
阅读量:0
网络爬虫是一种用于从互联网上的网页中提取数据的工具或代码。互联网数据价值不可估量,应用场景十分广泛,网络爬虫对于互联网数据的抓取发挥着重要作用。因此,从技术角度看,爬虫推动了大数据的发展。
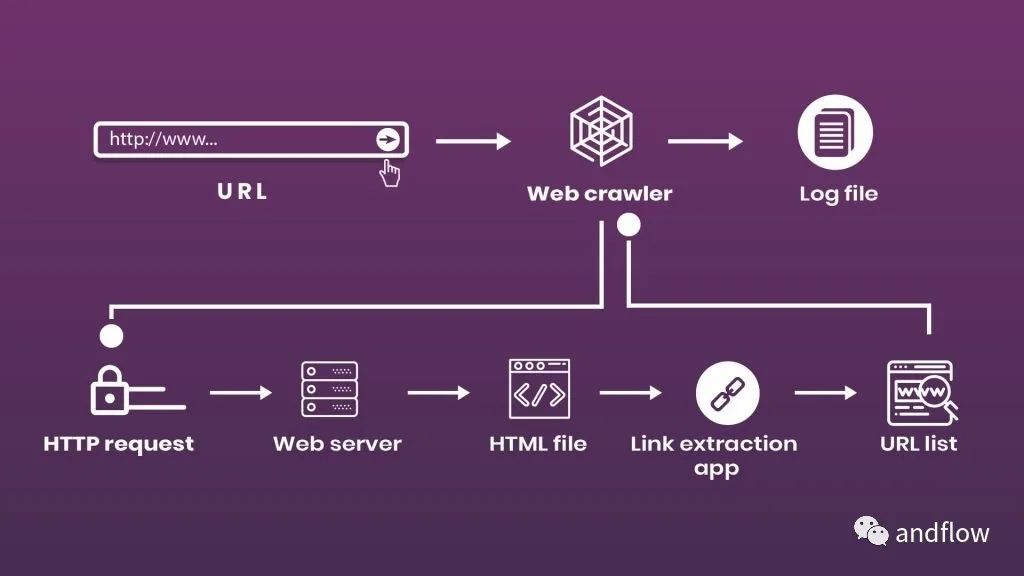
爬虫的工作流程非常简单,无非就是三个步骤:
模拟人类浏览网站的行为。输入目标URL后,它向服务器发送一个请求,并在HTML文件中获取信息。
有了HTML源代码,机器人就能够到达目标数据所在的节点,并按照抓取代码中的命令解析数据。
清洗抓取的数据,转换数据结构,并保存到数据库。
但在实际互联网环境下,无处不存在着道高一尺魔高一丈的博弈。因此并没有完美的爬虫工具,只能说尽量选择比较灵活、易于扩展的库,根据实际需要进行配置或开发。
在各种网络爬虫工具中,开源网络爬虫具备高灵活性、可扩展性,也更受技术人员的青睐。甚至有些爬虫项目能够实现无代码或低代码。
以下分别是在Python、Java、Go、JavaScript等开发语言领域比较优秀的开源网络爬虫库。
Python:Scrapy、PySpider、Mechanical Soup、AutoCrawler
java:WebMagic、Crawler4j、WebCollector、Nutch、Heritrix、Web_harvest、StormCrawler
Golang:Crawlab、ferret、Hakrawler、Crawlergo、Geziyor、Gospider、Gocrawl、fetchbot
JavaScript:Node-crawler、EasySpider
01
Scrapy
开发语言: Python
GitHub(49.3K):
https://github.com/scrapy/scrapy

