
阅读量:0
关注小庄 顿顿解馋(●’◡’●)

上篇回顾
我们上篇学习了本质为数组的数据结构—顺序表,顺序表支持下标随机访问而且高速缓存命中率高,然而可能造成空间的浪费,同时增加数据时多次移动会造成效率低下,那有什么解决之法呢?这就得引入我们链表这种数据结构
文章目录
一.何为链表
🏠 链表概念
概念:链表是一种
物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表
中的指针链接次序实现的 。
特点:物理结构不一定连续,逻辑结构连续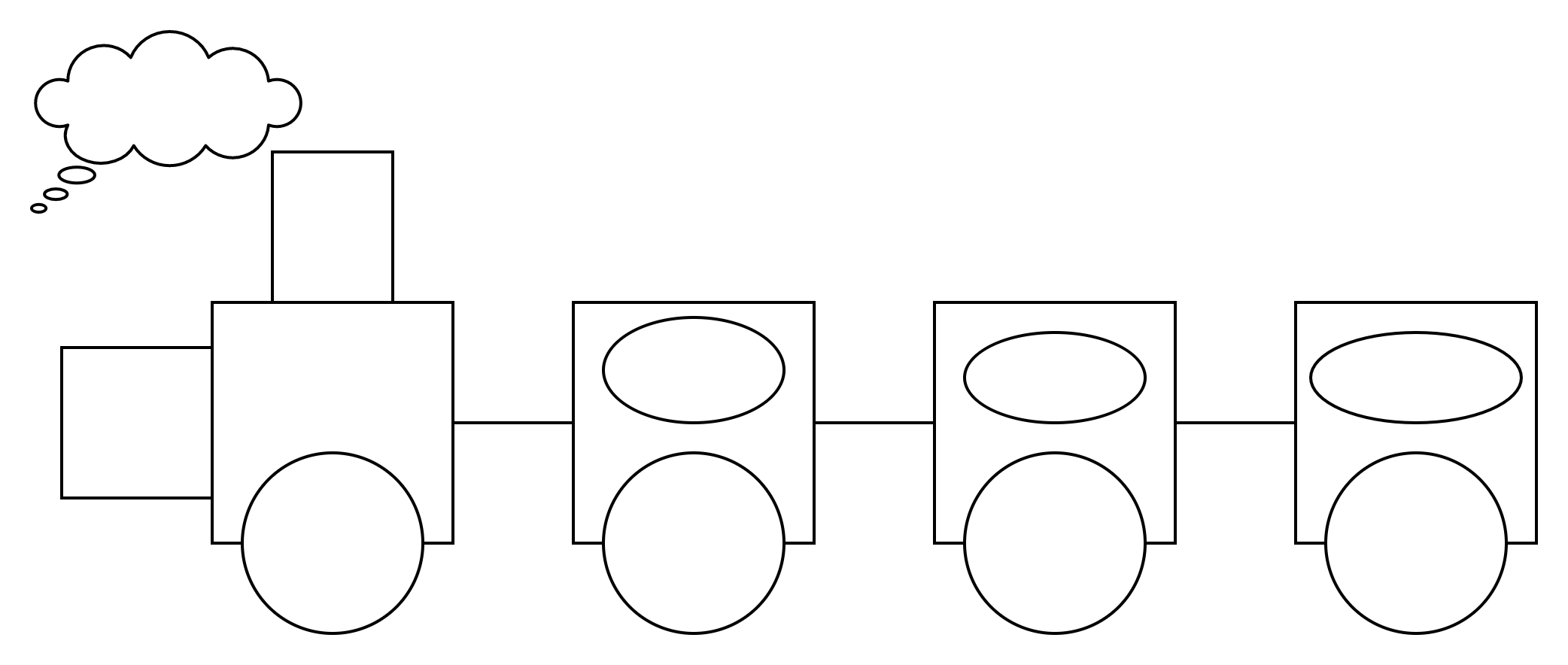
我们的链表结构类似我们的火车,有头有尾,中间每个结点被有序链接;与火车不同的是,链表的结点可能不是紧挨着的。
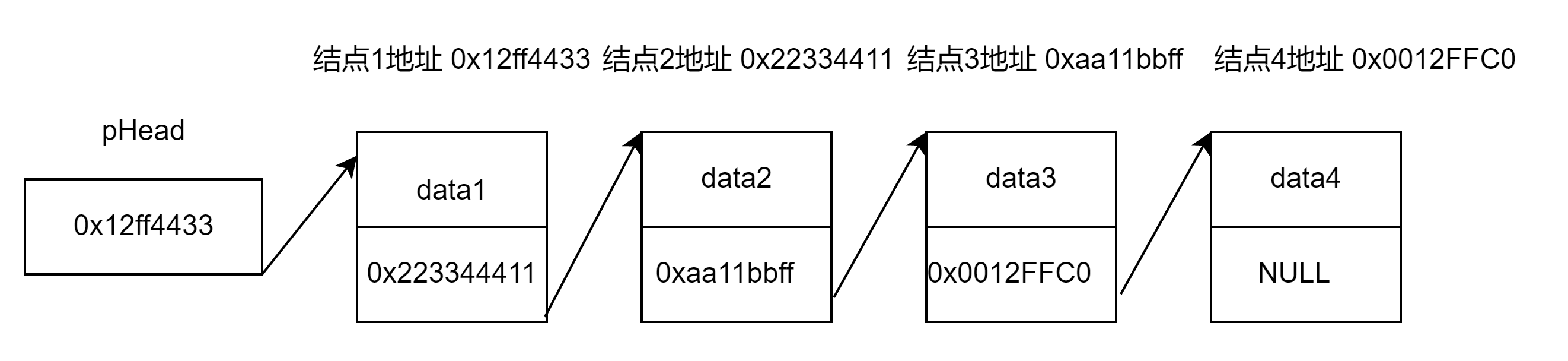
类似这样,我们可以得出:
1.每个结点由数据和下一结点地址两部分组成,而每个结点构成了一个链表。
2.每个结点保存的是下一个结点的地址,这样就能找到下一个结点,最后为空就停止
3.每个结点的地址不是连续的,可以体现出链表的物理结构不一定连续
注:我们的结点一般是在堆区开辟的,因为此时你在程序结束前不free就会一直存在这块空间,同时可根据需要灵活申请结点存数据。
这样我们就可以用一个结构体封装每个结点:
