阅读量:0
什么是存储虚拟化
分布式存储是利用虚拟化技术 “池化”集群存储卷内通用X86服务器中的本地硬盘,实现服务器存储资源的统一整合、管理及调度,最终向上层提供NFS、ISCSI存储接口,供虚拟机根据自身的存储需求自由分配使用资源池中的存储空间。
存储中的基本概念
IOPS
每秒钟的IOPS数,该指标主要用于评价小块IO性能,体现存储系统的IO延时能力和并发能力。业界一般默认IOPS指的是4K块大小的IO性能,该值越大说明性能越好。
吞吐
每秒钟的IO吞吐,单位MB/s,该指标主要用于评价大块IO性能,体现存储系统的IO带宽能力,该值越大说明性能越好。
缓存盘和数据盘
固态硬盘(SSD)性能高,但价格高,容量小,机械硬盘(HDD)价格低,容量大,但性能第。
为了实现存储系统在性能,容量,成本三者之间达到最佳均衡,一般会使用混合硬盘配置,以SSD缓存盘作为缓存层,HDD数据盘作容量层。
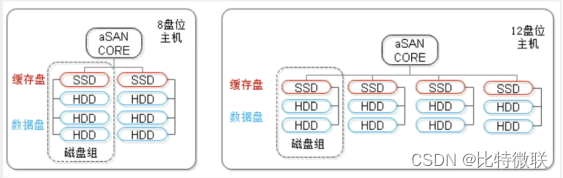
磁盘组
在混合硬盘配置下,缓存盘和数据盘以磁盘组的关系进行配对,每个磁盘组由一个SSD带n个HDD组成(n<7)。每个磁盘组的SSD仅为其磁盘组下的HDD提供缓存加速的能力。配对所带来的好处是减少了SDD故障所影响的范围(一块SSD带几块HDD)。
缓存盘容量需要多少是根据业务量来配置的,正常缓存盘是用来放热数据的,根据经验来说,热数据一般占比是20%左右,比如用户有10T的数据量一般应该配2T的缓存盘。
一般做方案时不知道用户业务量未来会增长多少,所以采纳了一个跟机械硬盘的比例,也就是裸盘比,这样一般能达到一个比较好的性能。比如6块4T的机械盘,缓存盘建议配置2.4T
镜像格式
虚拟机的虚拟磁盘文件的格式,如qcow2
数据分片
虚拟磁盘的大小是不固定的,可以小到几个G,大到几十T。为了能够更灵活地存放和处理这些数据,aSAN通过数据分片技术对单个qcow2文件按照固定单位大小(如aSAN3.0版本默认大小为4G)进行切分成若干个颗粒度更小的分片。 aSAN的诸多存储策略都是基于颗粒度更小的分片进行的,让数据在存储卷中分布更加地均衡,数据管理更加灵活。
优点:
· 单个qcow2文件(即单个虚拟磁盘)的大小可达到整个存储卷的可用容量大小
· 颗粒度小,策略灵活。例如分布均匀,断点续修
· 多盘性能(结合条带化)
虚拟机的磁盘在存储上实际是一个qocw2文件,像虚拟磁盘可能会非常大,可能配了几十个G或者几百G,分片就是把qocw2文件切成一个个以4g或者其他大小的小块文件
如果没有分片,一个虚拟机的磁盘(qcow2文件)是落在一个物理磁盘上的,只要在该物理磁盘满的时候,它才会占用下一个物理磁盘的空间,这样的话,虚拟机单个磁盘的大小是不允许超过单台物理主机的空间的,由于其占用的是一个物理磁盘空间(只有该物理磁盘满了的情况下才会占用下一个物理磁盘空间),所以它也只能利用到一个物理磁盘的读写性能。
