
1. 背景介绍
在之前分享的文章《基于开源大模型的问答系统本地部署实战教程》中,我们介绍了基于ollama实现本地问答系统的部署和使用。本文将基于ollama进一步实现本地垂直领域的问答系统搭建。ollama作为大模型的运行框架,可以提供大模型的使用接口,方便其他应用调用。
本文将利用AnythingLLM来实现隐私计算垂直领域的知识问答。本次分享一下搭建的过程,以及初步的体验,但如果想追求好的问答效果,还是需要好好准备高质量知识库,这个是起决定作用的因素。
我们采用docker的方式安装AnythingLLM。AnythingLLM是一款文档聊天机器人解决方案,能够将任何文档、资源或内容片段转化为大语言模型在聊天中可以利用的相关上下文。
2. 部署步骤
2.1 ollama准备大模型参数文件及模型加载
首先,通过ollama下载相应的本地模型,为了便于尝试不同大模型的效果,可以在ollama的models列表中下载多个模型。前几天看到google开源了Gemma 2B的文章,介绍了端侧小模型的进展,没想到ollama上就已经可以下载使用了,借着这次机会也体验一下。
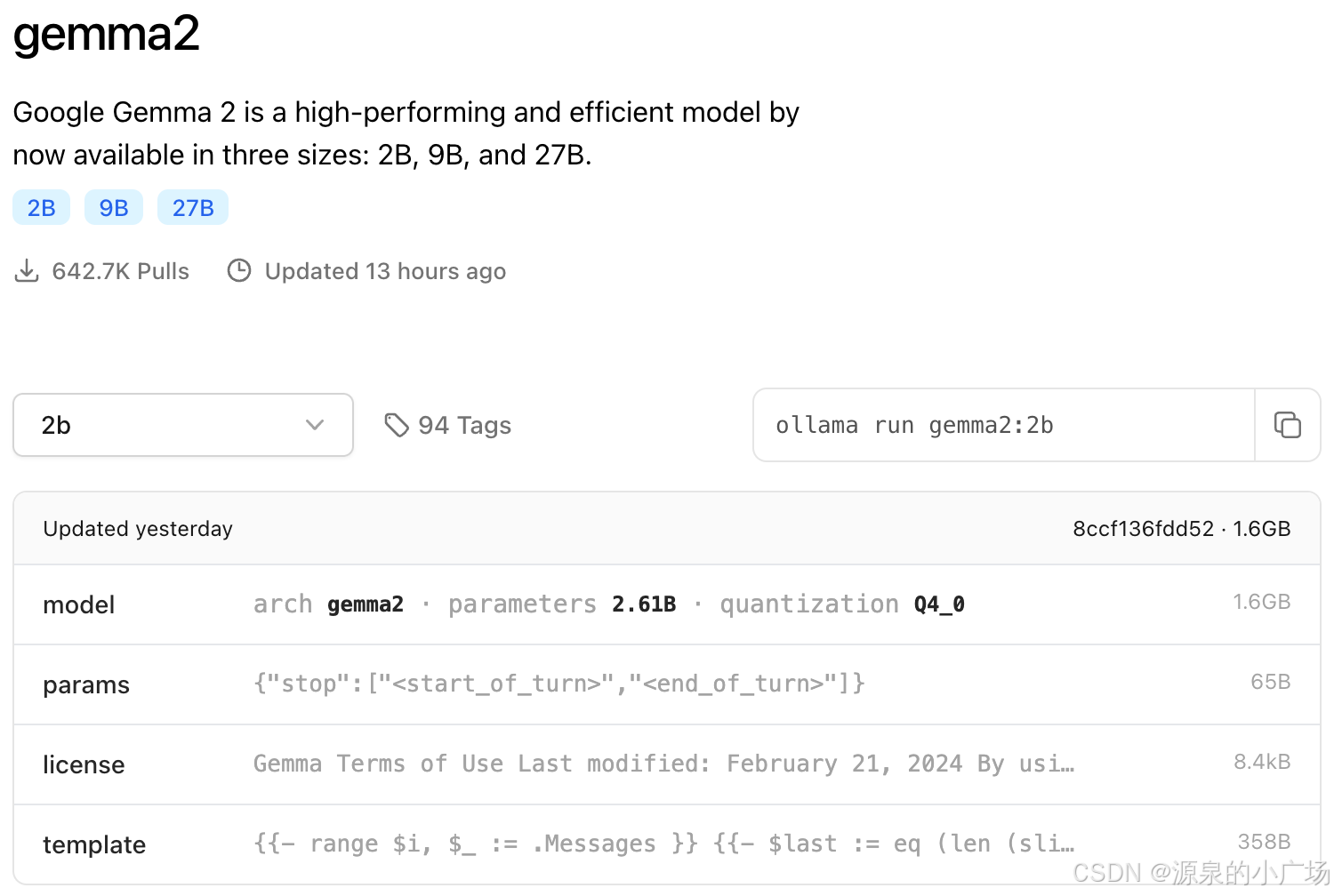
ollama 服务启动指令:
ollama serve
启动之后,后续AnythingLLM就可以使用ollama提供的接口能力。
2.2 docker安装AnythingLLM
