
阅读量:0
这篇文章主要用于对于多线程的一些查缺补漏。
一、 线程的状态
1,操作系统层面,线程的5种状态
关于线程有几种状态,有多种说法,5、6、7都有。
首先对于操作系统来说,只有5种状态,状态如下新建(New)、就绪(Ready)、等待(Waiting)、运行(Running)、结束(Terminated)。
线程刚刚创建,还没有开始运行,就是新建状态。
线程开始运行,但是还没被分配时间片,就是就绪状态。
线程被分配了时间片,进入运行状态。
线程因为某些原因,如java调用sleep,wait,操作系统层面,线程都是进入了阻塞状态。
阻塞状态的线程不再拥有时间片,但是也不能算作就绪状态,因为此状态的线程往往都是需要等待某个任务的完成再进入就绪状态,进而被分配时间片再次进入运行状态。要理解“为什么会出现阻塞状态这种奇怪的状态”就需要先理解cpu和内存、硬盘速度的差别。这里放到最后讲吧[注1]。
阻塞结束的线程,进入就绪状态,等待重新被分配时间片。
运行结束后,线程进入死亡状态。
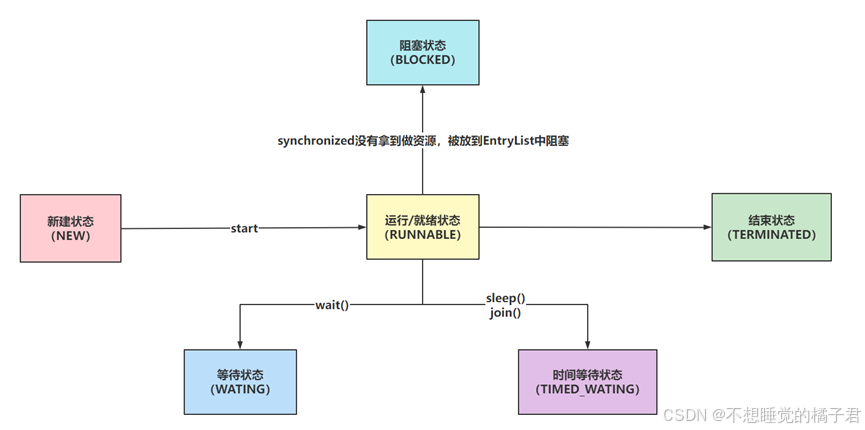
2,Java虚拟机层面,Java线程的6种状态
上面讲了操作系统层面的线程5种状态,很多文章用Java的方法来解释5种状态,个人觉得这是不正确的,因为Java的Thread类的内部类State中,明确定义了Java线程是6种状态,当然这6种状态很多其实对于操作系统来说就是阻塞,Java做了一层封装。
public enum State { /** * Thread state for a thread which has not yet started. */ NEW, /** * Thread state for a runnable thread. A thread in the runnable * state is executing in the Java virtual machine but it may * be waiting for other resources from the operating system * such as processor. */ RUNNABLE, /** * Thread state for a thread blocked waiting for a monitor lock. * A thread in the blocked state is waiting for a monitor lock * to enter a synchronized block/method or * reenter a synchronized block/method