
阅读量:0
代码复现的框架是基于:pengsida 的 Learning NeRF
源代码框架是基于 Linux 的,我在 Windows 上进行复现有些许 bug,Windows 上 bug 修复的框架版本:Learning NeRF
希望各位可以通过学习 NeRF-Pytorch 的源码来自己复现一下试试看!
文章目录
1 创建Dateset
核心函数包括:init,getitem,len
init函数负责从磁盘中load指定格式的文件,计算并存储为特定形式getitem函数负责在运行时提供给网络一次训练需要的输入,以及 groundtruth 的输出例如对NeRF,分别是1024条 rays 以及1024个 RGB 值
len函数是训练或者测试的数量:getitem函数获得的index值通常是[0, len-1]
1.1 __init__
这里我们主要要做3件事(公平公平还是tmd公平)
加载图像数据和相机位姿信息:
从磁盘中读取指定格式的文件,这些文件包含了图像路径和相机位姿信息,位姿保存在
self.poses从图片路径保存图片,并根据参数进行处理(白色背景+缩放比例)
最后,将处理后的图像添加到
self.images列表中
计算相机内参:
- 根据相机的视场角(FOV)和图像尺寸计算相机的焦距和相机矩阵
生成射线数据:
首先,对于每一个位姿,使用
rh.get_rays_np函数生成射线,并将所有射线堆叠起来然后,将射线和图像数据合并,并进行一系列的变换和重塑操作形成形状为
[N, H, W, ro+rd+rgb, 3]的numpy数组rays_rgbN是图像的数量H是图像的高度W是图像的宽度ro+rd+rgb表示每个射线的数据,包括射线的起始点(ro)、射线的方向(rd)和射线对应的像素颜色(rgb)3表示每个数据都是一个三维向量(例如,rgb颜色是一个三维向量,包含红色、绿色和蓝色的强度)
表示有
N*H*W条射线,每条射线有3个数据(ro、rd、rgb),每个数据都是一个三维向量存储打乱前的射线
img_rays_rgb, 一张一张图片存储的,没有整合在一起 ,形状为[N, H*W, ro+rd+rgb, 3],再转换为 Tensor
1.2 __getitem__
1.2.1 训练数据
主要功能是负责在运行时提供给网络一次训练需要的输入,以及 groundtruth 的输出 —— N_rays条rays和N_rays个RGB值 ( N_rays = 1024)
将所有的光线(rays)和对应的RGB值整合到一个数组中,然后将这个数组的形状从
[N, H, W, ro+rd+rgb, 3]改变为[-1, 3, 3],即将所有的光线和RGB值平铺到一个一维数组中得到[N*H*W, ro+rd+rgb, 3],并转为 Tensor对所有的光线和RGB值进行打乱,这里使用GPU加速了一下
打乱后,根据索引
index选择一个批次(1024条)的数据,再将批次的维度从第二位转换到第一位([1024,3,3]to[3,1024,3])在PyTorch中,通常希望批次维度在第一位,以便于进行批次处理
将选择的数据分为两部分:光线的数据(
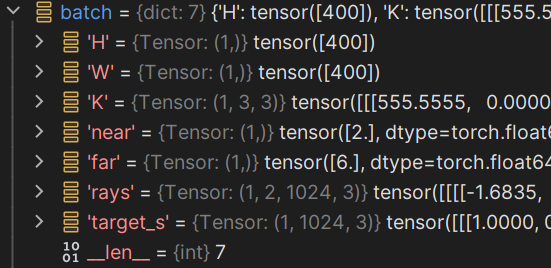