另外在不分片的情况下,文件的颗粒度就很大,很多存储策略就不灵活,比如主机之间数据分布不均匀,因为QCOW2文件很大,不分片的话虚拟机的磁盘会只占用一台物理机上的存储空间,所以有可能出现一台主机存储容量占用超过80%,另一台主机只有10%的情况,包括后面去做一些数据平衡的动作平衡时间会很长(平衡各主机之间的存储空间占用,将存储容量占用高的主机上的qcow2文件转移到其他存储更加空闲的主机上),因为它只能从一块磁盘上面去读、到另一块磁盘上去写,包括数据修复过程中,出现了一些故障,导致修复失败了,这时候又得从qcow2文件头开始去修,不灵活。
如果做了分片,虚拟机的磁盘文件是以分片为单位,比如分片1落在磁盘1的位置,分片2落在磁盘2的位置等等,它可以同时利用多块物理磁盘的性能,包括很多策略都是以分片的单位去执行,比如数据平衡、数据修复等。如果做了分片,理论上虚拟机可用磁盘大小是可以达到整个虚拟存储卷的可用容量大小的
条带化
条带化是传统的RAID 0模式采用的一种实现技术。条带化技术的普遍定义是将一块连续的数据切分成很多个小的数据块,然后并发地存储到不同物理硬盘上,实现对数据进行写入或读取时可以获得最大程度上的I/O 并发能力,从而获得优异的性能。
如下图所示,经过条带化处理的数据可以并发地写入到三块磁盘,而未经条带化处理的数据每次只能写入到一块磁盘中,因此数据经过条带化后的写入性能则是未经条带化的写入性能的3倍。
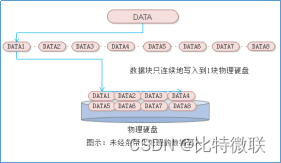
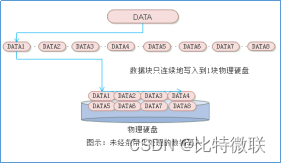
简单来说,条带化是将一个数据切成很多小碎块,然后并发地写入到多块磁盘上面,他的作用是能够最大程度提升IO并发能力,如上图,没有做条带化的时候(右图),写入数据是连续的去写,写完date1再写date2,不管怎么写,都只利用了一块物理磁盘的性能
做了条带化之后(左图),将一个文件切成一堆小碎块,写的时候同时并发地往三个物理磁盘去写,可以同时利用多块磁盘地性能。
条带数
条带数,又称为条带宽度。指的是对数据进行读写时可以同时并发I/0的物理硬盘数量,如下图所示的RAID0组条带则为3。
通常情况下,随着条带数的增加,可并发I/O的物理硬盘数也随之增加,I/O性能也能得到提升。
为了保证最优的I/O性能效果,条带数的默认不会超过存储卷中任意一台物理主机上的数据盘个数。
比如8盘位,两块SSD配了6块HDD,那这时候条代数就是6

条带大小
条带大小,又称为条带深度,指条带化过程中增量数据块的大小,也就是将一个大的文件按多大切成一个个小碎块
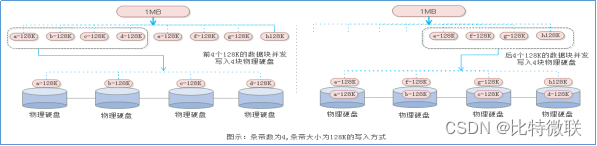
条带数和条带大小在实际IO流的呈现如下图所示:
假设条带数设为4,条带大小设为128K。当写入一个连续的1MB的数据时,实际上1MB的数据会被切分8(1MB除以128K)个条带大小为128K的小数据块,由于条带数为4,那么可以同时并发写入的物理硬盘数量为4个,所以前面4个128K的小数据块就同时并发地写入到4块物理硬盘中,写入完成后,再写入后面4个128K的小数据块
多副本
多副本,是指将数据保存多份的一种冗余技术,aSAN支持两副本、三副本,副本所存放的位置必须满足主机互斥原则。
