
阅读量:0
01 成本的构成
数据中台的成本主要包括硬件成本、软件成本、人力成本以及运营成本等几个方面。硬件成本包括购置服务器、存储设备等所需费用;软件成本涉及到购买和使用数据中台软件所需费用;人力成本包括数据中台项目的开发、运维以及管理等环节所需的人力投入;运营成本则包括数据中台日常运营过程中产生的费用,如电力、场地租赁等。
我们先来看一个例子:
某电商业务数据建设资源增长趋势
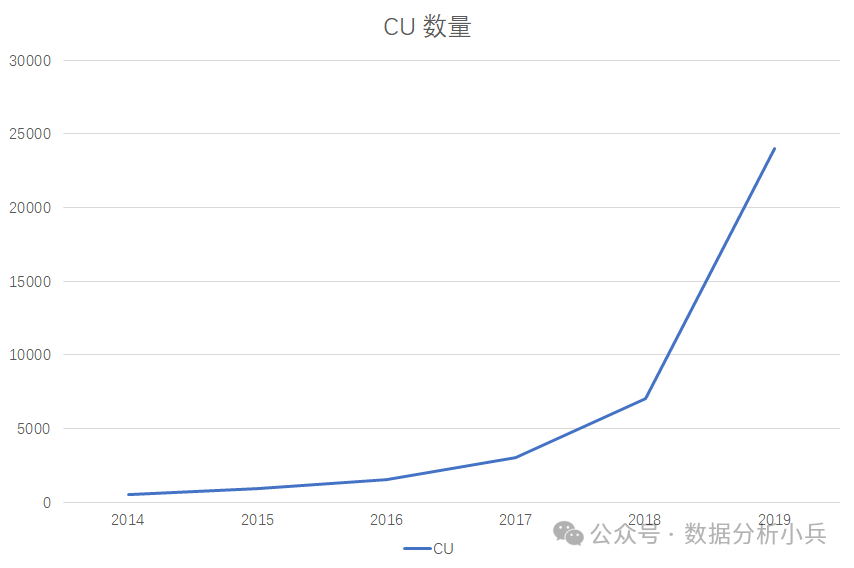
注:CU= 1vcpu + 4G memory
上图展示了某电商平台的大数据资源消耗增长趋势,需要关注的是,到了 2019 年,全年的资源规模已经达到了 25000CU,全年机器预算达到了 3500W。这样的开支势必会引起高层领导的关注,终于有一天,CEO 问了数据团队的负责人小帅两个问题,直接将小帅问懵了:
-
这 3500W 花在什么业务上?
-
你们做了哪些成本优化的举措,效果如何?
正常来说,数据中台的成本,是按照人力,物力,按照机器数量和电费来算的,不是按照数据应用来算的,所以上面例子中的小帅回答不出来。但是CEO会关注,因为一个公司的资源都是有限的,所以他必须确保这些资源应用在公司的核心战略的关键节点上(公司核心KPI相关的业务上)。数据中台刚好又是一个高消耗支撑部门,所以如果想展现自己的价值,至少要做到两方面:
1.支撑好业务,获得业务部门的认可;
2.资源分配要有策略,重点满足核心业务;
3.精简架构,控制成本,为公司省钱。
02 成本陷阱
想要做到精细化的成本管理,首先得清楚哪些“陷阱”造成了成本的增加和浪费,避开这些坑才能有效降低成本。
2.1 数据上线容易,下线难