1. 拉取镜像(执行需要点时间)
docker pull mintplexlabs/anythingllm
2. docker运行镜像(Linux/MacOs系统,根据实际情况可修改端口等信息)
其他的平台可以参考这里
export STORAGE_LOCATION=$HOME/anythingllm && \ mkdir -p $STORAGE_LOCATION && \ touch "$STORAGE_LOCATION/.env" && \ docker run -d -p 4001:3001 \ --cap-add SYS_ADMIN \ -v ${STORAGE_LOCATION}:/app/server/storage \ -v ${STORAGE_LOCATION}/.env:/app/server/.env \ -e STORAGE_DIR="/app/server/storage" \ mintplexlabs/anythingllm 3. docker管理平台
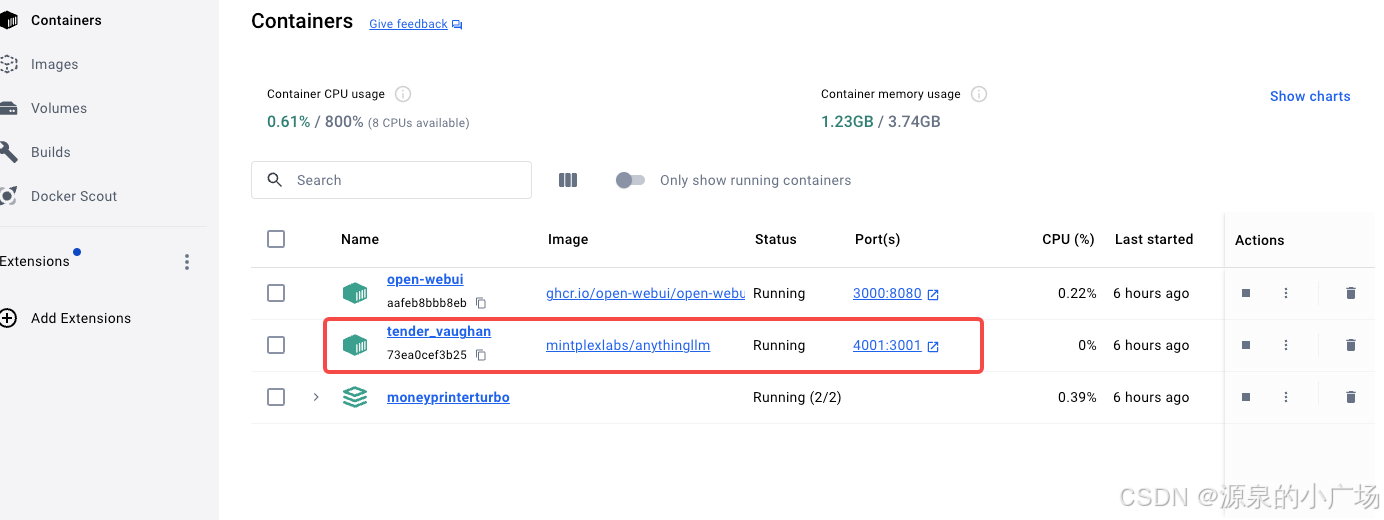
4.web访问
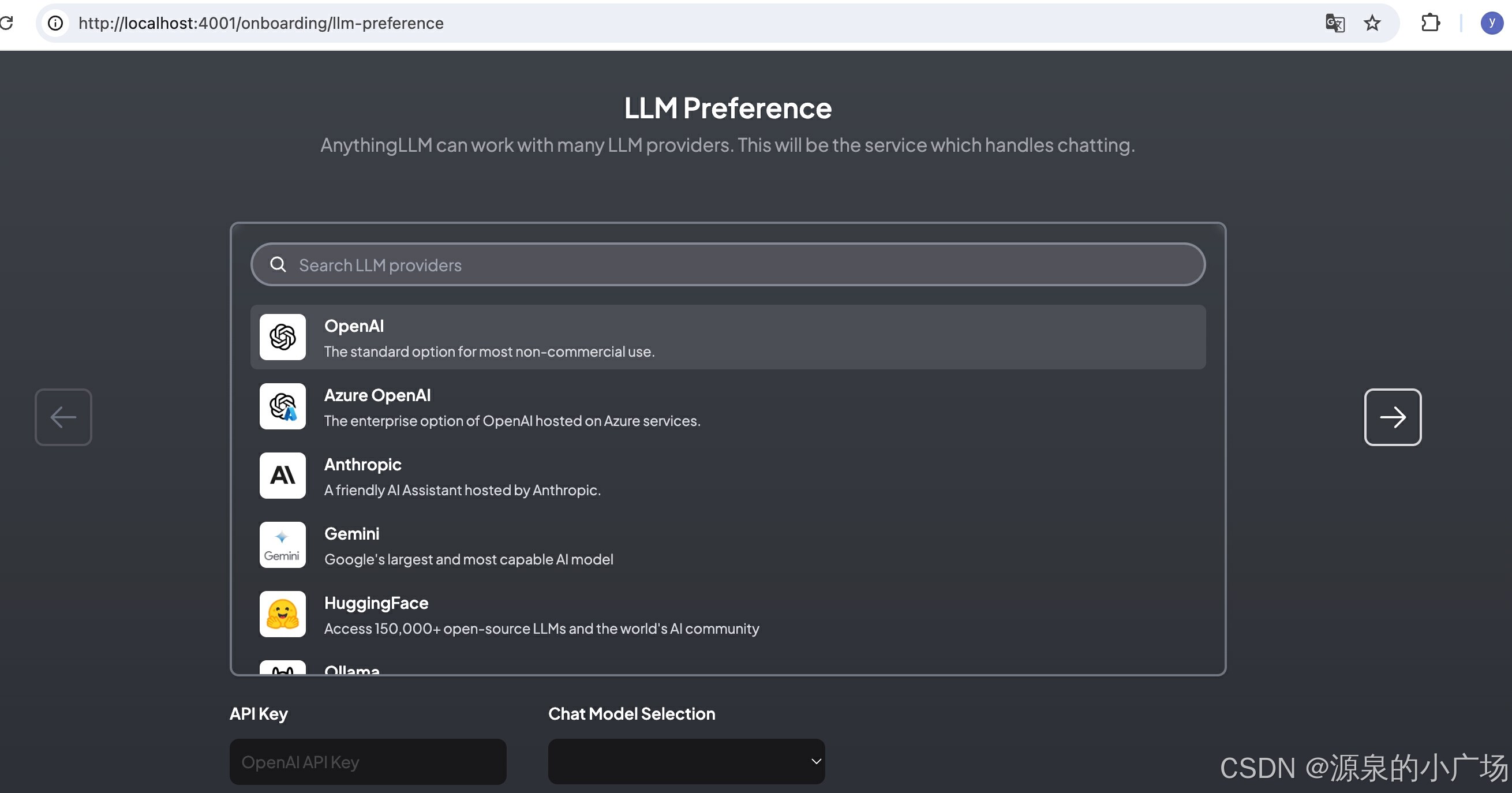
2.3 参数配置
2.3.1 配置LLM provider
我们这里就选择ollama服务。我选择了gemma2:2b,最大tokens数量设置4096.