副本也就是同一个数据存2份或三份保证数据冗余,并满足主机互斥的原则,比如2副本,date1存放在主机1的某块磁盘中,则date1的副本数据则会存放在集群内其他主机的某块磁盘中,这样即使主机1的某块磁盘故障或主机1故障,也不会影响虚拟机的数据。
存储池可用空间 = (集群数据盘总空间 - 数据盘预留总空间) / 副本数。通常情况下,每块数据盘预留的空间为16G。
举例:存储卷设置为两副本冗余模式,由4台物理主机组成,每个节点共插入6块1TB硬盘作为数据盘 (特别说明下,硬盘厂商生产的硬盘1TB=1000GB,但在系统中需要转换为1024进制格式,最终在系统识别到的容量实际约为931GB)
存储卷的实际可用空间 = (4台 * 6块 * (931GB – 16GB))/2 = 11052 GB,即11052 / 1024 = 10.8TB。(16GB是预留空间)

数据分布介绍
如图所示,虚拟机所设的条带数为6,条带大小为128K,其数据经过条带化、分片和副本复制后在aSAN中的分布过程为:
1、单个qcow2文件,以条带数为6,条带大小为128K,切成n个数据块。每6个128K的数据块组成1个条带组。
2、对应的,数据会先切分成6个分片,组成1个分片组。分片组的聚合副本的分片会在主机A中跨磁盘组并且跨磁盘分布,分片组的散列副本的分片会跨B、C、D主机并且在主机内跨磁盘组分布。
3、第1个128K的数据块 、 属于分片1,第2个128K的数据块 属于分片2,以此类推,第6个128K的数据块 属于分片6。条带组1中的6个数据块将并发地写入到所属分片对应的磁盘位置中,写入完成后,再以同样的方式写入条带组2,条带组3......
4、随着数据的写入,分片的大小也随之增大,当分片组的分片大小增大到4GB时,将生成第2个分片组,同样也是由6个分片所组成,分布的策略与上一个分片是一致的,即其聚合副本仍然位于主机A中跨磁盘组与跨磁盘分布,散列副本跨主机并且跨磁盘组分布。但注意分片所落在的磁盘具体位置并不一定与上一个分片组完全一样。

上图是结合了条带化、分片、副本,最后在分布式存储里面的数据流是怎样的。
假设虚拟机的虚拟磁盘条代数是6,条带默认大小是128K,数据在经过条带、分片、副本复制之后在落盘的时候的分布情况如上图所示。数据写入硬盘会经过以下两个过程:
1. 条带化
一块qcow2文件,先切成很多个数据块,其中每个数据块大小是128K,每6个是一个条带组,因为条代数是6(如上图中最上面“条带化”这几个字那一行),一个条带组可以并发地向磁盘中去写,写完第一个条带组写第二个条带组
这里有一个聚合副本的概念(如上图中主机A存储的数据就是聚合副本),就是说数据其中一个副本会聚合在某一台主机上面,另外一个副本会分散存放在其他主机上面。聚合副本主要是考虑数据本地化的效果,使虚拟机读写磁盘的操作都在本地进行,无需通过存储网络去读取,从而提升虚拟机读写性能,有聚合副本更好,但聚合副本不是必须的。若虚拟机运行在主机A上,主机A的存储空间利用率超过85%,此时若向虚拟机新增一块磁盘,此时新增的这块磁盘聚合副本就可能会落在其他主机上
