
阅读量:0
点一下关注吧!!!非常感谢!!持续更新!!!
目前已经更新到了:
- Hadoop(已更完)
- HDFS(已更完)
- MapReduce(已更完)
- Hive(已更完)
- Flume(已更完)
- Sqoop(已更完)
- Zookeeper(已更完)
- HBase(已更完)
- Redis (已更完)
- Kafka(正在更新…)
章节内容
上节我们完成了如下的内容:
- 消费者的基本流程
- 消费者的参数、参数补充

序列化器
由于Kafka中的数据都是字节数组,在将消息发送到Kafka之前需要将数据序列化成为字节数组。
序列化器作用就是用于序列化要发送的消息的。
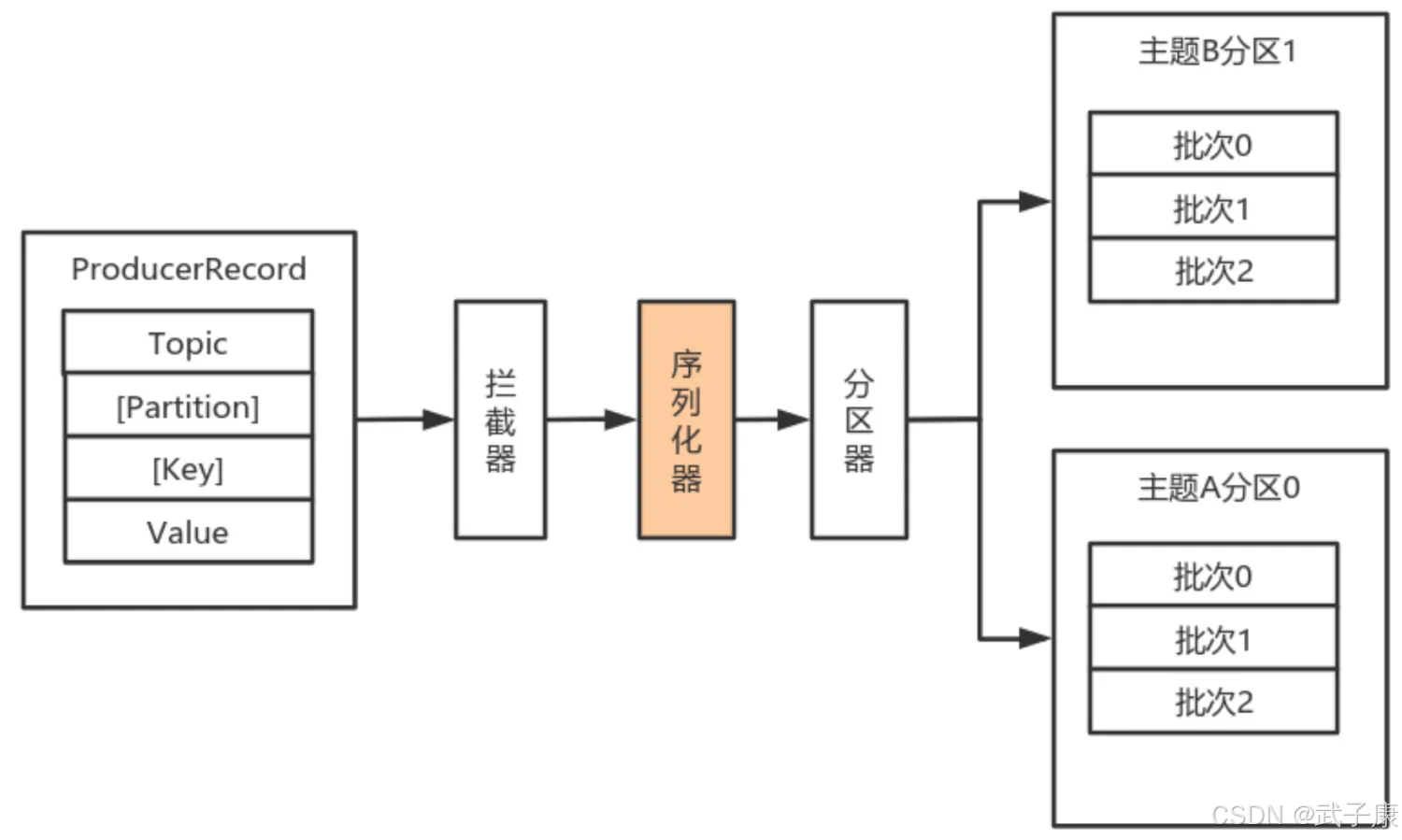
Kafka通过 org.apache.kafka.common.serialization.Serializer 接口用于定义序列化器,将泛型指定类型的数据转换为字节数据。
public interface Serializer<T> extends Closeable { /** * Configure this class. * @param configs configs in key/value pairs * @param isKey whether is for key or value */ default void configure(Map<String, ?> configs, boolean isKey) { // intentionally left blank } /** * Convert {@code data} into a byte array. * * @param topic topic associated with data * @param data typed data * @return serialized bytes */ byte[] serialize(String topic, T data); /** * Convert {@code data} into a byte array. * * @param topic topic associated with data * @param headers