
阅读量:0
目录
前言
在当今快速发展的人工智能领域,高性能计算平台的重要性不言而喻。国家超算互联网平台作为其中的重要一环,不仅提供了强大的计算资源,还通过其丰富的模型服务和便捷的操作体验,吸引了众多技术爱好者和专业人士的关注。本文将深入探讨该平台的显卡选用、模型服务体验以及本地模型推理体验,带您全方位了解这一前沿技术平台。
一、平台显卡选用
在进行深度学习和大规模数据处理时,显卡的选择至关重要。国家超算互联网平台提供了多种显卡选项,以满足不同用户的需求。
地址:https://www.scnet.cn/ui/mall/search/goods?common1=RESOURCE&common2=RESOURCE-AI
1、显卡选择
由于1分钱的显卡被抢占完了,我们选择了“NVIDIA L20 显存48GB PCIE”,这款显卡以其强大的计算能力和充足的显存,能够轻松应对复杂的模型训练和数据处理任务。(由于显卡是按小时收费,非常方便,不用的时候关机即可)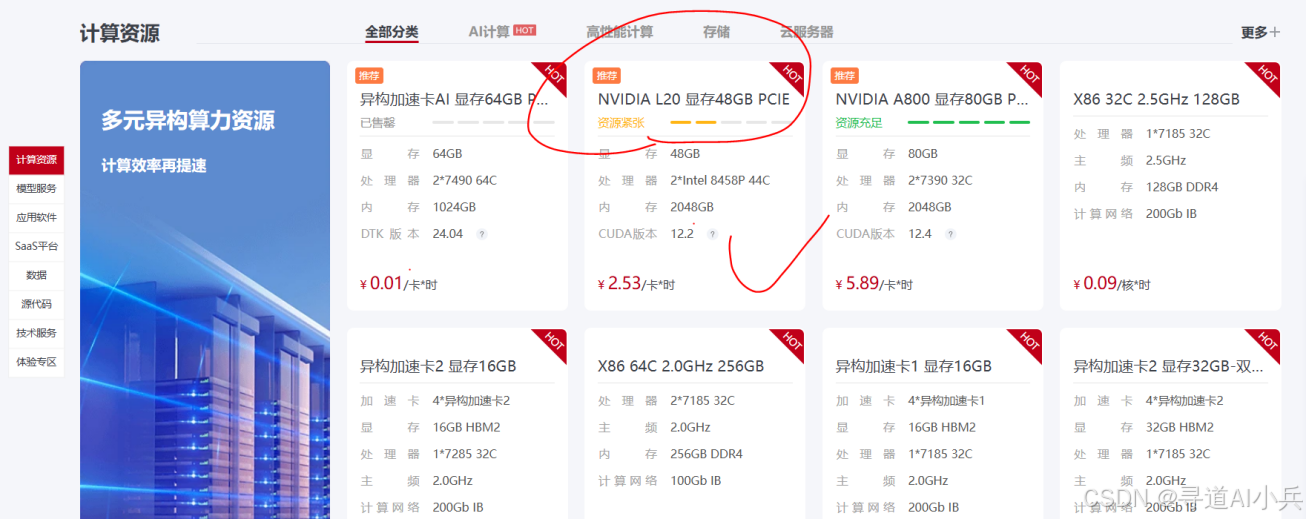
2、镜像选择
在显卡选择完成后,用户可以根据自己的需求选择基础镜像或平台提供的免费模型镜像。本次体验中,我们选择了“jupyterlab-stable-diffusion-normal-webui”镜像,它为用户带来了便捷的模型部署和运行体验。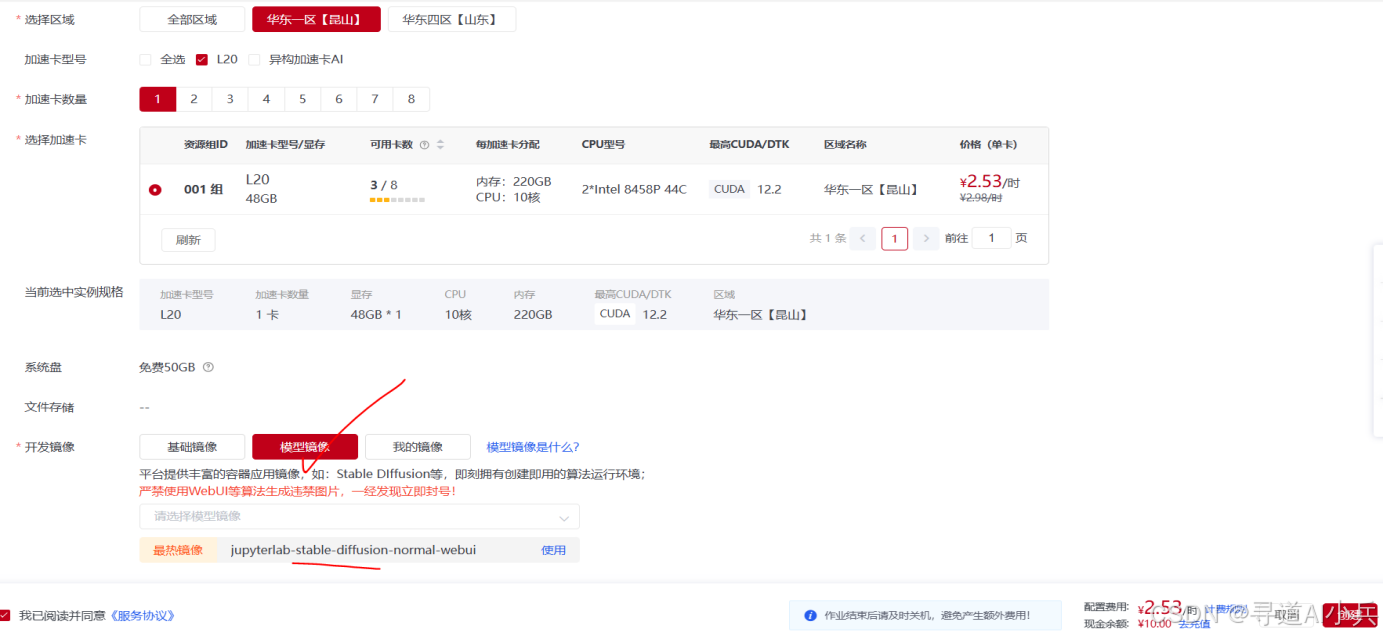
3、实例列表
选择完服务器和镜像后,选择完服务器和镜像后,用户将被引导至实例列表,这里可以查看和管理所有创建的实例。
4、登录服务器
通过点击服务列表中的“JupyterLab”,用户可以自动登录服务器,开始模型的部署和运行。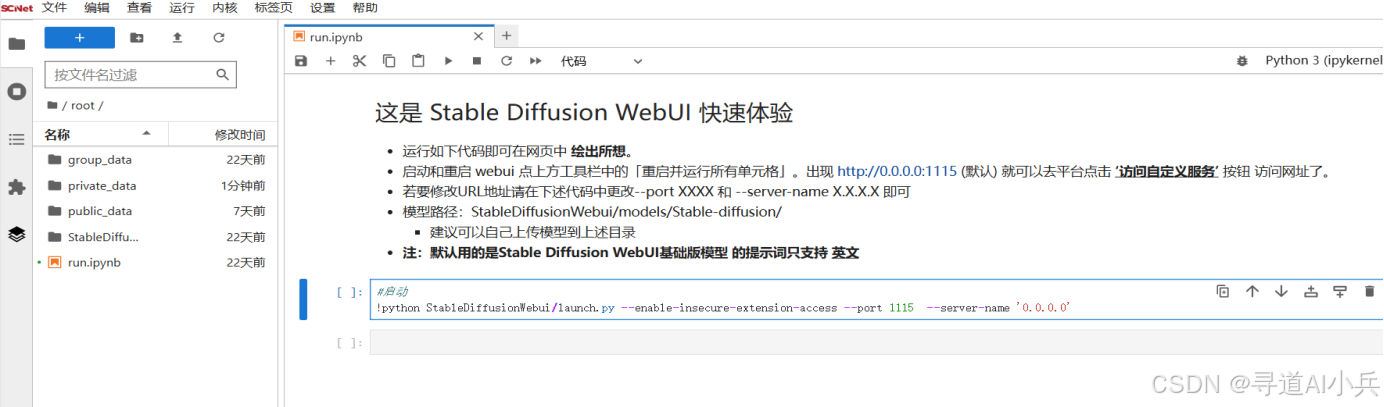
二、平台模型服务【Stable Diffusion WebUI】体验
登录服务器后,会自动打开run.ipynb文件;可进行Stable Diffusion WebUI 快速体验
1、模型运行
在JupyterLab中,用户可以直接执行以下代码来启动Stable Diffusion WebUI:
#启动 !python StableDiffusionWebui/launch.py --enable-insecure-extension-access --port 1115 --server-name '0.0.0.0' 代码执行如下: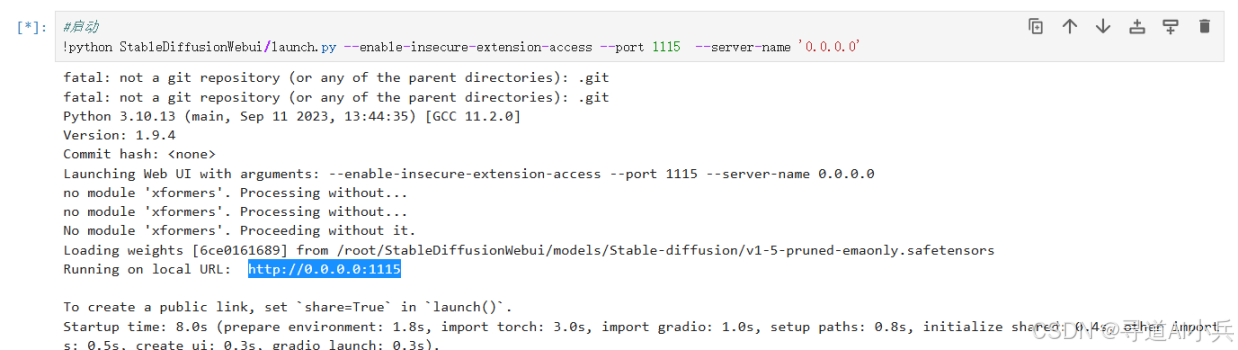
