
阅读量:0
准备工作
本节内容涉及深度学习的相关知识
安装必要的库:
pip install torch torchvision
pip install captcha
这里并不会学习深度学习相关的知识,所以有关深度学习方面的代码需要下载
Python3WebSpider/DeepLearningImageCaptcha: DeepLearning Image Captcha (github.com)
pytorch 安装流程和问题
安装
这里的的系统是 windows , 没有 GPU
1. 首先下载:

根据序号解释:
①:stable : 稳定版 preview :测试版 无特殊需求,选稳定版
②: 系统:根据自己系统选择
③:管理方式或者安装方式, 在有 conda(Anaconde) 的情况下 建议选 conda
④: 语言类型
⑤: GPU或 CPU ,如果选GPU 注意自己的版本 查看GPU 版本 (nvidia-smi)
⑥: 上面都选好之后就可以复制代码,到自己的环境中下载了
如果网站打不开,可以直接复制这段代码, CPU 版本的
conda install pytorch torchvision torchaudio cpuonly -c pytorch
说明:这个是在官网直接下载,如果网速不好,可能会很慢
也可以用镜像源下载,这里提供一个 清华源, 也可以找其他的
Index of /anaconda/cloud/pytorch/win-64/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/win-64/
将上面的 pytorch 换成这个地址即可, 也可以自己打开网站,再复制
安装完成之后,会在末尾出现 done 表示安装成功
可以看一下,是否有相关的库, 嫌麻烦,这一步可以省略
输入
conda list
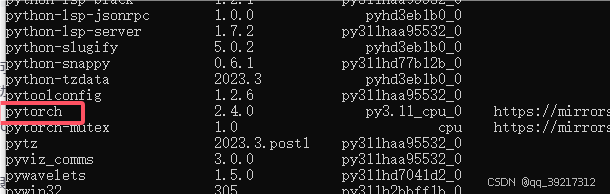
验证是否成功安装
打开刚刚的环境,什么方式都行,这里用 Anaconda Prompt
首先要进入自己的环境:
查看现有环境: conda info --envs
选择环境: activate 环境名
输入 ; python 或者自己设置的 python 环境变量

然后导入 torch
import torch
回车
我的在这一步出错了 错误提示:
OSError: [WinError 126] 找不到指定的模块。 Error loading “E:\python310\lib\site-packages\torch\lib\fbgemm.dll
路径名可能不一样,主要看报错的文件名 fbgemm.dll
首先要在报错路径下,看看这个文件是否存在,我的存在
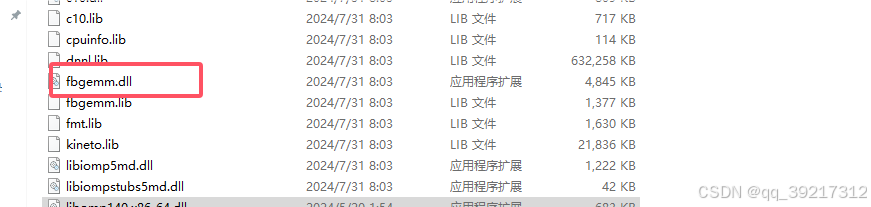
那就可能是依赖出问题了
需要下载一个依赖检测程序
Release minor fix on version number · lucasg/Dependencies (github.com)
下载,解压, 运行
选择 file --- open ----找到刚才报错路径下的那个文件 ---打开
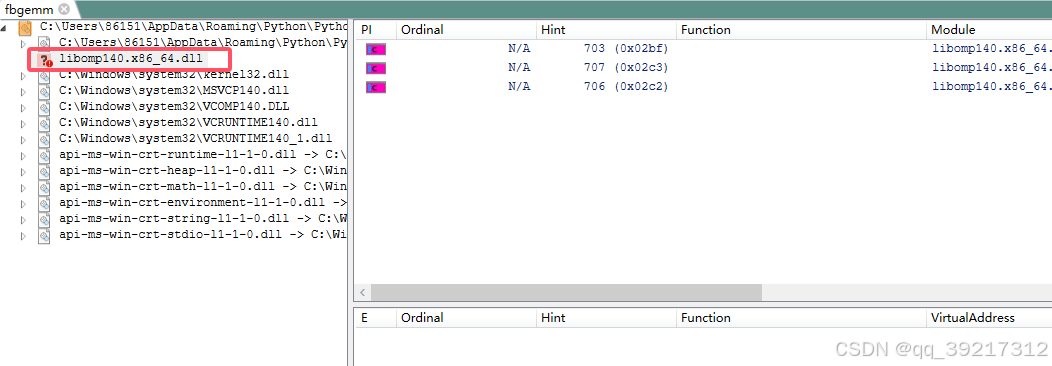
可以看到这个文件不对,需要下载这个文件
libomp140.x86_64.dll : Free .DLL download. (dllme.com)
下载之后,解压

将这个文件移动到刚刚报错的文件夹下,就 OK 了
数据准备
要训练一个深度学习模型,必不可少的就是训练数据。训练数据分为两部分,一部分是图片数据, 即一张张验证码图片,另一部分是标注数据,即验证码的内容是什么。有了这两部分数据,就可以训练一个识别图形验证码的深度学习模型,模型在训练中不断调优的过程,就是逐渐学会怎么识别一张验证码的过程。训练好之后,向模型输入类似的验证码图片,验证码就可以识别出对应的文本内容了
那这些数据标注怎么准备呢? 如果你稍微了解过深度学习相关的内容,相信并不会对数据标注这个词感到陌生, 数据标注有相当一部分是需要人工参与的。加入我们有很多验证码图片,又不知道验证码图片对应的内容是什么,就需要用到数据标注了。说白了,就是看一下验证码图片,然后把里面的文字记录下来,就相当于标注了一条数据
我们为了训练一个较好的用于识别图形验证码的深度学习模型,可能需要几万,十几万,甚至几十万条训练数据,此时如果只有验证码图片而没有标注,就需要人工标注,这是个非常耗时且枯燥的工作
那么解决办法是什么? 我们可以先随机生成和验证码位数相同的数字或字母组合而成的数据,然后使用这些数据生成对应的验证码,这样就可以不用标注了
上述生成验证码的过程分为两步,第一步是生成随机文本数据,第二步是根据生成的文本数据生成验证码图片,打开项目中的 generate.py 文件, 其中定义了两个方法
generate_captcha_text 和 generate_captcha_text_and_image