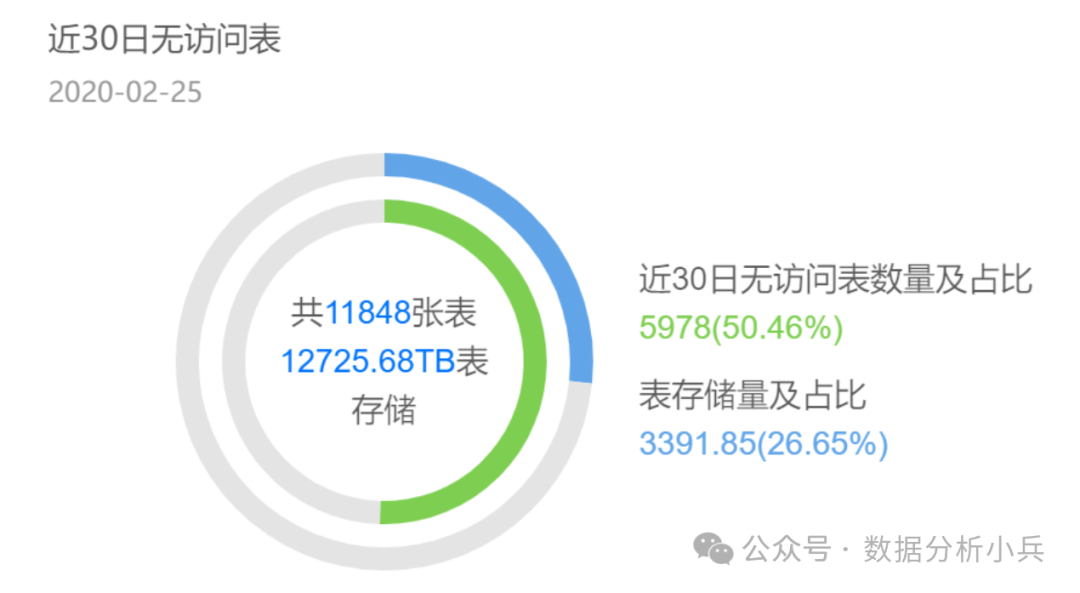
某数据中台项目,一半的表30天内都没有访问,而这些表占26%存储,换算成服务器需125台,成本一年近500W。对于这些无法及时清理或下线的报表,数据开发并不知道有哪些任务在引用,有哪些人在查询,因此,开发不敢也不能直接停止这个表的数据加工。此时,需要数据产品经理或运维人员进行梳理和统计,提供报表使用情况的说明,针对“无人问津”的报表,进行下线处理。
2.2 数据上线容易,下线难
有个宽表(拥有很多列的表),加上上游加工链路的任务,每天加工这张宽表要消耗6000块钱,一年200W,而实际这张宽表实际每天只有一个运营的实习生在使用。显然,投入和产出极不匹配。
2.3 烟囱式的开发模式
烟囱式的开发模式,重复造轮子本就是数据中台需要解决的核心问题,不仅研发效率低,还浪费资源。一张500T表,加工+计算+存储一年要消耗40W,而其每复用一次就相当于节省了40W,真正的降本增效。
2.4 缺少数据的生命周期管理
通常原始数据会进行长期且完整的存储,而在汇总层、集市层或者应用层,考虑到存储成本,数据建议按照生命周期来管理,通常保留几天的快照或者分区。如果存在大表没有设置生命周期,就会浪费存储资源。
2.5 调度周期不合理
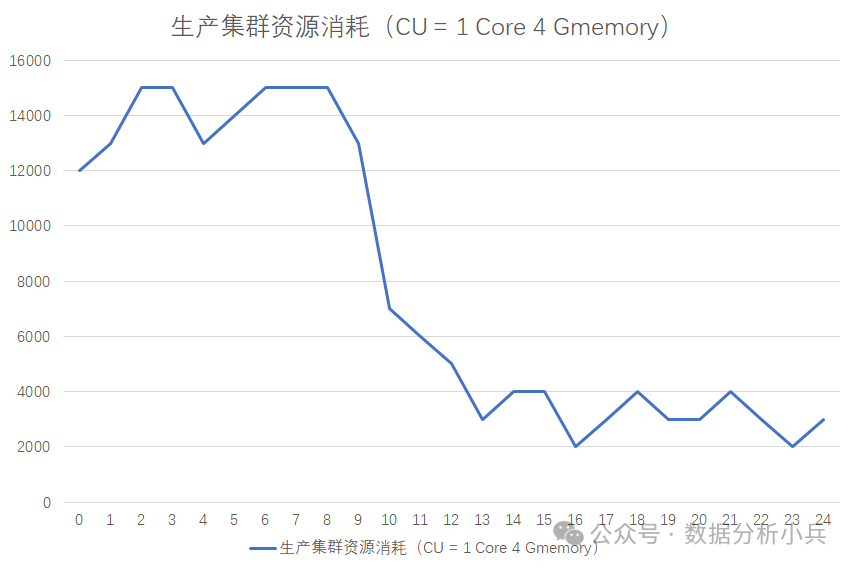
通过上图可以看到,大数据任务的资源消耗有很明显的高峰和低谷效应,一般晚上12点到第二天的9点是高峰期,9点到晚上12点,是低谷期。整个集群的资源配置取决于高峰期的任务消耗。将一些不必要在高峰期内运行任务进行错峰部署,可以降低整个集群的规模,从而降低硬件投入成本。
2.6 数据未压缩
