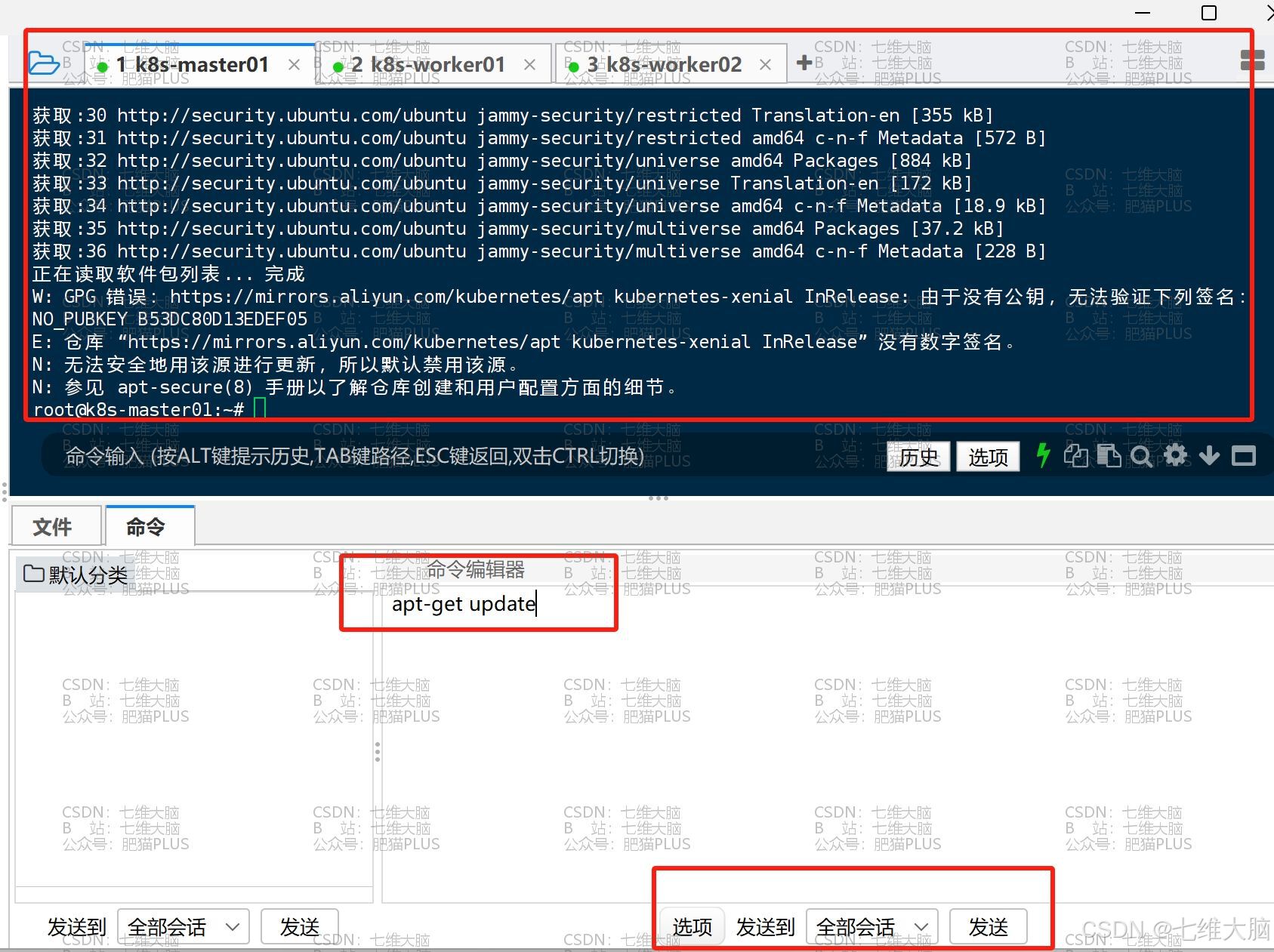
所以,我们需要将公钥添加至服务器:
(B53DC80D13EDEF05 部分以你显示的为准)
apt-key adv --recv-keys --keyserver keyserver.ubuntu.com B53DC80D13EDEF05 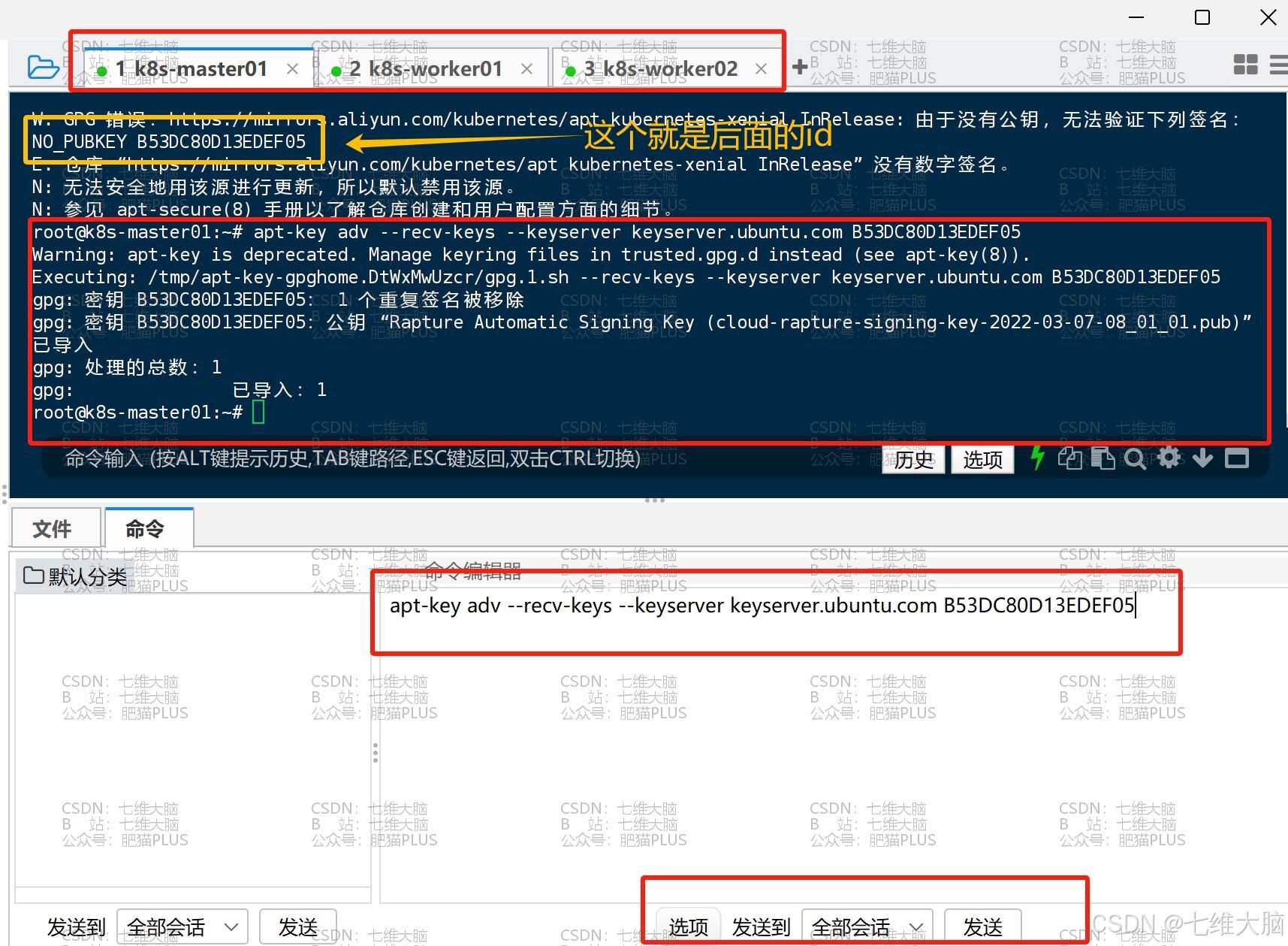
导入完成以后,我们再重新执行以下命令就可以了:
apt-get update 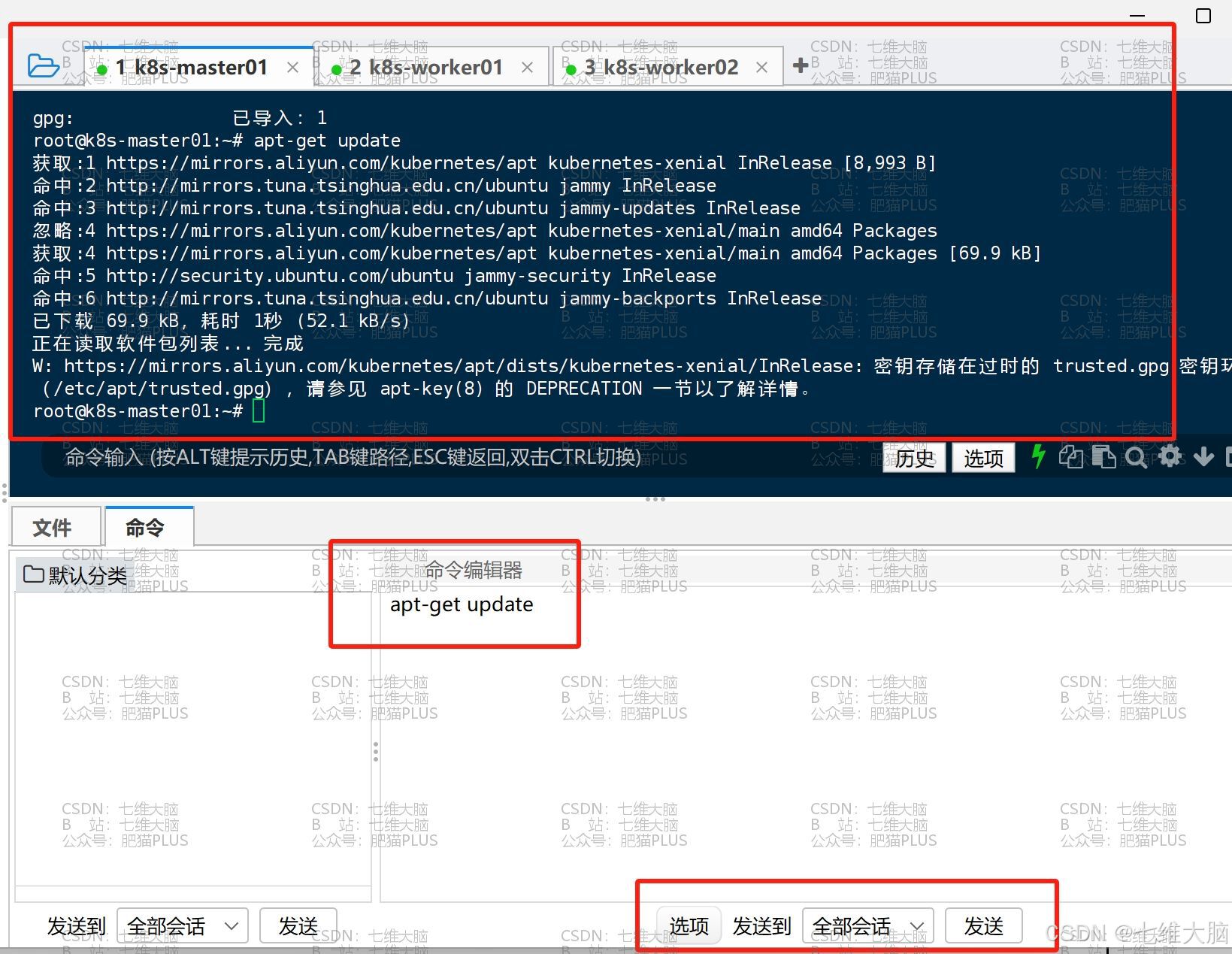
4.2 软件安装
以下针对所有主机,每次执行操作都需要保证三台机器都执行了且没有错误。
我们要使用 kubeadm 对我们的集群进行初始化,所以要先安装必要的软件:
apt-get install kubeadm=1.28.1-00 kubelet=1.28.1-00 kubectl=1.28.1-00 我这里以1.28.1版本为例,上面的命令就是指定版本安装。如果你们要安装最新版,将版本号去掉即可,那下面的命令可以查看支持的版本:
apt-cache madison kubeadm apt-cache madison kubelet apt-cache madison kubectl 
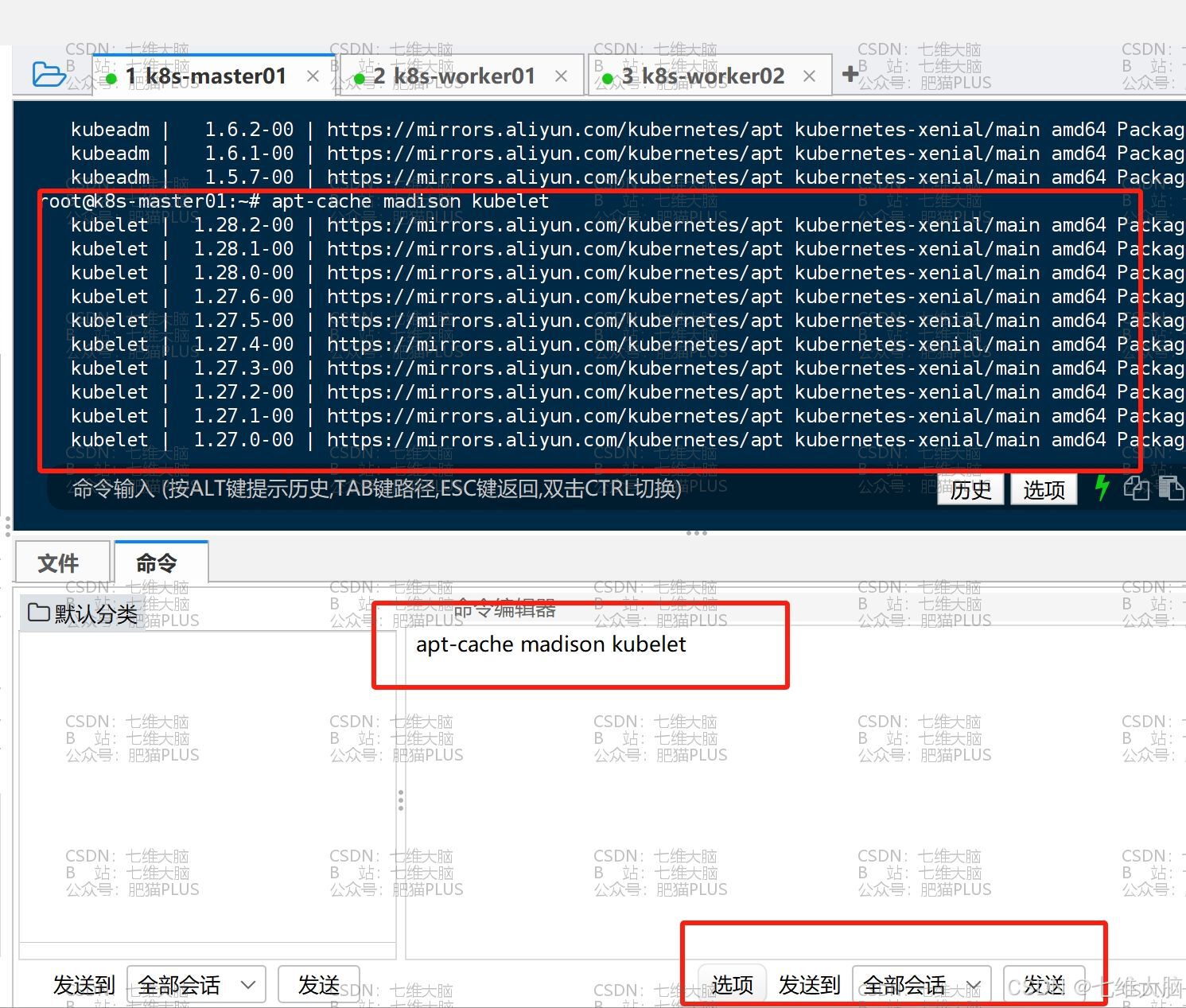
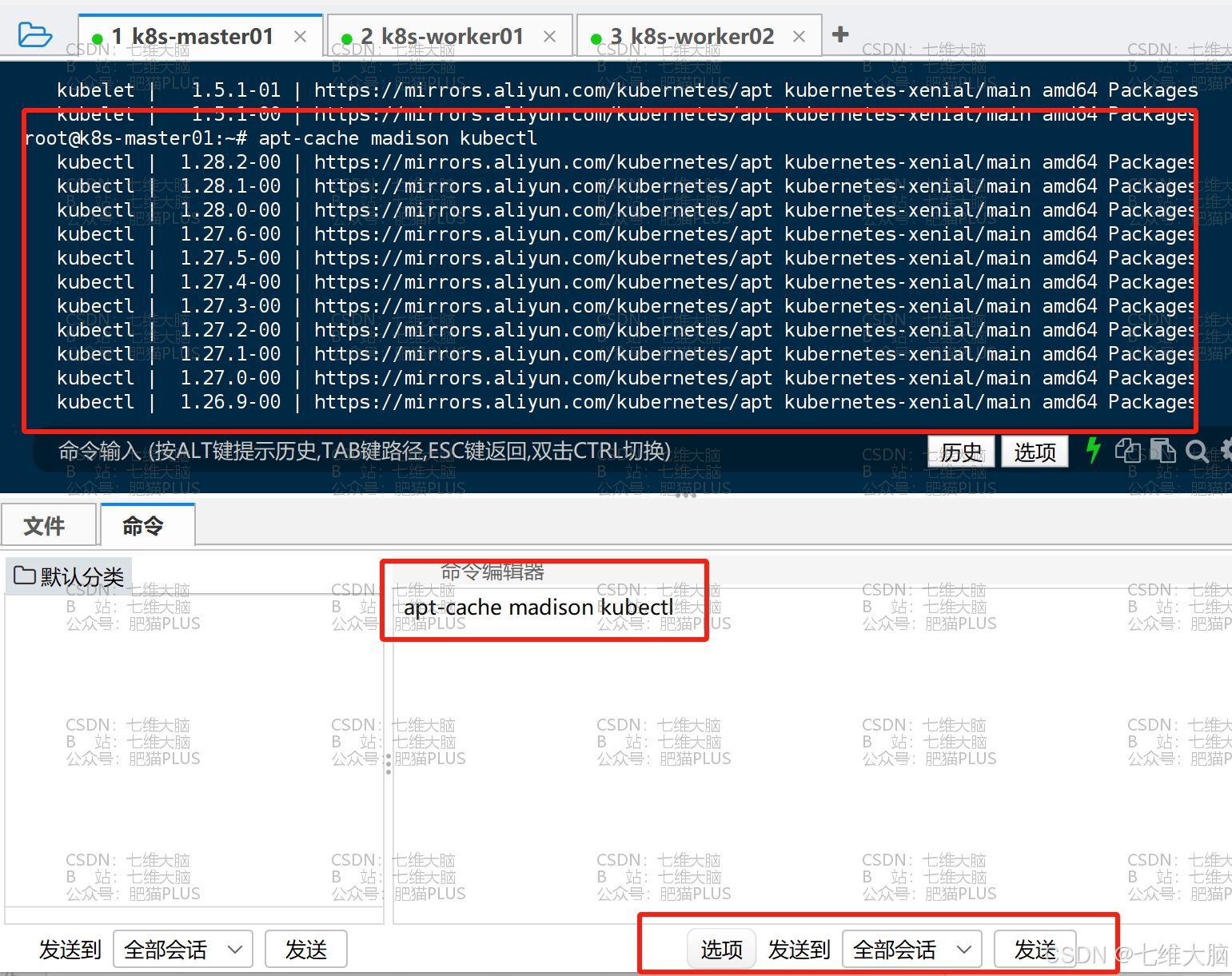
确定好自己要安装的版本后,执行安装命令:
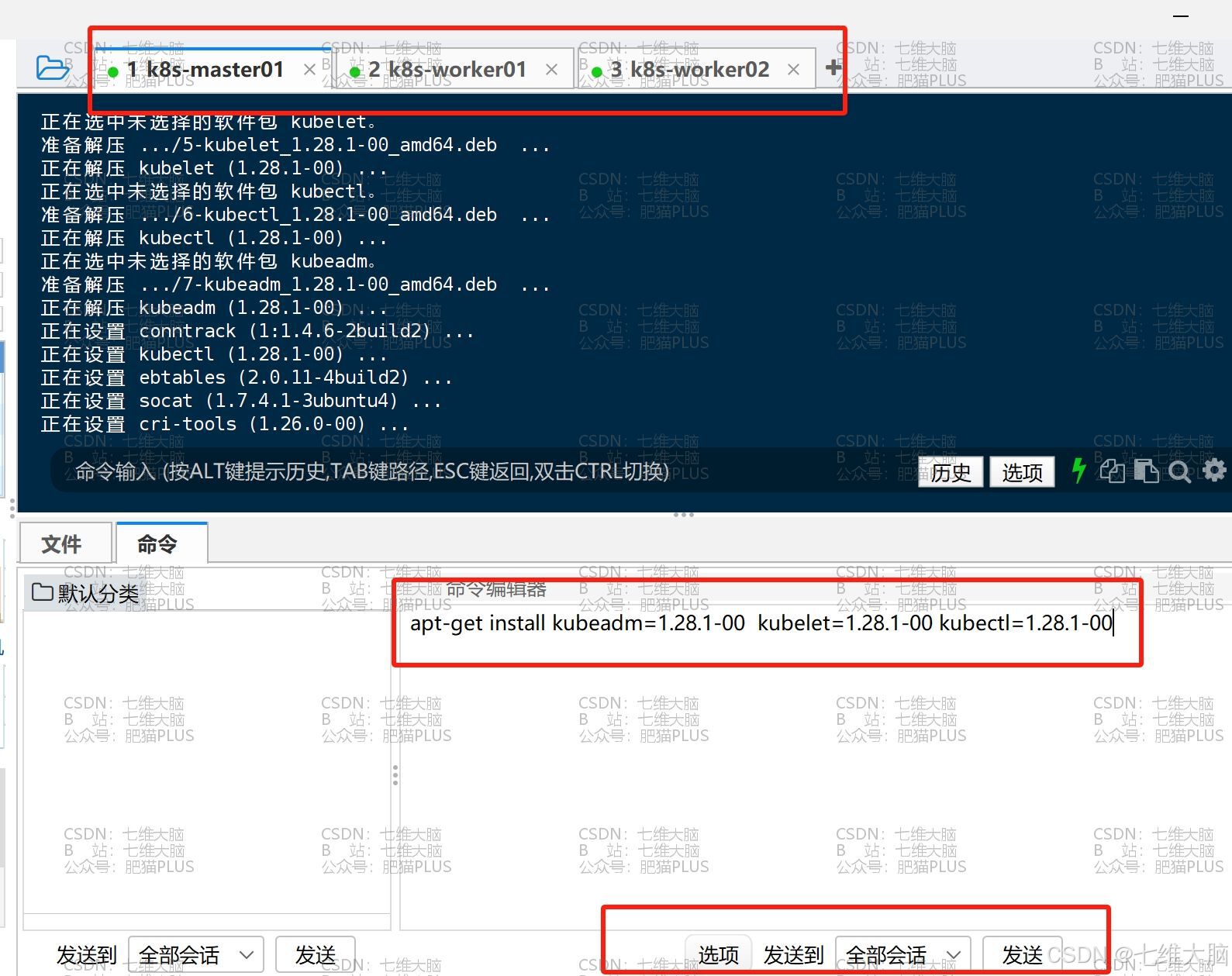
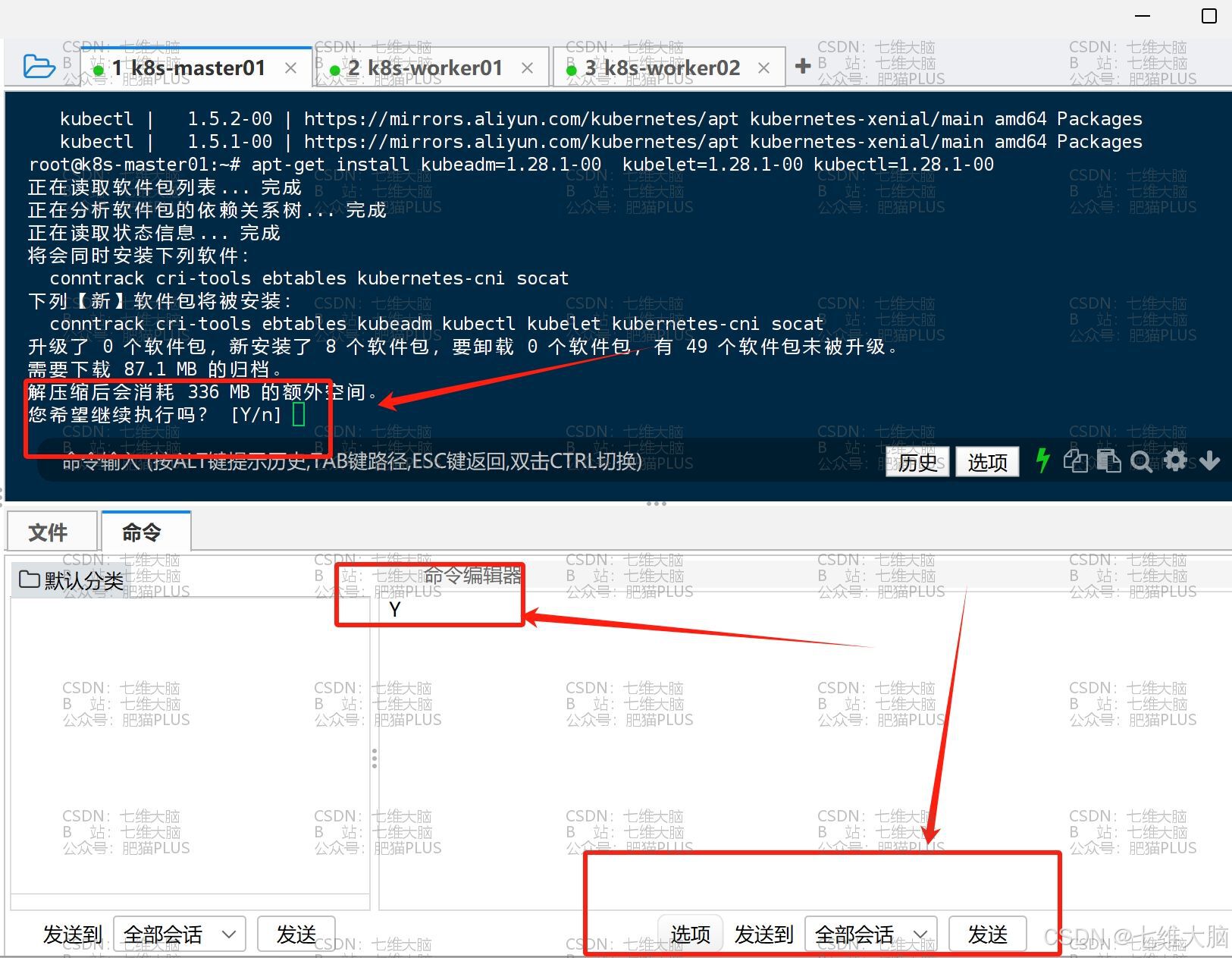
然后安装过程中会提示你输入 Y :
(下载过程可能会比较慢,耐心等待三台主机都下载完!一定要确保三台都下载完,再进行后续操作)