headers associated with the record * @param data typed data * @return serialized bytes */ default byte[] serialize(String topic, Headers headers, T data) { return serialize(topic, data); } /** * Close this serializer. * <p> * This method must be idempotent as it may be called multiple times. */ @Override default void close() { // intentionally left blank } } 其中Kafka也内置了一些实现好的序列化器:
- ByteArraySerializer
- StringSerializer
- DoubleSerializer
- 等等… 具体可以自行查看
自定义序列化器
自定义实体类
实现一个简单的类:
public class User { private String username; private String password; private Integer age; public String getUsername() { return username; } public void setUsername(String username) { this.username = username; } public String getPassword() { return password; } public void setPassword(String password) { this.password = password; } public Integer getAge() { return age; } public void setAge(Integer age) { this.age = age; } } 实现序列化
注意对象中的内容转换为字节数组的过程,要计算好开启的空间!!!
public class UserSerilazer implements Serializer<User> { @Override public void configure(Map<String, ?> configs, boolean isKey) { Serializer.super.configure(configs, isKey); } @Override public byte[] serialize(String topic, User data) { if (null == data) { return null; } int userId = data.getUserId(); String username = data.getUsername(); String password = data.getPassword(); int age = data.getAge(); int usernameLen = 0; byte[] usernameBytes; if (null != username) { usernameBytes = username.getBytes(StandardCharsets.UTF_8); usernameLen = usernameBytes.length; } else { usernameBytes = new byte[0]; } int passwordLen = 0; byte[] passwordBytes; if (null != password) { passwordBytes = password.getBytes(StandardCharsets.UTF_8); passwordLen = passwordBytes.length; } else { passwordBytes = new byte[0]; } ByteBuffer byteBuffer = ByteBuffer.allocate(4 + 4 + usernameLen + 4 + passwordLen + 4); byteBuffer.putInt(userId); byteBuffer.putInt(usernameLen); byteBuffer.put(usernameBytes); byteBuffer.putInt(passwordLen); byteBuffer.put(passwordBytes); byteBuffer.putInt(age); return