
阅读量:0
前言
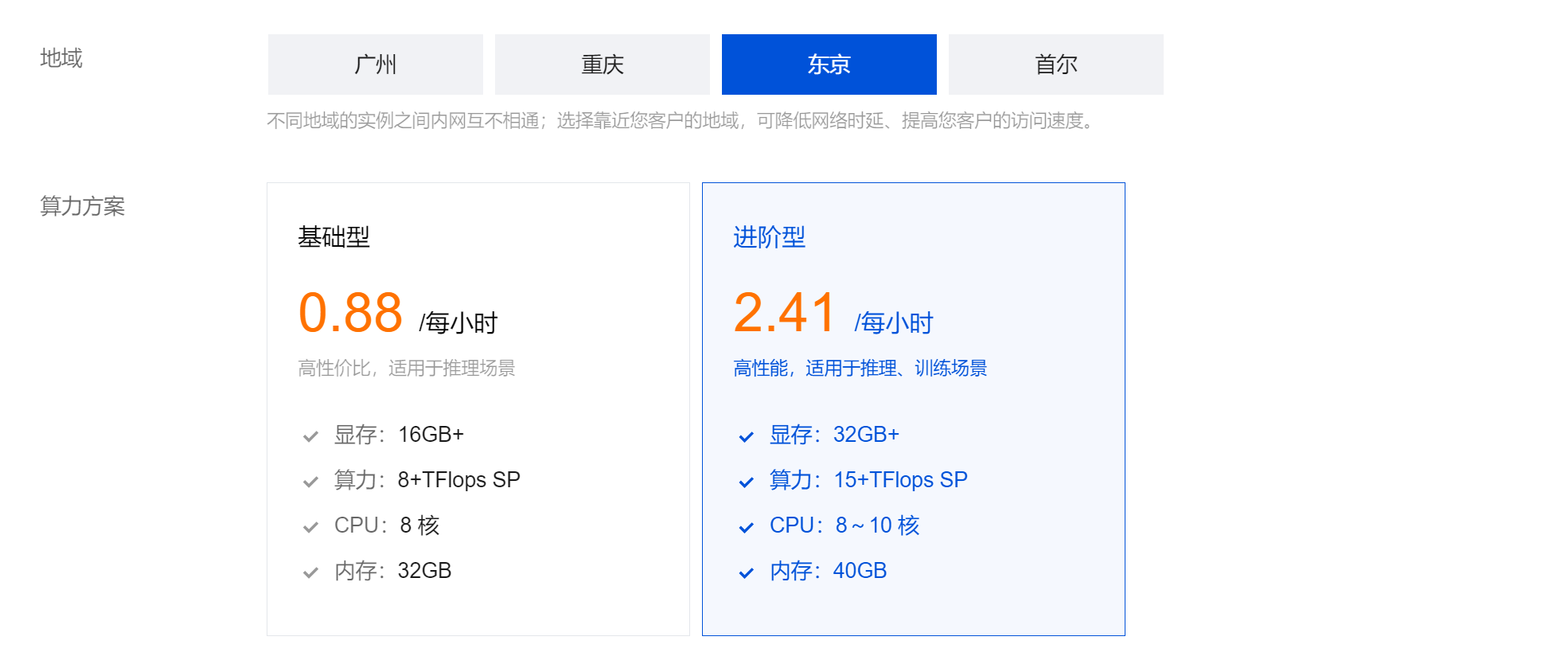
显存32G是我们普通电脑很难达到的水平,腾讯云的HAI在最近的官方推广中应该很多小伙伴们都使用过了,特别是图像生成的【Stable Diffusion】服务,并且我们可以选择32G显存的虽然当前只有默认的模型功能,但是用起来还是能满足我们的需求的进阶型服务,就说跑【sd-webui-animatediff】拓展功能,那就十分的有意思了,由于网络下载的比较慢,本章节我们先来说一下各种采样方式对应生成内容的结果。

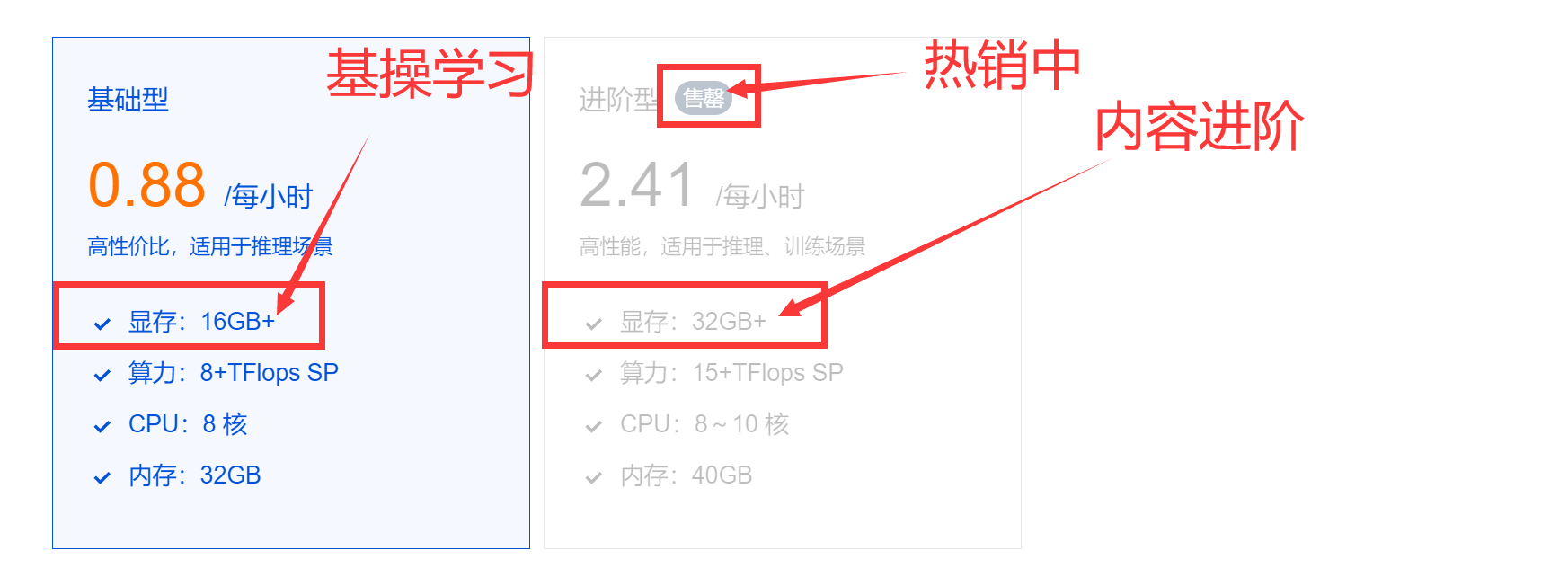 来会多刷新一下,四个地域呢,人数也多,上上下下的还是比较容易抢到手的。
来会多刷新一下,四个地域呢,人数也多,上上下下的还是比较容易抢到手的。
目标示例演示
让画动起来:
Stable Diffusion图片生成视频
好消息一手信息通知
当前只有学术加速功能,这个功能可以让我们下载插件快速一些,方便了很多,本月底还会更新暂停功能,让我们可以免去每次搭建服务的困扰,非常棒的更新。

直接进入我们的【Gradio WebUI】页面。

为方便操作,启动完毕后我们先安装一下中文插件。
中文语言包地址:【https://github.com/dtlnor/stable-diffusion-webui-localization-zh_CN】
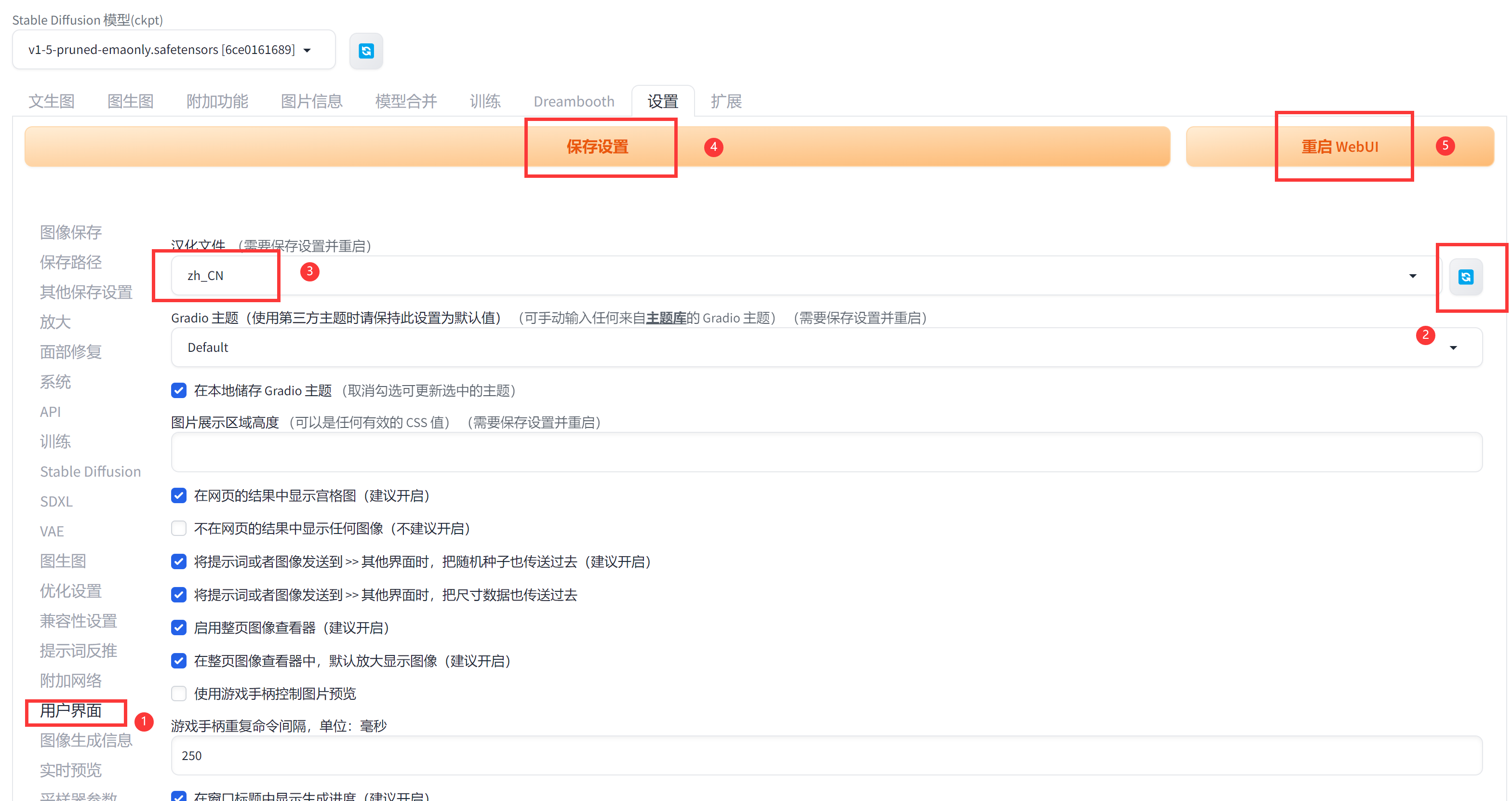
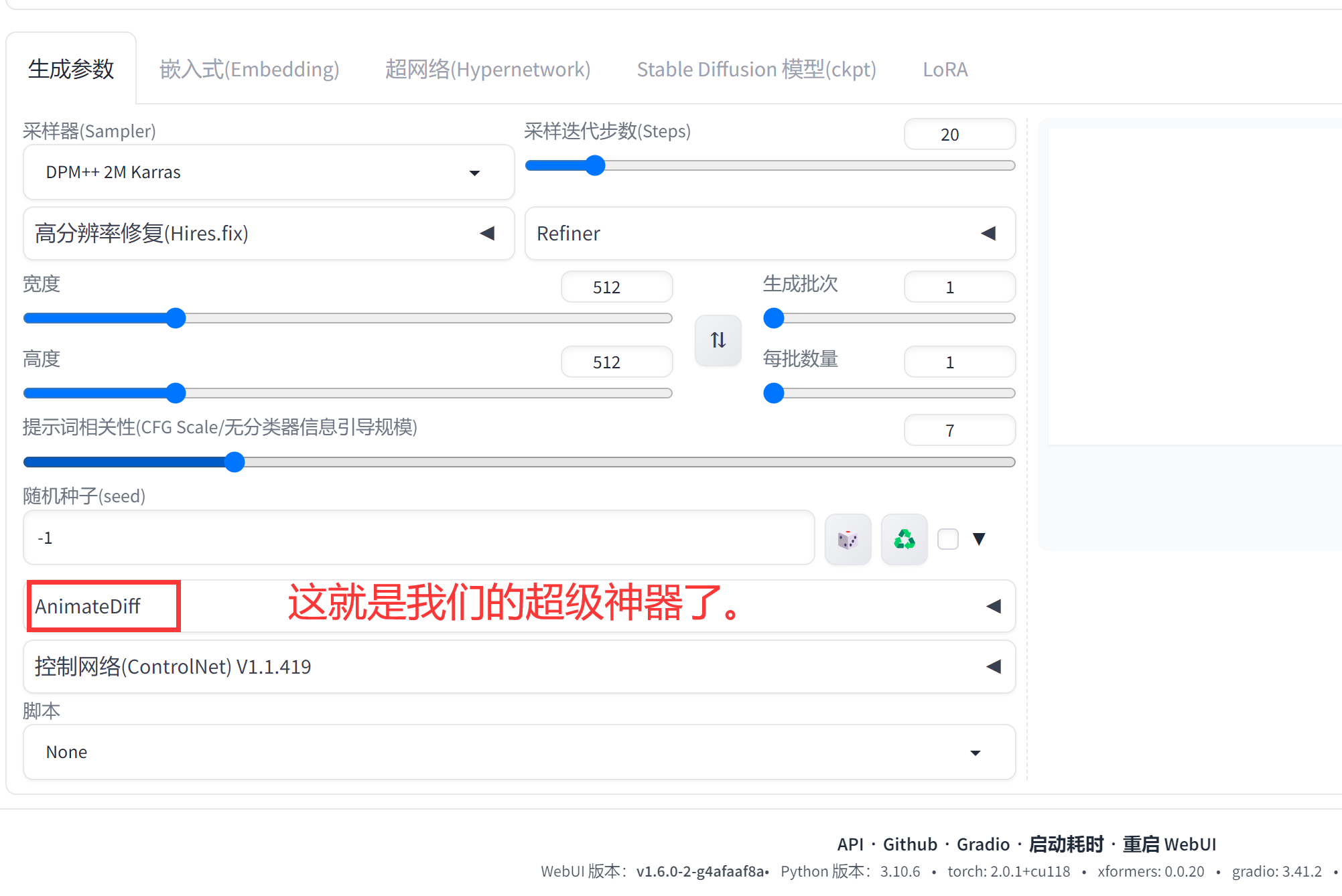
安装完毕设置以下就OK了呢,我们来直接生成一个图试试。
sd-webui-animatediff插件下载地址:
https://github.com/continue-revolution/sd-webui-animatediff下载的时候千万别着急,慢慢等。
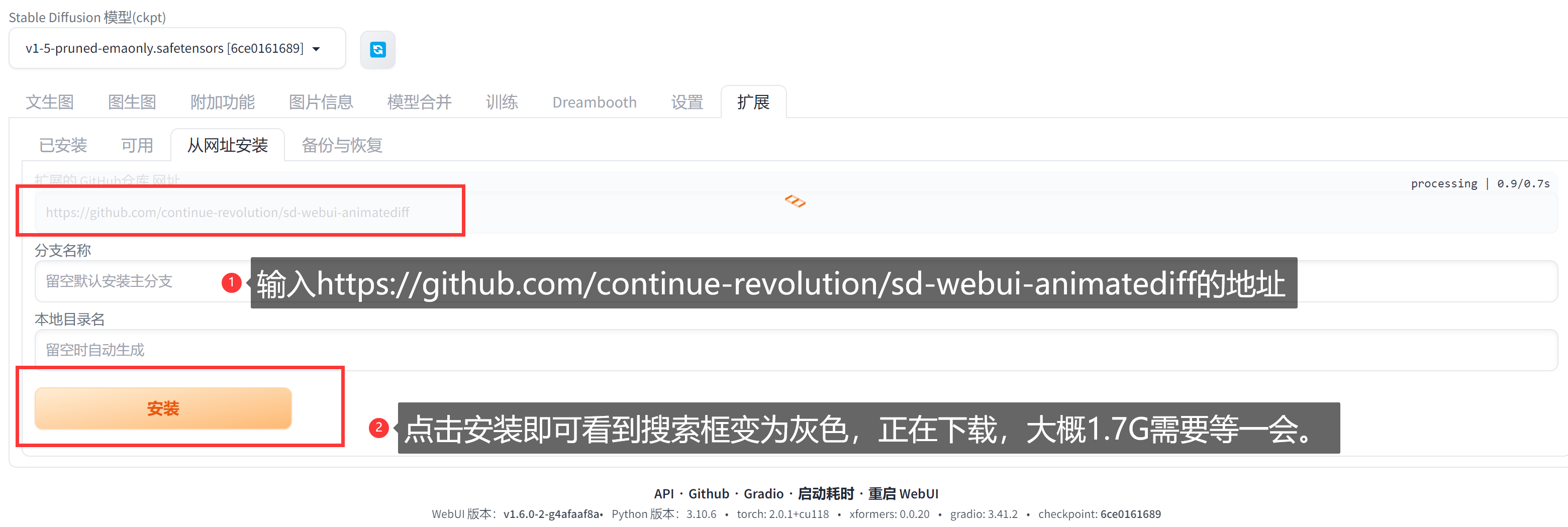
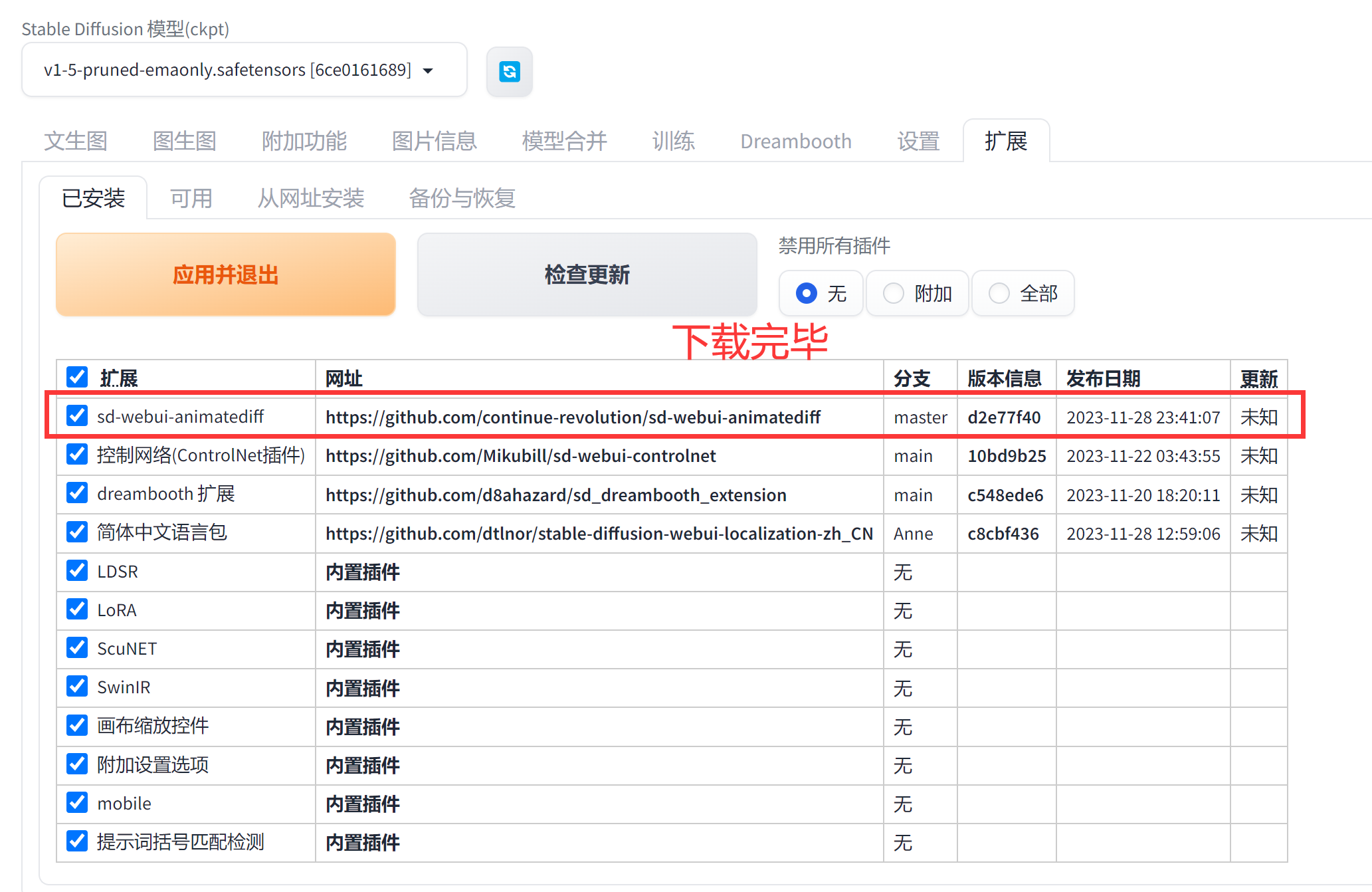
下载完毕可以在【已安装中看到】
 模型下载地址(已经没了,需要自己去网上找一下,一般都是百度云盘。): 【https://huggingface.co/guoyww/animatediff/tree/main】
模型下载地址(已经没了,需要自己去网上找一下,一般都是百度云盘。): 【https://huggingface.co/guoyww/animatediff/tree/main】
这是下载的内容【mm_sd_v15_v2.ckpt】大概1.7G,需要下载一会。 不要镜头也行,有这么一个够了。
