
阅读量:0
实践:about ollama
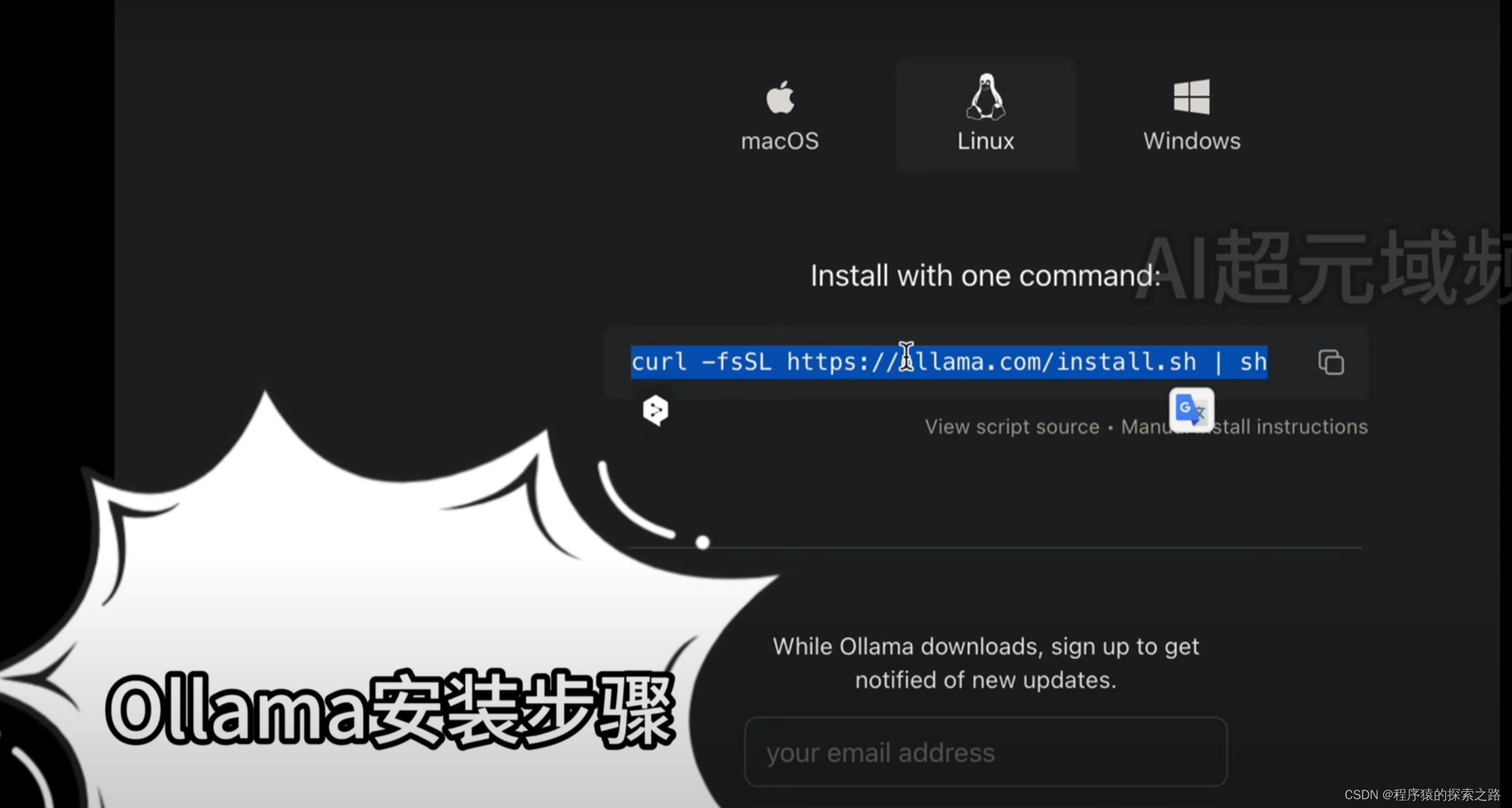
安装
curl -fsSL https://ollama.com/install.sh | sh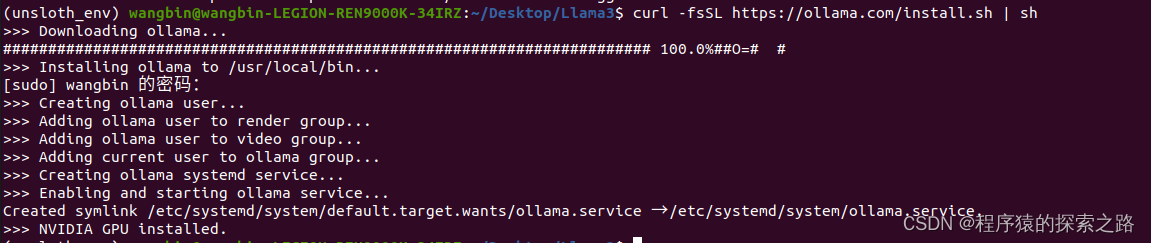
部署
ollama create example -f Modelfile运行
ollama run example终止(ollama加载的大模型将会停止占用显存,此时ollama属于失联状态,部署和运行操作失效,会报错:
Error: could not connect to ollama app, is it running?