安装完成以后,我们分别执行以下命令,验证一下是不是安装成功了:
(要确保三台主机都成功了)
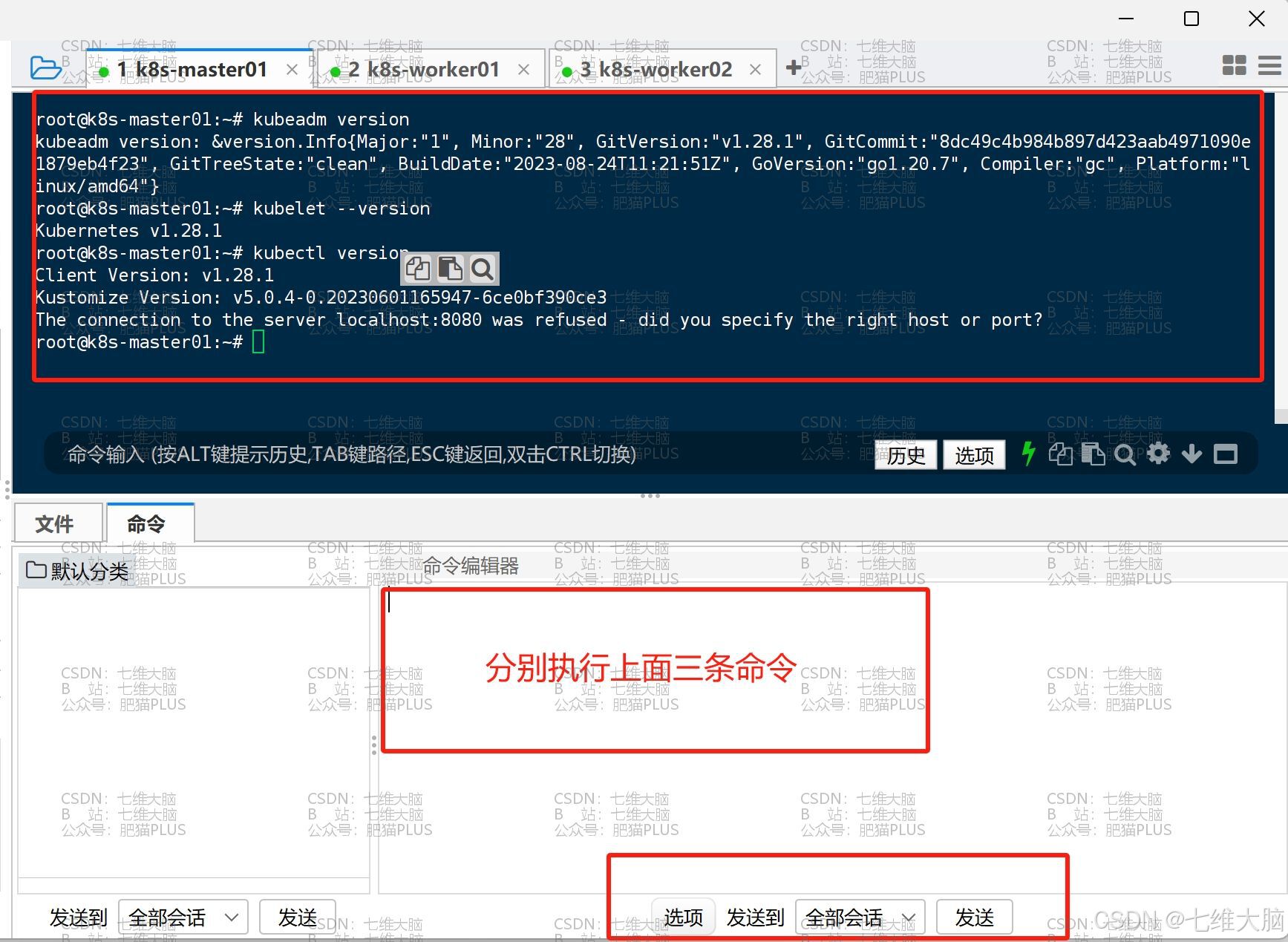
kubeadm version kubelet --version kubectl version - k8s-master01 已成功安装
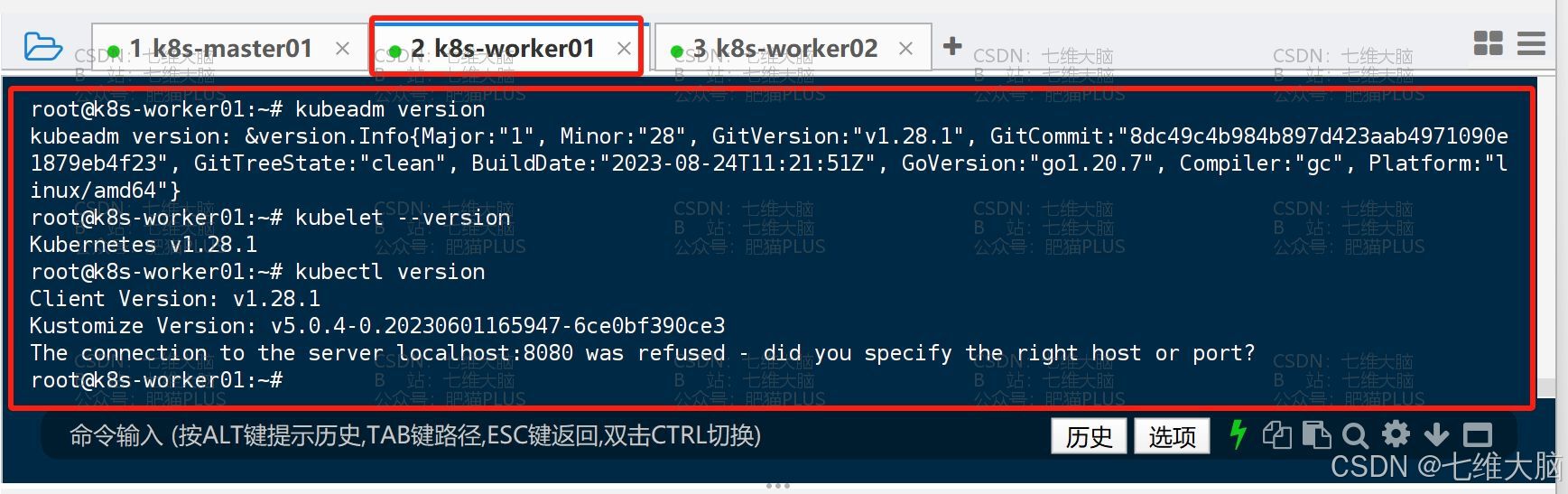
- k8s-worker01 已成功安装
- k8s-worker02 已成功安装
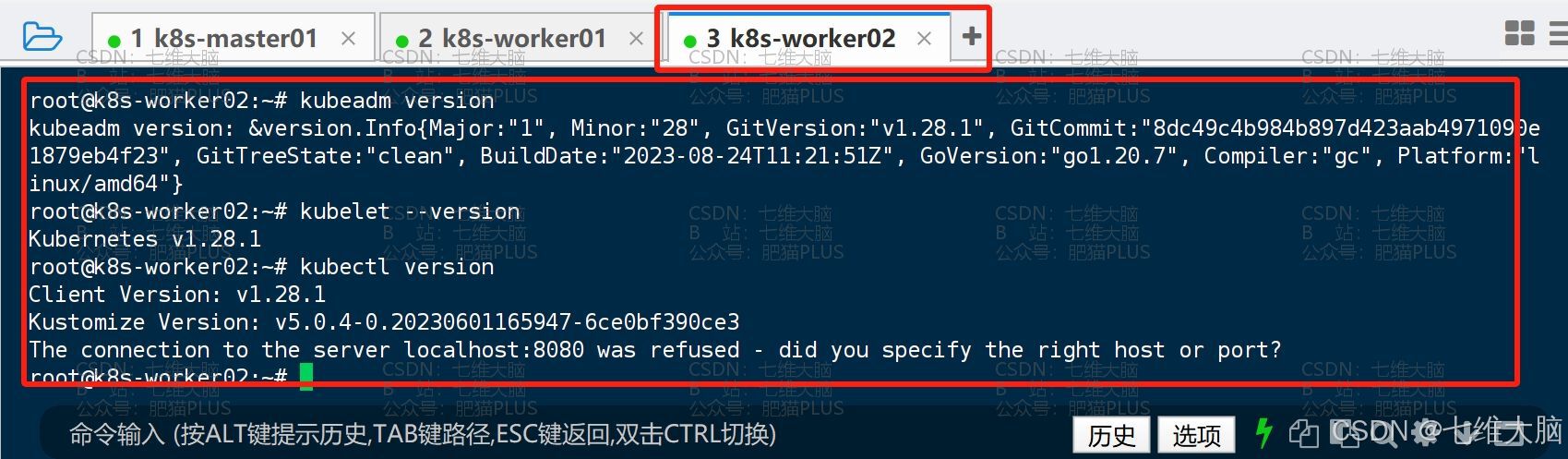
确定三台主机都已安装完以后,我们需要锁定版本,防止软件更新对 k8s 集群造成一定影响:
apt-mark hold kubeadm kubelet kubectl 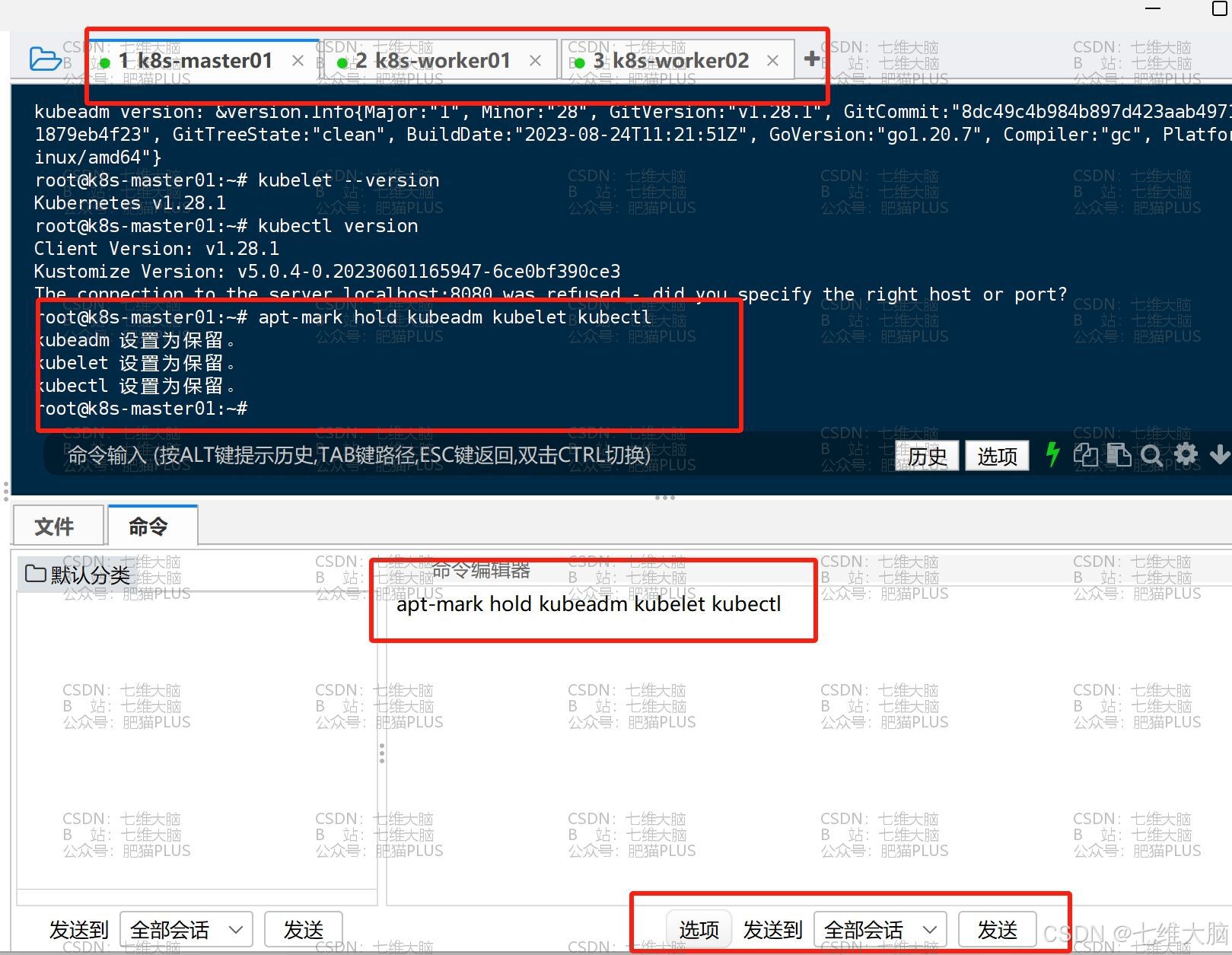
4.3 集群初始化
以下仅针对
master节点的主机,也就是只需要在master节点的主机上操作。如需在其他主机操作,我会特别说明。
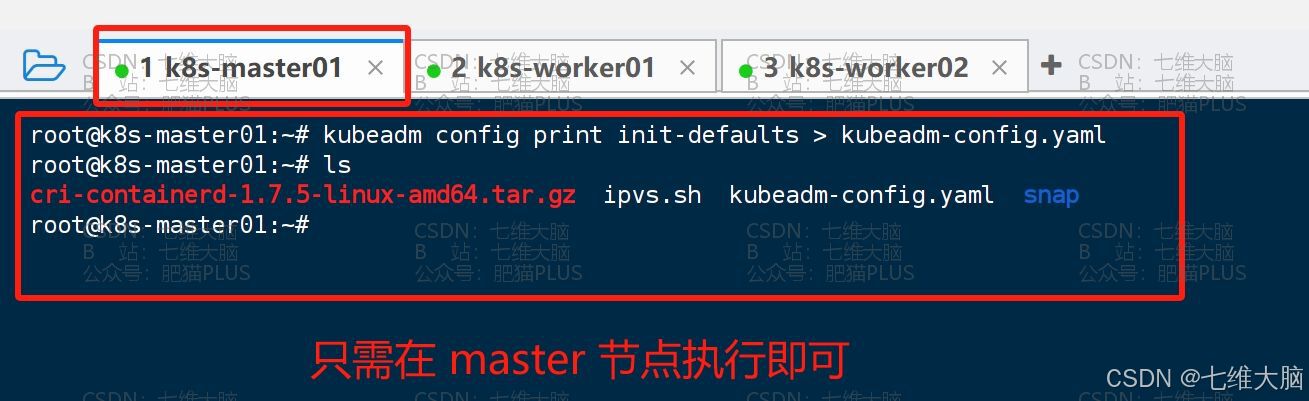
首先我们需要创建 kubeadm 配置文件:
这条命令的意思就是将配置打印到 kubeadm-config.yaml 文件中
kubeadm config print init-defaults > kubeadm-config.yaml 然后使用 ls 命令查看是否生成成功:
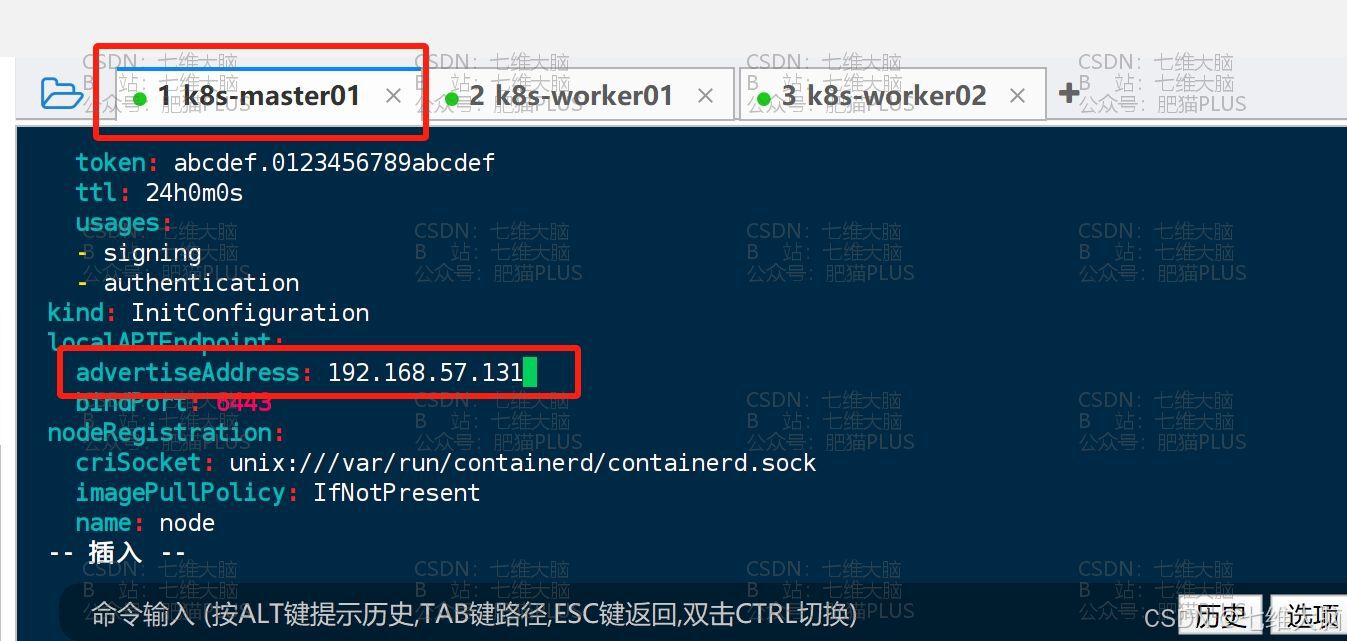
确认生成成功以后,我们开始编辑这个配置文件:
vim kubeadm-config.yaml 修改IP地址
修改名称
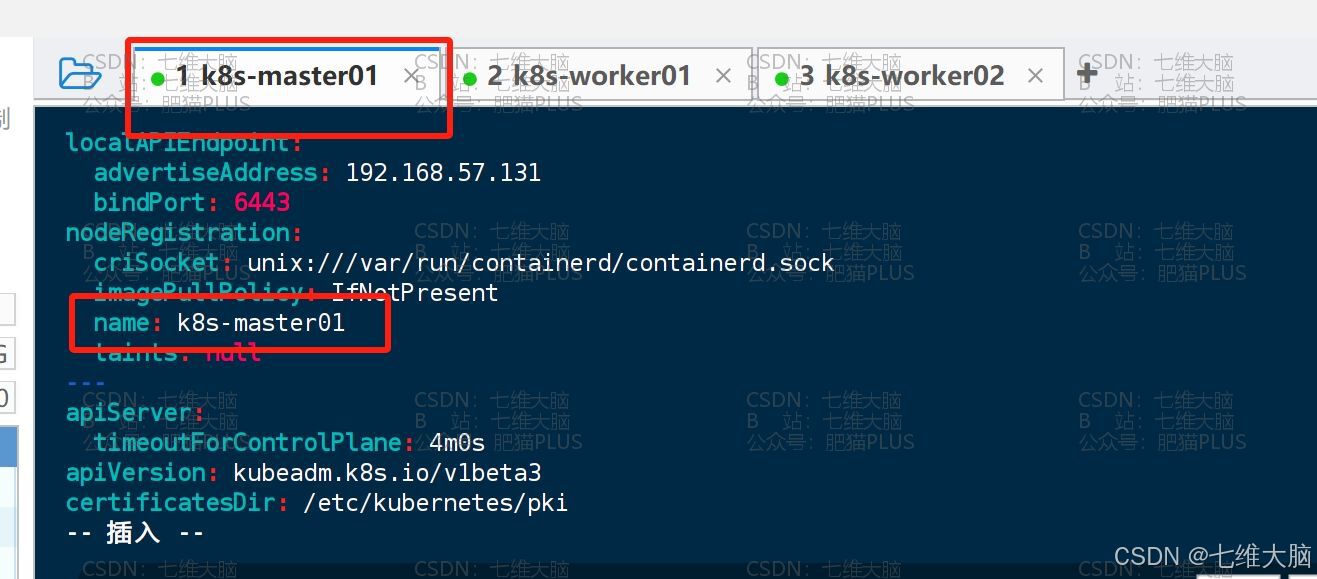