执行后,本地访问地址为:http://0.0.0.0:1115,用户可以通过此地址访问和体验模型。
2、端口映射配置
通过实例列表中的“访问自定义服务”设置端口映射,填入端口1115,用户便可以访问模型的Web界面。
配置映射端口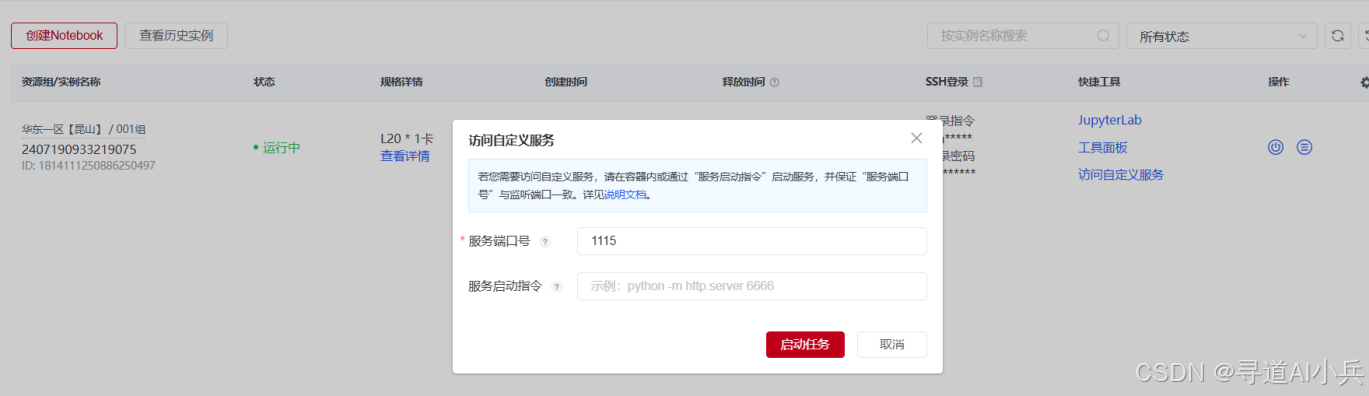
3、体验测试
模型运行后UI界面访问如下: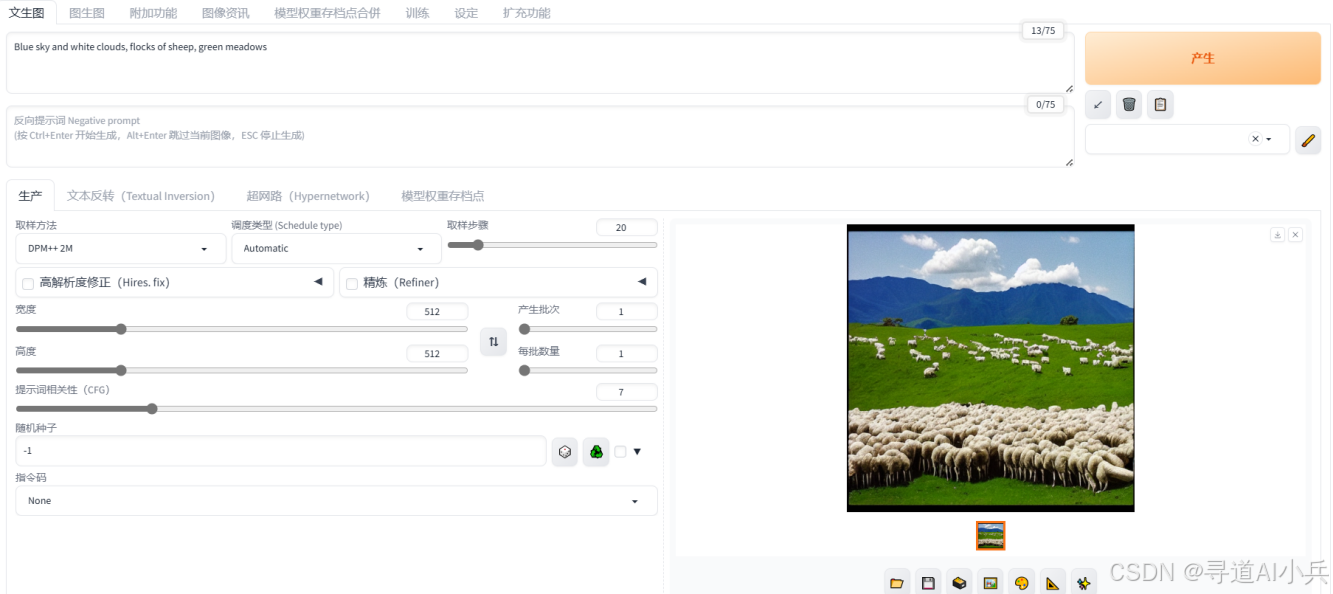
1)平台提供的模型镜像,整个启动运行过程快、非常便捷,几分钟内就能体验模型效果
2)模型运行效果很快,基本上都在2秒左右就能生成结果
3)模型效果测试也还不错,除了画质不是很好,生成的结果和提示词预期基本相符
三、本地模型【Qwen1.5-7B-Chat】推理体验
国家超算互联网平台不仅提供了模型镜像服务,还支持本地模型的推理体验。用户可以直接使用平台公共区域已经下载好的模型;或者自行下载模型,进行本地推理;平台公共区域“/root/public_data/llm_model”提供有多个开源模型。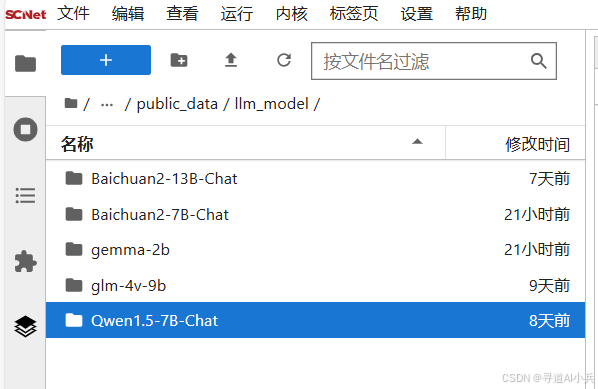
1、安装依赖
首先,用户需要安装必要的依赖库,如modelscope:
#安装modelscope !pip install modelscope 2、加载模型
接下来,加载本地的语言模型和分词器:
# 导入所需的库和模块 from modelscope import AutoModelForCausalLM, AutoTokenizer # 设置设备为GPU(如果有的话) device = "cuda" # the device to load the model onto # 从预训练模型中加载大型语言模型 model = AutoModelForCausalLM.from_pretrained( "/root/public_data/llm_model/Qwen1.5-7B-Chat", device_map="auto" ) # 从预训练模型中加载相应的分词器 tokenizer = AutoTokenizer.from_pretrained("/root/public_data/llm_model/Qwen1.5-7B-Chat") 需要注意的是,如果遇到模型加载报错如下,可能需要升级Transformer版本:
---------------------------------------------------------------------------KeyError