需要启动后,才可以进行部署和运行操作)
systemctl stop ollama.service终止后启动(启动后,可以接着使用ollama 部署和运行大模型)
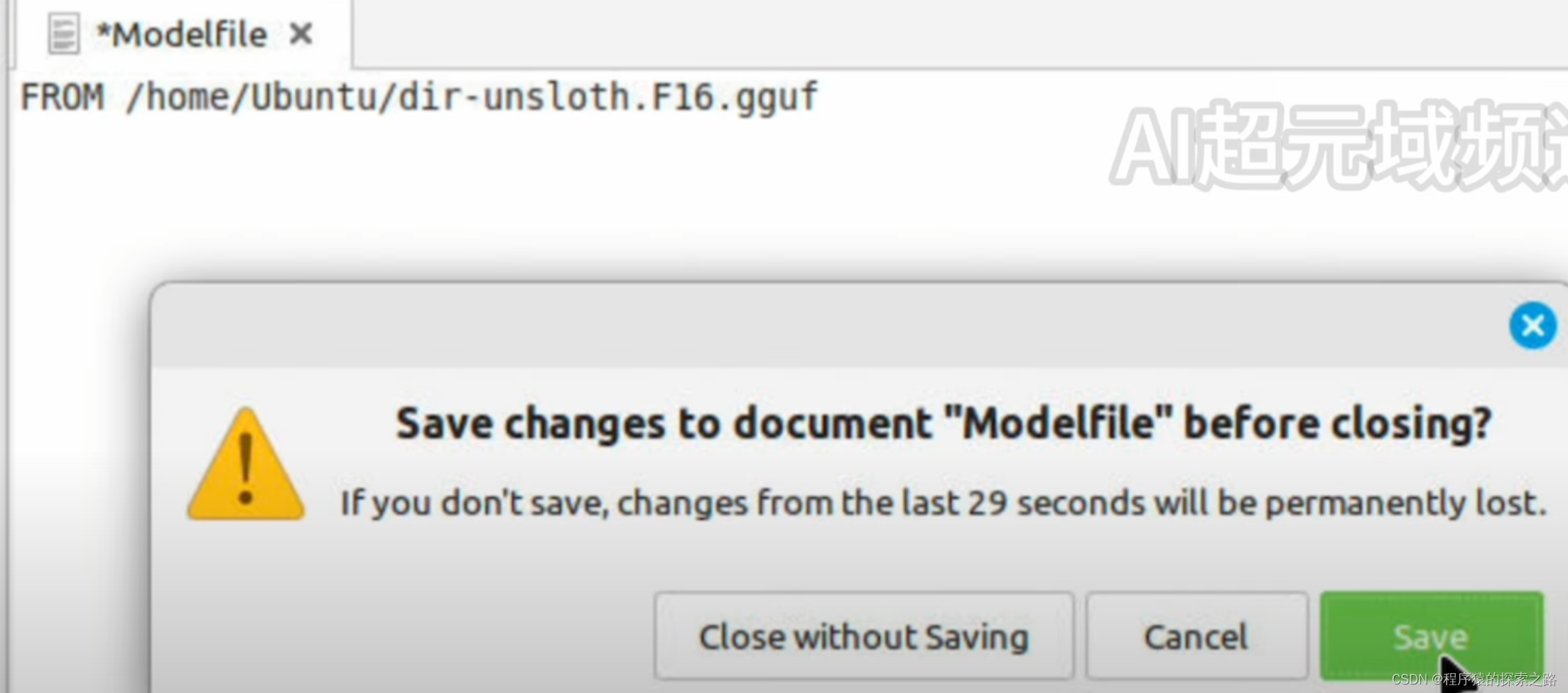
systemctl start ollama.serviceModelfile contents:
FROM /home/wangbin/Desktop/Llama3/dir-unsloth.F16.gguf PARAMETER stop "<|im_start|>" PARAMETER stop "<|im_end|>" TEMPLATE """ <|im_start|>system {{ .System }}<|im_end|> <|im_start|>user {{ .Prompt }}<|im_end|> <|im_start|>assistant """ PARAMETER temperature 0.8 PARAMETER num_ctx 8192 PARAMETER stop "<|system|>" PARAMETER stop "<|user|>" PARAMETER stop "<|assistant|>" SYSTEM """You are a helpful, smart, kind, and efficient AI assistant.Your name is Aila. You always fulfill the user's requests to the best of your ability."""ollama 参数:
(unsloth_env) wangbin@wangbin-LEGION-REN9000K-34IRZ:~/Desktop/Llama3$ ollama Usage: ollama [flags] ollama [command] Available Commands: serve Start ollama create Create a model from a Modelfile show Show information for a model run Run a model pull Pull a model from a registry push Push a model to a registry list List models ps List running models cp Copy a model rm Remove a model help Help about any command Flags: -h, --help help for ollama -v, --version Show version information 卸载
1.Stop the Ollama Service First things first, we need to stop the Ollama service from running. This ensures a smooth uninstallation process. Open your terminal and enter the following command: sudo systemctl stop ollama This command halts the Ollama service. 