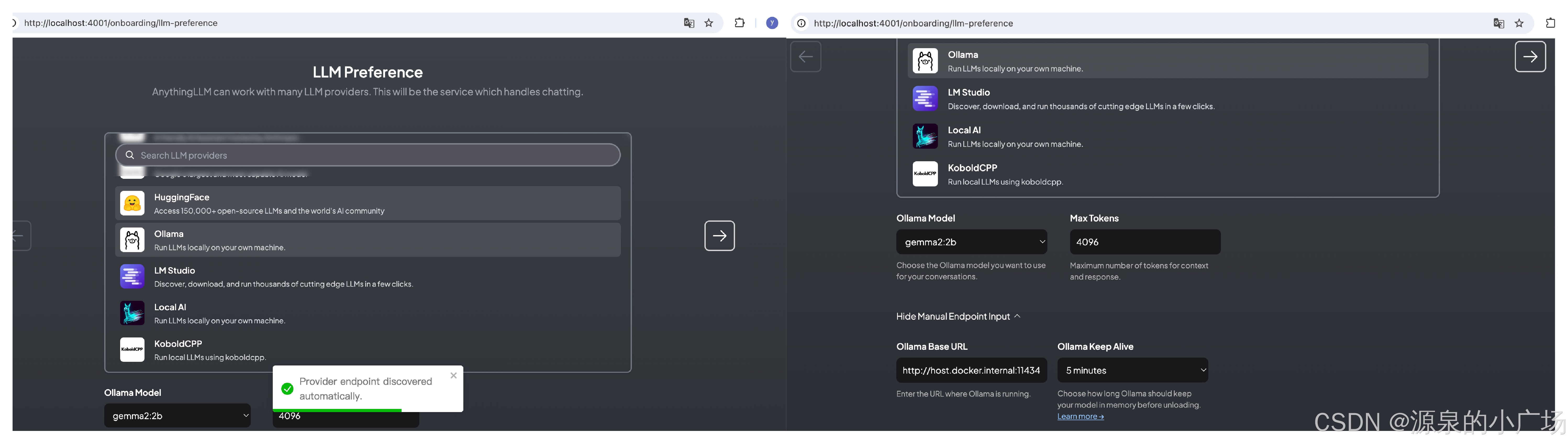
2.3.2 用户范围设置
AnythingLLM支持设置个人使用和团队使用,如果选择团队使用,需要配置管理员账户,其他成员加入需要管理员审核。
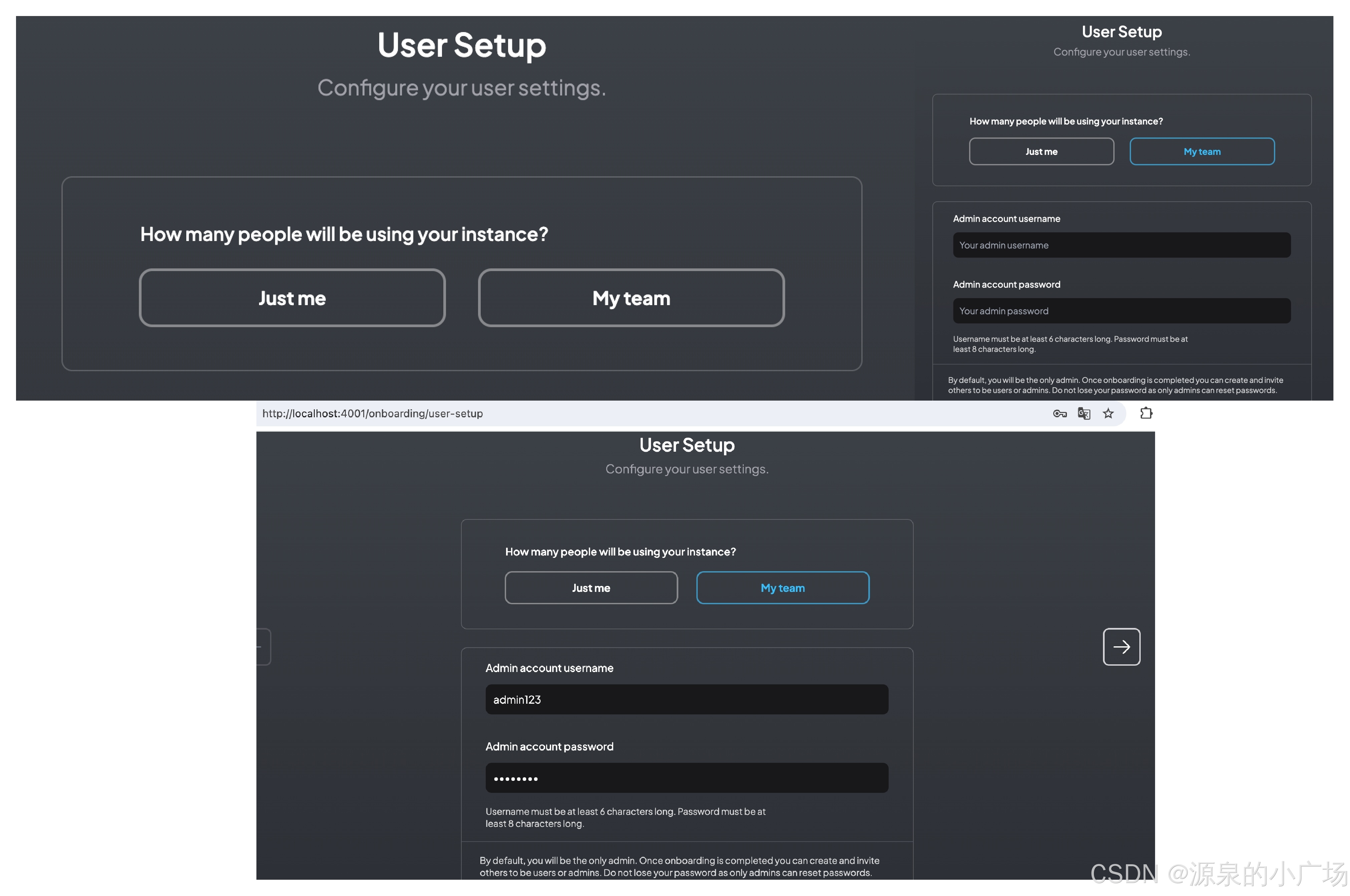
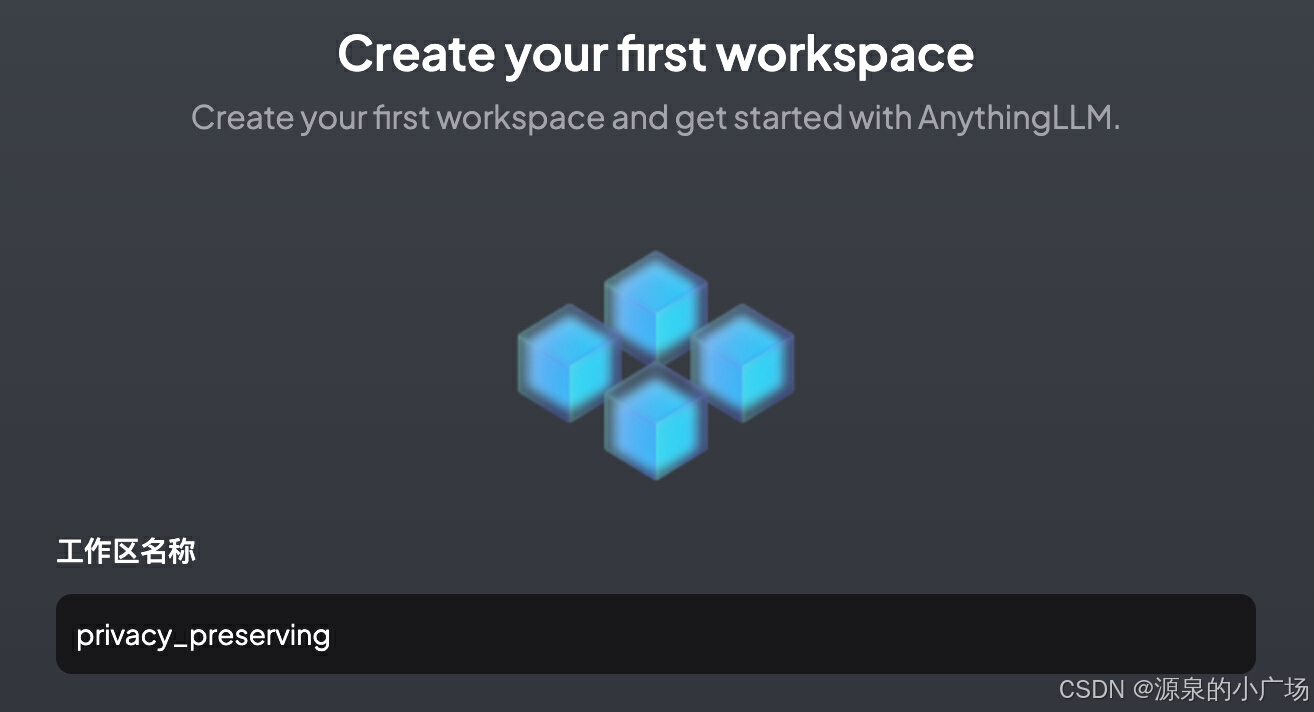