Hadoop 的HDFS 为了实现高可用,默认数据存储3副本,所以大数据的物理存储量消耗是比较大的。尤其是对于一些原始数据层和明细数据层的大表,动辄500多T,折合物理存储需要1.5P(三副本),大约需要16台物理服务器,如果不启用压缩,存储资源成本会很高。
03 精细化成本管理
了解了上述成本陷阱,我们来看一下如何针对问题进行精细化的成本管理。
成本管理应遵循全局盘点、发现问题、治理优化和效果评估四步:
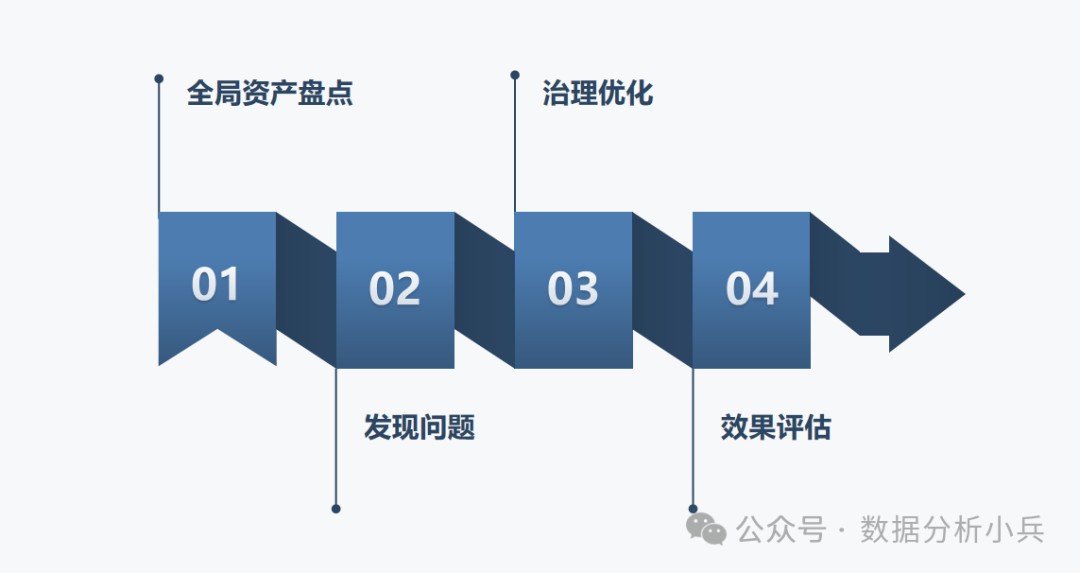
3.1 全局资产盘点
对数据中台所有数据的全面盘点,是精细化成本管控的第一步。
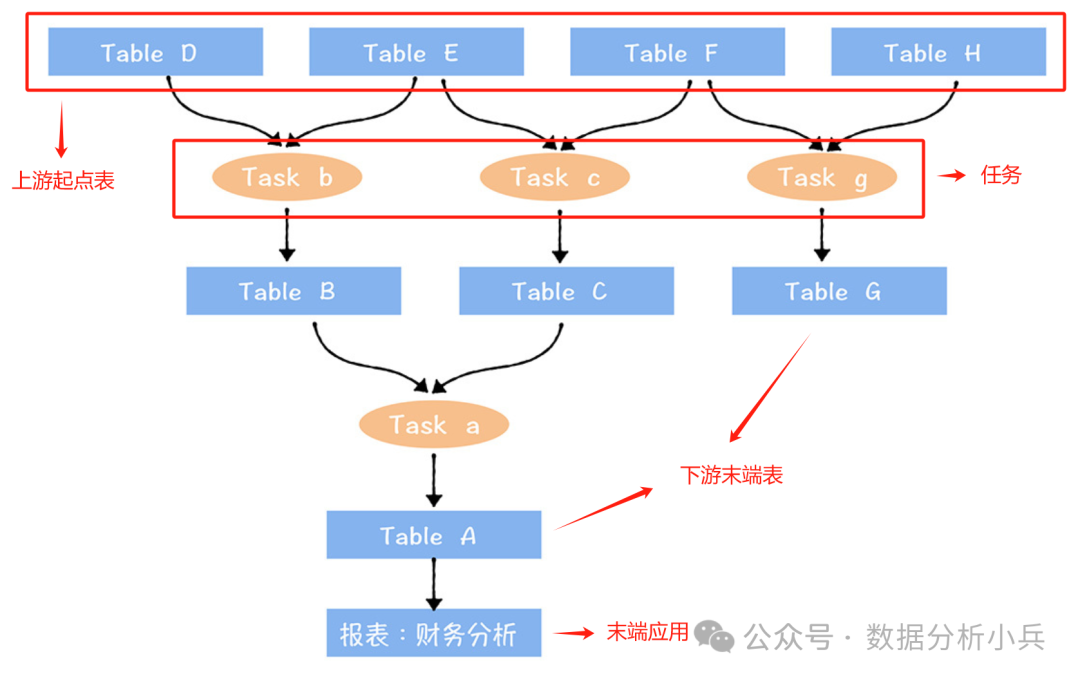
以上图为例,计算全链路数据资产视图中,未端数据的成本和价值(图中TableA,Table G)为什么一定要从未端开始? 因为中间数据在计算价值时,还要考虑下游表被使用的情况,较难计算清楚,所以从未端数据开始。这与下线表的顺序也一致,如数据的价值很低,成本很高,也从未端数据开始下线。
数据成本核算
报表上游链路中涉及:
-
【3个任务】a,b,c
-
【6张表】A,B,C,D,E,F
那么,这张报表的成本计算如下:
表成本=3个任务加工消耗的计算资源成本+6张表消耗的存储资源的成本
需要注意的是,如果一个表被多个下游应用复用,那么这个表的存储以及计算成本,需要分摊给多个应用。
数据价值核算
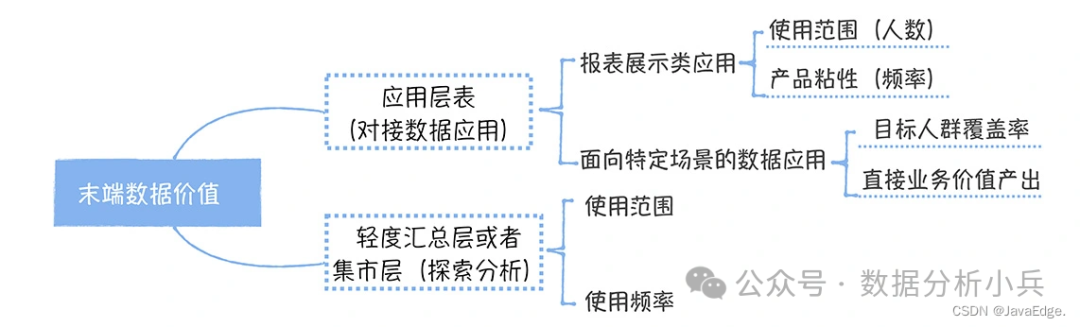
场景一:
如果末端数据是一张应用层的表,它对接的是一张数据报表,那么衡量这个数据的价值,主要是看报表的使用范围和使用频率。在计算使用范围时,通常使用周粒度,同时考虑不同管理层级的权重。