Traceback (most recent call last) Cell In[5], line 4 1 from modelscope import AutoModelForCausalLM, AutoTokenizer 2 device = "cuda" # the device to load the model onto----> 4 model = AutoModelForCausalLM.from_pretrained( 5 "/root/public_data/llm_model/Qwen1.5-7B-Chat", 6 device_map="auto" 7 ) 8 tokenizer = AutoTokenizer.from_pretrained("/root/public_data/llm_model/Qwen1.5-7B-Chat") File /opt/conda/lib/python3.10/site-packages/modelscope/utils/hf_util.py:113, in get_wrapped_class.<locals>.ClassWrapper.from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs) 110 else: 111 model_dir = pretrained_model_name_or_path--> 113 module_obj = module_class.from_pretrained(model_dir, *model_args, 114 **kwargs) 116 if module_class.__name__.startswith('AutoModel'): 117 module_obj.model_dir = model_dir File /opt/conda/lib/python3.10/site-packages/transformers/models/auto/auto_factory.py:456, in _BaseAutoModelClass.from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs) 453 if kwargs.get("torch_dtype", None) == "auto": 454 _ = kwargs.pop("torch_dtype")--> 456 config, kwargs = AutoConfig.from_pretrained( 457 pretrained_model_name_or_path, 458 return_unused_kwargs=True, 459 trust_remote_code=trust_remote_code, 460 **hub_kwargs, 461 **kwargs, 462 ) 464 # if torch_dtype=auto was passed here, ensure to pass it on 465 if kwargs_orig.get("torch_dtype", None) == "auto": File /opt/conda/lib/python3.10/site-packages/transformers/models/auto/configuration_auto.py:957, in AutoConfig.from_pretrained(cls, pretrained_model_name_or_path, **kwargs) 955 return config_class.from_pretrained(pretrained_model_name_or_path, **kwargs) 956 elif "model_type" in config_dict:--> 957 config_class = CONFIG_MAPPING[config_dict["model_type"]] 958 return config_class.from_dict(config_dict, **unused_kwargs) 959 else: 960 # Fallback: use pattern matching on the string. 961 # We go from longer names to shorter names to catch roberta before bert (for instance) File /opt/conda/lib/python3.10/site-packages/transformers/models/auto/configuration_auto.py:671, in _LazyConfigMapping.__getitem__(self, key) 669 return self._extra_content[key] 670 if key not in self._mapping:--> 671 raise KeyError(key) 672 value = self._mapping[key] 673 module_name = model_type_to_module_name(key) KeyError: 'qwen2' 主要是Transformer版本过低,需要升级版本