Scrapy是Python中最受欢迎的开源Web爬虫和协作Web抓取工具。有助于从网站中有效地提取数据,根据需要处理数据,并以一定数据格式(JSON,XML和CSV)保存。
优点:
快速且强大
易于使用,有详细的文档
无需修改内核即可增加新功能
健康的社区和丰富的资源
支持在云环境中运行
02
PySpider
开发语言: Python
GitHub(16.1K):
https://github.com/binux/pyspider
PySpider是一个强大的Python网络爬虫系统。采用分布式系统架构,提供易于使用的Web UI,提供了调度器、提取器和处理器等诸多组件。它支持MongoDB、MySQL等数据库。
优点:
强大的WebUI,包含脚本编辑器、任务监视器、项目管理器和结果查看器
支持使用RabbitMQ、Beanstalk、Redis和Kombu作为消息队列
分布式架构
03
Mechanical Soup
开发语言:Python
GitHub(4.5K):
https://github.com/MechanicalSoup/MechanicalSoup

Mechanical Soup是一个Python库,旨在模拟人类在使用浏览器时与网站的交互。它基于Python的Requests(用于HTTP会话)和BeautifulSoup(用于文档导航)构建。可自动存储和发送cookie,遵循重定向,遵循链接,并提交表单。
优点:
模拟人类行为的能力
快速抓取相当简单的网站
支持CSS和XPath选择器
04
AutoCrawler
开发语言:Python
GitHub(19.1K):
https://github.com/YoongiKim/AutoCrawler
这是个可控制Naver多进程图像爬虫(高品质速度可定制)。