-
管理级别越高,做出的商业决策影响就越大,诸如老板等管理人员,应赋予更高的权重。
-
使用频率一般使用单个用户每周查看报表的次数来衡量,指标数值越高,证明报表使用频次高,报表价值越大。
如果末端数据对接的不是一个数据报表,而是面向特定场景的数据应用。衡量此类报表的价值,主要考虑目标人群的覆盖率和直接业务价值产出。
场景二:
末端数据还可能是一张集市层的表,它主要提供给分析师用于探索式查询。这类表的价值主要看它被哪些分析师使用,使用频率如何。同样,在使用范围评估时,要对分析师按照级别加权。
3.2 发现问题
全局盘点为发现问题提供数据支撑,需关注以下三类问题:
-
持续产生成本,但已没有使用的末端数据(一般指30天内无访问)没有使用,但一直在消耗成本的表,对应的就是我提到的陷阱1
-
数据应用价值很低,成本却很高,这些数据应用上游链路上的所有相关数据低价值产出,高成本的数据应用,对应的是陷阱2
-
高峰期高消耗的数据、高成本的数据,对应陷阱3~6
3.3 治理优化
针对发现的三类问题,我们制定相应的治理优化策略:
第一类问题,参考下图,将对应表进行下线操作。
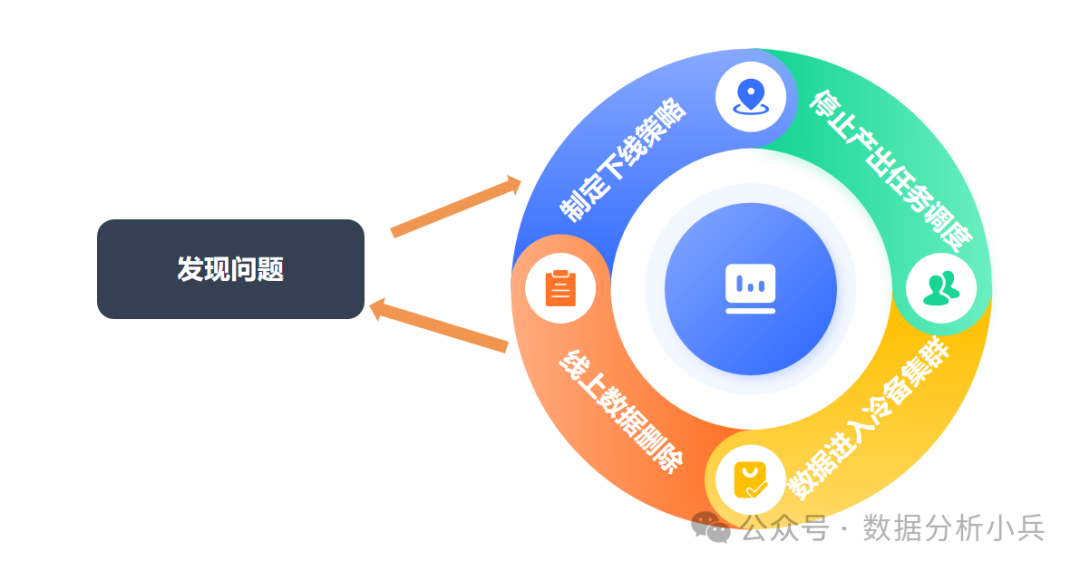
未端数据删除后,原先未端数据的上游数据会成为新的未端数据,同样还要按发现问题到治理优化进行重复,直到所有的未端数据都不满足下线策略为止。
第二类问题,我们需要评估应用是否还有存在的必要。对于报表,可以按照30天内没有访问的应用自动下线的策略,先对报表进行销毁,然后对报表上游的表进行下线,如果该表还被其他的应用引用,就不能下线。下线步骤可以参考前面的下线步骤。
第三类问题,主要是针对高消耗的数据,又具体分为产出数据的任务高消耗和数据存储高消耗。