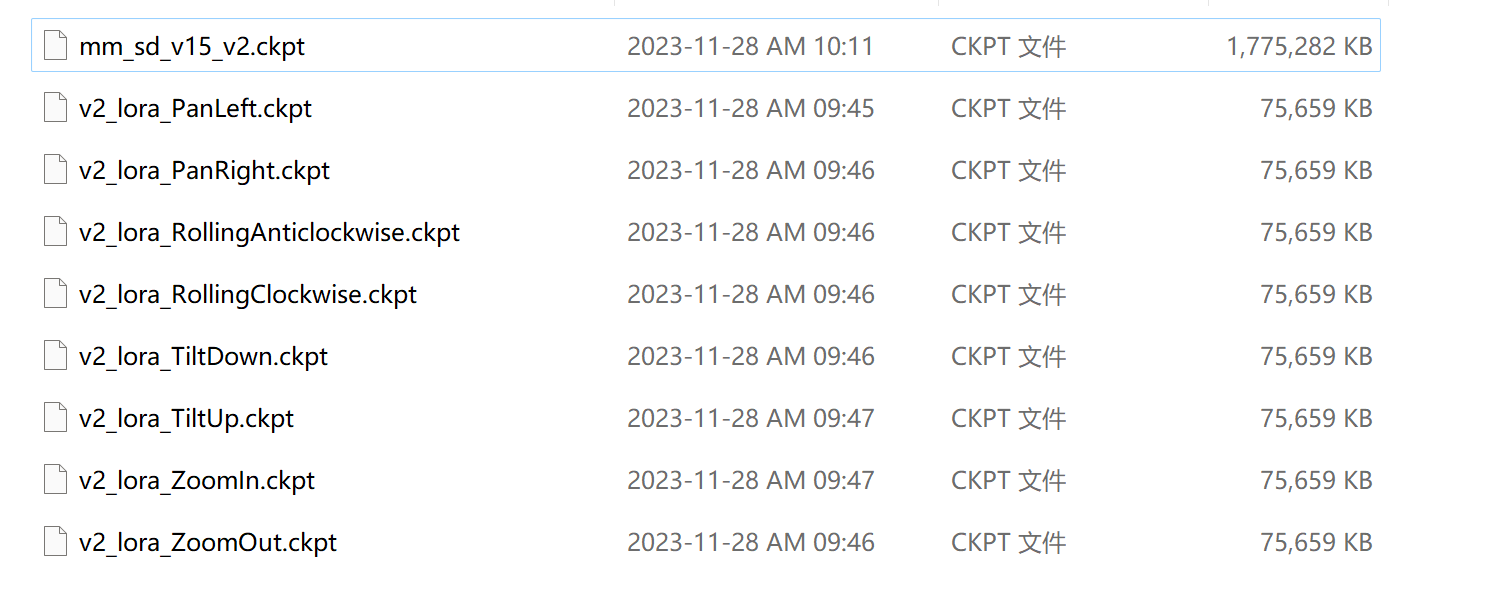
其它的是左移、右移、逆时针、顺时针、下倾斜、上倾斜、放大、缩小。
等待的时间很长,这里我来说一下采样率的不同
下载完毕——32G显存极限测试开始
下载完毕后可以在【/root/stable-diffusion-webui/extensions】下看到路径。
安装animatediff
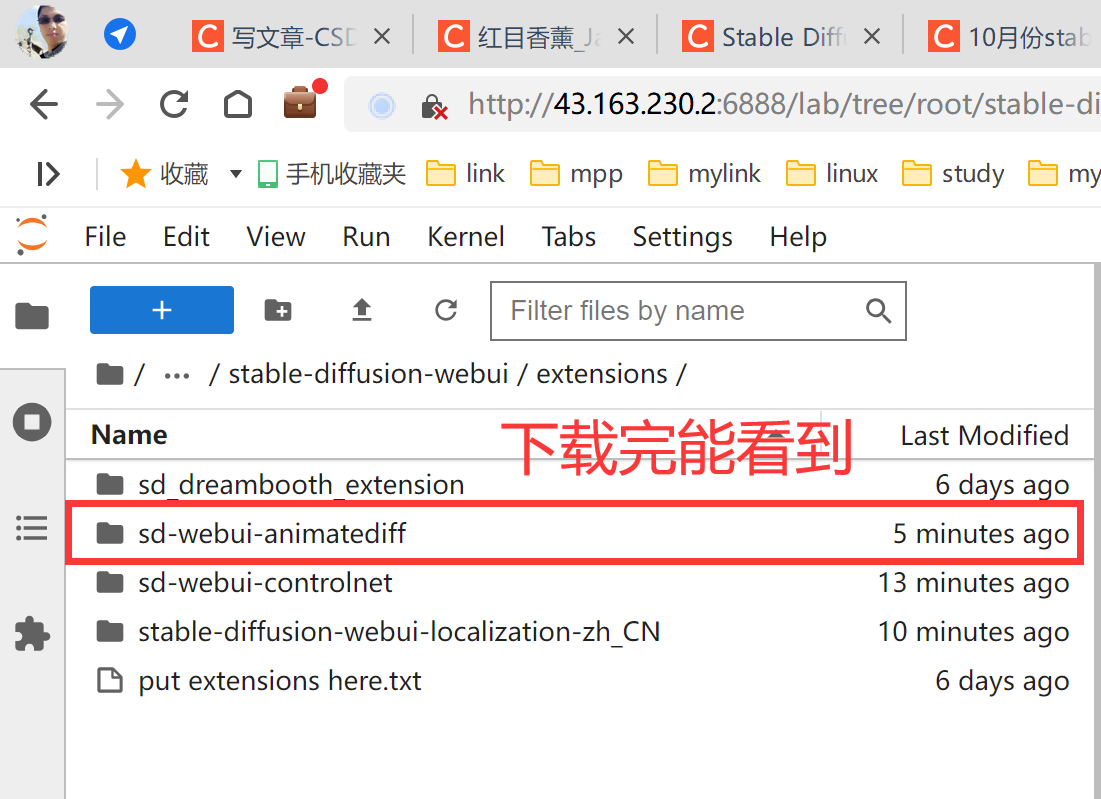
虽然在文件中能看到,但是现在WebUI还没有刷新样式,所以需要重启一下。
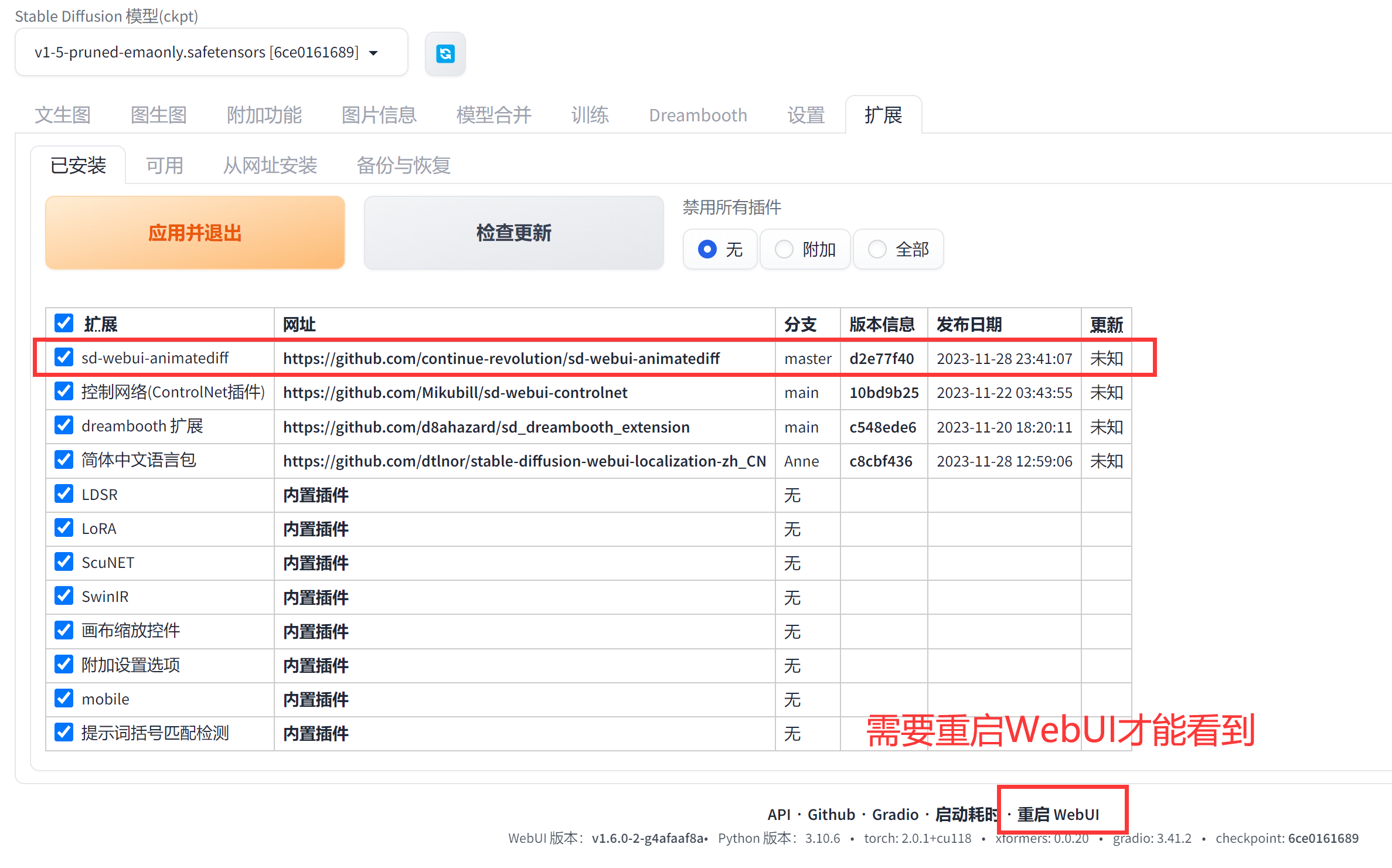
可以看到我们的神奇。
上传【mm_sd_v15_v2.ckpt】
这里我们还需要一个模型【mm_sd_v15_v2.ckpt】,这个比较大。
下载地址【https://huggingface.co/guoyww/animatediff/tree/main】 下载完毕后放置到:
【/root/stable-diffusion-webui/extensions/sd-webui-animatediff/model】文件夹下。
简单介绍:
注:如果模型没下载下来需要本地上传以下,上传的时候网络还算OK,进度可以看到。
完成后就能看到成果了。
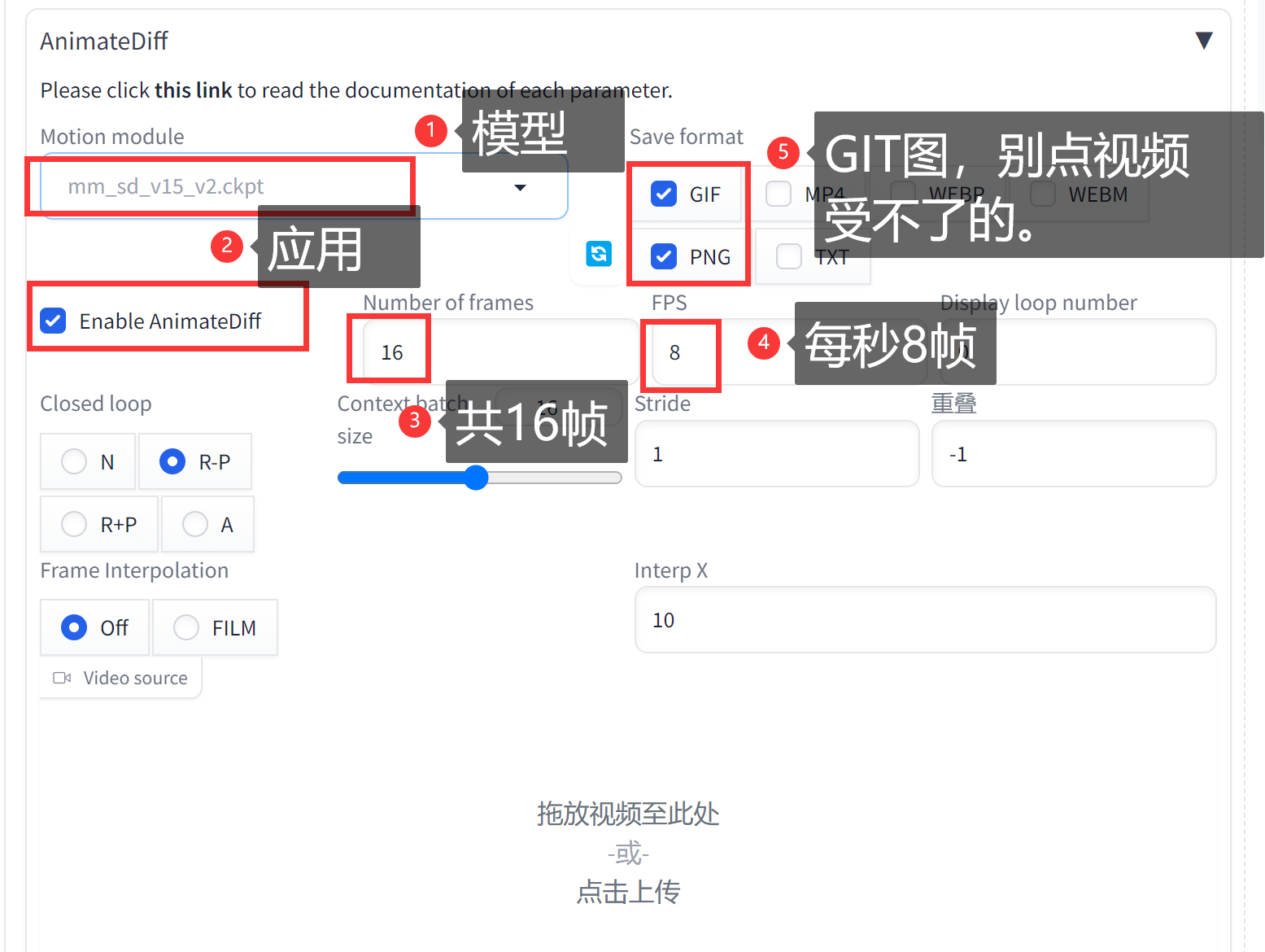
剩下的点击【开始】后等待即可,不建议生成太大的,不然得消耗N多个小时才能完成。我们可以在最上面看到生成的图像示例。
上传完毕:
重启WebUI,gif生成效果:
没有上传好模型,如果上传一些好模型会好看很多。
重新上传一个模型,好多了。
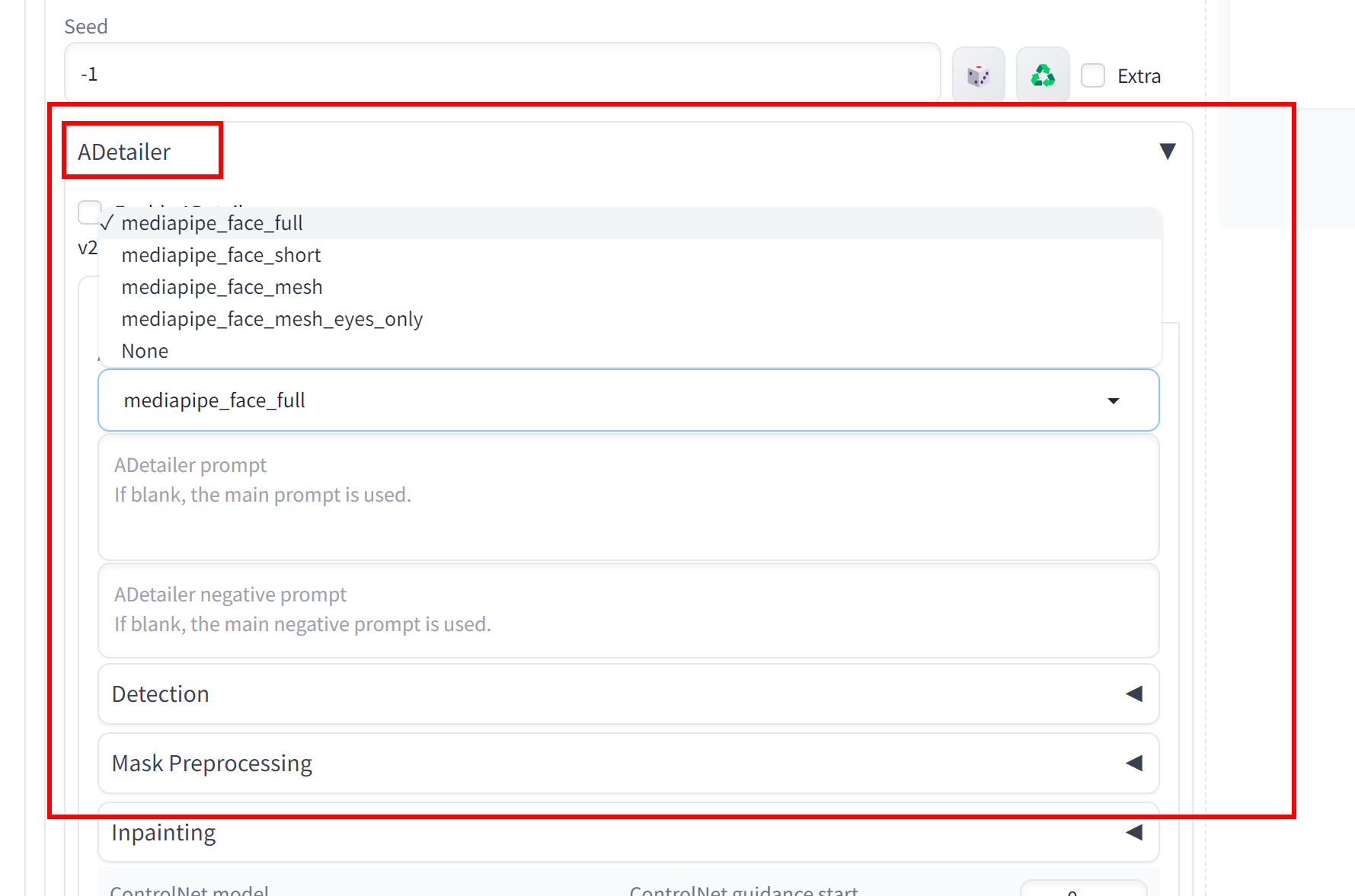
但是手好像是反的。我们需要:【Adetailer】

安装【Adetailer】
对应的参考博客:Stable Diffusion——Adetailer面部处理-CSDN博客
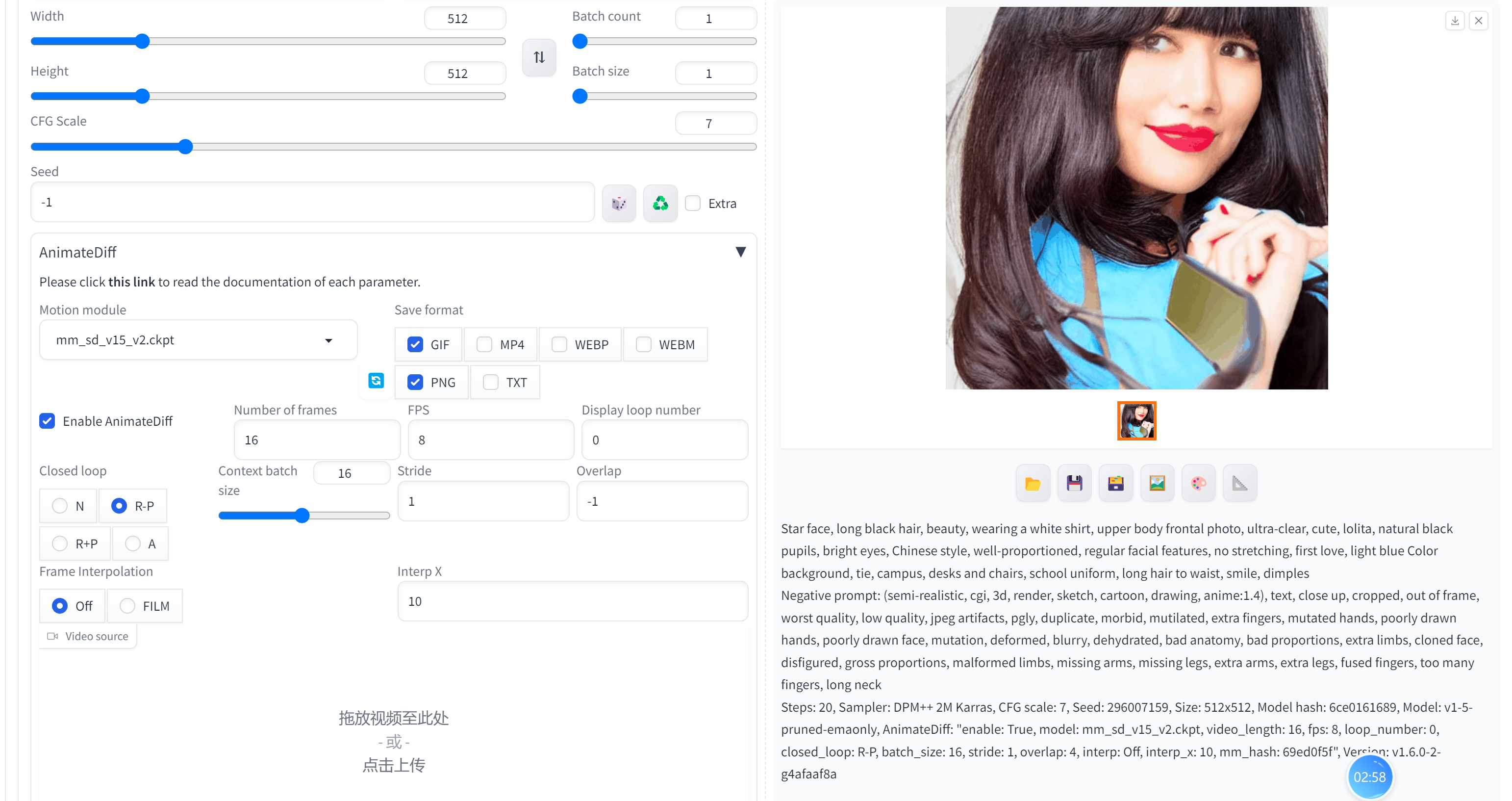
生成效果展示

全部参数:
GIF生成过程
生成过程stablediff
使用完毕需要关机哦:

采样率测试内容简述
1、测试不同采样率生成时间以及采样率作用
2、测试相同提示词在无负面提示词的情况下生成完整度
3、测试相同提示词与负面提示词的情况下各采样率生成结果
1、测试不同采样率生成时间以及采样率作用
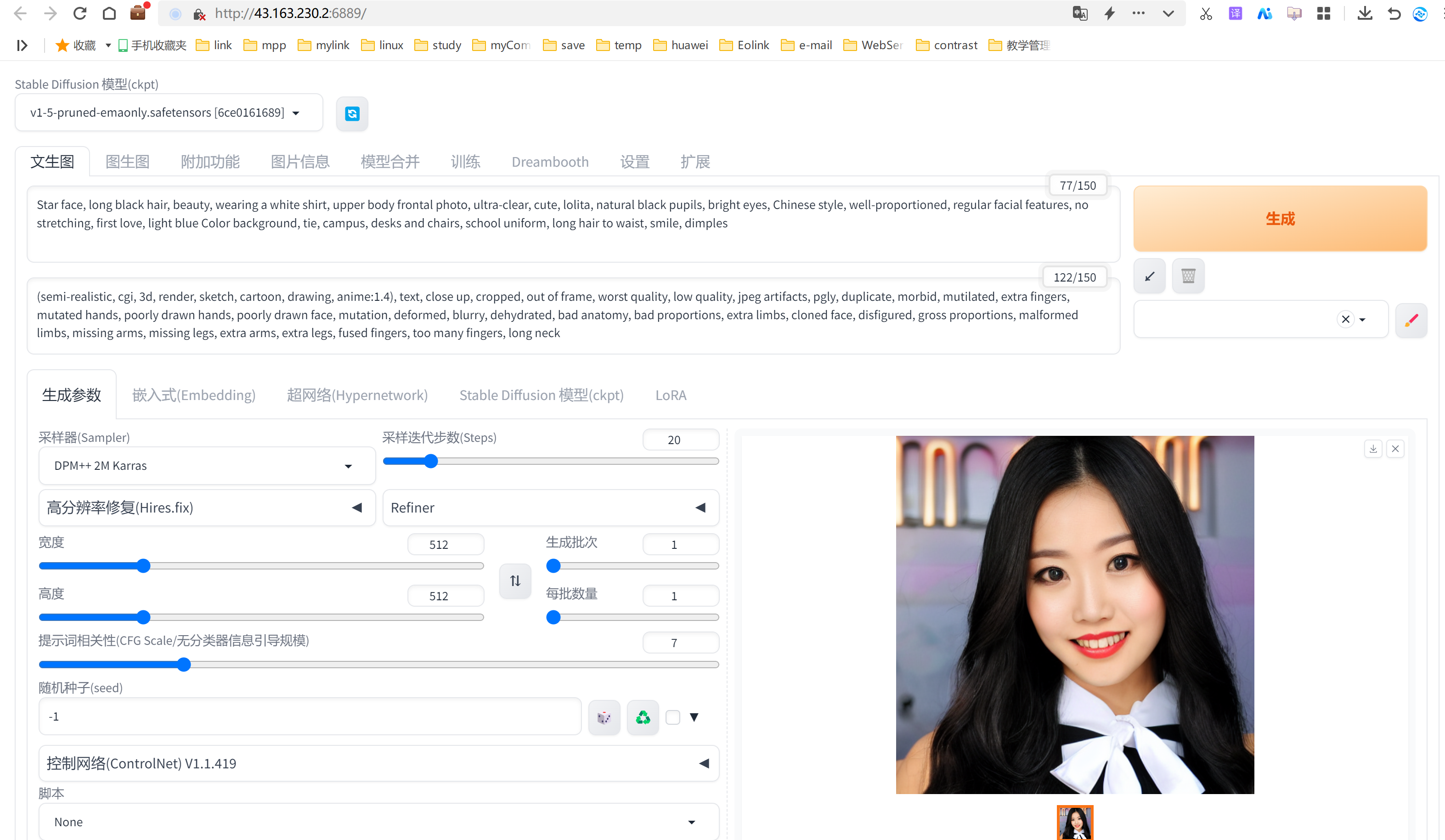
提示词:a girl
正式提示词:
Star face, long black hair, beauty, wearing a white shirt, upper body frontal photo, ultra-clear, cute, lolita, natural black pupils, bright eyes, Chinese style, well-proportioned, regular facial features, no stretching, first love, light blue Color background, tie, campus, desks and chairs, school uniform, long hair to waist, smile, dimples
反向提示词:
(semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime:1.4), text, close up, cropped, out of frame, worst quality, low quality, jpeg artifacts, pgly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck
时间单位:sec.
sec.是时间单位,即英文单词second的缩写,意为“秒”。秒是国际单位制中时间的基本单位,符号是s。有时也会借用英文缩写标示为sec.。秒主要用于计时、计算时间、计算速度等。
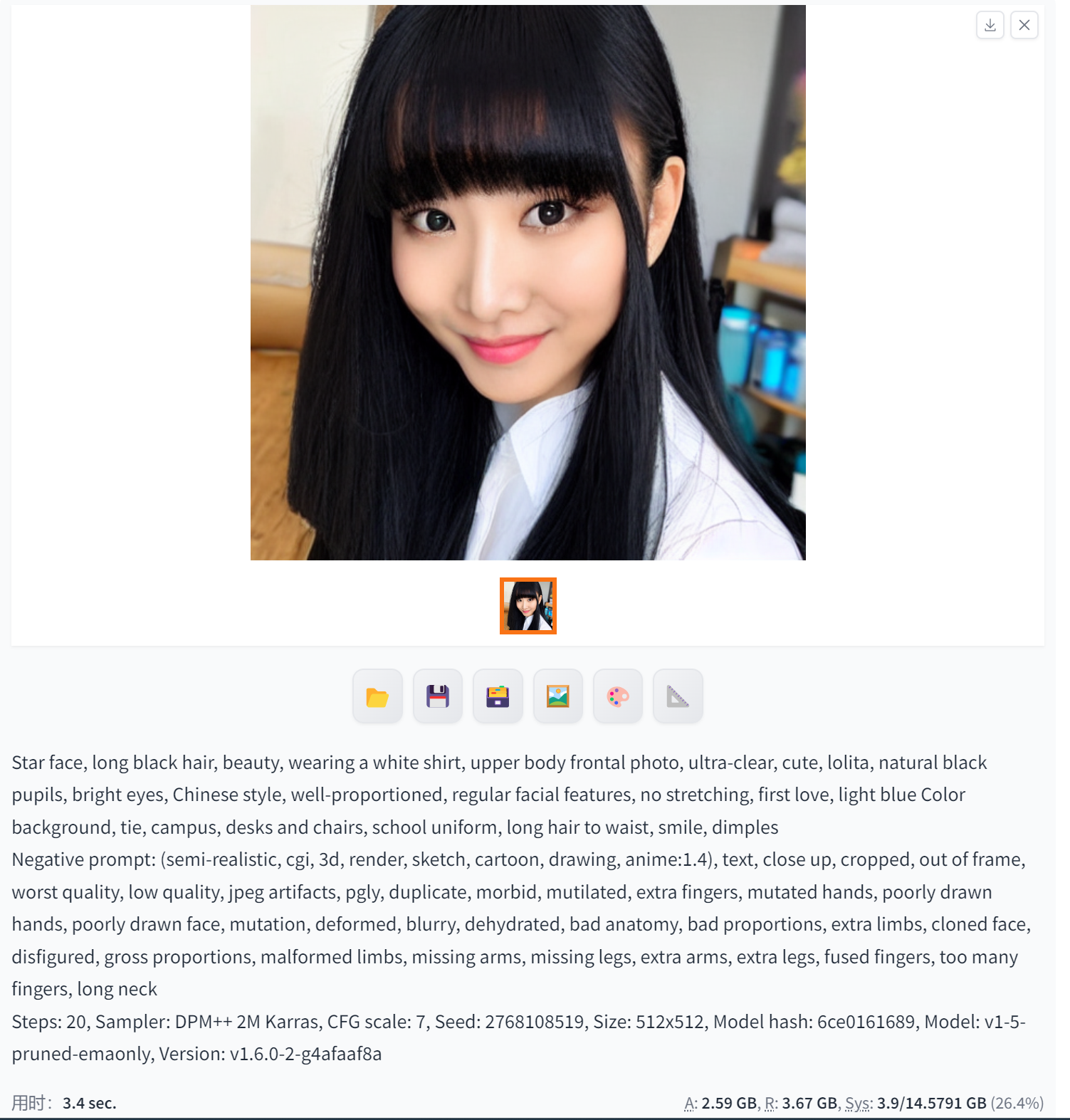
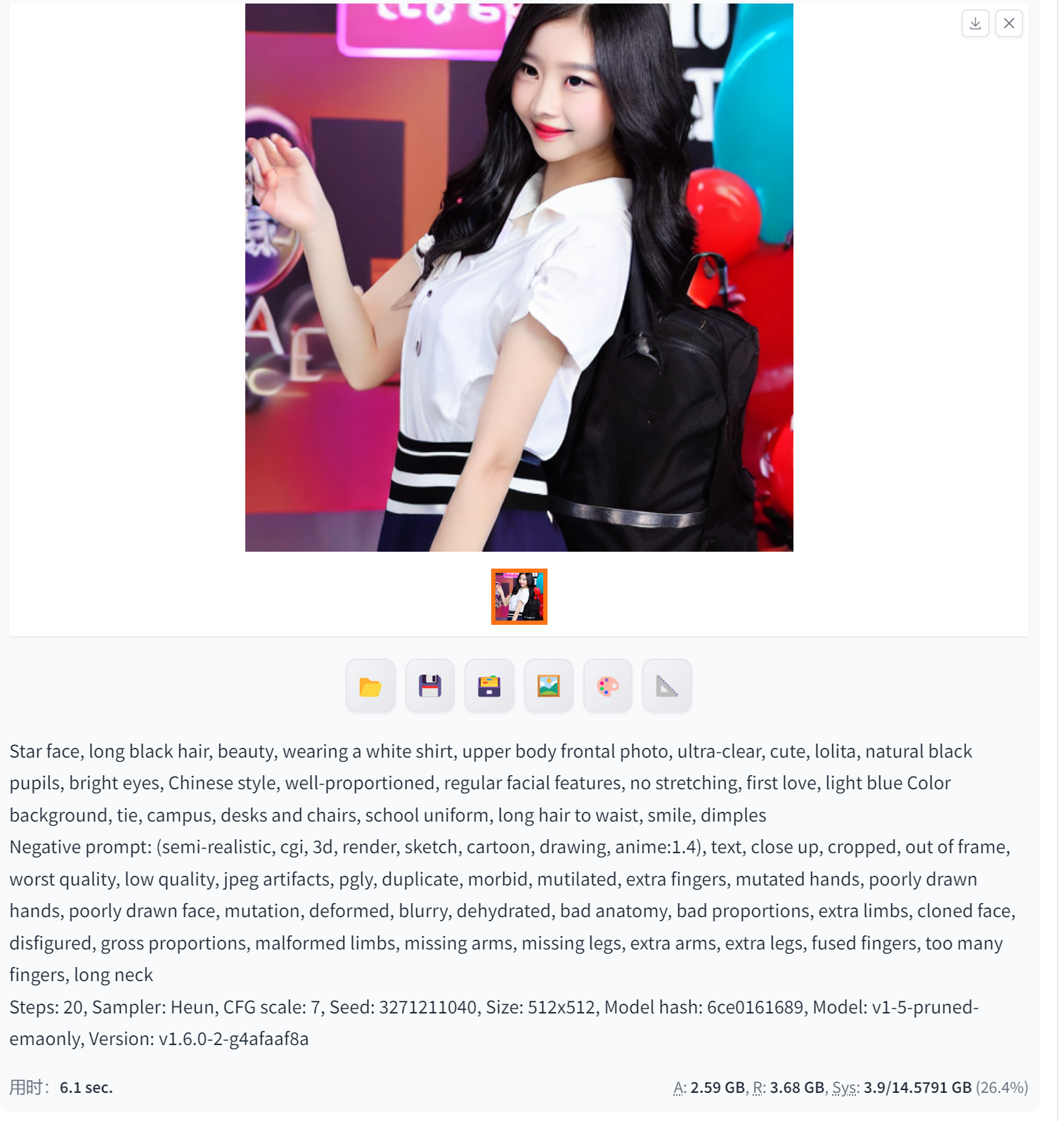
DPM++ 2M Karras(生成更精确的图像及其细节·精微人脸)
DPM++ 2M Karras是一种二阶扩展概率模型求解的算法,可以在速度与质量之间进行平衡,并生成更精确的图像及其细节。这种算法通常用于生成高质量的图像,包括二次元图像和三次元图像。
DPM++ 2M Karras在图像生成方面的应用包括但不限于生成逼真的人脸图像、自然场景图像、动物图像等。这种算法可以在较短时间内生成高质量的图像,并且可以通过增加迭代步数来逐步增加和完善图像的细节。因此,DPM++ 2M Karras在图像处理和计算机视觉等领域具有广泛的应用前景。
需要注意的是,DPM++ 2M Karras算法需要配合较高的迭代步数使用,才能达到最佳的效果。同时,该算法也需要进行参数调整和优化,以适应不同的图像生成任务和数据集。因此,在使用DPM++ 2M Karras进行图像生成时,需要有一定的专业知识和经验。
相对效果还算OK,真实图像,衣服的层叠有一些小异常,但是大体没问题。

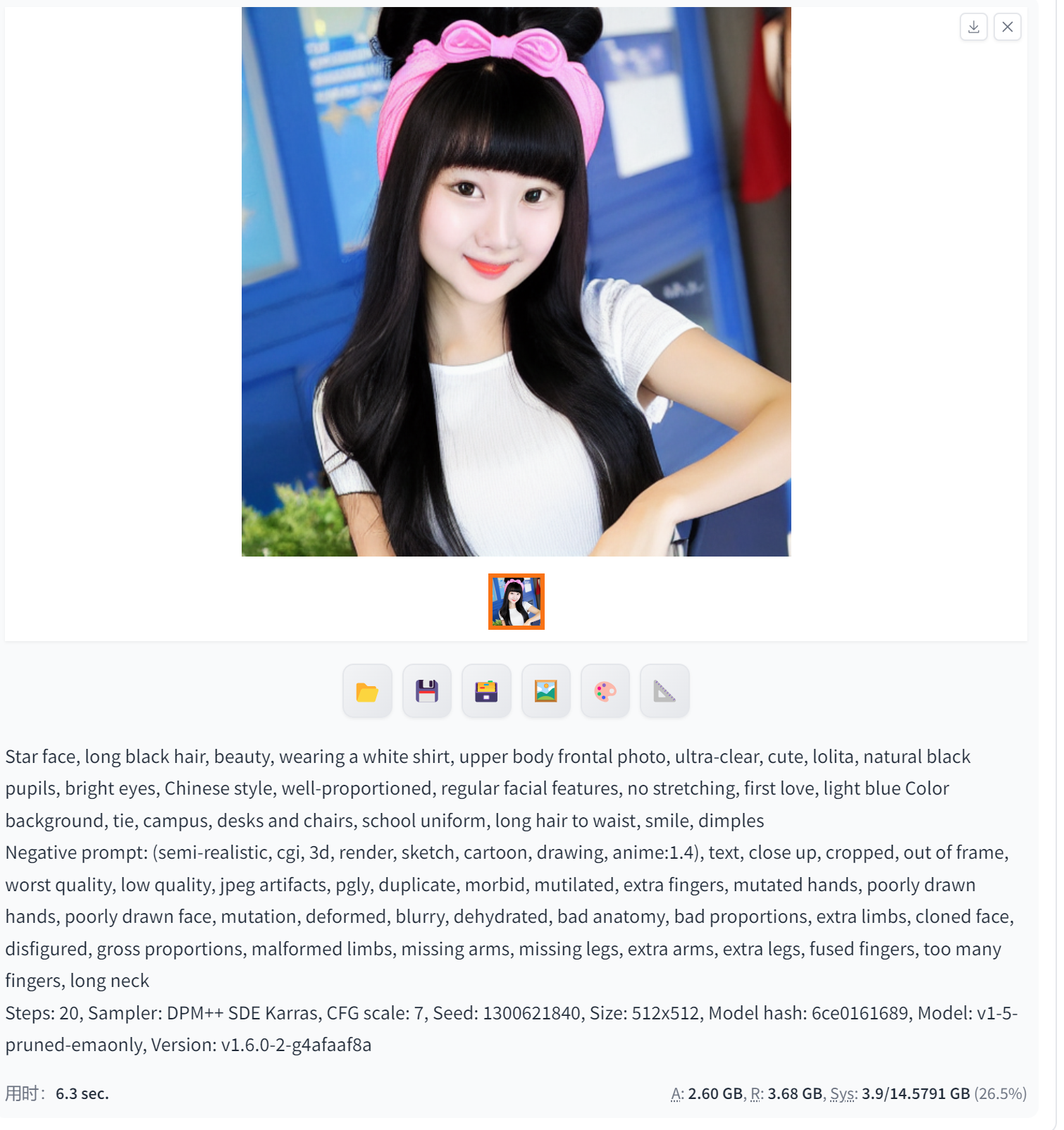
DPM++ SDE Karras(用于生成逼真的人脸图像·细节可以用DPM++ 2M Karras修)