after calling * {@link Object#wait() Object.wait}. */ BLOCKED, /** * Thread state for a waiting thread. * A thread is in the waiting state due to calling one of the * following methods: * <ul> * <li>{@link Object#wait() Object.wait} with no timeout</li> * <li>{@link #join() Thread.join} with no timeout</li> * <li>{@link LockSupport#park() LockSupport.park}</li> * </ul> * * <p>A thread in the waiting state is waiting for another thread to * perform a particular action. * * For example, a thread that has called <tt>Object.wait()</tt> * on an object is waiting for another thread to call * <tt>Object.notify()</tt> or <tt>Object.notifyAll()</tt> on * that object. A thread that has called <tt>Thread.join()</tt> * is waiting for a specified thread to terminate. */ WAITING, /** * Thread state for a waiting thread with a specified waiting time. * A thread is in the timed waiting state due to calling one of * the following methods with a specified positive waiting time: * <ul> * <li>{@link #sleep Thread.sleep}</li> * <li>{@link Object#wait(long) Object.wait} with timeout</li> * <li>{@link #join(long) Thread.join} with timeout</li> * <li>{@link LockSupport#parkNanos LockSupport.parkNanos}</li> * <li>{@link LockSupport#parkUntil LockSupport.parkUntil}</li> * </ul> */ TIMED_WAITING, /** * Thread state for a terminated thread. * The thread has completed execution. */ TERMINATED; } 对于Java线程的这6种状态,就可以通过sleep、wait来解释Java线程状态的流转。而不是直接用Java方法解释操作系统的5种状态。
New状态:线程被new出来,就是新建状态。
Runnable状态:操作系统层面的就绪/运行状态,都是Java虚拟机层面的Runnable状态。
Blocked状态:抢锁失败的Java线程,进入阻塞状态。
Waiting状态:调用了没有时间参数的wait方法,进入此状态,或者别的线程调用了Join方法,把此线程挤到了waiting状态。
Timed_Waiting状态:指定了时间参数的一些方法,会让此线程进入timed_waiting状态,如
* <li>{ #sleep Thread.sleep}</li> * <li>{ Object#wait(long) Object.wait} with timeout</li> * <li>{ #join(long) Thread.join} with timeout</li> * <li>{ LockSupport#parkNanos LockSupport.parkNanos}</li> * <li>{ LockSupport#parkUntil LockSupport.parkUntil}</li> JUC包中,有很多通过LockSupport.parknanos让线程进入waiting和timed_waiting状态的代码,一般通过线程中断位的改变(Thread类的interrupt方法),检测中断位的改变(Thread的isInterrupted方法)并抛出InterruptedException唤醒线程。
Terminated状态:线程结束运行,进入此状态。
二,并发编程三大特性:在操作系统层面的实现
原子性,一个操作或者多个操作,在执行的过程中不能被中断。
可见性,当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
有序性,程序执行的顺序按照代码的先后顺序执行[5]。
需要说明的是,这一节中,讲的主要是操作系统、汇编语言和硬件层面,在多线程的情况下,如何保证原子性、可见性、有序性的。