typedef int Datatype; typedef struct ListNode { Datatype x; struct ListNode* next; }Node; 注: 这里我们可以用typedef来重命名我们要存储的数据类型,这样对于不同数据的操作我们只要改typedef即可。
🏠 链表的分类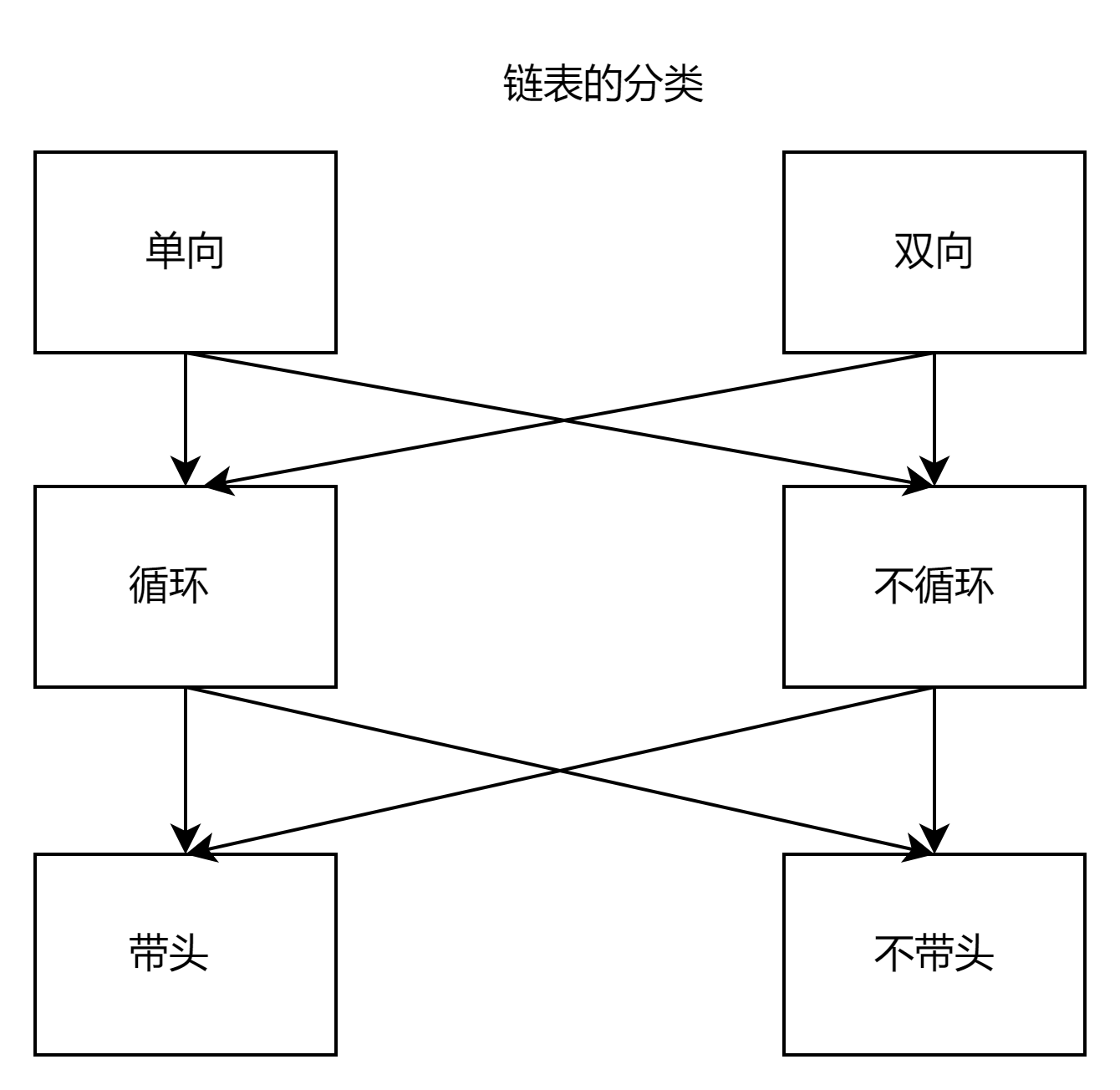
我们根据链表三个特点:
1.带头不带头 2.单向还是双向 3.循环还是不循环组合成了如上的8种链表
本篇博客,我们要实现的是单向不带头不循环链表(单链表),至于什么是带头,双向,循环我们下回双链表再进行讲解
二.单链表的实现
无头+单向+不循环链表的增删差改
🏠 链表的打印
- 链表数据的打印
这个接口就很好的体现了结点结构保存指针的妙处了~
//链表的打印 void SLTPrint(Node* phead) { asser(phead); Node* cur = phead; while (cur) { printf("%d ", cur->x); cur = cur->next; } } 🏠 链表的头插和尾插
- 链表的尾插
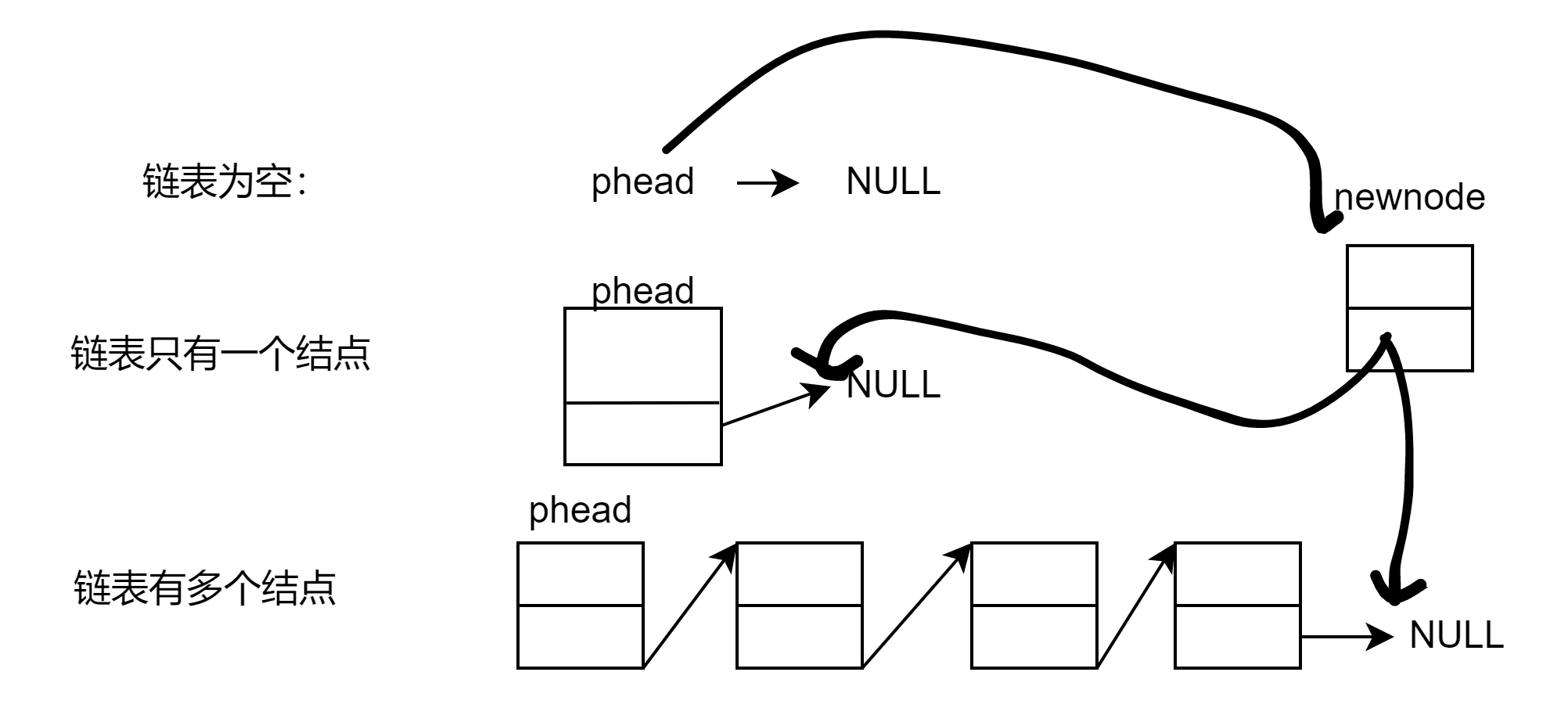
对于链表的尾插要注意几个问题:1.申请新结点 2.链表是否为空
解决方法:1.对于链表为空,直接让申请的新节点作为头节点 2.对于不为空的链表,首先要
找到尾结点,再进行插入3.对于申请新节点,我们后续的头插也要使用我们可以封装成一个接口,同时结点在堆区申请,调用完接口就不会释放了。