2. 数据分片
数据写入之前先分片,确定分片位置,后面的条带化数据是跟随着分片的位置去写入。
数据条带化之后会将数据写入不同的数据盘,写完之后,所有的条带化数据加起来涨到4G(假设分片以4G大小为单位),涨到4G之后就会生成第二个分片组,后面的条带也是对应的落在第二个分片组的位置。第二个分片组也有聚合副本和散列副本的概念,对于聚合副本来说还是会落在同一个主机上面,散列副本则会分布在其他主机上面,所有的条带化数据都是根据事先定好的数据分片位置去写的
数据分布的四大策略(分片位置确认)
1、数据本地化- 聚合副本和散列副本并存策略
数据(以qcow2文件为单位)的其中一个副本会聚合在一台主机主机上,称之为聚合副本;另外一个副本会分散在最多三台主机上,称之为散列副本。
虚拟机优先运行在聚合副本所在的主机上,以达到数据本地化的效果。虚拟机对数据进行访问时,可以直接从聚合副本中读取,避免跨存储网络对数据进行读取,以此可提高数据读取的吞吐性能,突破网络带宽的瓶颈,在全闪存模式下,性能提升的效果尤为明显。
2、利用更多的SSD-主机内优先跨磁盘组分布策略
无论是聚合副本还是散列副本,其分片组内的分片都会在主机内优先跨磁盘组分布。这是因无论是聚合副本还是散列副本,其分片组内的分片都会在主机内优先跨磁盘组分布。
这是因为每个磁盘组都有一块SSD可为其磁盘组下的HDD提供缓存加速的能力,尽可能跨越多个磁盘组,意味着对条带组内的数据进行并发读写时,可以利用到更多的SSD的缓存加速能力,从而提升性能。
跨磁盘组分布是为了利用更多的ssd的性能
如上图,假设主机A为8盘位,两块SSD和6块HDD,一块SSD和3块HDD组成一个磁盘组,主机A上有2个磁盘组。此时条带化数据写入时,分片1会写到磁盘组1中,分片2则不会往磁盘组1去写,而是写到磁盘组2中,此时写入可以利用到两块SSD的性能,散列副本也遵循跨磁盘组分布策略,这样可以避免分片1-6都是落在了磁盘组1中,从而只利用了一块SSD的性能
3、利用更多的HDD-磁盘组内优先跨磁盘分布策略
同一个分片组内的分片落入到同一个磁盘组时,会在磁盘组尽可能地跨磁盘进行分布。如上图所示主机A,同一个分片组内的分片尽可能保证不会落到同一块物理磁盘上。这是由于机械硬盘的随机I/O性能较差,为了避免对一个条带组内的数据块进行并发读写时对机械硬盘产生随机的I/O。
在介绍的aSAN条带数默认是不允许设置为超过存储卷中任意一台物理主机上的数据盘个数,也是基于同样的考虑,保证数据的聚合副本中每个条带组内的数据块在聚合的主机内有足够的数据盘被用于并发读写,而不会落到同一块物理磁盘。
跨磁盘分布是为了利用更多的hdd性能
如上图,比如一个分片组6个分片,如果说分片1、3、5全部写在磁盘组中1号盘的位置,此时并发写入时,分片3要写入只能等分片1的数据写完后才能写入,此时数据写入只用到了磁盘组中一块hdd的性能,所以跨磁盘分布可以同时将分片1、3、5写入磁盘组中不同的hdd,更大的提升磁盘的读写利用率
所以说条代数不允许设置超过任意一个主机数据盘的个数也是基于这个考虑