2.3.3 配置工作区
AnythingLLM支持创建工作区,这个想法还挺好的。不同的工作区相对独立,互补影响。可以创建不同垂直领域的知识库和问答应用。这里我创建了隐私计算工作区。
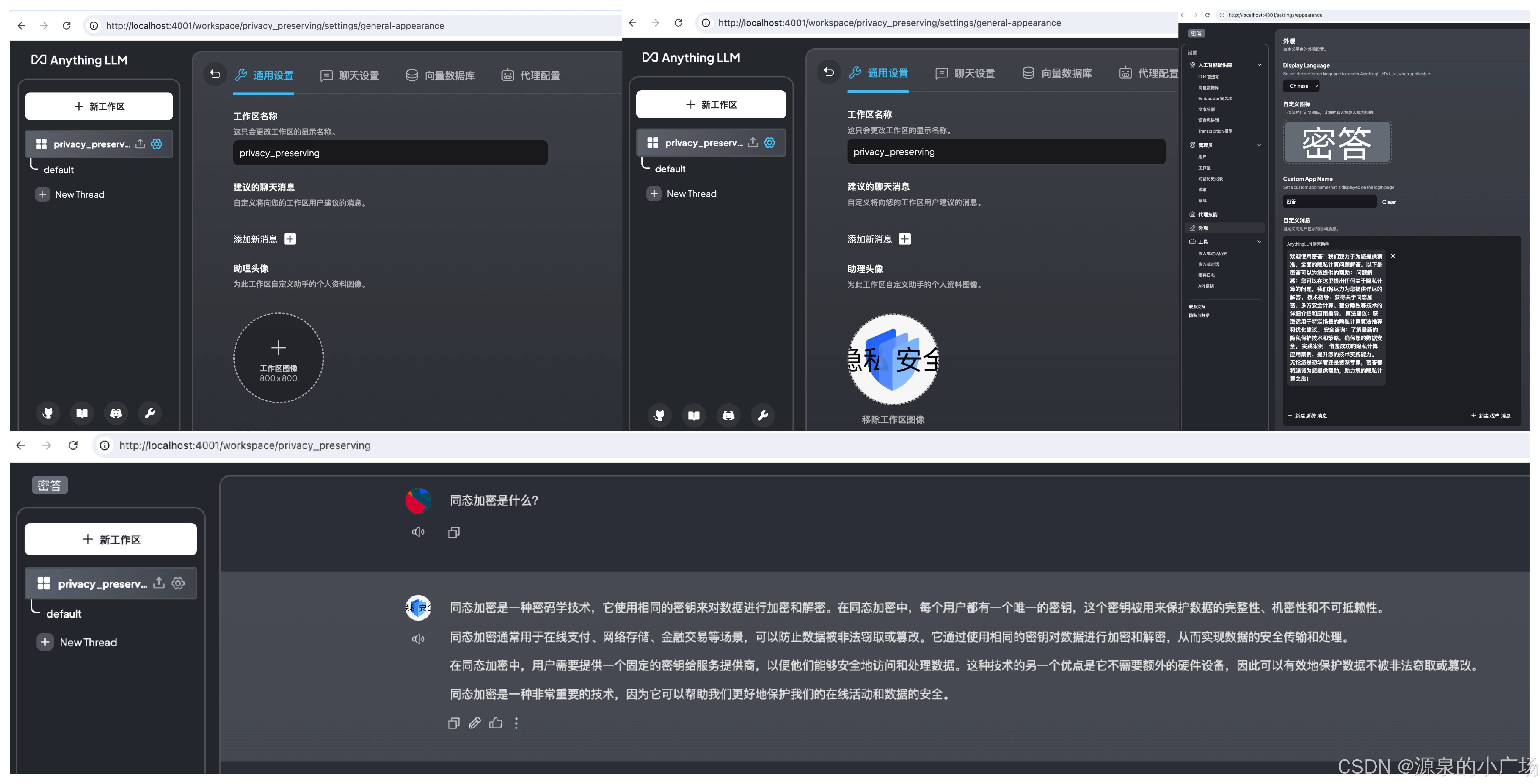
2.3.4 外观定制配置
可以根据自己的需求,定制外观展示,比如配置logo和平台名称等。这里我设置隐私计算知识稳单系统名称为“密答”。