DPM++ SDE Karras用于生成逼真的人脸图像。DPM++是一种高效的扩散模型采样方法,SDE Karras则是基于Karras等人提出的随机微分方程(SDE)的生成模型。这种生成模型可以用于生成高质量、高分辨率的图像,特别是在生成人脸图像方面表现出色。使用DPM++ SDE Karras方法可以生成具有高度真实感和细节的人脸图像,并且可以在较短的时间内完成生成过程。这种技术在计算机视觉、图像处理和人工智能等领域有着广泛的应用前景。
DPM++ 2M SDE Exponential(生成分子动力学模拟的轨迹图·不适合人像)
DPM++ 2M SDE Exponential 通常用于生成分子动力学模拟的轨迹图。DPM++是一个用于大规模分子动力学模拟的软件包,而2M SDE Exponential则是该软件包中用于执行双精度模拟的算法之一。该算法采用指数积分器(Exponential Integrator)对随机微分方程(Stochastic Differential Equation,SDE)进行数值求解,以模拟分子系统的动态行为。通过模拟分子在不同时间和条件下的运动轨迹,可以研究分子的结构、性质和反应机制,从而深入了解化学、生物学和材料科学等领域的基本问题。生成的轨迹图可以提供直观的分子运动可视化,有助于分析和解释模拟结果。

DPM++ 2M SDE Karras(生成逼真的人脸图像)
DPM++ 2M SDE Karras用于生成高质量、高分辨率的图像,尤其擅长生成逼真的人脸图像。这种算法结合了DPM++的高效采样和Karras等人提出的随机微分方程(SDE)生成模型,可以在较短时间内生成具有高度真实感和细节的图像。通过调整参数和增加迭代步数,可以逐步完善图像的细节,使其在视觉上更加逼近真实场景或对象。在计算机视觉、图像处理和人工智能等领域,DPM++ 2M SDE Karras有着广泛的应用前景。
需要注意的是,使用DPM++ 2M SDE Karras进行图像生成时,可能需要一定的专业知识和经验,以进行适当的参数调整和优化,从而获得最佳的生成效果。
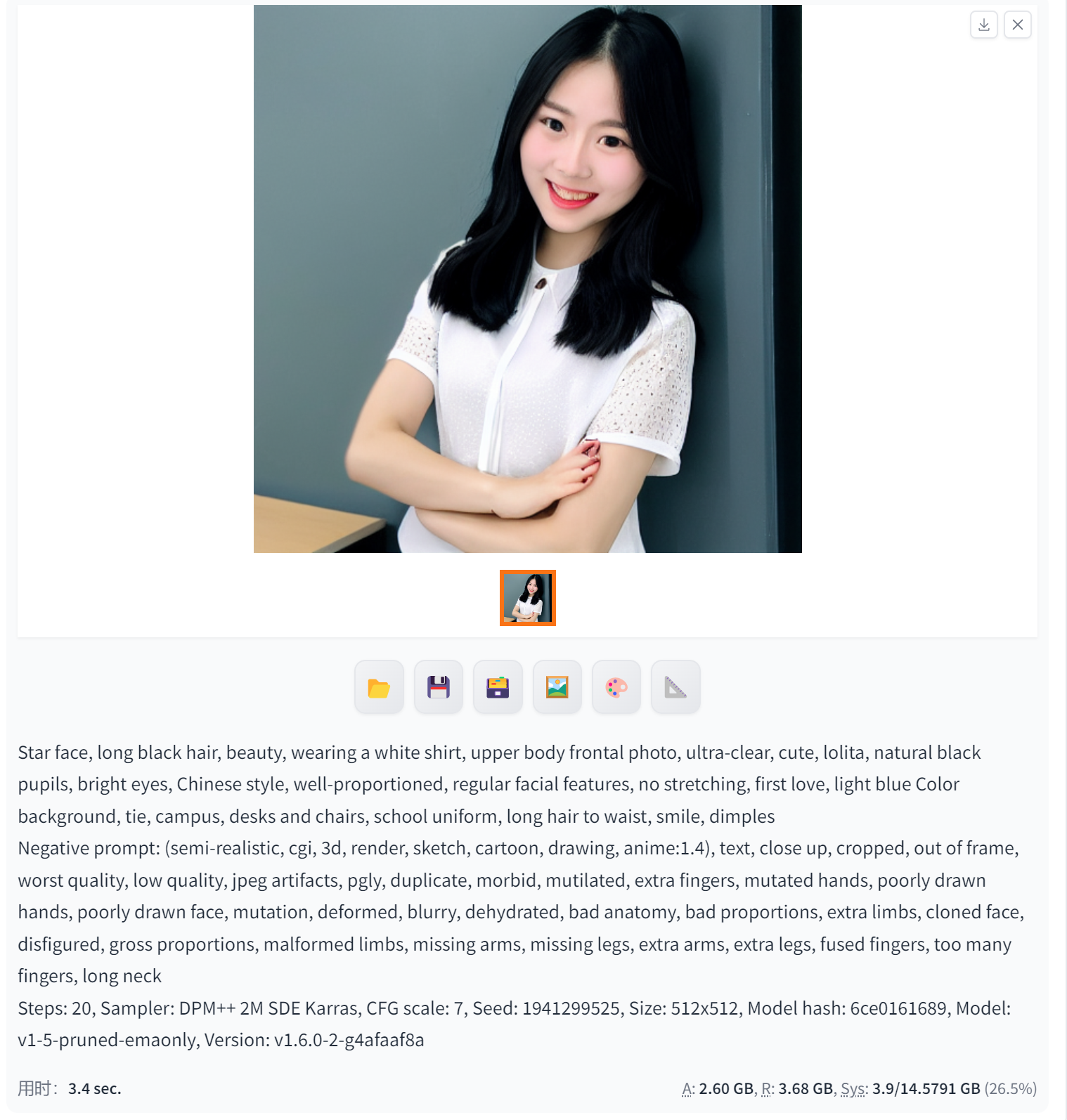
Euler a(高分辨率、逼真的图像)
Stable Diffusion中的Euler a是一种基于欧拉方法的扩散模型,可以用于生成图像。具体来说,Euler a可以用于生成高分辨率、逼真的图像,通过对噪声图像应用扩散步骤和反向扩散步骤来不断降噪,最终生成具有高质量的图像。
此外,Euler a还可以用于对缺失部分进行修复,通过在周围像素上进行扩散过程来填补缺失的部分,提高图像的完整性和真实性。同时,它也可以对低分辨率的图像进行超分辨率重建,通过在图像上进行多次扩散和反向扩散来获取更加精细的图像特征,从而获得更高分辨率的图像。