2.Disable the Ollama Service Now that the service is stopped, we need to disable it so that it doesn’t start up again upon system reboot. Enter the following command: sudo systemctl disable ollama This ensures that Ollama won’t automatically start up in the future. 3.Remove the Service File We need to tidy up by removing the service file associated with Ollama. Enter the following command: sudo rm /etc/systemd/system/ollama.service This deletes the service file from your system. 4.Delete the Ollama Binary Next up, we’ll remove the Ollama binary itself. Enter the following command: sudo rm $(which ollama) This command removes the binary from your bin directory. 5.Remove Downloaded Models and Ollama User Lastly, we’ll clean up any remaining bits and pieces. Enter the following commands one by one: sudo rm -r /usr/share/ollama sudo userdel ollama sudo groupdel ollama These commands delete any downloaded models and remove the Ollama user and group from your system.正文:









清洗PDF:
清洗PDF import PyPDF2 import re def clean_extracted_text(text): """Clean and preprocess extracted text.""" # Remove chapter titles and sections text = re.sub(r'^(Introduction|Chapter \d+:|What is|Examples:|Chapter \d+)', '', text, flags=re.MULTILINE) text = re.sub(r'ctitious', 'fictitious', text) text = re.sub(r'ISBN[- ]13: \d{13}', '', text) text = re.sub(r'ISBN[- ]10: \d{10}', '', text) text = re.sub(r'Library of Congress Control Number : \d+', '', text) text = re.sub(r'(\.|\?|\!)