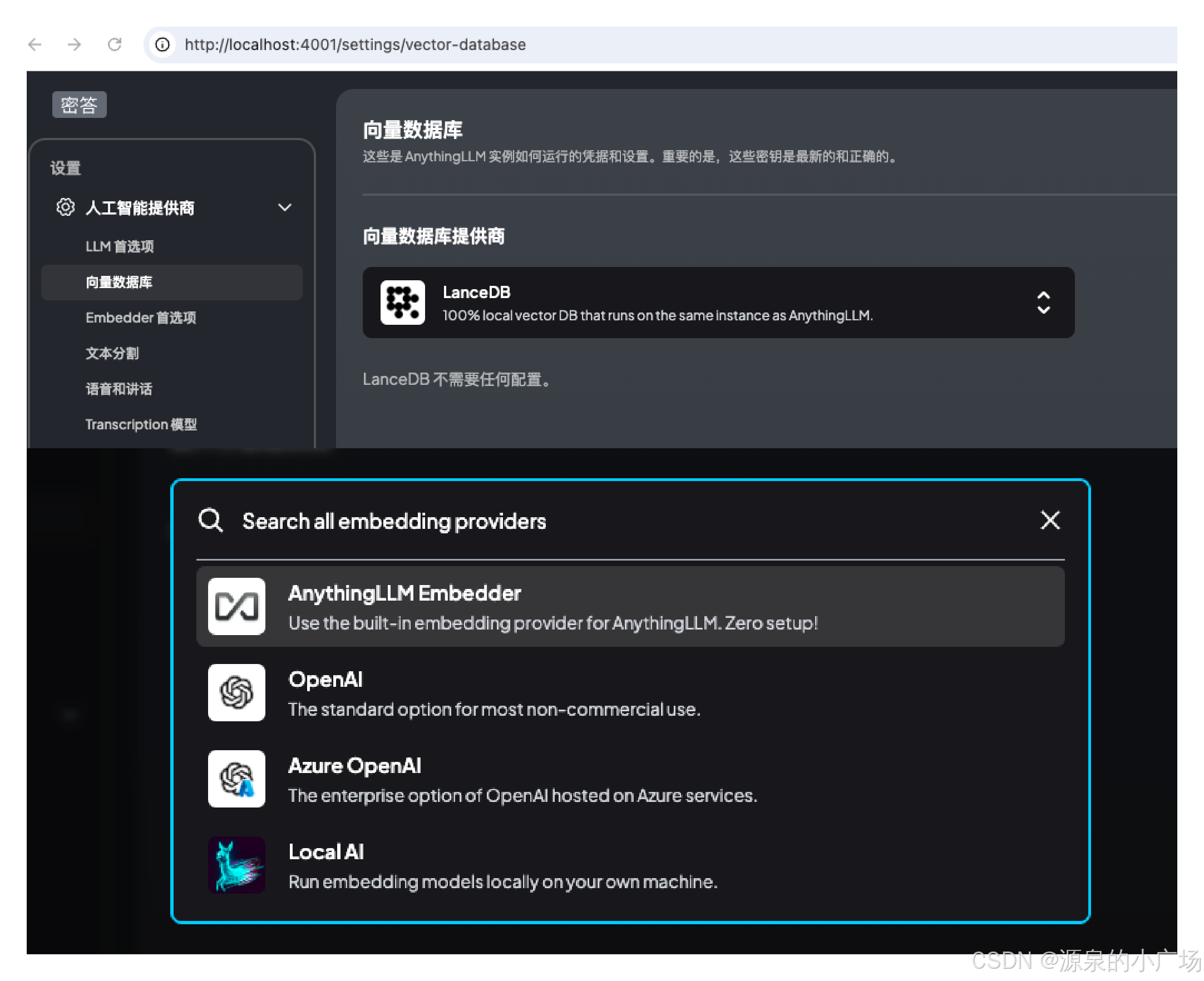
2.3.5 向量数据库和向量化模型的选择和配置
这里为了方便起见,我们使用了内置的LanceDB,以及内置的Embedder。可以按照自己的需求进行定制配置。Embedder的重要性比较高,最好使用向量表征能力强的模型,不然后续的向量检索质量也难以保证。
2.3.6 上传垂直领域知识内容
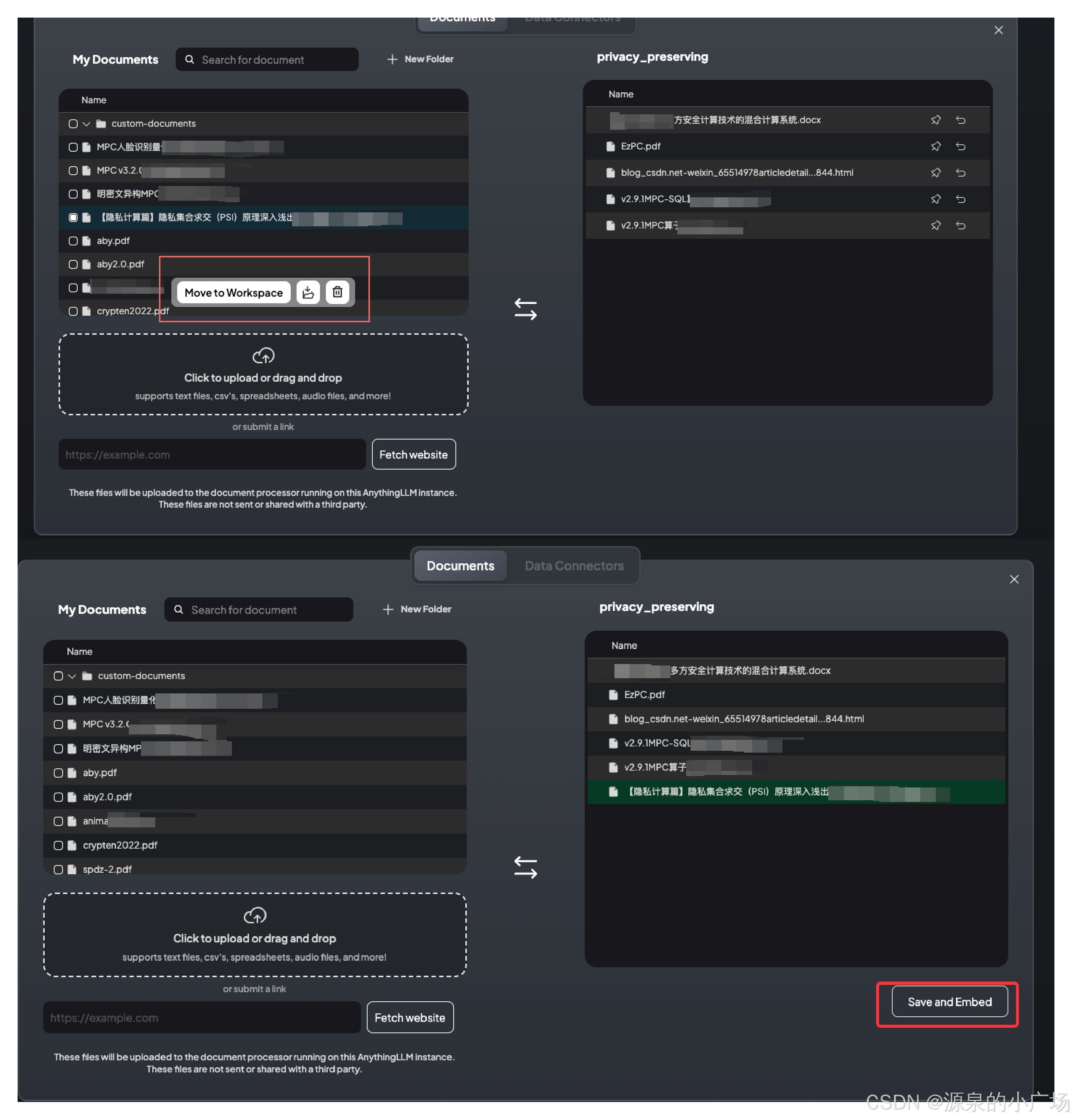
