
阅读量:0
整体思路参考如下
1.首先单独conda create 一个环境,用来安装依赖
pip install --upgrade --quiet langchain langchain-community langchain-openai langchain-experimental neo4j 2.首先是基础代码,这一步先查看当前模型的能力是否能够提取出文本中的实体和关系。(在这之前,笔者尝试了deepseek,glm4等api)其中glm-4 api10次大概有2次能够识别正确结果。
后切换为qwen api,初步代码如下,参考的是langchain + neo4j
#!/usr/bin/python # -*- coding: <utf-8> -*- from langchain.docstore.document import Document from langchain.text_splitter import CharacterTextSplitter from langchain_community.document_loaders import TextLoader from langchain_community.vectorstores import Neo4jVector from langchain_openai import OpenAIEmbeddings, ChatOpenAI from langchain_community.graphs import Neo4jGraph from langchain_experimental.graph_transformers import LLMGraphTransformer from langchain.llms import Tongyi import os # 设置api_key os.environ["DASHSCOPE_API_KEY"] = "sk-key" llm = Tongyi() #链接neo4j 账号密码 username = "user" password = "password" url = "your-url" database = "neo4j" graph = Neo4jGraph( url=url, username=username, password=password ) # LLMGraphTransformer模块 构建图谱 llm_transformer = LLMGraphTransformer(llm=llm) # 导入文档————参考链接中居里夫人那段文本 raw_documents = TextLoader(r"E:\task1\data\1.txt").load() # 将文本分割成每个包含20个tokens的块,并且这些块之间没有重叠 text_splitter = CharacterTextSplitter.from_tiktoken_encoder( chunk_size=20, chunk_overlap=0 ) # Chunk the document documents = text_splitter.split_documents(raw_documents) # 打印原始文档内容 print(f"Raw Document Content: {raw_documents[0].page_content}") # 打印分块后的文档内容 for i, doc in enumerate(documents): print(f"Chunk {i}: {doc.page_content}") # 打印转换过程中的中间结果 graph_documents = llm_transformer.convert_to_graph_documents(documents) for i, graph_doc in enumerate(graph_documents): print(f"Graph Document {i}:") print(f"Nodes: {graph_doc.nodes}") print(f"Relationships: {graph_doc.relationships}") 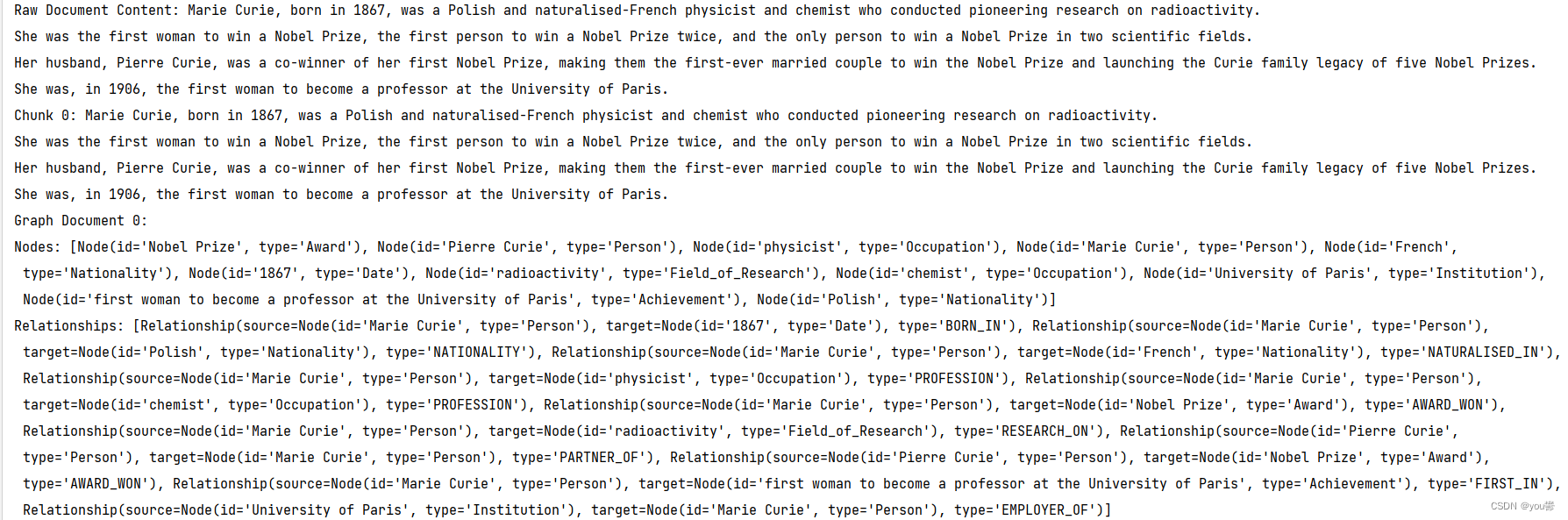
以上是运行结果,可以看到提取的节点大多都囊括了。
但是对于一个较长的语句,是我目前不需要的。
3.后续需要调整代码,限制节点的类型,以及关系的类型。(根据参考链接进行修改)
#!/usr/bin/python # -*- coding: <utf-8> -*- from langchain.docstore.document import Document from langchain.text_splitter import CharacterTextSplitter from langchain_community.document_loaders import TextLoader from langchain_community.vectorstores import Neo4jVector from langchain_openai import OpenAIEmbeddings, ChatOpenAI from langchain_community.graphs import Neo4jGraph from langchain_experimental.graph_transformers import LLMGraphTransformer from langchain.llms import Tongyi import os # 设置api_key os.environ["DASHSCOPE_API_KEY"] = "sk-key" llm = Tongyi() #链接neo4j 账号密码 username = "user" password = "password" url = "your-url" database = "neo4j" graph = Neo4jGraph( url=url, username=username, password=password ) # 导入文档 raw_documents = TextLoader(r"E:\task1\data\1.txt").load() # 将文本分割成每个包含20个tokens的块,并且这些块之间没有重叠 text_splitter = CharacterTextSplitter.from_tiktoken_encoder( chunk_size=20, chunk_overlap=0 ) # Chunk the document documents = text_splitter.split_documents(raw_documents) # 打印原始文档内容 print(f"Raw Document Content: {raw_documents[0].page_content}") # 打印分块后的文档内容 for i, doc in enumerate(documents): print(f"Chunk {i}: {doc.page_content}") # 打印转换过程中的中间结果 llm_transformer_filtered = LLMGraphTransformer( llm=llm, allowed_nodes=["Person", "Country", "Organization"], allowed_relationships=["NATIONALITY", "LOCATED_IN", "WORKED_AT", "SPOUSE"], ) graph_documents_filtered = llm_transformer_filtered.convert_to_graph_documents( documents ) for i, graph_doc in enumerate(graph_documents_filtered): print(f"Graph Document {i}:") print(f"Nodes: {graph_doc.nodes}") print(f"Relationships: {graph_doc.relationships}") 
以上是限制好了节点的类型,关系有哪些。
4.最后添加到你链接的Neo4j图谱中。
graph.add_graph_documents( graph_documents_filtered, baseEntityLabel=True, include_source=True ) 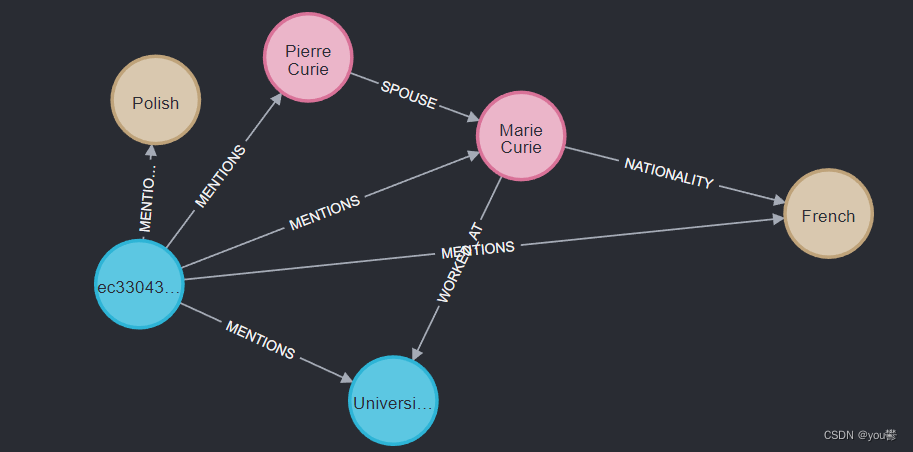
5.构建非结构化检索(verctor_index)
# 文本向量化 混合检索 文本和关键词检索器构建 vector_index = Neo4jVector.from_existing_graph( embeddings, search_type="hybrid", node_label="Document", text_node_properties=["text"], embedding_node_property="embedding" ) 6.结构化检索器(图谱)
① 提取question中的实体,后续用于图谱中去提取结构化的那些数据
from langchain.prompts import ( PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate, ) from langchain.output_parsers import PydanticOutputParser from pydantic import BaseModel, Field from typing import List from langchain.llms import OpenAI # 假设使用OpenAI的LLM import json # Extract entities from text 定义抽取实体的类 class Entities(BaseModel): """Identifying information about entities.""" names: List[str] = Field( ..., description="All the person, organization, or business entities that " "appear in the text", ) @classmethod def from_json(cls, json_data: dict): names = [] if 'entities' in json_data: for entity in json_data['entities']: names.append(entity['entity']) return cls(names=names) entity_query = "Where did Marie Curie work?" # Set up a parser + inject instructions into the prompt template. parser = PydanticOutputParser(pydantic_object=Entities) # 更新 ChatPromptTemplate 以包含新的提示词 chat_prompt = ChatPromptTemplate.from_messages( [ ( "system", "You are extracting organization and person entities from the text.", ), ( "human", "Use the given format to extract information from the following " "input: {question}. Please ensure the output is in valid JSON format.", ), ] ) # 创建提示模板 prompt_template = PromptTemplate( template="Answer the user query.\n{format_instructions}\n{query}\n", input_variables=["query"], partial_variables={"format_instructions": parser.get_format_instructions()}, ) # 格式化输入 _input = chat_prompt.format_prompt(question=entity_query) # 获取 LLM 输出 output = llm(_input.to_string()) # 解析输出 parsed_output = json.loads(output) # 使用自定义的 from_json 方法解析输出 entities = Entities.from_json(parsed_output) # 获取 names 列表 names = entities.names print(names) ② 构建结构化的检索器
def generate_full_text_query(input: str) -> str: """ Generate a full-text search query for a given input string. This function constructs a query string suitable for a full-text search. It processes the input string by splitting it into words and appending a similarity threshold (~2 changed characters) to each word, then combines them using the AND operator. Useful for mapping entities from user questions to database values, and allows for some misspelings. """ full_text_query = "" words = [el for el in remove_lucene_chars(input).split() if el] for word in words[:-1]: full_text_query += f" {word}~2 AND" full_text_query += f" {words[-1]}~2" return full_text_query.strip() # Fulltext index query def structured_retriever(names: List) -> str: """ Collects the neighborhood of entities mentioned in the question """ result = "" # # 前面提取到的实体 # entities = entity_chain.invoke({"question": question}) # entities = names # for entity in entities.names: for entity in names: response = graph.query( """CALL db.index.fulltext.queryNodes('entity', $query, {limit:2}) YIELD node,score CALL { WITH node MATCH (node)-[r:!MENTIONS]->(neighbor) RETURN node.id + ' - ' + type(r) + ' -> ' + neighbor.id AS output UNION ALL WITH node MATCH (node)<-[r:!MENTIONS]-(neighbor) RETURN neighbor.id + ' - ' + type(r) + ' -> ' + node.id AS output } RETURN output LIMIT 50 """, {"query": generate_full_text_query(entity)}, ) result += "\n".join([el['output'] for el in response]) return result 7.将非结构化检索器和结构化检索结合在一起
def retriever(question: str,names:List): print(f"Search query: {question}") structured_data = structured_retriever(names) unstructured_data = [el.page_content for el in vector_index.similarity_search(question)] final_data = f"""Structured data: {structured_data} Unstructured data: {"#Document ". join(unstructured_data)} """ return final_data 8.最后构建RAG链
# Condense a chat history and follow-up question into a standalone question _template = """Given the following conversation and a follow up question, rephrase the follow up question to be a standalone question, in its original language. Chat History: {chat_history} Follow Up Input: {question} Standalone question:""" # noqa: E501 CONDENSE_QUESTION_PROMPT = PromptTemplate.from_template(_template) def _format_chat_history(chat_history: List[Tuple[str, str]]) -> List: buffer = [] for human, ai in chat_history: buffer.append(HumanMessage(content=human)) buffer.append(AIMessage(content=ai)) return buffer _search_query = RunnableBranch( # If input includes chat_history, we condense it with the follow-up question ( RunnableLambda(lambda x: bool(x.get("chat_history"))).with_config( run_name="HasChatHistoryCheck" ), # Condense follow-up question and chat into a standalone_question RunnablePassthrough.assign( chat_history=lambda x: _format_chat_history(x["chat_history"]) ) | CONDENSE_QUESTION_PROMPT | llm | StrOutputParser(), ), # Else, we have no chat history, so just pass through the question RunnableLambda(lambda x : x["question"]), ) template = """Answer the question based only on the following context: {context} Question: {question} Use natural language and be concise. Answer:""" prompt = ChatPromptTemplate.from_template(template) chain = ( RunnableParallel( { "context": _search_query | retriever, "question": RunnablePassthrough(), } ) | prompt | llm | StrOutputParser() ) 提问
chain.invoke({"question": "Where did Marie Curie work?"}) 
最后实现了整个graphRAG的链路。
参考文档:https://blog.langchain.dev/enhancing-rag-based-applications-accuracy-by-constructing-and-leveraging-knowledge-graphs/
https://blog.csdn.net/KQe397773106/article/details/138051927
源代码参考复现:https://github.com/tomasonjo/blogs/blob/master/llm/enhancing_rag_with_graph.ipynb?ref=blog.langchain.dev