//申请新节点 Node* BuyNode(Datatype x) { Node* newnode = (Node*)malloc(sizeof(Node)); if (newnode == NULL) { perror("malloc failed"); return; } newnode->next = NULL; newnode->x = x; return newnode; } void SLTPushBack(Node** pphead, Datatype x) { assert(pphead); //申请新节点 Node* newnode = BuyNode(x); //链表为空 if (NULL == *pphead) { *pphead = newnode; return; } //链表不为空:1.找尾巴结点2.插入新节点 Node* ptail = *pphead; while (ptail->next) { ptail = ptail->next; } ptail->next = newnode; } 思考:这里为什么传二级指针?如果不传二级指针呢?
void SLTNPushBack(Node* pphead, Datatype x) { //申请新节点 Node* newnode = BuyNode(x); //链表为空 if (NULL == pphead) { pphead = newnode; return; } //链表不为空:1.找尾巴结点2.插入 Node* ptail = pphead; while (ptail->next) { ptail = ptail->next; } ptail->next = newnode; } int main() { Node* n1 = NULL; SLTNPushBack(n1,1); return 0; } 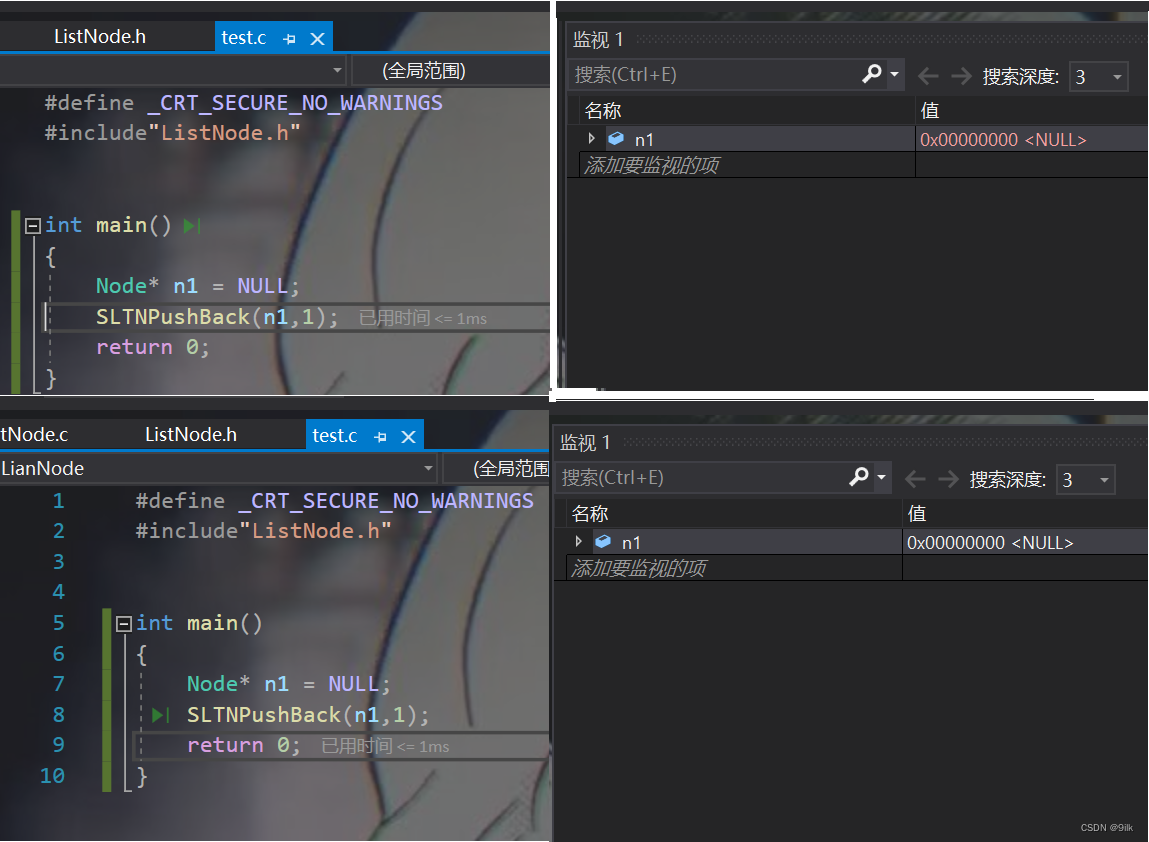
经过观察传一级指针版本的调用前后,我们发现n1这个指针变量存储的值并没发生改变,究其原因如下图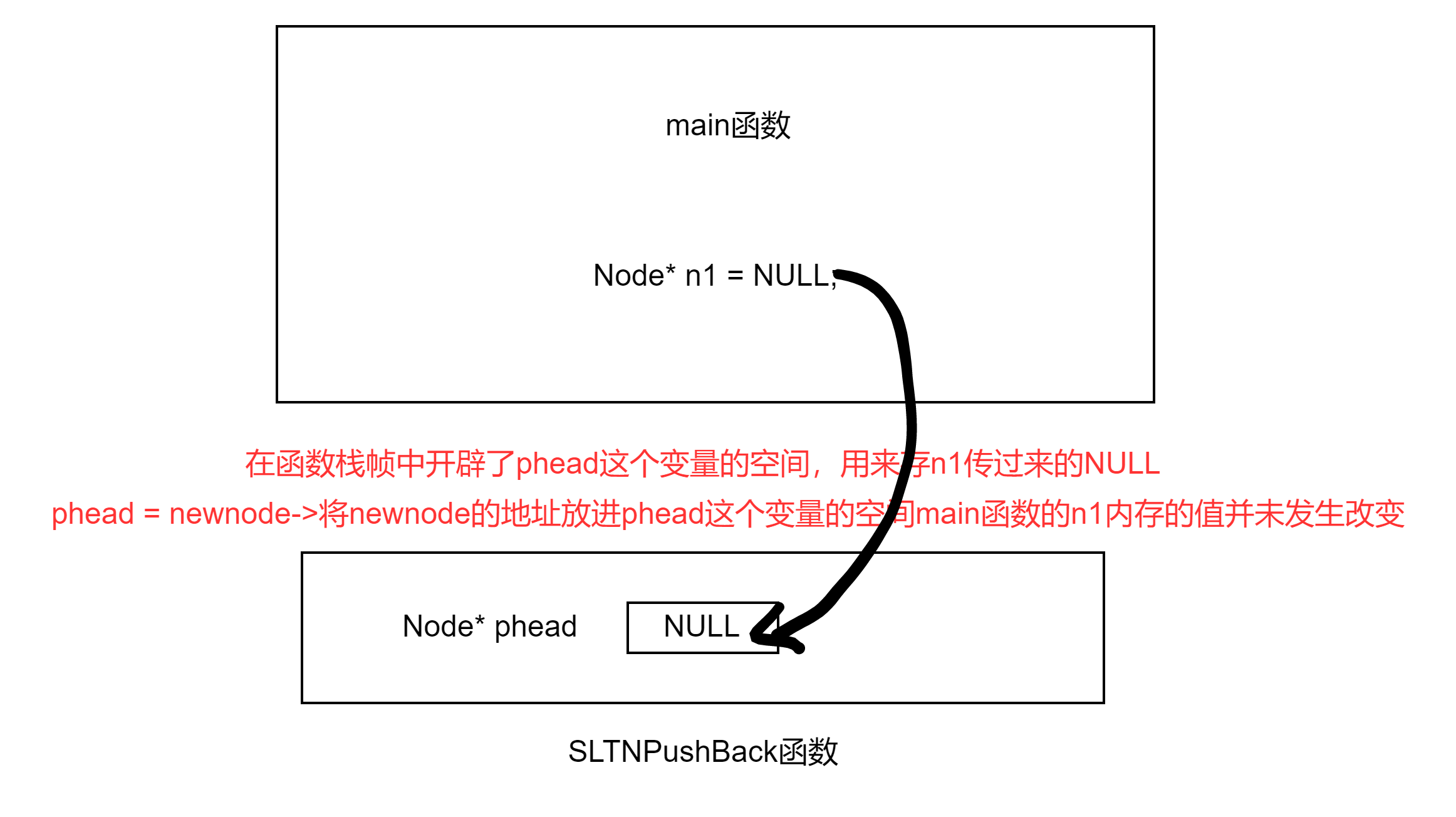
- 链表的头插
,
*对于链表的头插要注意的问题:1.申请新节点 2.链表释放为空 *
解决方法:1.链表为空时,申请的新结点作为头结点 2.链表不为空时,让newnode->next指向原来头节点,再让newnode成为新的头节点。
void SLTPushFront(Node** pphead, Datatype x) { assert(pphead); //申请新节点 Node* newnode = BuyNode(x); //链表为空 if (NULL == *pphead) { *pphead = newnode; return; } newnode->next = *pphead; *pphead = newnode; } 🏠 链表的尾删和头删