总之,Stable Diffusion中的Euler a主要用于生成高质量、高分辨率的图像,并可以对图像进行修复和超分辨率重建。
需要注意的是,使用Euler a进行图像生成可能需要一定的专业知识和经验,以进行适当的参数调整和优化,从而获得最佳的生成效果。
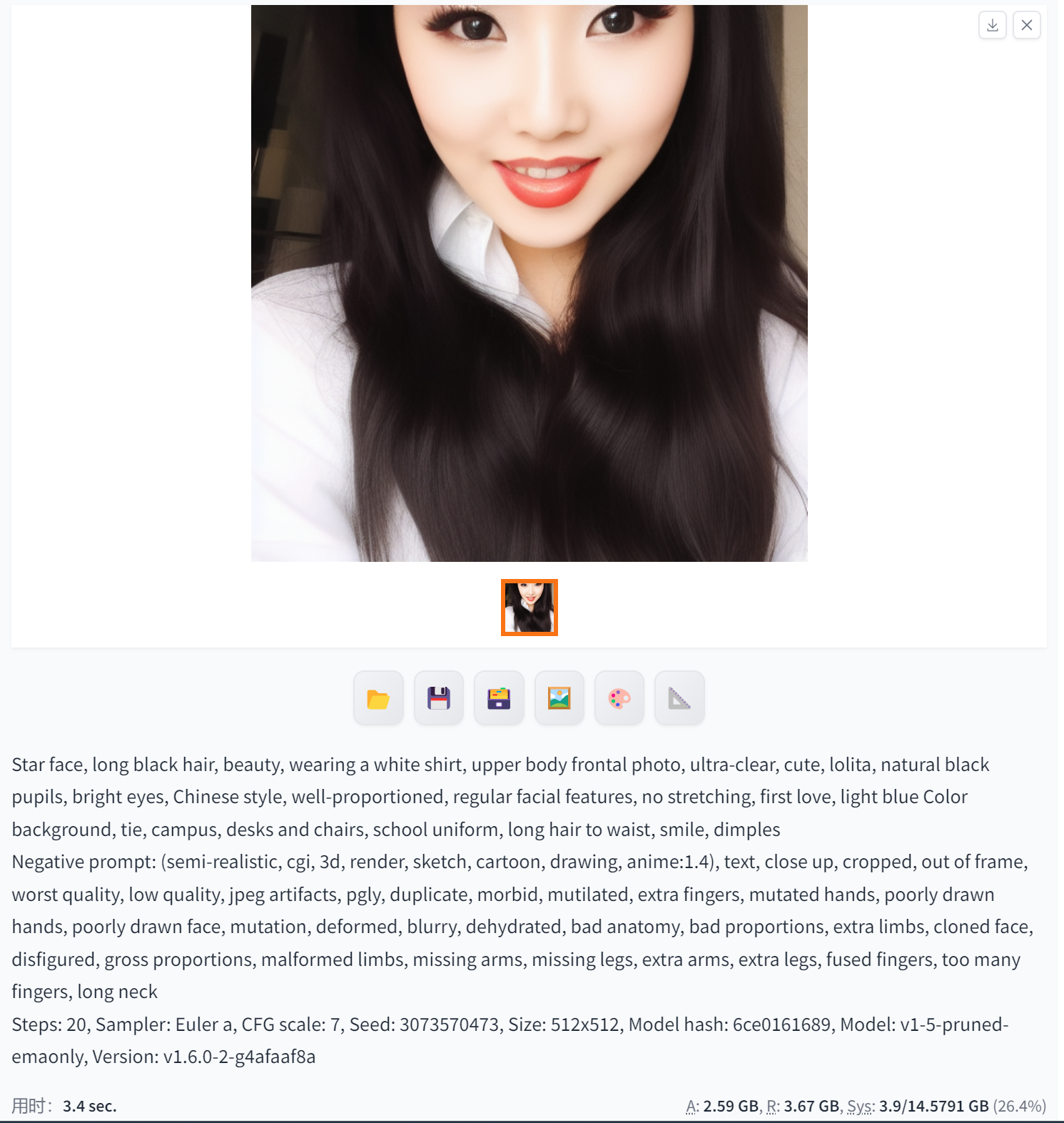
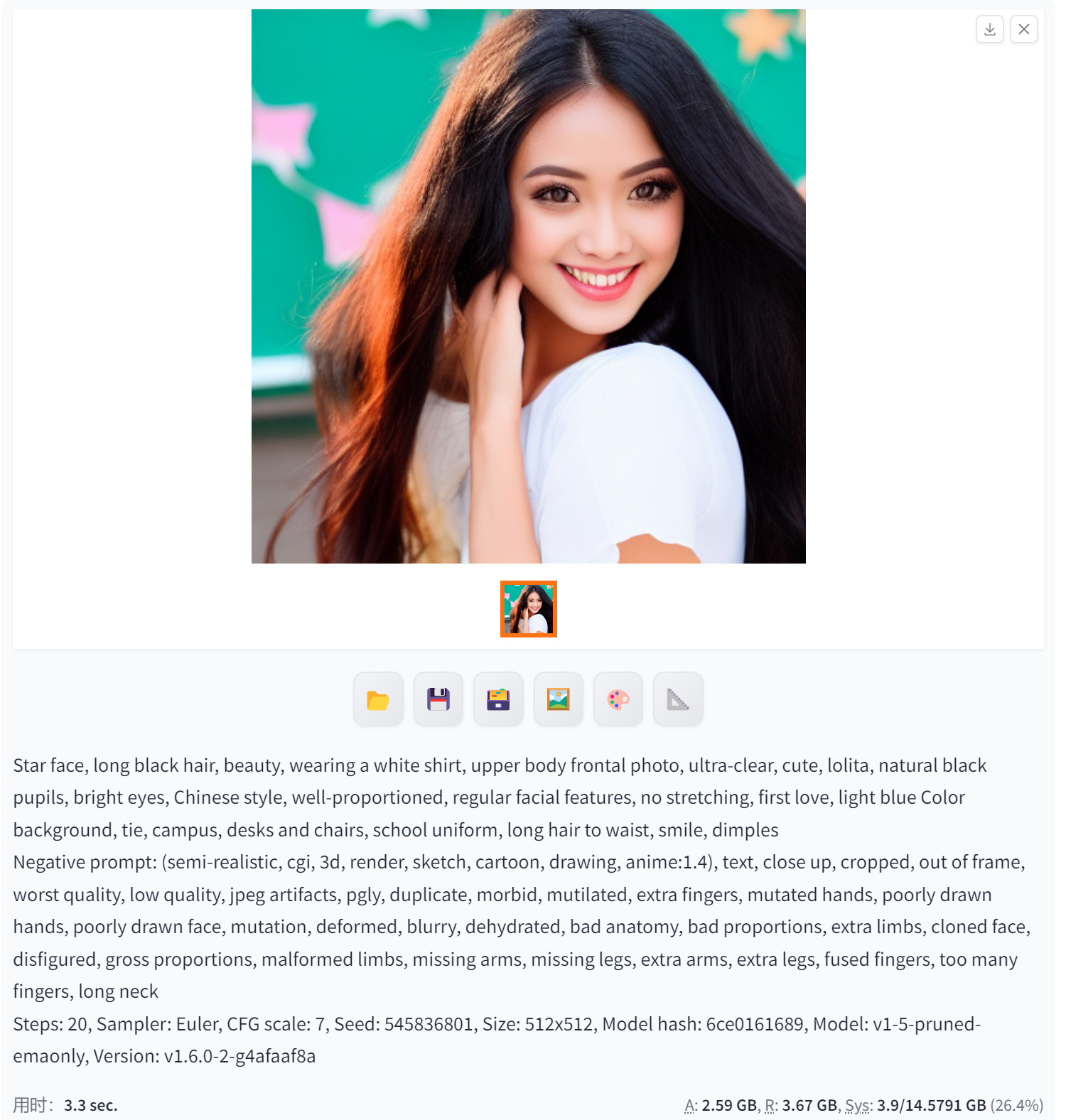
Euler(高质量的图像)
Stable Diffusion中的Euler方法主要用于生成高质量的图像。具体而言,它是一种基于扩散模型的算法,通过在图像上应用扩散步骤和反向扩散步骤来逐步降噪和生成图像。这种方法可以用于生成逼真的人脸图像、自然场景图像以及其他类型的图像。
Euler方法在Stable Diffusion中起到了关键作用,它可以帮助算法更加稳定和高效地生成图像。通过调整Euler方法的参数,可以控制生成图像的质量和分辨率,从而获得更好的生成效果。
需要注意的是,使用Stable Diffusion中的Euler方法进行图像生成可能需要一定的专业知识和经验,以进行适当的参数调整和优化。同时,该算法也需要强大的计算资源来支持其运行,例如需要使用GPU来加速计算过程。
总之,Stable Diffusion中的Euler方法主要用于生成高质量的图像,并可以通过调整参数和优化来获得更好的生成效果。
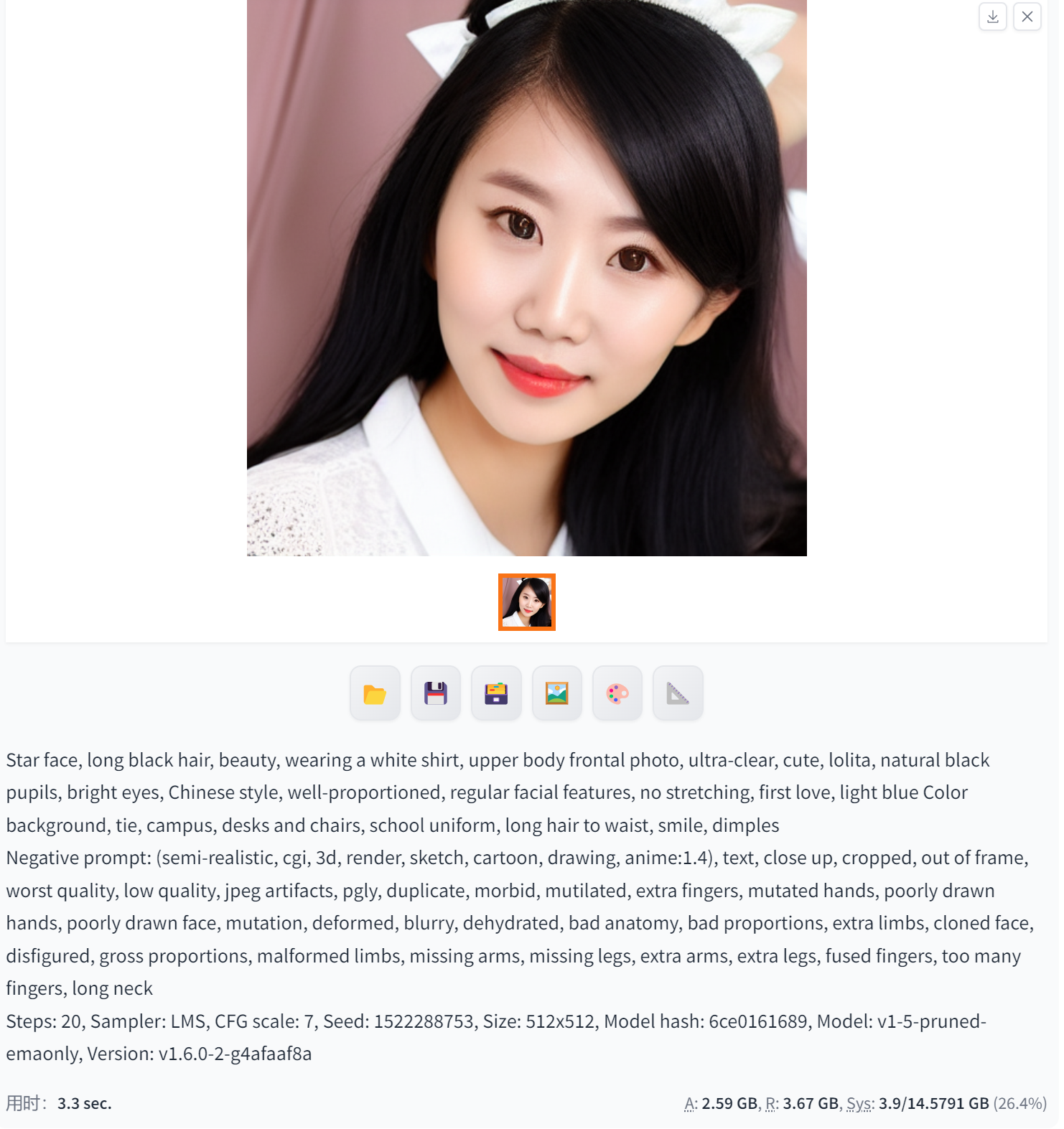
LMS(图像去噪和重建)
Stable Diffusion中的LMS(Least Mean Squares)算法主要用于图像去噪和重建,可以用于生成高质量的图像。具体而言,LMS算法是一种自适应滤波器,可以通过最小化均方误差来估计和去除图像中的噪声,从而提高图像的质量和清晰度。
在Stable Diffusion中,LMS算法可以被应用于对扩散过程中的噪声进行去除,从而生成更加逼真的图像。此外,LMS算法也可以与其他图像处理技术相结合,例如超分辨率重建和图像修复等,以进一步提高生成图像的质量和完整性。
需要注意的是,使用Stable Diffusion中的LMS算法进行图像生成和处理可能需要一定的专业知识和经验,以进行适当的参数调整和优化。同时,该算法也需要适当的计算资源来支持其运行,例如需要使用GPU或其他高性能计算设备来加速计算过程。
总之,Stable Diffusion中的LMS算法可以用于图像去噪、重建和高质量图像生成,并可以通过与其他图像处理技术的结合来进一步提高生成图像的质量和完整性。