接下来就是重头戏,上传隐私计算知识文档,可以支持各种类型文件:pdf、txt、word。不过建议还是转换成markdown的文件,既能够保证结构,又可以保持文本状态,减少pdf之类文件的复杂性,导致向量化存在问题。左侧操作框是上传的文件,需要选择对应文件移动到相应的工作区,然后执行保存和向量化,处理成功后就可以回到问答界面。
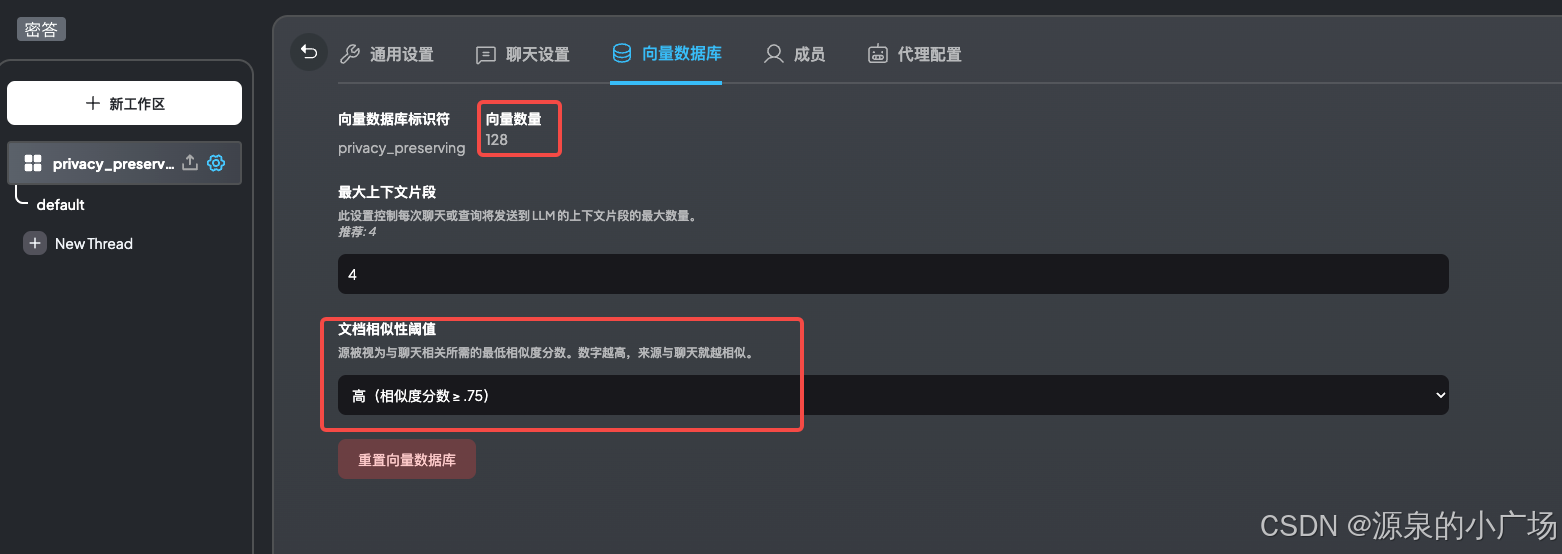
2.3.7 知识库关键参数配置
这里需要提示一下,在基于知识库的问答中,为了回答的问题尽可能与所提供知识相关,可以将知识库文档相似性阈值设置的高一些,实际体验下来效果会更准确。
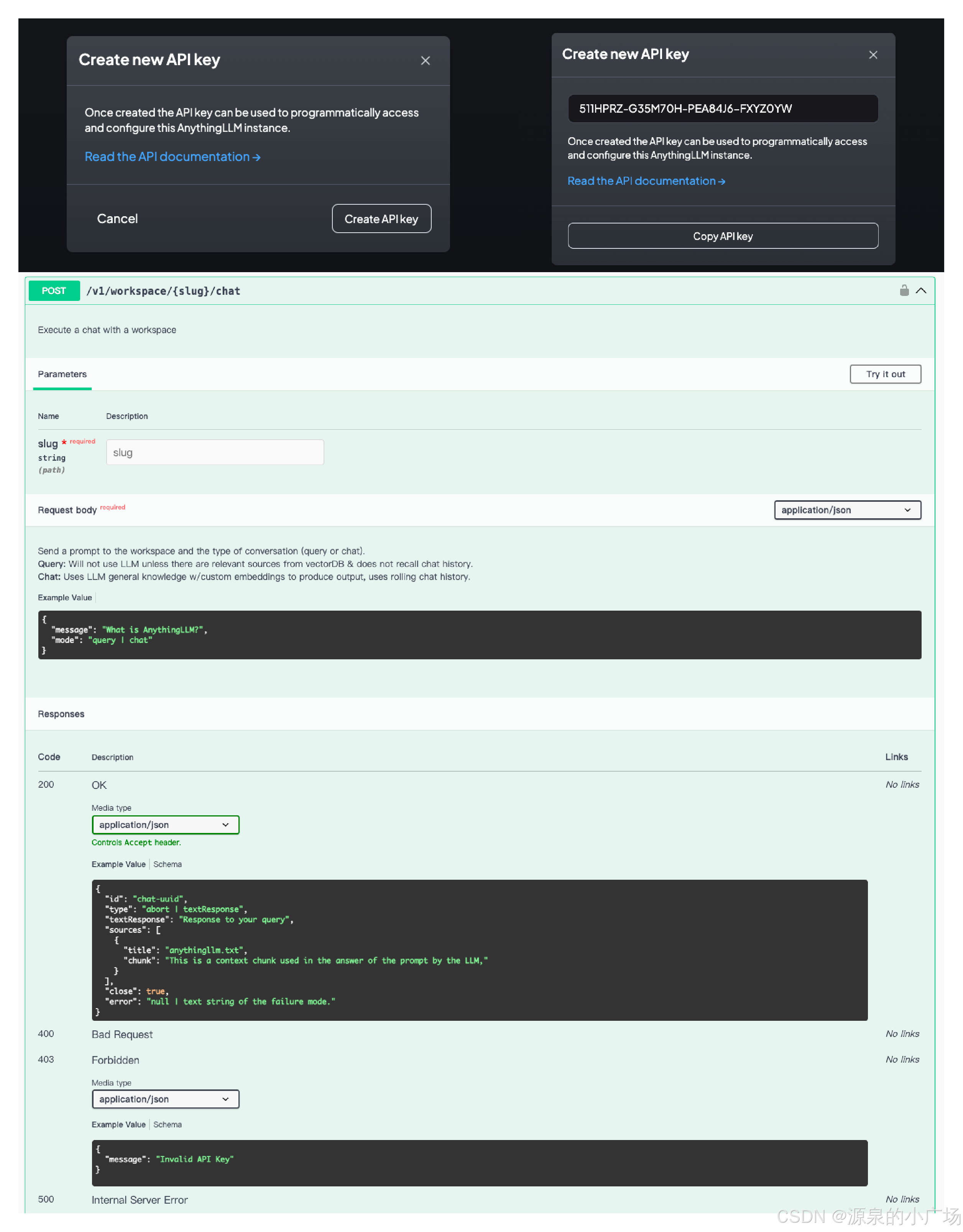
2.3.8 API对外服务能力
AnythingLLM还提供了API服务能力,使用方法可以参考API文档。