05
WebMagic
开发语言:Java
GitHub(11K):
https://github.com/code4craft/webmagic

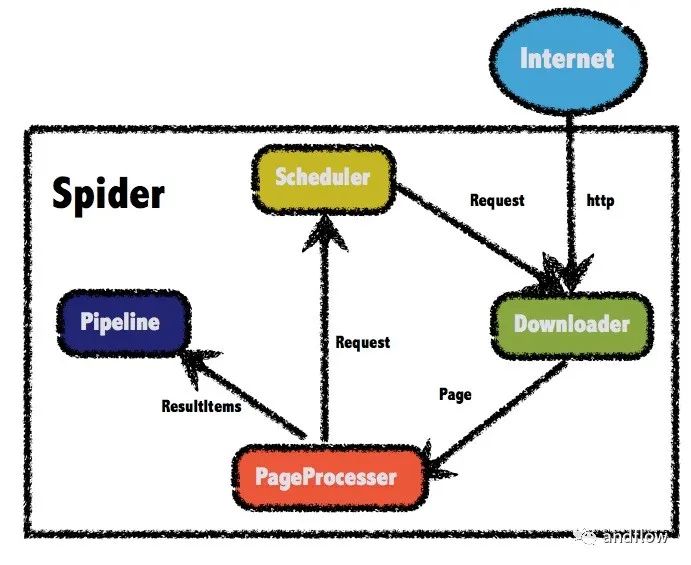
webmagic是一个开源的Java爬虫框架,目标是简化爬虫的开发流程,让开发者专注于逻辑功能的开发。下图是WebMagic的工作流程图。
优势:
完全模块化的设计,强大的可扩展性。
核心简单但是涵盖爬虫的全部流程,灵活而强大,也是学习爬虫入门的好材料。
提供丰富的抽取页面API。
无配置,但是可通过POJO+注解形式实现一个爬虫。
支持多线程。
支持分布式。
支持爬取js动态渲染的页面。
无框架依赖,可以灵活地嵌入到项目中去。
Maven:
<dependency><groupId>us.codecraft</groupId><artifactId>webmagic-core</artifactId><version>${webmagic.version}</version></dependency><dependency><groupId>us.codecraft</groupId><artifactId>webmagic-extension</artifactId><version>${webmagic.version}</version></dependency>
06
crawler4j
开发语言:Java
GitHub(4.5K):
https://github.com/yasserg/crawler4j

crawler4j是一个开源的Java网络爬虫,它提供了一个简单的接口, 抓取网页使用它,可以在几分钟内设置一个多线程的网络爬虫。
Maven:
<dependency><groupId>edu.uci.ics</groupId><artifactId>crawler4j</artifactId><version>4.4.0</version></dependency>
07
WebCollector
开发语言:Java
GitHub(3K):
https://github.com/CrawlScript/WebCollector
WebCollector是一个基于Java的开源网络爬虫框架。它提供了一些简单的界面,可以在5分钟内设置一个多线程网络爬虫。它除了是一个通用的爬虫框架之外,WebCollector还集成了CEPF(Web内容提取算法)。Maven:
<dependency><groupId>cn.edu.hfut.dmic.webcollector</groupId><artifactId>WebCollector</artifactId><version>2.73-alpha</version></dependency>
08
Apache Nutch
开发语言:Java
GitHub(2.7K):
https://github.com/apache/nutch

Apache Nutch是一个完全用Java编写的开源scraper,具有高度模块化的架构,提供了解析媒体类型、数据检索、查询和集群等插件。作为可插拔和模块化的,Nutch还提供了可扩展接口。
优点:
高度可扩展和可伸缩
遵守txt规则
充满活力的社区和积极发展
可插拔的解析、协议、存储和索引
09
Heritrix
开发语言:Java
GitHub(2.6K):
https://github.com/internetarchive/heritrix3

Heritrix是一个基于JAVA的开源爬虫工具,具有高度的可扩展性,并高度尊重robot.txt排除指令和Meta机器人标签,并以自适应速度收集数据,执行稳定性好。它提供了一个基于Web的用户界面,可通过Web浏览器访问,以供操作员控制、监控。
优点:
可更换的可插拔模块
基于web的界面
尊重robot.txt和Meta robot标记
延展性良好
10
Web-Harvest
开发语言:Java
下载地址:
https://sourceforge.net/projects/web-harvest/
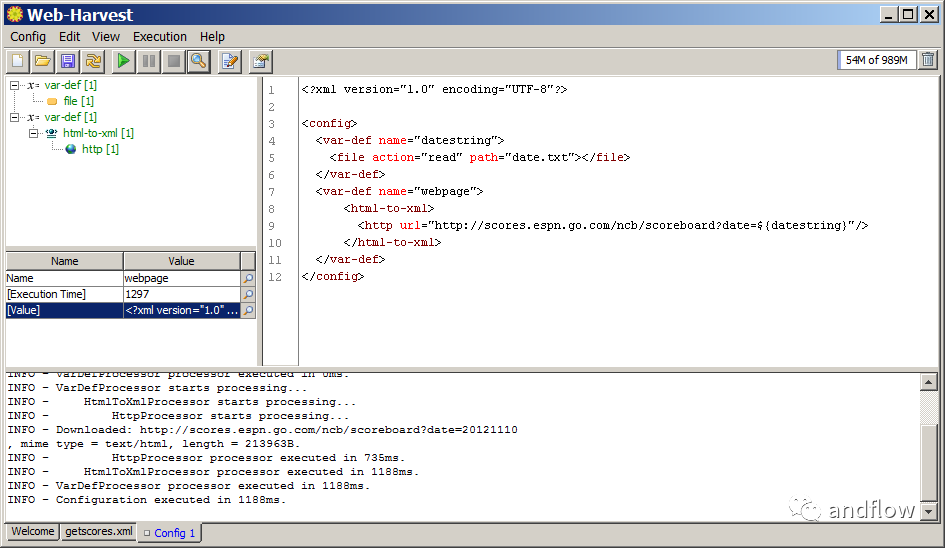
Web-Harvest是一个用Java编写的开源爬虫工具。它可以从指定的页面收集有用的数据。它利用XML、XQuery和正则表达式等技术来操作或过滤基于HTML/XML的网站的内容,可以很容易地扩展,以增强其提取能力。
优点:
可用于数据处理的强大文本和XML操作处理器
用于存储和使用的上下文变量
支持真实的脚本语言,可轻松集成到项目中
11
StormCrawler
开发语言: Java
GitHub(825):
https://github.com/DigitalPebble/storm-crawler

StormCrawler是一个成熟的开源Java网络爬虫。它由一系列可重用的资源和组件组成。可用于在Java中构建低延迟、可扩展、易优化的Web爬虫。
优点:
高度可扩展,可用于大规模递归爬网
易于使用其他Java库进行扩展
出色的线程管理,减少了抓取的延迟
12
crawlab
开发语言:Go
GitHub(10.4K):
https://github.com/crawlab-team/crawlab
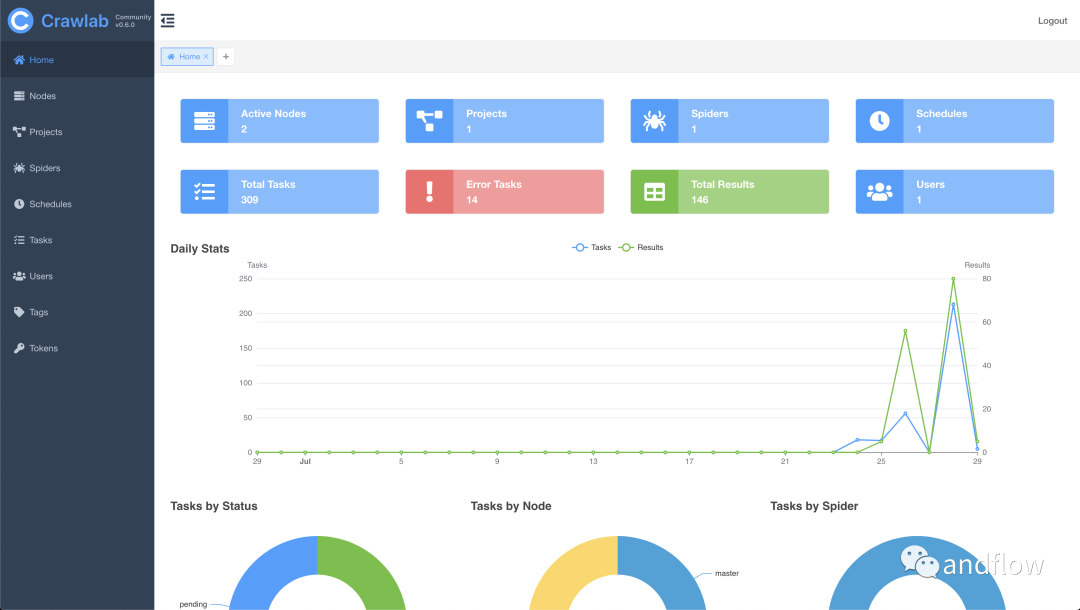