criSocket我们用的就是Containerd可以不用动,你们可以按需修改。imageRepository可以修改为registry.aliyuncs.com/google_containers阿里云镜像仓库,也可以默认,都可以。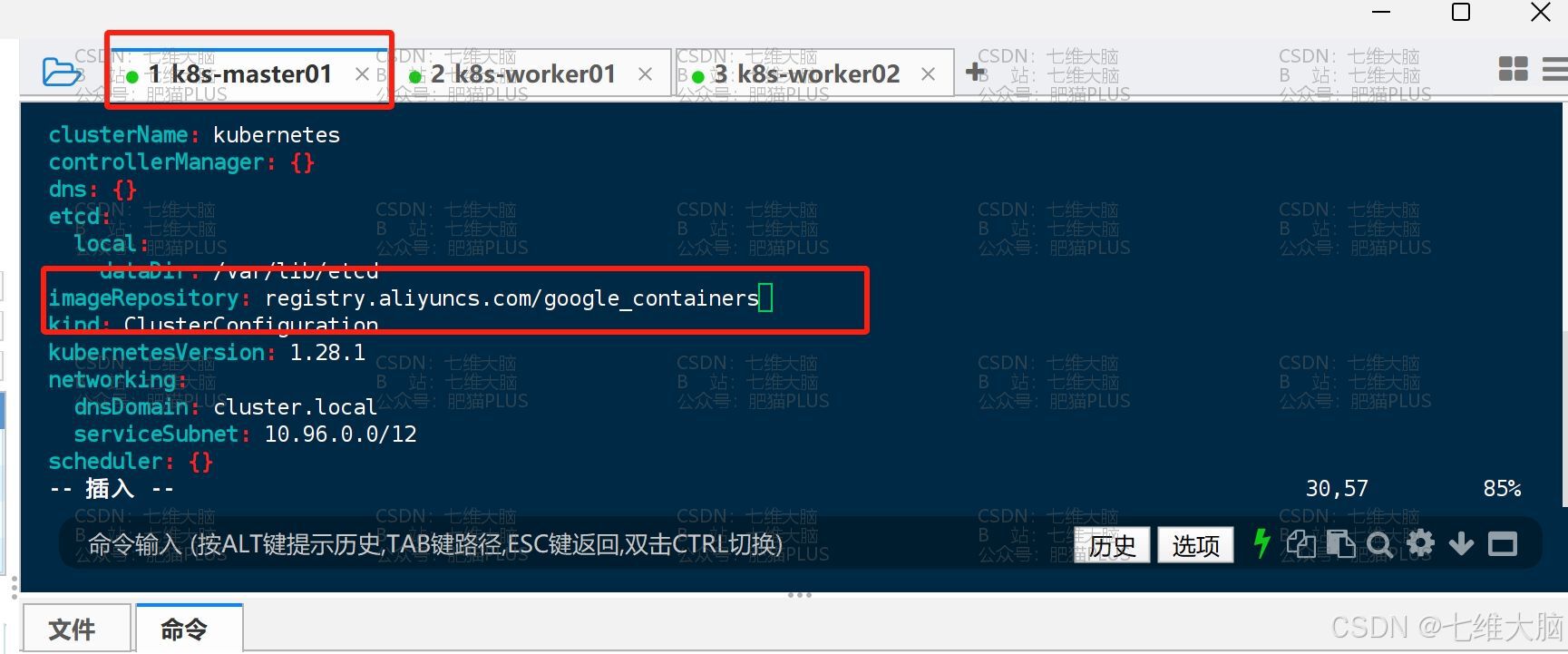
如果更改了镜像地址,那么还需要同步修改/etc/containerd/config.toml文件:vim /etc/containerd/config.toml(三台主机都需要修改这个文件,我这里只截图了一个)
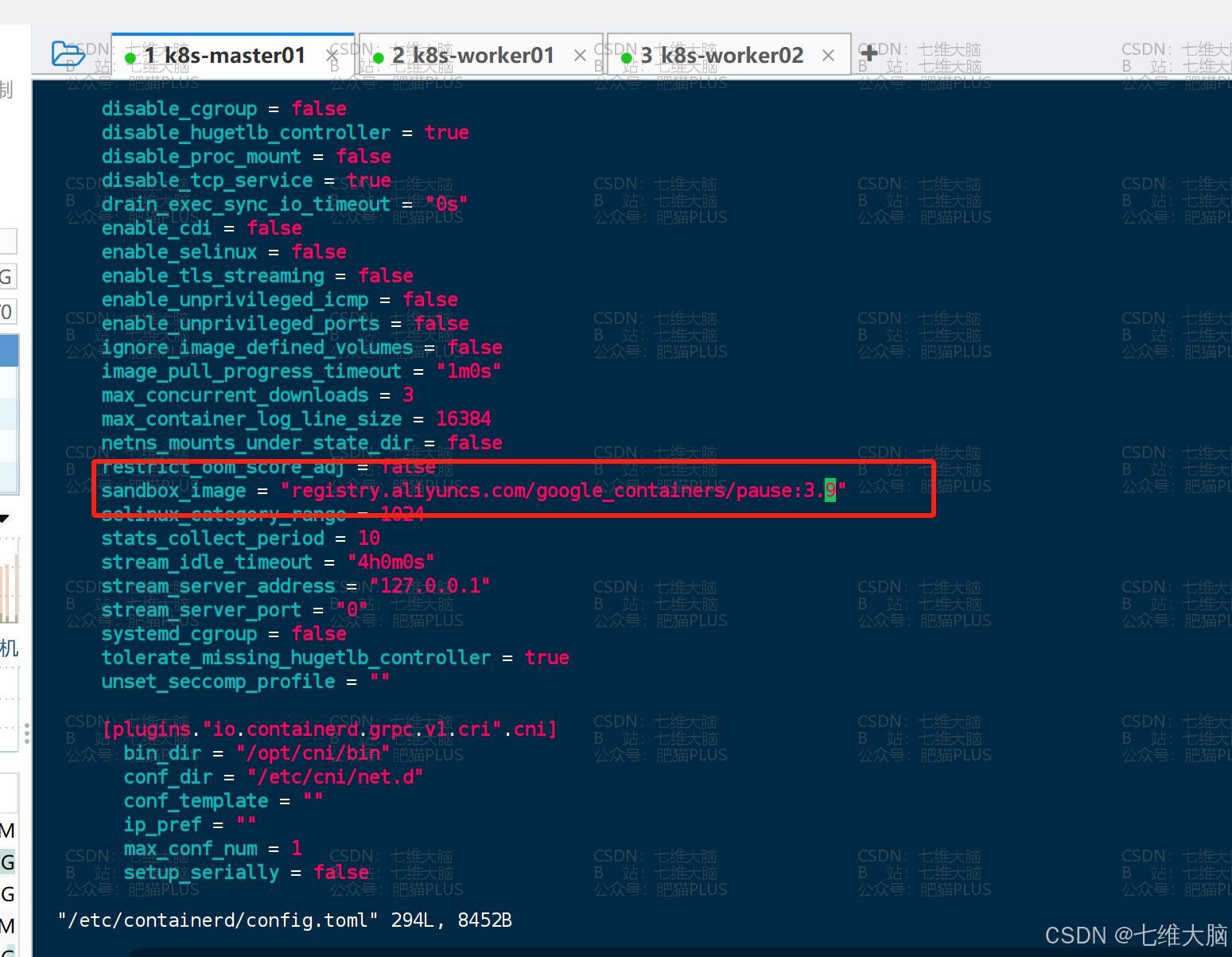
修改完以后,要分别执行以下命令重新启动
containerd和kubeletsystemctl restart containerd systemctl restart kubelet


kubernetesVersion修改为我们当前的版本1.28.1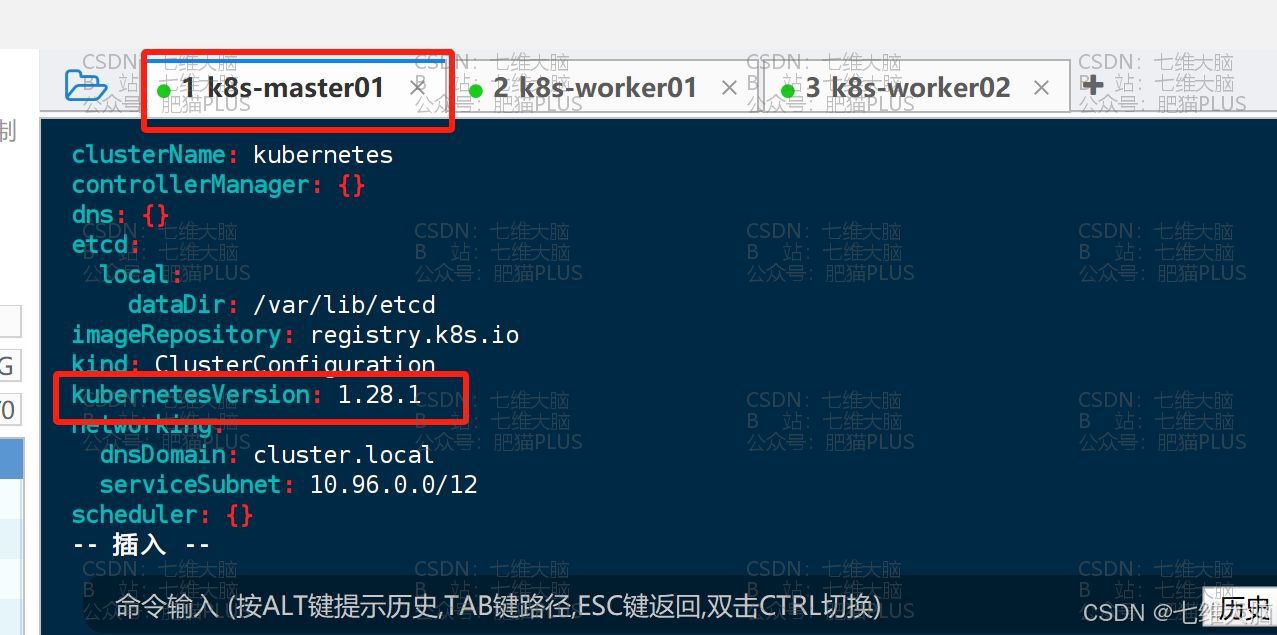
networking中的dnsDomain,可以默认,也可以改成你们公司的域名,但不要跟其他人出现重叠。(学习的话无所谓了)在
networking中的serviceSubnet后面加上podSubnet: 10.244.0.0/16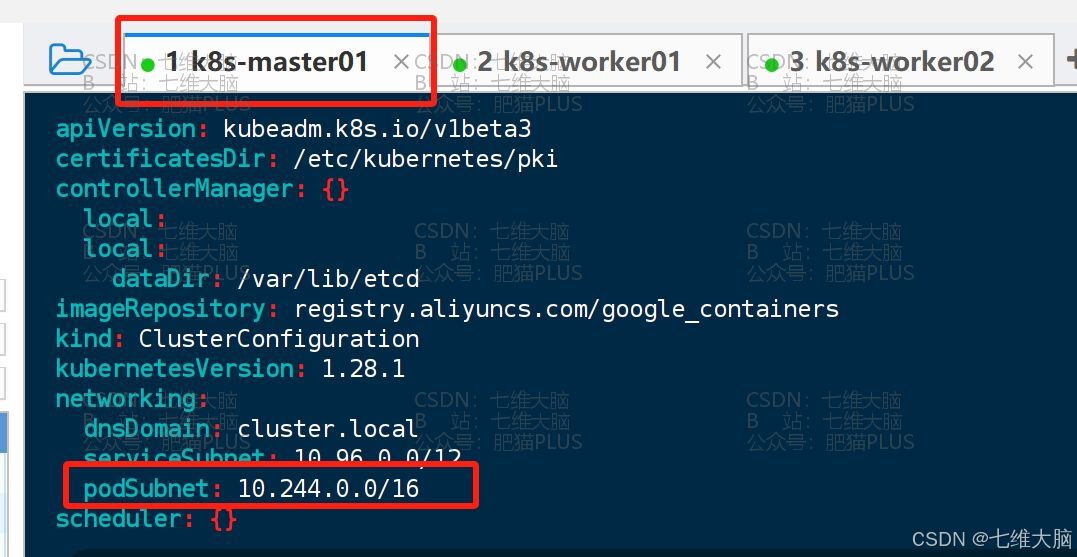
在配置文件最后加入以下配置:
--- kind: KubeletConfiguration apiVersion: kubelet.config.k8s.io/v1beta1 cgroupDriver: systemd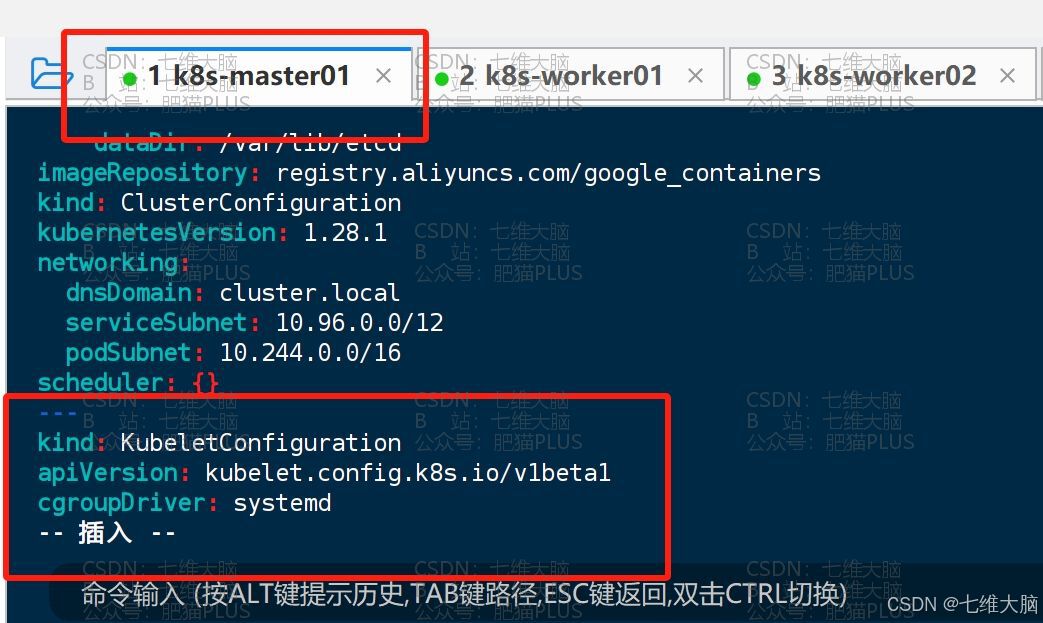
最后保存即可
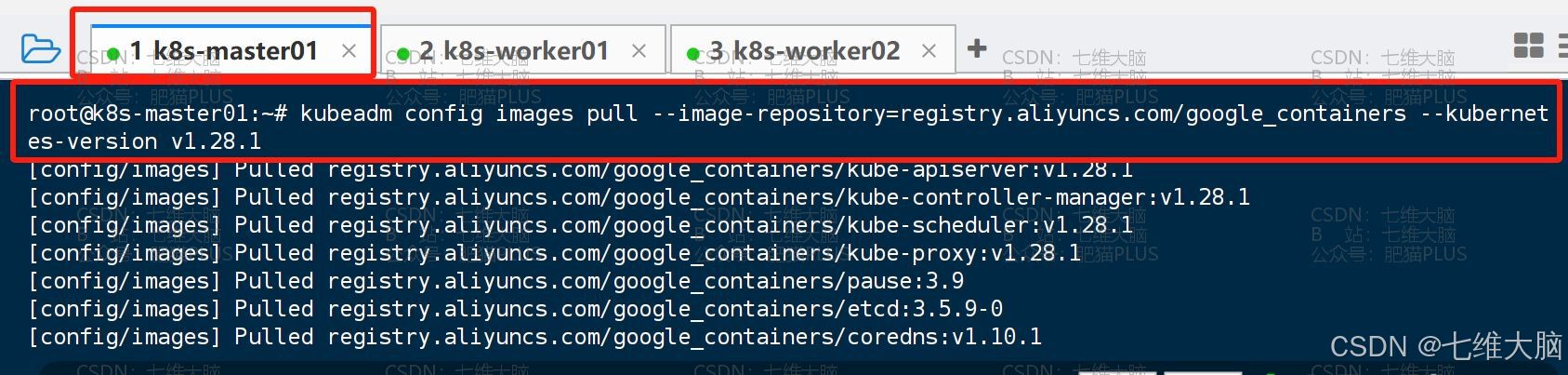
修改保存完以后,我们需要对我们 k8s 中所使用的一些镜像进行提前下载:
(这一步取决于你的网速,网速快下载的也就快,网速慢要等待的时间就越长)
