
阅读量:0
HTML + JavaScript 实现网页录制音频与下载
HTML + JavaScript 实现网页录制音频与下载
简介
在这个数字化的时代,网页端的音频处理能力已经成为一个非常热门的需求。本文将详细介绍如何利用 getUserMedia 和 MediaRecorder 这两个强大的 API,实现网页端音频的录制、处理和播放等功能。
getUserMedia
getUserMedia 和 MediaRecorder 是 HTML5 中两个非常重要的 API,用于访问设备媒体输入流并对其进行操作。
getUserMedia 允许网页端访问用户设备的媒体输入设备,比如摄像头和麦克风。通过该 API,在获得用户授权后,我们可以获取这些媒体流的数据,并用于各种网页应用场景中。
典型的使用方式如下:
// 请求获取音频流 navigator.mediaDevices.getUserMedia({ audio: true }) .then(stream => { // 在此处理音频流 }) getUserMedia 接受一个 constraints 对象作为参数,通过设置配置来请求获取指定的媒体类型,常见的配置有:
- audio:Boolean 值,是否获取音频输入。
- video:Boolean 值,是否获取视频输入。
- 以及更详细的各种音视频参数设置。
MediaRecorder
MediaRecorder API 可以获取由 getUserMedia 生成的媒体流,并对其进行编码和封装,输出可供播放和传输的媒体文件。
典型的用法如下:
// 获取媒体流 const stream = await navigator.mediaDevices.getUserMedia({ audio: true }) // 创建 MediaRecorder 实例 const mediaRecorder = new MediaRecorder(stream); // 注册数据可用事件,以获取编码后的媒体数据块 mediaRecorder.ondataavailable = event => { audioChunks.push(event.data); } // 开始录制 mediaRecorder.start(); // 录制完成后停止 mediaRecorder.stop(); // 将录制的数据组装成 Blob const blob = new Blob(audioChunks, { type: 'audio/mp3' }); 简单来说,getUserMedia 获取输入流,MediaRecorder 对流进行编码和处理,两者结合就可以实现强大的音视频处理能力。
获取和处理音频流
了解了基本 API 使用方法后,我们来看看如何获取和处理音频流。
首先需要调用 getUserMedia 来获取音频流,典型的配置是:
const stream = await navigator.mediaDevices.getUserMedia({ audio: { channelCount: 2, sampleRate: 44100, sampleSize: 16, echoCancellation: true } }); 我们可以指定声道数、采样率、采样大小等参数来获取音频流。
PS:这似乎不管用。
使用 navigator.mediaDevices.enumerateDevices() 可以获得所有可用的媒体设备列表,这样我们就可以提供设备选择功能给用户,而不仅仅是默认设备。
举例来说,如果我们想要让用户选择要使用的录音设备:
// 1. 获取录音设备列表 const audioDevices = await navigator.mediaDevices.enumerateDevices(); const mics = audioDevices.filter(d => d.kind === 'audioinput'); // 2. 提供设备选择 UI 供用户选择 const selectedMic = mics[0]; // 3. 根据选择配置进行获取流 const constraints = { audio: { deviceId: selectedMic.deviceId } }; const stream = await navigator.mediaDevices.getUserMedia(constraints); 这样我们就可以获得用户选择的设备录音了。
获得原始音频流后,我们可以利用 Web Audio API 对其进行处理。
例如添加回声效果:
// 创建音频环境 const audioContext = new AudioContext(); // 创建流源节点 const source = audioContext.createMediaStreamSource(stream); // 创建回声效果节点 const echo = audioContext.createConvolver(); // 连接处理链 source.connect(echo); echo.connect(audioContext.destination); // 加载回声冲击响应并应用 const impulseResponse = await fetch('impulse.wav'); const buffer = await impulseResponse.arrayBuffer(); const audioBuffer = await audioContext.decodeAudioData(buffer); echo.buffer = audioBuffer; 通过这样的音频处理链,我们就可以在录音时添加回声、混响等音效了。