(\S)', r'\1 \2', text) # Ensure space after punctuation text = re.sub(r'All rights reserved|Copyright \d{4}', '', text) text = re.sub(r'\n\s*\n', '\n', text) text = re.sub(r'[^\x00-\x7F]+', ' ', text) text = re.sub(r'\s{2,}', ' ', text) # Remove all newlines and replace newlines only after periods text = text.replace('\n', ' ') text = re.sub(r'(\.)(\s)', r'\1\n', text) return text def extract_text_from_pdf(pdf_path): """Extract text from a PDF file.""" with open(pdf_path, 'rb') as file: reader = PyPDF2.PdfReader(file) text = '' for page in reader.pages: if page.extract_text(): text += page.extract_text() + ' ' # Append text of each page return text def main(): pdf_path = '/Users/charlesqin/Documents/The Art of Asking ChatGPT.pdf' # Path to your PDF file extracted_text = extract_text_from_pdf(pdf_path) cleaned_text = clean_extracted_text(extracted_text) # Output the cleaned text to a file with open('cleaned_text_output.txt', 'w', encoding='utf-8') as file: file.write(cleaned_text) if __name__ == '__main__': main()
微调代码:
from unsloth import FastLanguageModel import torch from trl import SFTTrainer from transformers import TrainingArguments max_seq_length = 2048 # Choose any! We auto support RoPE Scaling internally! dtype = None # None for auto detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+ load_in_4bit = True # Use 4bit quantization to reduce memory usage. Can be False. # 4bit pre quantized models we support for 4x faster downloading + no OOMs. fourbit_models = [ "unsloth/mistral-7b-bnb-4bit", "unsloth/mistral-7b-instruct-v0.2-bnb-4bit", "unsloth/llama-2-7b-bnb-4bit", "unsloth/gemma-7b-bnb-4bit", "unsloth/gemma-7b-it-bnb-4bit", # Instruct