--image-repository的意思是从阿里云的镜像仓库下载(我发现走官方镜像太慢了,所以指定阿里云的仓库了)--kubernetes-version的意思是指定版本(如果你需要最新版可以把这个去掉执行)
kubeadm config images pull --image-repository=registry.aliyuncs.com/google_containers --kubernetes-version v1.28.1 (只对master节点操作)
做完上面的操作以后,我们就可以对 k8s 集群初始化了:
这个过程需要费点时间,耐心等待即可。
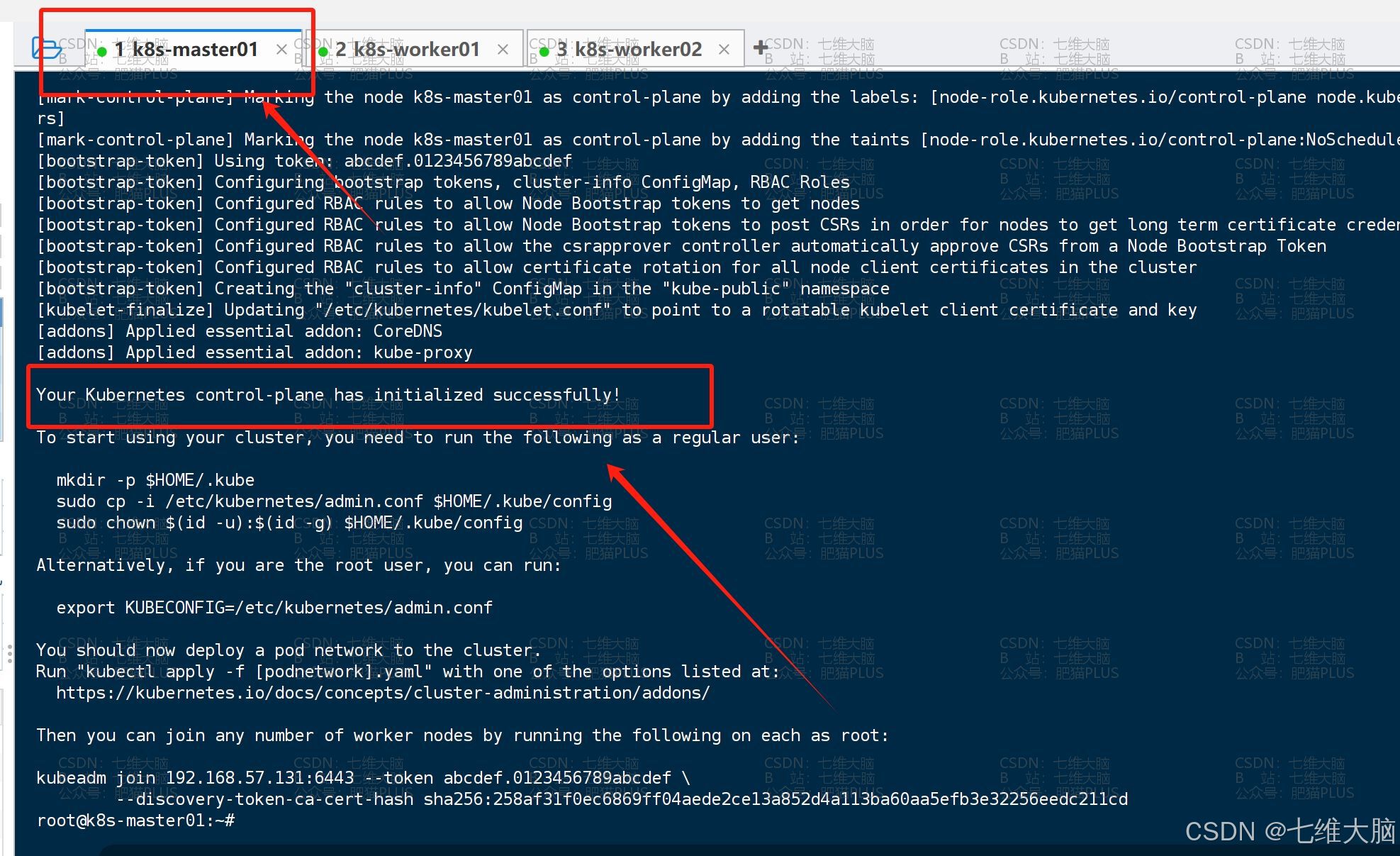
kubeadm init --config kubeadm-config.yaml (只对master节点操作)
最后出现 initialized successfully 就代表初始化成功了:
4.4 准备kubectl配置文件
以下仅针对
master节点的主机,也就是只需要在master节点的主机上操作。如需在其他主机操作,我会特别说明。
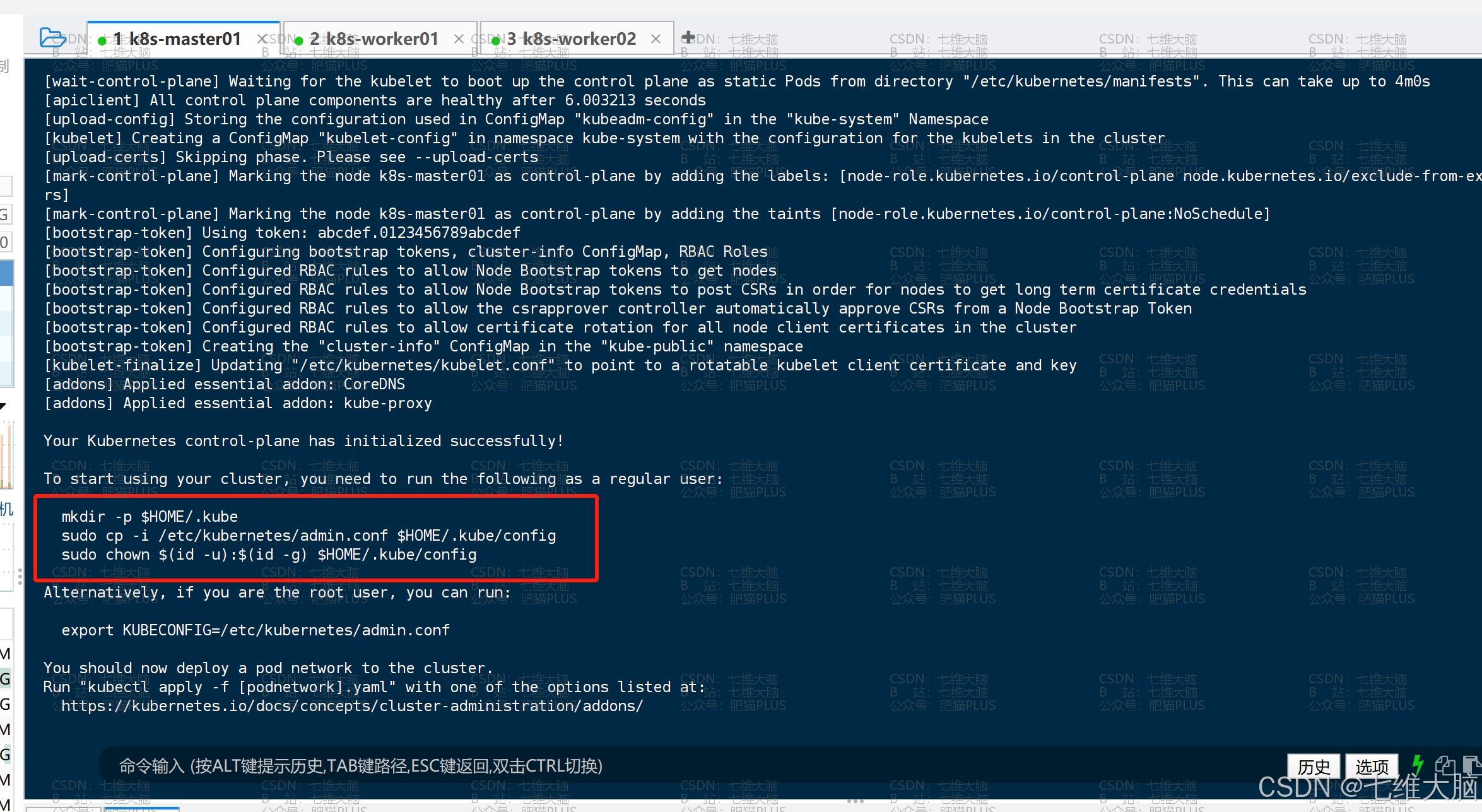
其实很简单,我们只需要把上面输出内容里提供的命令执行一下即可:
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config 然后我们可以使用以下命令查看节点信息了:
kubectl get nodes 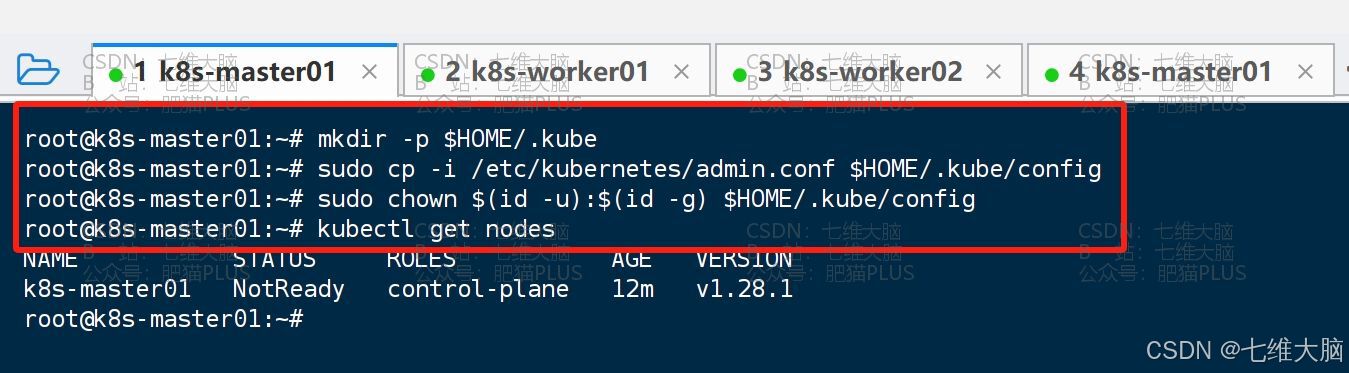
4.5 添加工作节点到集群
我们只需要将之前的输出内容中的命令复制到两个工作节点运行即可: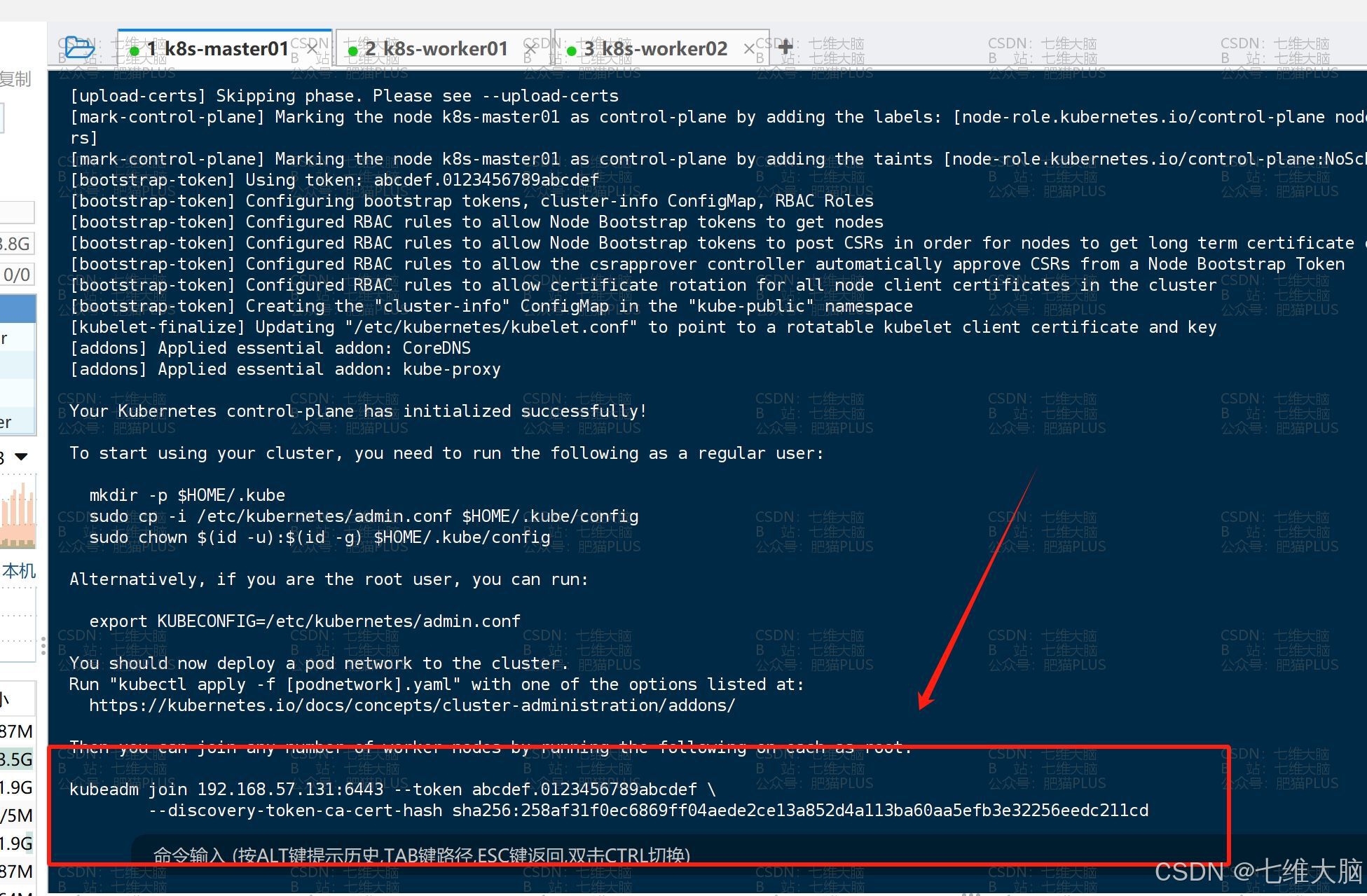
(你不要复制我的,自己往上面的输出内容中找!!)