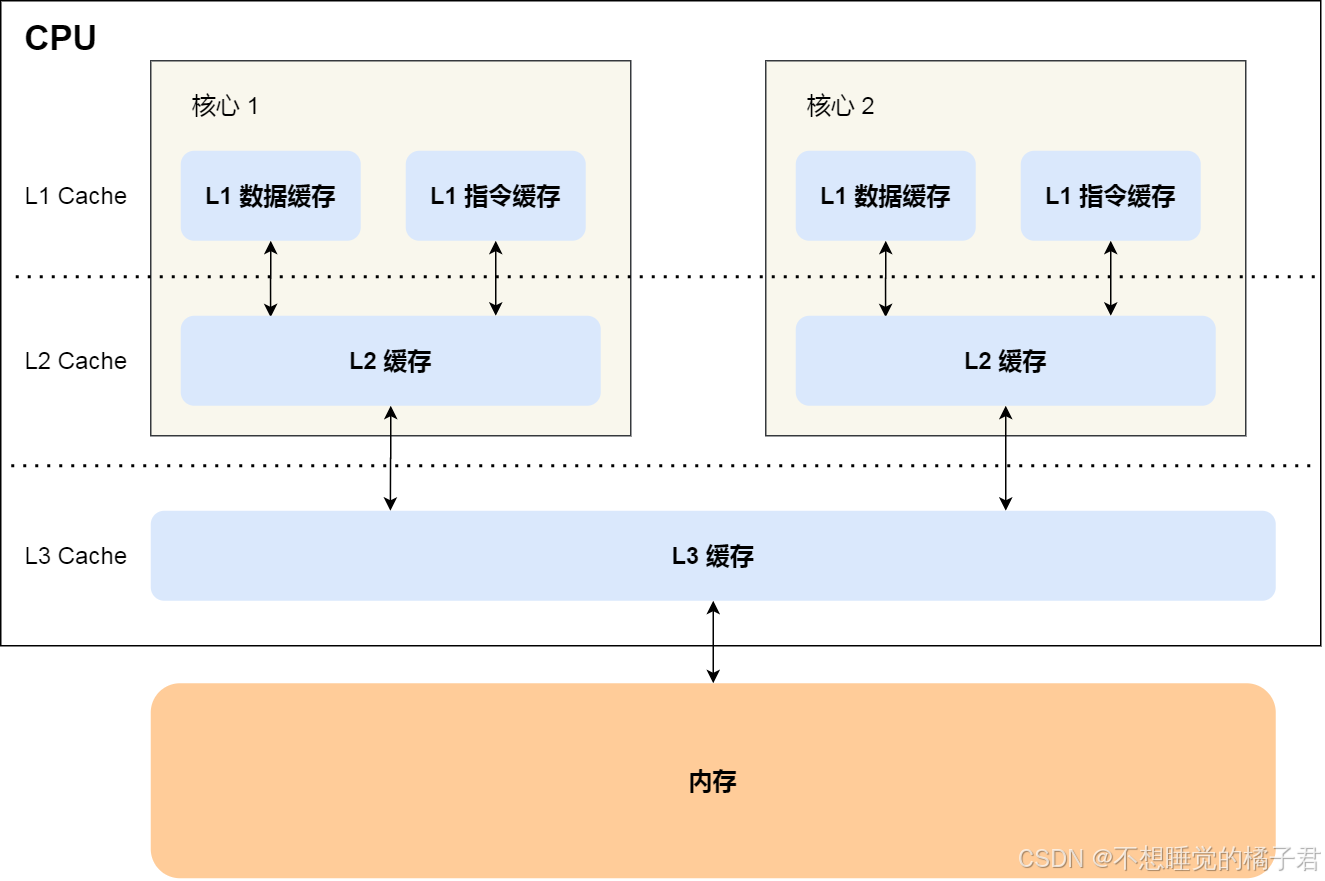
了解三大特性之前,需要先看一下这一块的架构,
高速缓存L1、L2、L3与共享内存的关系:
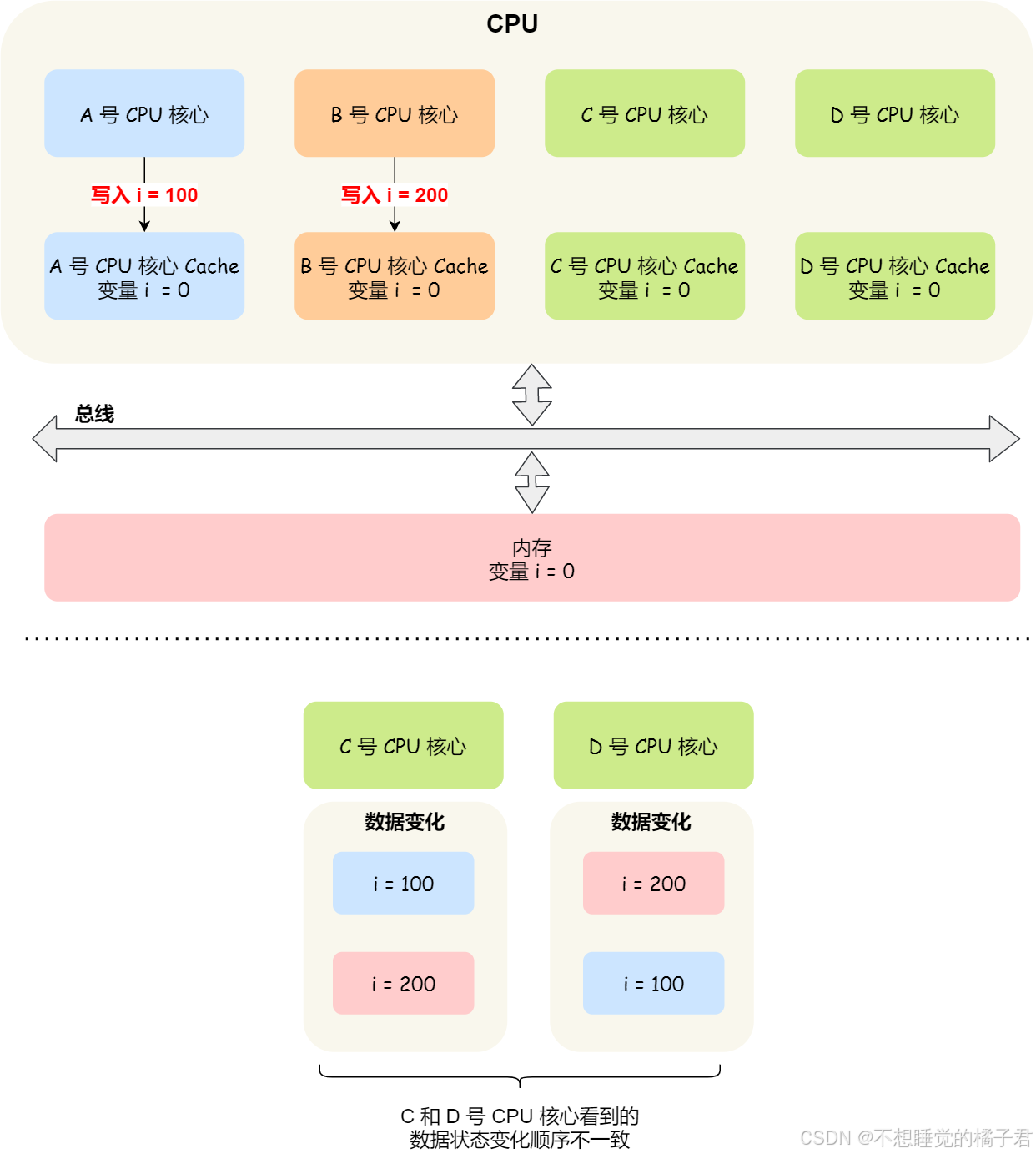
cpu,总线,内存之间的关系:
1,原子性
在操作层面,实现多线程并发情况下的原子性,底层依赖的是总线锁和缓存锁。关于总线锁和缓存锁更多的细节可以看这篇文章[6]。
首先讲一下总线锁,这个比较简单,总线锁是将多个cpu与共享内存之间的总线锁住,这样,原子性就得到了保证。因为总线锁的存在,多线程并发直接变成了单线程,原子性自然得到了保证。
另外一个比较复杂的就是缓存锁。要讲缓存锁,要先从缓存行(Cache Line)开始说起。缓存行是cpu读取内存的基本单位,大小为64个字节。也就是说,即使只读取一个4kb的int类型变量,依然会将这个整形所在的64kb大小的缓存行一整个读取进cpu的高速缓存。如果两个不同cpu上的不同线程同时修改了同一个缓存行,那么就会出现数据不一致的问题。因此出现了缓存一致性协议,保证对数据的修改,对于其他线程来说是立即可见的(如Intel实现的MESI协议)[7]。
当线程要操作的数据仅在一个缓存行时,通过缓存一致性协议,能保证向这个缓存行写入的数据,要么成功(期间没有别的线程向这个缓存行写入),要么失败(有别的线程向共享内存中的这个缓存行写入了,因此这个线程在一开始从共享内存中读取这个缓存行,并尝试向其同步时,就发现缓存行状态改变,意味着这个缓存行被其他线程修改过了,需要重新读取缓存行、计算和回写。
多个线程并发的情况下,缓存一致性协议存在伪共享性能问题[7]。
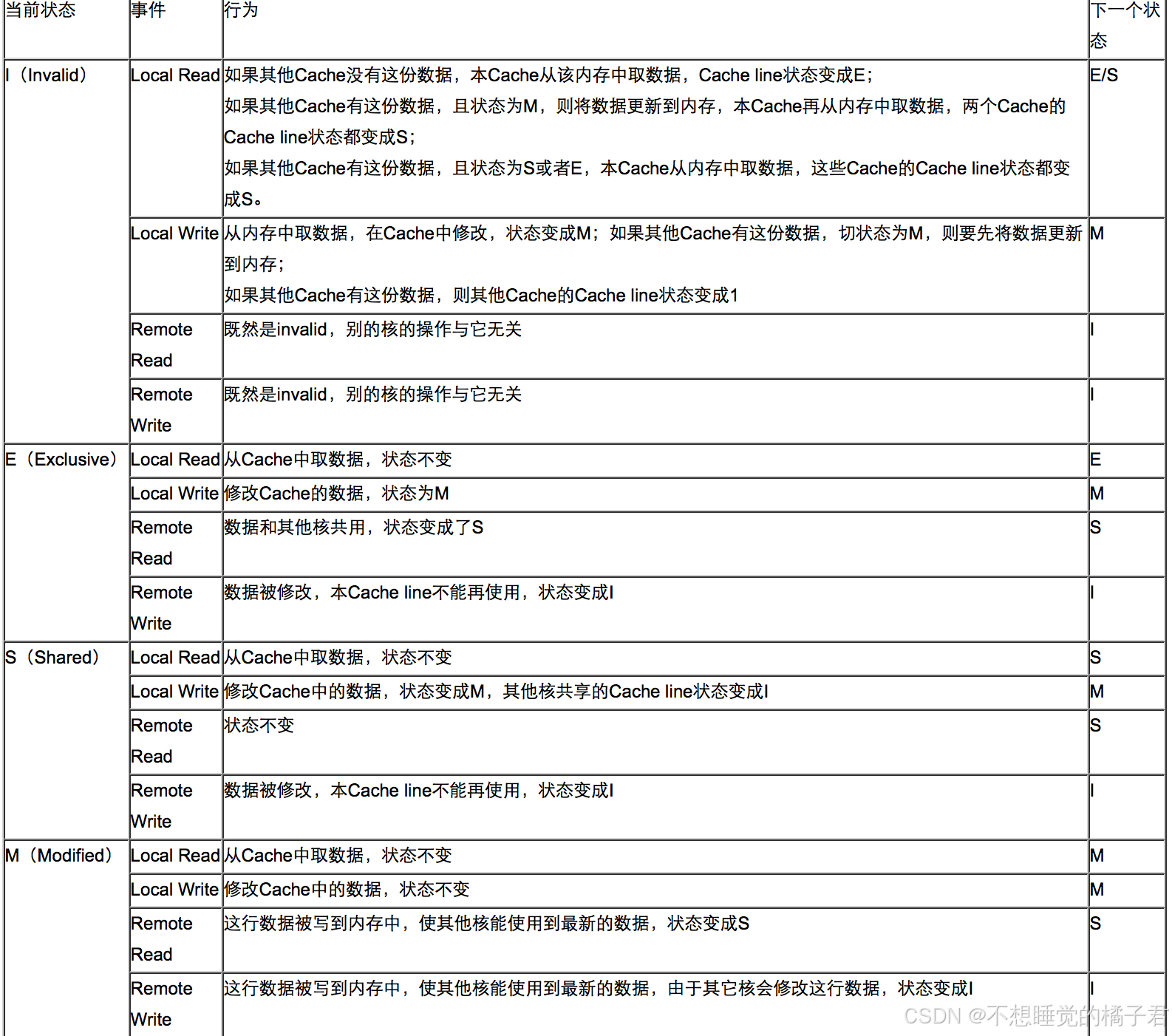
intel实现的MESI协议是一种简单而有效的缓存一致性协议。它定义了四种状态[15]:
Modified(M):数据项已被修改,与主存中的值不同。处理器核心必须将该数据项写回主存,以更新主存中的值。 Exclusive(E):数据项只存在于当前缓存中,与其他缓存中的值不同。处理器核心可以直接修改该数据项,无需通知其他核心。 Shared(S):数据项存在于多个缓存中,与主存中的值相同。处理器核心在修改该数据项前,需要将其状态变为Modified,并通知其他核心。 Invalid(I):缓存中的数据项无效,需要从主存或其他缓存中获取最新值。 不同状态的转换关系如下图[16],可以看到,修改和独占状态,都是只有自己这个线程在使用缓存行。
缓存一致性协议是保证可见性的(说是一致性也差不多),缓存锁又是如何实现的呢?