batch_rays)和对应的RGB值(target_s),并以字典的形式返回return {'H': self.H, 'W': self.W, 'K': self.K, 'near': self.near, 'far': self.far, 'rays': batch_rays, 'target_s': target_s}
1.2.2 测试数据
在测试时,输出一张图像的 rays 和 RGB 值,即 400 * 400 条 rays 和 400 * 400 个 RGB 值
从
self.img_rays_rgb中根据索引index获取一张图片的光线使用
torch.transpose函数将批次的维度从第二位转换到第一位([1024,3,3]to[3,1024,3])在PyTorch中,通常希望批次维度在第一位,以便于进行批次处理
将数据分解为射线数据
rays和对应的RGB值img_rgb;rays包含了每条射线的起始点和方向,img_rgb是每条射线对应的RGB值返回一个字典,包含了射线数据和对应的RGB值,以及对应的图片索引
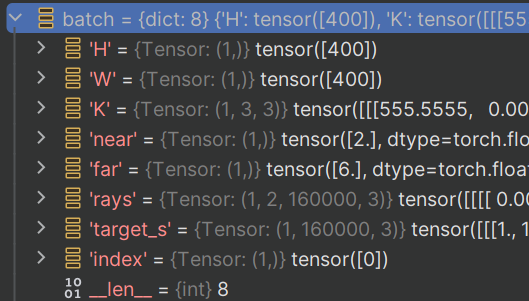
indexreturn {'H': self.H, 'W': self.W, 'K': self.K, 'near': self.near, 'far': self.far, 'rays': rays, 'target_s': img_rgb, 'index': index}
通过data_loader我们可以得到一个batch:
train:
test:
1.3 __len__
返回数据集的大小,即数据集中的样本数量,即图像的数量
2 Network
核心函数包括:__init__,__forward__
init函数负责定义网络所必需的模块forward函数负责接收Dataset的输出,利用定义好的模块,计算输出
对于NeRF来说,我们需要在init中定义两个 MLP 以及 encoding 方式,在forward函数中,使用rays完成计算
定义了两个主要的神经网络模型:NeRF 和 Network
2.1 NeRF 类
NeRF 类是NeRF的实现。它的结构包括了用于处理采样点和观察坐标方向的一系列MLP,以及相应的参数。主要方法是 forward,用于执行前向传播操作
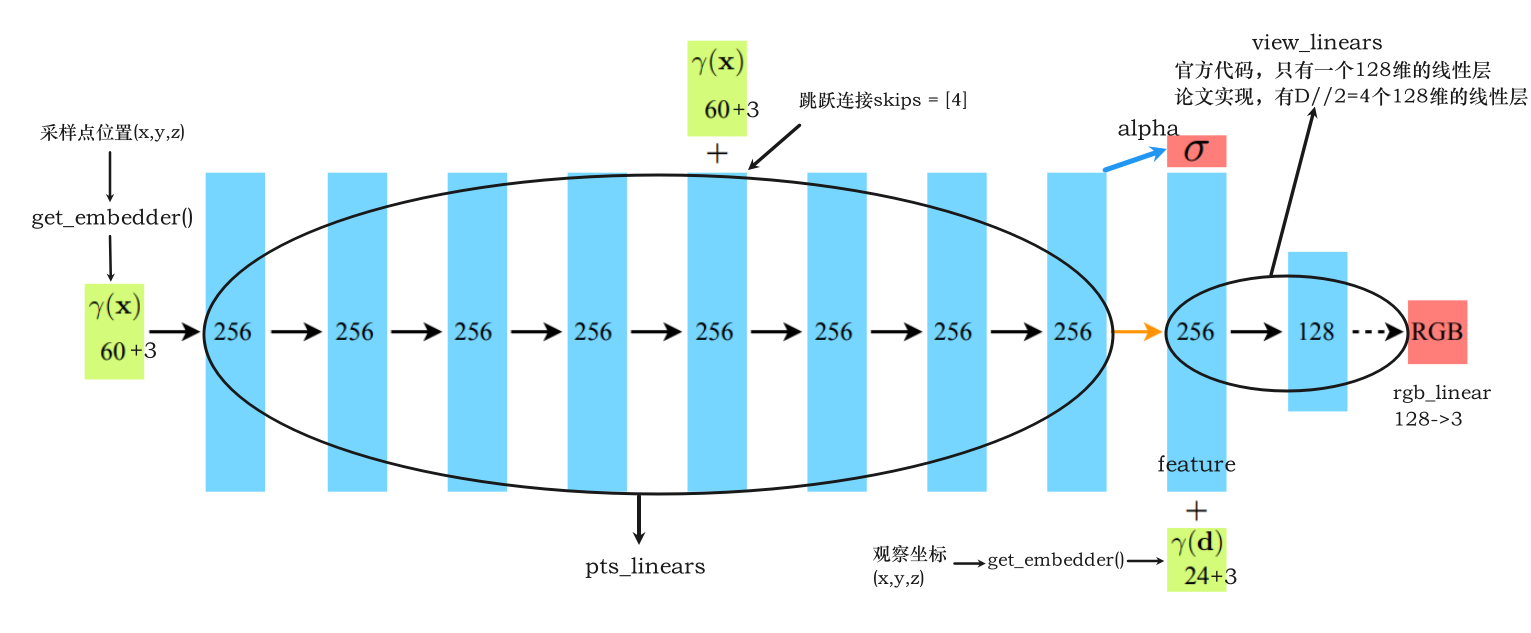
结构
__init__方法中定义了模型的各种参数和MLPforward方法实现了模型的前向传播逻辑,分别计算了辐射值和密度值,返回output——将rgb和alpha两个张量在最后一个维度上进行拼接outputs = torch.cat([rgb, alpha], -1)
2.2 Network 类
Network 类是整个神经网络的集成,其中包括了对 NeRF 模型的调用以及render的实现,完成模型的调用和计算模型产生的预估值(即在这部分完成渲染)
结构
__init__方法中初始化了整个网络模型,包括定义了两个NeRF模型(一个粗网络和一个精细网络),并根据配置参数进行设置batchify方法用于将函数应用于较小的批次数据network_query_fn方法,即网络查询函数,准备输入并将其传递给网络,并输出结果,使用batchify将一批一批的数据传入NeRF网络进行forwardforward方法,从batch中得到dataloader的数据,调用render函数:- 计算并创建射线,使用
render_utils中的batchify_rays进行放入网络得到结果,再渲染射线得到render_rays返回的字典(即最后的结果):
- 'rgb_map' (torch.Tensor): 每条光线的估计 RGB 颜色。形状:[num_rays, 3]。 - 'disp_map' (torch.Tensor): 每条光线的视差图(深度图的倒数)。形状:[num_rays]。 - 'acc_map' (torch.Tensor): 沿每条光线的权重总和。形状:[num_rays]。 - 'rgb0' (torch.Tensor): 粗模型的输出 RGB。见 rgb_map。形状:[num_rays, 3]。 - 'disp0' (torch.Tensor): 粗模型的输出视差图。见 disp_map。形状:[num_rays]。 - 'acc0' (torch.Tensor): 粗模型的输出累积不透明度。见 acc_map。形状:[num_rays]。 - 'z_std' (torch.Tensor): 每个样本沿光线的距离的标准差。形状:[num_rays]。再对结果进行整理得到一个列表
- 计算并创建射线,使用
通过dataloader的batch传入网络,最终得到整理后的结果:
一个包含了所有渲染结果和相关信息的列表
前面 0、1、2 对应 'rgb_map'、'disp_map'、'acc_map'
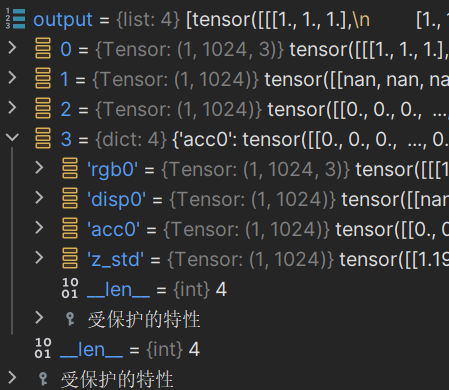
所有张量类型如下
dtype = torch.float64 device = device(type='cuda', index=0) 2.3 Render
增加 render_utils,并修改 raw2outputs()、render_rays() 函数使数据移动至 cuda 进行计算
3 Loss & Evaluate
3.1 Loss
loss 模块主要为 NetworkWrapper 的类。forward 方法即是 loss 计算的过程。
- 方法中,首先通过
self.net(batch)调用传入的神经网络模型进行预测 - 然后计算预测的RGB值与目标RGB值之间的MSE,并将其转换为PSNR。如果输出中包含rgb0(即包含粗网络预测的值),则还会计算粗网络的预测值RGB与目标RGB值之间的MSE和PSNR。
- 最后,将所有的统计量(包括PSNR和损失)添加到scalar_stats字典中,并返回。
3.2 Evaluate
evaluate 模块在这个项目中主要用于评估模型的性能。并将评估结果保存为图像文件和JSON文件。
- 首先从模型的输出和批次数据中获取预测的RGB值和真实的RGB值
- 计算均方误差(MSE)和峰值信噪比(PSNR)
- 将预测的RGB值和真实的RGB值重塑为图像的形状。再将真实的RGB值和预测的RGB值水平拼接在一起,并保存为图像,形成对比