4、尽可能分布均衡-优先选择组件剩余容量最多策略
为了保证存储卷内的数据分布均衡,避免某台主机或某块磁盘出现数据热点。存储卷内主机或磁盘的剩余容量大小也是数据分布时的一个重要考量因素。例如:
1.在能够满足策略1~策略3的分布策略的情况下,分片会优先选择落在剩余容量较多的磁盘上以及聚合副本会优先选择落在剩余容量较多的主机上;
2.若某台主机的空间使用率已超过85%,则该主机上原有的qcow2文件其聚合副本所新增的分片将不再要求在该主机内进行聚合,以及存储卷内新建的qcow2文件将不再选择该主机作为聚合副本的位置;
3.若某块磁盘的空间使用率已超过85%,则分片在选择落盘位置时会优先将该磁盘排除。
数据分片时会优先选择容量利用率低的磁盘,通过这个策略去保证它的数据分布均衡,如果主机A的存储空间已经超过85%,其他主机利用率仅为70%,这时新增的qcow2文件他的聚合副本就不会再选择主机A而是去选择其他存储更空闲的主机
也就是说分片选择位置会优先考虑磁盘容量、主机磁盘利用率等因素,尽可能地使数据均匀分布并提升存储地IO并发性能
分片、条带化后地效果
总结起来,通过以上的分布策略,aSAN在尽可能保证数据分布均衡的同时可以有效地提升I/O的并发性能:
当对一段数据进行写入操作时,可以尽可能地并发写入到多个磁盘组的SSD中,从而可以利用到多块SSD的性能。
当对一段数据进行读取操作时,如果数据被缓存在SSD中,即命中缓存时,同样可以尽可能地从多块SSD中并发地读取,利用到多块SSD的性能。如果所需读取的数据未被缓存在SSD中,即未命中缓存时,此时仍然可以尽可能多地从多块HDD中并发地读取,利用到多块HDD的性能。
存储优化
数据平衡
1. 数据失衡
扩容,包括添加磁盘或者添加主机
用户对某些虚拟机进行删除
磁盘或主机发生故障后完成重建,故障的组件重新恢复上线
个别虚拟机数据在短时间内增长较快,聚合副本
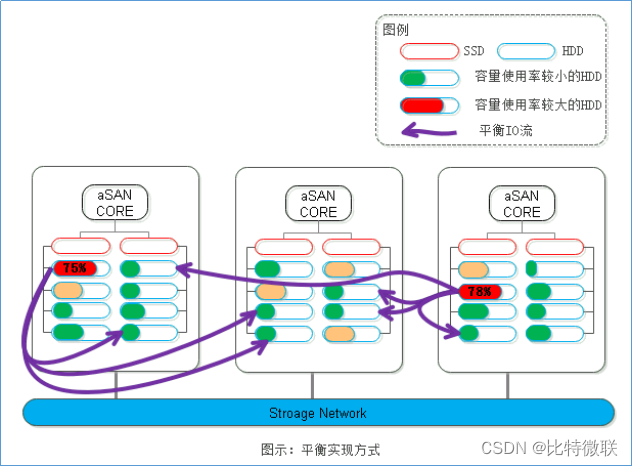
2、平衡实现的目标
保证在任何情况下,数据在存储卷内的各个组件内尽可能地分布均衡,避免产生极端的数据热点以及尽快地利用上新增组件的空间和性能,保证各组件的资源得到合理利用。
目标1:使得整个存储卷内最高和最低的磁盘容量使用率之差尽可能小
目标2:避免发生存储卷内某块磁盘的空间已用满,而其他磁盘仍有可用空间的情况
因此存储卷是否已经达到平衡是以磁盘为单位进行定义的,通过保证磁盘间的均衡同时可以达到主机之间的容量尽可能均衡。
3、平衡触发的条件
1、计划内平衡
计划内平衡是在用户所计划的时间范围发起的数据平衡。当存储卷内不同硬盘的容量使用率差异较大时,将对使用率较高的硬盘执行数据平衡,迁移部分数据到容量使用率较低的硬盘上,即目标1。
卷内最高和最低的磁盘容量使用率之差超过一定阈值时(默认是30%)即触发平衡,直至卷内任意两块硬盘的使用率不超过一定阈值(默认是20%)。
2、自动平衡
自动平衡是无需用户进行干预,由系统自动发起的数据平衡。是为了避免存储卷内某块磁盘的空间已用满,而其他磁盘仍有可用空间