!pip install -U transformers 重新加载模型,加载成功效果如下:

3、定义提示消息
定义一个简短的介绍大型语言模型的提示,并构建消息列表:
# 定义一个简短的介绍大型语言模型的提示 prompt = "Give me a short introduction to large language model." # 构建消息列表,包括系统角色和用户角色的内容 messages = [ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": prompt} ] 4、获取model_inputs
使用分词器将消息列表转换为model_inputs:
# 使用分词器将消息列表转换为适合模型输入的格式 text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True ) # 将文本转换为模型输入张量并移动到指定设备上 model_inputs = tokenizer([text], return_tensors="pt").to(device) model_inputs 输出:
5、生成模型输出
根据模型输入的inputs生成模型输出的generated_ids
# 生成模型输出 generated_ids = model.generate( model_inputs.input_ids, max_new_tokens=512 ) # 提取生成的ID,去除输入部分 generated_ids = [ output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids) ] generated_ids 输出: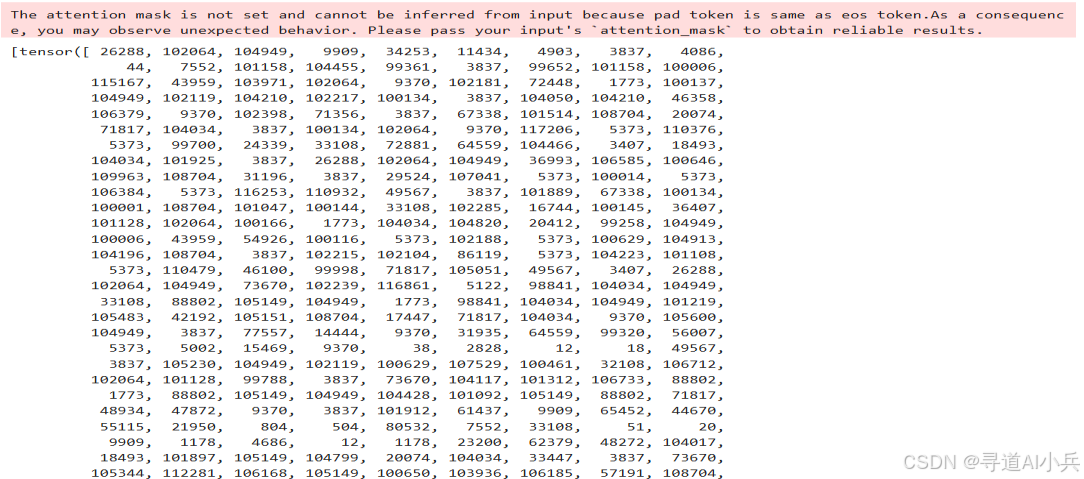
6、获取生成结果
对生成的generated_ids,进行解码获取响应结果
# 解码生成的ID为文本,并跳过特殊标记 response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] # 打印生成的响应 print(response) 输出:
大语言模型(Large Language Model,LLM)是一种人工智能技术,它是一种能够理解和生成人类语言的复杂系统。