
阅读量:0
引言
临近毕业季,想必很多今年毕业的朋友们最近都在焦头烂额地忙着撰写论文吧。那么如何高效地了解研究领域的热点问题,学习优秀论文解决问题的思路和方法呢?我们可以使用“知网”这个众所周知的平台来进行文献的检索与阅读。使用python可以更加有效地实现文献信息的爬取。通过快速浏览相关领域文献的基本信息,我们可以从中找出感兴趣的值得我们深入研究的文章再来进行精读,极大地提高了效率。
01 选择合适的待爬取网站
我们日常使用知网的网址为:https://www.cnki.net/。但是该网址难以获取网页源代码。右键“查看网页源代码”后会跳转到如下的页面:

但是,我们发现可以从知网空间获取网页源代码。知网空间是知网的一个搜索入口,常用于文献的快速检索,网址为:https://search.cnki.com.cn/。

02 目标页面分析
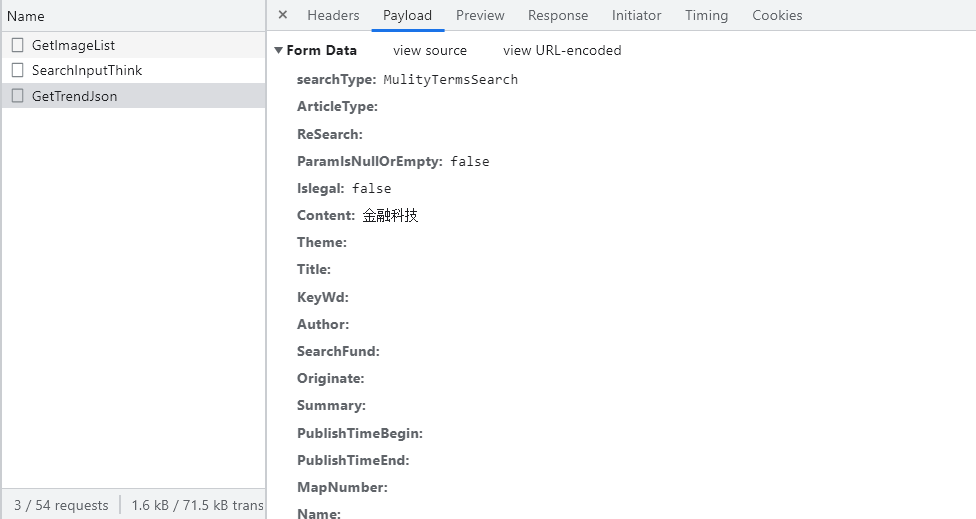
以“金融科技”为例,点击搜索,对页面进行分析,按F12选择Fetch/XHR。我们找到了如下发送的请求,且发现是以post方式发送。