当存储卷内存在某块磁盘空间使用率已超过风险阈值时(默认是90%)即触发自动平衡,直至卷内卷内最高和最低的磁盘容量使用率小于一定阈值(默认是30%)
数据平衡实现方式
目的端磁盘的个数可以是多个:
当满足平衡的触发条件时,会以分片为单位计算出源端磁盘上的各个分片其即将落入的目的端磁盘的位置,位置可以是本主机内的其他磁盘或者其他主机内的磁盘。
目的端磁盘位置计算的原则是:
必须满足主机互斥原则。即迁移后的分片两个副本不允许位于同一个主机上
性能最优原则。即优先选择可以使得迁移后的分片依然满足分布策略的磁盘作为目的端磁盘(散列副本)
容量最优原则。优先选择容量使用率低的目的端磁盘。
平衡保护措施 :
针对该分片上新增的数据是同时写入到源端和目标端,即多写一份副本
平衡结束前,对源和目标的数据进行校验,确保平衡前后数据一致性
平衡完成后,源端的分片会移动到临时目录保留一段时间后再删除
数据重建
以数据采用两副本策略为例,当存储卷内的组件(磁盘或主机)发生物理故障时,故障组件上的数据和存储在其他组件上的另一个副本,仍然可以保障虚拟机的正常读写,但此时存储卷的冗余度实际上已变低,假如此时另一副本所在的组件也发生故障,就会导致数据丢失 。
通过数据重建功能,在组件发生故障后,将以故障组件上数据的另一副本作为修复源,以分片为单位在目的组件上重建出新的副本,恢复副本的完整性,实现系统自愈。
差异数据修复≠数据重建
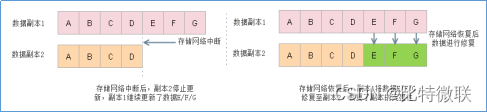
系统检测到磁盘离线后,系统将预留一段时间便于用户确认磁盘是否出现真实故障,如磁盘出现松动离线,人为拔插后恢复上线,此时只需对该磁盘进行修复即可,所需修复的数据为离线时间内的另一数据副本新增/修改的数据,即差异数据修复。
场景:存储网络中断后短时间内重新上线/某台主机在计划内离线进行维护并重新上线等。
差异数据修复是指当主机或硬盘离线短时间内又重新上线,此时离线时间还不满足数据重建条件,此时虚拟机又有新数据写入,假设离线之前,磁盘中文件是ABCD,离线这段时间,磁盘文件新增了EFG,此时数据副本1中地数据为ABCDEFG,而主机或硬盘上线后,数据副本2中地数据仍是ABCD,则触发差异数据修复,将数据副本2中缺少地EFG新增至副本2中
当主机或硬盘发生了真实且不可修复地故障时会触发数据重建
由于副本存放满足主机互斥原则,即使一台主机离线,集群内其他主机也有该主机上所有文件的备份副本,只需要以其副本作为修复源重建出缺少的文件,保证原来的两副本还是两副本

仲裁机制
aSAN的副本机制使得数据除了拥有多个数据副本以外,实际还同时存在仲裁副本。仲裁副本是一种特殊的副本,它只有少量的校验数据,占用的实际存储空间很小,主要是用于防止数据副本发生脑裂的。
仲裁副本同样要求与数据副本必须满足主机互斥的原则,因此至少三台主机组成的存储卷才具有仲裁副本。

脑裂
数据“脑裂”通常是由于网络发生故障,数据的多个副本出现了隔离,无法及时相互同步信息,并且副本各自孤立地写入更新了不同的数据,导致副本之间数据存在不一致,并且是“各自都存在对方不存在的数据”,这点和前面解释的差异数据修复是有区别的。