文章[11]中描述如下:
“如果要访问的内存区域(area of memory)在lock前缀指令执行期间已经在处理器内部的缓存中被锁定(即包含该内存区域的缓存行当前处于独占或以修改状态),并且该内存区域被完全包含在单个缓存行(cache line)中,那么处理器将直接执行该指令。由于在指令执行期间该缓存行会一直被锁定,其它处理器无法读/写该指令要访问的内存区域,因此能保证指令执行的原子性。这个操作过程叫做缓存锁定(cache locking),缓存锁定将大大降低lock前缀指令的执行开销,但是当多处理器之间的竞争程度很高或者指令访问的内存地址未对齐时,仍然会锁住总线。”
即第一,intel是基于MESI协议,在缓存行状态为独占或修改时,确保当前缓存行只有自己在使用,第二,如果发现只有自己在使用这个缓存行,就会锁定这个缓存行,不让其他线程读/写,直到锁定结束,来确保原子性。
在这篇文章[9]中,是这么描述的:“对于P6和最近的处理器系列,如果要操作的内存区域已经被缓存在处理器中,若此发生回写内存操作,LOCK#信号不能总是在总线上进行断言。相反,允许它的缓存一致性机制生效,以确保操作是原子进行的。 这 操作称为“缓存锁定”。 [9]”
因此,缓存锁定和缓存一致性协议,有关系,但不是一回事。很多文章将其混为一谈,是不对的。缓存一致性协议的名字已经告诉你了,它是保证一致性或者说是可见性的。
缓存锁的问题在于,
1,不能跨缓存行,也就是不能跨越多个缓存行对数据进行锁定,或者不能被缓存的数据,缓存锁也是无效的。 2,要处理器硬件支持缓存行才行。 如一些汇编指令,如Java中CAS操作,底层用的是cmpxchg(也就是CompareAndChange,比较和交换的意思,这样理解比较好记),前面会加上LOCK;volatile和synchronized,到了汇编层面,也是加lock。
volatile的属性在赋值时,在汇编层面代码[7]:
synchronized在汇编层面[7]:
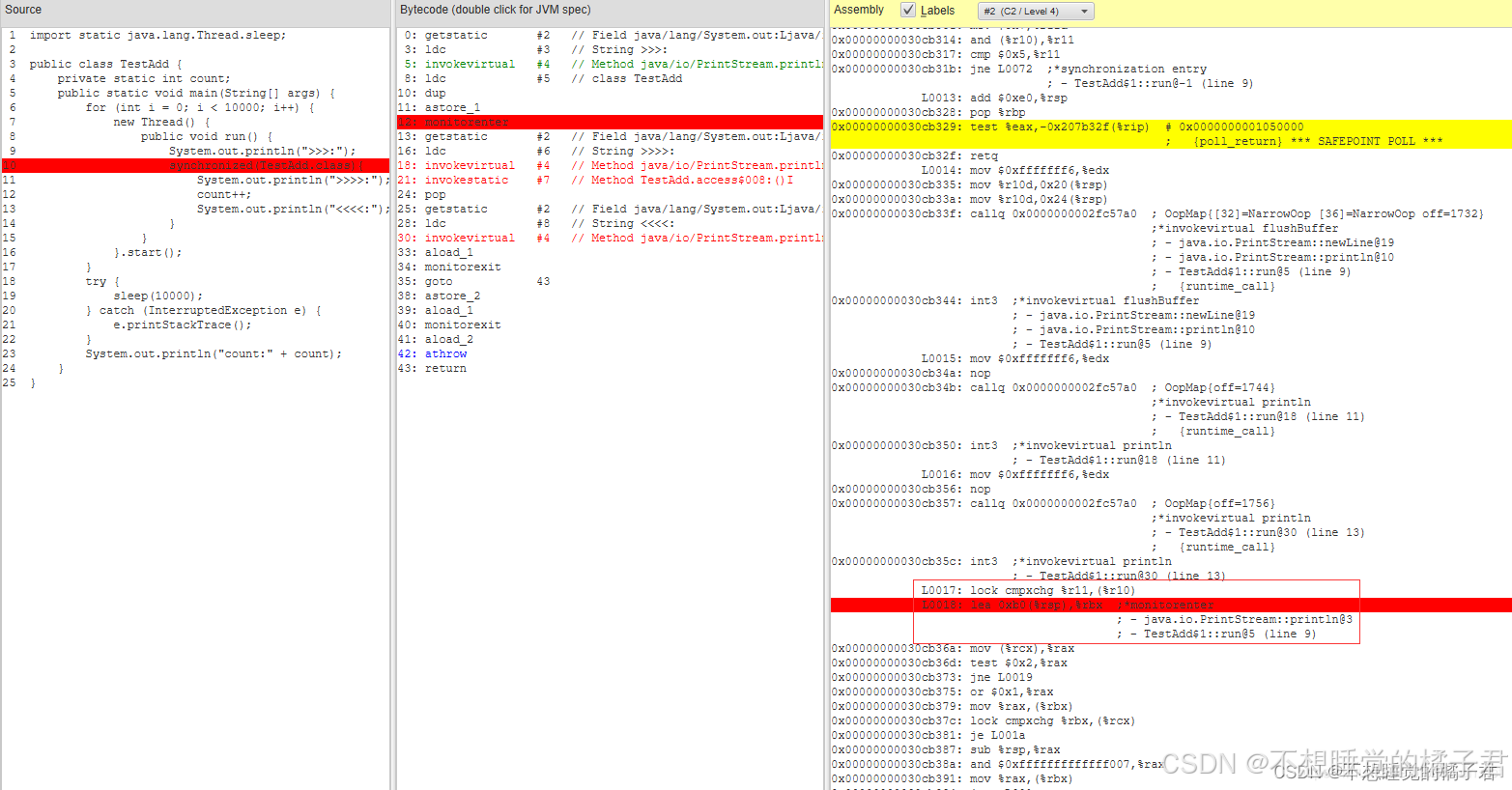
需要明确的是,加了lock,不一定就是总线锁。有的博客认为加了lock表示总线锁,这是错误的。intel开发手册中有明确,一些比较老的处理器,lock调用的就是总线锁,而比较新的处理器,lock会优先调用缓存锁,其次是总线锁[9]。