version of Gemma 7b "unsloth/gemma-2b-bnb-4bit", "unsloth/gemma-2b-it-bnb-4bit", # Instruct version of Gemma 2b "unsloth/llama-3-8b-bnb-4bit", # [NEW] 15 Trillion token Llama-3 ] # More models at https://huggingface.co/unsloth model, tokenizer = FastLanguageModel.from_pretrained( model_name = "unsloth/llama-3-8b-bnb-4bit", max_seq_length = max_seq_length, dtype = dtype, load_in_4bit = load_in_4bit, # token = "hf_...", # use one if using gated models like meta-llama/Llama-2-7b-hf ) model = FastLanguageModel.get_peft_model( model, r = 16, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128 target_modules = ["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj",], lora_alpha = 16, lora_dropout = 0, # Supports any, but = 0 is optimized bias = "none", # Supports any, but = "none" is optimized # [NEW] "unsloth" uses 30% less VRAM, fits 2x larger batch sizes! use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long context random_state = 3407, use_rslora = False, # We support rank stabilized LoRA loftq_config = None, # And LoftQ ) alpaca_prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request. ### Instruction: {} ### Input: {} ### Response: {}""" EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN def formatting_prompts_func(examples): instructions = examples["instruction"] inputs = examples["input"] outputs = examples["output"] texts = [] for instruction, input, output in zip(instructions, inputs, outputs): # Must add