kubeadm join 192.168.57.131:6443 --token abcdef.0123456789abcdef \ --discovery-token-ca-cert-hash sha256:258af31f0ec6869ff04aede2ce13a852d4a113ba60aa5efb3e32256eedc211cd k8s-worker01
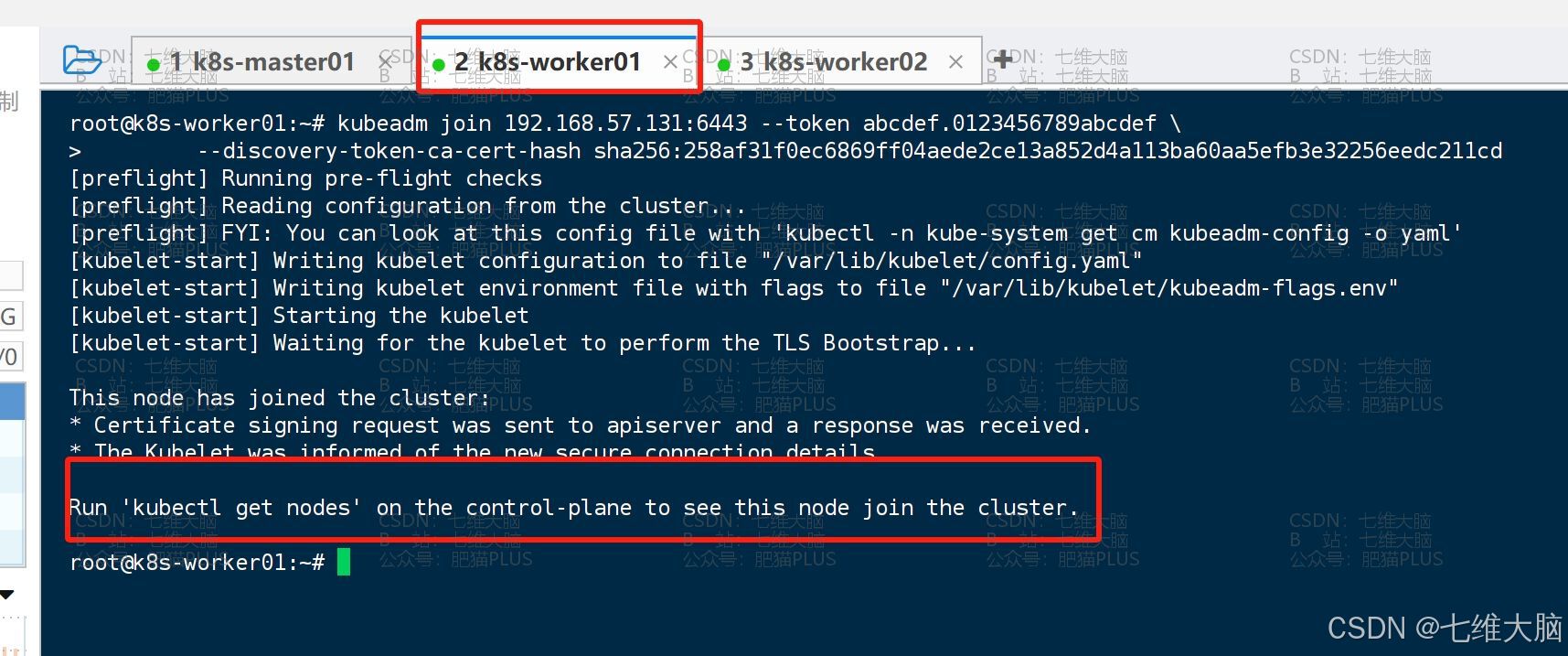
k8s-worker02
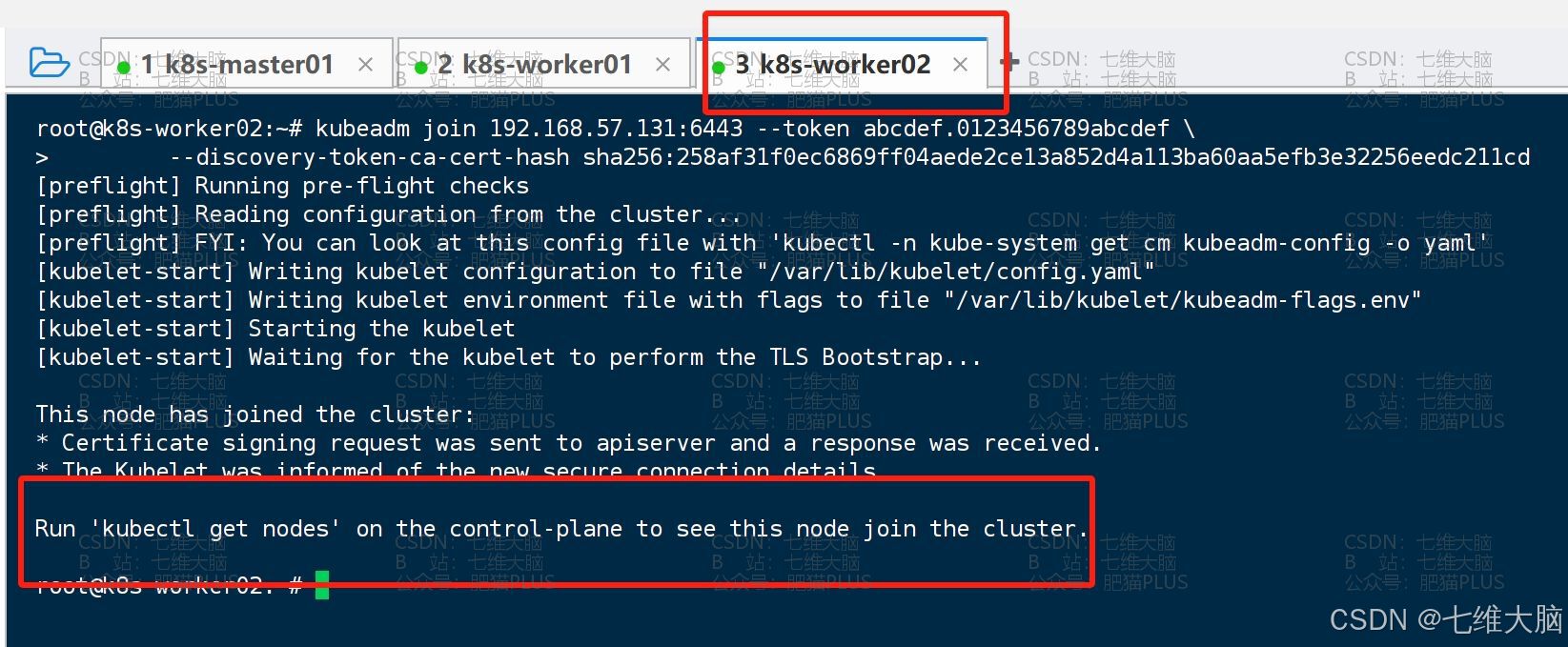
然后我们可以通过以下命令进行验证是否添加成功:
kubectl get nodes 可以看到已经添加成功了:
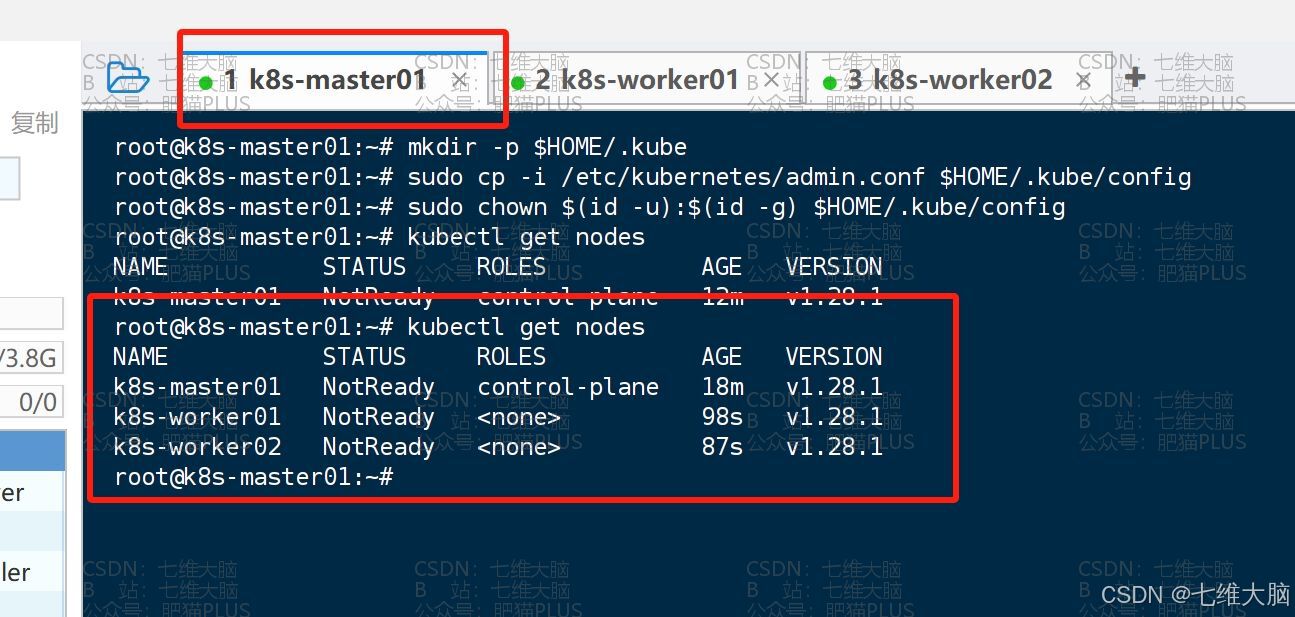
到这里呢,虽然工作节点也加入成功了,但其实也只是初始化成功了,但还不能用,状态还是 NotReady 状态,我们继续往下看。
5. K8S集群网络插件 Calico
我们这里使用的是 Calico ,下面是几个插件的区别:
- Flannel 是个小规模集群
- Calico 既适合小规模也适合大规模,部署也比较容易
- Cilium 对内核的版本要求较高,内核版本必须要达到6.3以上
5.1 operator
执行以下命令进行安装:
(如果需要安装其他版本请访问:https://projectcalico.docs.tigera.io/about/about-calico)
kubectl create -f https://raw.githubusercontent.com/projectcalico/calico/v3.26.1/manifests/tigera-operator.yaml 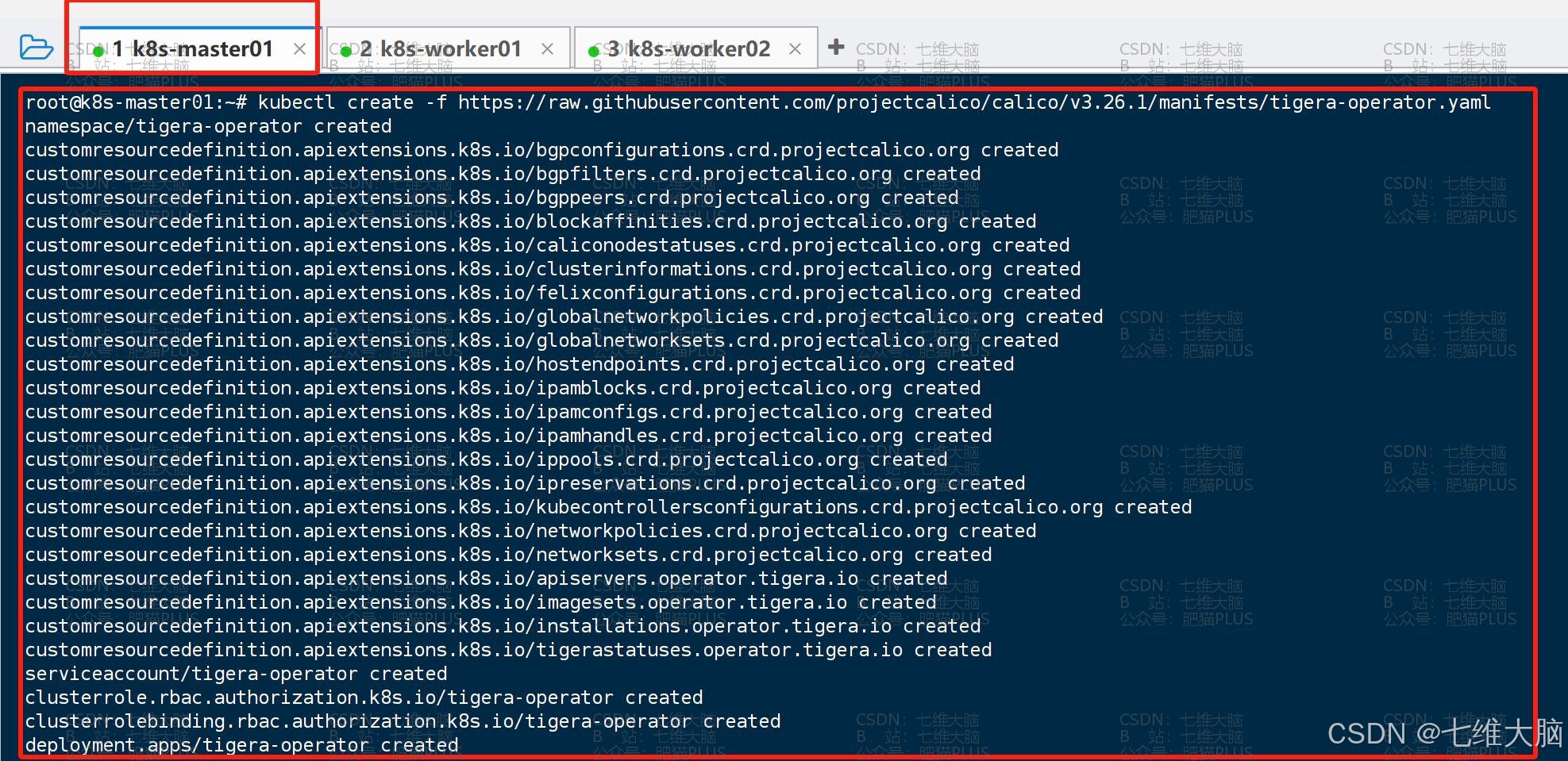
创建完成以后我们可以执行以下命令看下 tigera-operator 是不是已经存在了:
kubectl get ns 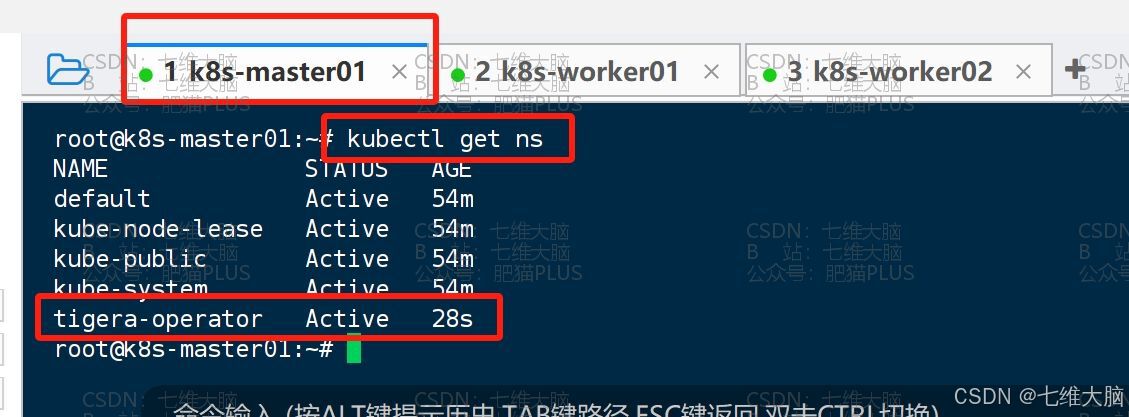
然后看一下我们的pod是不是 Runing 状态了,如果不是后续操作就无法进行了:
kubectl get pods -n tigera-operator 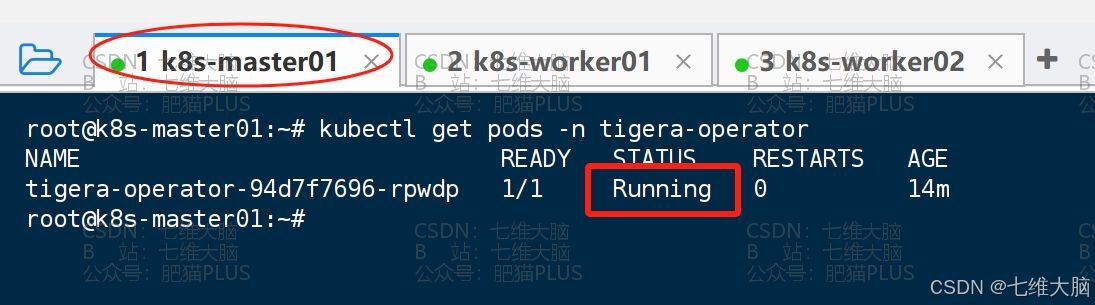
5.2 自定义配置
这里包括要分配的网段、所使用的模式等等,但这里因为我们的集群规模比较小,只要改一下网段即可。
先执行以下命令下载:
(如果需要安装其他版本请访问:https://projectcalico.docs.tigera.io/about/about-calico)
wget https://raw.githubusercontent.com/projectcalico/calico/v3.26.1/manifests/custom-resources.yaml 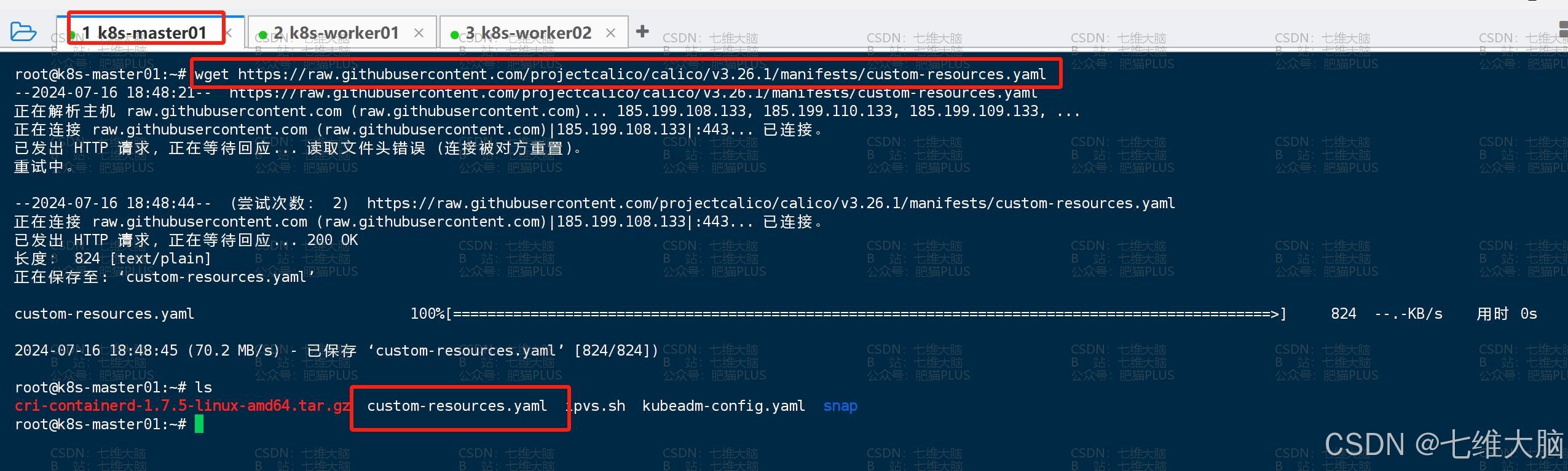
下载以后,首先我们进行网段修改,也就是文件的第13行:
这里就是改成咱们集群初始化的时候指定的网段
vim custom-resources.yaml 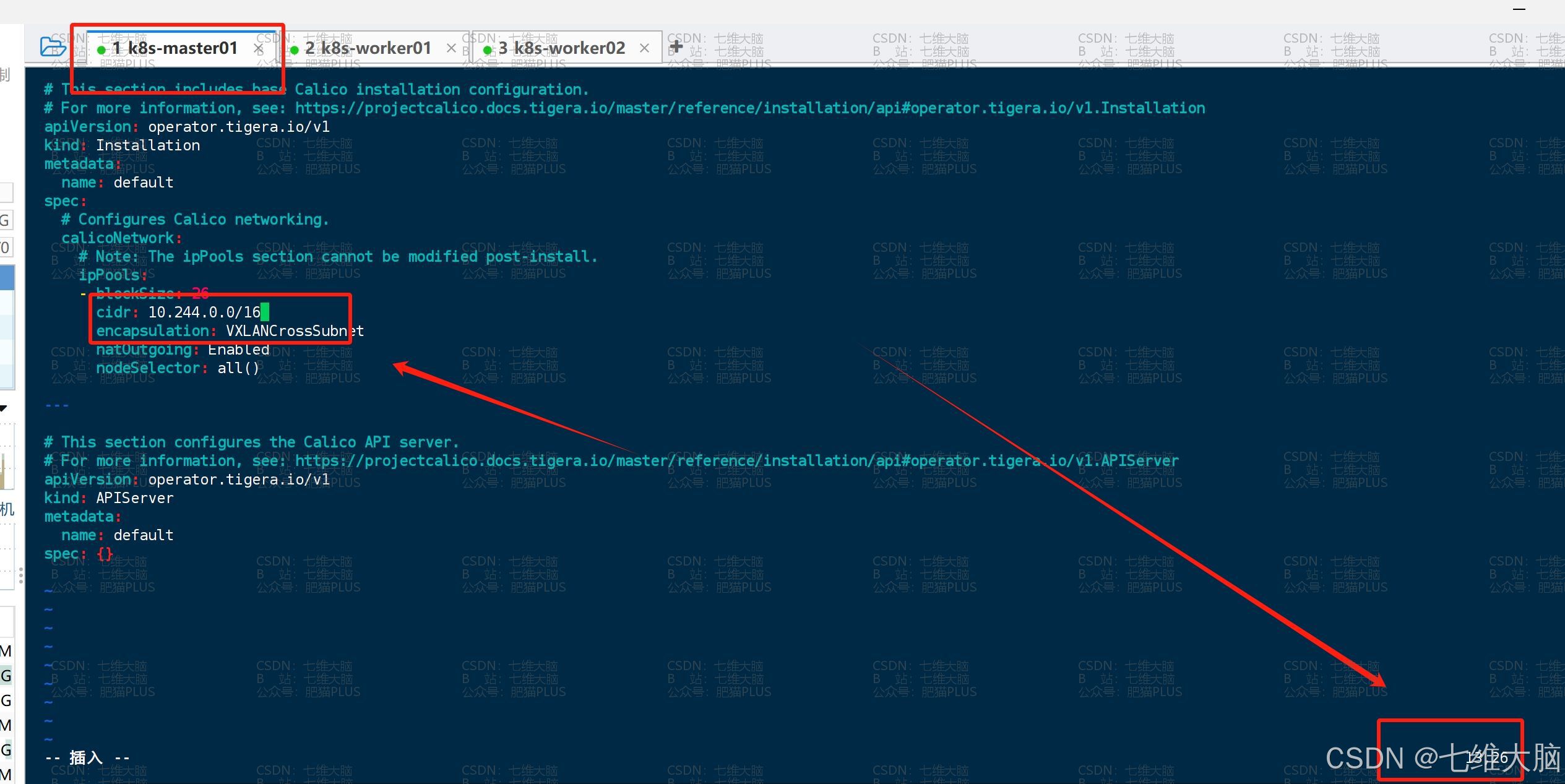
修改完以后,我们要先去手动拉取以下镜像。(三台主机都要拉!!)