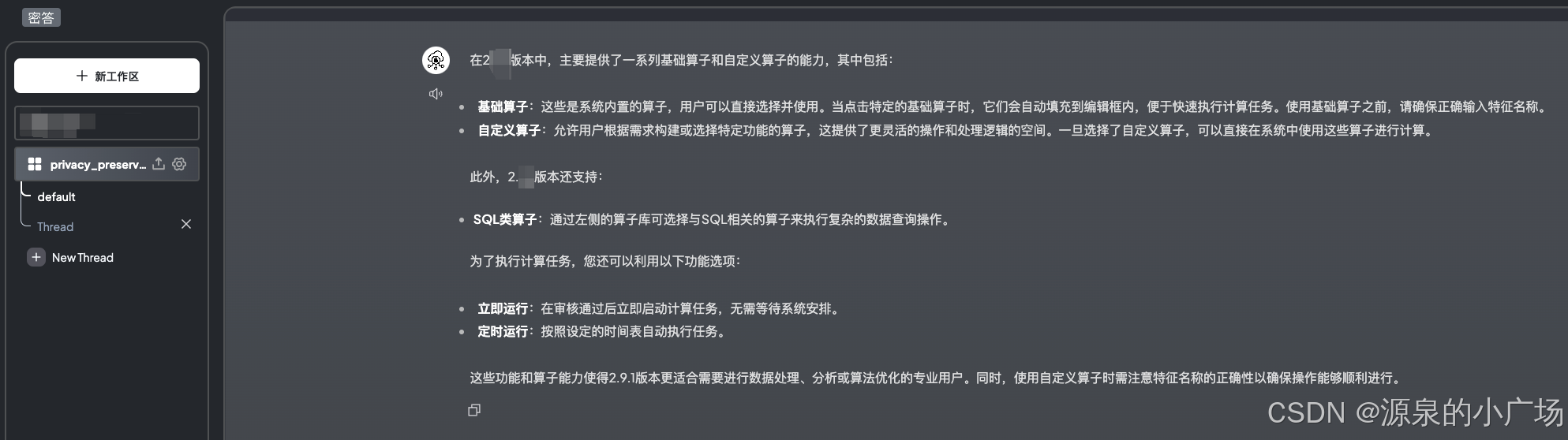
2.4 操作体验
测试了一个上传知识中的版本功能问题,回答挺不错。不过为了尽可能提升效果,需要好好处理你的知识文档以及选择合适的向量化模型、问答模型,这些都是影响因素。
本次分享介绍了基于本地垂直知识的隐私计算知识问答系统的搭建方法和初步使用体验。想要能够上生产的版本,还有很多工作要做,继续尝试优化提升。