系统检测到磁盘离线后,系统将预留一段时间便于用户确认磁盘是否出现真实故障,如磁盘出现松动离线,人为拔插后恢复上线,此时只需对该磁盘进行修复即可,所需修复的数据为离线时间内的另一数据副本新增/修改的数据,即差异数据修复。
场景:存储网络中断后短时间内重新上线/某台主机在计划内离线进行维护并重新上线等。

脑裂产生过程
第一步:正常情况下,虚拟机运行在主机A上,数据会同时写入到A主机和B主机上的两个副本中,两个副本上的数据完全一致。

第二步:当主机之间的存储网络出现中断,主机A和主机B相互隔离,无法正常同步数据。此时虚拟机可以继续在主机A上运行,但其新产生的数据只能往主机A的磁盘上写入更新。注意,主机B上的数据处于旧状态,数据已经出现不一致,但注意此时还未发生数据脑裂。
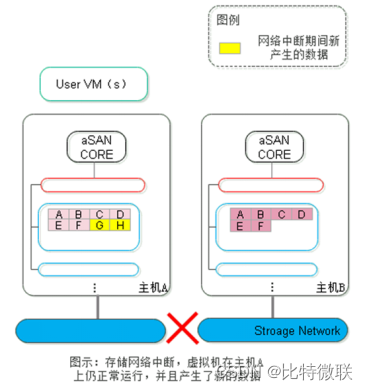
第三步,主机B经过心跳探测,无法与主机A取得通信,认为主机A发生故障。这时虚拟机的高可用(HA)机制生效,主机B上重新拉起了该虚拟机,即出现了“双实例”——两个相同的虚拟机。两个虚拟机各自往自己所运行位置上的主机写入新的数据。这时候,两台主机上的副本出现不一致,并且是各自都存在对方不存在的数据,即出现了数据脑裂。
仲裁工作原理
仲裁机制的工作核心原理是“少数服从多数”,即:当虚拟机运行所在的主机上可访问到的数据副本数小于总副本数(数据副本+仲裁副本)的一半时,则禁止虚拟机在该主机上运行。反之,虚拟机可以在该主机上运行。
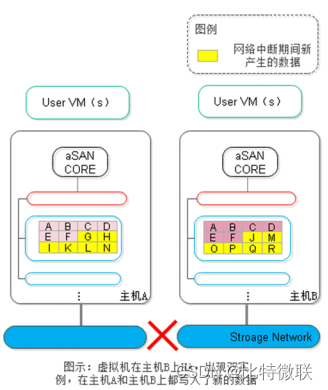
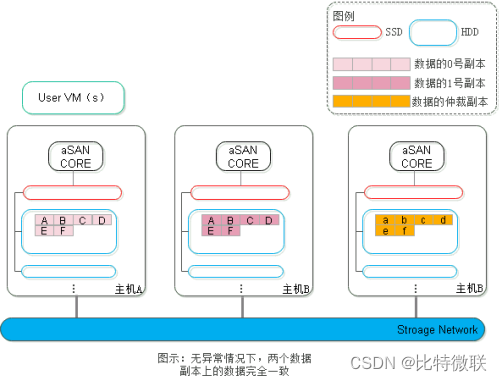
第一步:正常情况下,虚拟机运行在主机A上,数据会同时写入到A、B、C主机上,数据副本在A、B主机上,仲裁副本在C主机上。
第二步:当主机A的存储网络中断,无法与主机B和主机C正常通信。此时仲裁机制进行判断,虚拟机运行所在的主机A上可访问到的数据副本仅有本地的一份副本,数量小于总副本数3个(2个数据副本+1个仲裁副本)的一半,因此将主机A上的虚拟机进程kill掉。
主机A存储网络中断,此时主机A只能访问到它自己,根据总裁副本“少数服从多数”原则,则主机A知道是自己挂了,不会将虚拟机在主机A上拉起来

第三步:仲裁机制判断,对于主机B或主机C,其可访问到的副本数量均为2个(主机B的数据副本和主机C的仲裁副本),满足大于总副本数)的一半。因此可以在主机B和主机C任意一台主机中HA启动,如下图所示虚拟机在主机B上启动运行。虚拟机运行过程中,数据的写入可以正常更新至主机B和主机C上的副本。
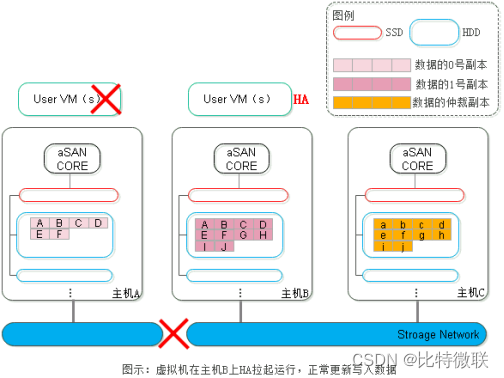
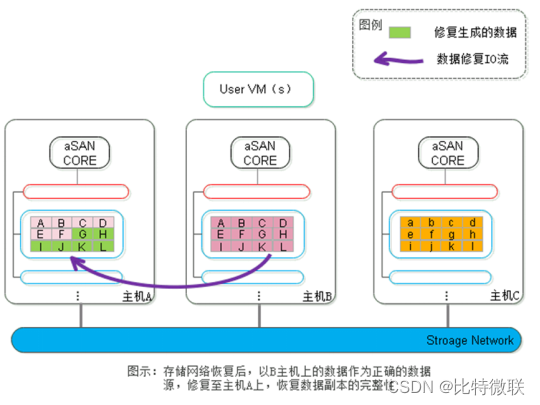
第四步:当存储网络恢复正常后,系统检测到数据的两个副本存在不一致,会触发数据修复以恢复副本的一致性,此时将以主机B上的数据副本作为修复的数据源,修复至主机A上的数据副本,恢复数据副本的一致性。