- 链表的尾删
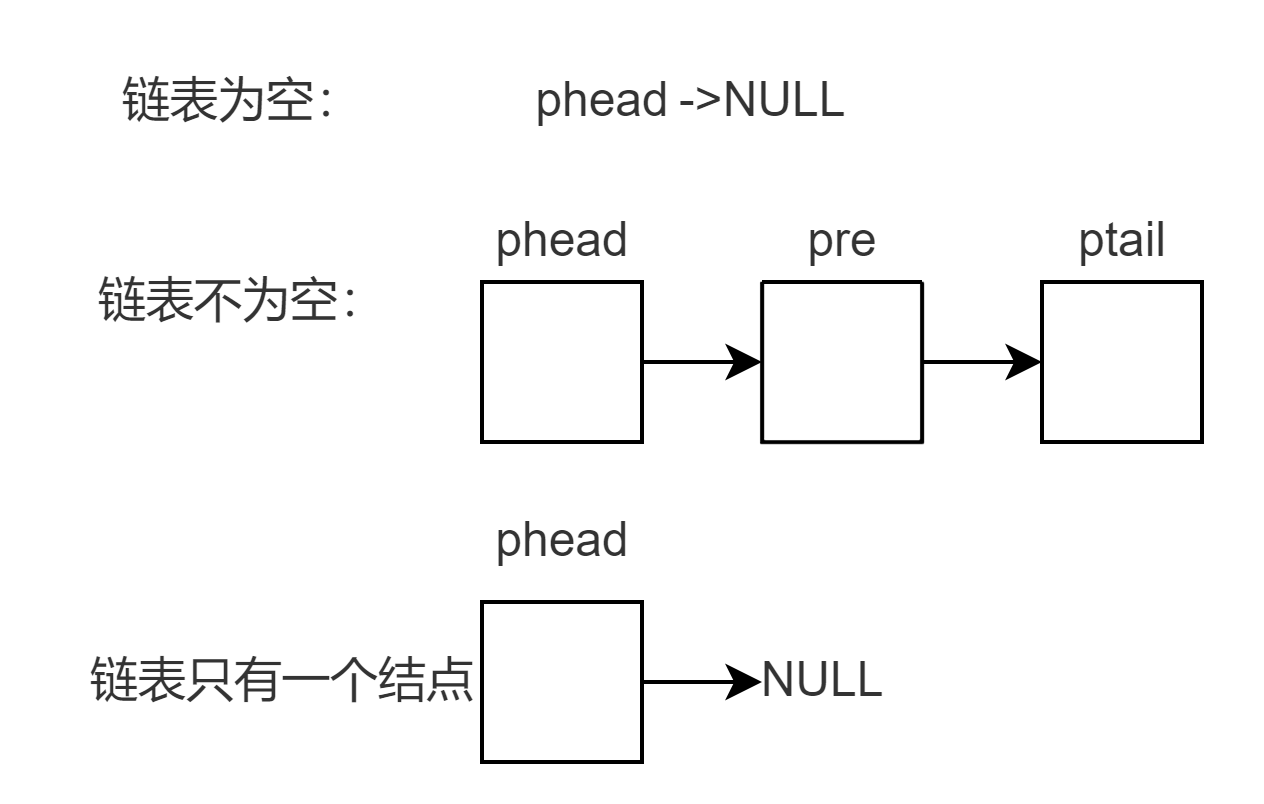
对于链表的尾删,我们需要分三种情况!
1.链表为空时此时删不了直接退出
2.链表只有一个结点时,释放头节点,置phead为空
3.链表有多个结点时,我们需要遍历链表找到尾结点的前置结点,先释放尾节点再将前置结点的next置为空注:不能先将前置结点的next置为空,再释放尾结点,此时就找不到尾结点的地址了。
//链表的尾删和头删 void SLTPopBack(Node** pphead) { assert(pphead); assert(*pphead);//判断链表不为空 if ((*pphead)->next == NULL) { free(*pphead); *pphead = NULL; return; } Node* pre = *pphead; while (pre->next->next) { pre = pre->next; } free(pre->next); pre->next = NULL; } - 链表的头删

对于链表的头删,分为两种情况就可以了,因为有了phead很方便~
1.链表为空时,删不了直接断言下
2.链表不为空时,记录头节点的下一个位置,先释放头节点,再更换phead指向的位置
注:这里也不能先更新phead再释放头结点