这个没办法,我们有堵无形的墙。手动拉一下镜像吧。。(三台主机都要拉!!)
使用 ctr 命令来拉取所用到的镜像,后面的版本好记得改成你自己安装的 calico 版号。(三台主机都要拉!!)
其中 docker.anyhub.us.kg 是一些国内大佬搞得映射(加速),下载速度非常快,如果这个地址不能用了,请访问下方链接查看最新地址:
https://github.com/DaoCloud/public-image-mirror/issues/2328
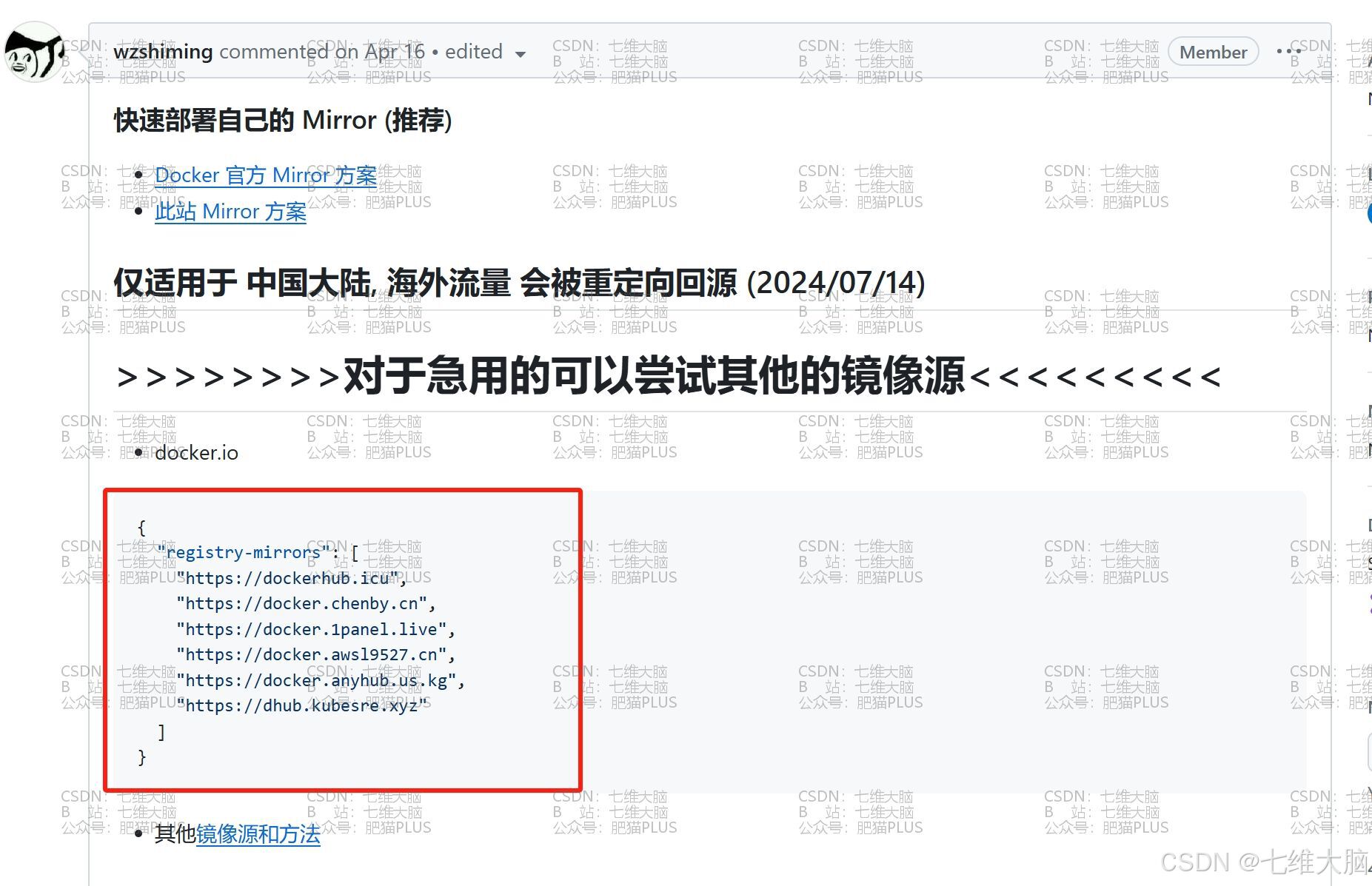
(三台主机都要拉!!)
ctr image pull docker.anyhub.us.kg/calico/cni:v3.26.1 ctr image pull docker.anyhub.us.kg/calico/pod2daemon-flexvol:v3.26.1 ctr image pull docker.anyhub.us.kg/calico/node:v3.26.1 ctr image pull docker.anyhub.us.kg/calico/kube-controllers:v3.26.1 ctr image pull docker.anyhub.us.kg/calico/typha:v3.26.1 ctr image pull docker.anyhub.us.kg/calico/node-driver-registrar:v3.26.1 ctr image pull docker.anyhub.us.kg/calico/csi:v3.26.1 (三台主机都要拉!!我这里只截图了master的主机,全截太多了!!)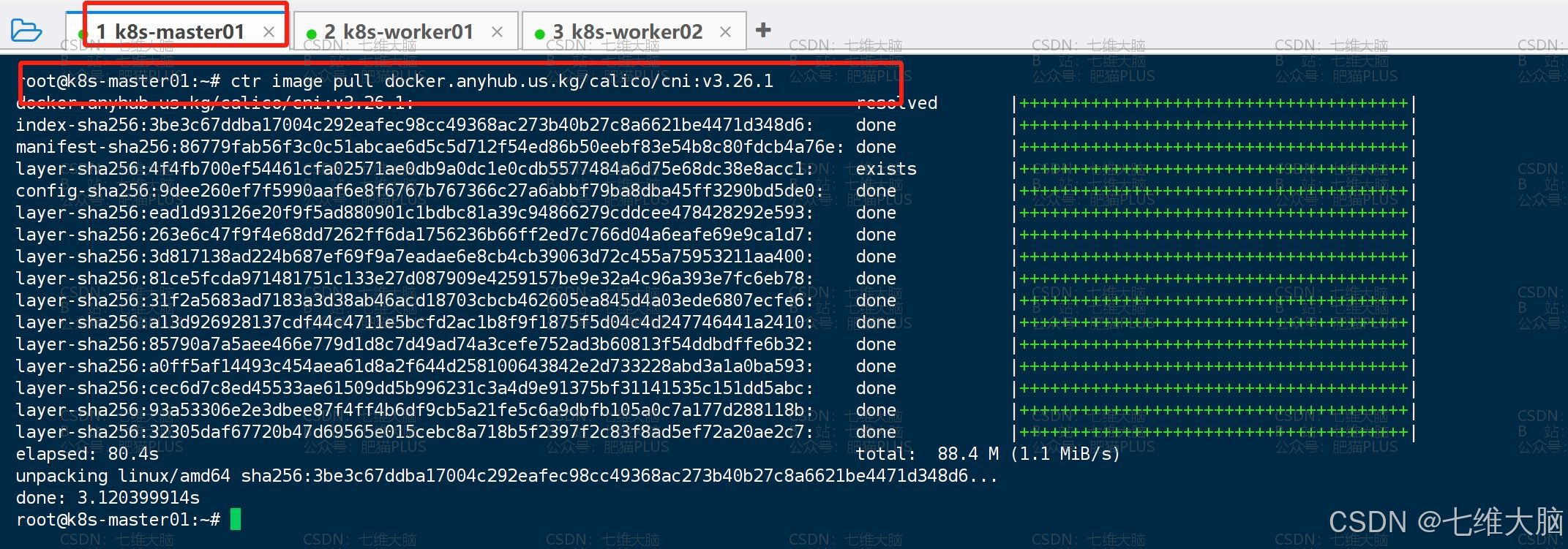
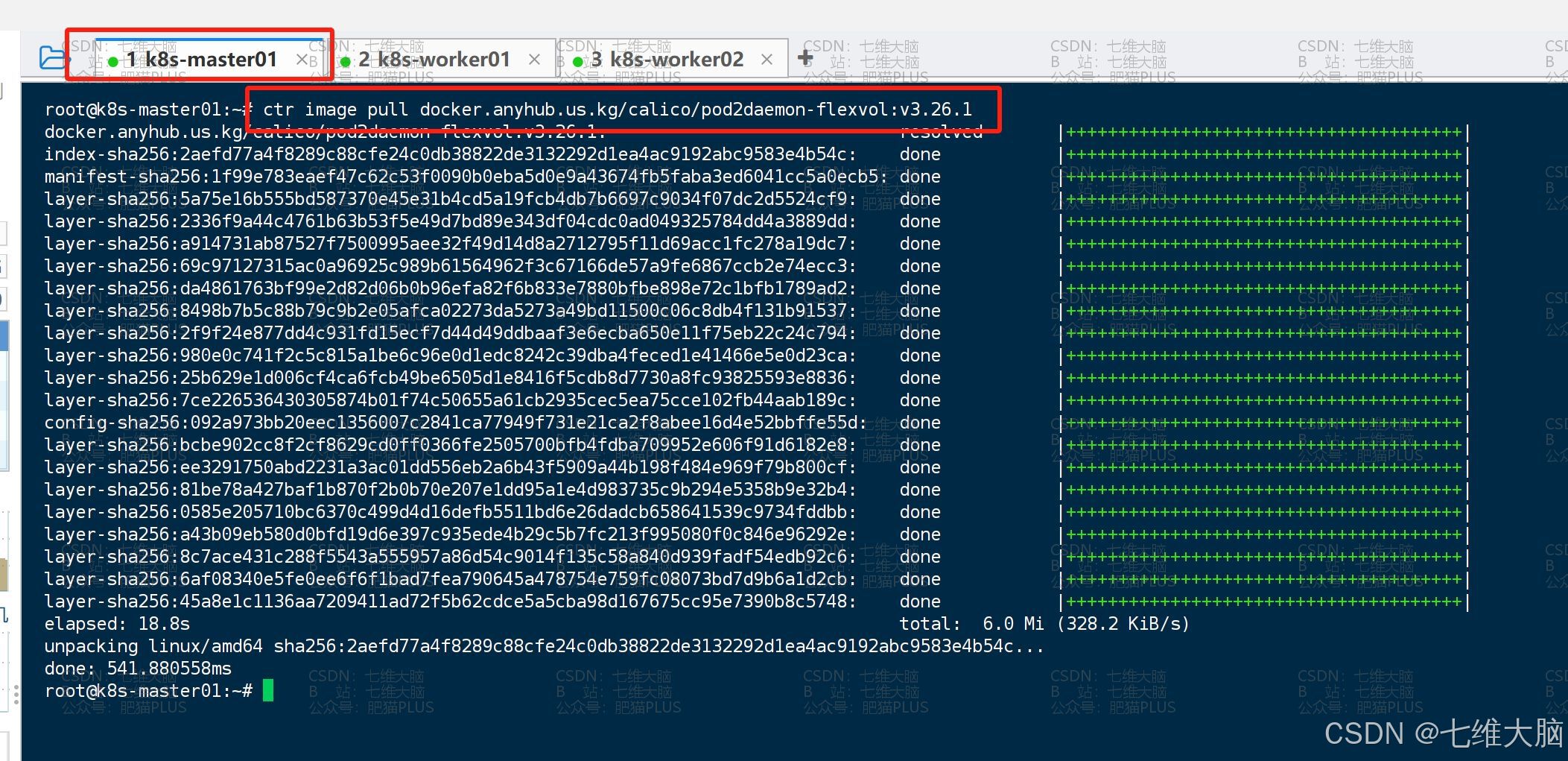
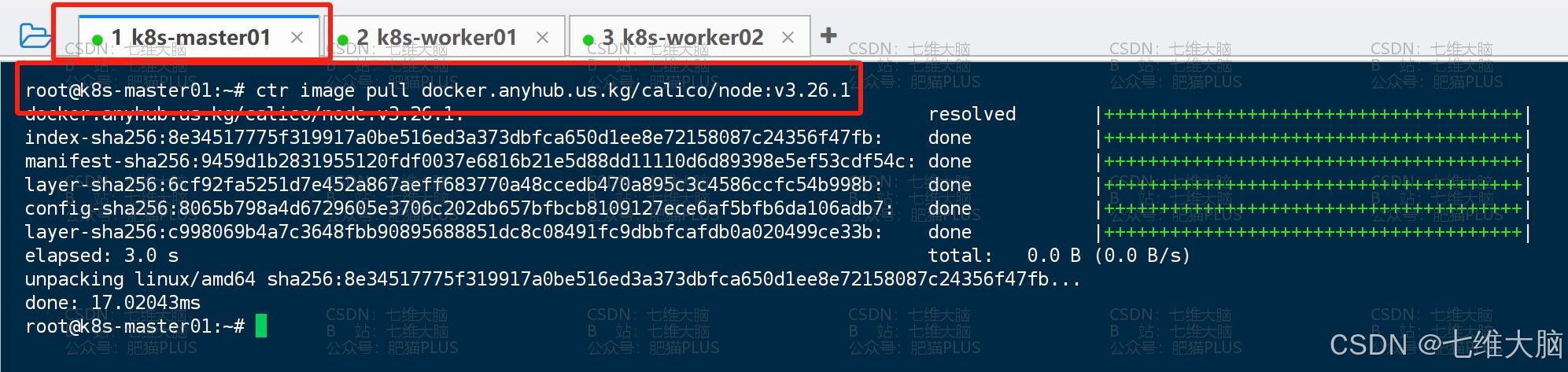

下载完成以后,我们可以通过 ctr image list命令查看镜像列表:
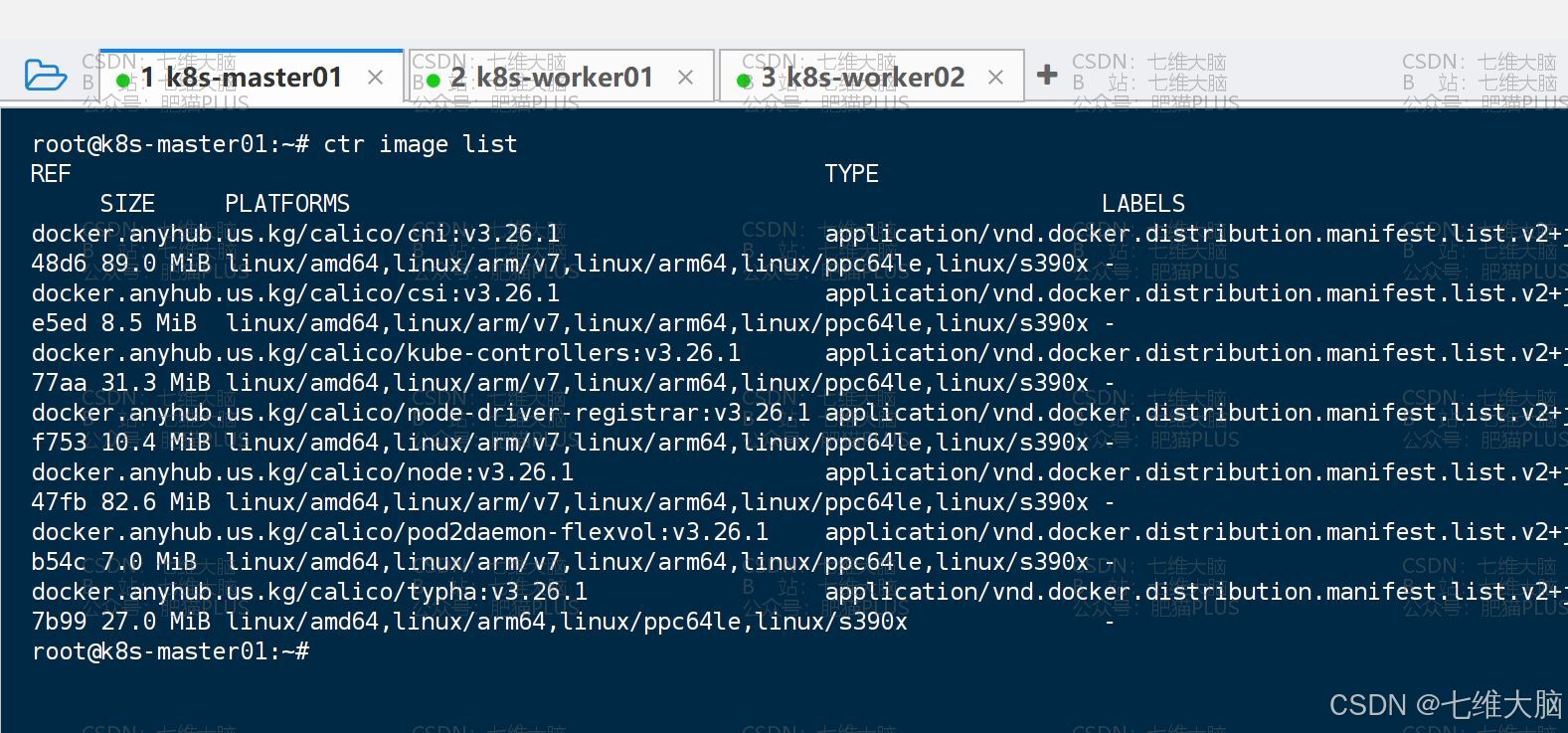
(一定要确定三台主机都拉下来了!!) 确定上面 7个镜像 都已经下载了,我们给 custom-resources.yaml 应用一下:
kubectl create -f custom-resources.yaml 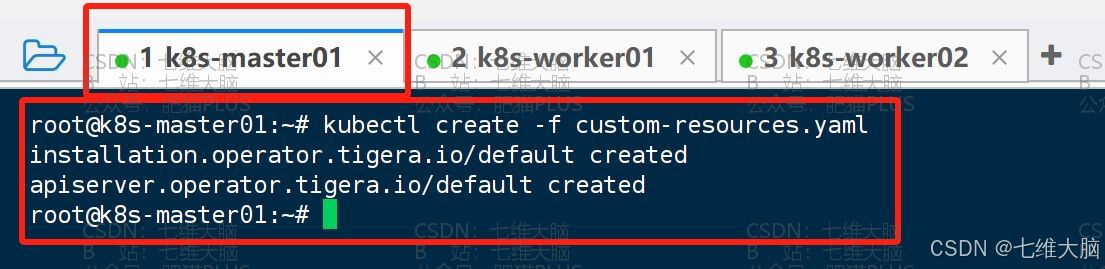
执行完以后,我们再执行以下命令,就能看到 calico-system 命名空间了:
kubectl get ns 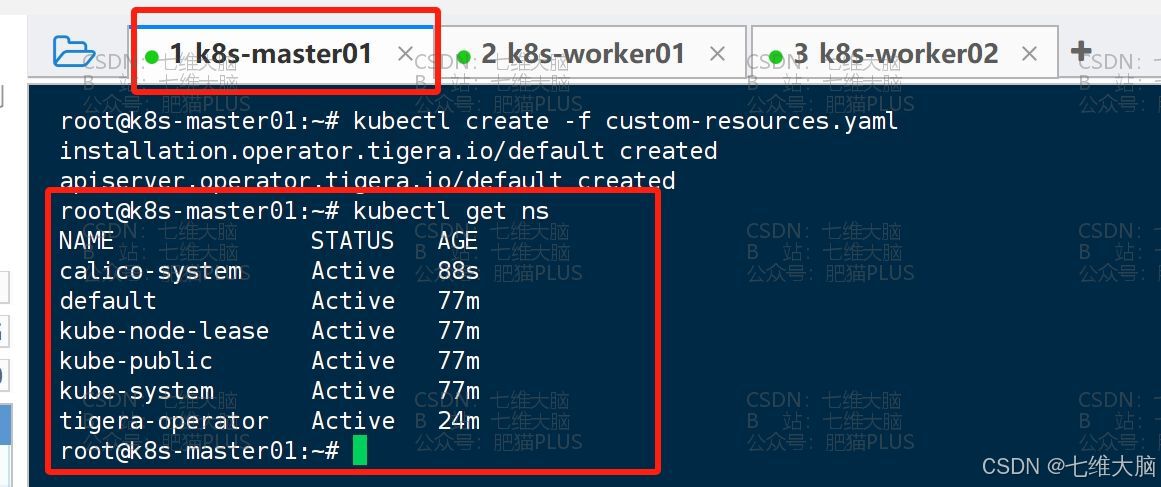
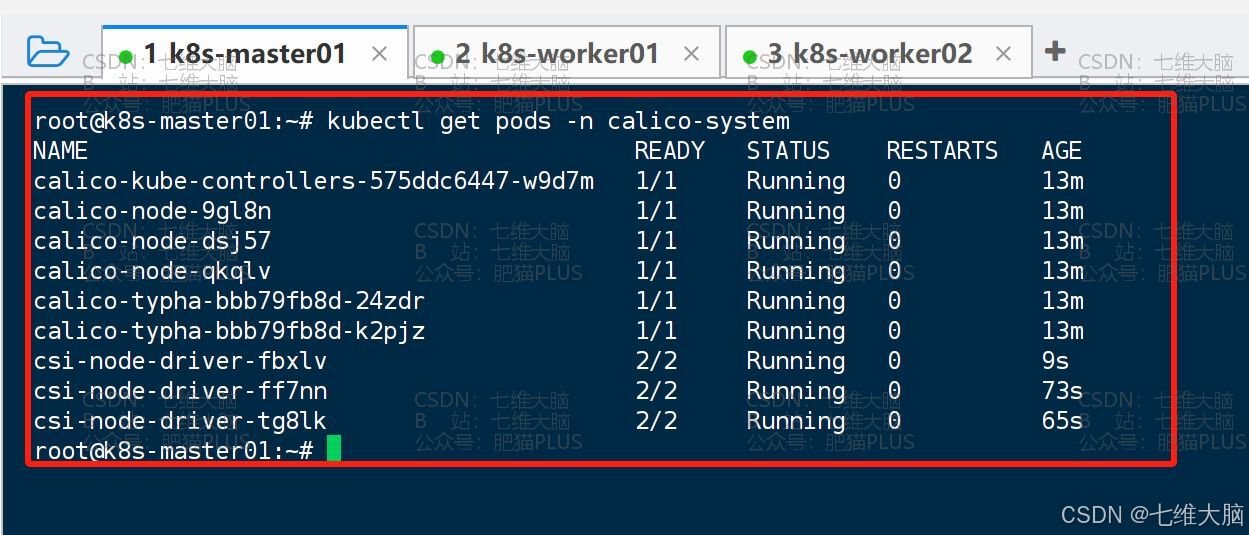
然后我们等待大约2-3分钟的时间,再通过以下命令来查看一下pod的状态:
kubectl get pods -n calico-system 然后就可以看到 ,所有的 pod 都是 Runing 状态了:
然后我们再运行查看节点信息的命令,就会发现状态已经变成 Ready 状态了:
kubectl get nodes 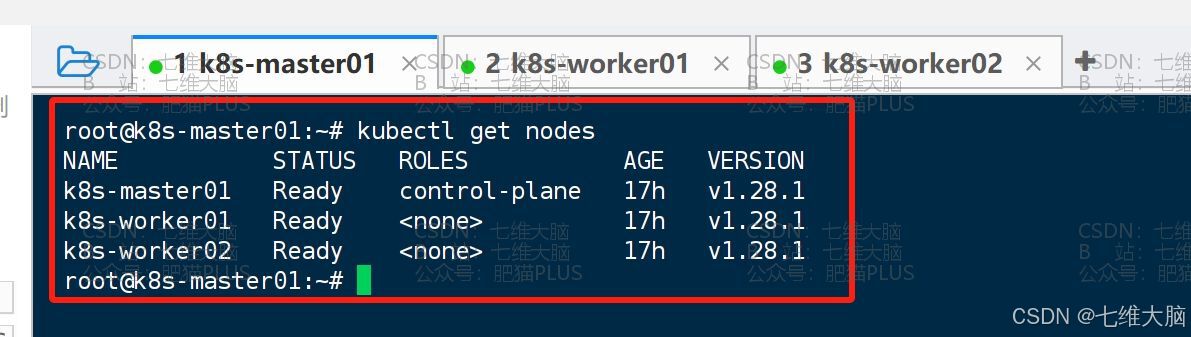
5.3 错误解答
如果出现 Init:ErrImagePull 或者 Init:ImagePullBackOf,那就是上面我提到的7个镜像没拉下来!
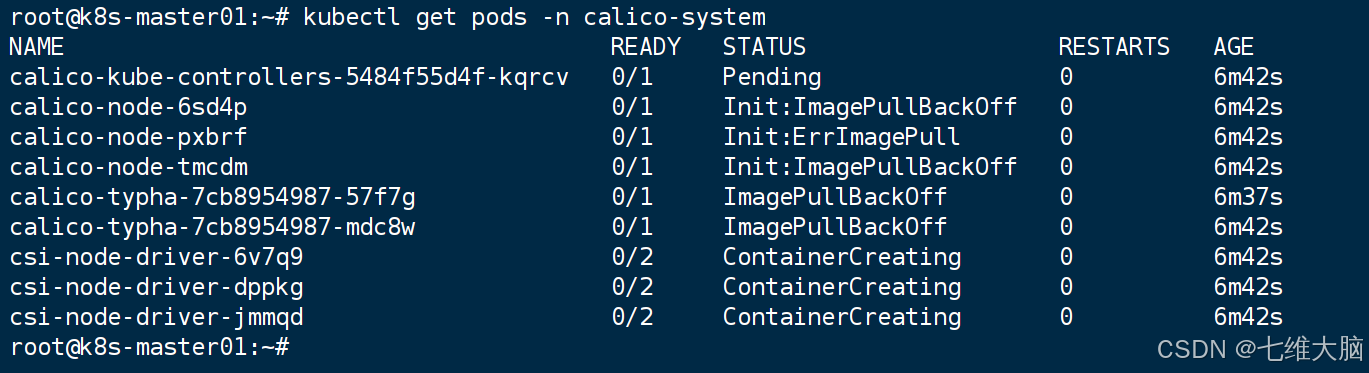