实现音频的录制和播放
录制音频的步骤:
- 调用 getUserMedia 获取音频流。
- 创建 MediaRecorder 实例,传入音频流。
- 注册数据可用回调,以获取编码后的音频数据块。
- 调用 recorder.start() 开始录制。
- 录制完成后调用 recorder.stop()。
代码:
let recorder; let audioChunks = []; // 开始录音 handler const startRecording = async () => { const stream = await navigator.mediaDevices.getUserMedia({ audio: true }); recorder = new MediaRecorder(stream); recorder.ondataavailable = event => { audioChunks.push(event.data); }; recorder.start(); } // 停止录音 handler const stopRecording = () => { if(recorder.state === "recording") { recorder.stop(); } } 录音完成后,我们可以将音频数据组装成一个 Blob 对象,然后赋值给一个 <audio> 元素的 src 属性进行播放。
代码:
// 录音停止后 const blob = new Blob(audioChunks, { type: 'audio/ogg' }); const audioURL = URL.createObjectURL(blob); const player = document.querySelector('audio'); player.src = audioURL; // 调用播放 player.play(); 这样就可以播放刚刚录制的音频了。
后续也可以添加下载功能等。
音频效果的处理
利用 Web Audio API,我们可以添加各种音频效果,进行音频处理。
例如添加回声效果:
const audioContext = new AudioContext(); // 原始音频节点 const source = audioContext.createMediaStreamSource(stream); // 回声效果节点 const echo = audioContext.createConvolver(); // 连接处理链 source.connect(echo); echo.connect(audioContext.destination); // 加载冲击响应作为回声效果 const impulseResponse = await fetch('impulse.wav'); const arrayBuffer = await impulseResponse.arrayBuffer(); const audioBuffer = await audioContext.decodeAudioData(arrayBuffer); echo.buffer = audioBuffer; 这样在录制时音频流就会经过回声效果处理了。
此外,我们还可以添加混响、滤波、均衡器、压缩等多种音频效果,使得网页端也能处理出专业级的音频作品。
实时语音通话的应用
利用 getUserMedia 和 WebRTC 技术,我们还可以在网页端实现实时的点对点语音通话。
简述流程如下:
- 通过 getUserMedia 获取本地音视频流。
- 创建 RTCPeerConnection 实例。
- 将本地流添加到连接上。
- 交换 ICE 候选信息,建立连接。
- 当检测到连接后,渲染远端用户的音视频流。
这样就可以实现类似 Skype 的网页端语音通话功能了。
代码:
// 1. 获取本地流 const localStream = await navigator.mediaDevices.getUserMedia({ audio: true, video: true }); // 2. 创建连接对象 const pc = new RTCPeerConnection(); // 3. 添加本地流 localStream.getTracks().forEach(track => pc.addTrack(track, localStream)); // 4. 交换 ICE 等信令,处理 ONADDSTREAM 等事件 // ... // 5. 收到远端流,渲染到页面 pc.ontrack = event => { remoteVideo.srcObject = event.streams[0]; } 获取本地输入流后,经过编码和传输就可以实现语音聊天了。
兼容性和 Latency 问题
尽管 getUserMedia 和 MediaRecorder 在现代浏览器中已经得到了较好的支持,但由于不同厂商和版本实现存在差异,在实际应用中还是需要注意一些兼容性问题:
- 检测 API 支持情况,提供降级方案。
- 注意不同浏览器对 Codec、采样率等参数支持的差异。
- 封装浏览器差异,提供统一的 API。