需要说明的是,lock锁调用的总线锁和缓存锁,其颗粒度很小,只是一条汇编语句加锁确保原子性,和synchronized确保整个对象的线程私有不同。synchronized更新后,无锁,偏向锁/匿名偏向,轻量级锁,重量级锁,是要在对象头或指针指向的轻量级锁Lock Record/重量级锁ObjectMonitor中记录线程id的,来确保这个对象只会被一个线程操作,保证了颗粒度更大的原子性,这才是Java应用层面上常用到的原子性。
2,可见性
前面在讲原子性的时候,讲了volatile修饰的变量,其赋值代码,在汇编层面,加了lock指令。因此这里还是介绍一下lock指令,文章[11]中查询IA-32架构手册,总结lock作用如下:
1,提供原子性,老cpu直接总线锁,新cpu优先缓存锁,其次总线锁[9] 2,lock后的写操作会回写已修改的数据,同时让其它CPU相关缓存行失效,从而重新从主存中加载最新的数据 3,不是内存屏障却能完成类似内存屏障的功能,阻止屏障两遍的指令重排序 仅就volatile修饰的变量的赋值操作本身,上面原子性举例的图中,可以看到汇编层面加lock锁,结合上面的解释,也就是说在汇编层面,赋值操作在lock结后会立即刷新回写到共享内存,并且在赋值期间加锁,保证数据的可见性。
文章[11]中举例两个线程同时执行i++如下:
工作内存Work Memory其实就是对CPU寄存器和高速缓存的抽象,或者说每个线程的工作内存也可以简单理解为CPU寄存器和高速缓存。 那么当写两条线程Thread-A与Threab-B同时操作主存中的一个volatile变量i时,Thread-A写了变量i,那么: Thread-A发出LOCK#指令 发出的LOCK#指令锁总线(或锁缓存行),同时让Thread-B高速缓存中的缓存行内容失效 Thread-A向主存回写最新修改的i Thread-B读取变量i,那么: Thread-B发现对应地址的缓存行被锁了,等待锁的释放,缓存一致性协议会保证它读取到最新的值 volatile修饰的变量的一行Java语句赋值操作,汇编层面加了lock指令,保证了一条汇编语句的原子性,这个例子中是这样的,难道因此volatile修饰的Java变量保证了其原子性吗?