产出任务高消耗:
-
首先要考虑是不是数据倾斜。具体怎么判断呢?其实你可以通过MR或者Spark日志中,Shufer的数据量进行判断。如果有某一个Task 数据量非常大,其他的很少,就可以判定出现了数据倾斜。
-
其次,判断是否有高峰期高消耗的数据,可根据重要程度将一些高消耗任务分配到非高峰期运行。
数据存储高消耗:
-
首先,要考虑是否可以进行数据压缩,建议对原始数据层和明细数据层进行压缩。
-
其次,要考虑生命周期是否设置,通常底层表都是长期保留,关注重点应是汇总层以上的表(包括汇总层),一般可根据数据的重要性,制定7天,1个月保留策略。
3.4 效果评估
效果评估的核心原则:为公司省了多少钱。
如果直接用减少服务器的数量来衡量,其实并不能真实地反映治理效果,因为未考虑业务增长等其他情况。因此,我们需要具体围绕优化任务数量背后的数据和资源成本考虑:
-
下线了多少任务和数据?
-
这些任务每日消耗了多少计算资源?
-
数据占用了多少存储空间?
拿这些资源来计算成本才比较客观和真实。
04 总结
要做好数据中台的成本管控,我们建议从常见成本陷阱入手,分析可能造成成本浪费的原因,然后针对问题原因,制定精细化成本管理的办法最后强调:
-
无用数据的下线应该从全链路数据资产视图的末端入手,然后抽丝剥茧,一层一层,向数据加工链路的上游推进。
-
应用层表的价值应该以数据应用的价值来衡量,对于低价值产出的应用,应该以应用为粒度进行下线。
-
对高消耗任务的优化只要关注集群高峰期的任务,项目的整体资源消耗只取决于高峰期的任务消耗,当然,如果你使用的是公有云的资源,可以高峰和低谷实施差异化的成本结算,那低谷期的也是要关注的。