基于Golang的分布式网络爬虫管理平台,支持Python、NodeJS、Go、Java、PHP等多种语言,支持Scrapy、Puppeteer、Selenium等多种网络爬虫框架。
简单说:它是管理爬虫的管理工具。
13
ferret
开发语言:Go
GitHub(5.5K):
https://github.com/MontFerret/ferret
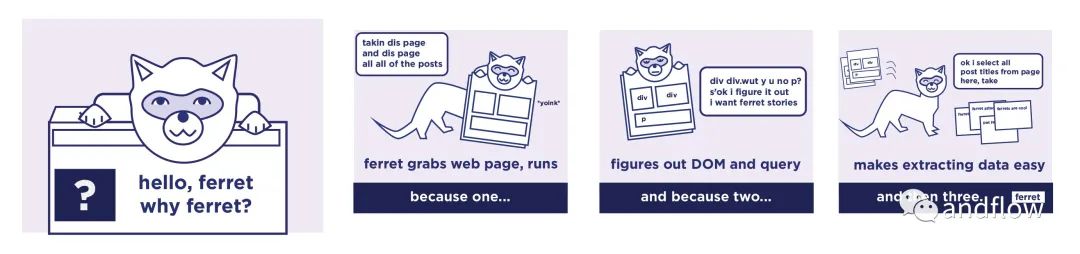
ferret是一个网页爬虫系统。旨在简化从Web中提取的数据,用于UI测试、机器学习、分析等。
ferret允许用户专注于数据。它使用自己的描述性语言抽象出底层技术的技术细节和复杂性。它非常便携、可扩展和快速。
优势:
支持描述性语言
支持静态和动态网页
可嵌入
可扩展
下面是ferret的架构图:
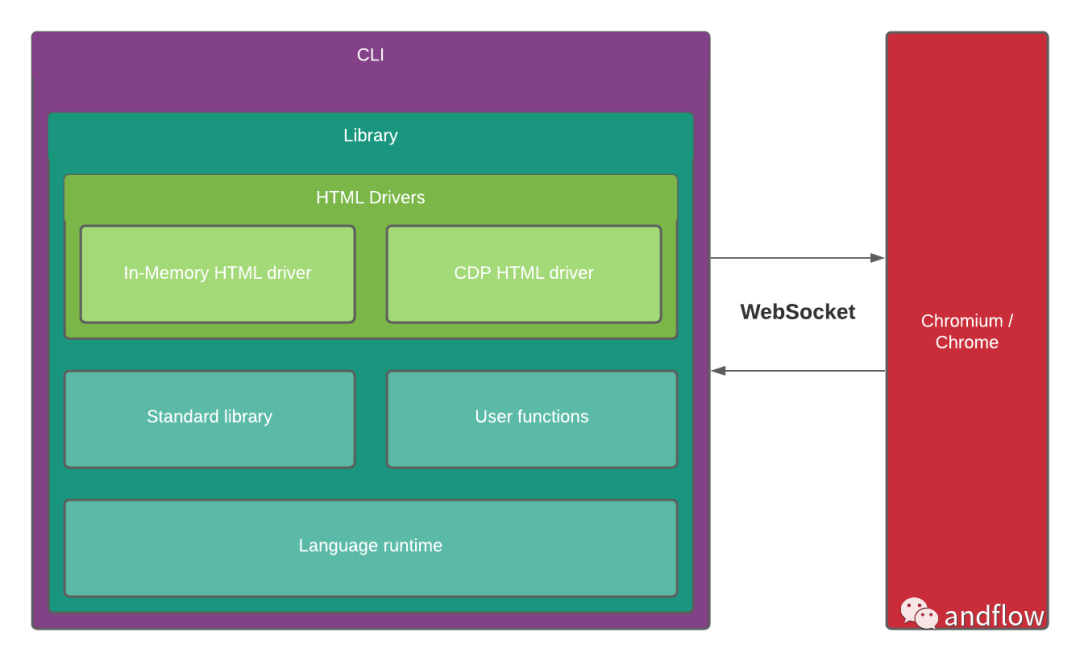
14
hakrawler
开发语言:Go
GitHub(4K):
https://github.com/hakluke/hakrawler
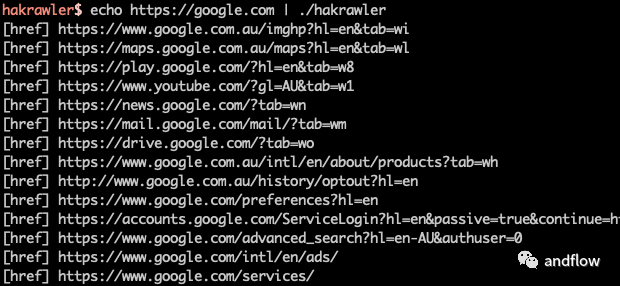
这是一个简单、快速的Web爬虫,旨在轻松、快速地发现Web应用程序中的端点和资产。用于收集URL和JavaScript文件位置的快速golang爬虫。是一个很棒的Gocolly库的简单实现。
15
crawlergo
开发语言:Go
GitHub(2.6K):
https://github.com/Qianlitp/crawlergo

crawlergo是一个使用chrome headless模式进行URL收集的网页爬虫。它对整个网页的关键位置与DOM渲染阶段进行HOOK,尽可能收集网站暴露的入口,自动进行表单填充并提交,配合智能的JS触发事件。内置URL去重模块,过滤掉了大量伪静态URL,对于大型网站仍保持较快的解析与抓取速度,最后得到高质量的请求结果集合。