并不是这样的,从Java语言到汇编的层层解释与编译,其实是很复杂的,例如一个synchronized在字节码层面是3个字节码,具体到汇编层面可能会有很多行代码,也可能根据具体的硬件不同会有不同的解释。
加了volatile的属性,写操作时汇编层面加个锁保证写入的原子性,读也能保证线程读到最新的值,一条汇编语句的锁,是颗粒度极小的锁,这和Java层面,给对象加synchronized锁,是两回事。
文章[11]中举例的是i++。但是解释有部分错误,其实是i++的字节码只有1个,前两个字节码操作是定义变量i的。
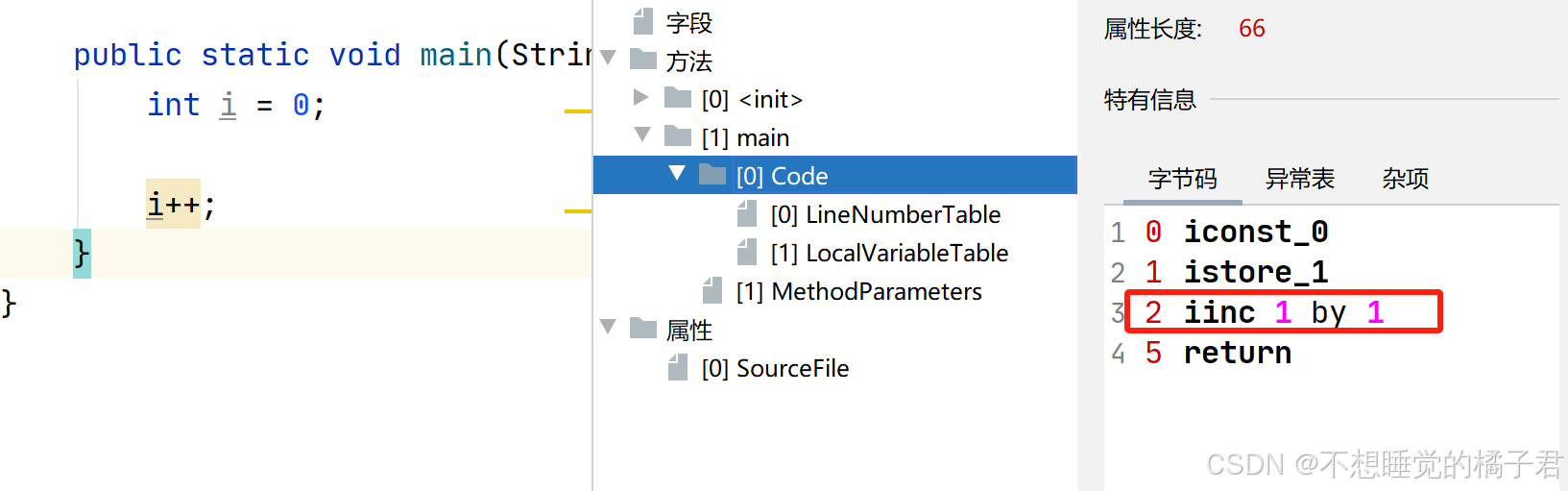
准确的说,是在汇编和机器执行层面,i++和++i都不是原子的[13],因此即使给多个操作中的某一个操作加了锁,整体上也不是原子的。
因为对于加了volatile修饰的对象,两个线程都可以读到最新的值,各自修改以后,都去进行写入,即使汇编层面单个写入操作有原子性,两个不同的写入,最后保证不了整体上的原子性,无法确保多个操作的执行不会被其他线程打断。
说到底,volatile只能保证可见性,但是不能保证原子性。因此对于volatile修饰的变量,底层汇编语句是什么样的,用的内存屏障还是lock锁,要具体情况具体分析,而且volatile更无法保证原子性,不要把它当锁,仅仅用于多线程时保证可见性和顺序性是可以的。
即使上面理解不了,也无所谓,这里需要明确,也是最重要的,java的volatile的语义:
- volatile属性被写:当写一个volatile变量,JMM会将当前线程对应的CPU缓存及时的刷新到主内存中
- volatile属性被读:当读一个volatile变量,JMM会将对应的CPU缓存中的内存设置为无效,必须去主内存中重新读取共享变量
3,顺序性
硬件层面有一个原则,叫as-if-serial,就是说Java代码编译到cpu指令,具体执行时,其实是有可能乱序执行的,只是对于单个线程来说,其乱序执行结果,看起来和顺序执行一样。即,单线程情况下,顺序性是默认被满足的。
但问题在于多线程时,这样的乱序执行会带来问题。如经典的单例问题,为什么要给单例对象加volatile?就是因为在给对象赋值的过程中,如果指令重排序,可能调用者会拿到一个为空的地址!