Heun(生成高质量的图像)
Stable Diffusion中的Heun方法是一种用于解决微分方程组的数值方法,它在Stable Diffusion中被应用来生成高质量的图像。具体而言,Heun方法可以用于对扩散过程进行更加精确的模拟和计算,从而生成更加逼真的图像。
与Euler方法相比,Heun方法使用了更加复杂的计算步骤和公式,因此可以更加准确地模拟扩散过程。这使得使用Heun方法生成的图像具有更高的质量和分辨率,可以更好地展现图像的细节和纹理。
除了生成高质量的图像之外,Heun方法还可以用于图像处理和修复。通过对扩散过程中的噪声进行建模和去除,Heun方法可以帮助恢复图像中缺失的信息和细节,从而提高图像的完整性和真实性。
需要注意的是,使用Stable Diffusion中的Heun方法进行图像生成和处理可能需要一定的专业知识和经验,以进行适当的参数调整和优化。同时,该算法也需要适当的计算资源来支持其运行,例如需要使用GPU或其他高性能计算设备来加速计算过程。
总之,Stable Diffusion中的Heun方法可以用于生成高质量的图像,并可以通过与其他图像处理技术的结合来进一步提高生成图像的质量和完整性。
DPM系列说明
虽然说是逐一增强,但是强度可能产生在色彩上,色彩强了反而会出现不美的情况。
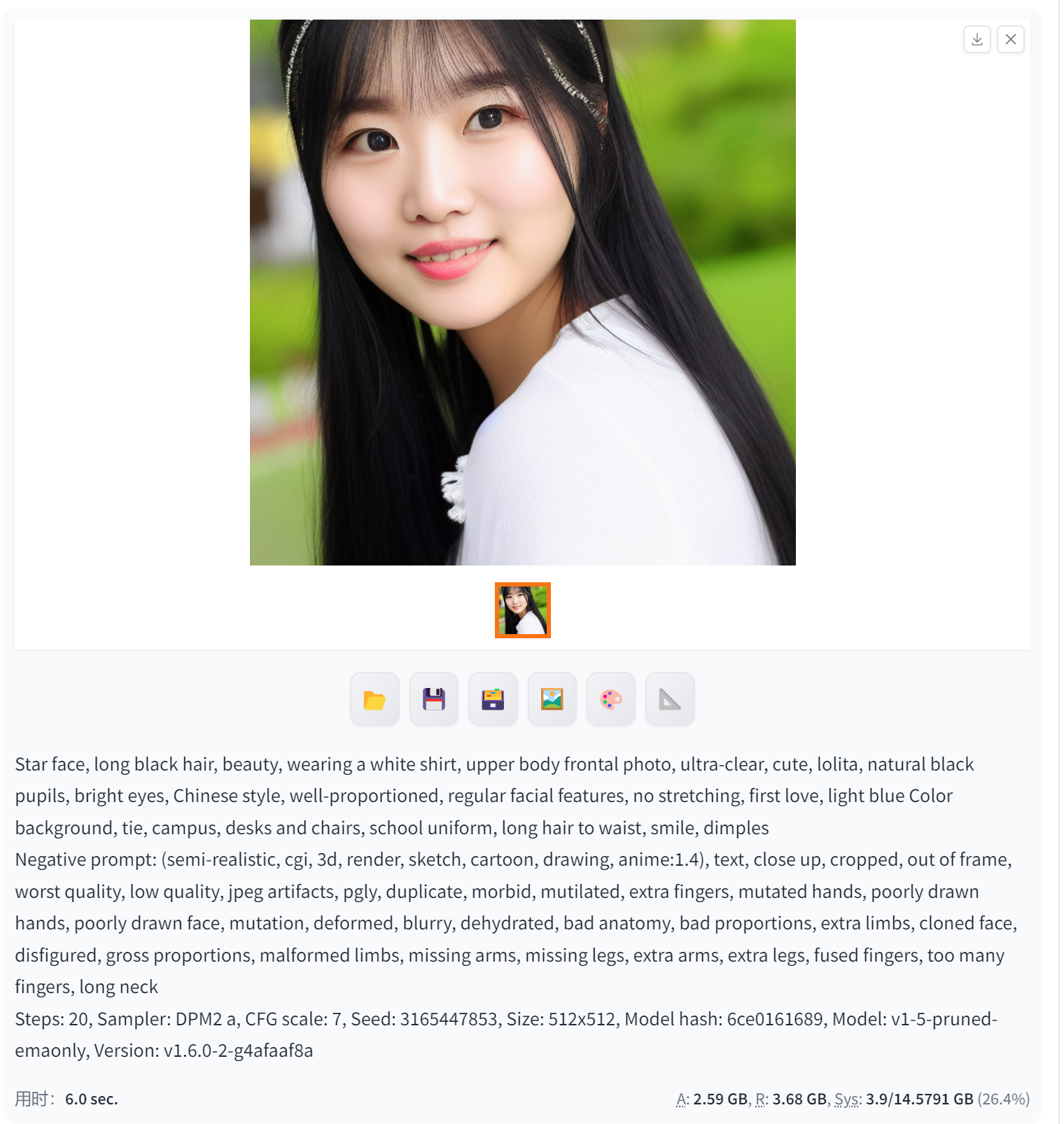
DPM2 a(生成具有特定风格和特点的图像)
DPM2 a在Stable Diffusion中可以生成具有特定风格和特点的图像。然而,具体的图像生成效果取决于多个因素,如使用的数据集、模型架构和训练方式等。因此,无法准确地预测DPM2 a可以生成哪种具体的图像。一般来说,DPM2 a可以生成具有艺术感和创意性的图像,例如抽象画、风景画、人物肖像等。
需要注意的是,DPM2 a是一种基于深度学习的图像生成模型,其生成的图像可能具有一定的随机性和不确定性。因此,在使用DPM2 a生成图像时,可能需要多次尝试和调整才能获得满意的结果。
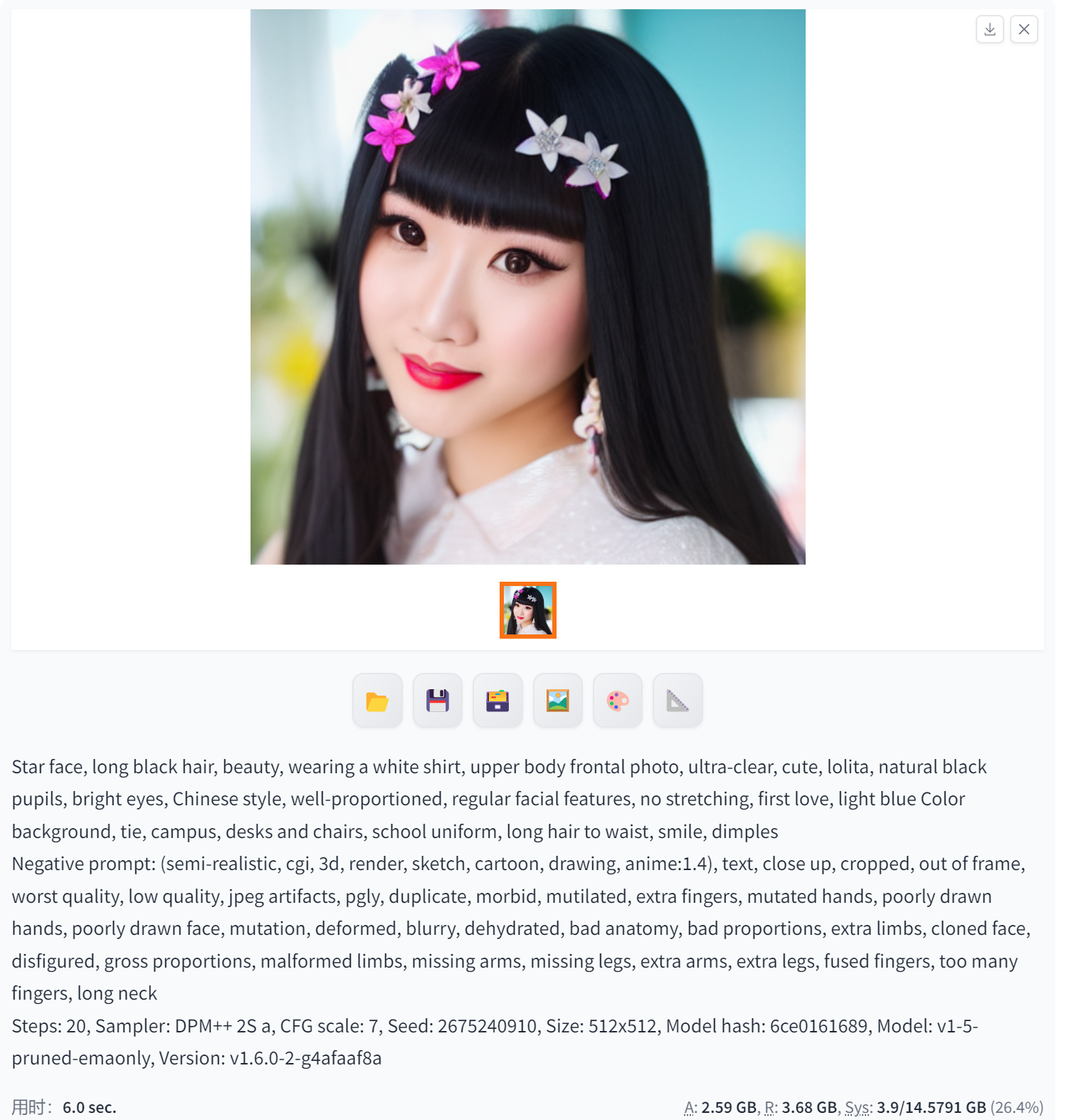
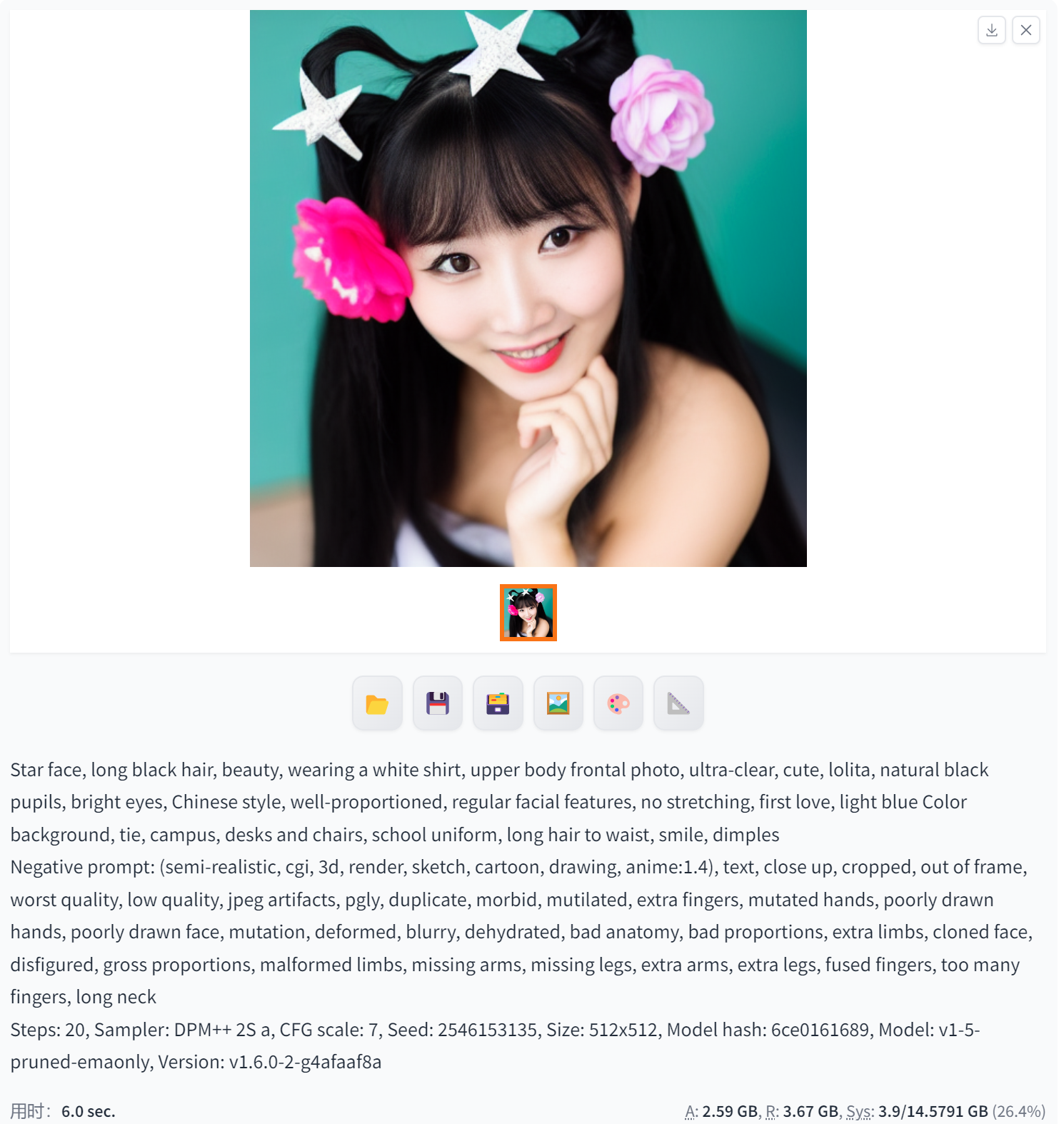
DPM++ 2S a(比DPM2 a更强的生成能力和更高的图像质量)——强度刚刚好
DPM++ 2S a是Stable Diffusion中一种更高级的图像生成模型,相比于DPM2 a,它具有更强的生成能力和更高的图像质量。使用DPM++ 2S a,用户可以生成更为逼真和具有细节的图像。
具体来说,DPM++ 2S a可以生成各种类型的图像,包括但不限于风景画、人物肖像、动物、建筑等。与DPM2 a相比,DPM++ 2S a更加注重图像的细节和真实感,可以生成更为细腻的图像。