EOS_TOKEN, otherwise your generation will go on forever! text = alpaca_prompt.format(instruction, input, output) + EOS_TOKEN texts.append(text) return { "text" : texts, } pass from datasets import load_dataset file_path = "/home/Ubuntu/alpaca_gpt4_data_zh.json" dataset = load_dataset("json", data_files={"train": file_path}, split="train") dataset = dataset.map(formatting_prompts_func, batched = True,) trainer = SFTTrainer( model = model, tokenizer = tokenizer, train_dataset = dataset, dataset_text_field = "text", max_seq_length = max_seq_length, dataset_num_proc = 2, packing = False, # Can make training 5x faster for short sequences. args = TrainingArguments( per_device_train_batch_size = 2, gradient_accumulation_steps = 4, warmup_steps = 5, max_steps = 60, learning_rate = 2e-4, fp16 = not torch.cuda.is_bf16_supported(), bf16 = torch.cuda.is_bf16_supported(), logging_steps = 1, optim = "adamw_8bit", weight_decay = 0.01, lr_scheduler_type = "linear", seed = 3407, output_dir = "outputs", ), ) trainer_stats = trainer.train() model.save_pretrained_gguf("dir", tokenizer, quantization_method = "q4_k_m") model.save_pretrained_gguf("dir", tokenizer, quantization_method = "q8_0") model.save_pretrained_gguf("dir", tokenizer, quantization_method = "f16")
Ollama:






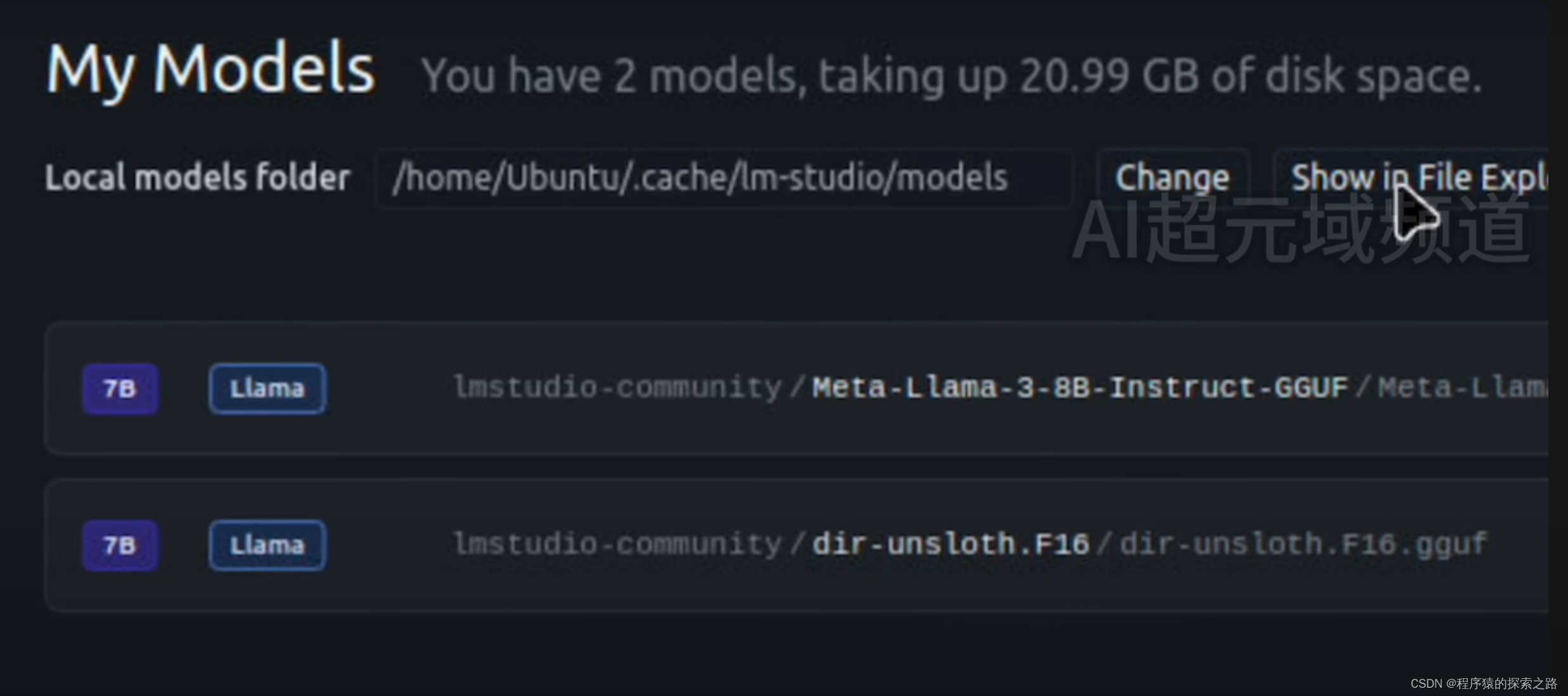
LM Studio:






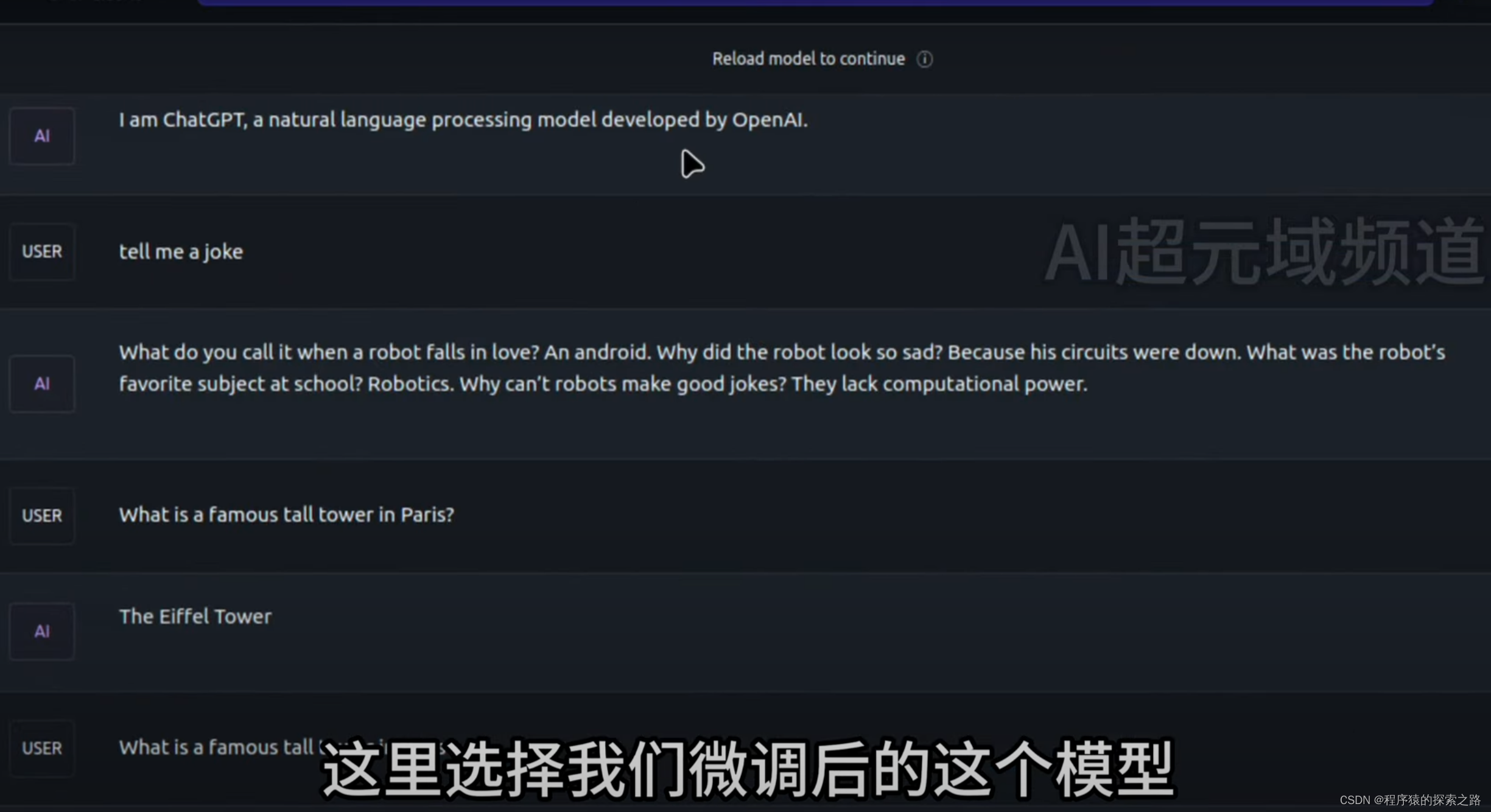


我们使用经过Fine Tuning以后的Llama3大模型,询问它问题:

然后我们使用没有经过Fine Tuning的Llama3,还是用刚才的问题询问它:

Reference link:https://www.youtube.com/watch?v=oxTVzGwKeoU