这种模型通常基于深度学习,特别是基于Transformer架构的神经网络,通过大量的文本数据进行训练,学习语言的语法、词汇、句法和语义规律。 在训练过程中,大语言模型会接收各种类型的文本输入,如书籍、新闻、网页、社交媒体帖子等,然后通过学习这些文本中的模式和上下文关系来理解语言结构。训练的目标是让模型能够生成连贯、准确、具有逻辑性的文本,无论是回答问题、创作故事、撰写代码还是进行对话等。 大语言模型可以分为两类:预训练模型和任务特定模型。预训练模型是在大规模无标签文本上进行训练的通用模型,例如Google的通义千问、OpenAI的GPT-3等,这类模型通常具有较高的泛化能力和语言理解能力,可以适应多种下游任务。任务特定模型则是针对特定任务进行微调的,比如BERT(Bidirectional Encoder Representations from Transformers)和T5(Text-to-Text Transfer Transformer),它们在经过特定领域的数据训练后,可以更好地服务于某个特定领域的问题解答或文本生成。 大语言模型的发展对于自然语言处理、人工智能、机器翻译等领域有着深远的影响,它正在逐步改变我们与计算机交互的方式,并且在不断推动技术进步。然而,也需要注意的是,虽然大语言模型在很多方面表现出色,但它并不完美,有时可能会出现偏见或误解,需要持续优化和完善。 结语
国家超算互联网平台以其高效计算能力和用户友好的操作体验,为人工智能领域的研究和应用提供了强有力的支持。通过本文的体验和技术解析,我们见证了该平台如何简化模型部署和推理过程,加速了从理论到实践的转变。随着技术的不断进步,该平台有望进一步推动科研创新和产业发展,为人工智能的未来探索提供更多可能性。同时,我们也期待平台能够持续优化,满足日益增长的计算需求,助力构建一个更加智能化的世界。

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:我是寻道AI小兵,资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索。
📖 技术交流:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,加入技术交流群,开启编程探索之旅。
💘精心准备📚500本编程经典书籍、💎AI专业教程,以及高效AI工具。等你加入,与我们一同成长,共铸辉煌未来。
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!