优势:
原生浏览器环境,线程池调度任务
表单智能填充、自动化提交
完整DOM事件收集,自动化触发
智能URL去重,去掉大部分的重复请求
全面分析收集,包括javascript文件内容、页面注释、robots.txt文件和常见路径Fuzz
支持Host绑定,自动添加Referer
支持请求代理,支持爬虫结果主动推送
16
geziyor
开发语言:Go
GitHub(2.3K):
https://github.com/geziyor/geziyor
Geziyor是一个非常快速的网页抓取和网页抓取框架。它可以用来抓取网站并从中提取结构化数据。Geziyor可用于广泛的目的,如数据挖掘,监控和自动化测试。
17
Gospider
开发语言:Go
GitHub(2.2K):
https://github.com/jaeles-project/gospider
Gospider是一个用Go语言编写的快速网络爬虫。
可在Docker运行:
# Clone the repogit clone https://github.com/jaeles-project/gospider.git# Build the contianerdocker build -t gospider:latest gospider# Run the containerdocker run -t gospider -h
18
Gocrawl
开发语言:Go
GitHub(2K):
https://github.com/PuerkitoBio/gocrawl
一个轻量级,高并发网络爬虫。
19
fetchbot
开发语言:Go
GitHub(777+):
https://github.com/PuerkitoBio/fetchbot

这是一个Go包,提供了一个简单而灵活的网络爬虫功能,遵循robots.txt 策略,支持延迟机制。
这是一个基于gocrawl重新改造的爬虫,具备更简单的API,更少的内置功能,但更灵活。
20
Node-crawler
开发语言: JavaScript
GitHub(6.5K):
https://github.com/bda-research/node-crawler

Node-crawler是一个强大的、流行的、基于Node.js的网络爬虫。完全用Node.js编写,支持非阻塞异步I/O,实现爬虫的流水线运行机制。同时支持DOM的快速选取(无需编写正则表达式)。
优点:
支持速率控制
支持不同优先级的requestsURL请求
可配置的池大小和重试次数
服务器端使用Cheerio(默认)或JSDOM实现jQuery自动插入DOM
21
EasySpider
开发语言:JavaScript
GitHub(17.5K):
https://github.com/NaiboWang/EasySpider
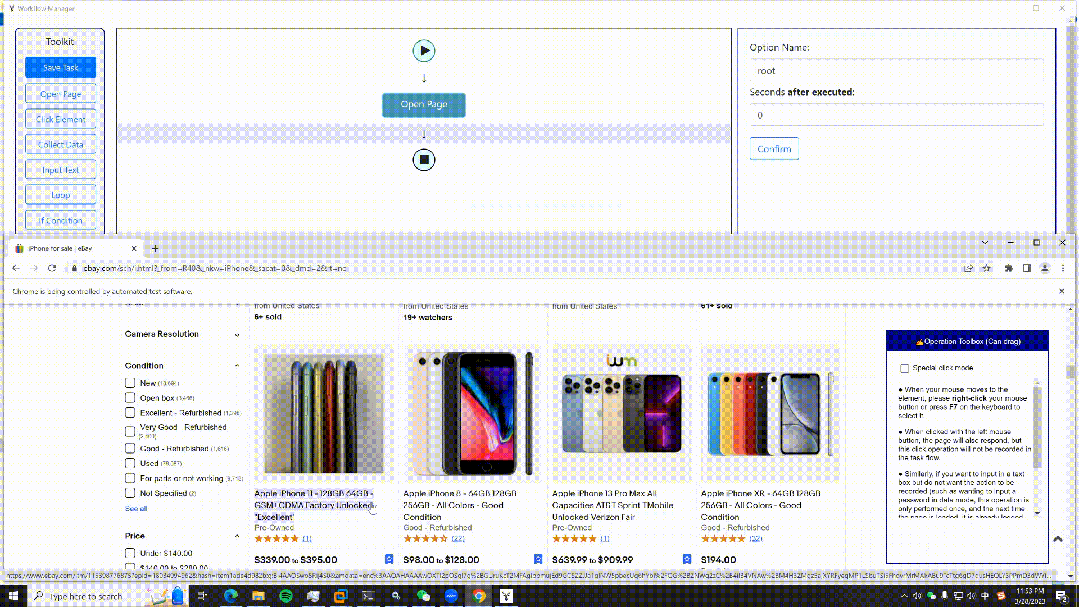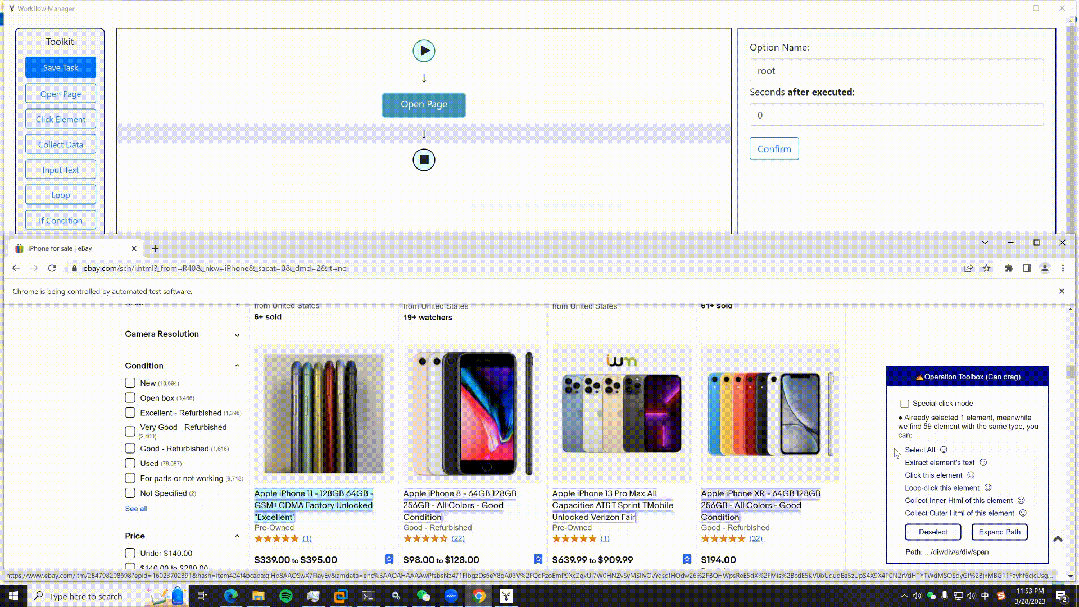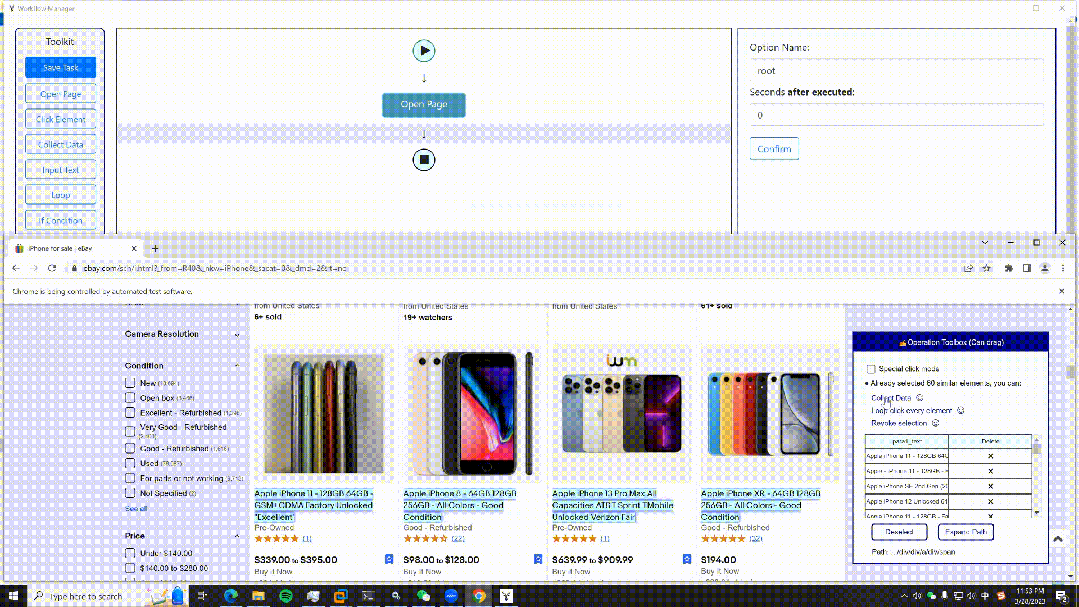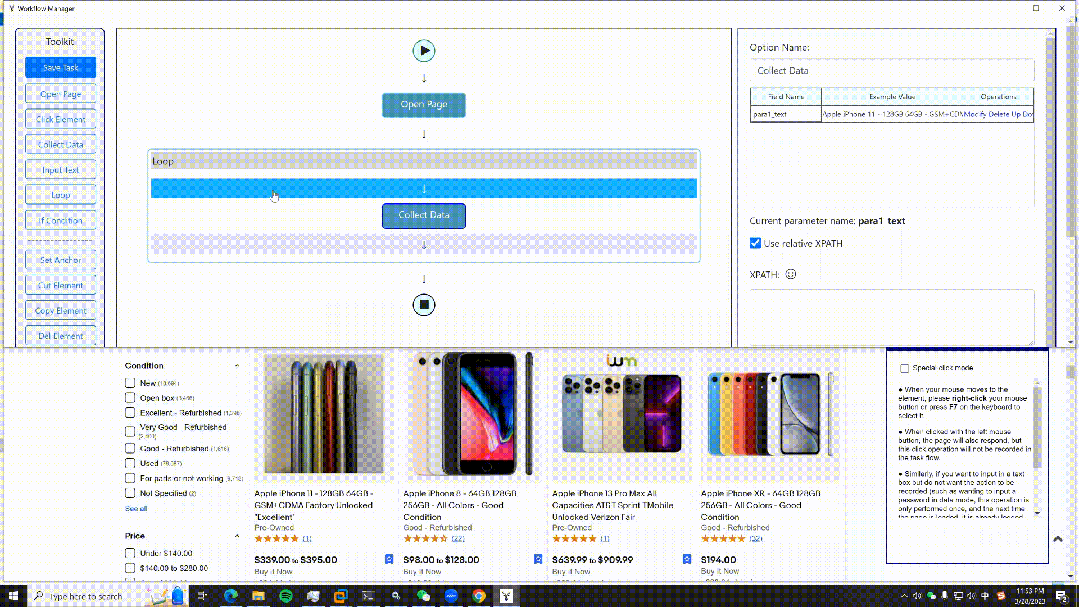
这是一个可视化浏览器自动化测试/数据采集/爬虫软件,可以使用图形化界面,无代码可视化的设计和执行任务。只需要在网页上选择自己想要操作的内容并根据提示框操作即可完成任务的设计和执行。同时软件还可以单独以命令行的方式进行执行,从而可以很方便地嵌入到其他系统中。
原文链接:
