
阅读量:0
1、LLM 大模型文档语义分块
参考:
https://blog.csdn.net/m0_59596990/article/details/140280541
根据上下句的语义相关性,相关就组合成一个分块,不相关就当场两个快
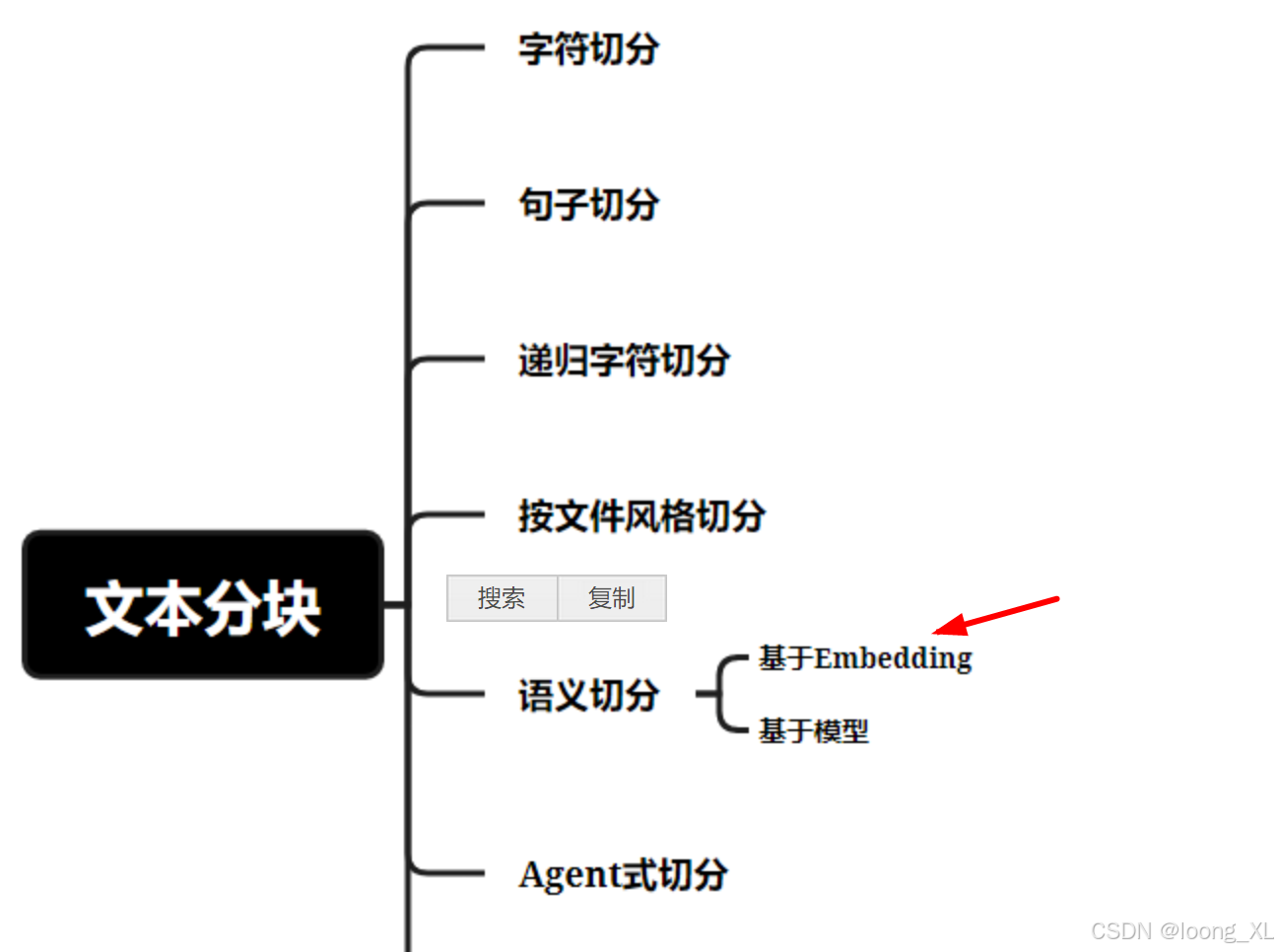
语义模型用的bert-base-chinese:
https://huggingface.co/google-bert/bert-base-chinese
代码:
对水浒传的分块
import torch from transformers import BertTokenizer, BertModel import re import os from scipy.spatial.distance import cosine def get_sentence_embedding(sentence, model, tokenizer): """ 获取句子的嵌入表示 参数: sentence