void SLTPopFront(Node** pphead) { assert(pphead); assert(*pphead); Node* pNext = (*pphead)->next; free(*pphead); *pphead = pNext; } 🏠 链表指定位置的插入和删除
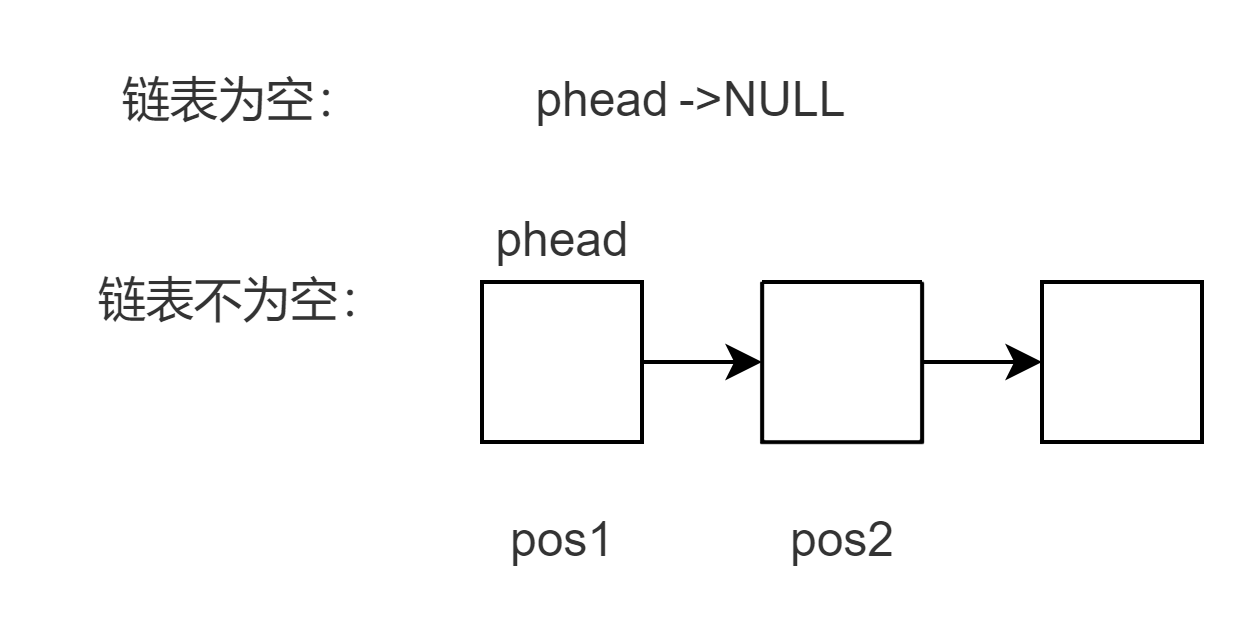
1.链表为空时,无法插入
2.pos位置结点刚好是头结点,直接头插或头删
3.pos位置结点不是头节点,需要找到pos位置的前置结点,记录位置。
void NodeInpos(Node** pphead, Node* pos, Datatype x) { assert(pphead); //pos不为空 -》 链表一定不能为空 assert(pos); assert(*pphead); //建立一个新节点 Node* newnode = BuyNode(x); //pos刚好是头结点的情况 if (*pphead == pos) { //运用头插 NodeinFront(pphead,x); return; } //pos刚好不是头结点 //1.先找出pos前面的结点pre 2.newnode->next = pre->next 3.pre-<next = newnode Node* pre = *pphead; while (pre->next != pos) { pre = pre->next; } newnode->next = pre->next; pre->next = newnode; } void NodeDelpos(Node** pphead, Node* pos) { assert(pphead); assert(pos); assert(*pphead); //pos刚好是第一个结点 执行头删 if (*pphead == pos) { NodeDelFront(pphead); return; } //pos不是第一个结点 1.先找到那个pos前面结点pre 2.pre->next = pos->next 3.free Node* pre = *pphead; while (pre->next != pos) { pre = pre->next; } pre->next = pos->next; free(pos); pos = NULL; } 🏠 链表的查找
Node* NodeFind(Node** phead, Datatype x) { assert(phead); //遍历链表 Node* pcur = *phead; while (pcur) { if (pcur->data == x) { return pcur; } pcur = pcur->next; } //找不到则返回NULL } 这里建议用一个临时变量来遍历~
🏠 链表的销毁
void NodeDestroy(Node** pphead) { assert(pphead); assert(*pphead); //1.创一个临时变量存pcur->next的地址 Node* pcur = *pphead; while (pcur) { Node* next = pcur->next; free(pcur); pcur = next; } *pphead = NULL; } 注: 这里要保存好下一个结点地址,销毁后就能继续遍历
三.单链表的分析以及与顺序表的比较
🏠 单链表的优缺点
通过实现我们的单链表,我们发现单链表有以下优点
1.单链表不存在空间浪费(根据需求灵活在堆上申请新结点)
2.单链表的任意插入和删除效率高
(分析: 这里是已经确定插入的位置,对于链表只需改变指针的指向就能实现插入和删除,时间复杂度是O(1),而数组插入和删除需要遍历数组,时间复杂度是O(N))
单链表也不是万能的,它在一些应用场景也发挥不出来作用
1.不支持随机访问
2.缓存命中率低
3.查找效率低
总结:链表适用于频繁任意插入和删除的场景,不适用于随机访问和查找
🏠 单链表与顺序表的比较
| 单链表 | 顺序表 |
|---|---|
| 物理空间不一定连续 | 物理空间一定连续 |
| 不支持随机访问 | 支持下标随机访问 |
| 插入和删除效率高 O(1) | 插入和删除效率低 O(N) |
| 缓存命中率低 | 缓存命中率高 |
| 无空间的浪费 | 可能造成数据丢失和空间浪费 |
| 缓存利用率高 |
综上 我们可以根据场景需求选择不同的结构,灵活运用数据~
本次分享到这结束了,下篇我们将讲解双向链表,不妨来个一键三连捏