# -*- coding: UTF-8 -*- from captcha.image import ImageCaptcha # pip install captcha from PIL import Image import random import time import setting import os def generate_captcha_text(): captcha_text = [] for i in range(setting.MAX_CAPTCHA): c = random.choice(setting.ALL_CHAR_SET) captcha_text.append(c) return ''.join(captcha_text) def generate_captcha_text_and_image(): image = ImageCaptcha() captcha_text = generate_captcha_text() captcha_image = Image.open(image.generate(captcha_text)) return captcha_text, captcha_image if __name__ == '__main__': count = 3000 path = setting.EVAL_DATASET_PATH if not os.path.exists(path): os.makedirs(path) for i in range(count): now = str(int(time.time())) text, image = generate_captcha_text_and_image() filename = text + '_' + now + '.png' image.save(path + os.path.sep + filename) print('saved %d : %s' % (i + 1, filename)) 这里的 generate_captcha_text 方法用于生成随机文本数据,可以看到方法中定义了一个执行 MAX_CAPTCHA 次的 for 循环, 每次循环都利用 random.choice 方法随机从 ALL_CHAR_SET 里挑选一个字符放入 captcha_text , 最后将 captcha_text 中的字符拼接在一起
其中 MAX_CAPTCHA 和 ALL_CHAR_SET 定义在 setting.py 里面
NUMBER = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'] ALPHABET = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z'] ALL_CHAR_SET = NUMBER + ALPHABET ALL_CHAR_SET_LEN = len(ALL_CHAR_SET) MAX_CAPTCHA = 4
可以看到 MAX_CAPTCHA 的值是 4 ,所以最后拼接而成的就是 4 位的验证码。 ALL_CHAR_SET 里面是 10 个阿拉伯数字, 和 26 个英文字母构成的列表, 所以拼接而成的验证码的文本是 4 位数字和字母的组合
接下来我们修改 generate.py 文件, 先生成一批数据, 建议生成 10 万个验证码
count = 100000 path = setting.TRAIN_DATASET_PATH
其中 cout 就是验证码的个数, 这里直接设置为 100000 ,path 是验证码的保存路径, 这在 setting.py 中定义好的了
TRAIN_DATASET_PATH : 训练集所在的路径,数据用于模型的训练
EVAL_DATASET_PATH : 验证集所在的路径,一般在训练过程中,或者训练完毕后用到,可用于验证模型的训练效果
PREDICT_DATASET_PATH : 推理集,一般在训练完毕后用到,可用于模型的推理和测试
然后运行 generate.py, 输出了很多数据, 这里就不展示了
利用同样的方法,可以生成验证集, 用于验证模型的训练效果
count = 3000
path = setting.EVAL_DATASET_PATH
验证集不需要像训练集那么大, count 就修改为 3000 , path 修改为:EVAL_DATASET_PATH ,然后重新运行 generate.py , 这样就生成了验证集的数据,这样数据集就都准备好了
模型训练
这里我们使用的深度学习模型是一个基本的 CNN 模型, 模型定义在 model.py 文件中
# -*- coding: UTF-8 -*- import torch.nn as nn import setting # CNN Model (2 conv layer) class CNN(nn.Module): def __init__(self): super(CNN, self).__init__() self.layer1 = nn.Sequential( nn.Conv2d(1, 32, kernel_size=3, padding=1), nn.BatchNorm2d(32), nn.Dropout(0.5), # drop 50% of the neuron nn.ReLU(), nn.MaxPool2d(2)) self.layer2 = nn.Sequential( nn.Conv2d(32, 64, kernel_size=3, padding=1), nn.BatchNorm2d(64), nn.Dropout(0.5), # drop 50% of the neuron nn.ReLU(), nn.MaxPool2d(2)) self.layer3 = nn.Sequential( nn.Conv2d(64, 64, kernel_size=3, padding=1), nn.BatchNorm2d(64), nn.Dropout(0.5), # drop 50% of the neuron nn.ReLU(), nn.MaxPool2d(2)) self.fc = nn.Sequential( nn.Linear((setting.IMAGE_WIDTH // 8) * (setting.IMAGE_HEIGHT // 8) * 64, 1024), nn.Dropout(0.5), # drop 50% of the neuron nn.ReLU()) self.rfc = nn.Sequential( nn.Linear(1024, setting.MAX_CAPTCHA * setting.ALL_CHAR_SET_LEN), ) def forward(self, x): out = self.layer1(x) out = self.layer2(out) out = self.layer3(out) out = out.view(out.size(0), -1) out = self.fc(out) out = self.rfc(out) return outk
可以看到这里定义了三层, 每层都是 Conv2d(卷积), BatchNorm2d(批标准化), Dropout (随机失活), Relu(激活函数)和 MaxPool2d (池化) 的组合, 经过这三层的处理后, 由一个全连接网络层输出最终结果, 用于计算模型的最终损失
模型的训练过程定义在 train.py 文件中, 整个训练逻辑是这样的
(1): 引入定义好的模型, 即 model.py 文件, 对模型进行初始化
(2): 定义损失函数 loss
(3): 定义优化器 optimizer
(4): 加载数据,一般包括训练数集数据和验证集数据
(5): 执行训练, 这个过程包括反向求导,模型权重更新
(6):在执行完特定的训练步数后,验证和保存模型
了解完基本的逻辑后,就可以尝试用现有的数据训练一个深度学习的模型了
运行 train.py 即可
epoch: 0 step: 9 loss: 0.20833534002304077
epoch: 0 step: 19 loss: 0.14808568358421326
这里会看到,训练过程中模型的损失在不断的降低,说明模型在不断的学习和优化,同时每训练完一个轮次后都会执行一次模型验证。由于在训练模型时没有使用验证集数据,所以用验证集数据来验证时可以得到模型的真实正确率的,是更为科学的
注意: GPU的速度会快过CPU ,不过如果不懂的话,可以先训练,有时间再捣鼓
经过一段时间的训练,模型的损失趋近于 0 , 训练的正确率在不断的上升,验证的正确率能达到 96% 以上, 最后可以在本地看到一个 best_model.pkl 文件, 这便是我们想要的模型
这里的正确率和损失值不一定要一样,不同机器会有不同结果,不用纠结
测试
现在我们来测试一下得到的模型,现在 PTEDICT-DATASET_PATH 变量对应的路径下生成几个验证码图片, 生成过程前面有提到过,这里随意选两个图片验证码放在哪个路径下
然后在 predict.py 文件中加载上面得到的模型 best_model.pkl 关键代码如下
cnn.load_state_dict(torch.load('best_model.pkl'))
并根据加载的模型对定义的 CNN模型的权重进行初始化, 整个模型加载完毕后,就和刚才训练时一样强大,拥有识别验证码的能力
运行 predict.py
这里运行时间太长,可以适当改变参数,缩短运行时间。
总结: 这里主要介绍了利用深度学习模型识别图形验证码的整体流程, 最终我们成功训练出模型,并得到了一个深度学习模型文件。往这个模型中输入一张图形验证码图片,它便会预测出其中文本的内容
至此我们可以基于本节内容做出进一步的优化
(1): 由于本节使用的验证码都是由, captcha 库生成的, 验证码的风格也都是事先设定好的, 所以模型的识别正确率会相对较高。 但如果输入其他类型的验证码,例如文本形状,文本数量,干扰线样式和本节不同, 模型识别的正确率可能并不理想。为了能过让模型识别更多的验证码,可以多生成一些不同风格的验证码来训练模型,这样得到的模型会更加的健壮
(2): 当前的模型的预测过程并不是很方便,可以考虑将预测过程对接 API 服务器,例如 Flask, Django , FastAPI 等, 把预测过程实现为一个支持 POST 请求的 API , 这个 API 可以接收一张验证码图片, 并返回验证码的文本信息,这样会使模型更加方便易用