解决方法:把缺失的镜像重新拉一下!
(三台主机都要拉!!)
ctr image pull docker.anyhub.us.kg/calico/cni:v3.26.1 ctr image pull docker.anyhub.us.kg/calico/pod2daemon-flexvol:v3.26.1 ctr image pull docker.anyhub.us.kg/calico/node:v3.26.1 ctr image pull docker.anyhub.us.kg/calico/kube-controllers:v3.26.1 ctr image pull docker.anyhub.us.kg/calico/typha:v3.26.1 ctr image pull docker.anyhub.us.kg/calico/node-driver-registrar:v3.26.1 ctr image pull docker.anyhub.us.kg/calico/csi:v3.26.1 (三台主机都要拉!!我这里只截图了master的主机,全截太多了!!)
下载完成以后,我们可以通过 ctr image list命令查看镜像列表:
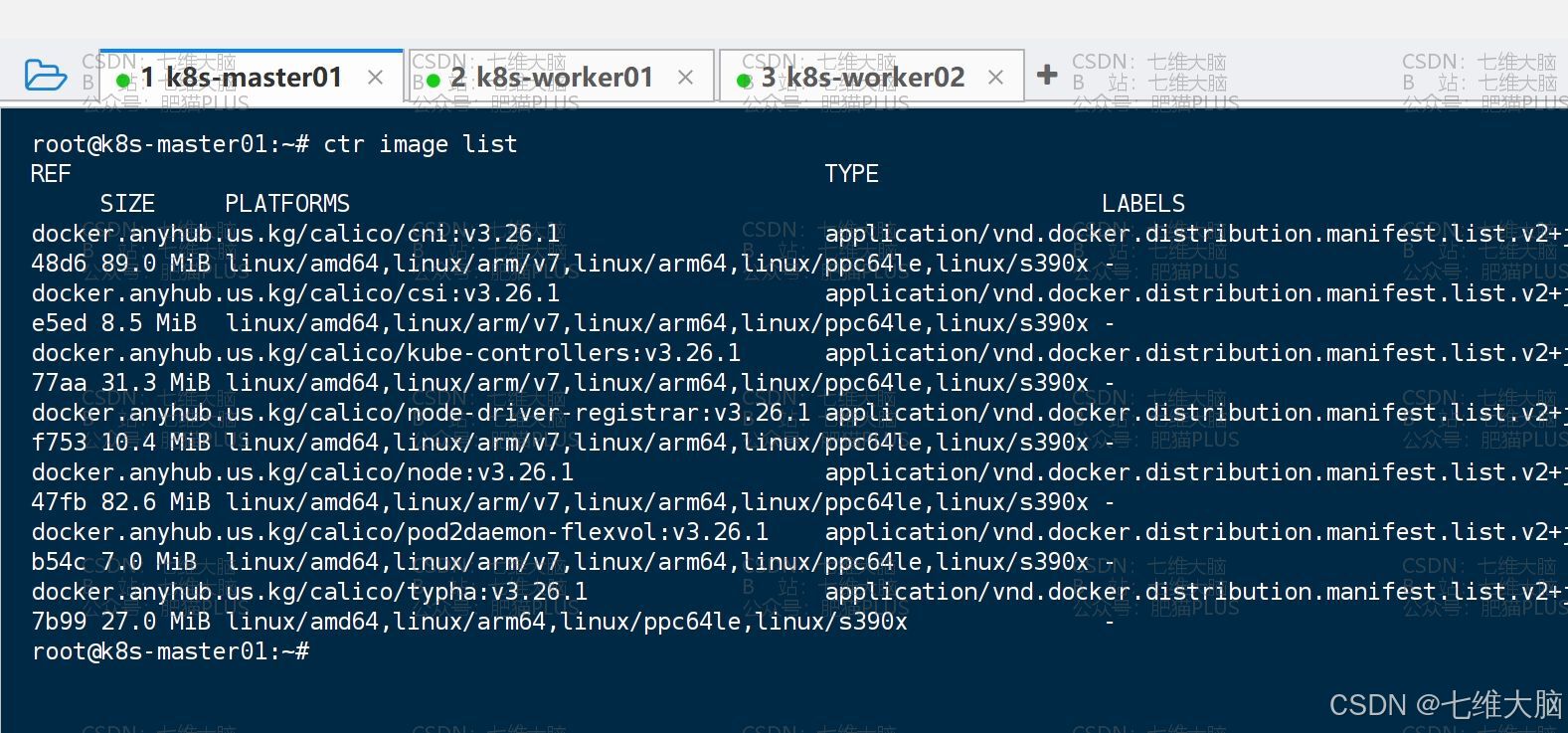
确定上面7个镜像都有了以后,我们需要删除所有有问题的 pod,也就是上面状态为 Init:ErrImagePull 和Init:ImagePullBackOf的 pod,以上图为例,我举几个栗子:
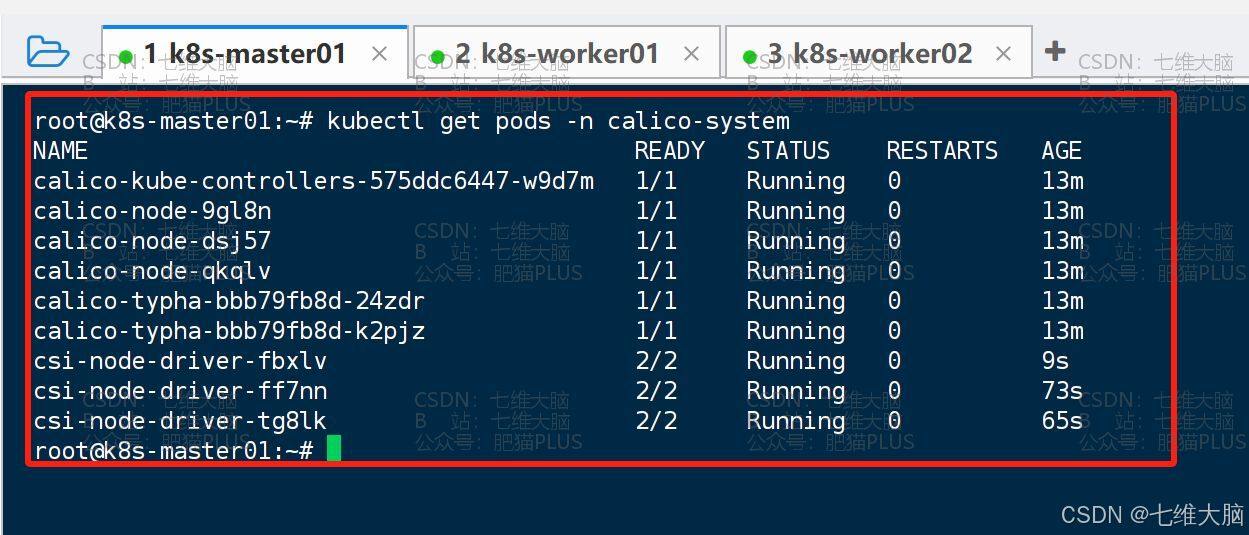
kubectl delete pod calico-node-6sd4p -n calico-system kubectl delete pod calico-node-pxbrf -n calico-system kubectl delete pod calico-node-tmcdm -n calico-system 确定所有有问题的pod都删除以后,我们等待个2-3分钟再执行以下命令
kubectl get pods -n calico-system 然后就可以看到 ,所有的 pod 都是 Runing 状态了
6. 部署Nginx测试验证K8S集群是否可用
上面我们已经部署完了K8S集群,那到底能不能用呢?下面我们就来部署一个简单的 Nginx 来测试一下。
首先我们来创建一个 Nginx 的 Deployment:
vim nginx-deployment.yaml 复制下面的配置到 nginx-deployment.yaml (注意缩进!!!),保存退出即可:
--- apiVersion: apps/v1 kind: Deployment metadata: name: nginxweb # 部署的名称 spec: replicas: 2 # 设置副本数量为2 selector: matchLabels: app: nginxweb1 # 用于选择匹配的Pod标签 template: metadata: labels: app: nginxweb1 # Pod的标签 spec: containers: - name: nginxwebc # 容器名称 image: registry.cn-hangzhou.aliyuncs.com/acs-sample/nginx:latest # 镜像拉取地址,换成阿里云的,不然会拉取失败 imagePullPolicy: IfNotPresent # 镜像拉取策略,如果本地没有就拉取 ports: - containerPort: 