此外,DPM++ 2S a还具有更强的可控性和灵活性。用户可以通过调整模型的参数和设置,来控制生成图像的风格、色彩、光照等方面的特点。这使得DPM++ 2S a可以应用于各种不同的场景和需求中,例如艺术创作、游戏设计、广告制作等。
需要注意的是,由于DPM++ 2S a是一种高级的图像生成模型,其训练和推理过程可能需要较高的计算资源和时间成本。因此,在使用DPM++ 2S a时,需要根据实际情况来选择合适的计算资源和训练策略。
DPM++2M(与DPM++ 2S相比,它具有更强的生成能力和更高的图像质量)
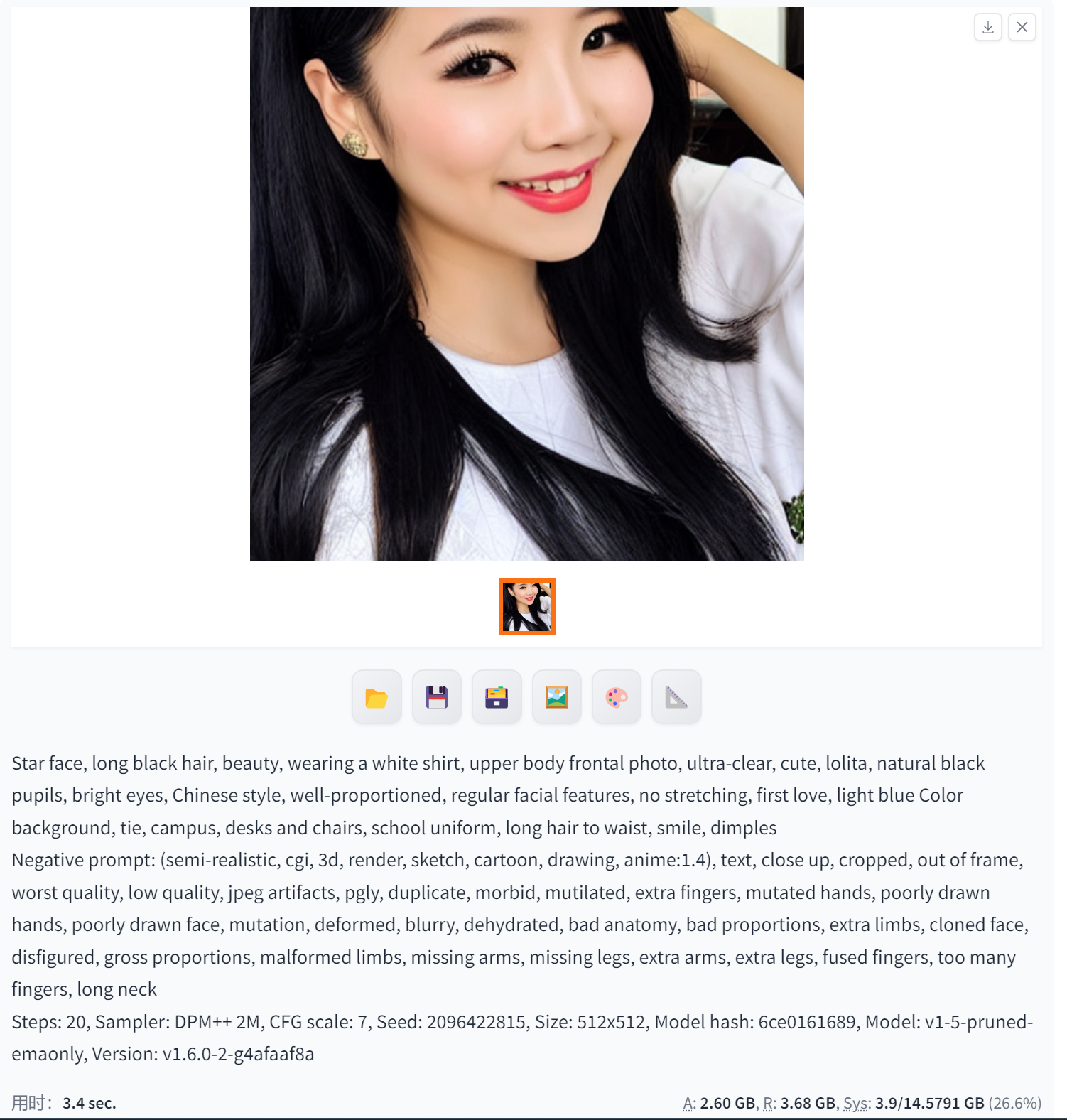
DPM++2M在Stable Diffusion中可以生成高质量的图像,与DPM++ 2S相比,它具有更强的生成能力和更高的图像质量。使用DPM++2M,用户可以生成更为逼真、具有丰富细节的图像。
具体来说,DPM++2M可以应用于各种场景和需求中,包括但不限于艺术创作、游戏设计、广告制作等。例如,在艺术创作领域,DPM++2M可以帮助艺术家生成具有独特风格和特点的图像作品,例如抽象画、油画、素描等。在游戏设计领域,DPM++2M可以生成高质量的游戏场景、角色和道具等图像资源,提升游戏的视觉效果和用户体验。在广告制作领域,DPM++2M可以帮助设计师生成具有吸引力和创意性的广告图像,吸引更多的用户关注和点击。
需要注意的是,由于DPM++2M是一种高级的图像生成模型,其训练和推理过程可能需要较高的计算资源和时间成本。因此,在使用DPM++2M时,需要根据实际情况来选择合适的计算资源和训练策略。同时,用户还需要具备一定的深度学习和图像处理知识,才能更好地利用DPM++2M生成高质量的图像。
总的来说,DPM++2M是一种功能强大的图像生成模型,可以帮助用户快速、高效地生成高质量的图像资源,应用于各种不同的领域和需求中。
DPM adaptive(DPM系列相对来说最强)
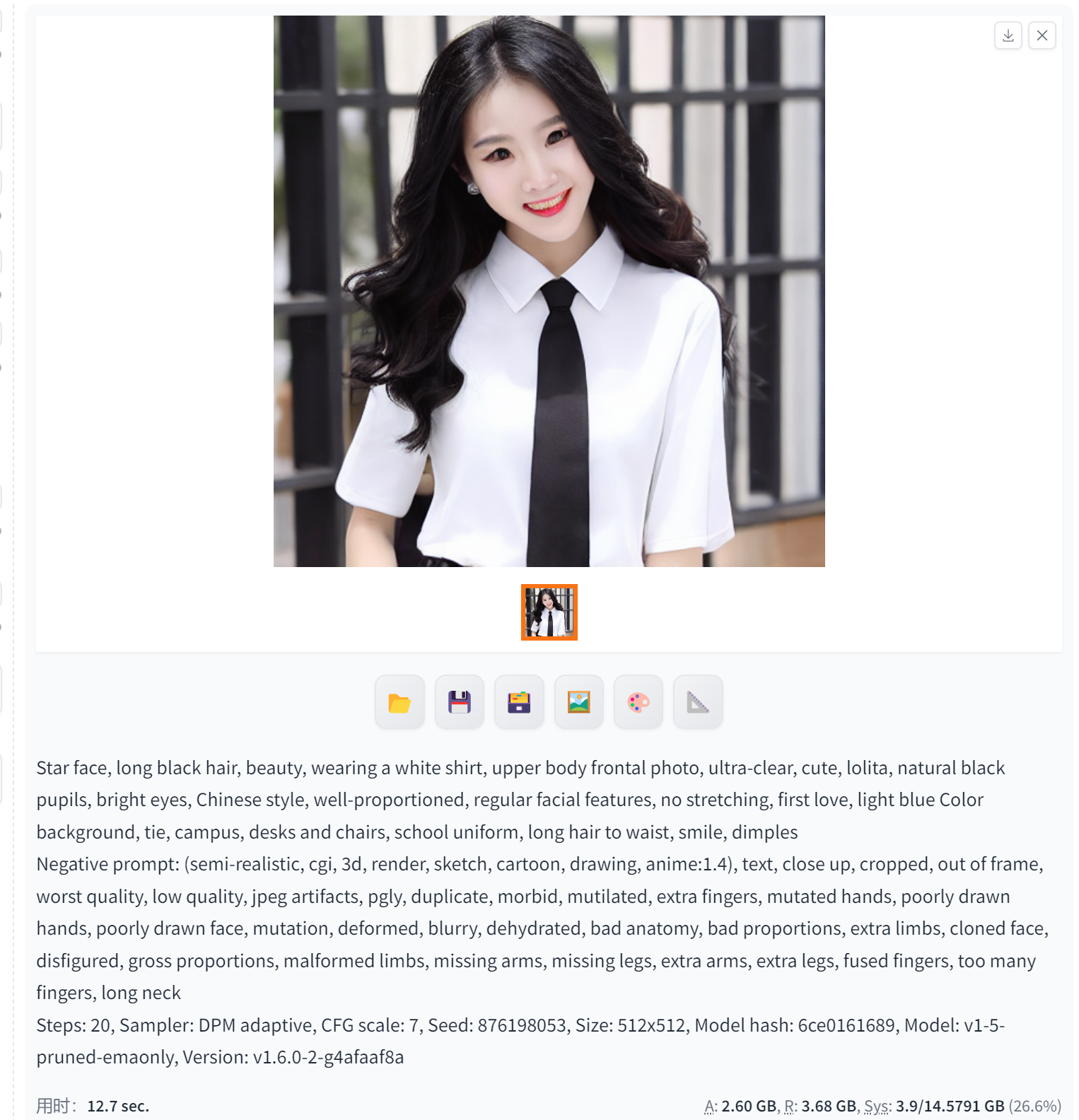
DPM Adaptive是Stable Diffusion中一种先进的图像生成模型,它具有强大的生成能力和高度的自适应性。与DPM++ SDE相比,DPM Adaptive可以生成更为逼真、具有丰富细节的图像,并且可以根据输入的不同自动调整生成图像的风格和特点。
具体来说,DPM Adaptive可以应用于各种场景和需求中,包括但不限于艺术创作、摄影后期处理、设计、影视制作等。它可以根据用户的需求自动生成高质量的图像,例如根据用户提供的草图生成逼真的场景图像,或者根据用户提供的照片生成具有高度真实感的艺术作品。