且携带的参数为:‘searchType’: ‘MulityTermsSearch’, ‘Article Type’: ‘’, ‘ReSearch’: ‘’, ‘ParamIsNullOrEmpty’: ‘false’, ‘Islegal’: ‘false’, ‘Content’: ‘金融科技’, ‘Theme’: ‘’, ‘Title’: ‘’, ‘KeyWd’: ‘’, ‘Author’: ‘’, ‘SearchFund’: ‘’, ‘Originate’: ‘’, ‘Summary’: ‘’, ‘PublishTimeBegin’: ‘’, ‘PublishTimeEnd’: ‘’, ‘MapNumber’: ‘’, ‘Name’: ‘’, ‘Issn’: ‘’, ‘Cn’: ‘’, ‘Unit’: ‘’, ‘Public’: ‘’, ‘Boss’: ‘’, ‘FirstBoss’: ‘’, ‘Catalog’: ‘’, ‘Reference’: ‘’, ‘Speciality’: ‘’, ‘Type’: ‘’, ‘Subject’: ‘’, ‘SpecialityCode’: ‘’, ‘UnitCode’: ‘’, ‘Year’: ‘’, ‘AcefuthorFilter’: ‘’, ‘BossCode’: ‘’, ‘Fund’: ‘’, ‘Level’: ‘’, ‘Elite’: ‘’, ‘Organization’: ‘’, ‘Order’: ‘1’, ‘Page’: ‘1’, ‘PageIndex’: ‘’, ‘ExcludeField’: ‘’, ‘ZtCode’: ‘’, ‘Smarts’: ‘’,
03 获取相应内容
base_url = 'http://search.cnki.com.cn/Search/ListResult' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36', } def get_page_text(url, headers, search_word, page_num): data = { 'searchType': 'MulityTermsSearch', 'ArticleType': '', 'ReSearch': '', 'ParamIsNullOrEmpty': 'false', 'Islegal': 'false', 'Content': search_word, 'Theme': '', 'Title': '', 'KeyWd': '', 'Author': '', 'SearchFund': '', 'Originate': '', 'Summary': '', 'PublishTimeBegin': '', 'PublishTimeEnd': '', 'MapNumber': '', 'Name': '', 'Issn': '', 'Cn': '', 'Unit': '', 'Public': '', 'Boss': '', 'FirstBoss': '', 'Catalog': '', 'Reference': '', 'Speciality': '', 'Type': '', 'Subject': '', 'SpecialityCode': '', 'UnitCode': '', 'Year': '', 'AcefuthorFilter': '', 'BossCode': '', 'Fund': '', 'Level': '', 'Elite': '', 'Organization': '', 'Order': '1', 'Page': str(page_num), 'PageIndex': '', 'ExcludeField': '', 'ZtCode': '', 'Smarts': '', } response = requests.post(url=url, headers=headers, data=data) page_text = response.text return page_text 04 解析内容
这里我们运用Xpath进行解析:
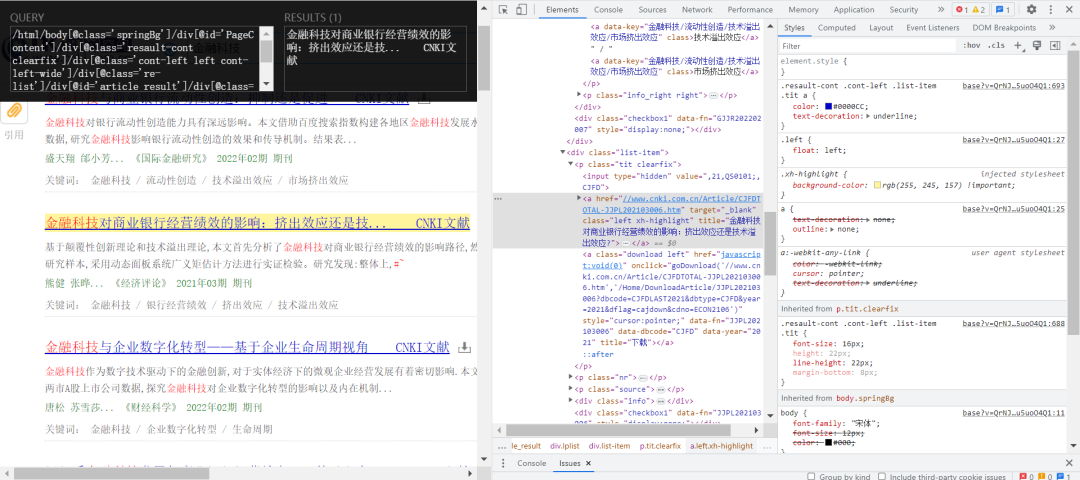
代码如下:
def list_to_str(my_list): my_str = "".join(my_list) return my_str def get_abstract(url): response = requests.get(url=url, headers=headers) page_text = response.text tree = etree.HTML(page_text) abstract = tree.xpath('//div[@class="xx_font"]//text()') return abstract def parse_page_text(page_text): tree = etree.HTML(page_text) item_list = tree.xpath('//div[@class="list-item"]') page_info = [] for item in item_list: # 标题 title = list_to_str(item.xpath( './p[@class="tit clearfix"]/a[@class="left"]/@title')) # 链接 link = 'https:' +\ list_to_str(item.xpath( './p[@class="tit clearfix"]/a[@class="left"]/@href')) # 作者 author = list_to_str(item.xpath( './p[@class="source"]/span[1]/@title')) # 出版日期 date = list_to_str(item.xpath( './p[@class="source"]/span[last()-1]/text() | ./p[@class="source"]/a[2]/span[1]/text() ')) # 关键词 keywords = list_to_str(item.xpath( './div[@class="info"]/p[@class="info_left left"]/a[1]/@data-key')) # 摘要 abstract = list_to_str(get_abstract(url=link)) # 文献来源 paper_source = list_to_str(item.xpath( './p[@class="source"]/span[last()-2]/text() | ./p[@class="source"]/a[1]/span[1]/text() ')) # 文献类型 paper_type = list_to_str(item.xpath( './p[@class="source"]/span[last()]/text()')) # 下载量 download = list_to_str(item.xpath( './div[@class="info"]/p[@class="info_right right"]/span[@class="time1"]/text()')) # 被引量 refer = list_to_str(item.xpath( './div[@class="info"]/p[@class="info_right right"]/span[@class="time2"]/text()')) item_info = [i.strip() for i in [title, author, paper_source, paper_type, date, abstract, keywords, download, refer, link]] page_info.append(item_info) print(page_info) return page_info 运行结果如下:
05 保存数据
这里我们将数据保存至excel表格中,并且实现,每个搜索词都在单独的一个sheet中,具体代码如下:
def write_to_excel(workbook, info, search_word): wb = workbook worksheet1 = wb.add_worksheet(search_word) # 创建子表 worksheet1.activate() # 激活表 title = ['title', 'author', 'paper_source', 'paper_type', 'date', 'abstract', 'keywords', 'download', 'refer', 'link'] # 设置表头 worksheet1.write_row('A1', title) # 从A1单元格开始写入表头 i = 2 # 从第二行开始写入数据 for j in range(len(info)): insert_data = info[j] start_pos = 'A' + str(i) # print(insert_data) worksheet1.write_row(start_pos, insert_data) i += 1 return True 06 结果展示
接着我们尝试爬取搜索词为“金融科技”和“数字经济”的前5页文献。
代码运行效果如下:

生成的excel表格如下:

以上就是小编带领大家爬取知网文献信息的全过程了,需要的小伙伴快动手演练一下吧~
▍学习资源推荐
零基础Python学习资源介绍
👉Python学习路线汇总👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(学习教程文末领取哈)
👉Python必备开发工具👈
温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉Python学习视频600合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
👉实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
👉100道Python练习题👈
检查学习结果。
👉面试刷题👈

资料领取
上述这份完整版的Python全套学习资料已经上传CSDN官方,朋友们如果需要可以微信扫描下方CSDN官方认证二维码输入“领取资料” 即可领取。