80 # 容器内部监听的端口 --- apiVersion: v1 kind: Service metadata: name: nginxweb-service # 服务的名称 spec: externalTrafficPolicy: Cluster # 外部流量策略设置为集群 selector: app: nginxweb1 # 用于选择匹配的Pod标签 ports: - protocol: TCP # 使用TCP协议 port: 80 # 服务暴露的端口 targetPort: 80 # Pod中容器的端口 nodePort: 30080 # 在每个Node上分配的端口,用于外部访问 type: NodePort # 服务类型,使用NodePort 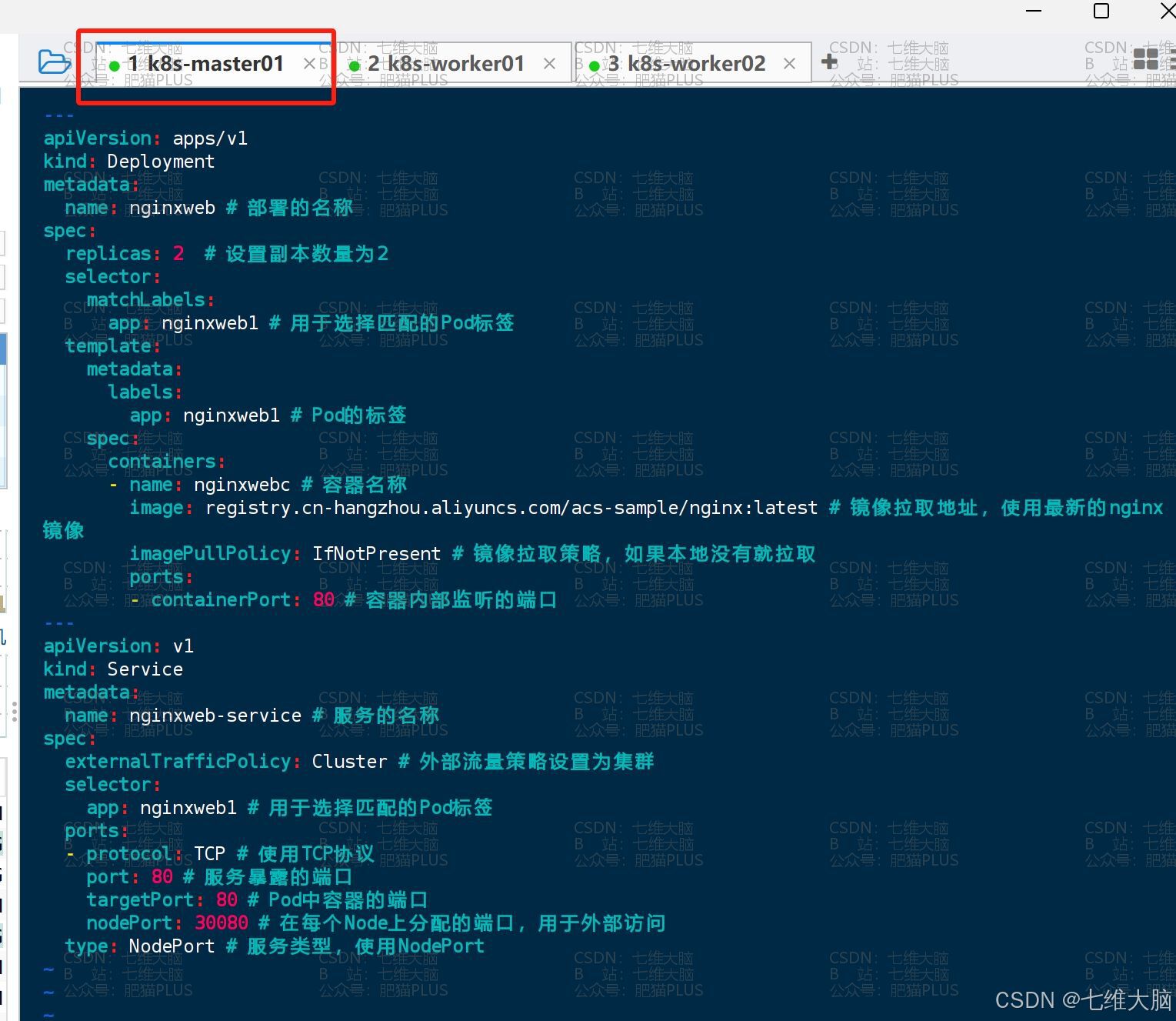
然后咱们再使用以下命令应用一下:
kubectl apply -f nginx-deployment.yaml 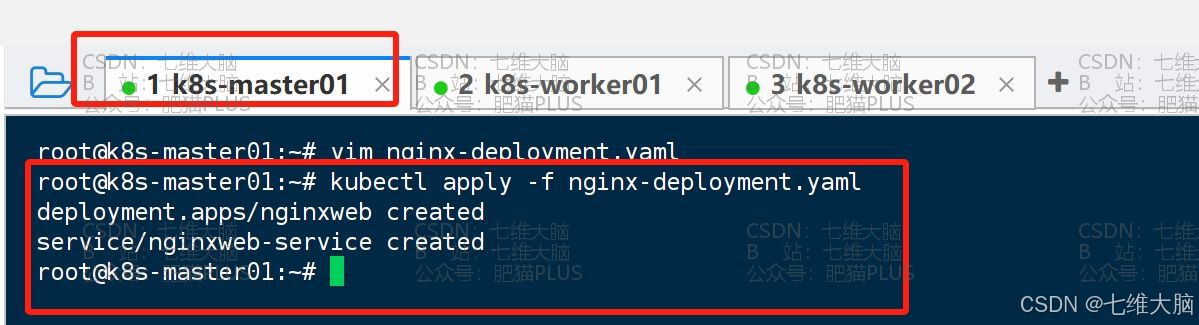
应用以后,我们等待个几分钟然后通过以下命令来查看以下是否已经生成了 pod,并且是否已经处于 Runing 状态了 :
kubectl get pods 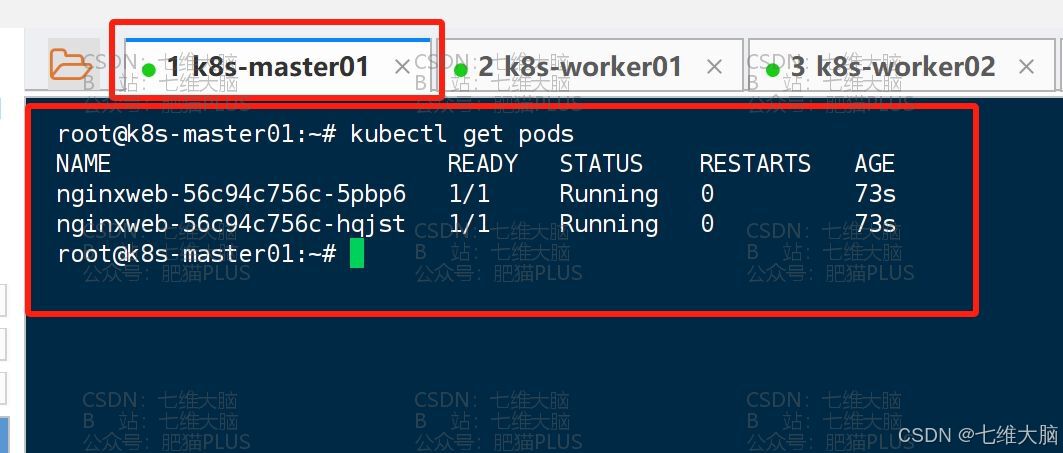
同时也会为生成的 pod 创建对应的 service,我们可以通过以下命令查看:
service就是我们通过service的ip地址或者service名称对我们pod进行访问的方法,防止我们pod出现故障以后,我们没办法再找到这个pod
kubectl get service 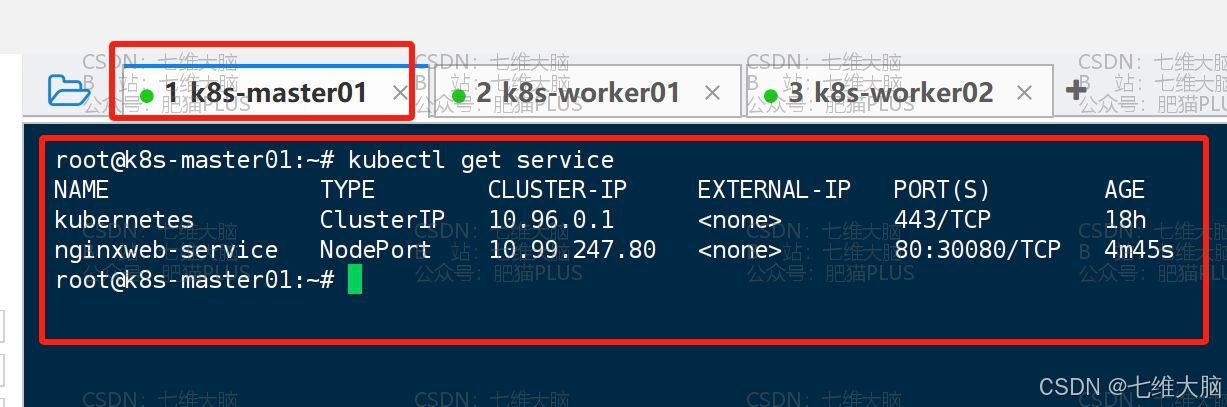
除了在k8s集群内通过service访问外,我们还可以在k8s集群外通过我们k8s集群的任意一个节点的IP地址加上他的30080端口(nginx-deployment.yaml文件中定义的)访问。
下面我们就直接对pod进行访问测试,首先要获取对应的IP地址:
kubectl get pods -o wide 
获取到IP地址以后,我们就可以直接通过 curl 命令进行访问:
curl http://10.244.69.203 curl http://10.244.79.71 我们可以看到已经出现了我们熟悉的 Welcome to nginx!:
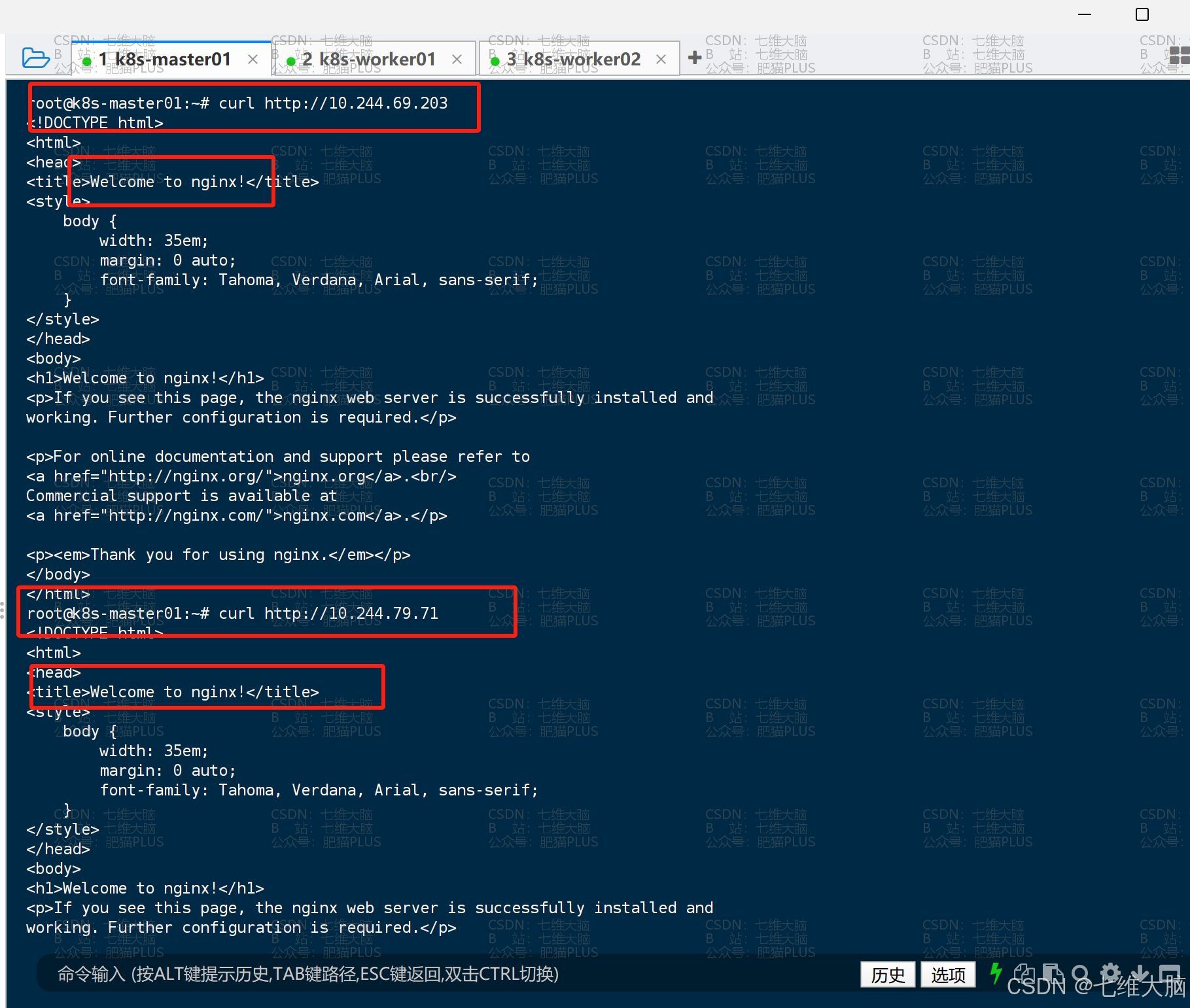
然后我们再对service进行访问测试,一样是要先获取对应的IP地址:
kubectl get service 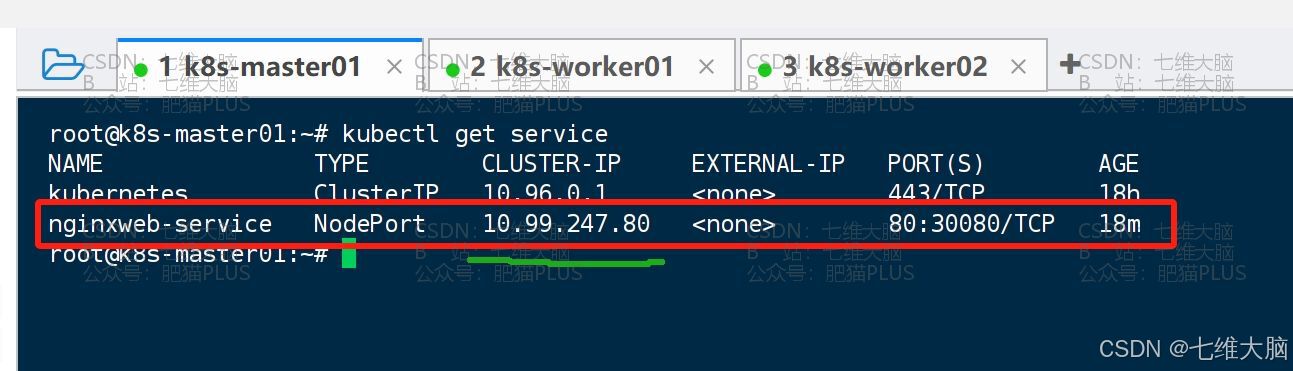
获取到IP地址以后,我们同样通过 curl 命令进行访问:
curl http://10.99.247.80 也是出现了我们熟悉的 Welcome to nginx!,没有问题:
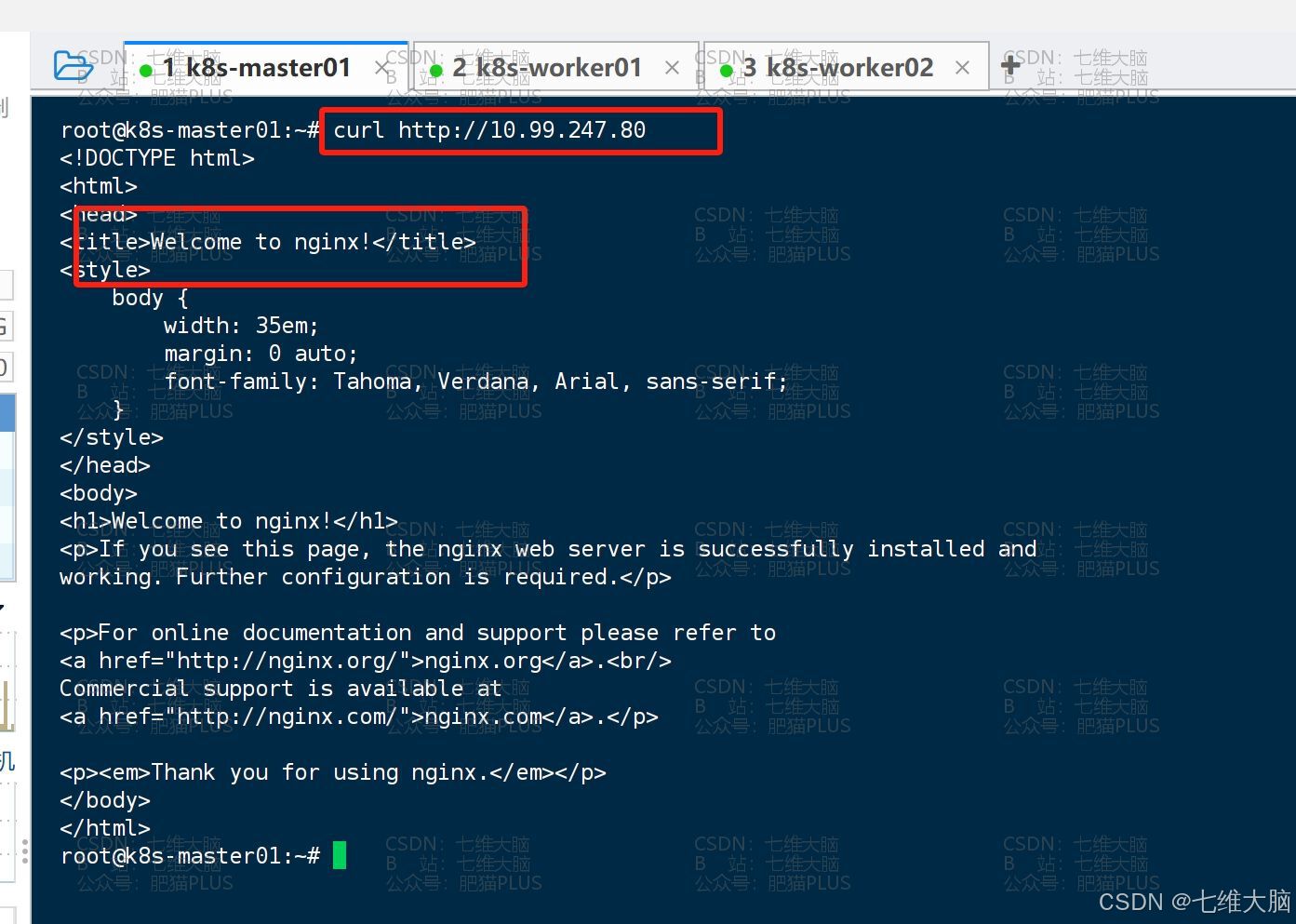
但通过service访问,具体访问的是哪个节点呢?这就取决于我们service在调度的过程中的访问策略了,他具有负载均衡的能力。
最后,我们再验证一下从k8s集群外进行访问,首先打开我们物理机(也就是本机电脑)的浏览器,然后输入我们各个节点的ip加上30080端口,进行测试访问:
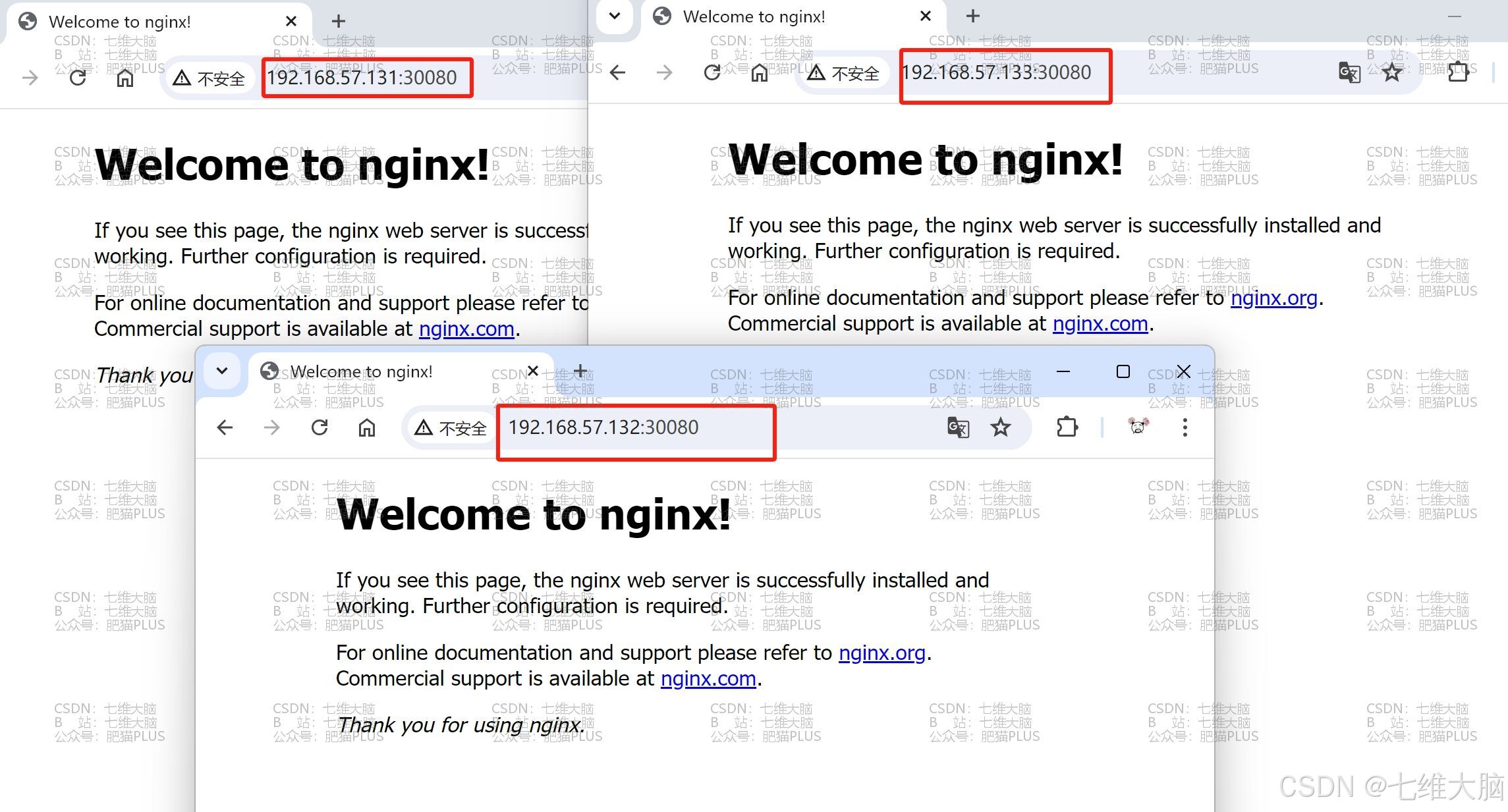
到此,结束。
帮到你的话,请点赞、收藏、关注!谢谢啦!
B站搜索:
七维大脑
抖音搜索:七维大脑
公众号搜索:肥猫PLUS