DPM Adaptive采用了先进的深度学习技术和自适应算法,可以根据输入的不同自动调整生成图像的风格、色彩、光照等方面的特点,生成具有高度自适应性的图像。这种自适应性可以使得生成的图像更加符合用户的期望和要求,提高生成的图像的质量和满意度。
此外,DPM Adaptive还具有高度的可控性和灵活性。用户可以通过调整模型的参数和设置,来控制生成图像的各种属性和特点。这使得DPM Adaptive可以应用于各种不同的场景和需求中,满足用户的不同需求和要求。
需要注意的是,由于DPM Adaptive是一种高级的图像生成模型,其训练和使用可能需要较高的计算资源和时间成本。因此,在使用DPM Adaptive时,需要根据实际情况来选择合适的计算资源和训练策略。同时,用户还需要具备一定的深度学习和图像处理知识,才能更好地利用DPM Adaptive生成高质量的图像。
UniPC(耗时最长,非人像效果相对最好)
UniPC是Stable Diffusion中一种强大的图像生成模型,具有出色的生成能力和高质量的图像输出。它可以生成各种类型的图像,包括但不限于自然风景、人物肖像、动物、建筑等。
具体来说,UniPC可以应用于以下场景和需求:
艺术创作:UniPC可以帮助艺术家生成高质量的艺术作品,例如逼真的油画、细腻的素描等。
设计:UniPC可以生成各种具有创意和实用性的设计图像,例如产品渲染图、海报、宣传片等。
影视制作:UniPC可以生成高质量的特效图像和场景,提高影视作品的视觉效果。
游戏开发:UniPC可以生成逼真的游戏场景、角色和道具等图像资源,为游戏开发提供有力的支持。
UniPC采用了先进的深度学习技术和图像生成算法,可以根据用户的输入和要求,自动地生成高质量的图像。同时,它还具有高度的可控性和灵活性,用户可以通过调整模型的参数和设置,来控制生成图像的风格、色彩、光照等方面的特点。
总的来说,UniPC是一种功能强大的图像生成模型,可以帮助用户快速、高效地生成高质量的图像资源,应用于各种不同的领域和需求中。
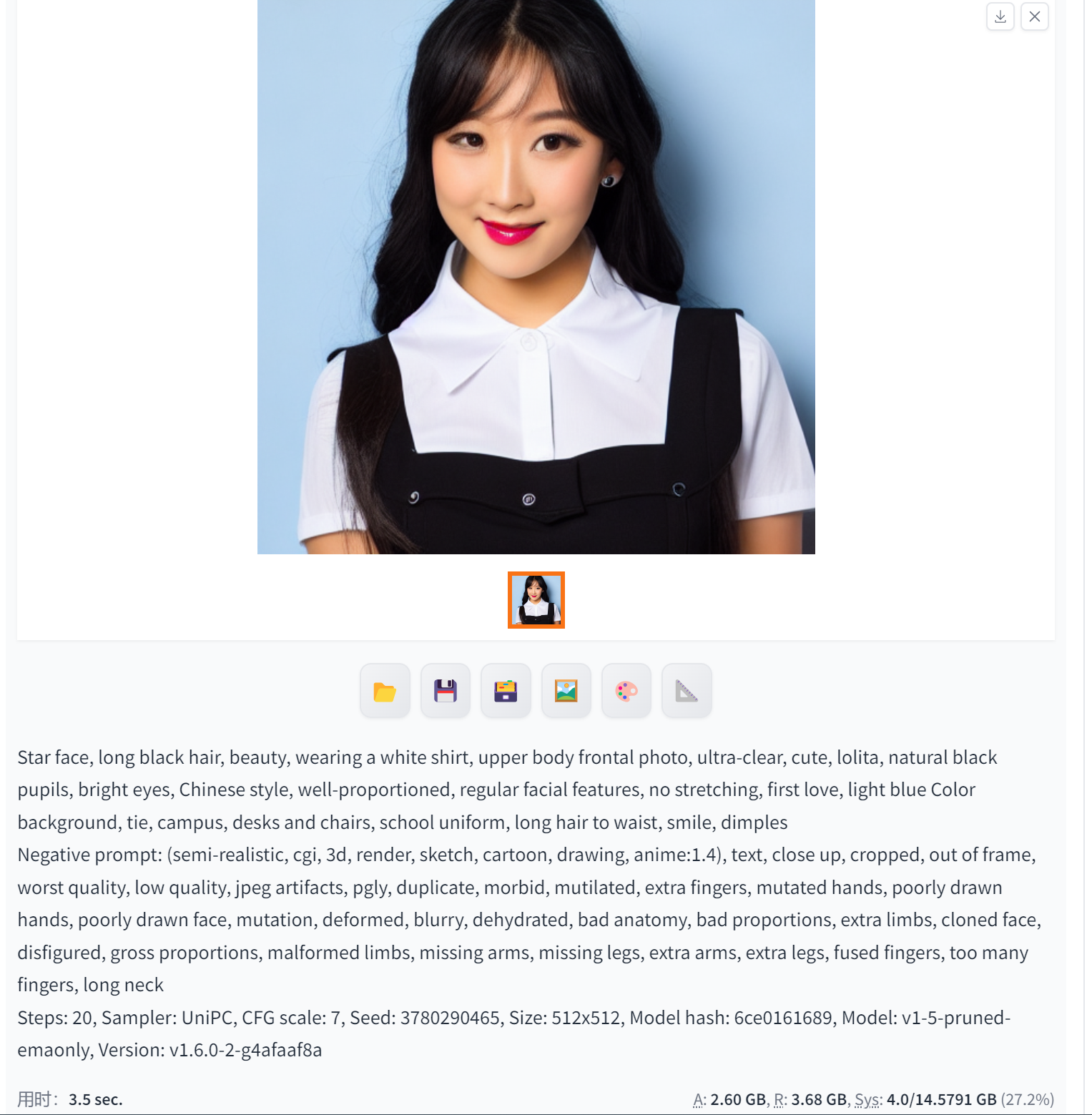
生成非人像效果很好:
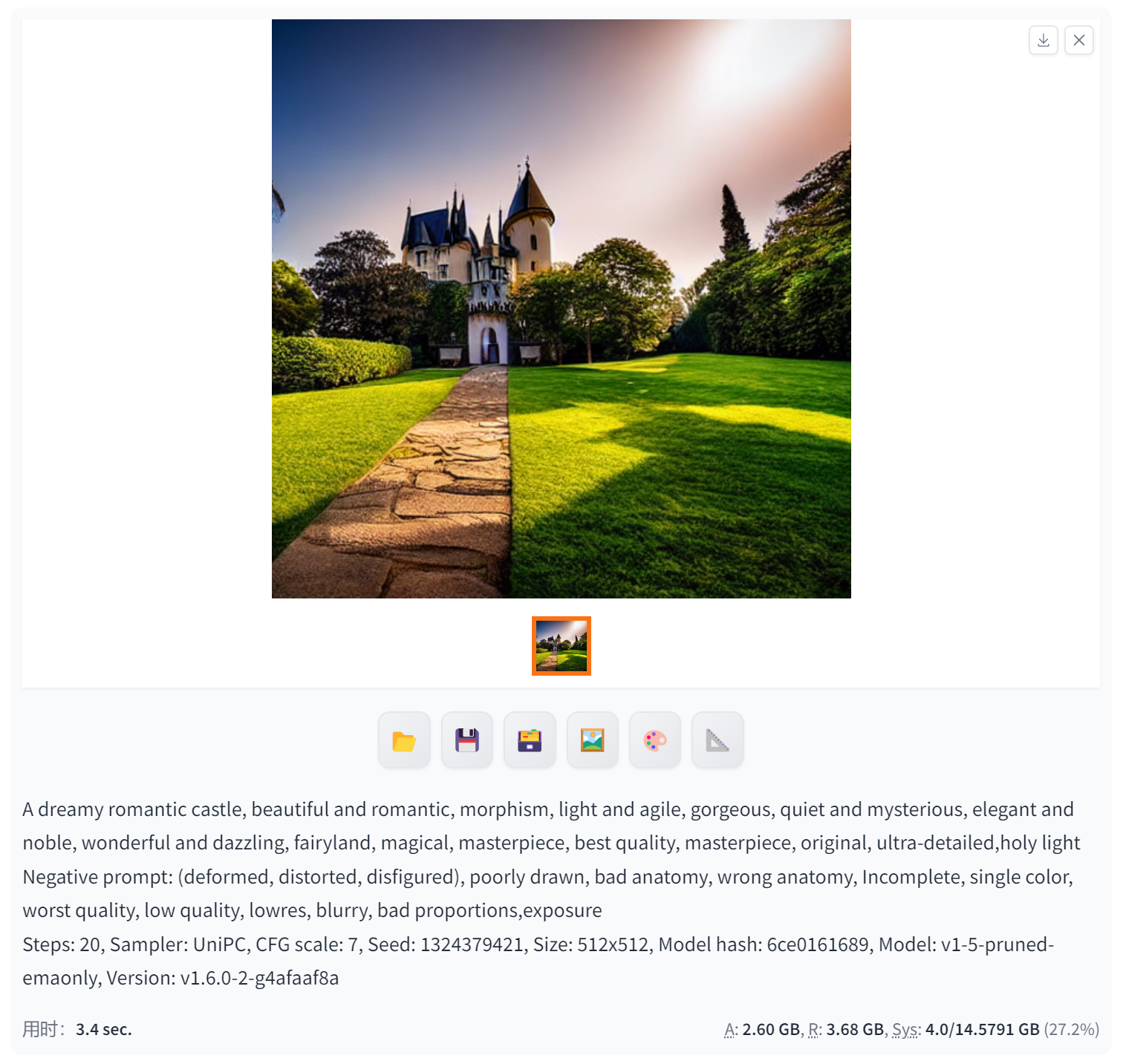
总结
我们可以使用不同的采样率生成我们需要的目标图片,这些图片也可以通过微调进行连贯的制作出视频。文章最开头就是一个视频的展示,后面会有对应的具体教程,本篇文章先带大家认识各类的采样率。后面是对应插件的安装,从下面的内容基本可以看到网址都是【github】的,如果不科学上网是很难下载的,可以给大家看看一个合格模型的大小。
插件安装位置:
一般模型大小,这个算是不大不小的:
模型可以在:
这个网站中找找看,很多非常优秀的模型,选一个自己喜欢的一直玩下去,合适的才是最好的。