byteBuffer.array(); } @Override public byte[] serialize(String topic, Headers headers, User data) { return Serializer.super.serialize(topic, headers, data); } @Override public void close() { Serializer.super.close(); } } 分区器
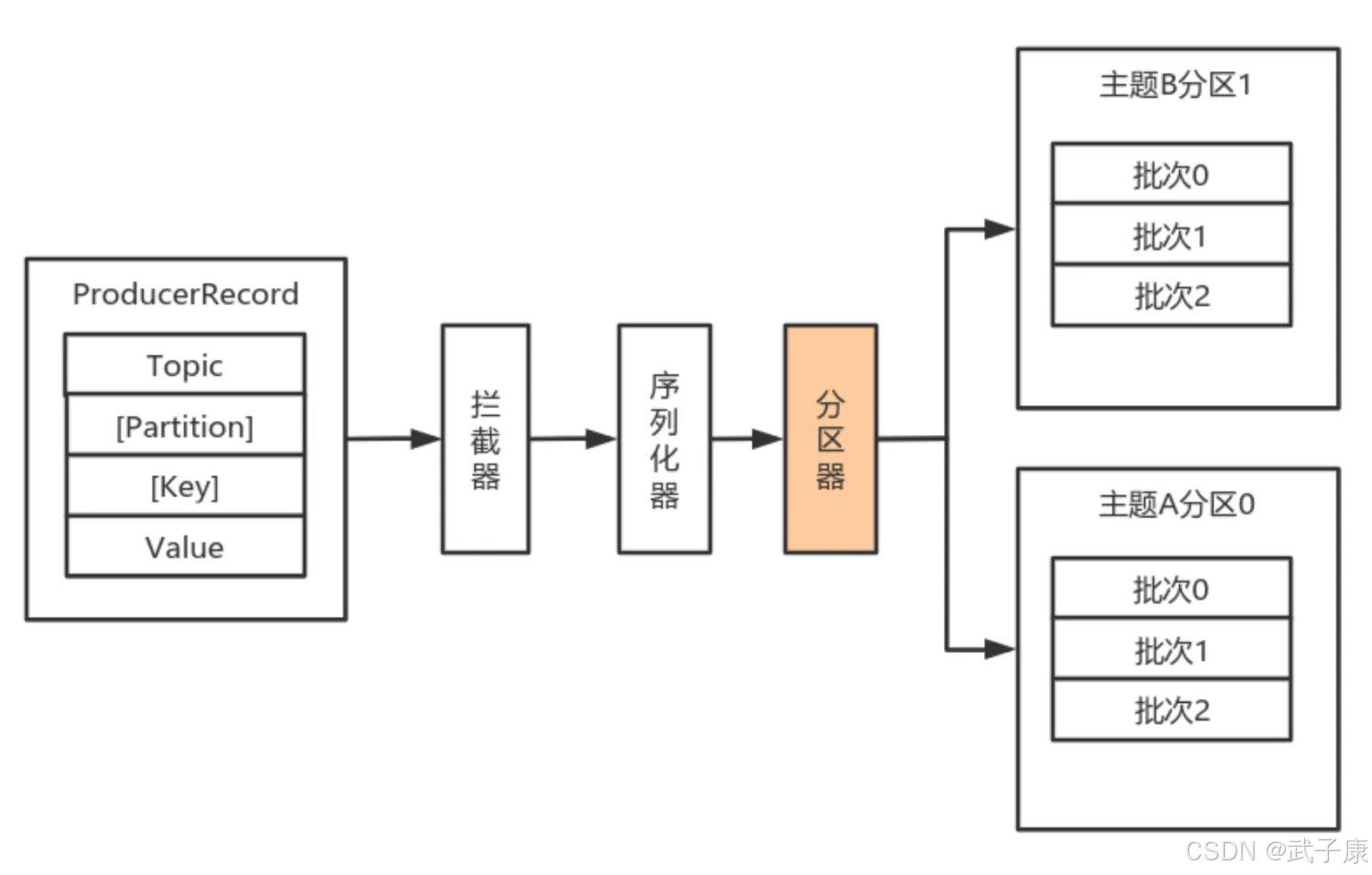
默认情况下的分区计算:
- 如果Record提供了分区号,则使用Record提供的分区号
- 如果Record没有提供分区号,则使用Key序列化后值的Hash值对分区数取模
- 如果Record没有提供分区号,也没有提供Key,则使用轮询的方式分配分区号
我们在这里可以看到对应的内容:
org.apache.kafka.clients.producer 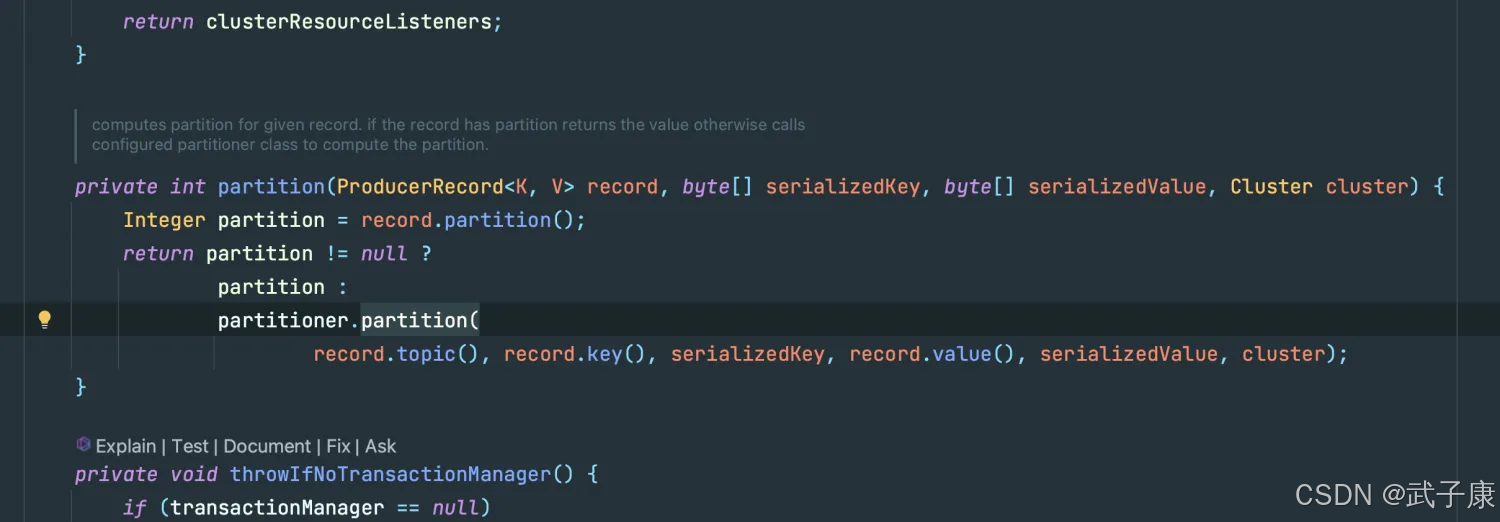
可以看到,如果 Partition 是 null的话,会有函数来进行分区,跟进去,可以看到如下方法: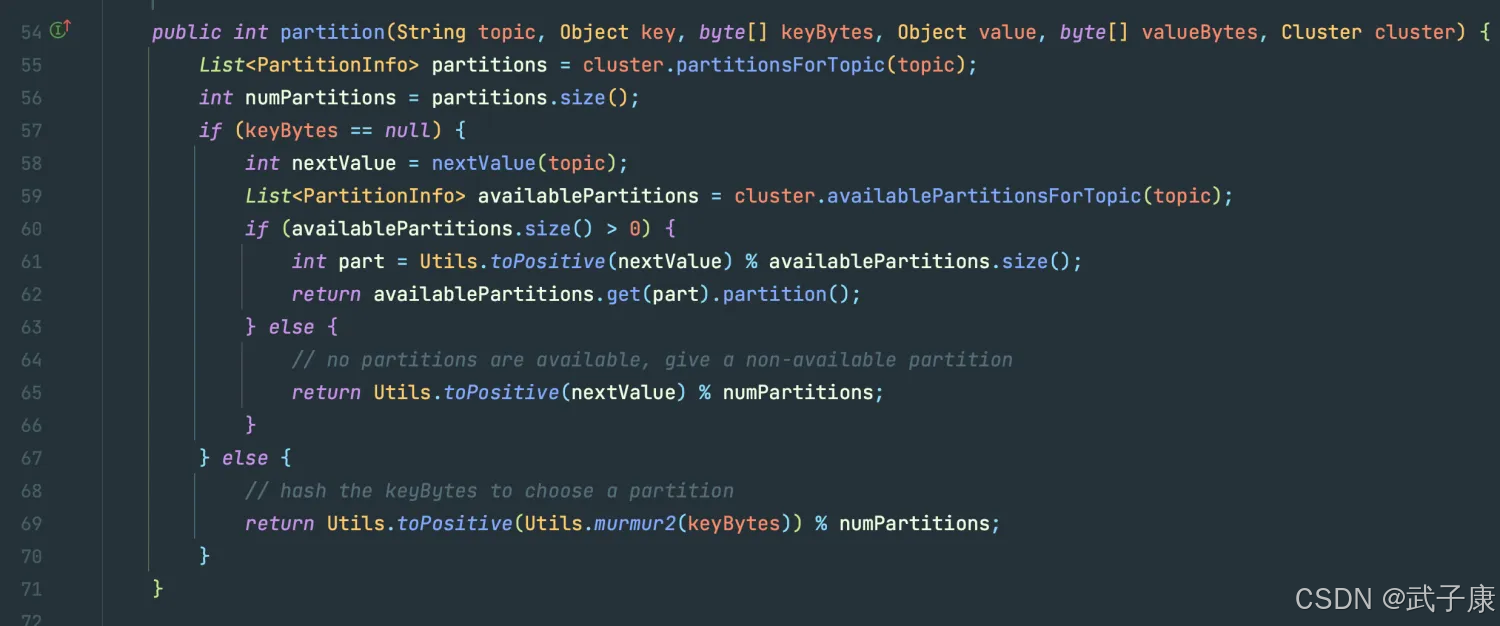
自定义分区器
如果要自定义分区器, 需要:
- 首先开发Partitioner接口中的实现类
- 在KafkaProducer中进行设置:configs.put(“partitioner.class”, “xxx.xxx.xxx.class”)
public class MyPartitioner implements Partitioner { @Override public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { return 0; } @Override public void close() { } @Override public void configure(Map<String, ?> configs) { } } 