那如何满足多线程情况下的顺序性呢?
第一,加锁,不管是总线锁,还是缓存锁,只要cpu给你用上了,就能多线程并发竞争读取临界资源,就会变成单线程,因此满足了顺序性。经典的”解决不了问题就解决提出问题的人“的思路。
第二,禁止指令重排序。怎么禁止呢?答案就是内存屏障
硬件层面的内存屏障,如intel的cpu指令[11]sfence、mfence等。
应用层面也会有自己的内存屏障,如JSR(Java Specification Request,JSR,Java规范请求)中的内存屏障,LoadLoad屏障,LoadStore屏障,StoreStore屏障等(其底层实现不一定是sfence,也可能是锁)。
以intel的sfence、lfence等为例,内存屏障就是禁止读操作重排序越过读屏障(lfence),禁止写操作重排序越过写屏障(sfence)。
至于happens-before原则,是JVM规定重排序需要遵守的规则,与硬件层面无关。
【注1】:
为什么会出现阻塞状态这种状态?线程干活就Running状态,不干活就Ready,干完活就Terminated不好吗?这其中的原因,是因为cpu、内存、硬盘速度的天差地别。
前几天在看游戏本,cpu基本都能做到四五个G的晶振频率,也就是说每秒计算5G次,5G=510^128bit,而1s等于10的12次方ns,换算下来,cpu完成一次计算,大概只需要1/(5*8)=0.025ns。
而内存和硬盘呢,L1到L3高速缓存从1ns到十几ns不等[2],共享内存大概是80ns左右,固态硬盘大约是100um,机械硬盘是15毫秒。
cpu、内存、硬盘,每两个存在至少3个量级的速度差别。
假设线程在进行IO,从硬盘的一个位置写入到另一个位置,意味着线程在完成cpu拷贝(将数据从用户空间的内存拷贝到内核空间的内存或者相反)后,在进行从内存向硬盘的复制时,cpu因为速度太快硬盘太慢,cpu要等待很长时间。
因此为了彻底挖掘牛马cpu的计算速度,现代计算机有很多措施保证:
如,1,很多硬件基本都配置了dma,代替计算机cpu进行拷贝,所谓DMA,就是代替计算机做"复制粘贴"这种简单工作的控制器;
2,使用零拷贝技术[3,4],sendfile取消2次cpu拷贝,mmap取消了1次cpu拷贝,而正常的IO,需要2次dma拷贝,2次cpu拷贝;
3,最重要的是,在cpu不需要干活,但是线程的任务还没有完成的时候,让线程进入阻塞状态,暂时不给线程分配时间片,让别的线程来使用这个cpu(线程在cpu的切换,叫做切换线程上下文,需要备份线程的资源,是一个比较耗时的操作,但仅仅是内存数据的备份相对cpu计算来说耗时),彻底挖掘cpu的计算能力。
也就是说,线程的阻塞状态,让cpu从等待中解放出来,可以多干活了。而任务没有完成,比如需要等待IO完成的线程,sleep到一定时间再醒来的线程,被wait排队的线程,都会进入阻塞状态。
阻塞状态的线程,无法被分配时间片,是因为该状态的线程要等待任务的完成(IO,sleep),或是等待被唤醒(wait)。等待任务完成后被唤醒,进入就绪状态。当线程再次被分配时间片,就会重新进入运行状态。
参考文章:
[1],线程的5种状态详解
[2],类比 -高速缓存Cache/内存/磁盘读写速度类比
[3],DMA 和 零拷贝技术 到 网络大文件传输优化
[4],传统IO与零拷贝的几种实现
[5],并发编程三大特性——原子性、可见性、有序性
[6],原子操作的实现原理(锁和循环CAS)
[7],【JVM】从硬件层面和应用层面的有序性和可见性,到Java的volatile和synchronized
[8],聊聊CPU的LOCK指令
[9],lock指令底层是总线锁还是缓存锁
[10],汇编指令的LOCK指令前缀
[11],volatile与lock前缀指令
[12],【JVM】class文件格式,JVM加载class文件流程,JVM运行时内存区域,对象分配内存流程
[13],i++是否原子操作?并解释为什么?
[14],内置锁(ObjectMonitor)
[15],深入解析缓存一致性协议:MESI与MOESI
[16],【并发编程】MESI–CPU缓存一致性协议