此外,录音和播放也存在一定的延迟问题。我们需要针对 Latency 进行优化,比如使用更小的 buffer 大小,压缩数据包大小等方法。
项目代码
record.html:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Record Page</title> <link rel="stylesheet" type="text/css" href="css/record.css"> </head> <body> <div class="app"> <audio controls class="audio-player"></audio> <button class="record-btn">录音</button> <a id="download" download="record.aac"></a> </div> </body> <script src="js/record.js"></script> </html> record.css:
.app { display: flex; justify-content: center; align-items: center; } .record-btn { margin: 0 10px; } record.js:
const recordBtn = document.querySelector(".record-btn") const player = document.querySelector(".audio-player") const download = document.querySelector('#download') if (navigator.mediaDevices.getUserMedia) { let audioChunks = [] // 约束属性 const constraints = { // 音频约束 audio: { sampleRate: 16000, // 采样率 sampleSize: 16, // 每个采样点大小的位数 channelCount: 1, // 通道数 volume: 1, // 从 0(静音)到 1(最大音量)取值,被用作每个样本值的乘数 echoCancellation: true, // 开启回音消除 noiseSuppression: true, // 开启降噪功能 }, // 视频约束 video: false } // 请求获取音频流 navigator.mediaDevices.getUserMedia(constraints) .catch(err => serverLog("ERROR mediaDevices.getUserMedia: ${err}")) .then(stream => {// 在此处理音频流 // 创建 MediaRecorder 实例 const mediaRecorder = new MediaRecorder(stream) // 点击按钮 recordBtn.onclick = () => { if (mediaRecorder.state === "recording") { // 录制完成后停止 mediaRecorder.stop() recordBtn.textContent = "录音结束" } else { // 开始录制 mediaRecorder.start() recordBtn.textContent = "录音中..." } } mediaRecorder.ondataavailable = e => { audioChunks.push(e.data) } // 结束事件 mediaRecorder.onstop = e => { // 将录制的数据组装成 Blob(binary large object) 对象(一个不可修改的存储二进制数据的容器) const blob = new Blob(audioChunks, { type: "audio/aac" }) audioChunks = [] const audioURL = window.URL.createObjectURL(blob) // 赋值给一个 <audio> 元素的 src 属性进行播放 player.src = audioURL // 添加下载功能 download.innerHTML = '下载' download.href = audioURL } }, () => { console.error("授权失败!"); } ); } else { console.error("该浏览器不支持 getUserMedia!"); } 运行实例
打开 record.html,首先获取麦克风权限:

点击“允许”。
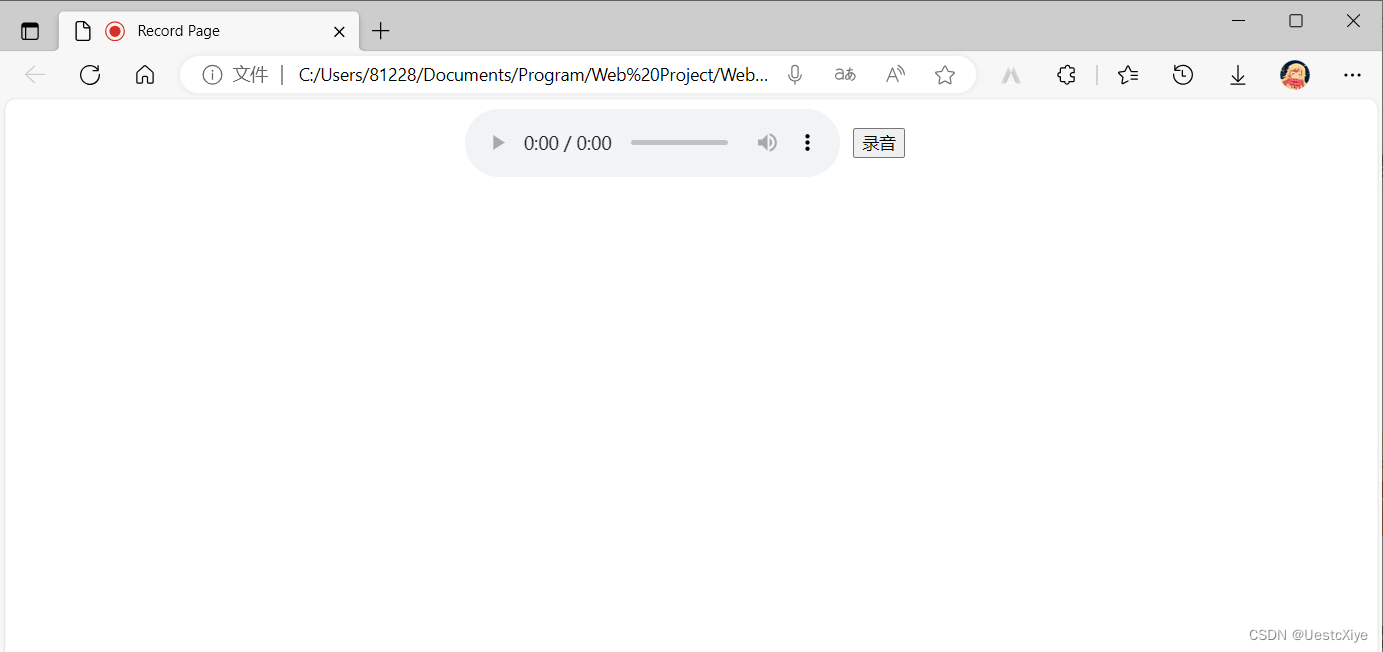
页面有一个 audio-player 和一个 buttom。
点击“录音”按钮,就开始录音了。
再点一次按钮,停止录音,数据传回给 audio-player,可以在网页上播放录音。
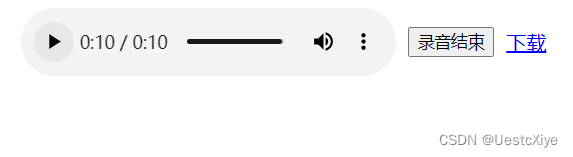
点击“下载”,可以下载录制的音频。
PS:音频文件名称设置为 record.aac,文件格式为 WebM,音频格式为 opus,单声道,采样率 48kHz,位深 32bit。
参考
源码下载
CSDN:Web Record.zip
GitHub:Web-Record
